I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video demonstrates some of the individual components of a room’s acoustical contributions.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video demonstrates one of the more important problems that we face in dealing with a room’s acoustical contribution to “the sound” of a loudspeaker: room modes (or room resonances), as well as some basic introduction to some strategies for compensating for them.
Sometimes, on a rare occasion, I can muster up enough gumption to admit that I’m wrong. This posting is just such an admission…
Once-upon-a-time, I learned about equal loudness contours (I will explain these below…). Then I learned about weighting filters and how they’re used to make a measurement system as imperfect as we are. (I will also explain this below). The short explanation at the end of that lesson was “A-weighting is for measuring quiet sounds, and C-weighting is for loud sounds.”
This put a hard-and-fast belief in my head that then made me grumpy any time someone published a specification that said something like “maximum sound pressure level: 120 dB SPL (A)”, since 120 dB SPL is NOT a quiet sound – so the idiot that wrote that should have used a C-weighting instead.
However, as Bertrand Russell once said, “It’s healthy now and then to hang a question mark on things you’ve long taken for granted.” It turns out that my almost-religious-indignation regarding “mis-” use of weighting curves might not be so righteous after all.
Equal Loudness Contours
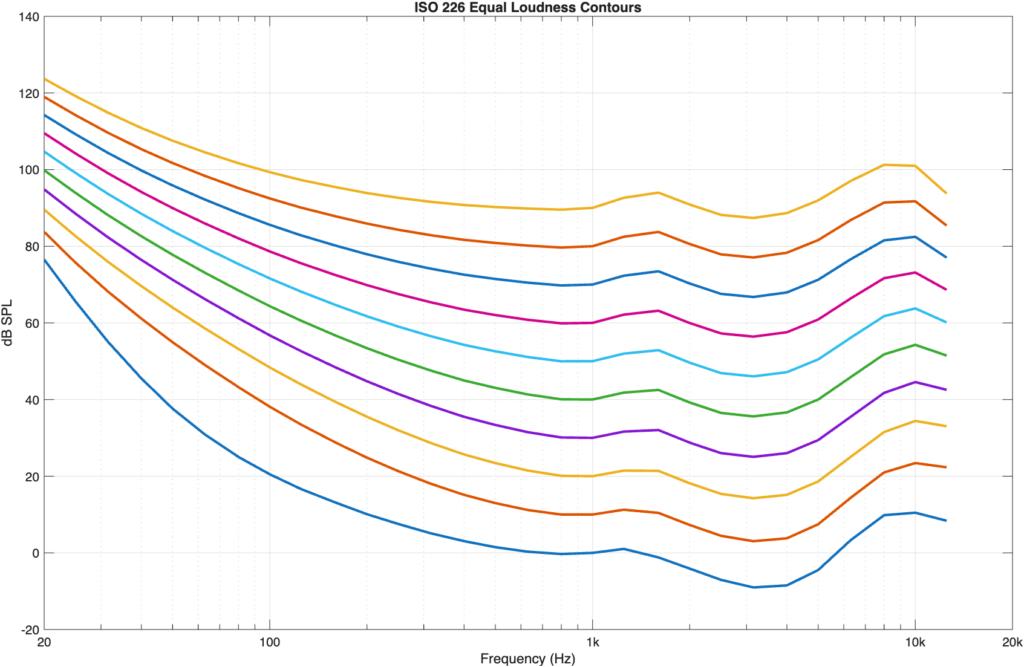
Once-upon-a-time, some research (Fletcher and Munson) figured out that humans do not have a flat frequency response. We are, generally speaking, more sensitive to midrange information than lower- and higher-frequency bands. If you a play a tone for a test subject at a given sound pressure level at 1 kHz, then change to a different frequency and ask the subject to adjust the level of the second frequency so that it sounds the same level as the 1 kHz tone, you get some offset gain value. If you do that again and again for a lot of frequencies and a lot of people and average the results, you get curves that show contours of equal loudness – the sound pressure levels of different frequencies that sound the same level to us.
Fig 01: ISO 226 standard versions of Equal Loudness Contours
Figure 1, above shows the ISO 226 version of these equal loudness contours which are more like the ones found by Robinson and Dadson and not Fletcher and Munson, as can be seen in the comparison of the two data sets, below.
The curves are typically labelled using the SPL value where they cross 1 kHz. For example, the curve that hits 50 dB SPL at 1 kHz is called the “50-phon” curve; a sinusoidal tone at a given frequency on that line will have a perceived loudness of 50 phons, which will be 50 dB SPL at only 3 frequencies, one of which is 1 kHz.
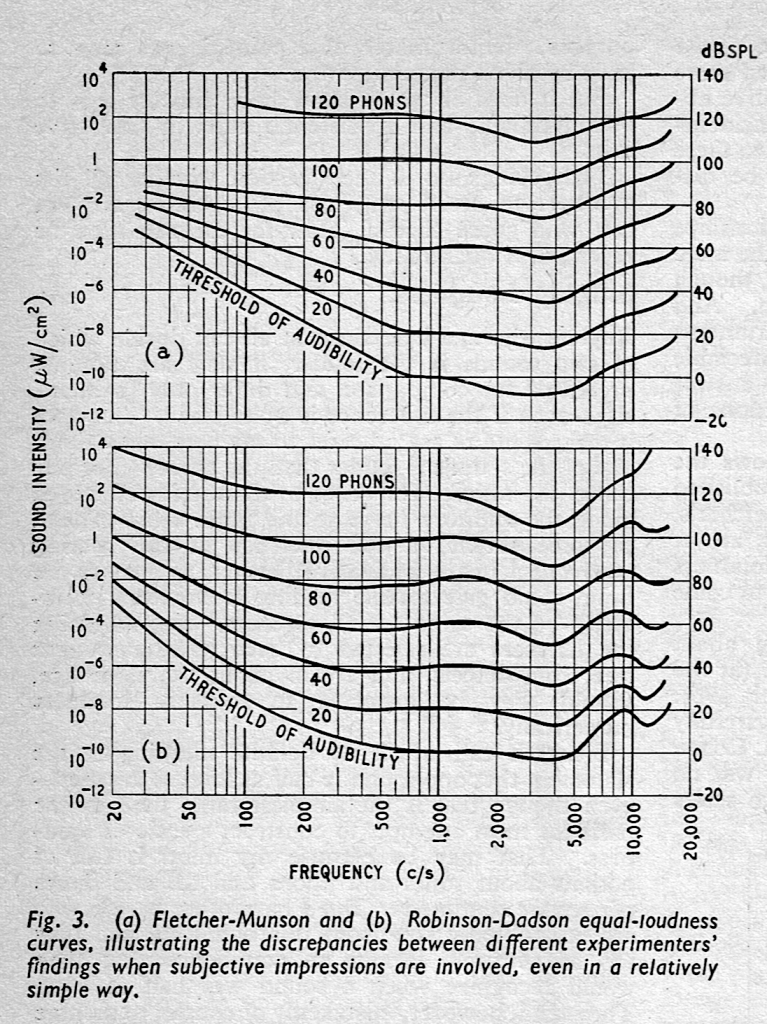
Figure 2, from Wireless World magazine, March 1962
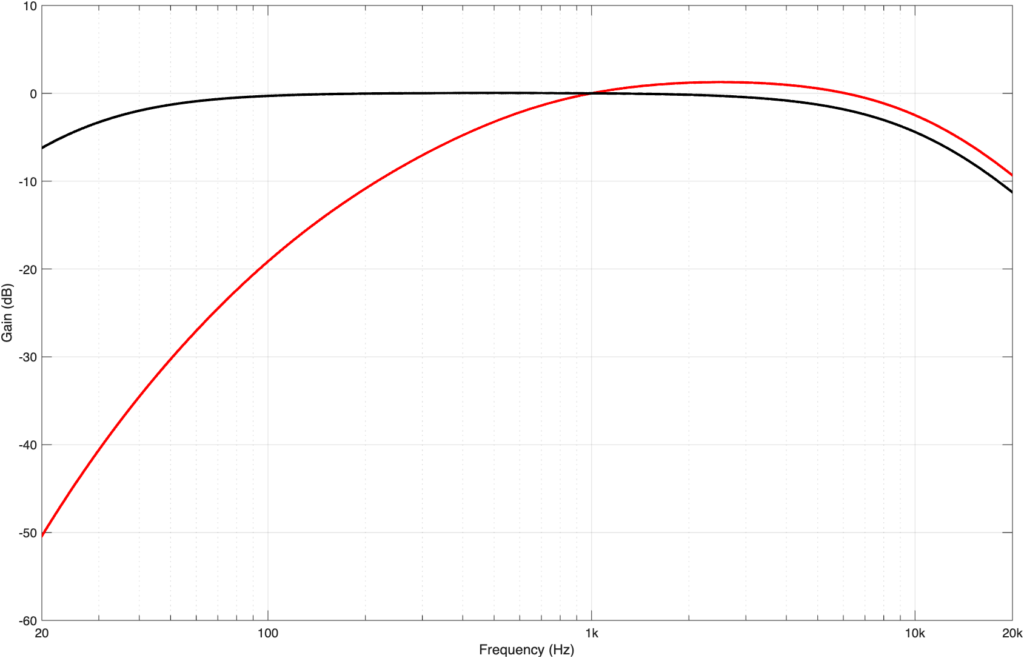
As I mentioned above, the A- and C-weighting filters (as well as other variants) were designed to simulate this lack-of-linearity to make measurements (like noise levels, for example) more aligned with human perception. For example, as can be seen above, we are bad at hearing low frequencies at low levels. So, if you are tasked with measuring the background noise caused by an air conditioning system in an office space, you’ll bring a microphone that can detect the noise better than we can, which results in you getting a high SPL value for something that we can’t hear. Therefore, we apply a roll-off to the microphone’s output before capturing a measurement value. This is the purpose of an A-weighting filter, the response of which is shown in Figure 3, below.
Figure 3: The red curve is the response of an A-weighting filter. The black curve is for C-weighting.
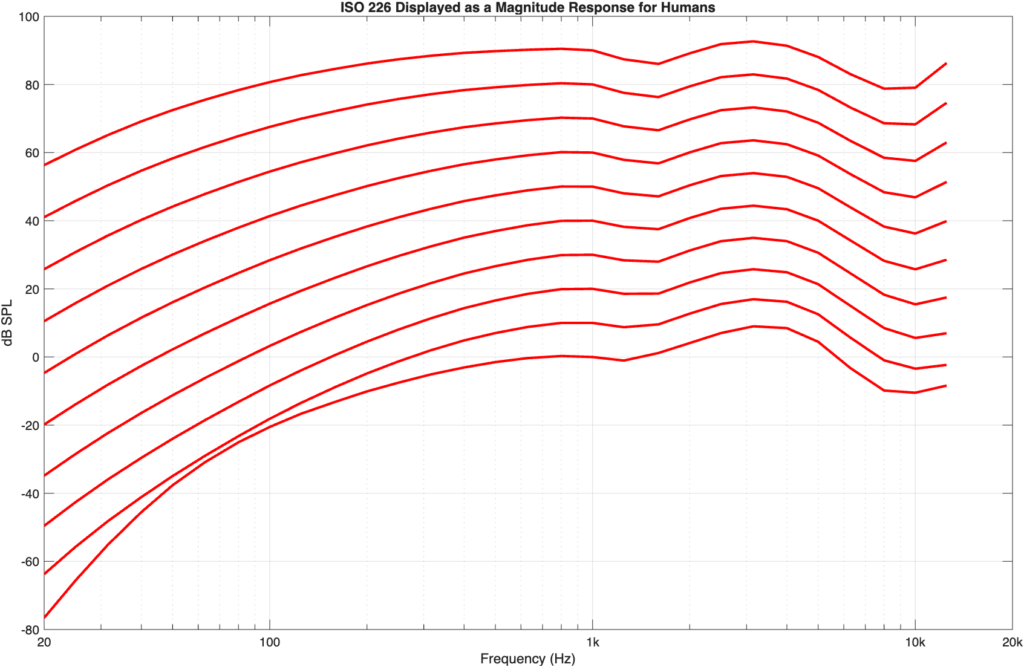
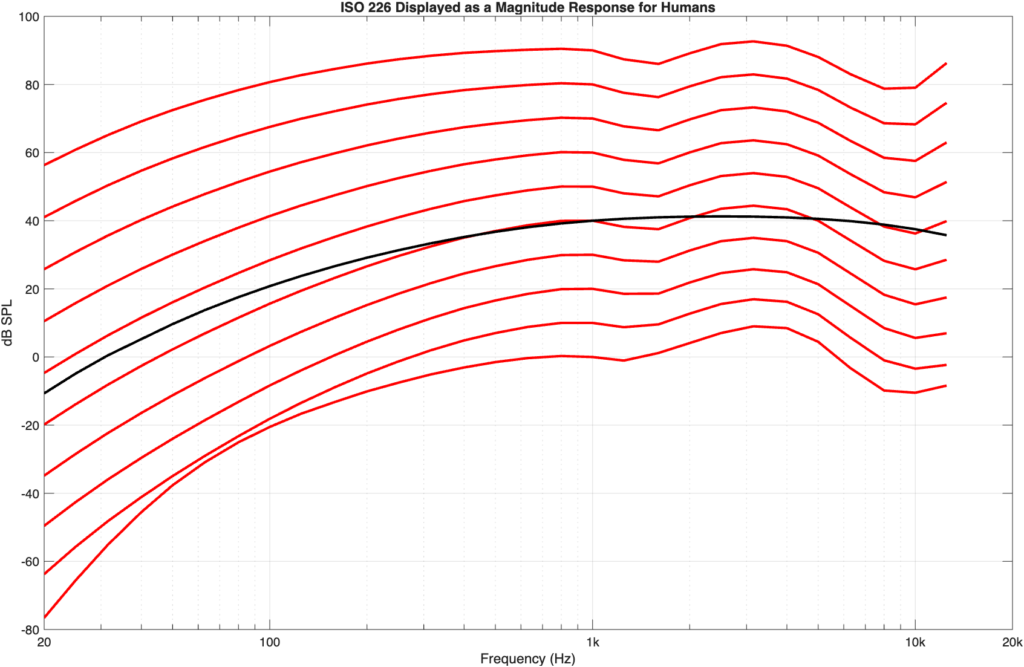
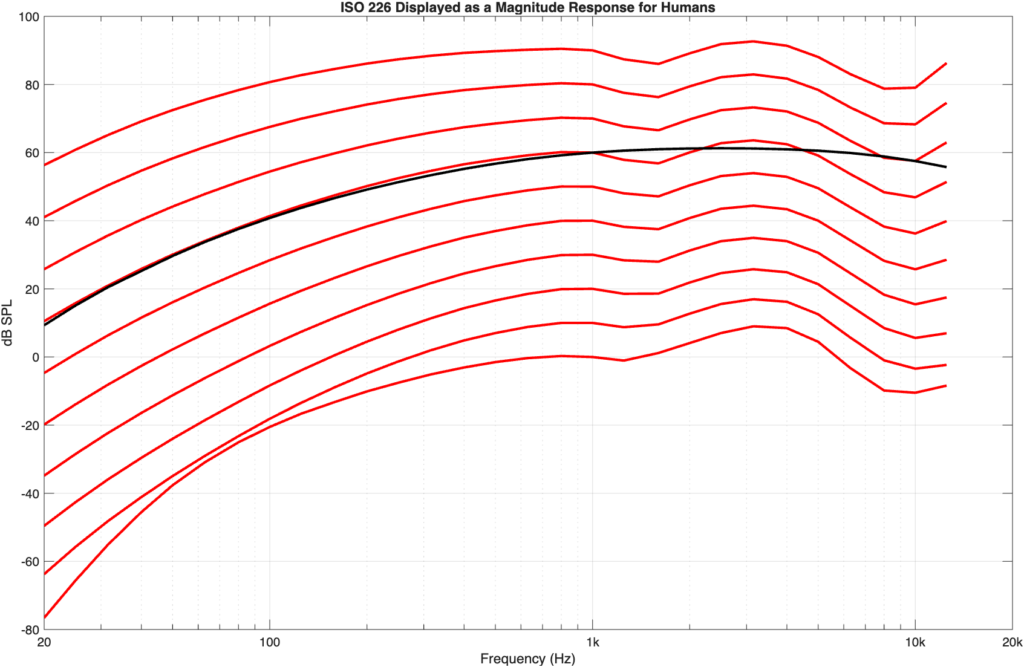
If we flip the equal loudness contours upside-down so that they show our hearing sensitivity as a magnitude response, then they’d look like the curves in Figure 4.
Figure 4: the ISO 226 equal loudness contours shown upside-down so that they appear as magnitude response plot (with offsets) instead.
The A-weighting was based on the 40-phon Fletcher–Munson curves, which represented an early determination of the equal-loudness contour for human hearing.
Subsequent research has demonstrated that A-weighting is in closer agreement with the updated 60-phon contour incorporated into ISO 226:2003 than with the 40-phon Fletcher-Munson contour, which challenges the common misapprehension that A-weighting represents loudness only for quiet sounds.
Let’s then test this by plotting the A-weighting response on top of the equal loudness contours.
Figure 5: The A-weighting curve (in black) plotted to align with the 40-phon curve (the curve that crosses 1 kHz at 40 dB SPL)
Figure 6: The A-weighting curve (in black) plotted to align with the 60-phon curve (the curve that crosses 1 kHz at 60 dB SPL)
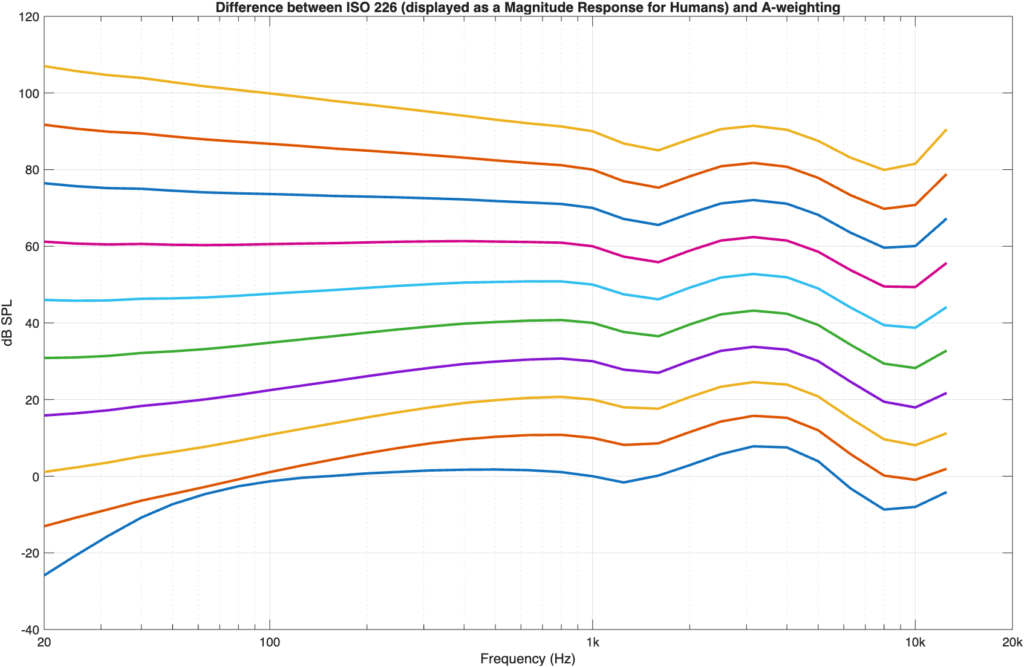
As you can see in Figure 5 and 6, the A-weighting curve better matches the 60-phon curve than the 40-phon curve. If I do this more generally, by looking at the difference between the A-weighting curve and each of the equal loudness contours (viewed as a magnitude response) then the result is as shown in Figure 7.
Figure 7: The difference between ISO 226 and A-weighting
As you can see there, the flattest curve is the one for 60-phon; the one that crosses 1 kHz at 60 dB SPL, so that statement from Wikipedia is correct.
Of course, 60 dB SPL is not THAT loud – and it’s certainly not the same as 120 dB SPL… but it seems that my high horse might not be worth staying on, and maybe using A-weighting as a general approximation, regardless of the level might NOT be as terrible a sin as I believed for so many years…
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This video explains how we are able to localise the direction of and the distance to a sound source in the real world.
Note that there are two small errors in the video. I said that 800 µsec is 8 millionths of a second. It’s 800 millionths of a second. I’ll let you find the other error.
I’ve started working with a number of my colleagues on a series of videos for internal training at Bang & Olufsen. They were kind enough to make some of these videos publicly available.
This one explains some basic concepts of human hearing in the frequency domain, including how our hearing changes with level, the reason we use “loudness” processing in loudspeakers, and psychoacoustic masking.
In case you’re interested in looking into this a little further, the curves I show there are from the Robinson-Dadson experiments, not the Fletcher-Munson version. An interesting place to start learning about the history of this is the March, 1962 issue of Wireless World magazine, which includes this plot comparing the two.
The June, 1968 issue of Wireless World magazine includes an article by R.T. Lovelock called “Loudness Control for a Stereo System”. This article partly addresses the issue of resistance behaviour one or more channels of a variable resistor. However, it also includes the following statement:
It is well known that the sensitivity of the ear does not vary in a linear manner over the whole of the frequency range. The difference in levels between the threshold of audibility and that of pain is much less at very low and very high frequencies than it is in the middle of the audio spectrum. If the frequency response is adjusted to sound correct when the reproduction level is high, it will sound thin and attenuated when the level is turned down to a soft effect. Since some people desire a high level, while others cannot endure it, if the response is maintained constant while the level is altered, the reproduction will be correct at only one of the many preferred levels. If quality is to be maintained at all levels it will be necessary to readjust the tone controls for each setting of the gain control
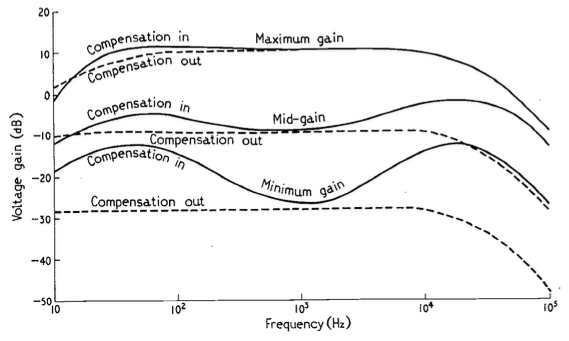
The article includes a circuit diagram that can be used to introduce a low- and high-frequency boost at lower settings of the volume control, with the following example responses:
These days, almost all audio devices include some version of this kind of variable magnitude response, dependent on volume. However, in 1968, this was a rather new idea that generated some debate.
In the following month’s issue The Letters to the Editor include a rather angry letter from John Crabbe (Editor of Hi-Fi News) where he says
Mr. Lovelock’s article in your June issue raises an old bogey which I naively thought had been buried by most British engineers many years ago. I refer, not to the author’s excellent and useful thesis on achieving an accurate gain control law, but to the notion that our hearing system’s non-linear loudness / frequency behaviour justifies an interference with response when reproducing music at various levels.
Of course, we all know about Fletcher-Munson and Robinson-Dadson, etc, and it is true that l.f. acuity declines with falling sound pressure level; though the h.f. end is different, and latest research does not support a general rise in output of the sort given by Mr. Lovelock’s circuit. However, the point is that applying the inverse of these curves to sound reproduction is completely fallacious, because the hearing mechanism works the way it does in real life, with music loud or quiet, and no one objects. If `live’ music is heard quietly from a distant seat in the concert hall the bass is subjectively less full than if heard loudly from the front row of the stalls. All a `loudness control’ does is to offer the possibility of a distant loudness coupled with a close tonal balance; no doubt an interesting experiment in psycho-acoustics, but nothing to do with realistic reproduction.
In my experience the reaction of most serious music listeners to the unnaturally thick-textured sound (for its loudness) offered at low levels by an amplifier fitted with one of these abominations is to switch it out of circuit. No doubt we must manufacture things to cater for the American market, but for goodness sake don’t let readers of Wireless World think that the Editor endorses the total fallacy on which they are based.
with Lovelock replying:
Mr. Crabbe raises a point of perennial controversy in the matter of variation of amplifier response with volume. It was because I was aware of the difference in opinion on this matter that a switch was fitted which allowed a variation of volume without adjustment of frequency characteristic. By a touch of his finger the user may select that condition which he finds most pleasing, and I still think that the question should be settled by subjective pleasure rather than by pure theory.
and
Mr. Crabbe himself admits that when no compensation is coupled to the control, it is in effect a ‘distance’ control. If the listener wishes to transpose himself from the expensive orchestra stalls to the much cheaper gallery, he is, of course, at liberty to do so. The difference in price should indicate which is the preferred choice however.
In the August edition, Crabbe replies, and an R.E. Pickvance joins the debate with a wise observation:
In his article on loudness controls in your June issue Mr. Lovelock mentions the problem of matching the loudness compensation to the actual sound levels generated. Unfortunately the situation is more complex than he suggests. Take, for example, a sound reproduction system with a record player as the signal source: if the compensation is correct for one record, another record with a different value of modulation for the same sound level in the studio will require a different setting of the loudness control in order to recreate that sound level in the listening room. For this reason the tonal balance will vary from one disc to another. Changing the loudspeakers in the system for others with different efficiencies will have the same effect.
In addition, B.S. Methven also joins in to debate the circuit design.
Apart from the fun that I have reading this debate, there are two things that stick out for me that are worth highlighting:
Notice that there is a general agreement that a volume control is, in essence, a distance simulator. This is an old, and very common “philosophy” that we forget these days.
Pickvance’s point is possibly more relevant today than ever. Despite the amount of data that we have with respect to equal loudness contours (aka “Fletcher and Munson curves”) there is still no universal standard in the music industry for mastering levels. Now that more and more tracks are being released in a Dolby Atmos-encoded format, there are some rules to follow. However, these are very different from 2-channel materials, which have no rules at all. Consequently, although we know how to compensate for changes in response in our hearing as a function of level, we don’t know what the reference level should be for any given recording.
The July 1968 issue of Wireless World Magazine contains a description of an early, but interesting analysis of the relationship between phantom image placement in a 2-channel stereo system and interchannel level differences. This is an old favourite topic of mine, originally inspired by the work of Michael Williams and his “Stereophonic Zoom”, and extending to my first AES paper in 1999.
If you, like me, are interested in this (for example, if you’re making a panning algorithm or you’re testing the veracity of headphone-based “virtual” systems), some important figures from that article are shown below.
The typical way of showing the relationship between IAD and phantom image placement.
This one is interesting because it shows the different results in different rooms, (which would also be influenced by loudspeaker directivity.)
Note that, for the plots above and below, the x-axes show the position of the image in the stereo sound stage, where 0 is the centre point between the two loudspeakers and 0.5 is a position in one of the two loudspeakers. This is 0.5 because it’s one-half of the total angular distance between the two loudspeakers. So, you can consider the loudspeaker aperture as ±0.5.
The relationship between image WIDTH and position. This is something I’ve not seen expressed so clearly before.
For more information similar to this, see these links as a start:
In Part 1, we looked at what happens when you try to record a signal whose frequency is higher than 1/2 the sampling rate (which, from now on, I’ll call the Nyquist Frequency, named after Harry Nyquist who was one of the people that first realised that this limit existed). You record a signal, but it winds up having a different frequency at the output than it had at the input. In addition, that frequency is related to the signal’s frequency and the sampling rate itself.
In order to prevent this from happening, digital recording systems use a low-pass filter that hypothetically prevents any signals above the Nyquist frequency from getting into the analogue-to-digital conversion process. This filter is called an anti-aliasing filter because it prevents any signals that would produce an alias frequency from getting into the system. (In practice, these filters aren’t perfect, and so it’s typical that some energy above the Nyquist frequency leaks into the converter.)
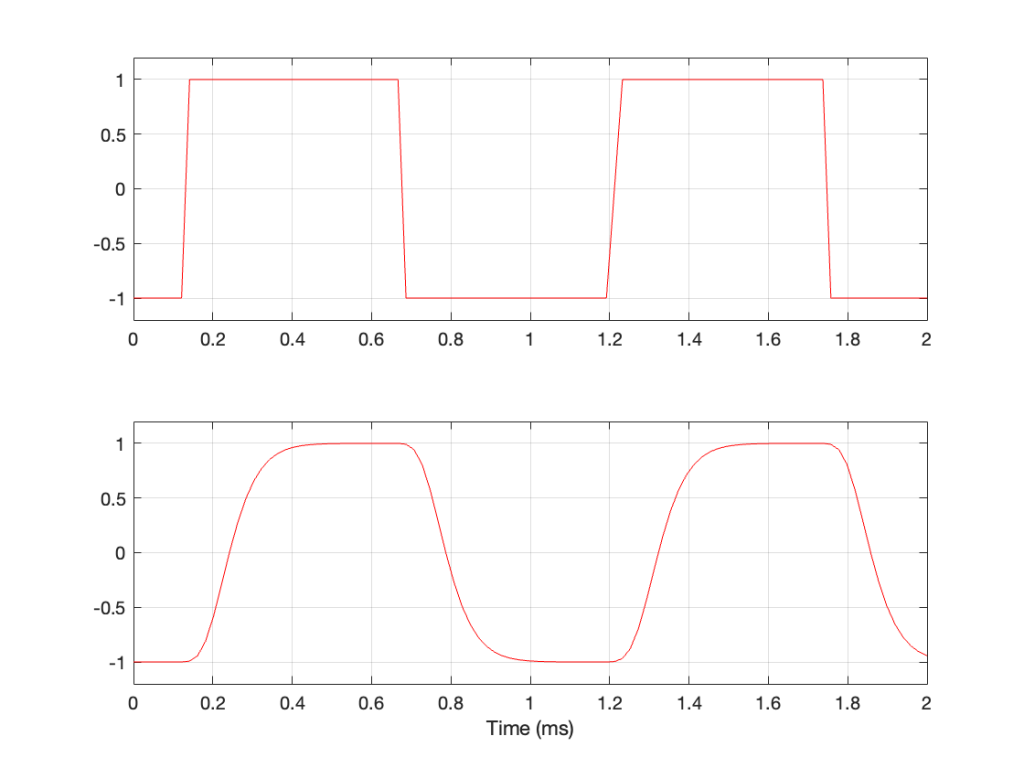
So, this means that if you put a signal that contains high frequency components into the analogue input of an analogue-to-digital converter (or ADC), it will be filtered. An example of this is shown in Figure 1, below. The top plot is a square wave before filtering. The bottom plot is the result of low-pass filtering the square wave, thus heavily attenuating its higher harmonics. This results in a reduction in the slope when the wave transitions between low and high states.
Figure 1: A square wave before and after low-pass filtering.
This means that, if I have an analogue square wave and I record it digitally, the signal that I actually record will be something like the bottom plot rather than the top one, depending on many things like the frequency of the square wave, the characteristics of the anti-aliasing filter, the sampling rate, and so on. Don’t go jumping to conclusions here. The plot above uses an aggressively exaggerated filter to make it obvious that we do something to prevent aliasing in the recorded signal. Do NOT use the plots as proof that “analogue is better than digital” because that’s a one-dimensional and therefore very silly thing to claim.
However…
… just because we keep signals with frequency content above the Nyquist frequency out of the input of the system doesn’t mean that they can’t exist inside the system. In other words, it’s possible to create a signal that produces aliasing after the ADC. You can either do this by
creating signals from scratch (for example, generating a sine tone with a frequency above Nyquist) or
by producing artefacts because of some processing applied to the signal (like clipping, for example).
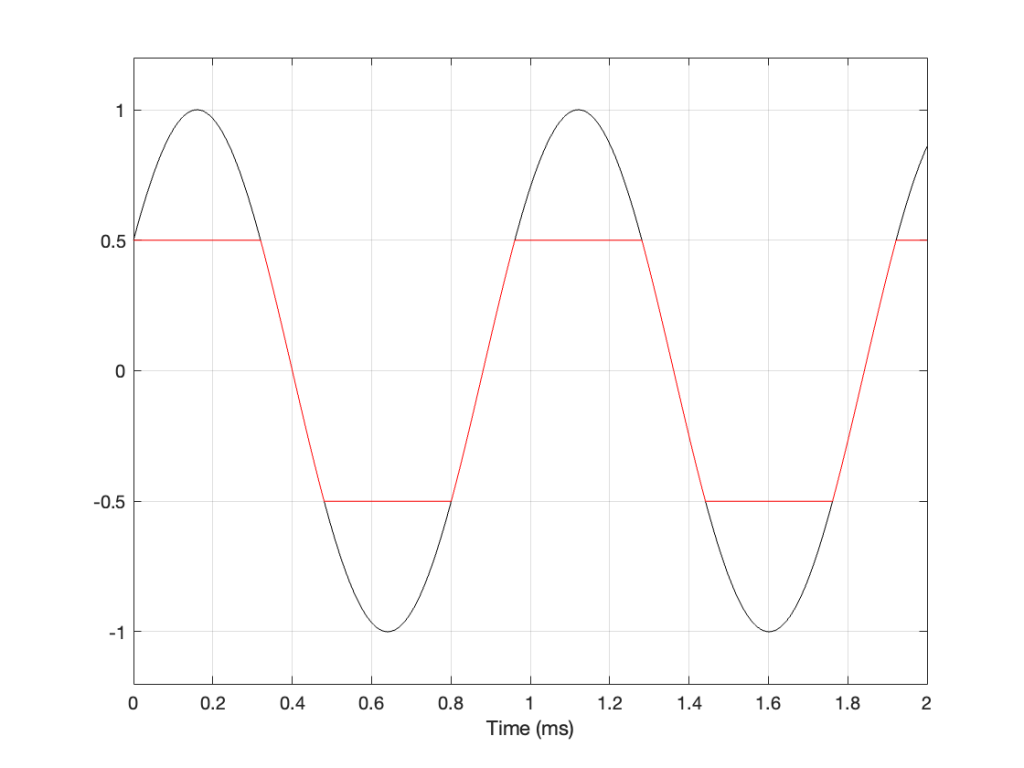
Let’s take a sine wave and clip it after it’s been converted to a digital signal with a 48 kHz sampling rate, as is shown in Figure 2.
Figure 2: The red curve is a clipped version of the black curve.
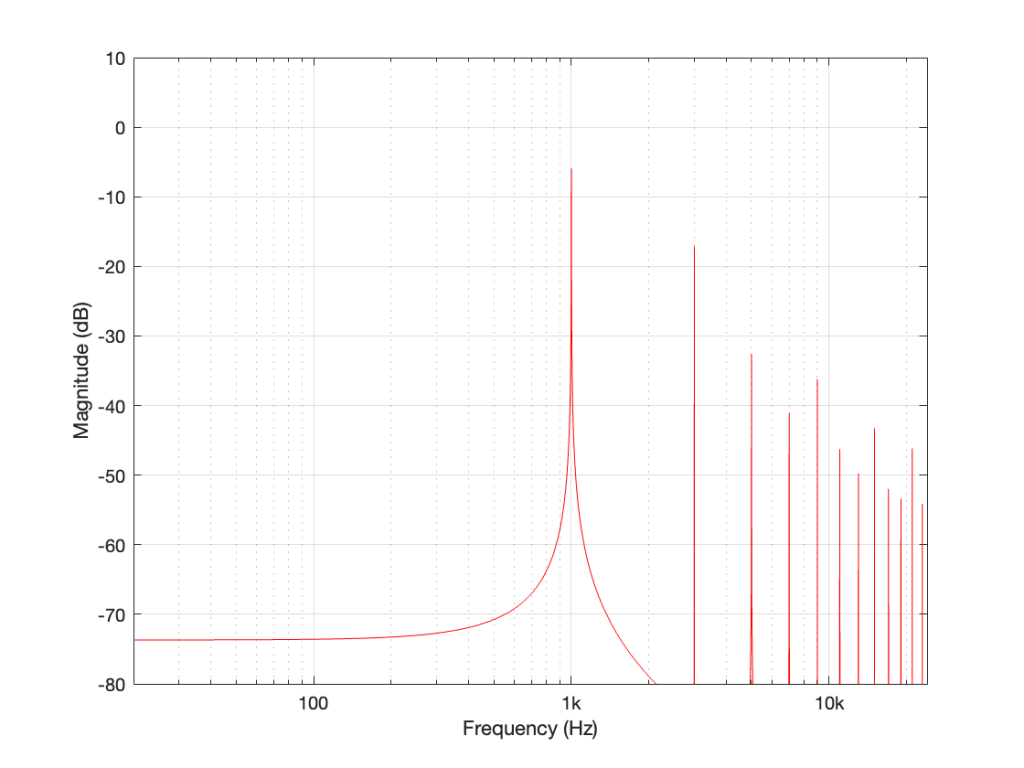
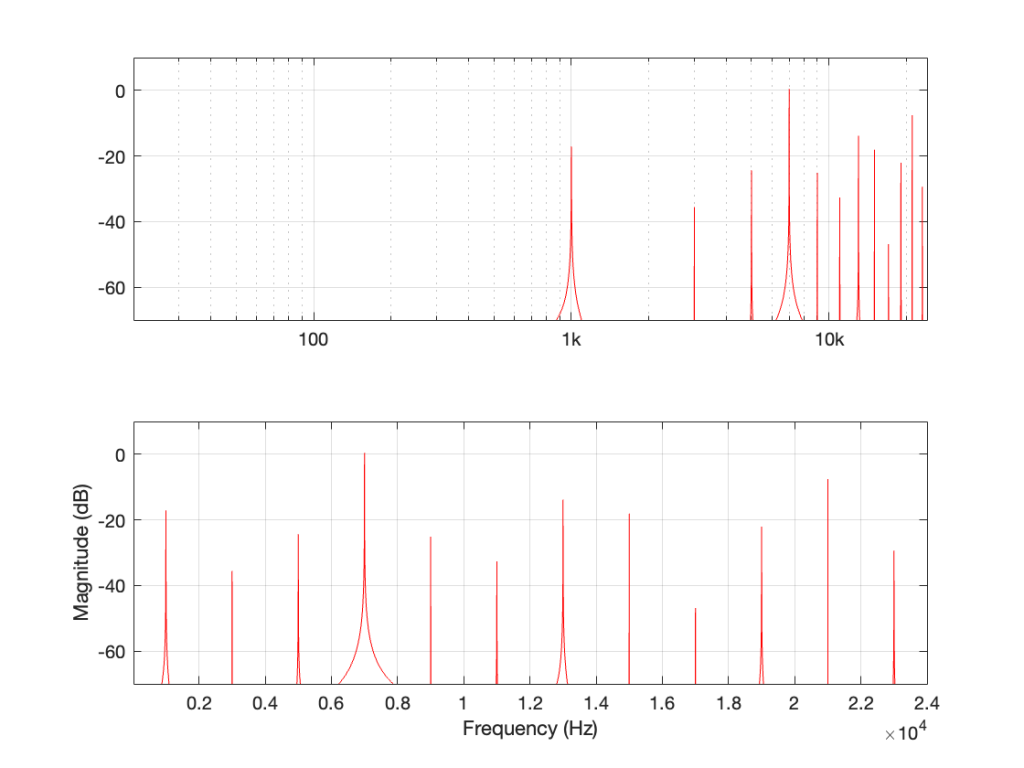
When we clip a signal, we generate high-frequency harmonics. For example, the signal in Figure 2 is a 1 kHz sine wave that I clipped at ±0.5. If I analyse the magnitude response of that, it will look something like Figure 3:
Figure 3: The magnitude response of Figure 2, showing the upper harmonics that I created by clipping.
The red curve in Figure 2 is not a ‘perfect’ square wave, so the harmonics seen in Figure 3 won’t follow the pattern that you would expect for such a thing. But that’s not the only reason this plot will be weird…
Figure 3 is actually hiding something from you… I clipped a 1 kHz sine wave, which makes it square-ish. This means that I’ve generated harmonics at 3 kHz, 5 kHz, 7 kHz, and so on, up to ∞ Hz..
Notice there that I didn’t say “up to the Nyquist frequency”, which, in this example with a sampling rate of 48 kHz, would be 24 kHz.
Those harmonics above the Nyquist frequency were generated, but then stored as their aliases. So, although there’s a new harmonic at 25 kHz, the system records it as being at 48 kHz – 25 kHz = 23 kHz, which is right on top of the harmonic just below it.
In other words, when you look at all the spikes in the graph in Figure 3, you’re actually seeing at least two spikes sitting on top of each other. One of them is the “real” harmonic, and the other is an alias (there are actually more, but we’ll get to that…). However, since I clipped a 1 kHz sine wave in a 48 kHz world, this lines up all the aliases to be sitting on top of the lower harmonics.
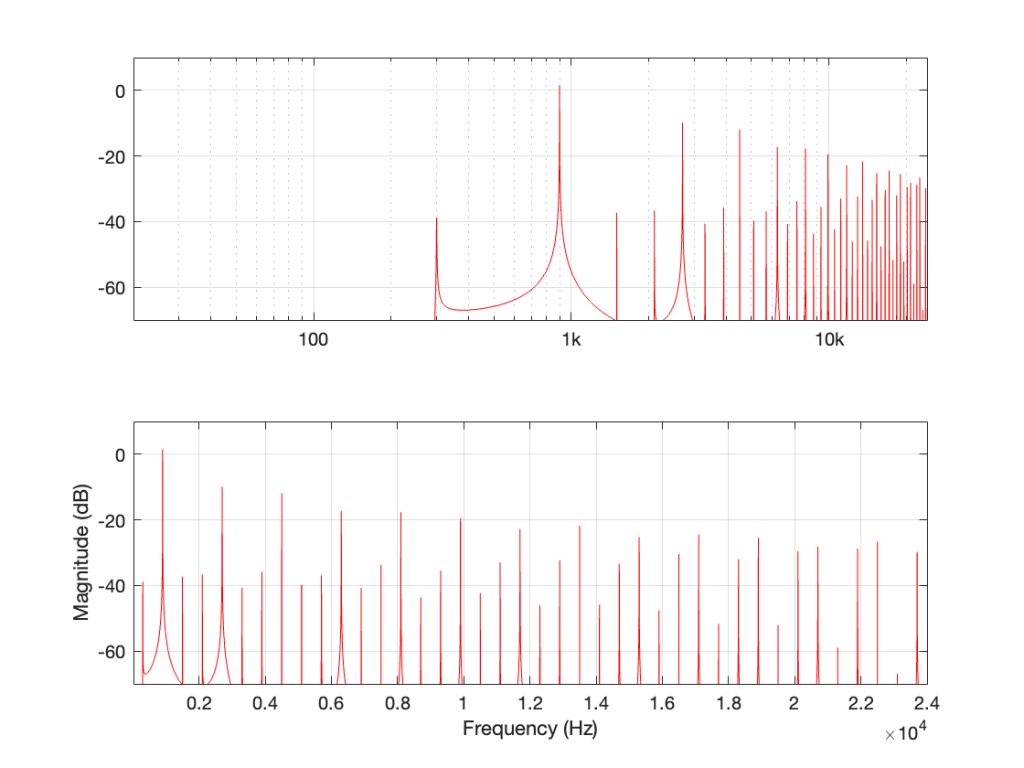
So, what happens if I clip a sine wave with a frequency that isn’t nicely related to the sampling rate, like 900 Hz in a 48 kHz system, for example? Then the result will look more like Figure 4, which is a LOT messier.
Figure 4: The magnitude response of a 900 Hz square wave, plotted with a logarithmic frequency axis in the top axis and a linear axis in the bottom.
A 900 Hz square wave will have harmonics at odd multiples of the fundamental, therefore at 2.7 kHz, 4.5 kHz, and so on up to 22.5 kHz (900 Hz * 25).
The next harmonic is 24.3 kHz (900 Hz * 27), which will show up in the plots at 48 kHz – 24.3 kHz = 23.7 kHz. The next one will be 26.1 kHz (900 Hz * 29) which shows up in the plots at 21.9 kHz. This will continue back DOWN in frequency through the plot until you get to 900 Hz * 53 = 47.7 kHz which will show up as a 300 Hz tone, and now we’re on our way back up again… (Take a look at Figure 7, below for another way to think of this.)
The next harmonic will be 900 Hz * 55 = 49.5 kHz which will show up in the plot as a 1.5 kHz tone (49.5 kHz – 48 kHz).
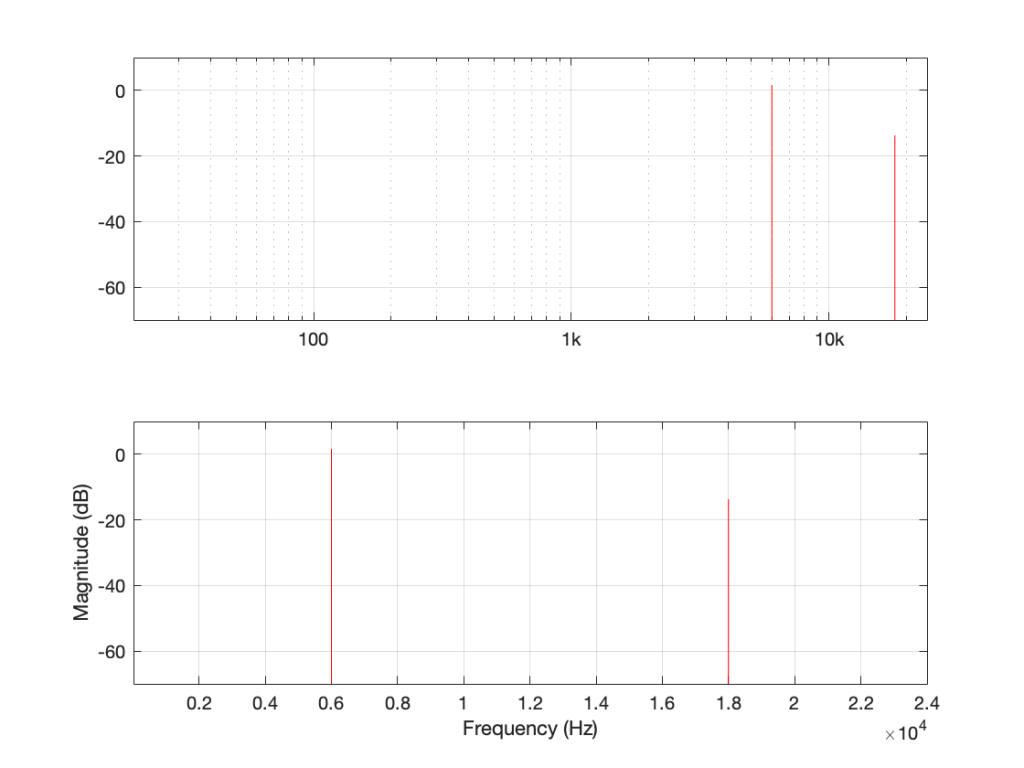
Depending on the relationship between the square wave’s frequency and the sampling rate, you either get a “pretty” plot, like for the 6 kHz square wave in a 48 kHz system, as shown in Figure 5.
Figure 5: the magnitude response of a 6 kHz square wave in a 48 kHz system
Or, it’s messy, like the 7 kHz square wave in a 48 kHz system in Figure 6.
Figure 6: The magnitude response of a 7 kHz square wave in a 48 kHz system.
The moral of the story
There are three things to remember from this little pair of posts:
Some aliased artefacts are negative frequencies, meaning that they appear to be going backwards in time as compared to the original (just like the wheel appearing to rotate backwards in Part 1).
Just because you have an antialiasing filter at the input of your ADC does NOT protect you from aliasing, because it can be generated internally, after the signal has been converted to the digital domain.
Once this aliasing has happened (e.g. because you clipped the signal in the digital domain), then the aliases are in the signal below the Nyquist frequency and therefore will not be removed by the reconstruction low-pass filter in the DAC. Once they’re mixed in there with the signal, you can’t get them out again.
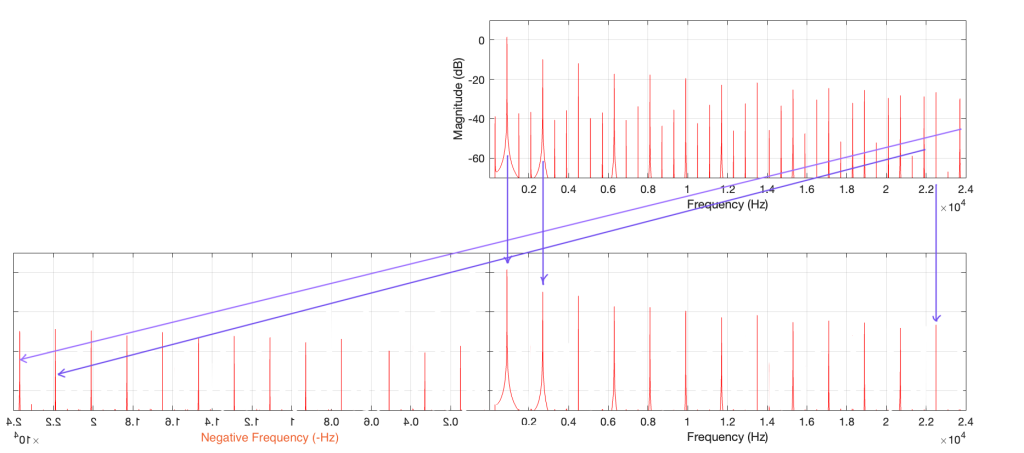
Figure 7: This is the same as Figure 4, but I’ve removed the first set of mirrored alias artefacts and plotted them on the left side as being mirrored in a “negative frequency” alternate universe.
One additional, but smaller problem with all of this is that, when you look at the output of an FFT analysis of a signal (like the top plot in Figure 7, for example), there’s no way for you to know which components are “normal” harmonics, and which are aliased artefacts that are actually above the Nyquist frequency. It’s another case proving that you need to understand what to expect from the output of the FFT in order to understand what you’re actually getting.
One of the best-known things about digital audio is the fact that you cannot record a signal that has a frequency that is higher than 1/2 the sampling rate.
Now, to be fair, that statement is not true. You CAN record a signal that has a frequency that is higher than 1/2 the sampling rate. You just won’t be able to play it back properly, because what comes out of the playback will not be the original frequency, but an alias of it.
If you record a one-spoked wheel with a series of photographs (in the old days, we called this ‘a movie’), the photos (the frames of the movie) might look something like this:
As you can see there, the wheel happens to be turning at a speed that results in it rotating 45º every frame.
The equivalent of this in a digital audio world would be if we were recording a sine wave that rotated (yes…. rotated…) 45º every sample, like this:
Notice that the red lines indicating the sample values are equivalent to the height of the spoke at the wheel rim in the first figure.
If we speed up the wheel’s rotation so that it rotated 90º per frame, it looks like this:
And the audio equivalent would look like this:
Speeding up even more to 135º per frame, we get this:
and this:
Then we get to a magical speed where the wheel rotated 180º per frame. At this speed, it appears when we look at the playback of the film that the wheel has stopped, and it now has two spokes.
In the audio equivalent, it looks like the result is that we have no output, as shown below.
However, this isn’t really true. It’s just an artefact of the fact that I chose to plot a sine wave. If I were to change the phase of this to be a cosine wave (at the same frequency) instead, for example, then it would definitely have an output.
At this point, the frequency of the audio signal is 1/2 the sampling rate.
What happens if the wheel goes even faster (and audio signal’s frequency goes above this)?
Notice that the wheel is now making more than a half-turn per frame. We can still record it. However, when we play it back, it doesn’t look like what happened. It looks like the wheel is going backwards like this:
Similarly, if we record a sine wave that has a frequency that is higher than 1/2 the sampling rate like this:
Then, when we play it back, we get a lower frequency that fits the samples, like this:
Just a little math
There is a simple way to calculate the frequency of the signal that you get out of the system if you know the sampling rate and the frequency of the signal that you tried to record.
Let’s use the following abbreviations to make it easy to state:
Fs = Sampling rate
F_in = frequency of the input signal
F_out = frequency of the output signal
IF F_in < Fs/2 THEN F_out = F_in
IF Fs > F_in > Fs/2 THEN F_out = Fs/2 – (F_in – Fs/2) = Fs – F_in
Some examples:
If your sampling rate is 48 kHz, and you try to record a 25 kHz sine wave, then the signal that you will play back will be: 48000 – 25000 = 23000 Hz
If your sampling rate is 48 kHz, and you try to record a 42 kHz sine wave, then the signal that you will play back will be: 48000 – 42000 = 6000 Hz
So, as you can see there, as the input signal’s frequency goes up, the alias frequency of the signal (the one you hear at the output) will go down.
There’s one more thing…
Go back and look at that last figure showing the playback signal of the sine wave. It looks like the sine wave has an inverted polarity compared to the signal that came into the system (notice that it starts on a downwards-slope whereas the input signal started on an upwards-slope). However, the polarity of the sine wave is NOT inverted. Nor has the phase shifted. The sine wave that you’re hearing at the output is going backwards in time compared to the signal at the input, just like the wheel appears to be rotating backwards when it’s actually going forwards.
In Part 2, we’ll talk about why you don’t need to worry about this in the real world, except when you REALLY need to worry about it.