#69 in a series of articles about the technology behind Bang & Olufsen loudspeakers
#68 in a series of articles about the technology behind Bang & Olufsen loudspeakers
#67 in a series of articles about the technology behind Bang & Olufsen loudspeakers
This was recorded by one of the journalists that was invited to the first press event for BeoLab 50. This was some months ago… so there are some comments in there about some details not yet finalised…
#65 in a series of articles about the technology behind Bang & Olufsen loudspeakers
Although active Beam Width Control is a feature that was first released with the BeoLab 90 in November of 2015, the question of loudspeaker directivity has been a primary concern in Bang & Olufsen’s acoustics research and development for decades.
As a primer, for a history of loudspeaker directivity at B&O, please read the article in the book downloadable at this site. You can read about the directivity in the BeoLab 5 here, or about the development Beam Width Control in BeoLab 90 here and here.
Bang & Olufsen has just released its second loudspeaker with Beam Width Control – the BeoLab 50. This loudspeaker borrows some techniques from the BeoLab 90, and introduces a new method of controlling horizontal directivity: a moveable Acoustic Lens.

The three woofers and three midrange drivers of the BeoLab 50 (seen above in Figure 1) are each driven by its own amplifier, DAC and signal processing chain. This allows us to create a custom digital filter for each driver that allows us to control not only its magnitude response, but its behaviour both in time and phase (vs. frequency). This means that, just as in the BeoLab 90, the drivers can either cancel each other’s signals, or work together, in different directions radiating outwards from the loudspeaker. This means that, by manipulating the filters in the DSP (the Digital Signal Processing) chain, the loudspeaker can either produce a narrow or a wide beam of sound in the horizontal plane, according to the preferences of the listener.
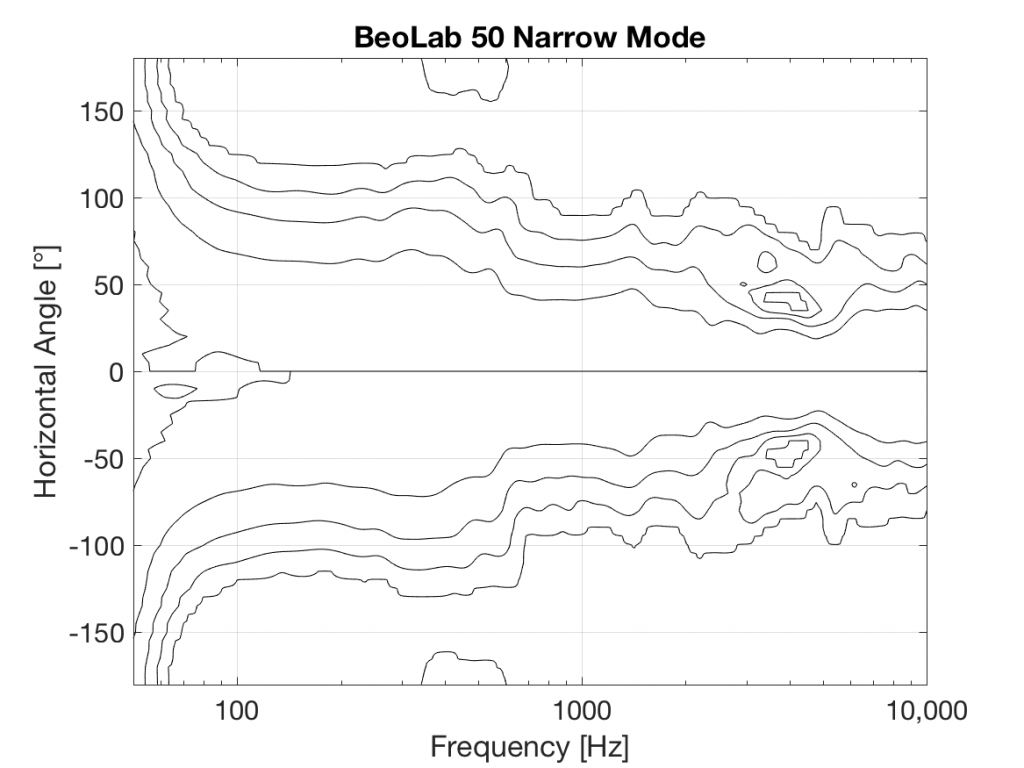
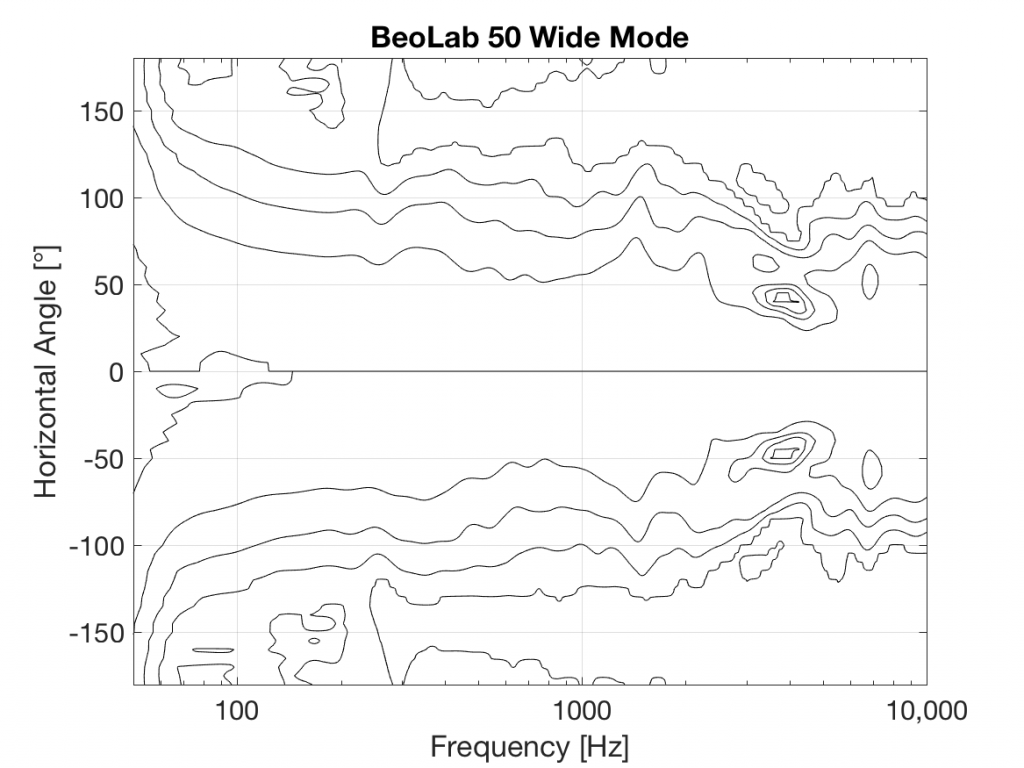
You’ll see that there is only one tweeter, and it is placed in an Acoustic Lens that is somewhat similar to the one that was first used in the BeoLab 5 in 2002. However, BeoLab 50’s Acoustic Lens is considerably different in a couple of respects.
Firstly, the geometry of the Lens has been completely re-engineered, resulting in a significant improvement in its behaviour over the frequency range of the loudspeaker driver. One of the obvious results of this change is its diameter – it’s much larger than the lens on the tweeter of the BeoLab 5. In addition, if you were to slice the BeoLab 50 Lens vertically, you will see that the shape of the curve has changed as well.
However, the Acoustic Lens was originally designed to ensure that the horizontal width of sound radiating from a tweeter was not only more like itself over a wider frequency range – but that it was also quite wide when compared to a conventional tweeter. So what’s an Acoustic Lens doing on a loudspeaker that can also be used in a Narrow mode? Well, another update to the Acoustic Lens is the movable “cheeks” on either side of the tweeter. These can be angled to a more narrow position that focuses the beam width of the tweeter to match the width of the midrange drivers.

In Wide Mode, the sides of the lens open up to produce a wider radiation pattern, just as in the original Acoustic Lens.

So, the BeoLab 50 provides a selectable Beam Width, but does so not only “merely” by changing filters in the DSP, but also with moving mechanical components.
Of course, changing the geometry of the Lens not only alters the directivity, but it changes the magnitude response of the tweeter as well – even in a free field (a theoretical, infinitely large room that is free of reflections). As a result, it was necessary to have a different tuning of the signal sent to the tweeter in order to compensate for that difference and ensure that the overall “sound” of the BeoLab 50 does not change when switching between the two beam widths. This is similar to what is done in the Active Room Compensation, where a different filter is required to compensate for the room’s acoustical behaviour for each beam width. This is because, at least as far as the room is concerned, changing the beam width changes how the loudspeaker couples to the room at different frequencies.