I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video demonstrates some of the individual components of a room’s acoustical contributions.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video presents an intuitive explanation of why we typically need bigger loudspeaker drivers to reproduce low frequency bands, and smaller drivers for higher bands.
Yesterday, I once again read something on the Internet by someone saying something like “of course, as you know, high frequency sound travels faster than low frequencies”.
This is not true for any practical purposes within the limits of human hearing.
The speed of sound in air, in m/s is approximately
331.67 + 0.607*Temperature
So, at 20°C, the speed of sound is just under 344 m/s. I normally say 345 m/s, partly because 22°C is a good guess, and it’s easier to type.
Any dependency on frequency is measurable, but should not be considered to be perceivable – and is certainly not worth laying awake at night, worrying about it. There is a small, easily ignored (about 0.1 m/s) increase in the speed going up to 100 Hz, and then it’s pretty constant from there up.
Sometimes, on a rare occasion, I can muster up enough gumption to admit that I’m wrong. This posting is just such an admission…
Once-upon-a-time, I learned about equal loudness contours (I will explain these below…). Then I learned about weighting filters and how they’re used to make a measurement system as imperfect as we are. (I will also explain this below). The short explanation at the end of that lesson was “A-weighting is for measuring quiet sounds, and C-weighting is for loud sounds.”
This put a hard-and-fast belief in my head that then made me grumpy any time someone published a specification that said something like “maximum sound pressure level: 120 dB SPL (A)”, since 120 dB SPL is NOT a quiet sound – so the idiot that wrote that should have used a C-weighting instead.
However, as Bertrand Russell once said, “It’s healthy now and then to hang a question mark on things you’ve long taken for granted.” It turns out that my almost-religious-indignation regarding “mis-” use of weighting curves might not be so righteous after all.
Equal Loudness Contours
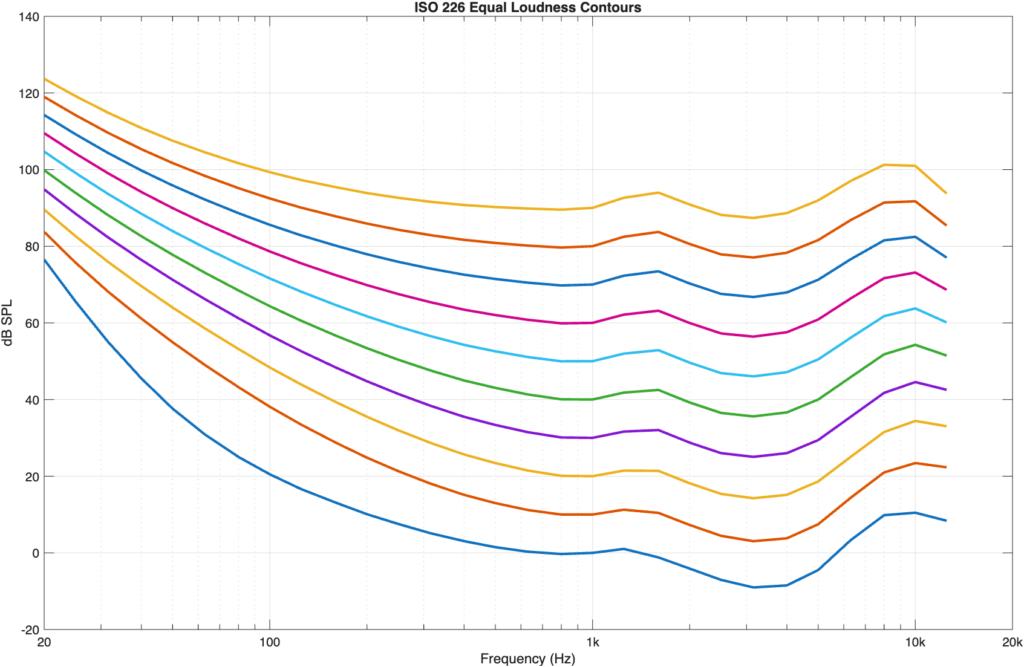
Once-upon-a-time, some research (Fletcher and Munson) figured out that humans do not have a flat frequency response. We are, generally speaking, more sensitive to midrange information than lower- and higher-frequency bands. If you a play a tone for a test subject at a given sound pressure level at 1 kHz, then change to a different frequency and ask the subject to adjust the level of the second frequency so that it sounds the same level as the 1 kHz tone, you get some offset gain value. If you do that again and again for a lot of frequencies and a lot of people and average the results, you get curves that show contours of equal loudness – the sound pressure levels of different frequencies that sound the same level to us.
Fig 01: ISO 226 standard versions of Equal Loudness Contours
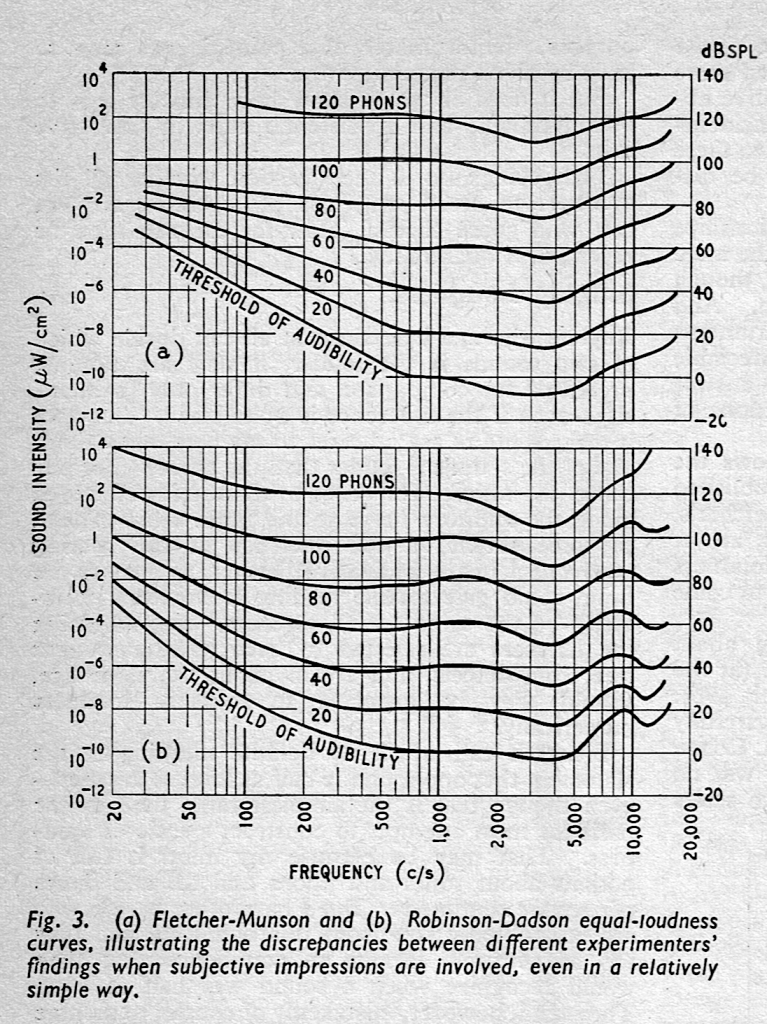
Figure 1, above shows the ISO 226 version of these equal loudness contours which are more like the ones found by Robinson and Dadson and not Fletcher and Munson, as can be seen in the comparison of the two data sets, below.
The curves are typically labelled using the SPL value where they cross 1 kHz. For example, the curve that hits 50 dB SPL at 1 kHz is called the “50-phon” curve; a sinusoidal tone at a given frequency on that line will have a perceived loudness of 50 phons, which will be 50 dB SPL at only 3 frequencies, one of which is 1 kHz.
Figure 2, from Wireless World magazine, March 1962
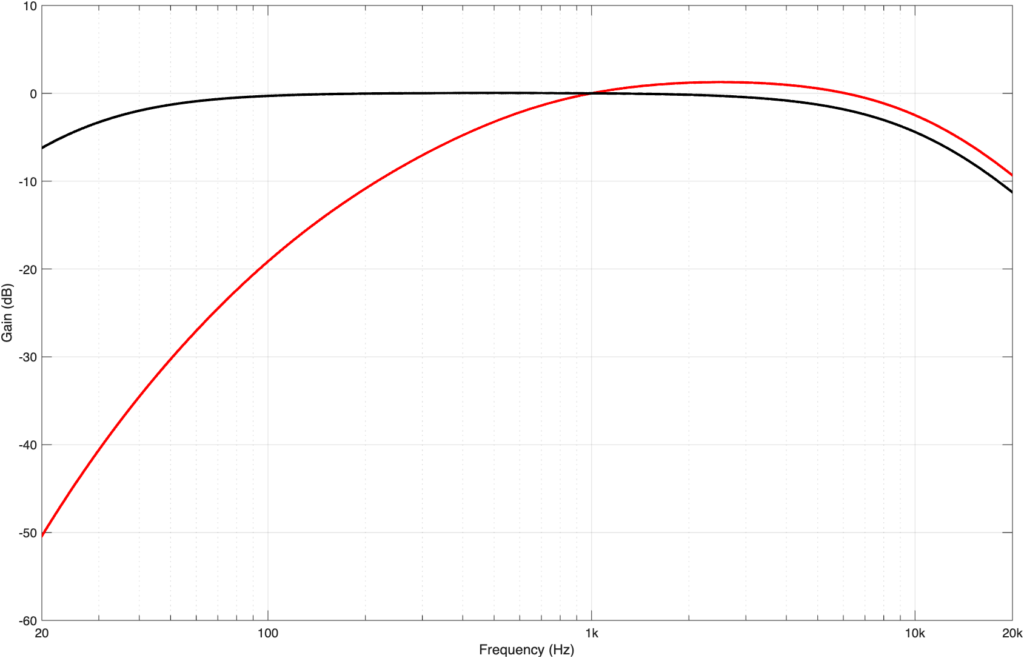
As I mentioned above, the A- and C-weighting filters (as well as other variants) were designed to simulate this lack-of-linearity to make measurements (like noise levels, for example) more aligned with human perception. For example, as can be seen above, we are bad at hearing low frequencies at low levels. So, if you are tasked with measuring the background noise caused by an air conditioning system in an office space, you’ll bring a microphone that can detect the noise better than we can, which results in you getting a high SPL value for something that we can’t hear. Therefore, we apply a roll-off to the microphone’s output before capturing a measurement value. This is the purpose of an A-weighting filter, the response of which is shown in Figure 3, below.
Figure 3: The red curve is the response of an A-weighting filter. The black curve is for C-weighting.
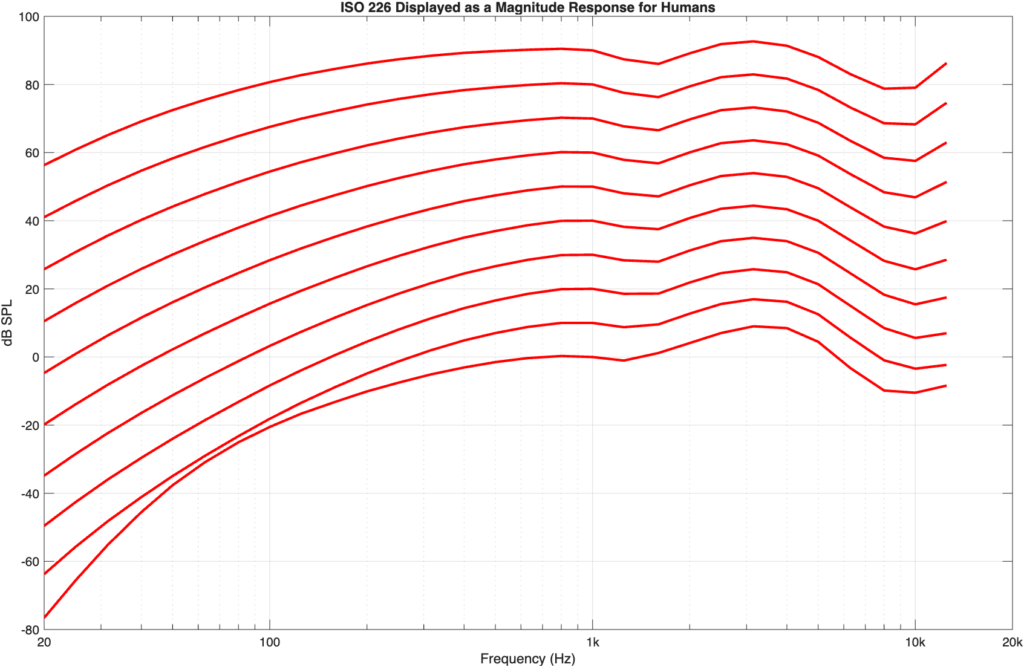
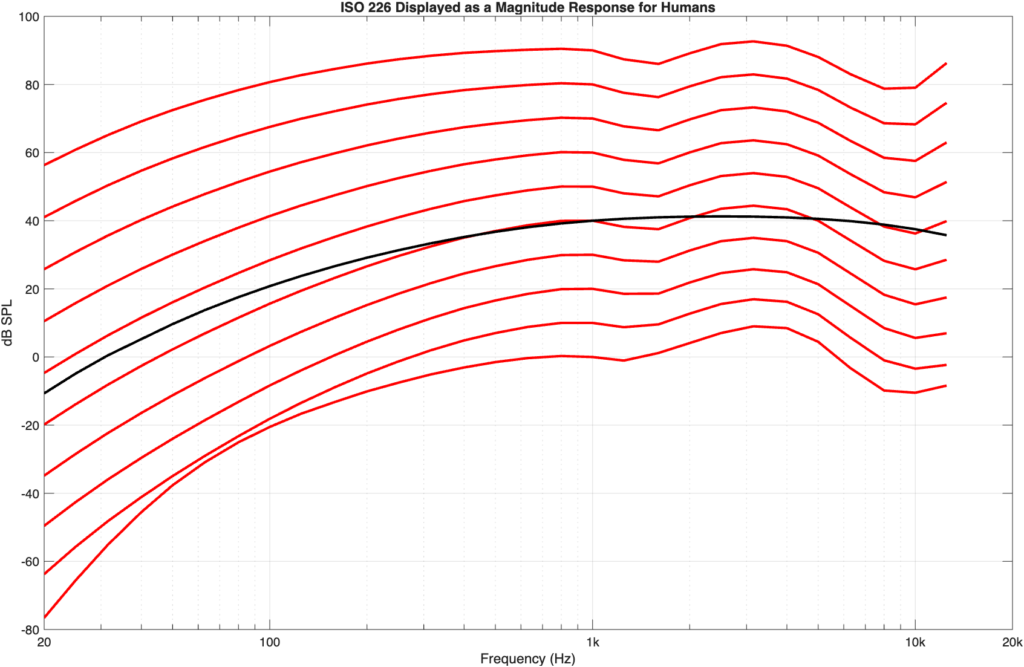
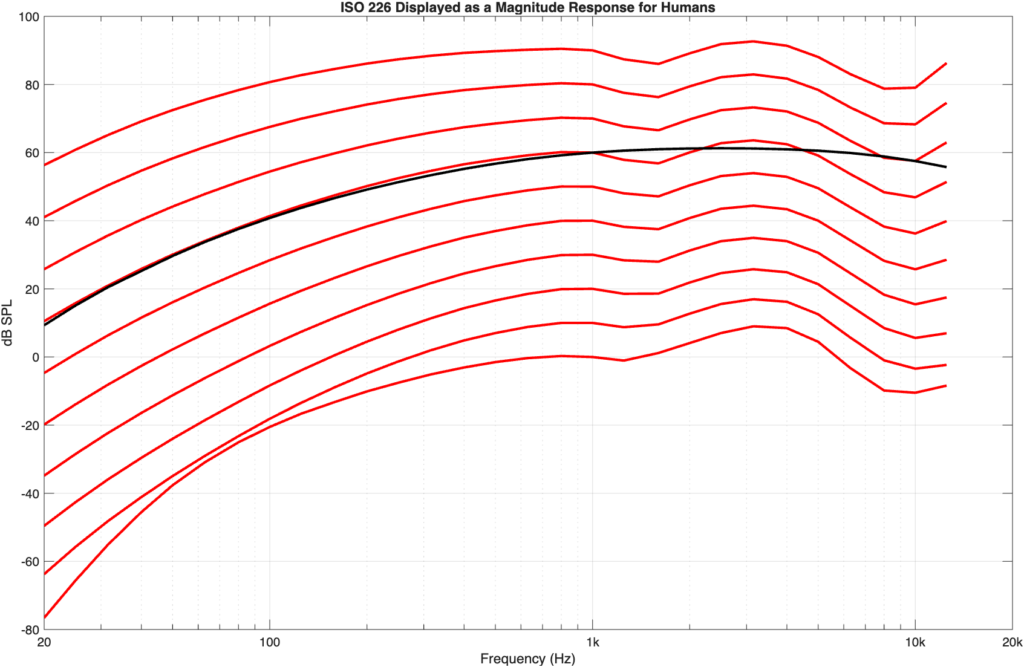
If we flip the equal loudness contours upside-down so that they show our hearing sensitivity as a magnitude response, then they’d look like the curves in Figure 4.
Figure 4: the ISO 226 equal loudness contours shown upside-down so that they appear as magnitude response plot (with offsets) instead.
The A-weighting was based on the 40-phon Fletcher–Munson curves, which represented an early determination of the equal-loudness contour for human hearing.
Subsequent research has demonstrated that A-weighting is in closer agreement with the updated 60-phon contour incorporated into ISO 226:2003 than with the 40-phon Fletcher-Munson contour, which challenges the common misapprehension that A-weighting represents loudness only for quiet sounds.
Let’s then test this by plotting the A-weighting response on top of the equal loudness contours.
Figure 5: The A-weighting curve (in black) plotted to align with the 40-phon curve (the curve that crosses 1 kHz at 40 dB SPL)
Figure 6: The A-weighting curve (in black) plotted to align with the 60-phon curve (the curve that crosses 1 kHz at 60 dB SPL)
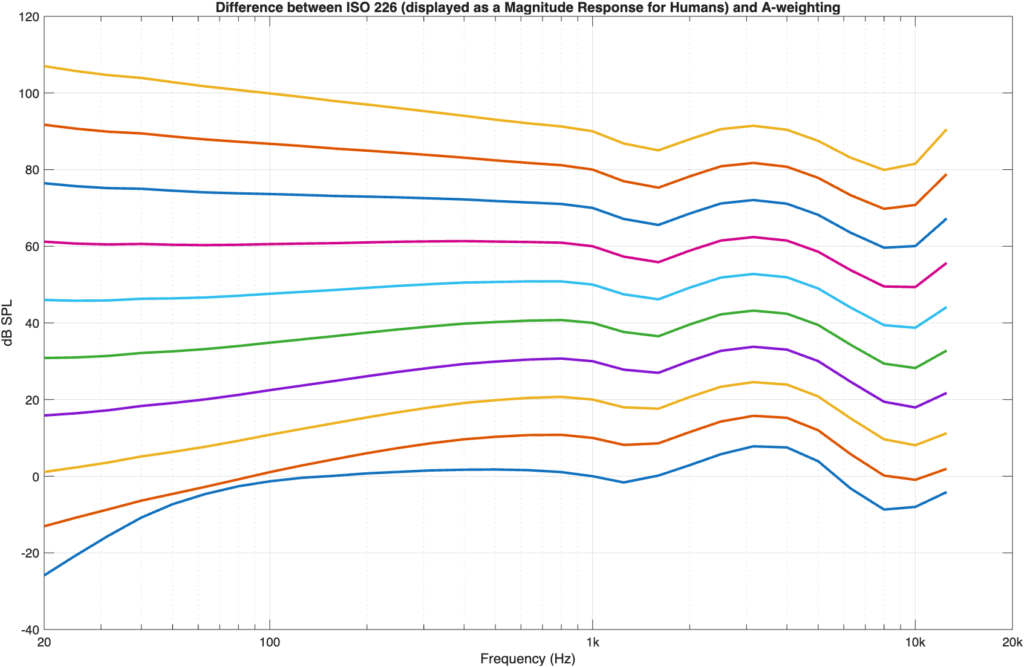
As you can see in Figure 5 and 6, the A-weighting curve better matches the 60-phon curve than the 40-phon curve. If I do this more generally, by looking at the difference between the A-weighting curve and each of the equal loudness contours (viewed as a magnitude response) then the result is as shown in Figure 7.
Figure 7: The difference between ISO 226 and A-weighting
As you can see there, the flattest curve is the one for 60-phon; the one that crosses 1 kHz at 60 dB SPL, so that statement from Wikipedia is correct.
Of course, 60 dB SPL is not THAT loud – and it’s certainly not the same as 120 dB SPL… but it seems that my high horse might not be worth staying on, and maybe using A-weighting as a general approximation, regardless of the level might NOT be as terrible a sin as I believed for so many years…
Once-upon-a-time, I taught a course in electroacoustic measurements at McGill. I used to devote an entire 3-hour class to explaining decibels, partly because we use them so often in audio, partly because I had such difficulty wrapping my own head around them when I was starting off, and partly because the reason I and many other people have that problem is largely due to the laziness of others.
Yesterday, I found myself being annoyed once again by this laziness as I edited a scan of a document from 1961 to correct it before posting it online…
Some background information:
We humans generally respond to things logarithmically. Without getting into the math, this means that our reptile brains like multiplication more than addition.
For example: if I have $10 in the bank, and you have $100 – and we both win $10 in a lottery, I’ll be happier than you. We both won the same amount of money, but I won 100% of my current balance, whereas you only won 10% of your current balance.
Another example is a piano keyboard. Each octave looks the same distance on the keyboard, but the fundamental frequency of those notes are doubling each time you go up one octave. So, a piano keyboard (and music notation) are frequencies displayed on a logarithmic scale.
This is also true of detecting how loud things are: we think “twice as loud” or “half as loud” when talking about the Sound Pressure Level (SPL) that we hear.
We use percent and octaves to do two things:
The first is to convert the values we’re talking about into multiplications instead of additions.
The second is to compare a value (like our lottery winning) to another value (like the bank account balance). (It wouldn’t make sense if I said “I bought a lottery ticket and I won 100%!” 100 percent of what?)
When it comes to comparing levels of things like Sound Pressure Level, electrical power, voltages, or radio signal power, we use decibels (or dB) to make the scale logarithmic.
So, you’ll see someone write something like “the sound of a jet engine at takeoff is 120 decibels”, which is when my pet peeve rears its ugly head. The problem is that this sentence is incomplete.
If you do the math, then you find out that “120 decibels” is the same as saying “1,000,000 times” (because 10^(120/20) = 1,000,000)*, which means that the following two sentence fragments say exactly the same thing:
“the sound of a jet engine at takeoff is 120 dB”
“the sound of a jet engine at takeoff is 1,000,000 times louder than”
“louder than” what? THIS is the problem. The sentence should have said
“the sound of a jet engine at takeoff is 120 dB SPL” which means “the sound of a jet engine at takeoff is 1,000,000 times louder than the quietest level that an average person can hear when the audio signal is a 1 kHz sinusoidal tone.”
Without the “SPL” after the “dB”, there’s no way to know what you’re talking about, which is why, 40 years ago, I couldn’t understand what a “decibel” was – and why, 10 years later, my students had such trouble as well.
Without the “SPL”, it would be like if speed limits said that you should drive “50 km/”. Per second? Per minute? Per hour? Per day? These are very different things…
This also means that if you’re talking about something else, then you need a different letter after the “dB”. For example:
Sound Pressure Level “dB SPL” means “sound pressure level relative to a sound pressure level of 20 µPascals”
Volts “dB V” means “voltage relative to 1 V RMS”
Volts (another version) “dB u” means “voltage relative to 0.775 V RMS”
Watts “dB m” means “voltage relative to 1 mW”
and there are lots more…
In case it’s interesting, a before-and-after of the plot that I edited yesterday is here:
… and if you want to dig into this a little more deeply, then I wrote this explanation for my electroacoustic measurements course 30 years ago
* Five last things:
#1: If you already have the measurement of the thing that you want to express in decibels relative to something else, AND it’s a pressure or voltage measurement, then the math you do is:
x dB = 20 * log10(Pressure1 / Pressure2)
For example, if Pressure1 = 2.5 pascals and Pressure2 = 1.25 pascals, then
20 * log10(2.5/1.25) = 6.02 dB
So you can say that 2.5 pascals is 6.02 decibels higher than 1.25 pascals.
If, instead, Pressure2 is the standard reference of 20 µPa, then:
20 * log10(2.5/0.00002) = 101.9
So, you can say that 2.5 pascals is 101.9 dB SPL.
#2: If you want to do it backwards for pressure or voltage then the math you do is:
Pressure2 * 10^(dB/20) = Pressure1
If you have the dB SPL value and you want to find out how many pascals you’re talking about, then Pressure2 = 0.00002
For example, if you know that the measurement is 101.9 dB SPL, then:
0.00002 * 10^(101.9 / 20) = 2.489 pascals
#3: Some examples:
20 * log10(4/2) = 6.02 dB “+6 dB” is about the same as saying “times 2”
20 * log10(5/10) = -6.02 dB “-6 dB” is about the same as saying “times one half”
20 * log10(100/10) = 20 dB “+20 dB” is exactly the same as saying “times 10”
20 * log10(20/200) = -20 dB “-20 dB” is exactly the same as saying “times 0.1”
#4: If you’re measuring power (in electrical watts or acoustic watts), then the math is slightly different.
#5: If you also see a letter in parentheses at the end such as dB SPL (A) or dB SPL (C), then this means something that you cannot ignore, but that I will not explain here…
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video explains why loudspeaker drivers are typically put in enclosures (boxes), the three types of enclosures that we use (sealed, ported, and passive radiators), and the differences in impact that these enclosure types have on the loudspeaker’s behaviour.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video explains the various components inside a typical loudspeaker driver.
It’s been a long time (about 11 years or so…) since I wrote Part 1 in this “series”, so it’s about time that I came out with a Part 2. This one is about the ‘Maximum Sound Pressure Level (SPL)’ and the ‘Bass Capability’ values that are shown for each loudspeaker model on the Bang & Olufsen website.
Before I explain either of those numbers, we need to discuss the fact that B&O loudspeakers are fully-active. This means that all the signal processing, including simple things like the volume control and more complicated things like filtering and crossovers for the loudspeaker drivers happen in a digital signal processing (DSP) chain before the amplifiers, which are individually connected to the loudspeaker drivers. (In other words, if you see a woofer and a tweeter, then there are two amplifiers inside the loudspeaker, one for each.)
That DSP chain includes even more complicated features that help to protect the loudspeaker from abuse. This means that, even if you’re playing a signal that’s been mastered at a high level, and you’ve cranked up the volume control, the processor prevents things like:
letting the loudspeaker drivers exceed their maximum excursions
letting the amplifiers go beyond their voltage or current capabilities
letting the power supply try to deliver more current than it can to the entire system
letting the loudspeaker’s internal components get so hot that things start to melt.
(None of this means that it’s impossible to break the loudspeaker. It just means that you’d have to try a lot harder than you would with a lot of other companies’ loudspeakers.)
One important side-effect of all of those protection algorithms is that, when you play a loud signal at maximum volume, the loudspeaker will be constantly trying to protect itself. Therefore its maximum output level will vary over time, depending on the signal you’re playing and things like the temperatures of its various individual components.
This, in turn, makes it difficult to state what the “Maximum Sound Pressure Level” will be, since it will change over time with different conditions.
On the other hand, it’s necessary to give a number that states the maximum Sound Pressure Level of each loudspeaker for lots of reasons. It’s also necessary that we use the same procedure to do the measurement so that the values can be compared from loudspeaker to loudspeaker.
The method
So, how do we balance these two things? The answer is to make the measurement short enough that we show the maximum output of the loudspeakers when it’s hitting its limits without being affected by a build-up of heat. This can give you an idea of how loud a short-term signal (like the punch of a kick drum or a snare drum hit) can play: the Maximum SPL. Whatever that number is, the loudspeaker definitely can’t play louder than it (since the amplifier can’t deliver more current and the loudspeaker drivers can’t move in and out any further) but that doesn’t necessarily mean it can play at that level continuously.
The way we measure both the Maximum SPL and the Bass Capability is by placing a microphone 1 m in front of the loudspeaker, and then putting in a short ‘burst’ of 5 periods of a sinusoidal tone at a given frequency. The sound pressure level of the output is measured at the microphone’s position, we wait long enough for everything to cool down, the level of the incoming signal is increased, and then we do the measurement again. This is repeated until the output signal’s level is being automatically reduced by the loudspeaker’s protection algorithms by a pre-determined amount (-6 dB).
If we were a company that made passive loudspeakers, a normal way to do this would be to increase the level until we reached a pre-determined level of total harmonic distortion (say, 10% or 20% THD, for example). However, this won’t work for a B&O loudspeaker because the protection algorithms probably won’t allow the product to distort enough to have a usable threshold.
What’s the difference?
Generally, the method of measuring both the Maximum SPL and the Bass Capability values are the same. The only difference is the range of frequencies that are used for each.
The Bass Capability shows the maximum SPL of the loudspeaker when the input signal is a 50 Hz sinusoidal wave.*
The Maximum Sound Pressure Level is an average of the maximum SPL of the loudspeaker when it is measured using a number of sinusoidal signals ranging from 200 Hz to 2 kHz. Each frequency is measured individually, and the resulting maxima are averaged to produce a single value. (If you’re read Part 1, then the frequency range of this measurement will look familiar.)
How does this correspond to real life?
This is a difficult question to answer, since the measurement is done on-axis to (or ‘directly in front of’) the loudspeaker in the measurement room. This measurement room is different from a ‘normal’ living room, where more of the total power of the loudspeaker that’s radiated in all three dimensions is reflected back to the listening position. This is the reason why some companies list the maximum output level of their loudspeakers with two numbers: one in a ‘free field’ (a room or ‘field’ that is ‘free’ of reflections) and the other in a ‘listening room’ (which may or may not be like your listening room). You’ll probably see that the ‘listening room’ SPL is higher than the ‘free field’ SPL because the room is reflecting more energy back to the measurement microphone, if nothing else…
In other words ‘results may vary’. So, the maximum SPL of a loudspeaker in your living room may not be the same as the Maximum SPL that B&O lists on its website. Time frames are different, signals are different, and rooms are different: and all of these have significant effects on the result.
What happens when I have more than one loudspeaker?
Generally speaking, if your loudspeakers are reasonably far apart, then you can use a simple rule to calculate the maximum SPL if you add more loudspeakers.
+ 3 dB per doubling
In other words, if you have a loudspeaker that can hit 100 dB SPL, and you add a second loudspeaker, then you’ll hit 103 dB SPL. If you then add two more loudspeaker (another doubling of the total number) you’ll hit 106 dB SPL.
This rule is based on a number of assumptions:
the loudspeakers are all the same type
the loudspeakers are in the same room, but fairly far apart
the loudspeakers are all playing their maximum output levels at the same time
I’m ignoring room modes, which might make things louder or quieter, depending on the frequency that you’re playing, the placements of the loudspeakers, and the location of the listening position
we’re ignoring other protection algorithms like thermal protection
The reason that this rule is a basic one: we’re assuming that every time you double the number of speakers, you double the total power at the listening position (which is a reasonable assumption if the list of assumptions above are true). Two times the acoustic power is the same as an increase of +3 dB SPL (because 10 log10(2) = 3).
If, however, the frequency was very low, and the loudspeakers were very close together, and they were playing exactly the same signals at exactly the same time, you might make the argument that you can say that there is a +6 dB increase for every doubling of loudspeakers, because it’s their amplitudes (and not their acoustic powers) that are added.
Neither of these two basic assumptions is correct, and so the real number is probably between +3 and +6 dB per doubling of loudspeakers, and it will be different for different frequency bands and different loudspeaker separations. However, it’s best to err on the safe side.
One last thing
This should help to explain why, when you compare the Bass Capabilities and the Maximum Sound Pressure Levels of different loudspeakers, the former has much bigger differences than the latter.
For example:
Beosound Explore
< difference >
Beolab 50
Max SPL @ 1 m
91 dB SPL
26 dB
117 dB SPL
Bass capability
59 dB SPL
52 dB
111 dB SPL
The table above shows a direct comparison of two VERY different loudspeaker models using data taken directly from bang-olufsen.com on 2025 04 01. I’ve converted the numbers for the Beolab 50 to a ‘per loudspeaker’ instead of ‘per pair’ by subtracting 3 dB from the published numbers.
As you can see there:
the difference in Bass Capability between a Beosound Explore and a Beolab 50 is (111-59) = 52 dB
the difference in Max SPL between a Beosound Explore and a Beolab 50 is (117-91) = 26 dB
Speaking VERY generally, the difference in Max SPL values is less than the difference in Bass Capabilities because the difference in size and power of the drivers producing the midrange frequency band of the two loudspeakers is smaller than the difference in size and power of the woofers. In other words, there is a difference between the different differences. (I think that I got that right…)
* To get the Bass Capability measurement, it looks like I said that we do the measurement of a single 50 Hz sinusoidal tone. This isn’t really true. We do a number of measurements at different frequencies ranging from 20 Hz to 100 Hz and then calculate the equivalent value for a 50 Hz tone using some averaging.
If the loudspeaker is comprised of a single low-frequency driver in a closed cabinet, then the resulting number would be the same as if we just measured using a 50 Hz tone. However, if the loudspeaker is ported or has a passive driver with a resonant frequency in the 20 – 100 Hz range, then this method will probably produce a slightly different number than measuring only with a 50 Hz tone.
In Part 2, I showed the raw magnitude response results of three pairs of headphones measured on three different systems, each done 5 times. However, when you plot magnitude responses on a scale with 80 dB like I did there, it’s difficult to see what’s going on.
Differences in measurements relative to average
One way to get around this issue is to ignore the raw measurement and look at the differences between them, which is what we’ll do here. This allows us to “zoom in” on the variations in the measurements, at the cost of knowing what the general overall responses are.
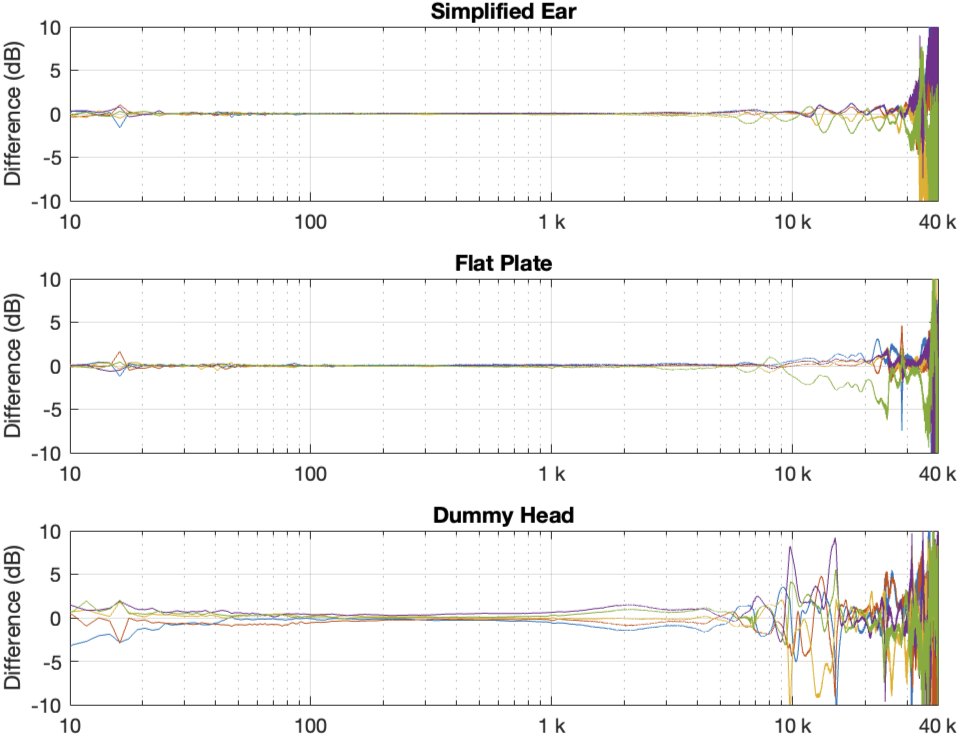
Figure 1 in Part 2 showed the 5 x 3 sets of raw magnitude responses of the open headphones. I then take each set of 5 measurements (remember that these 5 measurements were done by removing the headphones and re-setting them each time on the measurement rig) and find their average response. Then I plot the difference between each of the 5 measurements and that average, and this is done for each of the three measurement systems, as shown below in Figure 1.
Figure 1: Open headphones: The difference between each of the 5 measurements done on each system and the mean (average) of those 5 measurements.
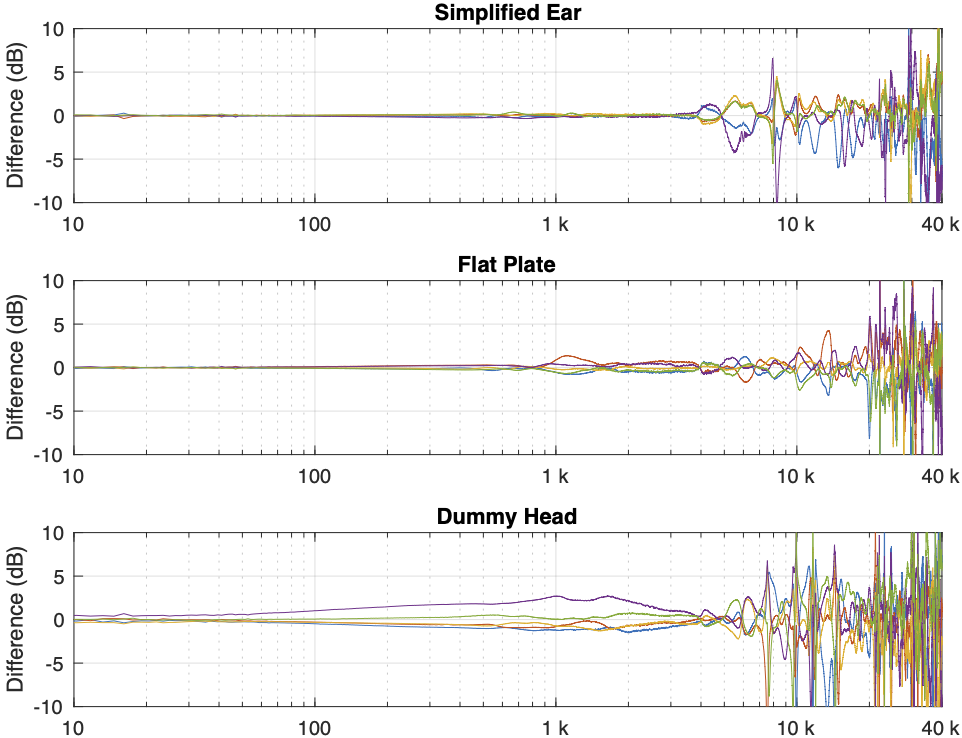
Figure 2: Semi-open headphones: The difference between each of the 5 measurements done on each system and the mean (average) of those 5 measurements.
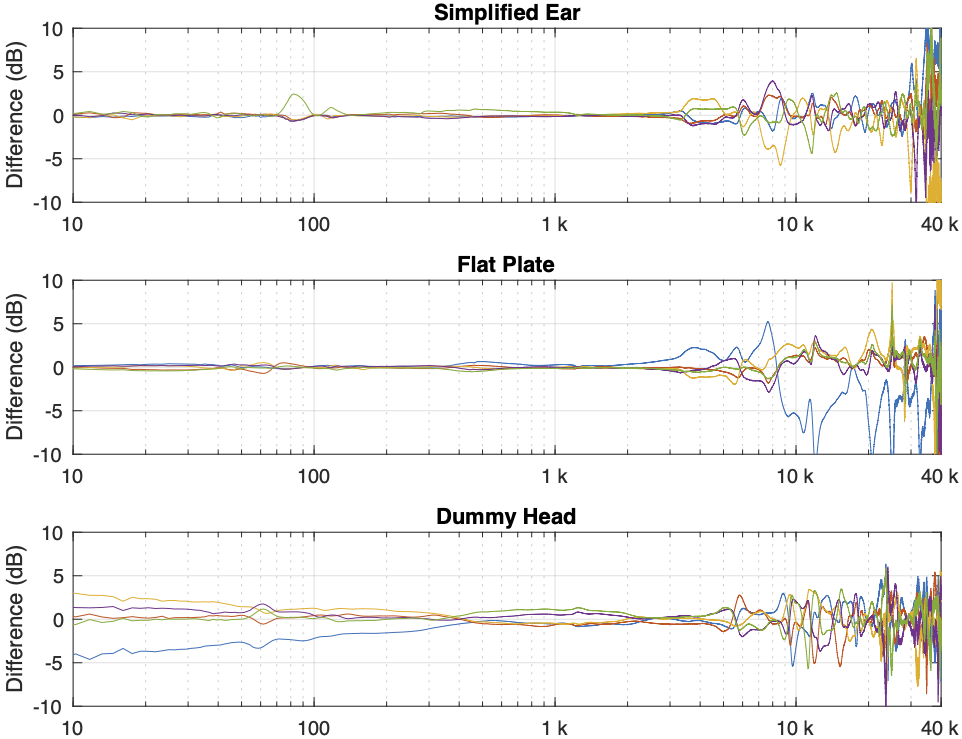
Figure 3: Closed headphones: The difference between each of the 5 measurements done on each system and the mean (average) of those 5 measurements.
Some of the things that were intuitively visible in the plots in Part 2 are now obvious:
There is a huge change in the measured magnitude response in the high frequency bands, even when the pair of headphones and the measurement rig are the same. This is the result of small changes in the physical position of the headphones on the rig, as well as changes in the clamping force (modified by moving the headband extension). I intentionally made both of these “errors” to show the problem. Notice that the differences here are greater than ±10 dB, which is a LOT.
Overall, the differences between the measurements on the dummy head are bigger and have a lower frequency range than for the other two systems. This is mostly due to two things:
because the dummy head has pinnae (ears), very small changes in position result in big changes in response
it is easier to have small leaks around the ear cushions on a dummy head than with a flat surrounding of a metal plate or an artificial ear. This is the reason for the low-frequency differences with the closed headphones. Leaks have no effect on open headphone designs, since they are always leaking out through the diaphragm itself.
The differences that you can see here are the reason that, when we’re measuring headphones, we never measure just once. We always do a minimum of 5 measurements and look at the average of the set. This is standard practice, both for headphone developers and experienced reviewers like this one, for example.
In addition to this averaging, it’s also smart to do some kind of smoothing (which I have not done here…) to avoid being distracted by sharp changes in the response. Sharp peaks and dips can be a problem, particularly when you look at the phase response, the group delay, or looking for ringing in the time domain. However, it’s important to remember that the peaks and dips that you see in the measurements above might not actually be there when you put the headphones on your head. For example, if the variations are caused by standing waves inside the headphones due to the fact that the measurement system itself is made of reflective plastic or metal (but remember that you aren’t…) then the measurement is correct, but it doesn’t reflect (ha ha…) reality…
One additional thing to remember with these plots is that something that looks like a peak in the curve MIGHT be a peak, but it might also be a dip in the average curve because we’re only looking at the differences in the responses.
System differences
Instead of looking at the differences between each individual measurement and the average of the measurement set, we can also look at the differences between what each measurement system is telling us for each headphone type. For example, if I take one measurement of a pair of headphones on each system, and pretend that one of them is “correct”, then I can find the difference between the measurements from the other two systems and that “reference”.
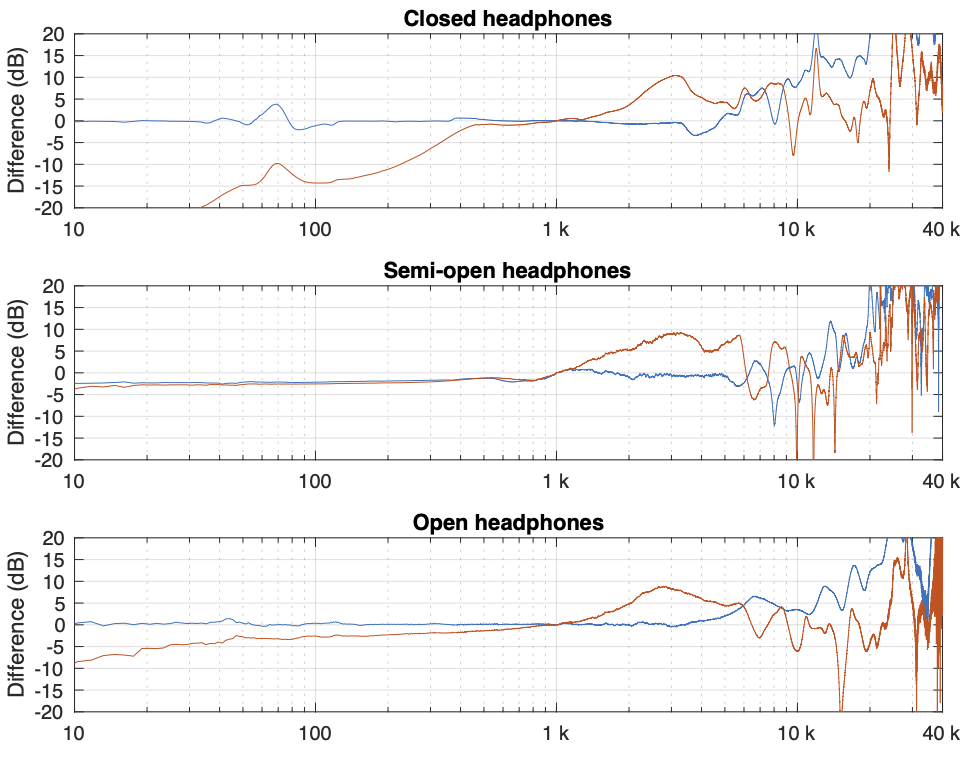
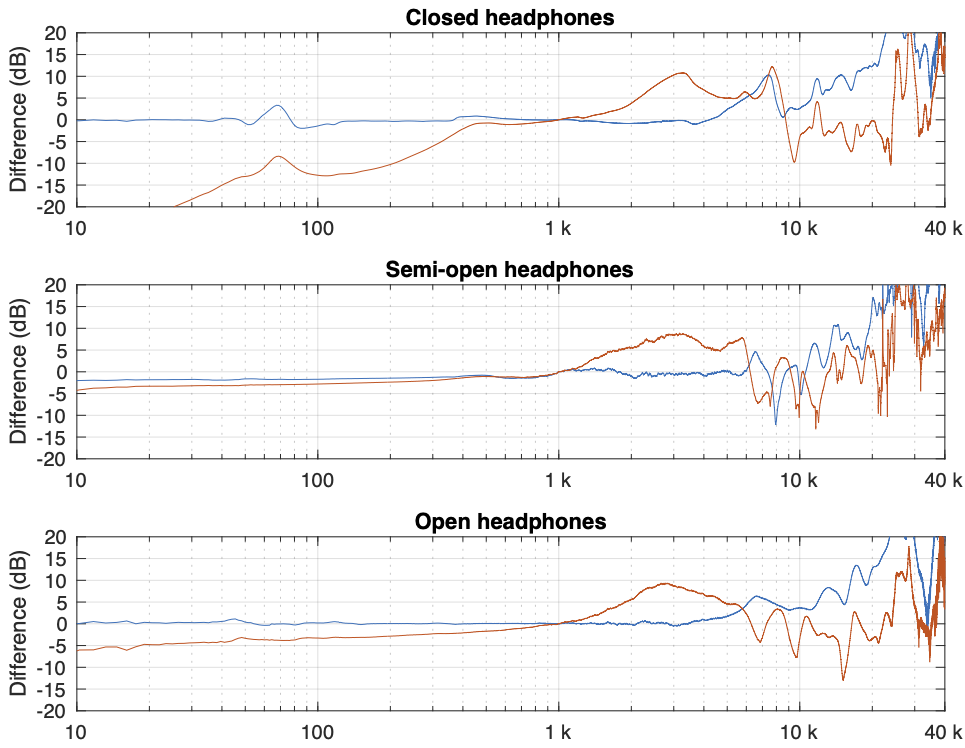
Figure 4. One measurement for each pair of headphones on each measurement system. The red curves are the dummy head and the blue curves are the artificial ear RELATIVE TO THE FLAT PLATE.
In Figure 4, I’m pretending that the flat plate is the “correct” system, and then I’m plotting the difference between the dummy head measurement (in red) and the artificial ear measurement (in blue) relative to it.
Again, it’s important to remember with these plots is that something that looks like a peak in the curve might actually be a dip in the “reference” curve. (The bump in the red lines around 2 – 3 kHz is an example of this…)
Of course, you could say “but you just said that we shouldn’t look at a single measurement”… which is correct. If we use the averages of all 5 measurements for each set and do the same plot, the result is Figure 5.
Figure 5. The average of all 5 measurements for each pair of headphones on each measurement system. The red curves are the dummy head and the blue curves are the artificial ear relative to the flat plate.
You can see there that, by using the averaged responses instead of individual measurements, the really sharp peaks and dips disappear, since they smooth each other out.
Comparing headphone types
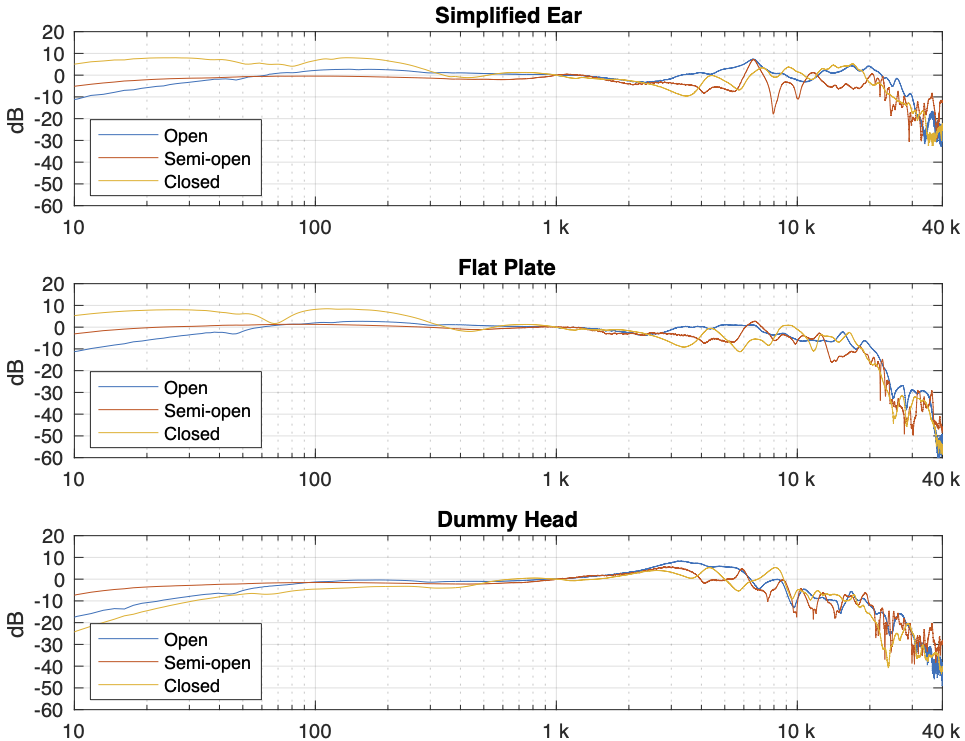
Things get even more complicated if you try to compare the headphones to each other using the measurement systems. Figure 6, below, shows the averages of the five measurements of each pair of headphones on each measurement system, plotted together on the same graphs (normalised to the levels at 1 kHz), one for each measurement system.
Figure 6: Comparing the three pairs of headphones on each measurement system.
This is actually a really important figure, since it shows that the same headphones measured the same way on different systems tell you very different things. For example, if you use the “simplified ear” or the “flat plate” system, you’ll believe that the closed headphones (the yellow line) is about 10 – 15 dB higher than the open headphones (the blue line) in the low frequency region. However, if you use the “dummy head” system, you’ll believe that the closed headphones (the yellow line) is about 5 – 10 dB lower than the open headphones (the blue line) in the low frequency region.
Which one is correct? They all are, even though they tell you different things. After all, it’s just data… The reason this happens is that one measurement system cannot be used to directly compare two different types of headphones because their acoustic impedances are different. With experience, you can learn to interpret the data you’re shown to get some idea of what’s going on. However, “experience” in that sentence means “years of correlating how the headphones sound with how the plots look with the measurement system(s) you use”. If you aren’t familiar with the measurement system and how it filters the measurement, then you won’t be able to interpret the data you get from it.
That said, you MIGHT be able to use one system to compare two different pairs of open headphones or two different pairs of closed headphones, but you can’t directly compare measurements of different headphone types (e.g. open and closed) reliably.
This also means that, if you subscribe to two different headphone magazines both of which use measurements as part of their reviews, and one of them uses a flat plate system while the other uses a dummy head, the same pairs of headphones might get opposite reviews in the two magazines…
Which review can you trust? Both of them – and neither of them.
Conclusions
Looking at these plots, you could come to the conclusion that you can’t trust anything, because no two measurements tell you the same things about the same devices. This is the incorrect conclusion to draw. These measurement systems are tools that we use to tell us something about the headphones on which we’re working. And people who use these tools daily know how to interpret the data they see from them. If something looks weird, they either expected it to look weird, or they run the measurement on another system to get a different view.
The danger comes when you make one measurement on one device and hold that up as The Truth. A result that you get from any one of these systems is not The Truth, but it is A Truth – you just need more information. If you’re only shown one measurement (or even an average of measurements) that was done on only one measurement system, then you should raise at least one eyebrow, and ask some questions about how that choice of system affects the plots that you see.
In many ways, it’s like looking at a recipe in a cookbook. You might be able to determine whether you might like or probably hate a dish by reading its description of ingredients and how to prepare it. But you cannot know how it’ll taste until you make it and put it in your mouth. And, if you cook like I do, it’ll be just a little different next time. It’s cooking – not a chemistry experiment. If you use headphones like I do, it’ll also be a little different next time because some days, I don’t wear my glasses, or I position the head band a little differently, so the leak around the ear cushion or the clamping force is a little different.