I’ve decided to disable the “comments” option on all of the postings on this website. This should not delete the existing comments – but new ones will not be possible in the future. This will happen over the coming days. I have a number of reasons for this, but mostly, it’s because I am increasingly trying to disconnect from my computer and phone – and curating / moderating comments on a website is one of the easier tasks to drop.
If you have specific questions about things I have written here, you are welcome to email me. However, I cannot promise that the reply will be rapid, since I’m also trying to disconnect from my email more and more…
I’m originally from Newfoundland – one of the few places in the world with a 1/2-hour time zone. So, when it’s 10:00 a.m. in Montreal, it’s 11:30 a.m. in St. John’s – my home town. This meant that, when I was a kid 40 years ago, and we would call our relatives in Toronto or Germany to wish them a Merry Christmas, there were two questions that you could always rely on being asked: (1) what’s the weather like there? and (2) what time is it there?
These days, I have a similar problem that is well-described by “Segal’s Law“. My iPhone and my wristwatch (an old analogue one with hands that go around pointing at the floor and the fridge…) are never synchronised… This is because of two things: (1) I probably did a bad job of setting my watch and (more importantly) (2) my watch runs just a little bit slowly…
So, let’s say, for example, that I set my watch to be EXACTLY in sync with my phone on a Monday morning at 9:00 a.m. As the week goes by, my iPhone and my watch drift apart, and, just for the sake of argument let’s say that, one week later, when my iPhone turns over to 9:00 a.m. on Monday morning, my wristwatch turns over to 8:59 a.m. So, I lose 1 minute per week on my watch.
(It’s pretty safe to assume that my iPhone is also not perfect – but it’s different because, every once in a while, it compares its internal clock with another, more accurate clock somewhere else via a connection across the Internet (which, we will assume, for the purposes of this discussion, works).)
Let’s consider this from a strange point of view. Let’s assume that
I’m checking the time on my watch every minute, on the minute
someone else is “fixing” my watch every week so that it’s correct at 9:00 a.m. on Mondays. They do this by adjusting the watch to the correct time 30 seconds before the iPhone says it’s 9:00 a.m.
I don’t know that they’re doing this for me…
If we think about this from my perspective, I’ll live in a strange world where 8:59 on Mondays never exists. This is because at 8:58 and 30 seconds (on my watch), my friend re-sets the time to 8:59 and 30 seconds (while I’m not looking) to synchronise with the iPhone…
IF my watch was running fast – say, gaining one minute each week, then I would live in a different strange universe where 9:00 happens twice every Monday morning…
The basic problem here is that we have two clocks that do not run at the same rate – but they are expected to do so. So, we synchronise them regularly (in the above example, on Monday mornings at 9:00) – but between those synchronisation events, they drift apart in time.
So what?
The example above is very, very similar to the way a digital audio streaming system works – especially if you’re using a wireless connection between the transmitting device and a receiver.
Lets say that you’re playing a sound file that was recorded at 44.1 kHz and streaming it wirelessly to a receiver. I’m trying to be as generic as possible here, but I could be talking about a Bluetooth connection to a pair of headphones or a WiFi connection via DLNA to a device connected to a pair of loudspeakers, for example…
It is not unusual with such a connection for the transmitter to collect up a block of audio samples – say, 64 of them – and send them to the receiver’s input buffer. The receiver then pulls those samples out, one by one, and (eventually) sends them to a digital-to-analogue converter that produces a signal that (eventually) comes out as an audio signal. Then, 64/44100’ths of a second later (64 samples later) the transmitter sends another block, and so on and so on until the song ends.
This system works well if the clock inside the transmitter and the clock inside the receiver are perfectly synchronised. We can even be a little generous and say that they can drift apart a little – but not so much that we either run out of samples to play (because the receiver is playing them out faster than they’re coming in from the transmitter) or that we have samples left over to play when the next block comes in (because the receiver is playing them out slower than they’re coming in from the transmitter).
Dealing with this problem the right way
The right way to deal with this issue is for the receiver to always be checking what time it thinks it is when the block arrives from the transmitter. If the block arrives a little early, then the receiver should think “hmmmm, my clock is going too slowly – I’ll speed it up a bit”. If the block arrives a little late, then the receiver should adjust its clock to go a little slower.
So, in this case, the receiver has a basic, nominal speed for its internal clock – but it’s constantly adjusting it to be faster and slower to try and match the clock of the transmitter – but it can only do this adjustment at the block rate – the frequency at which the blocks of samples arrive, which is dependent on the block length (how many samples are in each block) and the sampling rate (how many samples per second). (Of course, this can result in “jitter and wander” problems if you’re not careful (I won’t talk about this here…) – so you have to pay a little attention to how quickly you’re adjusting your clock rate… but that’s “just” a matter of correct implementation.)
Dealing with this problem the wrong way
There is another way to deal with this problem, which, unfortunately, has measurable and possibly audible consequences. This implementation is basically the same as my original example, where I had a friend “fixing” my wristwatch once a week. You have a transmitter that sends blocks of samples to the receiver – and although these two devices should have exactly the same clock rate, they don’t.
Let’s say, for example, that the receiver is playing the samples faster than they’re being sent by the transmitter. This means that the two will slowly drift farther and farther apart until, eventually, the receiver will have to play a sample, but nothing has come in from the transmitter yet, so there’s no sample there to play. In this case, the receiver says “no problem, I’ll just play the last sample again, and the next block will come in while I’m doing that” – so it inserts an extra sample that is just a duplicate of the previous one.
If the receiver’s clock is going slower than the transmitter’s, then, as the two drift farther apart, we will get to a moment where the receiver will receive a new block of samples but it’s not done playing all of the samples in the previous block yet. In this event, it says “no problem, I’ll just leave that last sample out and move on to the next block to catch up” – so it skips a sample.
This is called a “Skip / Insert” strategy for dealing with clock synchronisation. It’s done by software and hardware engineers because it’s simple to implement, and, in many cases, a manufacturer can get away with this, since it is rarely audible for a couple of reasons.
Can this be measured?
The simple answer to this is “yes” – and it can be measured in a number of different ways. I’ll show one way below…
Can I hear it?
The honest answer to this question is “sometimes” – but it’s not as easy to detect as one might think. Of course, a skip/insert event (a duplicated sample or a dropped one) creates an artefact. However, the magnitude of this artefact relative to the “correct” signal is dependent on when it happens.
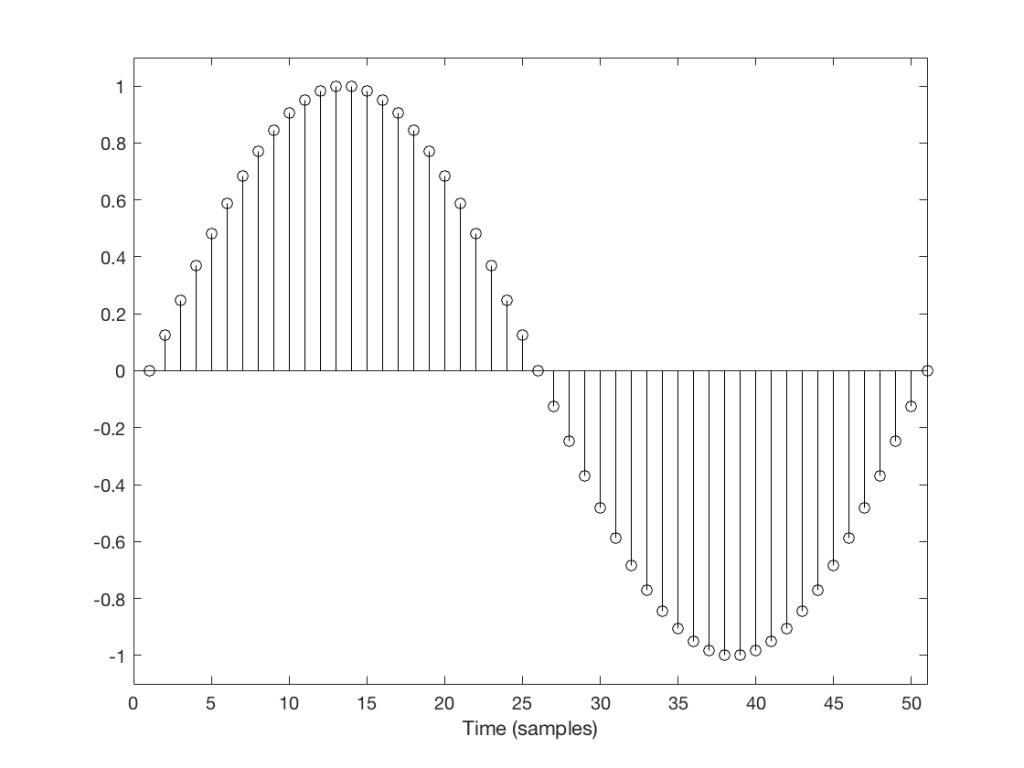
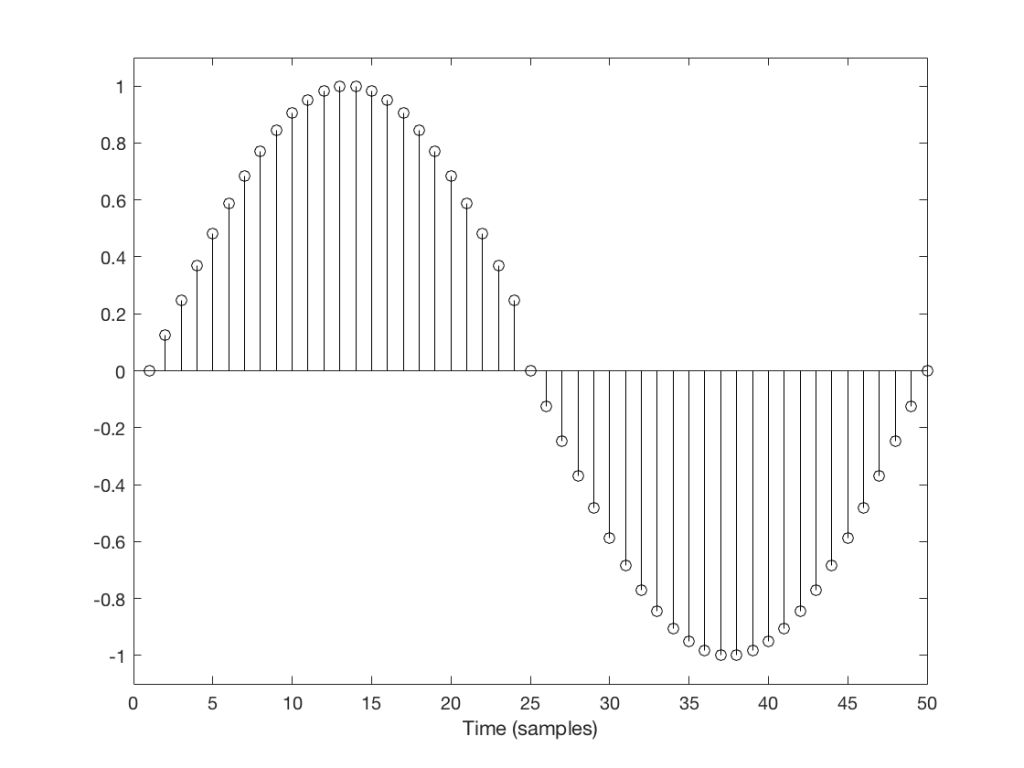
Let’s take a look at a couple of simple cases. We’ll “transmit” one period of a sine wave that should come out on the other side of the system looking like Figure 1.
Fig 1: The original signal that we want to transmit
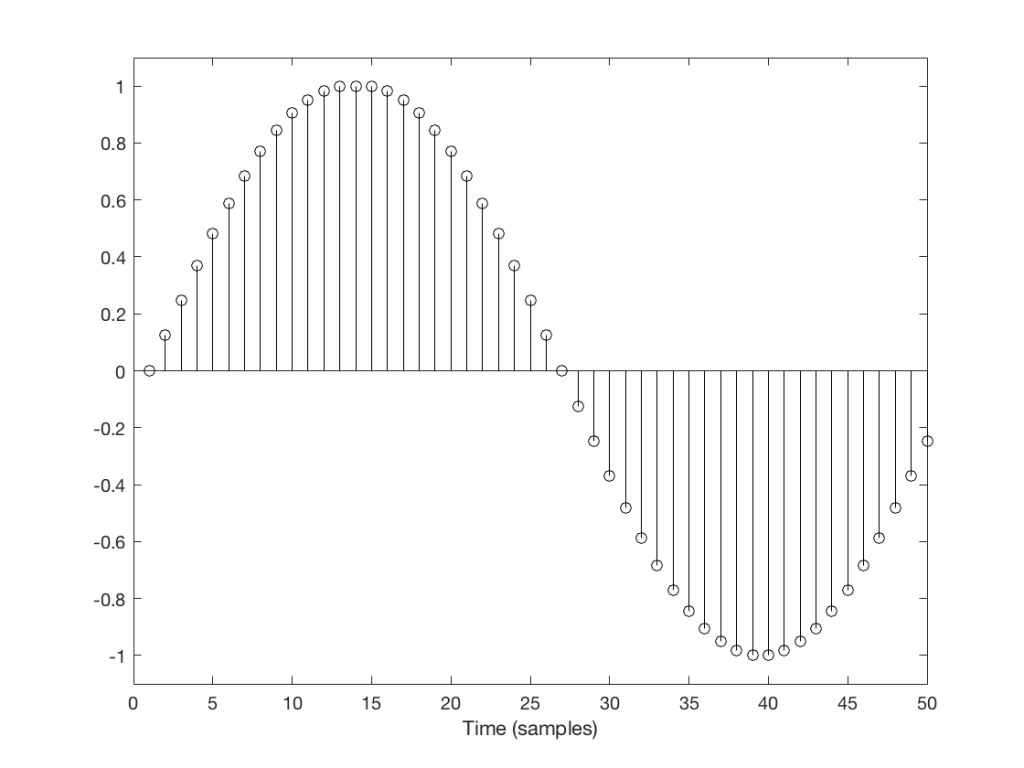
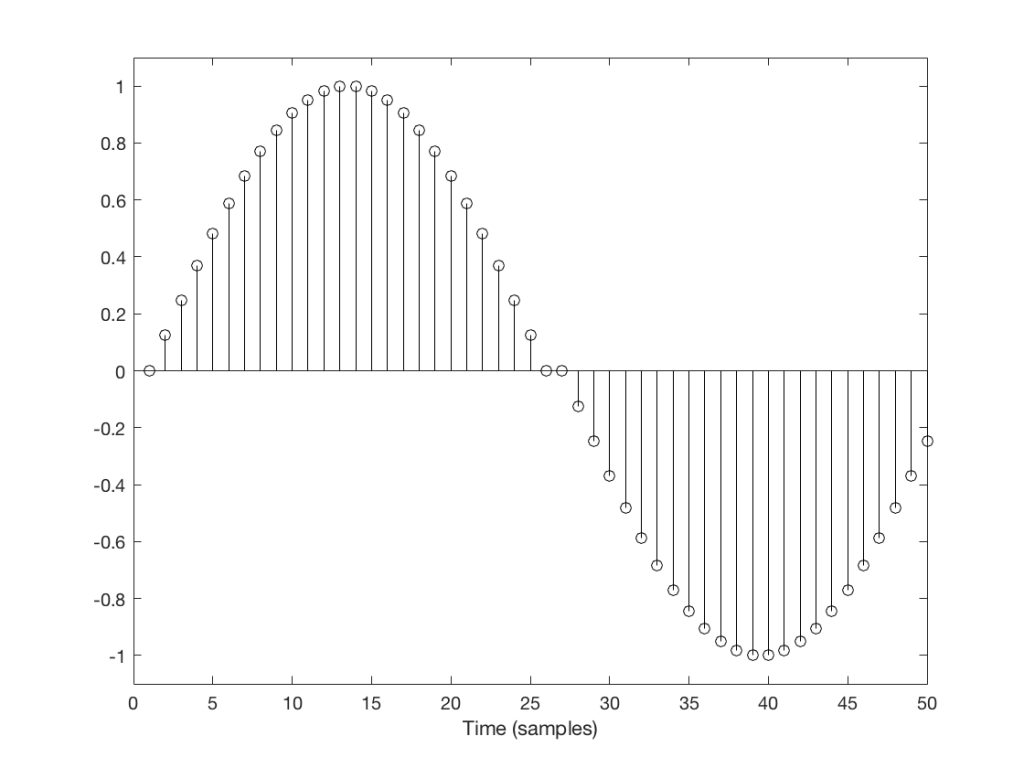
But what happens if we don’t get a block in time to keep outputting a signal? We insert a duplicate sample and hope that the block comes in before I have to send out another one. Examples of this are shown in Figures 2 and 3, below.
Fig 2: Insert example 1Fig 3: Insert example 2
You’ll probably notice that it’s much easier to see which sample I duplicated in Figure 3 than in Figure 2. In Figure 3 it was sample number 26 that was duplicated. In Figure 2 it’s sample number 13.
The reason it’s easier to see the error in Figure 3 is that duplicating the sample causes an obvious change in the slope of the signal, whereas in Figure 2 it does not – the slope of the signal is 0, and by duplicating a sample, I am also making it 0 – but for a slightly longer time.
This does not mean that we did not generate an error. It just means that we’ll probably “get away with it” in the case of Figure 2, and we probably won’t in the case of Figure 3.
However, since the drifting of the two clocks (in the receiver and transmitter) are not dependent on the signal, there’s no way to know when this is going to happen.
And, of course, if this happens in the middle of a snare drum hit or a ssssinger sssstarting a word in a ssssong with the letter “s” – then we also won’t hear it because there’s so much going on (frequency-wise) that the artefact will be buried in the mess.
Also, since this clock drifting is usually not completely regular, the errors do not usually come in at a regular rate (although I’ve seen exceptions…). So, it’s not like you can listen for “a click every second” or “one per minute”. They happen when they happen – hopefully when you’re not listening and/or when the tune is busy enough to hide it.
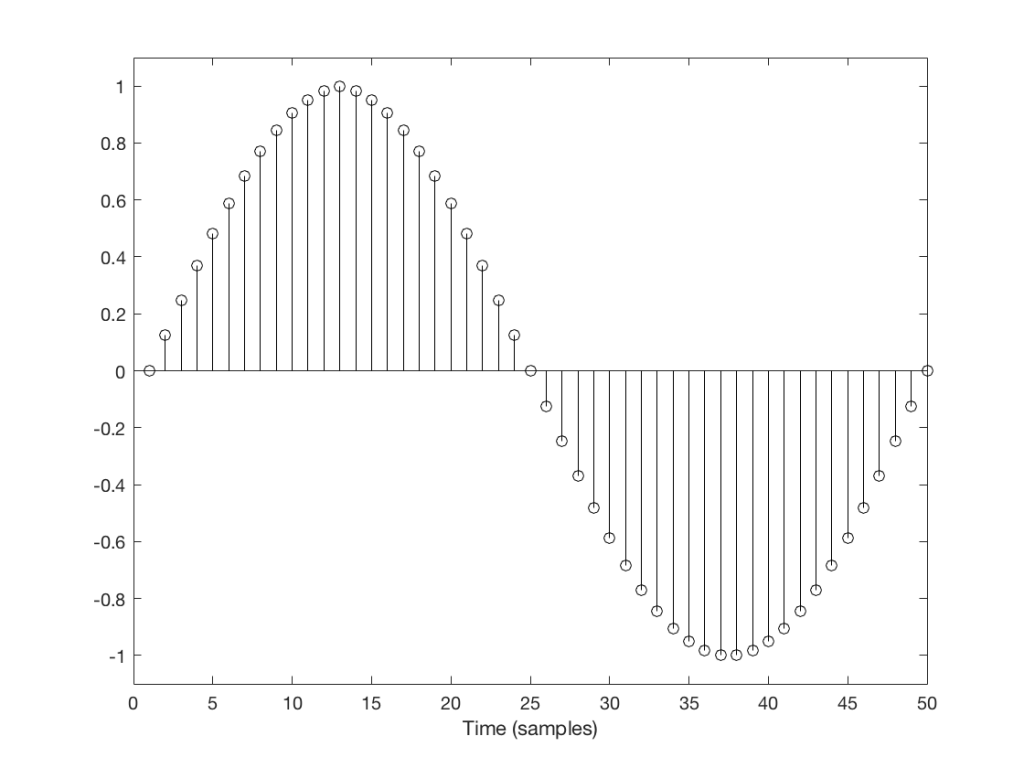
A skip event is similar to an insert, as you can see in the two examples in Figures 4 and 5.
Fig 4: Skip example 1Fig 5: Skip example 2
Again, I’ve intentionally put in these two skips in places where they are least obvious (Figure 4) and most obvious (Figure 5).
The real world
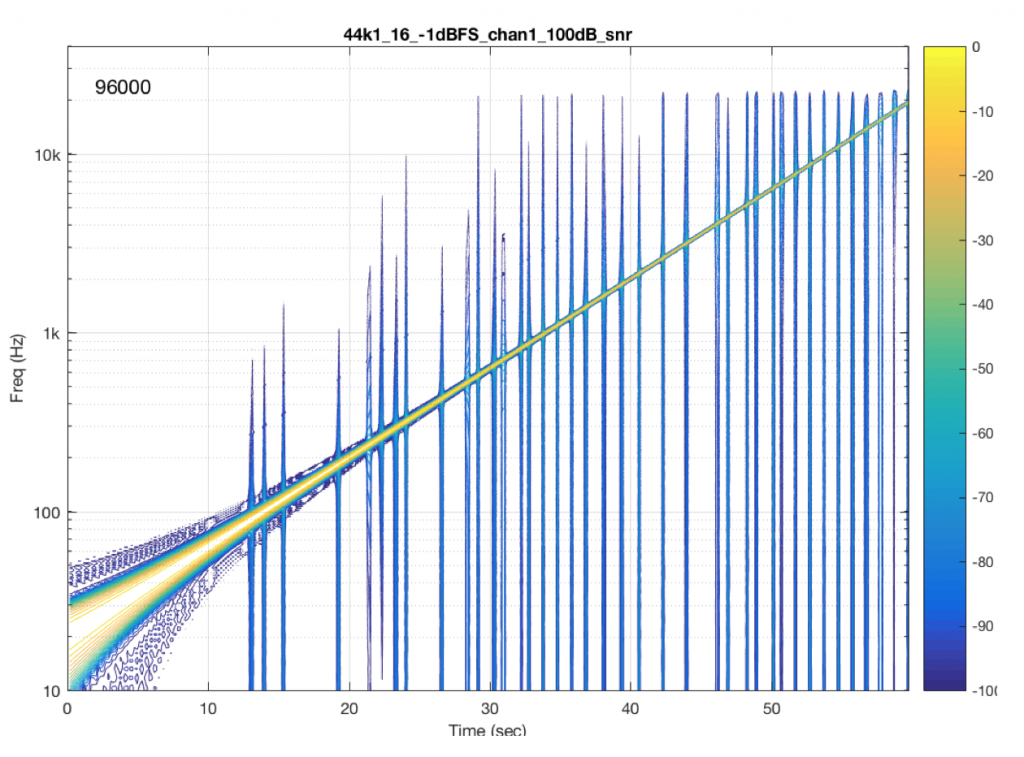
One of the tests that can be done on an audio system is to send a sinusoidal signal with a swept frequency through a system, capture the output, and then do a spectrogram of the result. In theory, if you see anything other than a single frequency at any one time at the output, then you know that something has happened to the signal. You would probably then need to go back and look at the output signal itself to start evaluating exactly what happened… This is a test that is used to evaluate one aspect of the performance of different sampling rate converters, for example, at this site.
Let’s take a sine sweep and run it through a system. The sweep goes up logarithmically in frequency from 20 Hz to about 90% of Nyquist (which would correspond to 20,000 Hz in a system running at 44.1 kHz) over 60 seconds and has a level of -1 dB FS. We’ll then capture the output in a system that is behaving perfectly and do a spectrogram of this, looking for artefacts down to some level below the signal level. (If you’re really geeky, you’ll know that this signal-to-error ratio is dependent on the window length of the FFT I’m using to create the spectrogram – but this is beyond our discussion today…).
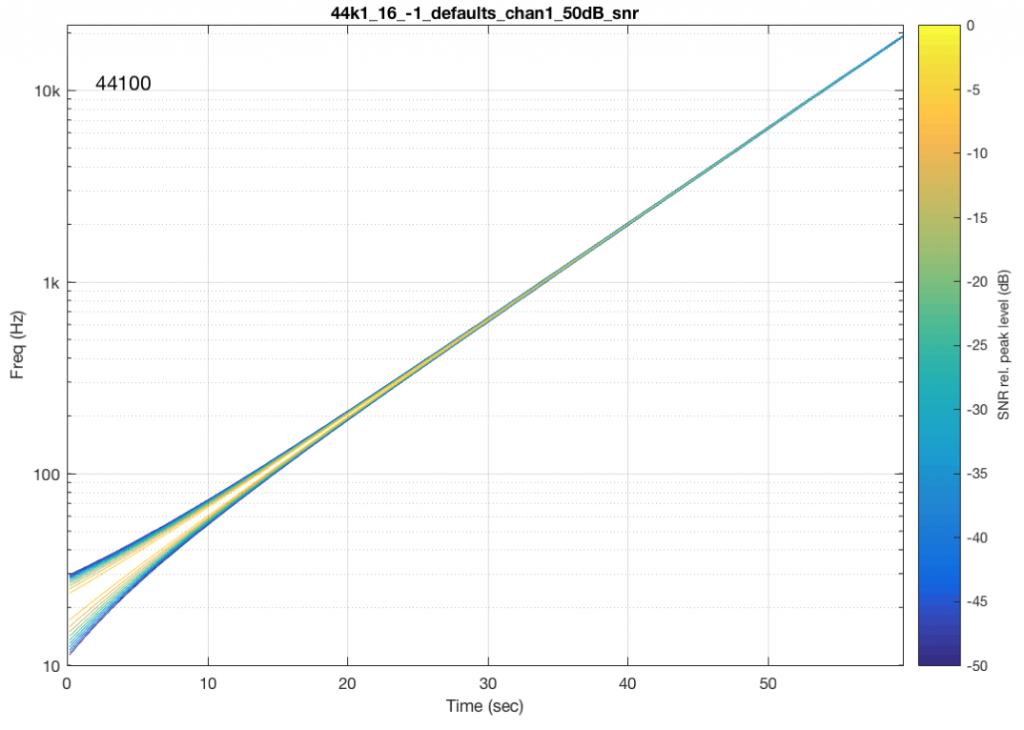
An example of the output of a system that is behaving well is shown in Figure 6.
Fig 6. A spectrogram of a sinusoidal signal, swept in frequency over 60 seconds. Notice that there are no additional signals within 50 dB (the scale on the right) of the signal.
You may notice that the plot looks a little “wide” in the beginning. This is because the window length of the FFT I’m using to analyse the signal isn’t long enough to get a precise analysis of a low-frequency signal. So, this is an artefact of the analysis – not an error in the playback system.
What happens if we have random skip/insert events in the system? This is shown in Figure 7.
Fig 7. Intentionally-created skip/insert events seen as artefacts in the frequency domain.
The signal in Figure 7 was one that I created – I intentionally made skip/insert events at random times and applied them to my test signal.
There are two things to notice here. The first is that each event is visible as a vertical “spike” in the plot. This is because a skip/insert event will cause a short, wide-band “burst” that sounds like a click. However, the bandwidth of the click is dependent on when it happens relative to the signal. For example, the skip/insert events in Figure 2 and 4 would not create as much high-frequency energy as the ones in Figure 3 and 5. So, the bigger the effect on the slope of the signal, the more high frequency energy we’ll get in our “click” sound. Since the slope of a signal increases with frequency, then this also means that low-frequency signals will likely produce lower-bandwidth artefacts.
Now let’s look at the results from some real-world devices and systems that are commercially available.
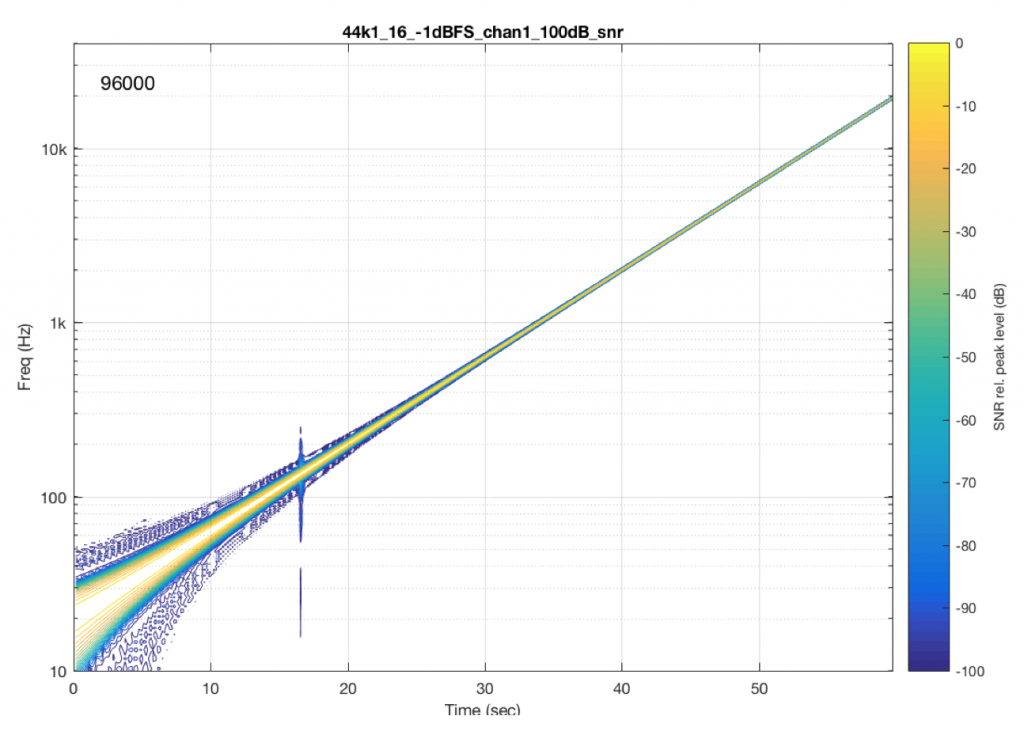
Fig 8. The same test run on a commercially-available system/device. If you’re curious about some of the information listed in the plot, you can decode it as follows: The title “44k1_16_-1dBFS_chan1_100dB_snr” means that the original file I was playing was a 44.1k kHz / 16 bit file. The level of the sinusoidal sweep was -1 dB FS, and TPFD dithered. The analysis we’re looking at here is for channel 1 (the left channel), and we’re looking for artefacts down to 100 dB below the signal level. The “96000” you see on the top left of the plot indicates that the output of the system was captured at a sampling rate of 96 kHz (the internal sampling rate of the sound card that I used to do this measurement).
As you can see in Figure 8, there was one skip/insert event that happened during the 60 seconds I was running this test. Remember that the time that that event happened had nothing to do with the frequency it was playing. It just happens when it happens due to the relationship between the transmitter’s and the receiver’s clock speeds.
Fig 9. Another commercially-available system/device.
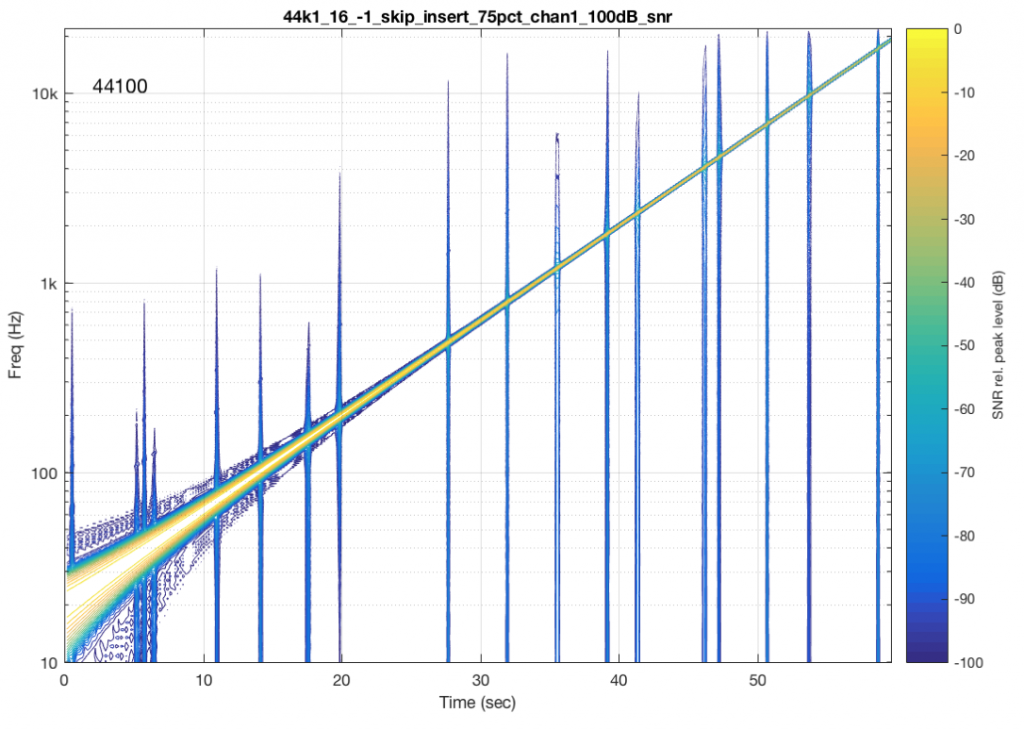
Figure 9 shows the results from a different system/device that obviously uses a skip/insert strategy to deal with clock synchronisation problems. It also obviously has some serious clock issues, since it has to correct on the order of approximately once a second…
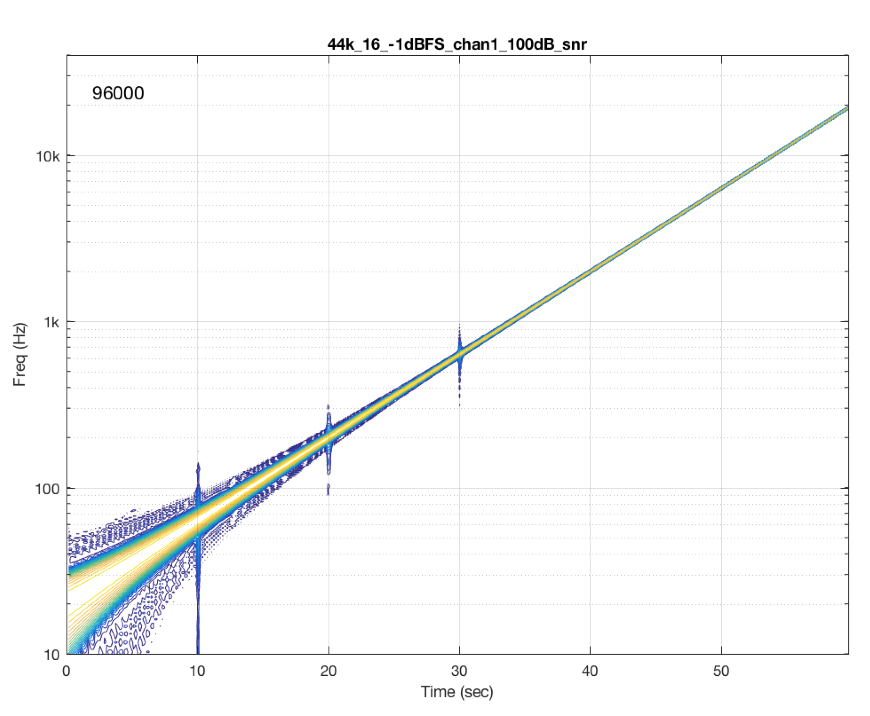
Fig 10. Another commercially-available system/device.
Figure 10 shows the results from a different system/device that uses a skip/insert strategy – but appears to do so at scheduled intervals. In this case, there is a high probability of getting a skip/insert event every 10 seconds with the counter starting at the instant I starting hearing the music.
Addendum 1
Inquisitive readers may be asking why it is that, although I’m doing an analysis down to -101 dB FS (100 dB below the signal level of -1 dB FS), you can’t see the effects of the dither noise floor in my original 16-bit file (which is normally assumed to be at -93 dB FS). This is because the -93 dB FS estimate of a dither signal assumes that you are looking at the total energy from the entire frequency band. The spectrograms above are based on FFT’s that split up the total frequency band into “slices” (called frequency bins) – and the total energy in each of these bins is less than the total energy in all of them (one person clapping is not as loud as 1000 people clapping at the same time…). If we wanted to see the dither noise, I would have had to set my analysis to go down approximately 30 dB lower – but the actual value for this is dependent on the relationship between the sampling rate, the window length of the FFT’s, and the windowing function that I’m using.
Addendum 2
Do not bother contacting me to ask which “commercially-available system/device” I measured and in which I found these errors. I’m not doing this to get anyone in trouble. I’m just doing this to try to illustrate common errors that I see often when I evaluate and test audio devices.
An besides, it would not be fair for me to rat on specific companies, systems, or devices, since, in some cases, these errors may have already been fixed with a firmware update, meaning that “naming names” would be irrelevant and unnecessarily detrimental.
But, I will say that I see this problem often. A rough estimate is that I would see errors like this on roughly half of the commercially-available devices and systems I test. It can also be sneaky, as we saw in Figures 8 and 10. Sometimes you get one of these clicks only once in a minute. So, if you do a 10-second measurement to test if your wireless audio receiver is “bit accurate” – the answer can be “yes” – but if you keep measuring for 1 or 2 minutes, you find out the answer is “no”…
Addendum 3
If it helps, I could have used the example of a leap year instead of two clocks at the beginning. The reason we have a February 29 every 4 years is that our calendar “runs” a little faster than the time it takes us to get around the sun (because a “year” is actually 365.25 days long…). So, every 4 years we have to “insert” a day to put the two clocks back in sync.
Also, since a “year” is not exactly 365.25 days long, we also have the occasional “leap second” as well. But most people don’t notice this, since it’s rarely useful as an excuse when you’ve missed a meeting…
It was the third of June, another sleepy, dusty Delta day I was out choppin’ cotton, and my brother was balin’ hay
I’ve always liked the song “Ode to Billy Joe”. It starts on a 7-chord, so you know it’s going to go somewhere… I love how Papa, when he hears that Billy Joe jumped off the Tallahatchie Bridge just says that he “never had a lick of sense”, and asks for more biscuits. And who, exactly, did Brother Taylor see with Billy Joe? What did they throw off the bridge?
I like the fact that there are many questions and few answers – and life just goes on anyway…
But we’re not here to talk about songwriting, we’re here to talk about typical errors in digital audio – specifically today – streaming services.
This error is an easy one to discuss – but an important one nonetheless…
When I’m sitting at work, typing on my computer, I listen to music a lot. Usually, I use the “Audirvana” software on my Mac, with an external Teac UD-501 USB-Audio headphone DAC (which does the digital-to-analogue conversion and the amplification for the headphones, all in one box). The reasons I choose to use Audirvana are (1) that it can play all of my files (I have some DSD stuff on my hard drive), it can stream directly to my external DAC without routing the audio through Mac’s OS, and it can also see my Tidal account.
Now, just to be clear, this posting is not an advertisement for Apple, Audirvana, Teac, or Tidal. I mention all of that just as background information… I also drive an 11-year old base-model Honda Civic (that will come up later in this posting) and I wear Ecco shoes (which is completely irrelevant…).
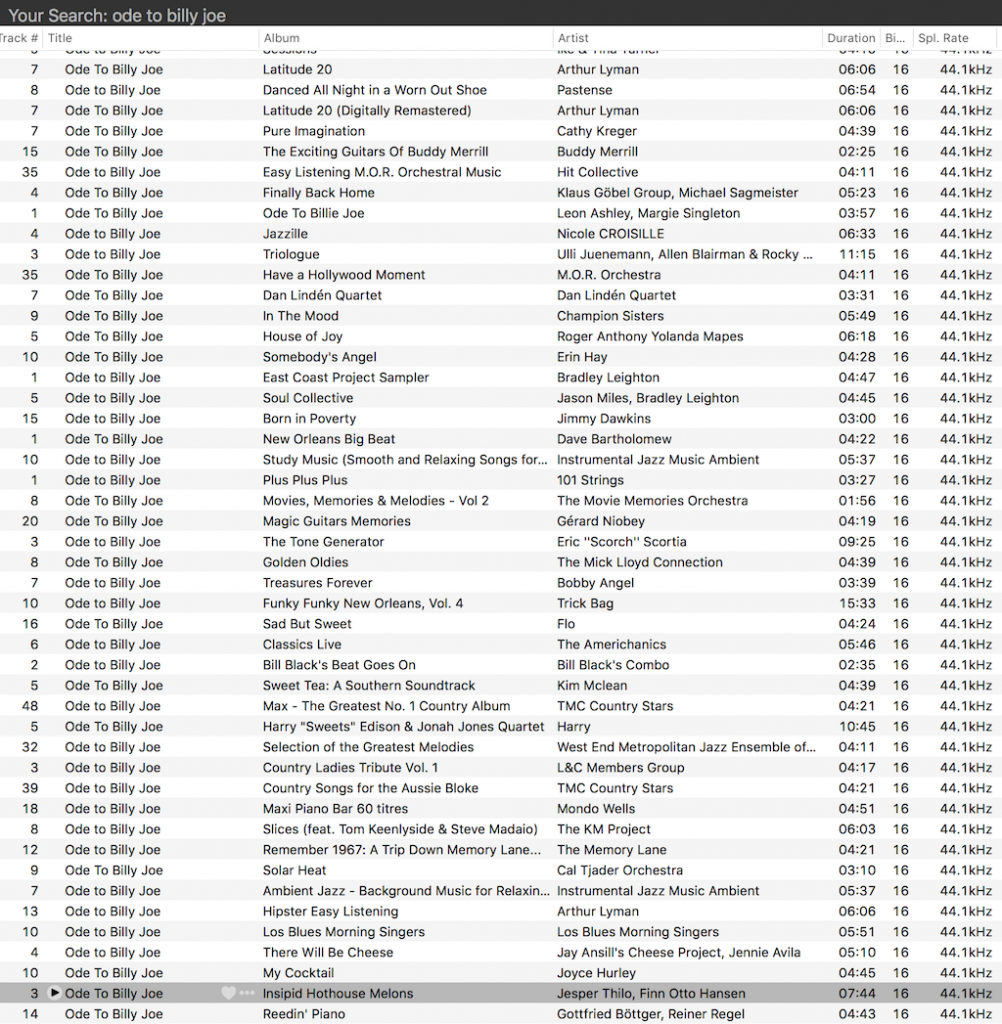
If you use Audirvana to search Tidal for tracks called “Ode to Billy Joe” You will get 300 hits. I don’t know if this is because there are 300 covers of that song on Tidal (I doubt it) or if 300 is a limit on the number of tracks either Tidal or Audirvana will report in a Search function (I suspect that this is the case…)
As you can see in the screenshot in Figure 1, all of them are 16 bit, 44.1 kHz files. So far so good…
Fig 1: There are many “Ode to Billy Joe” covers in Tidal
I have two favourite versions of this song. One of them is by Paula Cole (the other is by Patty Smyth). If I press “play” on the Paul Cole version, and I look at the top of the screen, I see something like the screenshot in Figure 2.
Fig 2: Ode to Billy Joe
One of the nice things about Audirvana is that it tells you a little technical information about the track to which you’re listening. Notice there on the right-hand side of the screenshot above, that we’re listening to a 16-bit, 44.1 kHz FLAC file.
This makes sense. In fact, it’s what I expect, since my Tidal subscription promises “lossless high fidelity sound quality” – that’s why I pay extra for a Tidal HiFi subscription…
So far so good.
One of my less-favourite renditions of “Ode to Billy Joe” is performed by The Stadium Saxophone Players on their album “Timeless Sax Instrumentals – Volume 2”. IF I press play on this version, and look at the top of my Audirvana window, I see the information in Figure 3.
Fig 3: Ode to Billy Joe
Interesting…. Notice that I am now listening to a 96 kbps AAC file with a 16-bit word length, and a sampling rate of “22.1 kHz” (actually 22.05 kHz – half of 44.1). So much for “lossless high fidelity sound quality”.
This calls for more investigation.
So, I pressed “Play” on the top hits in my search, one by one, and checked the file format displayed on the screen. The results of this “test” was that, in the first 66 “Ode to Billy Joe’s” listed, 6 of them were 96 kbps AAC files, 60 of them were FLAC.
So, for this sampling, roughly 9% of the available tracks were not in a lossless format, and were not even full bandwidth. Admittedly, the tracks that were in the lower-quality format were versions that I would not listen to anyway – so, to be honest, I don’t really care too much.
Now, before you mis-interpret me, I want to be very explicit and state that this is NOT Tidal’s fault. Of course they did not ask for an AAC version of the file they put on their hard drives. This was the file format supplied to them by the record label (to use an increasingly old-fashioned term…). So, we can’t blame Tidal for this – and I’m quite certain that they’re not the only streaming service that “suffers” from this issue.
However, what my little test shows is that what Tidal is actually selling me is the capability of streaming “lossless high fidelity sound quality” – and not a guarantee that what is in the “pipe” really is lossless.
Of course, this is not just true for streaming services. Other people have shown that some higher-priced “high resolution” audio files that you can purchase online are actually just a bit-for-bit copy of the “normal resolution” version of the same track. I have at least one CD that contains at least one track that has MP3 artefacts obvious enough that I can hear them on my unbranded audio system in my 11-year old Honda Civic while I’m driving… (It’s a compilation disc, so I guess the label was supplied with an MP3 version that they decoded to PCM and put on the CD.)
So, just like Ode to Billy Joe – there are some questions here… and you don’t need to know much about digital audio to answer them… But the basic moral of this part of the story is that the format that is used to deliver your music is not a guarantee of higher quality…
One thing that annoys me (okay, okay… one of the many things) is when people confuse “acoustic” with “acoustical”. These are not interchangeable – in the same way that “electric” is not the same as “electrical”.
An electric engineer is an engineer that runs on electricity (in other words, a robot) – in the same way that an electric train is a train that runs on electricity.
An electrical engineer is an engineer that works on things that involve electricity. For example, this is a person (who runs on food) who looks at wiring diagrams.
A person who develops loudspeakers or designs concert halls is an acoustical engineer. This is a person (who also runs on food) and works on projects involving sound and acoustics.
An acoustic engineer is an engineer that makes funny noises when struck – which is something different.
Then again, I guess if you hit any acoustical engineer hard enough, you would make that person an acoustic acoustical engineer.
“Learnings” is not a real word. Please stop using it. It is the plural form of the imaginary noun “learning” which is also not a real word.
If we continue to use this, then we’re on a slippery slope to sentences like “The researches resulting in a lot of learnings that increased our knowledges with many informations.”
Don’t get me wrong, I’m all for the evolution of language. I understand what people mean when they say “peruse”, even when they don’t know what they are actually saying… I don’t complain when people ask for “less things” instead of “fewer things”. Although I admit that I cringe a little when people use “super-” in front of words like “exciting” instead of words like “man” and “duper”.
If you don’t own a 2011-model Apple MacBook Pro with a problem with it’s discrete GPU, then you should probably stop reading right now and go look at a video on wimp.com instead. This one is pretty funny.
The backstory
I confess. I’m a Macintosh person. In fact, I’m one of those annoying Mac people who makes fun of people who own Windows machines. I’ve been a Mac person since about 1990 when I bought my first computer – a Mac Classic. In those days, if you used a computer for MIDI, you had to get a Mac because Windows machines never really knew what time it was. Not precisely or accurately enough to be used to play a MIDI file. And, once audio editing came along (not ProTools – the GOOD stuff, like Sonic Solutions) it was Macintosh or nothing because Windows people would look at you funnily when you talked about SCSI drives.
Last week, though, my evangelism came to a crashing halt when my trusty 2-year old MacBook Pro suddenly went bezerk. It started with my son booting up Minecraft, which tried to change the screen resolution. The result was a large black vertical stripe down the middle of the screen with the left side of the desktop on the right side of the screen, wrapping around to the left side. “Dad, there’s something wrong with the computer…” he said. “No problem” I said, “let’s just reboot it.”
Rebooted the computer, got the pretty grey Apple logo, then just a blank grey screen. Tried again, same result, Tried again, same result… Uh oh… It’s only been a couple of weeks since the last backup, so I haven’t lost too much data – but the time it’s going to take to get up and running again… Guh.
So, I started Googling for some solutions about what to do with a stuck grey screen. Apple has a friendly page about this – try this, try that… If that doesn’t work, try something else. If that doesn’t work, you probably have to reformat your drive. Guh.
Turns out that my hard drive is fine. My data is all intact. What is NOT fine is my discrete Graphic Processor Unit or GPU. Apparently, MacBook Pro’s made in 2011 (mine is a late-2011 model) are dropping like flies. And, interestingly, the whole mess was sort of predicted by this site when they did a tear-down of the computer back when it first came out. As they said back then, in talking about the GPU: “Holy thermal paste! Time will tell if the gobs of thermal paste applied to the CPU and GPU will cause overheating issues down the road.” and “Absurd amounts of pre-applied thermal paste may cause problems down the road.”
Okay, so the MBP’s from 2011 have a problem. This is forgivable – even engineers make mistakes sometimes. Manufacturing or design defects are not surprising in this day and age. However, what astounds me is that Apple is completely denying that this issue exists.The stories being told tell tales of people forking out over $300 to get a logic board replacement, only to have it fail within a couple of months. Another $300 logic board, also fails… Apparently, Apple is replacing faulty logic boards with “refurbished” boards that have exactly the same problem as the one getting taken out of the machine. So it seems that there is a large circulation of faulty circuit boards getting put into machines at $300 a pop. This means that I won’t be sending my computer off to get a “new” logic board any time soon.
Solution #1
Other people tell epic tales of a great little utility called gfxCardStatus which allows you to force the computer into using either the discrete GPU or the integrated GPU.
So, following some interactions on the Interweb, I tried rebooting my computer over and over and over and over (say, about 50 times, but it felt like a million…) until it worked! installed gfxCardStatus and locked it into the integrated GPU. Life was great. A little slow, but great. At least my computer was up and running again. Long enough to do a backup of EVERYTHING – just in case.
Sadly, the party didn’t last long. 4 days later, the machine crashed. 50 reboots later, it was running again – this time for only 3 days. And when it crashed that time, things got worse. The machine did a complete shutdown, and restarting resulted in another complete shutdown immediately after seeing a stripy grey Apple sign.
Solution #2
So, I went to plan #2 – trying to disable the discrete GPU permanently by moving the .kext, .plugin and .bundle files for the GPU. I did this following the instructions at this page – which I’ve repeated below. If you’re reading this because you have the same problem as I do, and you try this, don’t hold me responsible if you break your Mac using this technique. It was a last-ditch attempt for me to revive my machine – and so far so good…
Start up in Single User Mode (hold down CMD-S immediately after startup)
Get ready to move System files by typing the text mount -uw /
Create a directory to move the Extension files into by typing mkdir /System/Library/DisabledExtensions
Move the files by typing mv /System/Library/Extensions/ATI* /System/Library/DisabledExtensions
Type exit
You might need to type exit again to reboot.
This still required that I do a hard shutdown (holding the power button for 5 seconds) and restart 4 or 5 times – but here I am, once again, typing on my computer that, yesterday, was a brick. Let’s hope that this solution sticks.
However, what would be REALLY nice is if Apple were to own up to this one, and call up all those people like me who own a defective machine, and tell us that they’re going to fix it for free. Or at least fix it for a reasonable cost with a solution that actually works. Either way, I might regain a little faith in a company that I used to trust.
A little more information, in case you’re reading this because you have a similar problem: I have a 15″ late-2011 MacBook Pro with an AMD Radeon HD 6750M discrete GPU. I haven’t done anything to it (like replace the HD or add extra RAM).
Before I start my little rant, let’s do some basic grade-school geometry.
The area of a rectangle is equal to its length multiplied by its width. For example, if you have rectangle with sides of lengths 2 cm and 4 cm, then its area is 8 square centimeters (2 * 4 = 8). This means that if you have a square, then its area is the length of its side squared. For example, if you have a square with sides of a length 3 m, then its area is 9 square metres (3 * 3 = 3^2 = 9). In other words, for rectangles, A = L * W where A is Area, L is Length and W is Width. The only thing that makes a square special is that L = W.
The area of a circle is equal to π multiplied by its radius (the distance from the centre of the circle to its edge) squared. In other words, A = π * r^2 (say “pie are squared”) where A is area, π is roughly equal to 3.14 and r is the radius. So, if you have a circle with a radius of 4 mm then its area is approximately 28.27 square millimeters.
In the case of the square and the circle, if you double the width (or diameter, or radius), you quadruple the area. If you increase the width by a factor of 3, you increase the area by a factor of 9 (3 x 3). Stated generally, the area is proportional to the square of the width.
Representing your data with a bar graph
Now, let’s pretend that we have some data to show to people. We’ll start with something simple – we’ll display the total annual sales of widgets over 3 years. Let’s say that, in the first year, you sold 10 widgets; 20 widgets the second year and 30 widgets the third year. Your competitor, by comparison, only sold 10 widgets in each of the three years.
How do we plot these data? Of course, there are lots of ways, but one way that makes sense is to use a bar graph. A bar graph shows a single bar for each value (in our case, widget sales in each year), side by side, where all of the bars have the same width. The value is represented by the height of the bar. An example of a bar graph of our widget sales is shown below.
For the purposes of my little rant, there’s something important in that last paragraph. I said that the height of the bars shows the data, but the width of all of the bars are the same. This means that the data are not only shown by the heights of the bars, but also their areas.
Mis-representing your data with a weird bar graph
What if we were to get creative and say that the data are not only represented by the height of the bars, but also their widths? On the one hand, you could make the argument that this is fair, since you could look at either the relative heights OR the widths to see the data comparions. However, if you take a look at the example shown below where I’ve plotted such a graph, you’ll see that this might not be a fair representation. Why not? Well, if your eyes are like my eyes, you don’t see the heights of the bars, you see the areas of the bars. And, since I’ve doubled the height and the width of the bar with double the value, the area is 4 times. In other words, I’m exaggerating the difference in the values by doing this (to be precise, I’m squaring the difference).
But I hear you cry, “Of course no one would ever do this! I’ve never see such a plot! Or, at least, I can’t make one in Excel…(although I can in Tableau…)” Read on!
Getting to the point… bit by bit
Let’s say that we did some kind of test where we want to represent a bunch of data points for various categories. For example, a listening test comparing four loudspeakers, where each loudspeaker was rated on 15 attributes. We’ll assume for the purposes of this discussion that the test was designed and conducted correctly, and that we can trust the data. We’ll also assume that the test subjects that produced the data (our listening panel) are experts and can rate things perfectly linearly. In other words, for a given attribute, if the listening panel says that one loudspeaker gets a score of 30 and the other one gets a score of 60, then the second one is twice as good as the former. We’ll also say that, for the purposes of this test, each attribute was scored on a range from 0 to 100. Finally, we’ll assume (for the purposes of keeping this discussion clear) that a higher score for any attribute means “better”.
So, we did our test and we got some strange results. (Note that these data are not from a real listening test. I made up everything to illustrate my point.) One loudspeaker got a score of 100 (out of 100) on every attribute. Another loudspeaker got a score of 50 on every attribute. The other two loudspeakers were a little more realistic (but still faked, don’t forget…)
So, as you can see in the above bar graph, one loudspeaker got a score that was only half as good as the other in all categories. This is easily seen in the bar graph. If you squint just right, you can also imagine two rectangles, one big black one and one big red one. Since those two rectangles have the same width, their areas also represent the data accurately.
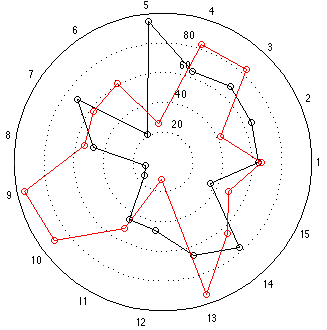
But, what would happen if we plotted exactly the same data using a spider plot? That would look like the figure below.
Notice that the same data is plotted as before, but the message your eyes see is slightly different. You see the black circle and how it compares to the red circle. Since the red circle has twice the radius of the black circle, it has four times the area. If you’re like me, you see the comparison of the areas of the circles – not their radii. So, if you don’t force your brain to do a little sqare-rooting on the fly, the plot appears to say that the second loudspeaker is four times better overall, which is not what the data says. This is basically where I’m headed…
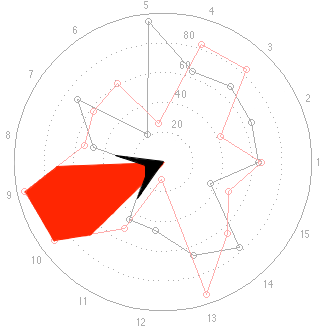
Now let’s look at the “results” for the other two loudspeakers, whose data was a little more varied. These are displayed in the bar graph and spider plots below.
This time, at first glance, things look a little more “normal” but look carefully, particularly at the results for categories 9 and 10. The same problem (of a spider plot showing the square of the results) happens again here. The big area between the red points and the black points for 9 and 10 exaggerates the difference in the actual data, which are better displayed in the bar graph. One way to think of this is that the “slice of the pie” gets bigger in area as you go further out from the centre of the circle. The figure below shows the way my brain interprets the plot.
Of course, if the data were for the same for all attributes for both speakers except for one attribute where one loudspeaker got a score of 100 and the other got a 50 (so you would just see a spike at one angle on the plot), then the spider plot would come very close to representing the data correctly. But this is because, with those weird collection of numbers, you come close to eliminating area in the plot – and it just becomes what most people call a “compass plot” which is something different.
The conclusion
As the title says, my conclusion is that a spider plot mis-represents differences in data because they show us something that it more like the square of the difference rather than the difference itself. To be fair, its representation approaches the square of the difference as all of the values for a given product become more equal (as I showed in the first spider plot with the two circles, above).
Personally, I prefer to have graphs that show me the results – not a weird scaling of the results – which is why I hate looking at spider plots.
Mostly, however, it’s because I’m too lazy to do square roots in my head.