Inspired by a conversation with Jamie Angus following my last posting, I did some digging into the probability density functions (PDF’s) of a bunch of test tracks that I use for tuning and testing loudspeakers.
The plots below are the results of this analysis.
Some explanations, to start…
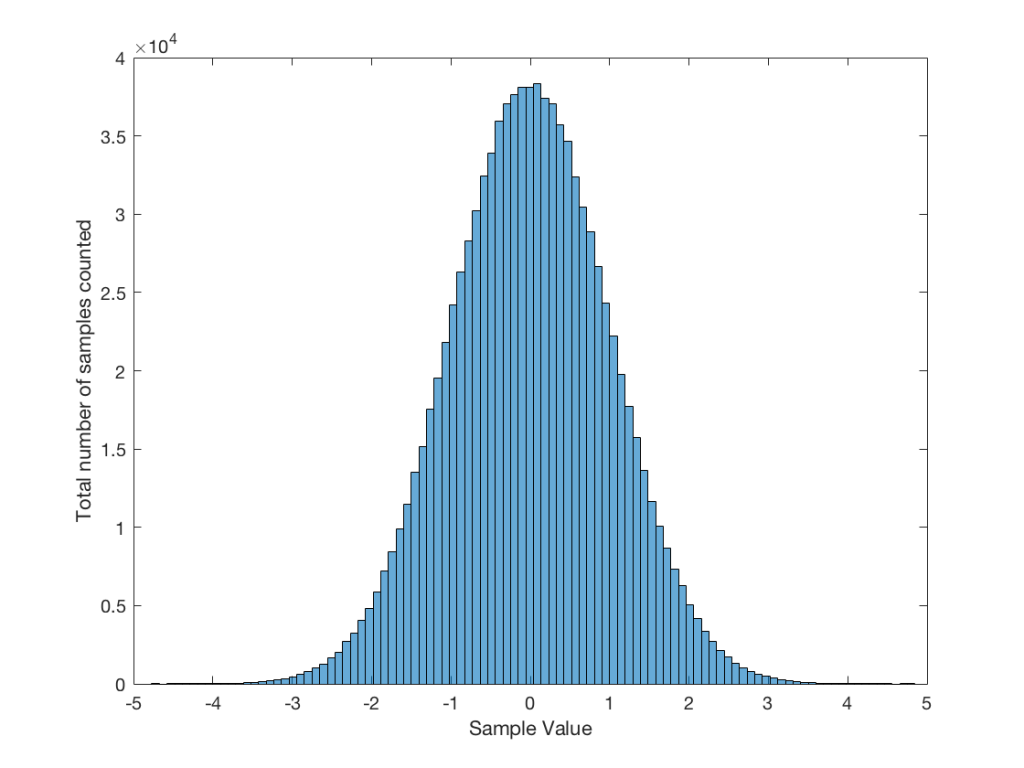
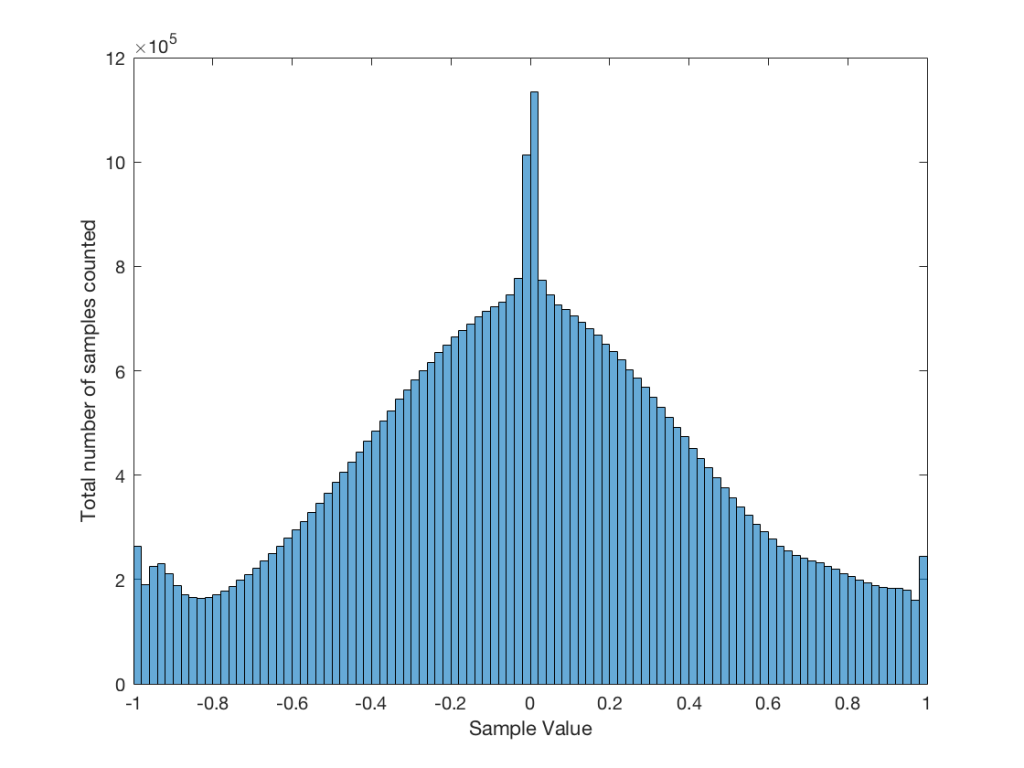
A PDF of an audio signal is a measurement of the probability that a given level (or sample value) will happen in a given period of time. In the case of the plots below, I just counted each time every sample value the 16-bit range of possibilities (from -32768 to 32767, if you think in binary – from -1 to +1-2^-15 in steps of 2^-15 if you prefer to think in floating point decimal) occurred in an entire track (usually the full tune). That’s plotted below as the gray “curve” in a linear world.
I converted the linear levels to “instantaneous” (sample-by-sample) dB values (since they’re instantaneous, they’re not in dB FS – but let’s not get into that discussion), but kept the positive and negative polarities of the linear values separate. Those are plotted as the red (negative values, expressed in dB) and black (positive values, expressed in dB). I cheated a little here, since a linear value of “0” isn’t really -96 dB – it’s -infinity dB… but, except for that one value, everything else is plotted correctly.
When I did these analyses, I noticed lots of sample values in lots of tracks that had no probability of ever occurring. Sometimes, this is just because the track is mastered low in level – so the “upper” sample values are not used. Sometimes, there are “dead values” well inside the range. This likely points to an error in the converter and/or digital mixing and/or mastering equipment.
Finally, I made a plot of the number of “dead” sample values per 128 sample values in 512 blocks (65536/128 = 512). That’s the red line above the gray one.
Some other things are noticeable in the plots, but we’ll take those as they come, below…
Note that I will not reveal the names of the tracks I used, since it’s not my purpose here to make anyone look bad. It’s to look at the differences between different recordings, types, and even equipment… Don’t ask which recordings I used.

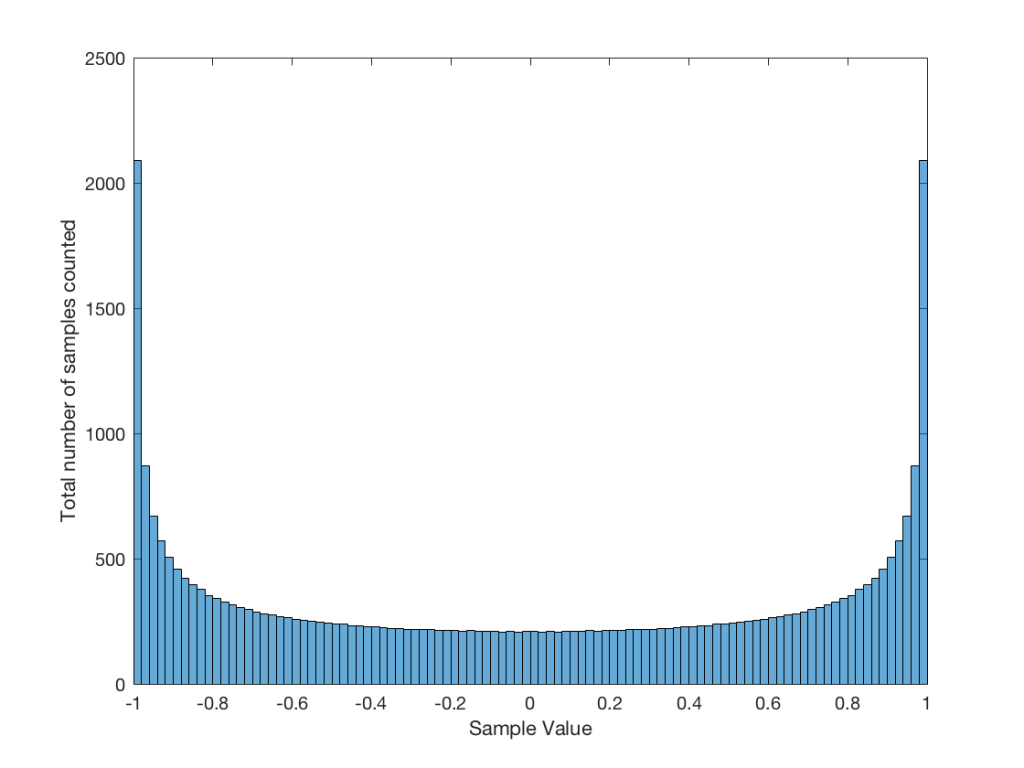
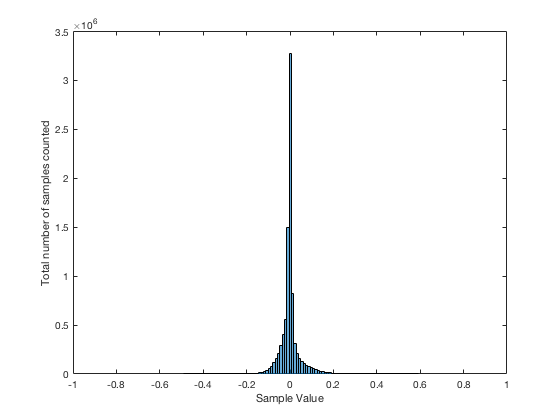
This plot of an orchestral recording (“orchestral8”) looks fairly normal. As Jamie pointed out in the last posting, the distribution looks to be Laplacian. There is a big spike at the “0” mark – due to the silence at the beginning and end of the track. As can be seen, the track peaks around a linear value of about +/- 0.2 or about -14 dB below full scale. So, the sample values above 0.2 (or below -0.2) are unused. This can be seen in the blue lines (comprised of a blue dot at each sample value) in the top plot, and the red line at 128 (the number of “dead values” per 128 possible values) in the bottom plot.

The “solo inst3” is very similar in behaviour, even though it’s a completely different recording. This one is of a solo stringed instrument in a fairly reverberant space. Notice that its basic characteristics are very similar to those shown in “orchestra8”.

The “voice3” recording is also similar. It’s a little interesting in all three of these recordings to note the transition between levels where there are no dead sample values (around the “0” line) and levels where there are nothing but dead values. In this area (in the “voice3” recording, for example, around +/- 0.3, there are sample values that are used – but others that are skipped. This is because the track has a reasonably large crest factor (the ratio between the peak and the RMS of the track) – in other words, it has noticeable peaks. When the levels peak positively or negatively, there will be some values skipped along the way…
Although these are very different recordings of different instruments in different spaces on different labels – they all appear to have some characteristics in common.
- They very likely had little or no compression applied
- They don’t use the entire dynamic range available. This is not necessarily a bad thing, since it could be that each of those tracks was part of a larger collection, and its level made sense in the context of the entire album.
Now let’s look at another acoustic recording that was done with four microphones, and no compression – but possibly some small processing done in the mastering.

Obviously the “orchestra6” recording has something strange going on. It almost looks as though something in the recording chain “favoured” every second sample value – hence the zig-zag pattern in the probability density function. Note that this was not a small thing – the difference in how much the sample values are “preferred” is by a factor of 10.
What could cause this? This is difficult to say by just looking at this plot, since we have to remember that these values are complied using the entire track. So, for example, three possibilities that come immediately to mind are:
- for some strange reason, the analogue-to-digital converter, or one of the DSP blocks in the mastering console “liked” every second sample value 10 times more than the others
- for some other strange reason, the original ADC only used every second sample value – and one 10th of the track was edited together (or “spliced”) from a different take that needed extra gain.
- something else
To be honest, I think that the first or third of these is more likely than the second – but either way, it certainly looks weird…

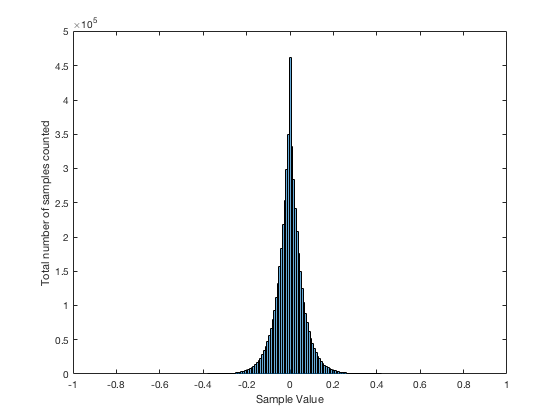
This track of another solo instrument (hence “solo inst1”) is a little different – but not terribly so. There is a little flatter behaviour in the upper plot, which corresponds to a more convex “umbrella” shape in the lower one – but generally, this is nothing serious to raise any eyebrows in my opinion… It probably indicates some minor compression.
Let’s look at some other tracks with compression…


“testtracks4” and “pop21” both have indications of compression in the flat response of the top plots and the convex shape of the lower ones. The “pop21” track has the added indication of clipping – the spikes on the sides of the plots. This indicates that we have an unusual number of samples with values of either -1 or +1. Note, however, that we do not move smoothly into that clipping – it was what we call “hard clipping”, since the values just before the +/- 1 values show no indication of a smooth transition to the spike.

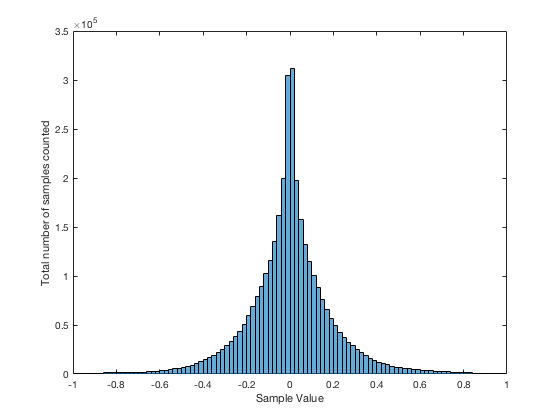
The “bass20” track is interesting, not only because of the compression, but the apparent lack of silence (notice there is no spike around the “0” line). This is because this track is from a live album that is intended for gapless playback – and I just grabbed the track. So, it starts and stops with a hard transition to and from audience sound – there is no fade in or fade out.

The “bass2” track also has the spikes on the ends, showing the clipping – but, as you can see, the plots (particularly the linear plot on the bottom) starts to slope upwards just before the spike – indicating some kind of soft clipping or a peak limiting function was used to shape the envelope.

The “bass15” track is interesting, since it has the characteristic spikes on the sides that look a little like clipping (especially if you only look at the upper plot) but, as can be seen in the bottom plot, these are not at values of -1 or +1. So, this would indicate either that something else in the recording chain clipped – and then was smoothed out and reduced in level a little later in the process – or we’re looking at some kind of interesting soft-clipping processor that keeps a little “bump” in the envelope of the signal above the “clipping” area.
Now let’s look at some really strange ones…

I have no explanation for the plot in “testtracks6”. I can’t understand what would cause that bump only in the negative portion of the signal around -70 dB FS. My guess is that this is some sort of weird watermark that is inserted – but this is really stretching my imagination… Of course, if could just be that something in the processing chain is just broken… Anyone reading this have any good ideas? Seems to me that I should do a little more digging into this track to see what’s going on around those sample values…

The “pop11” track is an example of a recording that was probably done on early digital recording gear – or an early digital mastering console. As can be seen in both plots, there are missing sample values across the entire range of possible values.
One possible explanation of this is that this is a digital recording that had gain applied to it using a processor that did not use dither. This would cause the signal to not use every second sample value (or every third or fourth – depending on the gain applied). It’s also possible that it was processed or recorded using a device that had a “stuck bit”. I’ll do some simulations to show what that would look like and publish the plots in a future posting.
Note that the small “spikes” of peak limiting (looking a little like clipping on a small scale) are visible in the bottom plot – but they’re very small…
Some more recordings with strangely dead sample values are shown below. Note that some of these are very recent recordings – so the “early digital gear” excuse doesn’t hold up for all of them…




So, something is obviously broken in all four of these examples… Please don’t ask me how to explain them. The only thing I can do is to suspect that at least one piece of gear and/or software that was used in the late stages of the process was really broken… I just hope that, whatever gear/software it was, it didn’t cost a lot of money….
An interesting pair of examples are shown below…


The “jazz1” and “jazz2” recordings both come from the same album released by a small jazz ensemble. Notice that, although they are different tracks, they have similar PDF’s, seen in the “spikes” through the upper plots. It seems that there is something weird going on in the mastering console (or software) in this case – or perhaps the final mixing console…

The “speech4” track has obvious “favouring” of alternate sample values – but this was a track that was recorded on a very early DAT machine about 35 years ago… To be honest, knowing what I know about using an identical model DAT recorded, I’m surprised this looks as good as it does…
I’ll just put in a bunch more plots without comment – just to let you see some of the variety that shows up with this kind of analysis.

















Post-script
This posting has a Part 2 that you’ll find here, and a Part 3 that you’ll find here.