Everything that you read on this website was written by me without the help of AI. I promise.
I, for one, am sick and tired of the word salads that are getting put on websites by people who feed some keywords in a large language model, and then copy-and-paste the results without any kind of critical thinking, or even a modicum of copy editing. (Even worse are the automatically-generated webpages that are created from the keywords in your search, where the only human in the process is you.) The result is usually something that looks like it should make sense, but winds up being confusing because you’re actually trying to navigate in a sea of errors.
I’ve also debated for a long time whether to try to block LLMs from scraping this site to feed their salad bowls. For now, I’ve decided that I will give it a try, using the Block AI Crawlers plugin for WordPress.
Before there was magnetic tape, there were magnetic wire recordings using a 0.1 mm steel wire instead of plastic tape with a magnetic coating. However, the basic principle is the same.
I’ve spent the past couple of weeks getting a magnetic wire recording up and running again – at least the playback part… This mechanism came out of a Beocord 506 UK. The 506 means that it was made by Bang & Olufsen in 1951. The U meant that it had a Universal power supply (220 AC or 220 V DC, since the mains power was not yet standardised in Denmark in those days…) and the K stood for Kuffert or portable case. Originally, it looked like this:
The Beocord 506UK incorporated a turntable with a fixed rotation speed of 78 RPM, with a mono output (of course…). The take-up spool of for the magnetic wire recorder doubled as the turntable platter, which makes it easy to ensure that it’s running at the correct speed (there’s an adjustment screw just on the other side of the white plastic plate on the top between the two wheels).
It was possible to record directly from the turntable output or from the microphone input (the connector is on the top left of the front panel). It had a built-in loudspeaker, so it was a stand-alone “portable” device.
My intention was only to get the magnetic player up and running – not to restore the entire device, so I donated all of the extra parts that I didn’t need to keep to a friend of mine who repairs and restores old B&O equipment.
Step 1 was to remove the player from the rest.
This means being a little careful, since that angled casing that you see on the right of the photo below is made of asbestos. Luckily, the nice people at the local dump know how to deal with this, so they were willing to take it off my hands.
Notice as well that, in the 1950s, B&O wound its own transformers.
Back in those days, B&O also made its own custom loudspeaker drivers. This one is still in reasonably good condition, so I kept it with the plan to connect it to a modern amplifier for listening to the magnetic wire recordings.
One problem with these old Beocord players is in the idler wheel that sits between the motor drive shaft and the outside edge of the take-up spool. This is the metal wheel with the white rubber edge in the middle of the photo below. The problem is that, over the past 70 years, this rubber has not only shrunk, but it has hardened, so there’s no friction to drive the spool.
One solution to this is to put the wheel on a lathe, reduce the diameter of the (now hard) rubber, and glue on an elastic band. This works well. I took a different path. I first got a rough measurement of the outside diameter of the wheel as a starting point.
I then cut, filed, and sanded off all of the old rubber. I 3D printed a new edge ring which is glued to the metal wheel. I then cut a strip out of a bicycle inner tube and glued that to the edge. I used Loctite Extreme for both, since it works on metal, plastic, and rubber, and remains flexible after curing. The truth is that this took 4 different attempts to get things working correctly. The last version needed only a 0.5 mm reduction in the diameter to get it behaving.
The “new” idler wheel can be seen in the photo below, back on its axle. It sits on a triangular plate that is able to move a millimeter or two.
When playing a wire, the spring on the bottom-middle of the photo pulls the idler wheel against the edge of the take-up spool (the large circle on the left) and the axle of the motor (which has been removed in this photo).
When rewinding, the L-shaped arm is pulled to the right by an electromagnet, which pulls the triangular plate slightly upwards and to the right (in this photo). This reduces the amount of friction on the take-up spool, but still provides enough tension pulling against the rewind motor to keep the magnetic wire from spooling out of control and turning into a bird’s nest.
For reference, this is the photo from the original technical service manual. “Idler wheel” in Danish is “Mellem hjul”.
This is the final result. I’ve connected the output of the playback head to a standard RIAA preamplifier. It doesn’t have exactly the same response as the original, but it’s close enough. The output of the RIAA is connected to the analogue input of a Beoplay A1, which is what you’re listening to.
Notice that there is a mechanical link between the rotation of the take-up spool and the vertical position of the head. This ensures that the wire doesn’t bunch in the middle of either spool when you’re playing or rewinding. Also note that there is no “fast-forward” option. You only have PLAY, STOP, and REWIND. Due to the way I’ve wired up the head, it’s possible to listen to the output as you’re re-winding, however, this would be muted in the original Beocord.
Also note that I’m using an isolation transformer for the mains power – mostly to ensure that I don’t get electrocuted when I touch things, but also as a backup circuit breaker.
While I had things apart, I also used a USB microscope to take a look at the details in the playback head. Some of those photos are shown below.
The photo below shows the right side of the playback head looking down from the top. The wire runs in a groove along the front of the head which is the curve on the bottom of the photo. The coil of wire inside the orange lacquer generates a small electrical current when there is a change in the magnetic field in the gap directly below it.
The photo below shows the same coil, looking from the front a little more. The gap is too small to be seen in this photo, but it’s at the location of the small discontinuity in the nice curve with the groove in it.
The photo below is looking directly into the front of the groove. The blurry silver shape in the upper right is the front of the coil shown above.
As can be seen, it was never my intention to make an entirely new binding, so it maintains the patina of an old book. I just wanted to stabilise the original one and make the book useable and considerably less fragile.
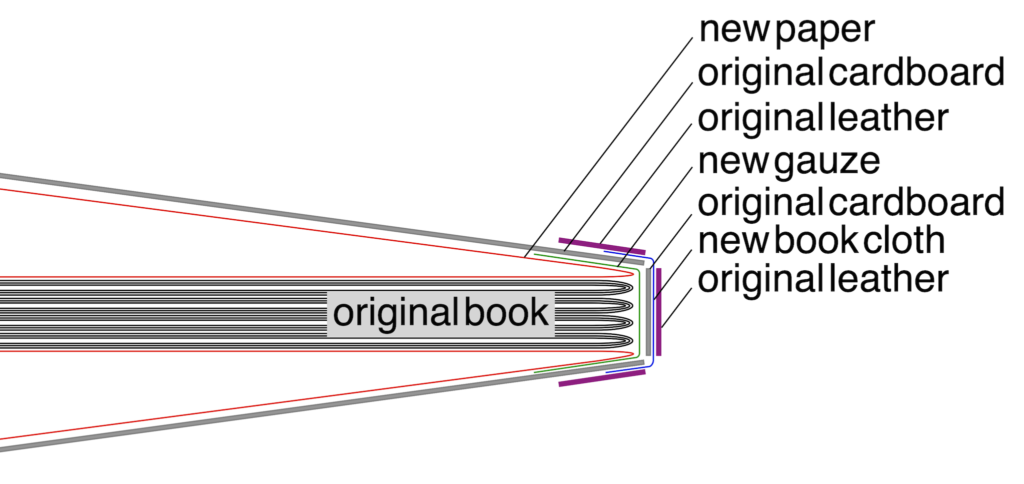
A simplified diagram of the layers in the final book. Not shown in this breakdown are the paper backing and the sewing on the original book, and the location of the glue.
Final assembly begins with gluing the edge of a piece of Japanese paper to the original purple paper. This was done with just a thin line of glue (about 5 mm wide). (In this photo, you see the back of the Japanese paper that will be glued to the inside of the cover.)
Then, the gauze was glued down and then the entire side of the paper that you see there was coated with glue. This is then attached to the inside of the cover. (I realised after it was too late that I take blurry, out-of-focus photos when I’m rushing to get it done before the glue makes the paper wrinkle too much… Sorry.)
The moisture of the glue caused the Japanese paper to wrinkle, as expected. This was smoothed out using a rubber roller, the bone folder, and my fingers.
Then the whole thing was clamped overnight to prevent the covers from curling due to the glue. Notice the fabric spine (with the original cardboard spine glued to its inside) that will be covered with the original leather in the next step.
The leather has been glued to the fabric spine and then the whole thing was wrapped in the elastic bandage. Again, the baking paper keeps things that shouldn’t stick from sticking together.
Then back under the weights for another night, bandages and all.
The first step was to prepare the spine reinforcement with gauze and bookbinding glue. The gauze is about 3x the width of the spine. The extras on the sides will form part of the hinges when they’re finally glued to the inside of the covers.
I made a temporary support out of wood for gluing the curved cardboard to the underside of the cloth that will become the new back. Fat-resistant baking paper is placed between the cardboard and the wood to make sure it doesn’t all stick together. The entire thing is wrapped in an elastic bandage.
The cloth+cardboard spine has been glued to the covers by gluing the cloth under the leather strips. Notice in the middle that the cloth has been folded over the top and bottom of the cardboard (on the left and right of the photo).
The two tabs that are sticking out will be folded and glued to the insides of the covers under the paper. The gauze reinforcement on the book’s spine is also easily visible at the top of the photos.
I made 5 bevelled leather strips and glued them to the inside of the leather backing. Because of the twist in the leather, it looks like they’re not parallel, but they are… I promise…
The four tabs were glues to the insides of the front and back covers.
New, machine-sewn headbands were glued onto the spine and reinforced with a little more gauze.
Step 1 of the dismantling was to cut off the back of the cover. I had my doubts about whether I wanted to slice through that nice leather, but it was the only way to ensure that the new binding would be done properly.
All of the loose paper shreds had to be shaved off the spine. Initially, this was done with a scalpel, and then with 80-grit sandpaper.
Luckily, all of the sewing and the cords are still in place, so I didn’t have to completely disassemble the book and re-sew it.
The card and leather cover of the back came apart fairly easily. Notice that the ribs in the leather were just for decoration, and not cords used in the binding. They’re cardboard strips, 4 mm wide at the base and 2 mm wide at the top. I’ll make new ones to replace these.
All of the bits and pieces so far…
I used a bone folder and the scalpel to separate the leather strip from the card underlay. I only cut down to the line where the marbled paper meets the leather. This way, there was still some old hide glue holding the leather in place. The new binding material will slide in under the leather.
All of the paper was initially scraped, and then sanded off the inside of both covers. A little spray of water helped here, soaking it just enough to be able to rub off a large amount with my fingers (which turned purple as a result…)
Both covers were a little warped, so, while they were still a little damp, I used an iron to heat them up and straighten them out, and then I left them in a press between two pieces of plywood for a couple of days.
I have a bunch of hobbies, and I am particularly pleased when they intersect or overlap.
This weekend’s project started with a visit to a good friend who has a large collection of magazines and books about radio and audio dating back over 100 years. One of the books on his shelf was a bound set of Radio Uge-Revue magazine from 1926, however, after 100 years and much use, the binding has disintegrated. So, I took the book home with an agreement that I would try to repair the book and, in return, he would not criticise my amateurish attempts…
This was the starting point. The leather spine of the book has become completely torn away from the leather strip on one cover. Structurally, the rest of the binding turned out to be in decent shape, so I spent a lot of time debating what to do.
The spine was nicely attached to the other cover, and the internal threads were in decent shape.
Both headbands were in pretty bad shape, as was the paper covering on the spine itself.
So, step one was to start dismantling the binding – but only as much as necessary…
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video illustrates the difference between the two main categories of reflections.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video demonstrates some of the individual components of a room’s acoustical contributions.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video demonstrates one of the more important problems that we face in dealing with a room’s acoustical contribution to “the sound” of a loudspeaker: room modes (or room resonances), as well as some basic introduction to some strategies for compensating for them.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video presents an intuitive explanation of why we typically need bigger loudspeaker drivers to reproduce low frequency bands, and smaller drivers for higher bands.