#72 in a series of articles about the technology behind Bang & Olufsen loudspeakers
After a previous posting, someone posted this as part of a comment:
“What I’ve been asking myself for a long time: how does a single driver manage to produce two or more frequencies (or a frequency range) at the exact same time? For example a singer singing while the guitar plays in the background. Could you try to explain how this works?”
So, this posting is an attempt to answer that question.
Sound is a change of air pressure over time. That pressure is modulating on top of the day’s average barometric pressure – which is just a measurement of how closely the air particles around you are squeezed together. On a high-pressure day, the air is more densely packed – on a low pressure day, the air is less dense.
When you make a sound, you make slight variations in that pressure – so, for example, when a woofer moves out of a loudspeaker enclosure (a fancy name for “box”) then it pushes the air particles in front of it, and they’re squeezed together, resulting in a compression wave that radiates away from the loudspeaker. When the woofer pulls into the enclosure, it pulls the air particles apart, and you get a rarefaction wave instead. (You can see an animation of this at this posting.)
Let’s make a graph that shows a plot of the acoustic pressure changing over time. This is shown below in Figure 1. When this plot shows a positive number, it means that the air particles are being compressed more than normal. When it’s negative, then they’re being separated more than normal. Without getting into too many details, let’s just say that this is a low frequency. (If you want to get picky, then you’ll see that this is one cycle of a wave that takes 100 ms. Since there are 1000 ms in a second, then this must be a 10 Hertz signal, because 1000 / 100 = 10. That makes it a VERY low frequency by normal audio standards… )
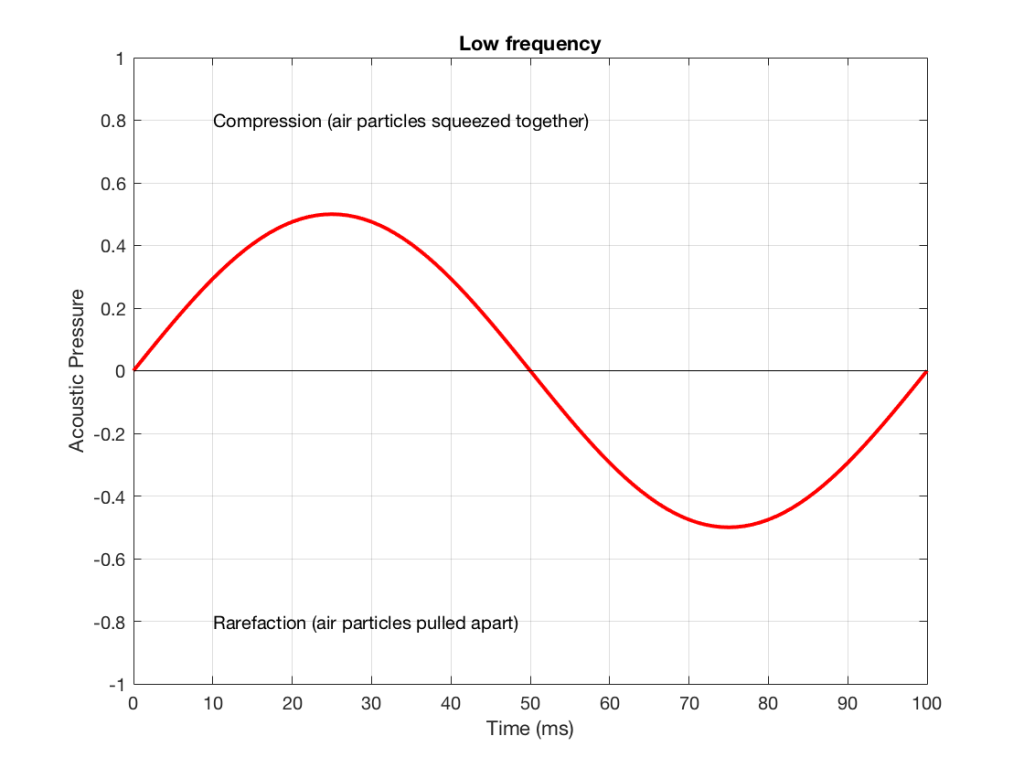
Let’s also look at an example of a higher frequency, shown in Figure 2, below.
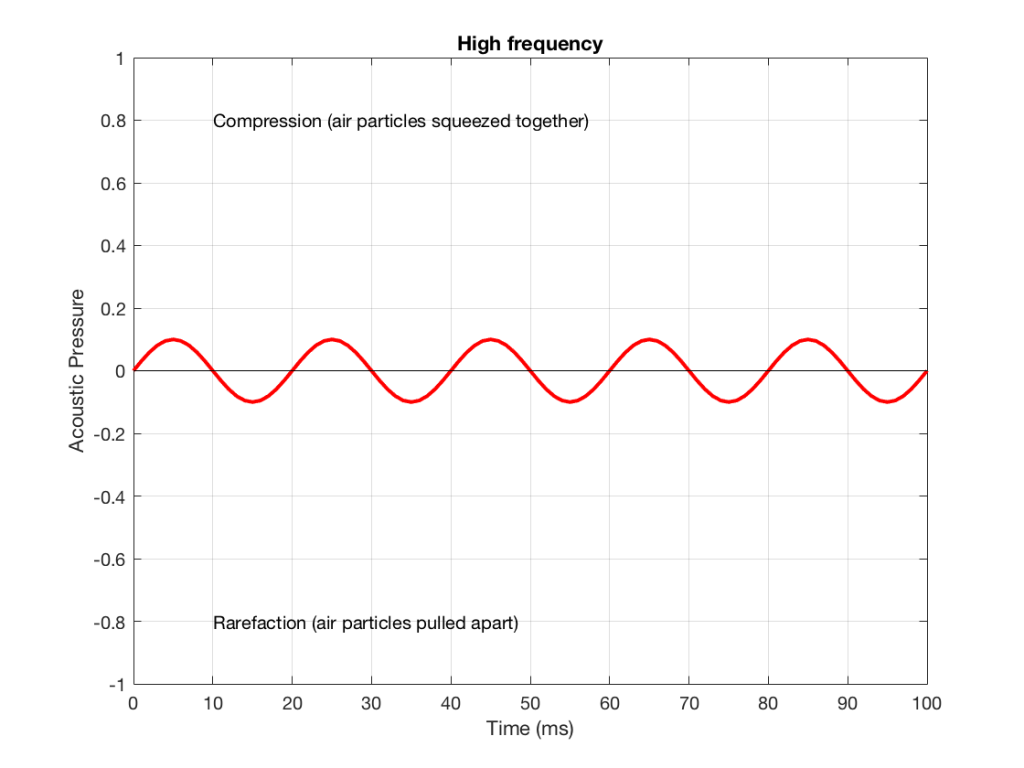
We can see that Figure 2 has a higher frequency signal, because it moves up and down more frequently. It has 5 cycles (5 ‘ups’ and ‘downs’) in the same amount of time that it took the wave in Figure 1 to have 1 cycle – therefore it is 5 times the frequency (and therefore, if you’re being picky, 50 Hz – which, by audio standards, is also a very low frequency, but this is just an example…)
Ignoring that ACTUAL frequencies that are plotted there, let’s pretend for a moment that the low frequency (Figure 1) came from a bass guitar and the higher frequency (Figure 2) came from a singer. If we took those two signals and put them into a mixing console, what does the result look like?
Well, we take the instantaneous value of the signal at one moment in time and add it to the instantaneous value of the other signal at the same time. Let’s do that.
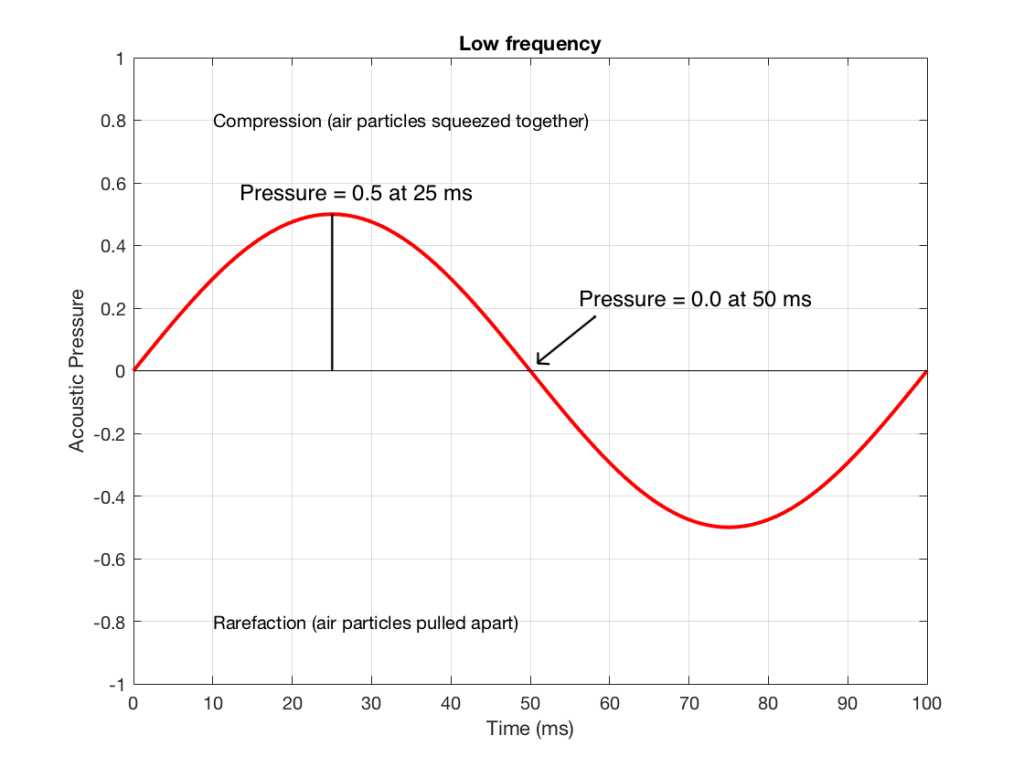
Figure 3 shows the same signal as in Figure 1, but I’ve pointed out the values at two moments in time – at 25 ms and at 50 ms. So, for example, you can see there that, at 25 ms, the value is 0.5 – whatever that means…
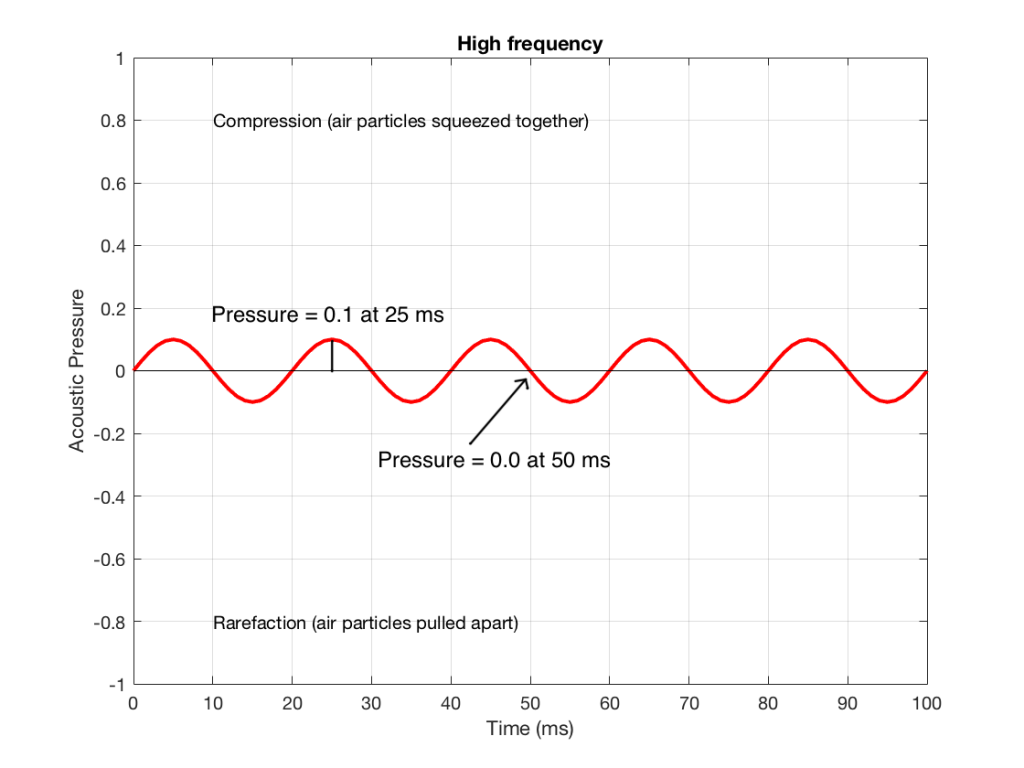
Figure 4 shows the same signal as in Figure 2, but I’ve pointed out the values at two same moments in time – at 25 ms and at 50 ms. So, for example, you can see there that, at 25 ms, the value is 0.1 – whatever that means.
We take the value at 25 ms from each of the two signals (0.5 and 0.1) and add them together to get 0.6. This is the value of the signal at the output of the mixer at 25 ms. At 50 ms, the mixer’s output will have a value of 0 (because 0+0 = 0). This is shown graphically below for all of the values of both plots from 0 ms to 100 ms.
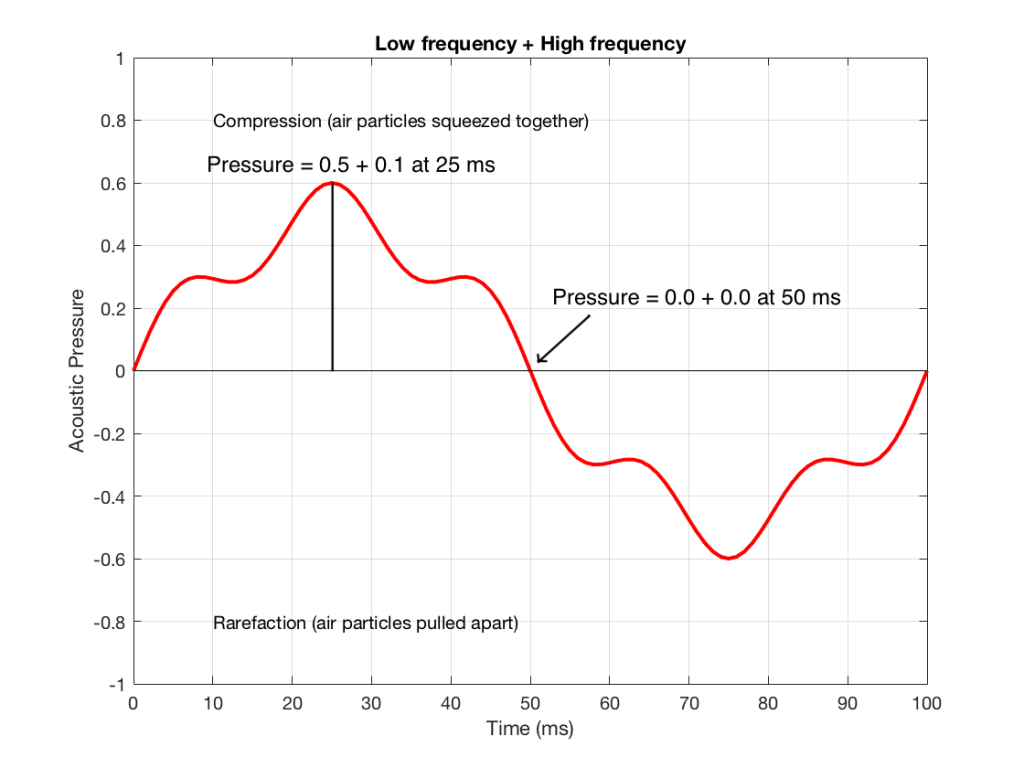
So, you can see in Figure 5 what the result will be. This signal contains both the low frequency, shown in Figure 1 and the higher frequency shown in Figure 2. If we send this combined signal to a loudspeaker, then both signals will get reproduced.
One interesting thing to note is that this mixing can also be done in the air. If a bass guitar and a singer are performing a song together, live, then the bass is pushing and pulling the molecules at the same time that the singer’s voice does. So, if at 25 ms, the bass pushes the molecules with a value of 0.5 (whatever that means) and the singer pushes the molecules with a value of 0.1, then your eardrum will be pushed in with a value of 0.6. So, the summation of the pressure signals happens in the air, just like it does as voltages or voltage measurements in the mixing console.
Typically, however, a loudspeaker is comprised of more than one driver – for example, a woofer (for the low frequencies) and a tweeter (for the high frequencies). (Of course, some loudspeakers have more than two drivers, but we’re keeping things simple today…)
So, what we do there is to put the total signal, shown in Figure 5, and send it to two circuits that change how loud things are, depending on their frequency. One circuit is called a “low pass filter” because it allows low frequencies to pass through it unchanged, but it reduces the level of higher frequencies. The other circuit is called a “high pass filter” because it allows the high frequencies to pass through it unchanged, but it reduces the level of the lower frequencies. (we won’t talk about how those circuits do that in this posting…)
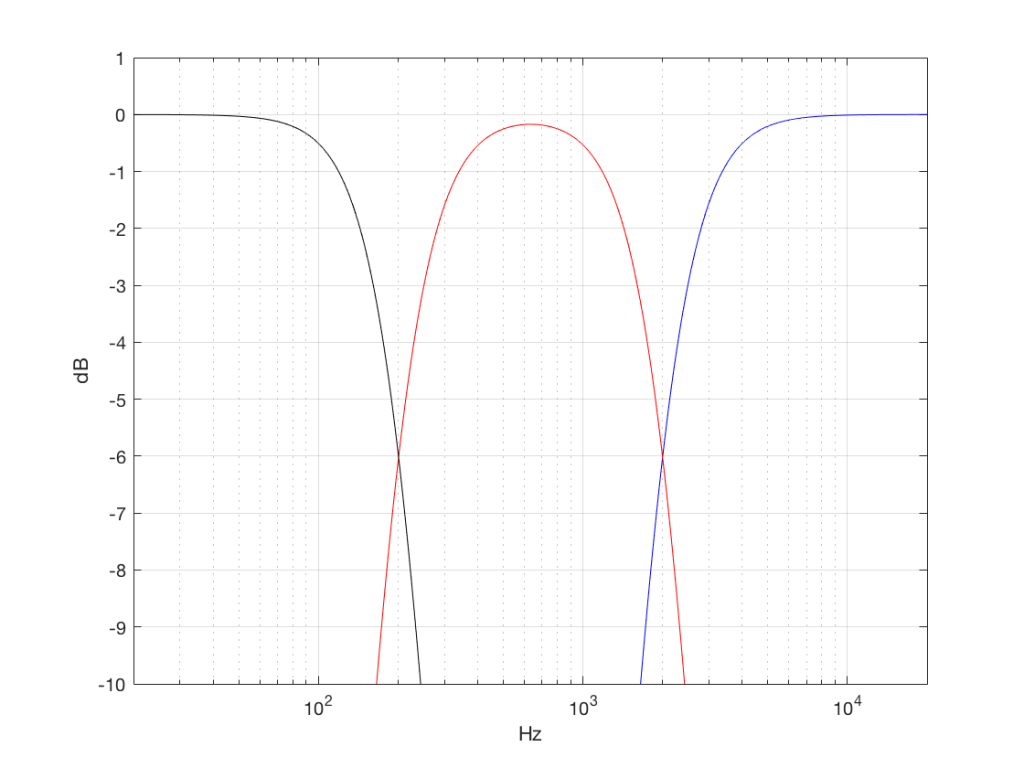
We can plot the two characteristics of these two circuits – an example of which is shown in Figure 6.
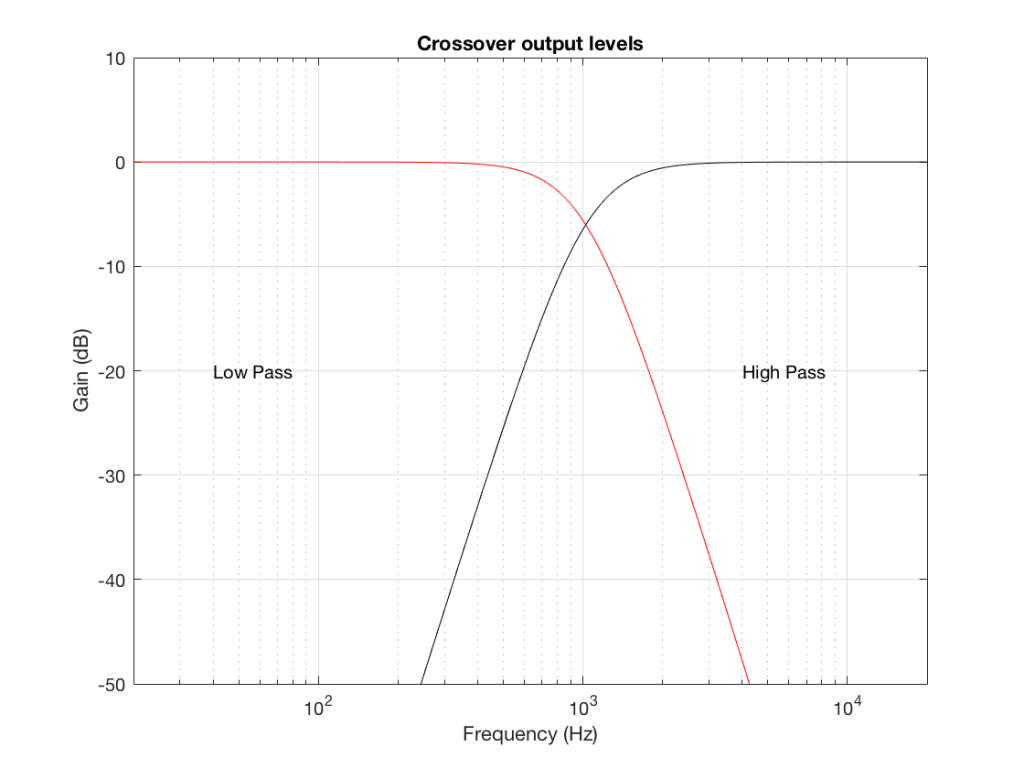
IF we send a signal like the one in Figure 5 to a crossover that happens to have a crossover frequency that is between the two frequencies it contains, then the signal will be split into two – one output containing mostly low-frequency components, and the other one containing mostly high-frequency components. Examples of these are shown below.
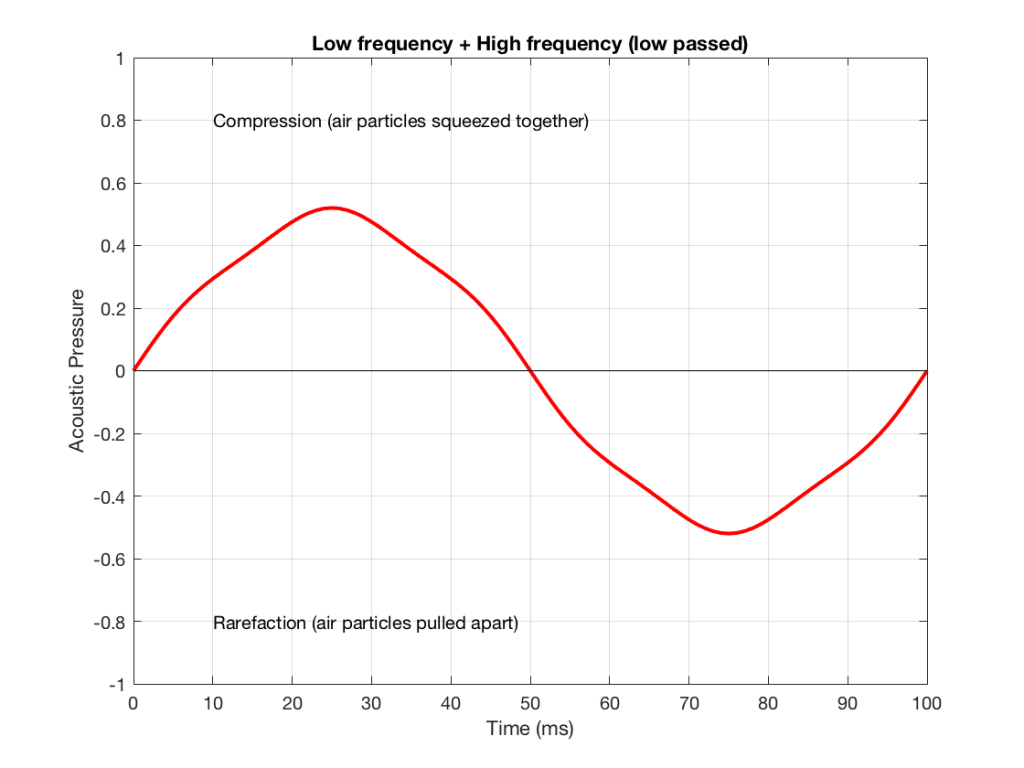
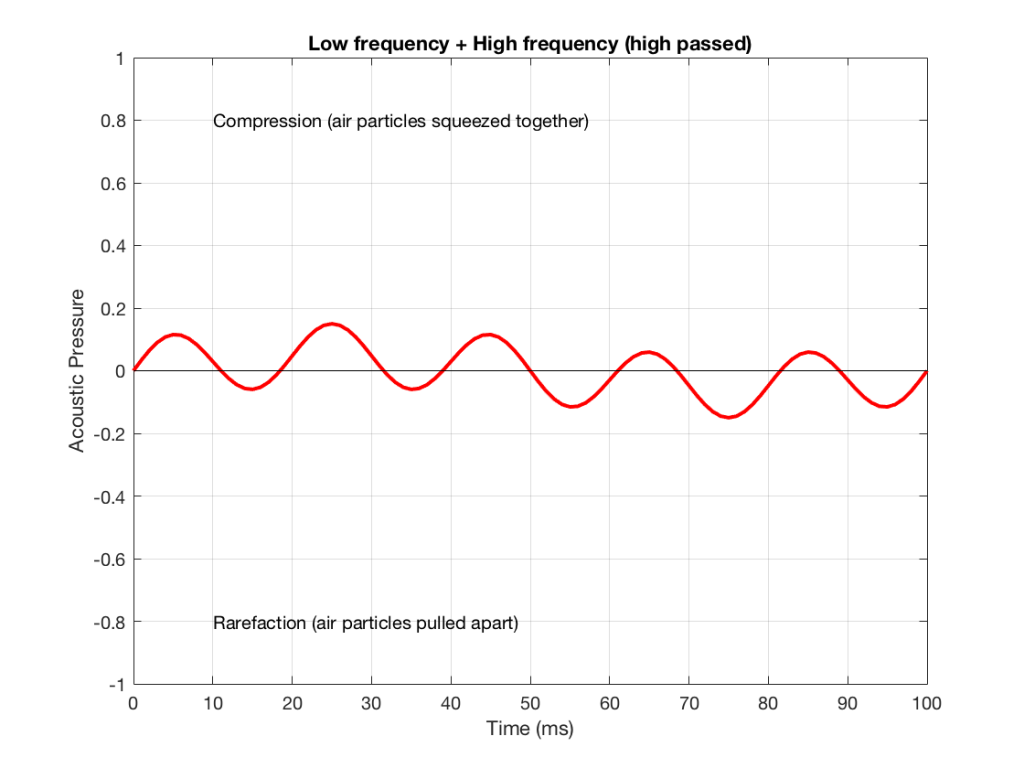
NB: Of course, everything I’ve shown here are just examples to make the concept intuitive. The crossover shown in Figure 6 would not work the way I’ve shown it in Figures 7 and 8 because the crossover frequency is too high compared to the 10 Hz and 50 Hz waves that I used in the example. So, please do not make comments talking about how I chose the wrong crossover frequency…
In the last posting, I talked about the effects of a bandpass filter on the probability density function (PDF) of an audio signal. This left the open issue of other filter types. So, below is the continuation of the discussion…
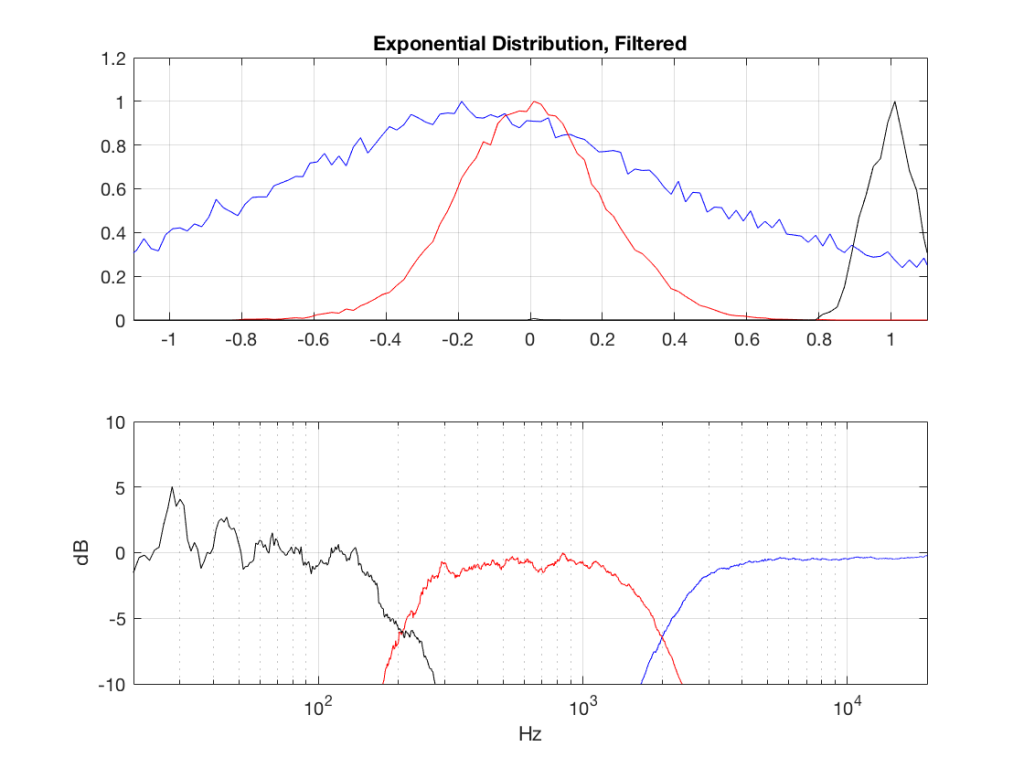
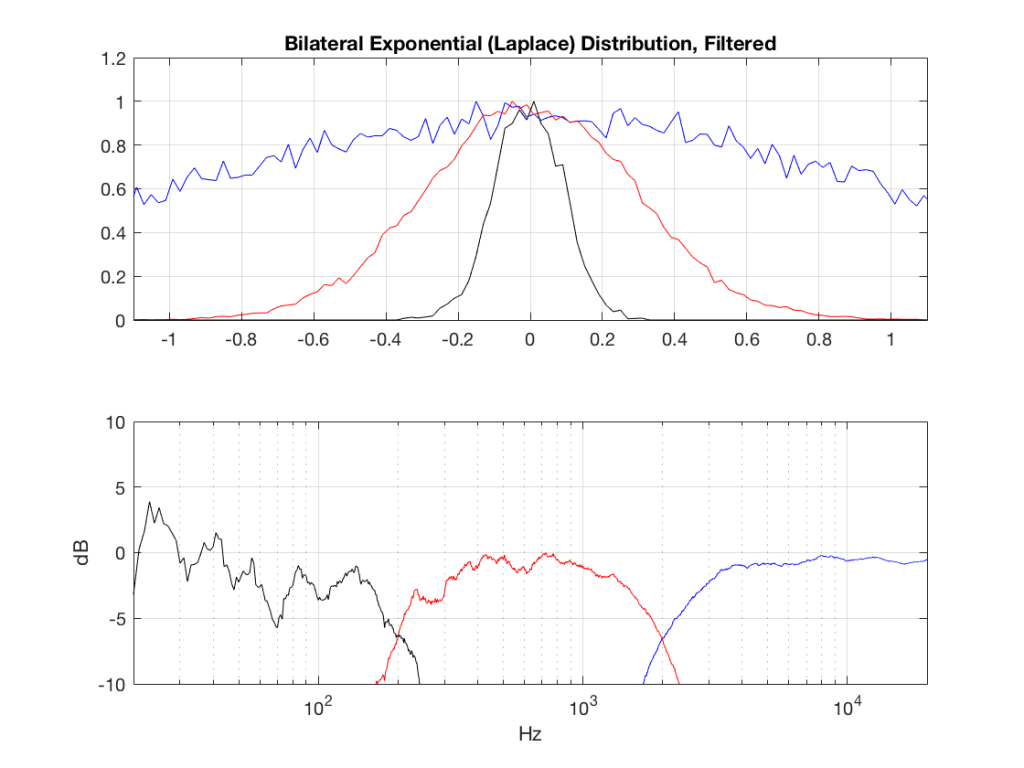
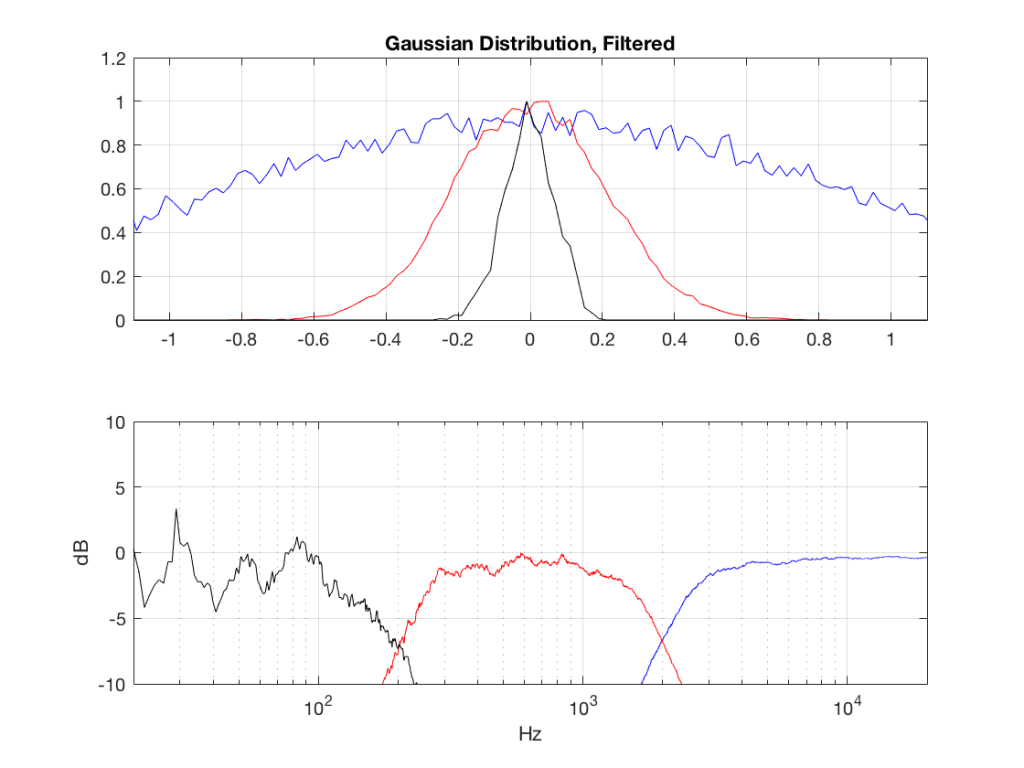
I made noise signals (length 2^16 samples, fs=2^16) with different PDFs, and filtered them as if I were building a three-way loudspeaker with a 4th order Linkwitz-Riley crossover (without including the compensation for the natural responses of the drivers). The crossover frequencies were 200 Hz and 2 kHz (which are just representative, arbitrary values).
So, the filter magnitude responses looked like Figure 1.
The resulting effects on the probability distribution functions are shown below. (Check the last posting for plots of the PDFs of the full-band signals – however note that I made new noise signals, so the magnitude responses won’t match directly.)
The magnitude responses shown in the plots below have been 1/3-octave smoothed – otherwise they look really noisy.
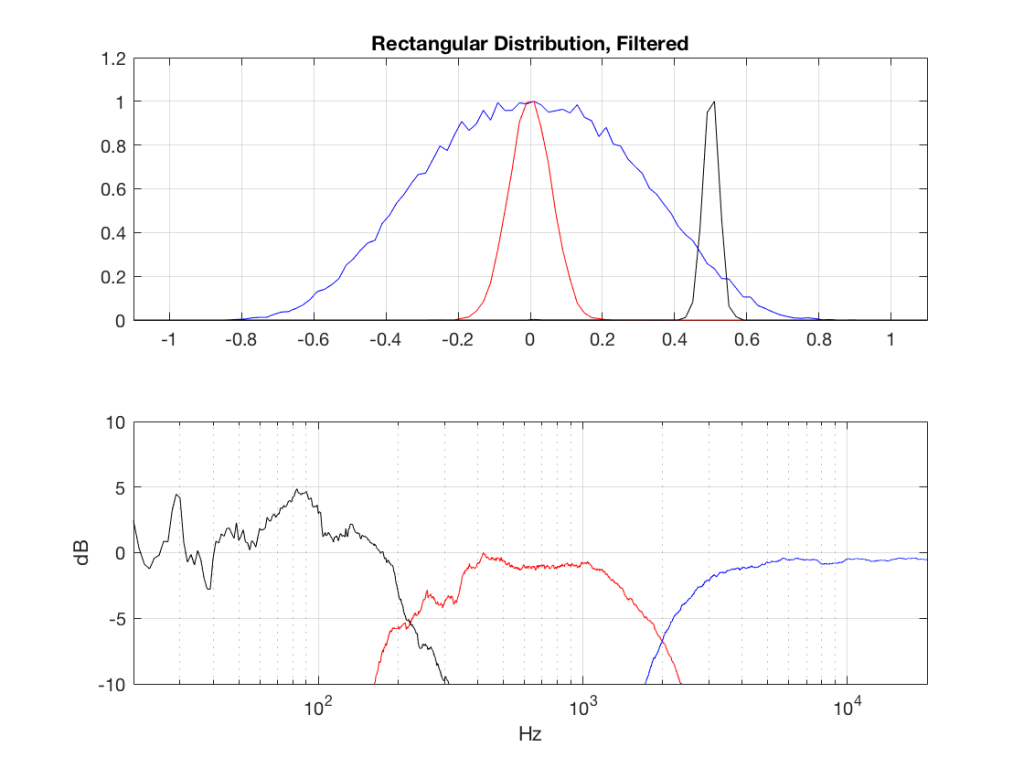
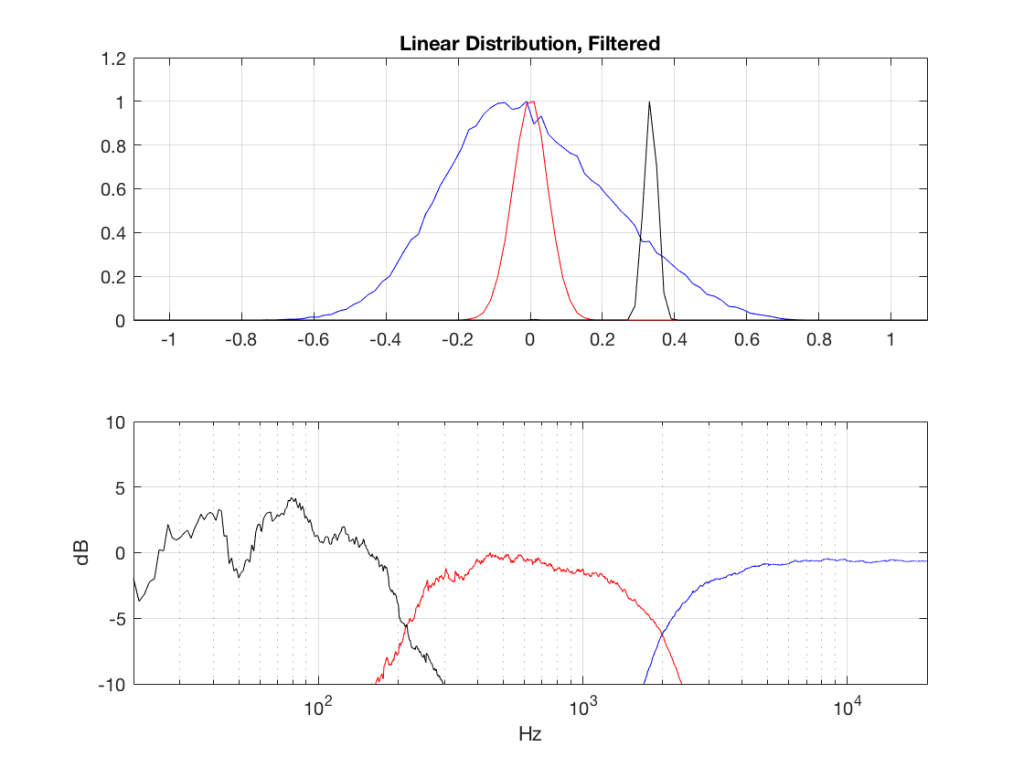
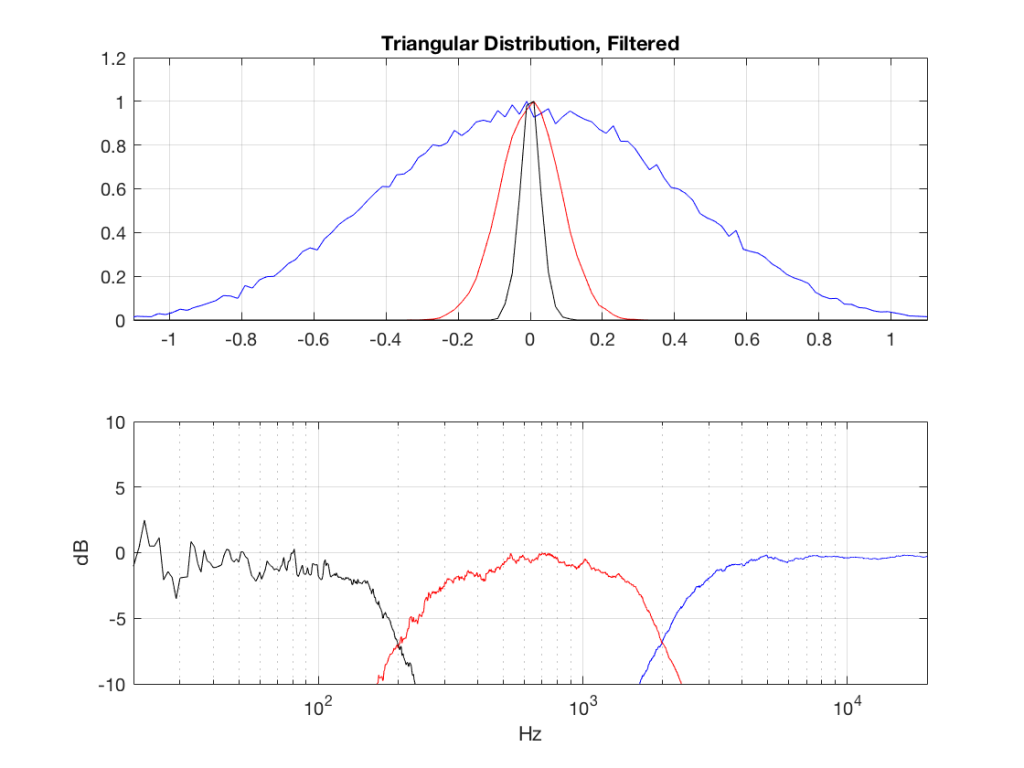
This posting has a Part 1 that you’ll find here and a Part 2 that you’ll find here.
In a previous posting, I showed some plots that displayed the probability density functions (or PDF) of a number of commercial audio recordings. (If you are new to the concept of a probability density function, then you might want to at least have a look at that posting before reading further…)
I’ve been doing a little more work on this subject, with some possible implications on how to interpret those plots. Or, perhaps more specifically, with some possible implications on possible conclusions to be drawn from those plots.
To start, let’s create some noise with a desired PDF, without imposing any frequency limitations on the signal.
To do this, I’ve ported equations from “Computer Music: Synthesis, Composition, and Performance” by Charles Dodge and Thomas A. Jerse, Schirmer Books, New York (1985) to Matlab. That code is shown below in italics, in case you might want to use it. (No promises are made regarding the code quality… However, I will say that I’ve written the code to be easily understandable, rather than efficient – so don’t make fun of me.) I’ve made the length of the noise samples 2^16 because I like that number. (Actually, it’s for other reasons involving plotting the results of an FFT, and my own laziness regarding frequency scaling – but that’s my business.)
uniform = rand(2^16, 1);
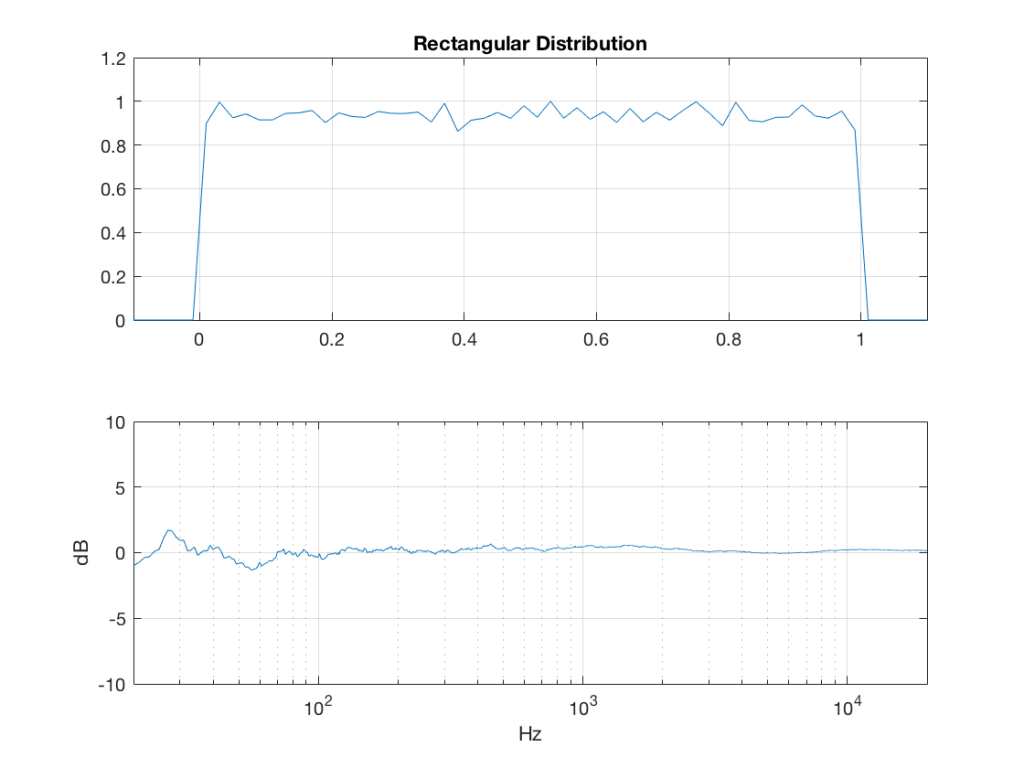
Of course, as you can see in the plots in Figure 1, the signal is not “perfectly” rectangular, nor is it “perfectly” flat. This is because it’s noise. If I ran exactly the same code again, the result would be different, but also neither perfectly rectangular nor flat. Of course, if I ran the code repeatedly, and averaged the results, the average would become “better” and “better”.
linear_temp_1 = rand(2^16, 1);
linear_temp_2 = rand(2^16, 1);
temp_indices = find(linear_temp_1 < linear_temp_2);
linear = linear_temp_2;
linear(temp_indices) = linear_temp_1(temp_indices);
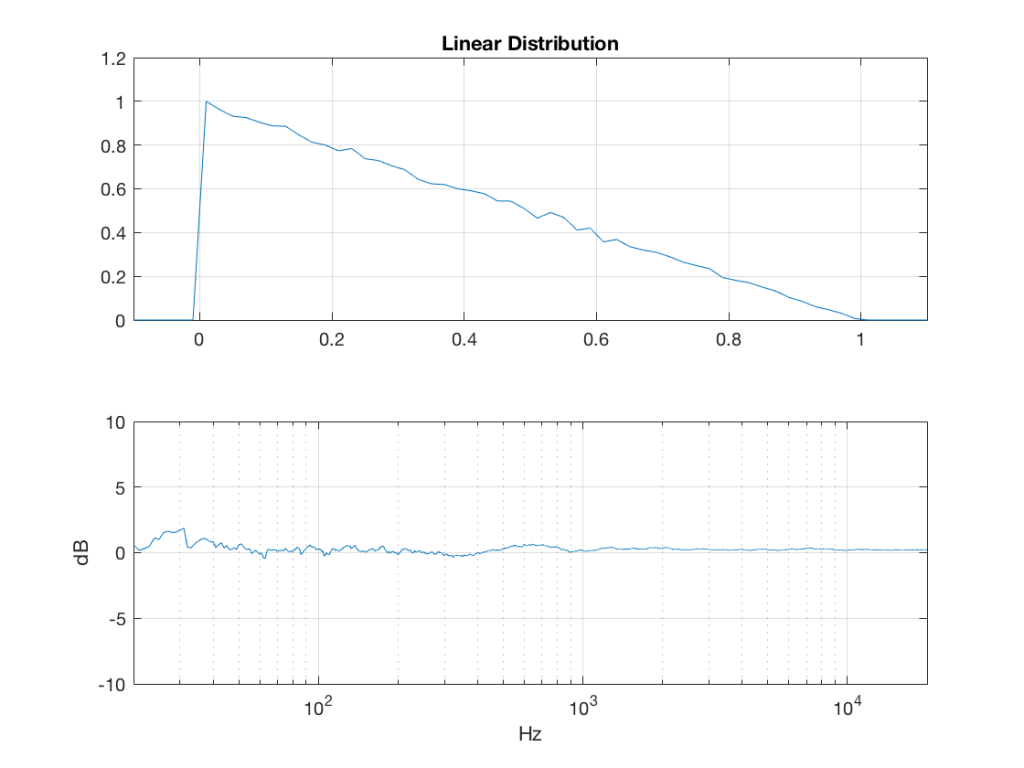
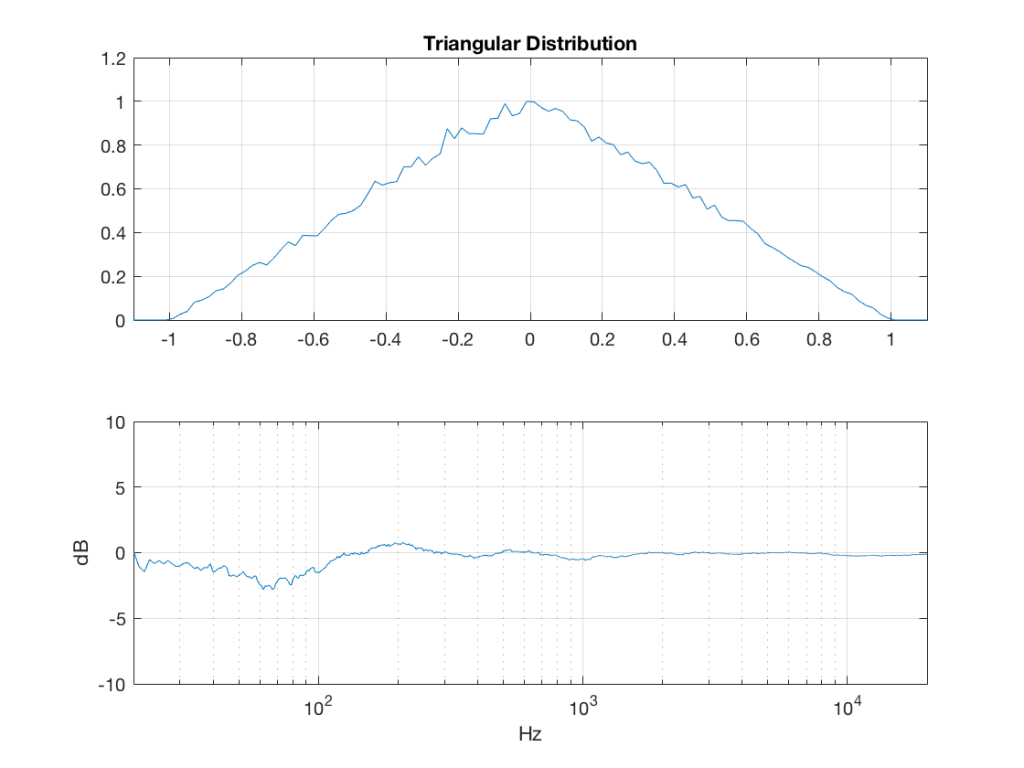
triangular = rand(2^16, 1) – rand(2^16, 1);
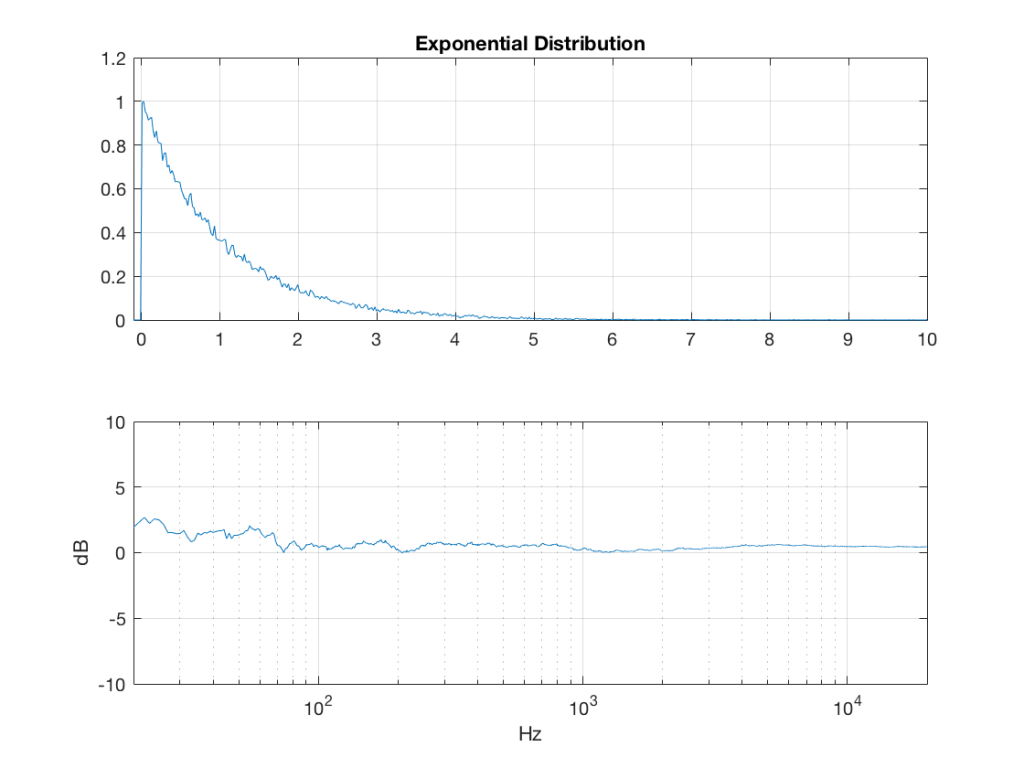
lambda = 1; % lambda must be greater than 0
exponential_temp = rand(2^16, 1) / lambda;
if any(exponential_temp == 0) % ensure that no values of exponential_temp are 0
error(‘Please try again…’)
end
exponential = -log(exponential_temp);
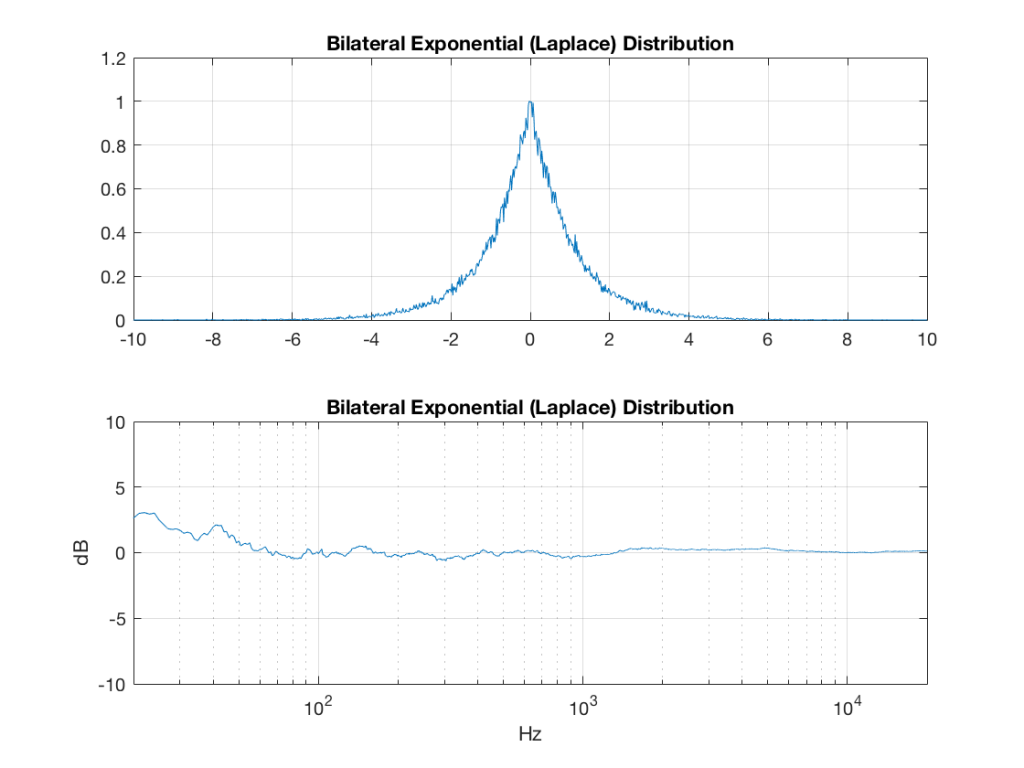
lambda = 1; % must be greater than 0
bilex_temp = 2 * rand(2^16, 1);
% check that no values of bilex_temp are 0 or 2
if any(bilex_temp == 0)
error(‘Please try again…’)
end
bilex_lessthan1 = find(bilex_temp <= 1);
bilex(bilex_lessthan1, 1) = log(bilex_temp(bilex_lessthan1)) / lambda;
bilex_greaterthan1 = find(bilex_temp > 1);
bilex_temp(bilex_greaterthan1) = 2 – bilex_temp(bilex_greaterthan1);
bilex(bilex_greaterthan1, 1) = -log(bilex_temp(bilex_greaterthan1)) / lambda;
sigma = 1;
xmu = 0; % offset
n = 100; % number of random number vectors used to create final vector (more is better)
xnover = n/2;
sc = 1/sqrt(n/12);
total = sum(rand(2^16, n), 2);
gaussian = sigma * sc * (total – xnover) + xmu;
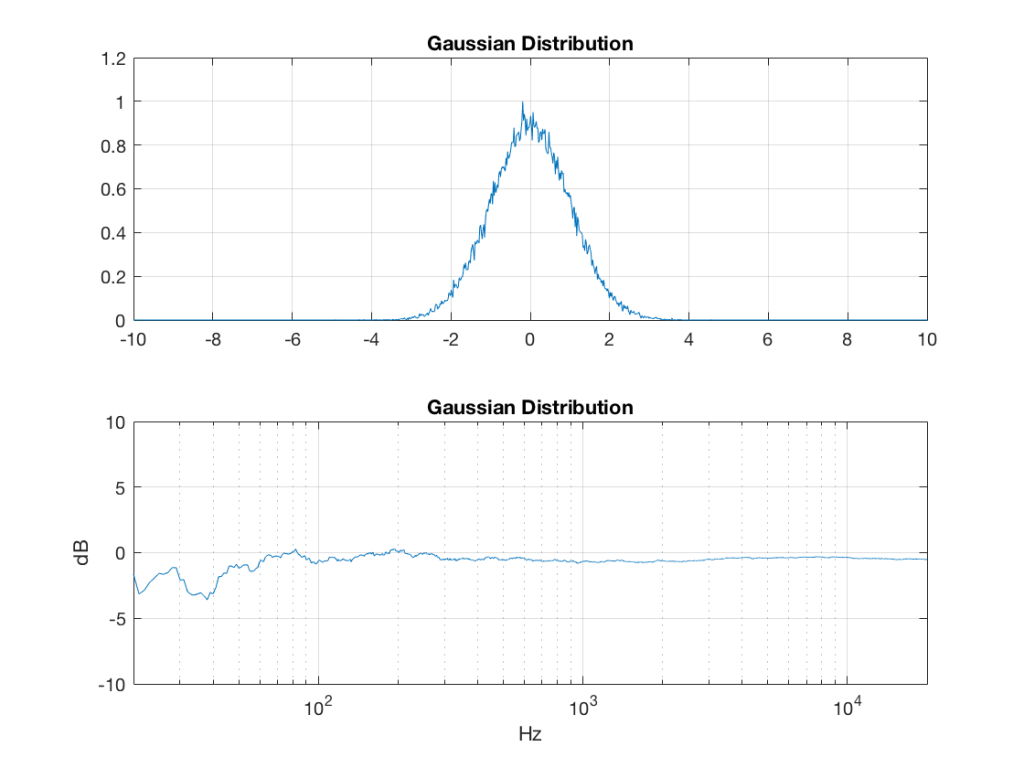
Of course, if you are using Matlab, there is an easier way to get a noise signal with a Gaussian PDF, and that is to use the randn() function.
What happens to the probability distribution of the signals if we band-limit them? For example, let’s take the signals that were plotted above, and put them through two sets of two second-order Butterworth filters in series, one set producing a high-pass filter at 200 Hz and the other resulting in a low-pass filter at 2 kHz .(This is the same as if we were making a mid-range signal in a 4th-order Linkwitz-Riley crossover, assuming that our midrange drivers had flat magnitude responses far beyond our crossover frequencies, and therefore required no correction in the crossover…)
What happens to our PDF’s as a result of the band limiting? Let’s see…
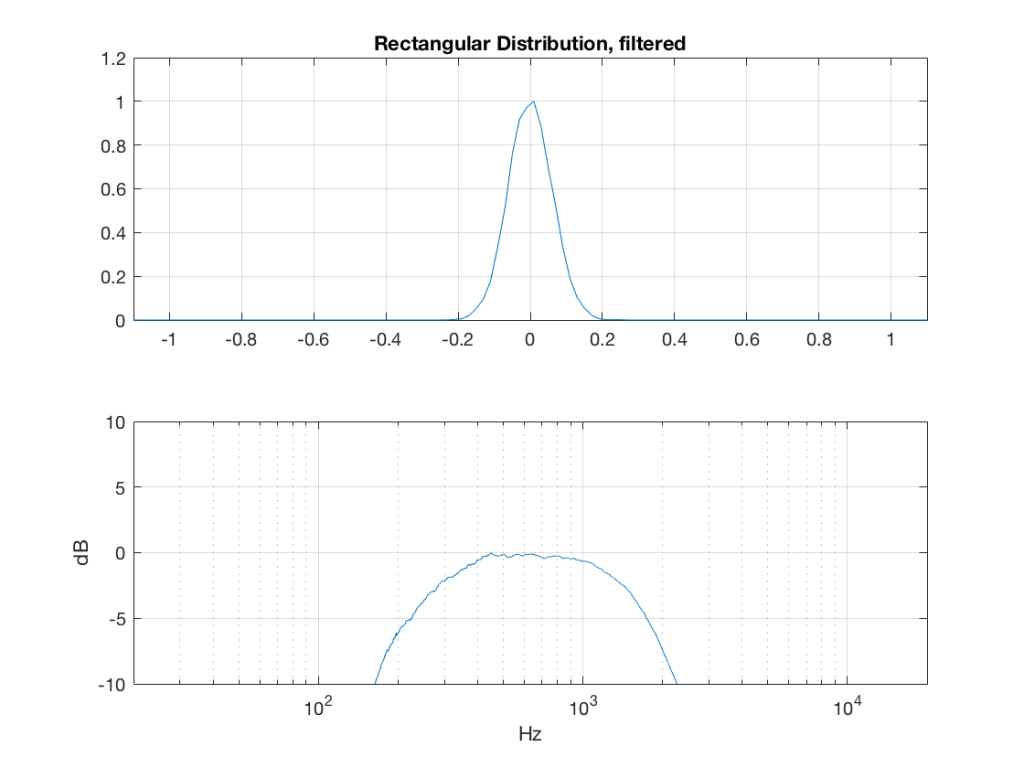
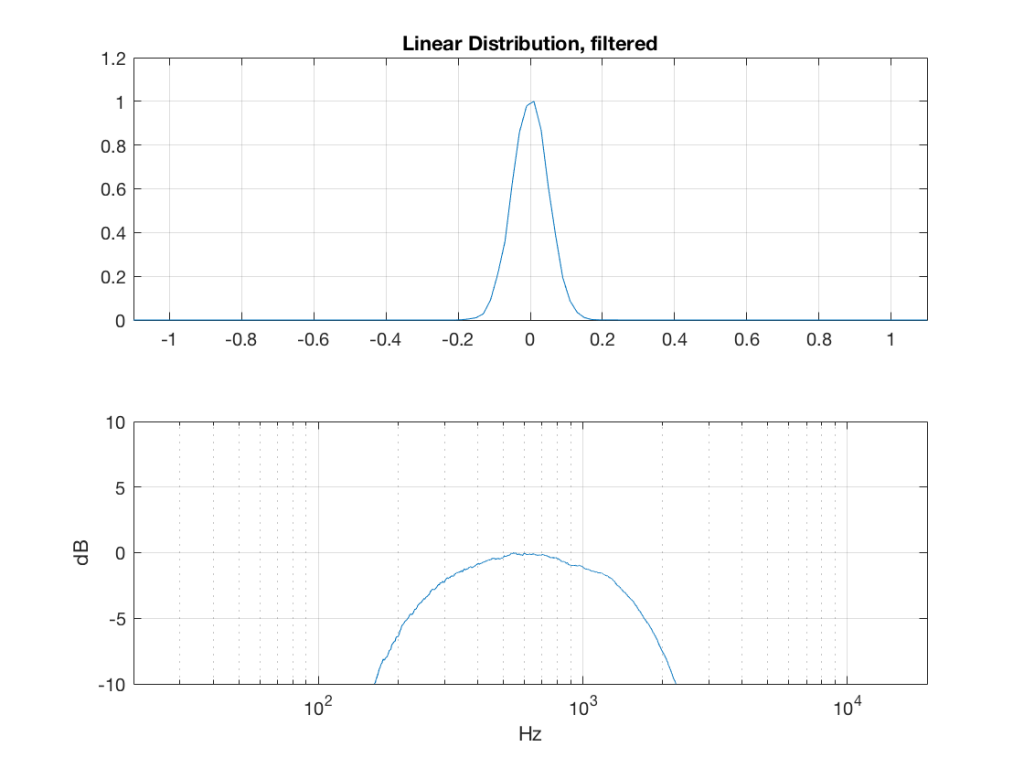
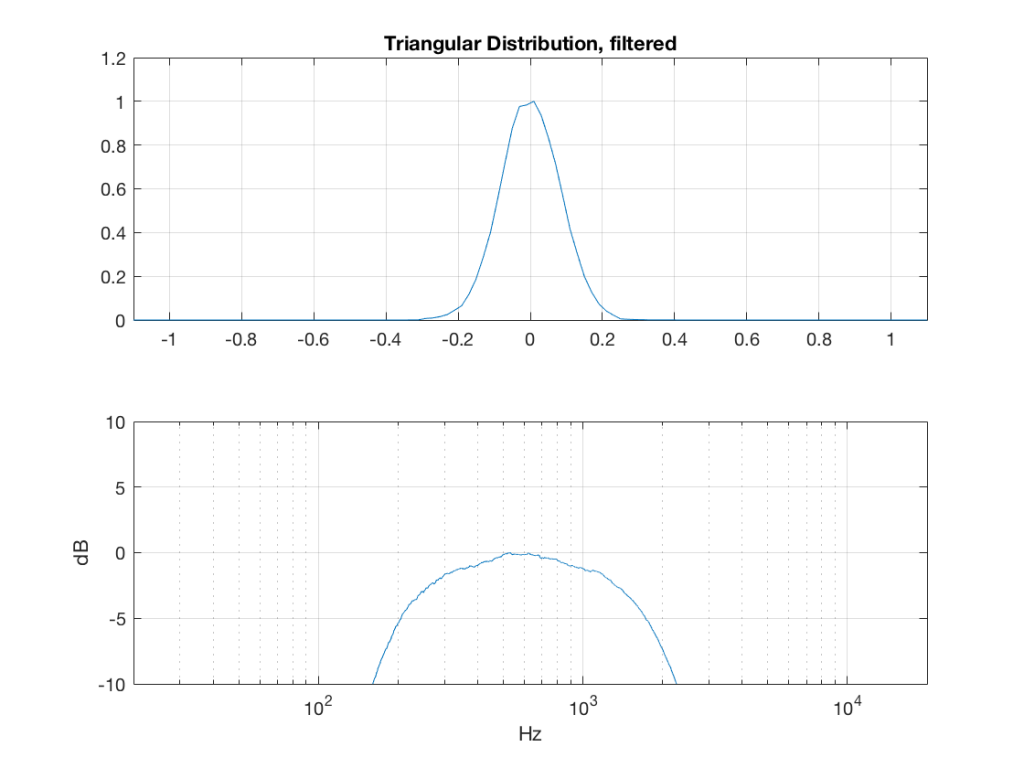
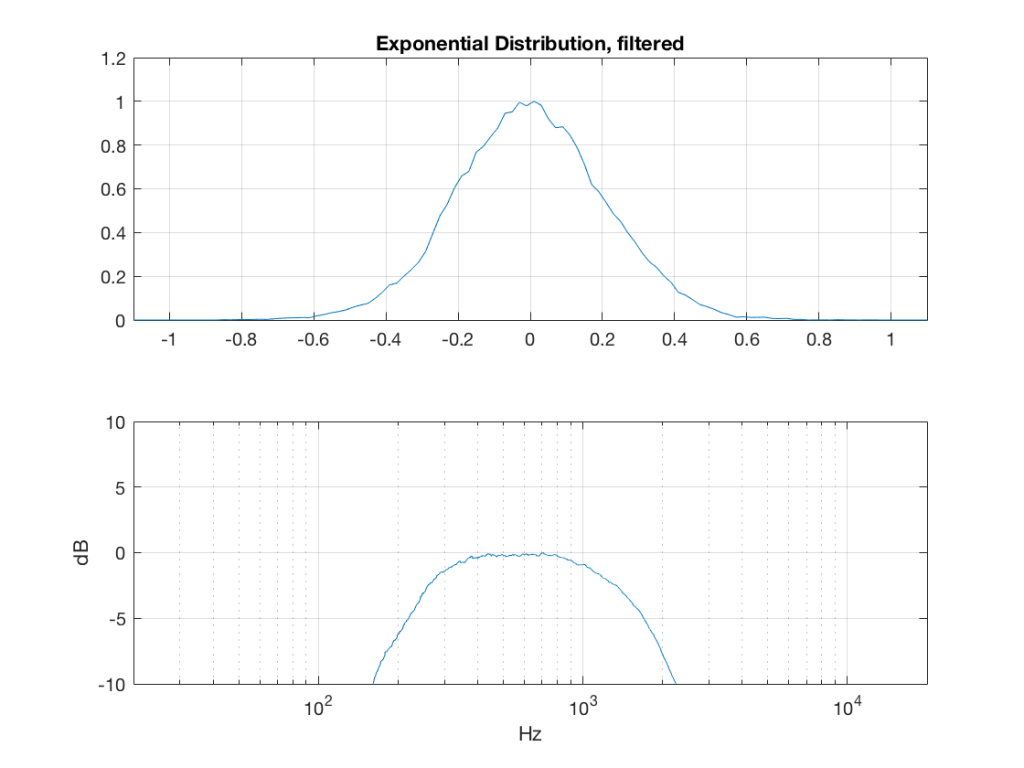
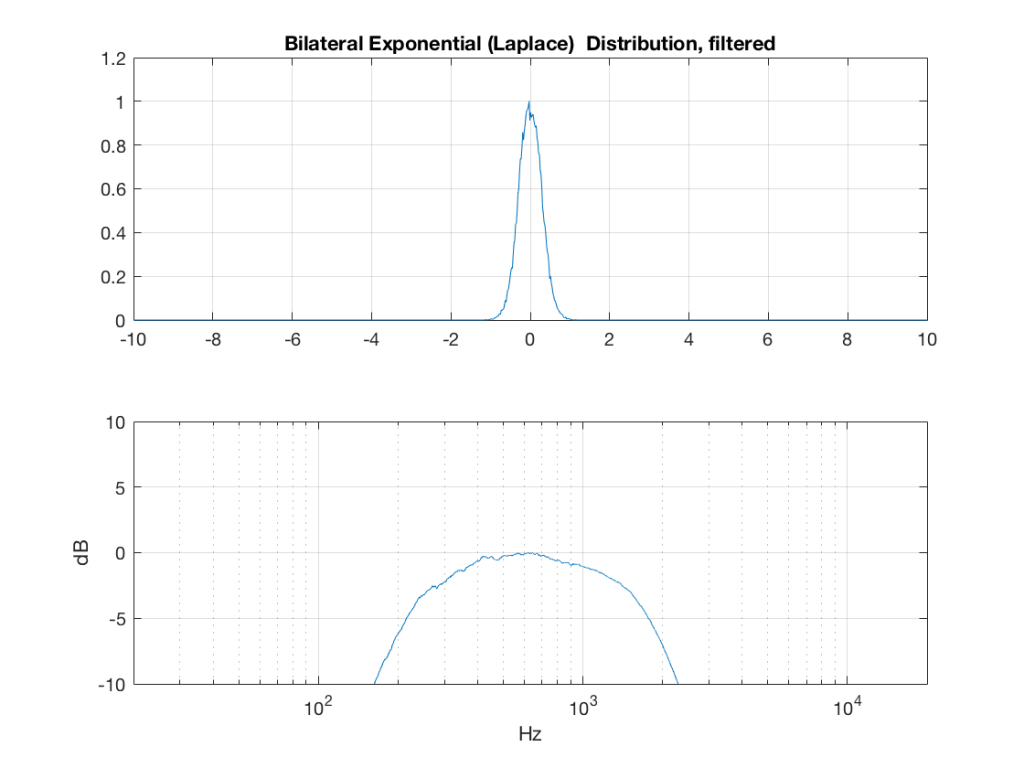
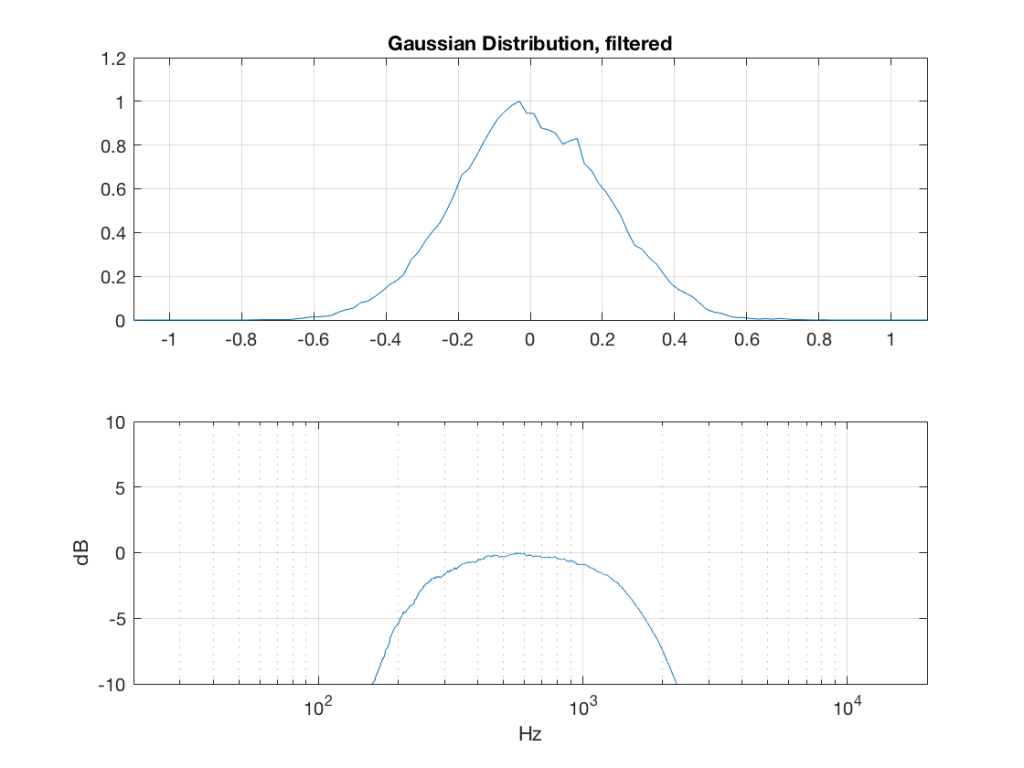
So, what we can see in Figures 7 through 12 (inclusive) is that, regardless of the original PDF of the signal, if you band-limit it, the result has a Gaussian distribution.
And yes, I tried other bandwidths and filter slopes. The result, generally speaking, is the same.
One part of this effect is a little obvious. The high-pass filter (in this case, at 200 Hz) removes the DC component, which makes all of the PDF’s symmetrical around the 0 line.
However, the “punch line” is that, regardless of the distribution of the signal coming into your system (and that can be quite different from song to song as I showed in this posting) the PDF of the signal after band-limiting (say, being sent to your loudspeaker drivers) will be Gaussian-ish.
And, before you ask, “what if you had only put in a high-pass or a low-pass filter?” – that answer is coming in a later posting…
This posting has a Part 1 that you’ll find here, and a Part 3 that you’ll find here.
In my previous posting, I mentioned that I was using a tone at or around 997 Hz to test my signal. In truth, only one of the plots I showed there actually used 997 Hz – but that doesn’t really matter.
The question that I’ll talk about in this posting is “why did I prefer to use 997 Hz instead of 1 kHz as my target frequency?” (I didn’t just randomly choose 997 Hz – it’s a common number that’s often used by people in the audio industry.)
The answer to that question has to do with some considerations on how digital audio equipment and software is tested.
Let’s start by talking a little about how a signal gets a PCM (Pulse-Code Modulation) representation in the digital domain. Note that this is the VERY basic explanation – I’m leaving out a lot of steps here…
We’ll start with a signal like the portion of a sine wave shown in Figure 1.
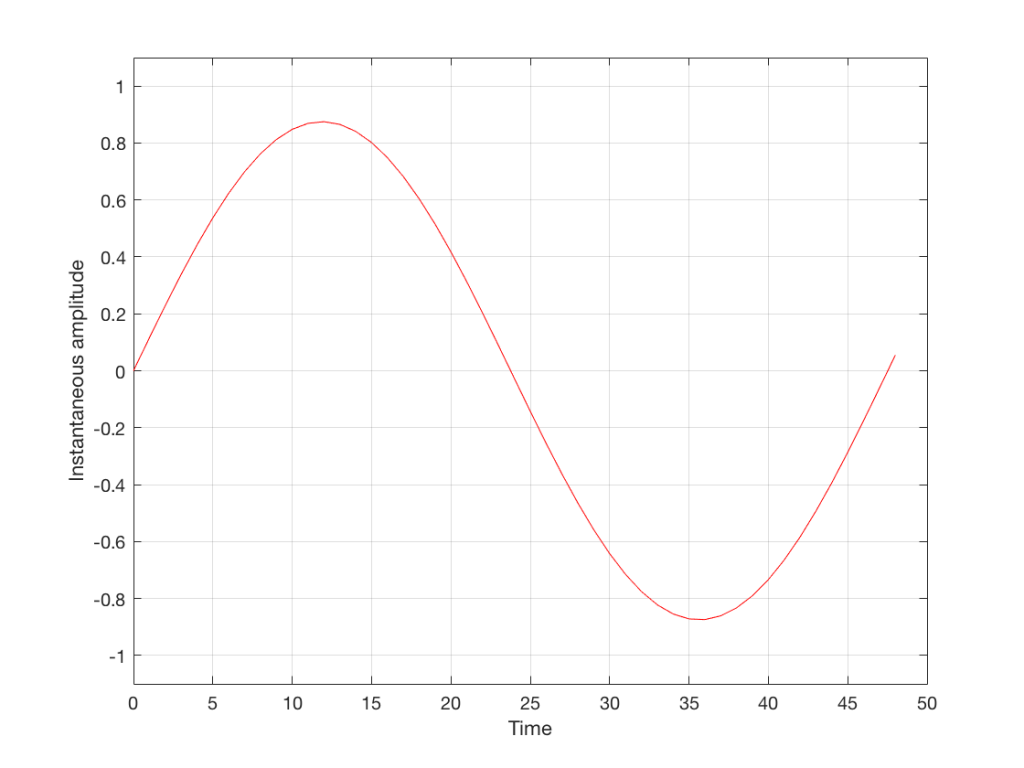
This signal is continuous – meaning that we can zoom in infinitely and still get a smooth curve – both in terms of time, and amplitude.
We then take that signal and measure its amplitude every time a clock ticks – and regular intervals. This is represented by the red dots in Figure 2. (I just left out a whole lot of information about anti-aliasing filters, but it doesn’t matter for the purposes of this discussion…)
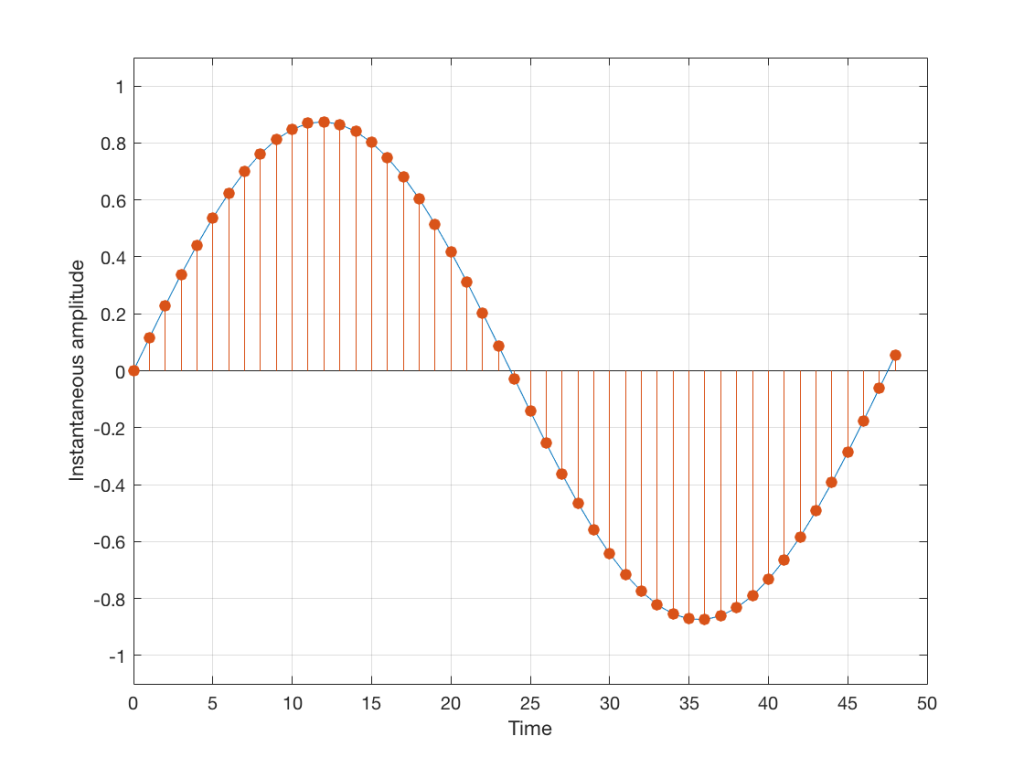
So, in Figure 2 we have a representation of a sinusoidal wave that has been “sampled” – a word that means “measured at regular time intervals. We are grabbing a “sample” or a “measurement” of the amplitude of the signal.
The problem is that the “ruler” we use to measure those values doesn’t have infinite resolution – just like the ruler that you would use to measure the length of something. If your ruler has lines only as fine as millimetres or 1/16th of an inch, then you cannot measure something accurately to the micrometer or to 1/64th of an inch. So, you “round off” your measurement to the nearest value on the ruler.
We do the same with audio – we have a finite number of values that we can store or transmit to represent the instantaneous amplitude of the signal, so we have to round off or “quantise” the values to the nearest value that we have. The result looks something like Figure 3:
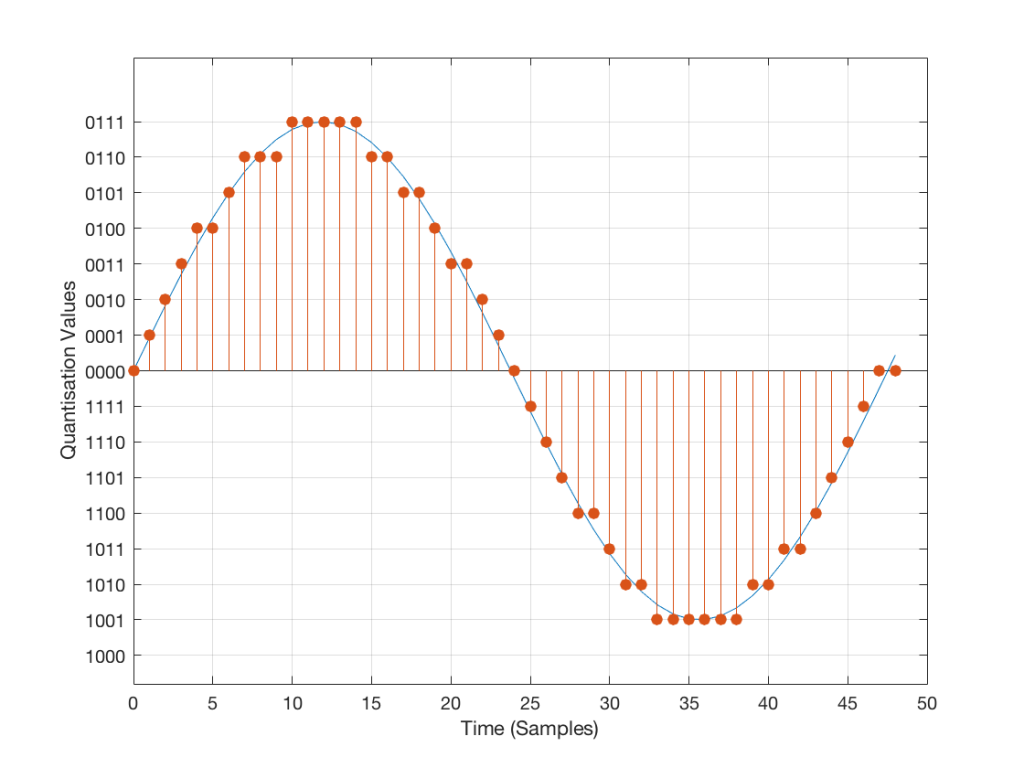
I’ve shown the quantisation values on the left (the Y-axis) as binary values. As you can see there, we have a 4-bit signal which gives us a total of 2^4 = 16 possible quantisation values for storing the signal’s amplitude at each sample.
If you’re really paying attention, you’ll notice that there are one fewer positive values than negative values, since one of the positive values is taken to represent the “0” line. This is why, when I made my original signal, I didn’t scale it all the way up to ±1 – just to keep things smooth in the explanations. If you aren’t paying that much attention, and you didn’t notice this – then please have a look, since it will come up again later…
Normally, of course, we store audio signals with a LOT more bits than this – a CD uses 16-bit resolution, which gives us a total of 65536 possible quantisation levels (2^16). Other systems use a different number of bits – either fewer or more, depending.
At this point, it should be pretty clear that you have a finite number of samples (or measurements) per second (typically 44100 samples per second (or 44.1 kHz), if it’s a CD, although 48000 samples per second (48 kHz) is also a pretty common number – other systems use other values for this.)
So, if we look at a CD, we have 44100 samples per second, and 65536 possible quantisation values to choose from for each sample (because it’s a 44.1 kHz, 16-bit system). Notice that we have more quantisation values than samples per second…
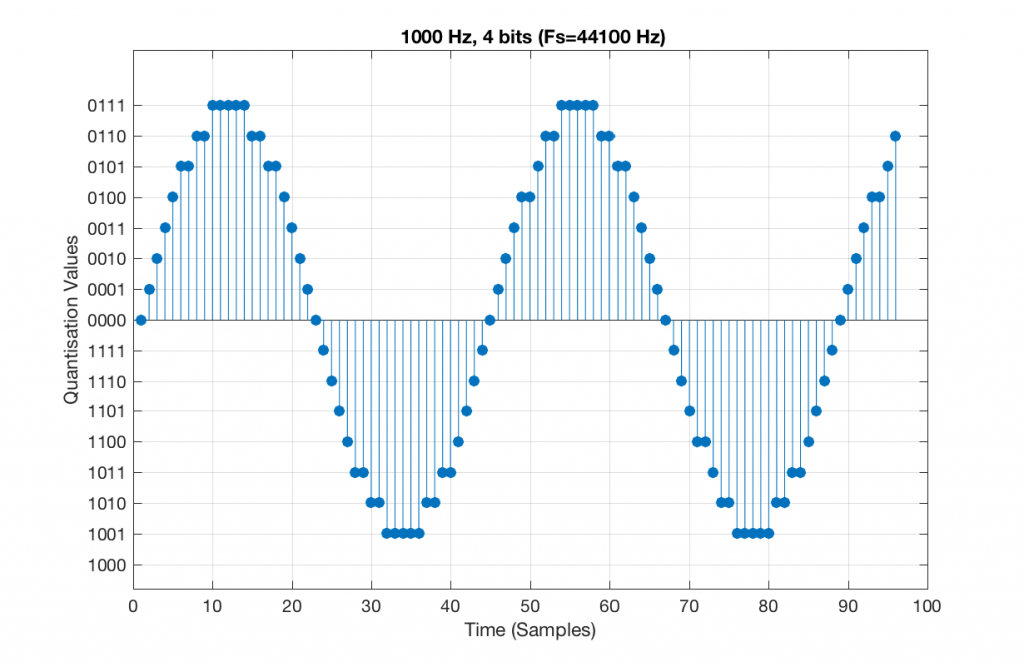
Now, let’s say that we want to test a piece of digital audio gear, and one of the tests that we wanted to perform was to ensure that all possible quantisation values are working properly (whatever that means). Let’s also say that the gear has only 4 bits of resolution and is running at a sampling rate o 48 kHz, to start. One way to test any audio gear is to feed in a sine tone and to see what comes out. So, we’ll do that, using a 1 kHz sine tone. The result looks like Figure 4, below.
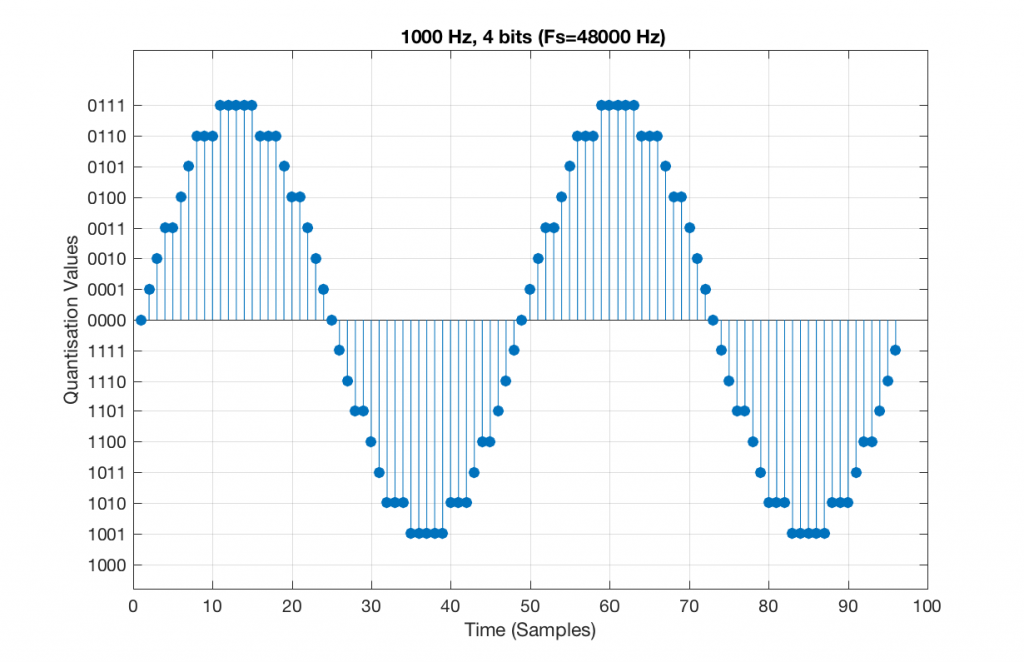
There are two things to notice about that signal in Figure 5:
Let’s take that same signal (1 kHz in a 4-bit, 48 kHz PCM system) and we’ll count the number of times each sample value occurs after 1 second (or in a time of 48000 samples). We can then plot these values as is shown in Figure 6, which is a kind of plot called a “histogram”.
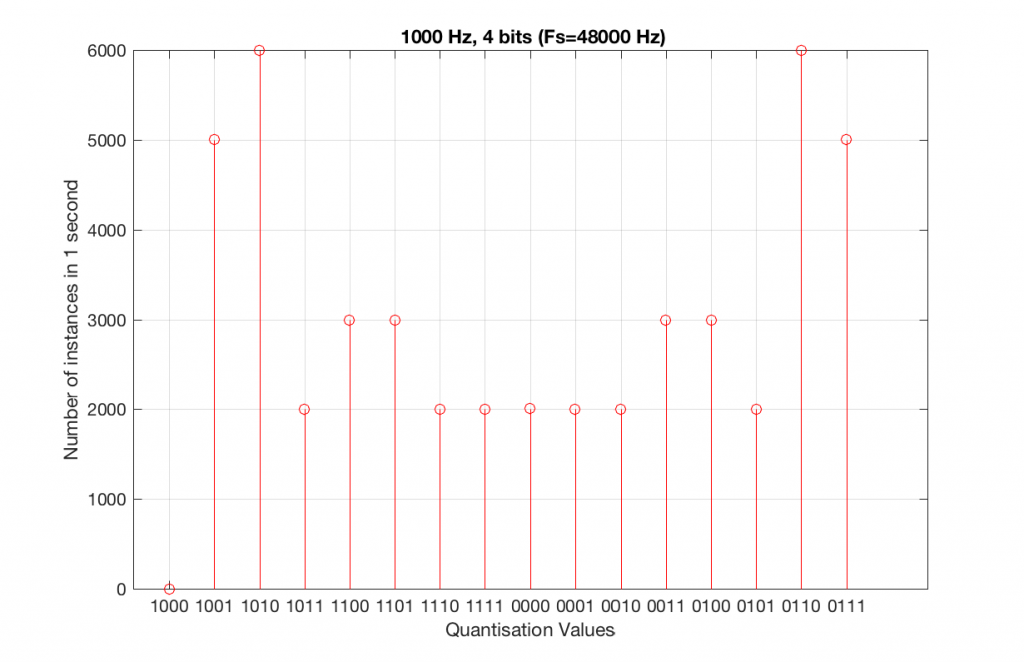
As can be seen in Figure 6, the bottom quantisation value (1000) is never used – but apart from that one, all others are.
Let’s do the same thing, but with a 4-bit, 44.1 kHz system instead. The results of this are shown below in Figure 7 and 8.
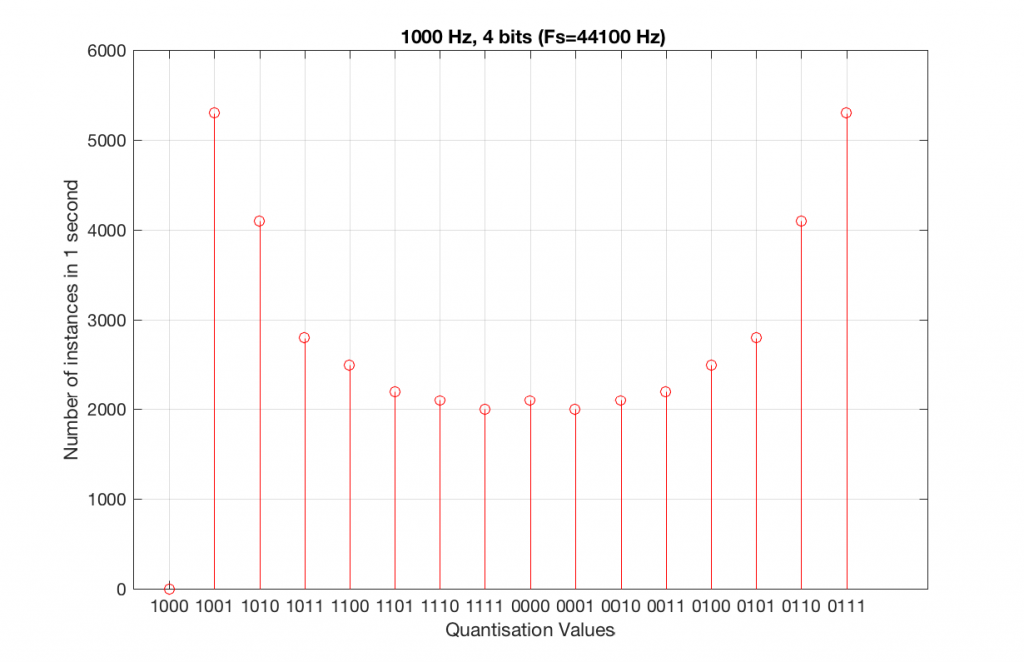
Compare Figures 6 and 8. Notice that Figure 8 appears to be a “smoother” shape. This is due to the fact that the instances of the waveform are not identical copies of each other. As can be seen in Figure 7, the waveform is slightly different. Of course, after a full second, then the whole cycle repeats itself, since there are 1000 cycles per second in the signal, and 44100 samples per second. If the signal were 1000.1 Hz, then it would take 10 seconds for the repetition to start.
Let’s increase the number of bits and see what happens. We’ll take it up to 6 bits.
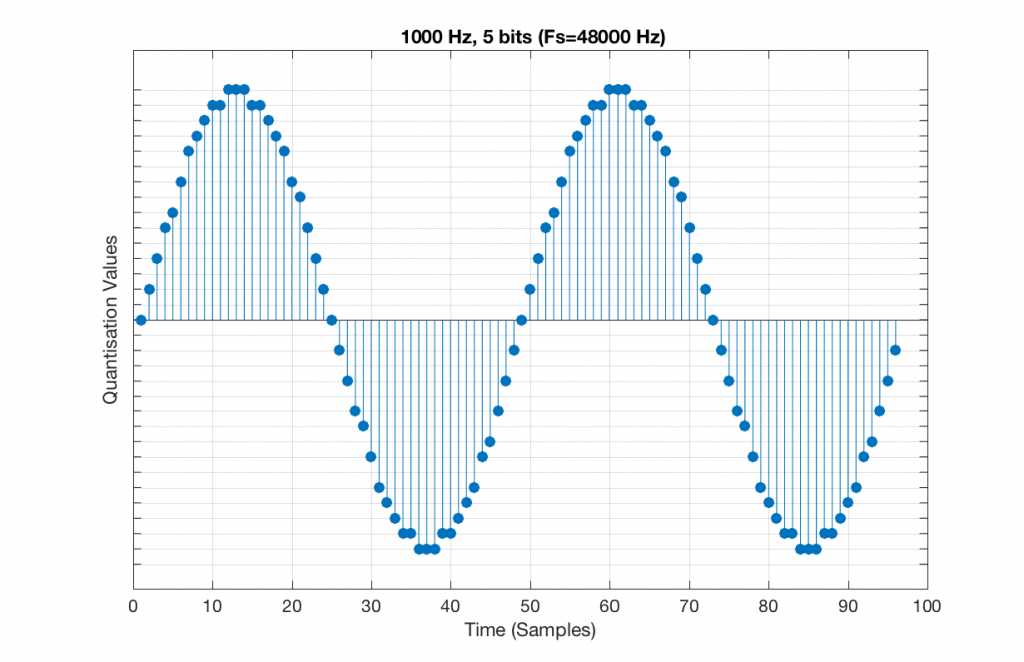
Figure 9 shows a 1 kHz sine tone in a 5-bit, 48 kHz system. Again, since 48000/1000 = 48, the two cycles are identical to each other. However, something new has happened here. If you look carefully at the positive side of the sine wave, you may notice that there are 5 quantisation values that are never used. On the negative side, there are 3 unused values, as well as the very bottom one.
So, because we are in a 5-bit system, we have 2^5 = 32 possible quantisation values, but, because we are using a 1 kHz sine tone, 9 of those possible values are never used. As a result, our histogram looks like Figure 10, below.
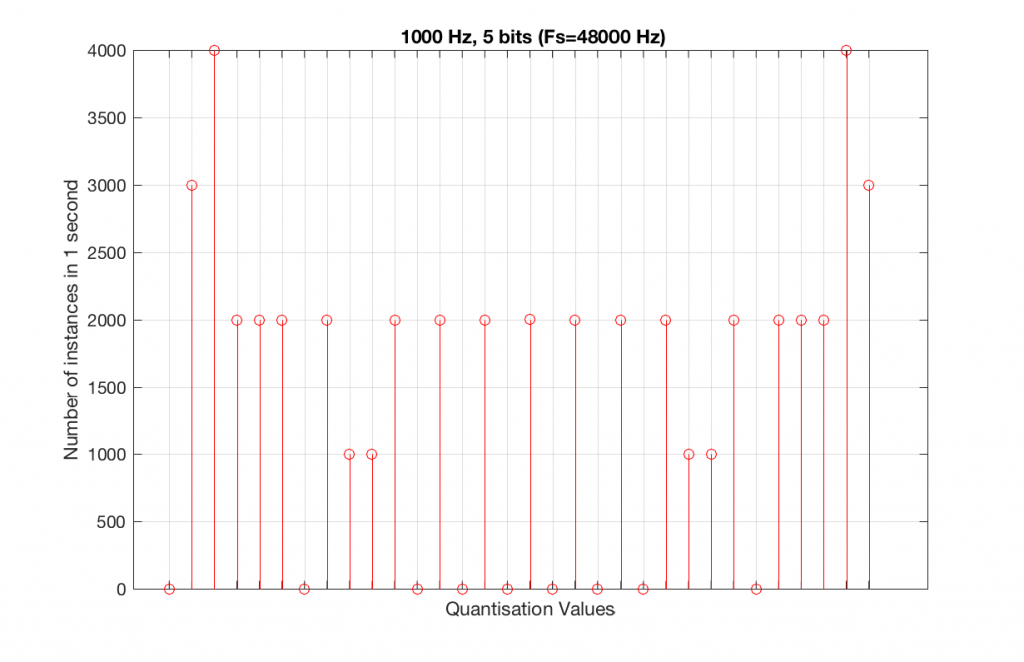
Let’s now compare that to a 5-bit, 44.1 kHz system.
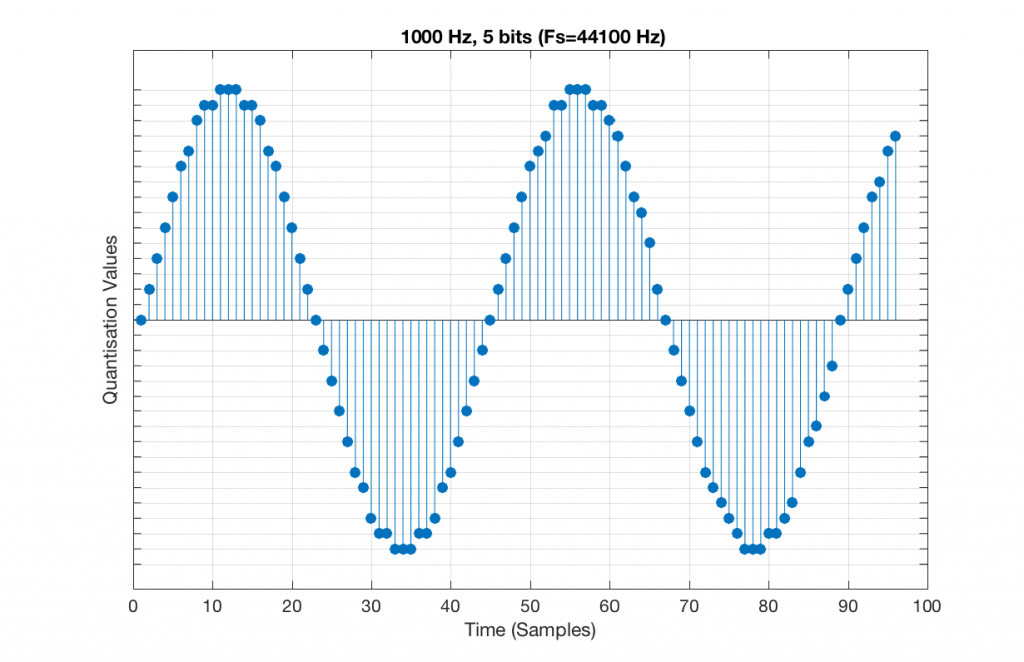
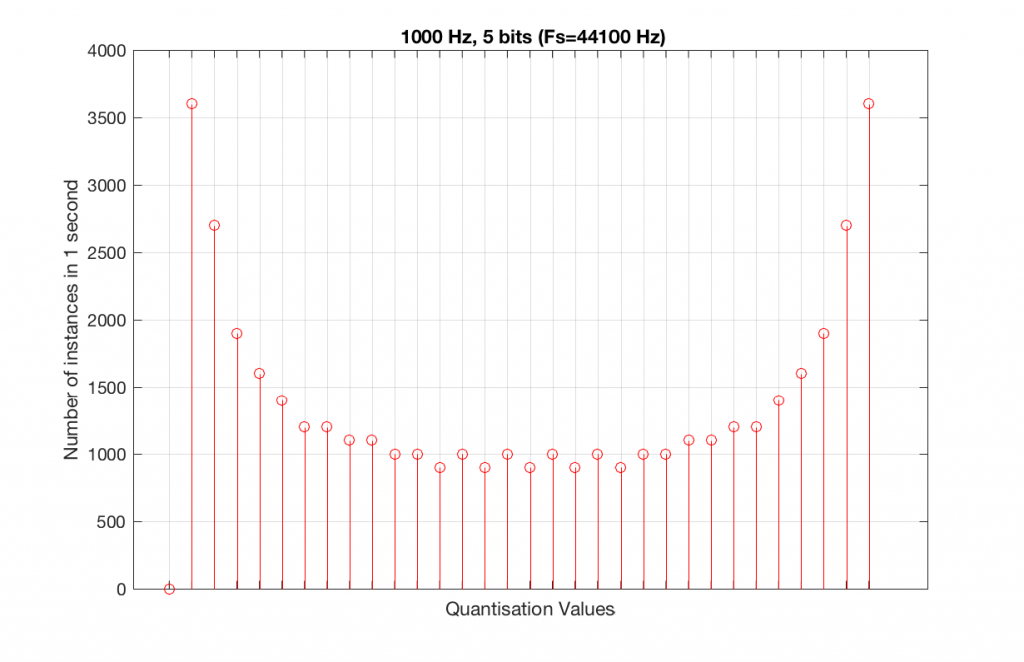
We can see that there is a basic problem here. The behaviour of the system may be different due only to the relationship between the sampling rate and the frequency of the signal.
The question is “what do we do about this?” We can see from Figures 10 and 12 that, when the signal’s frequency is not a nice round divisor of the sampling rate, we stand a better chance of testing the system more completely. So, instead of using a “nice” frequency like 1000 Hz, let’s use something close, but different enough to make things “misbehave” a little. One possible solution is to use 997 Hz, as we can see below:
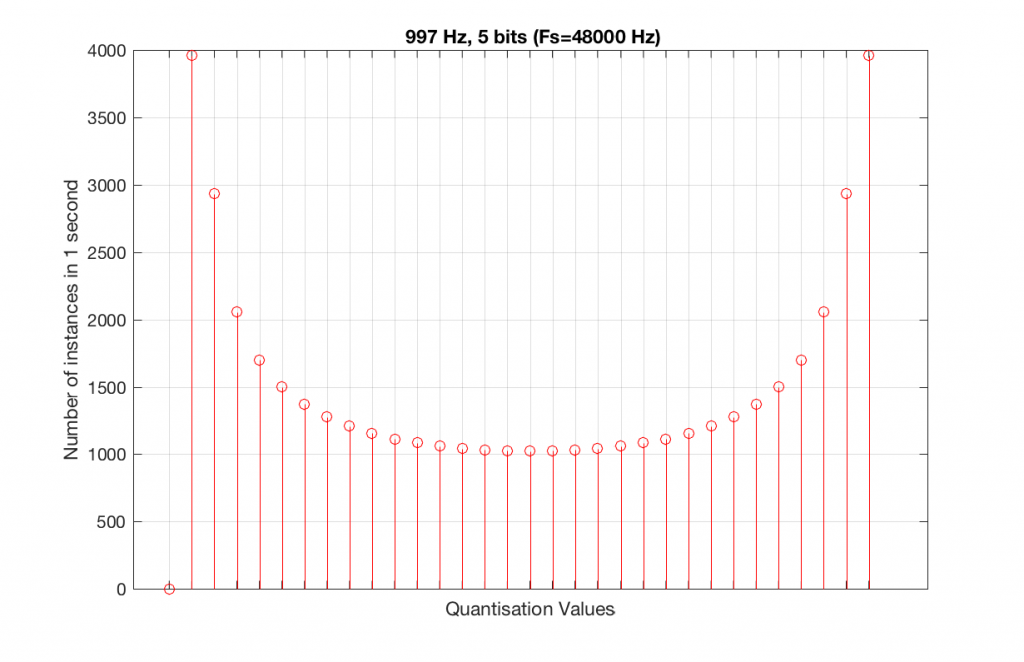
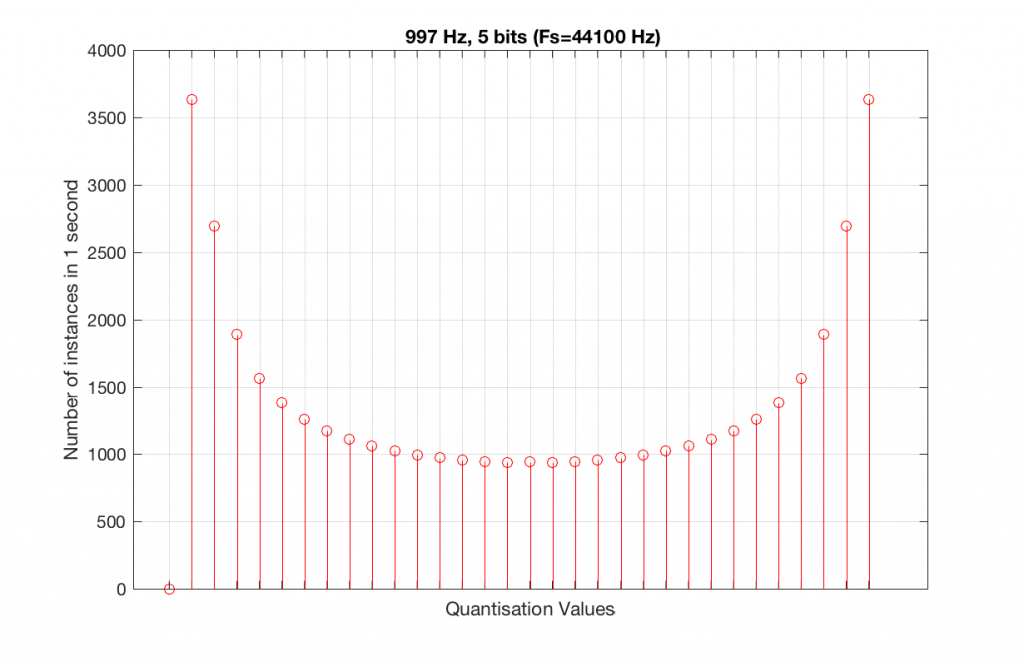
As can be seen in the histograms in Figure 13 and 14, changing the signal to 997 Hz from 1000 Hz results in us using all of the quantisation values in both sampling rates. So, we do a more thorough test, and stand a better chance of not missing anything…
At this point, you might say, “yes, but normally we used far more than 5 or 6 bits – this won’t happen in a system with more bits…” Nice try, but actually, things get worse, as you can see in Figures 15 and 16, below.
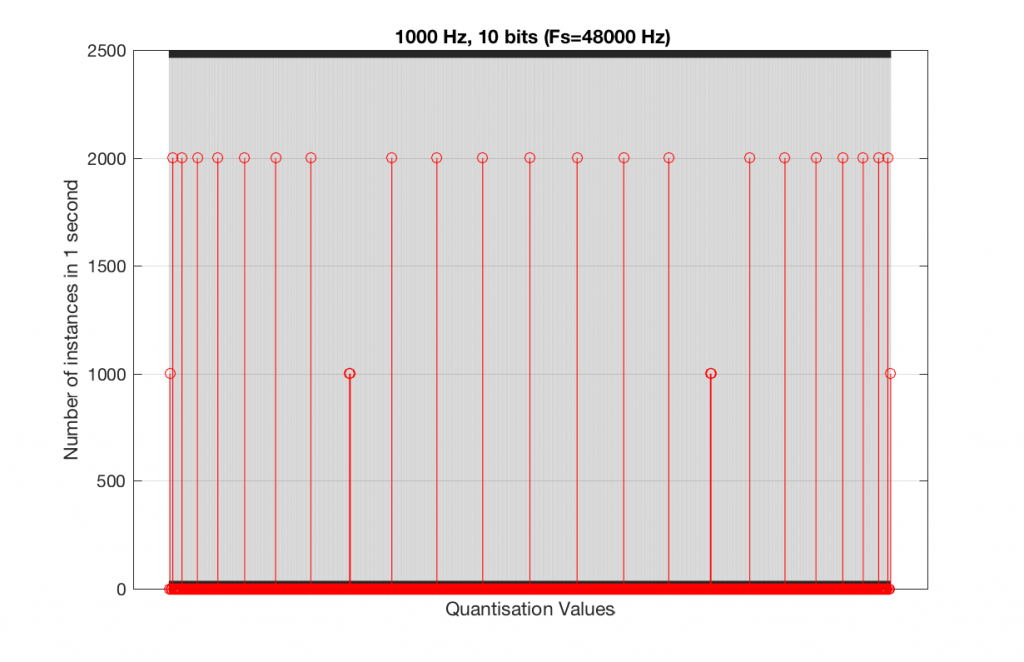
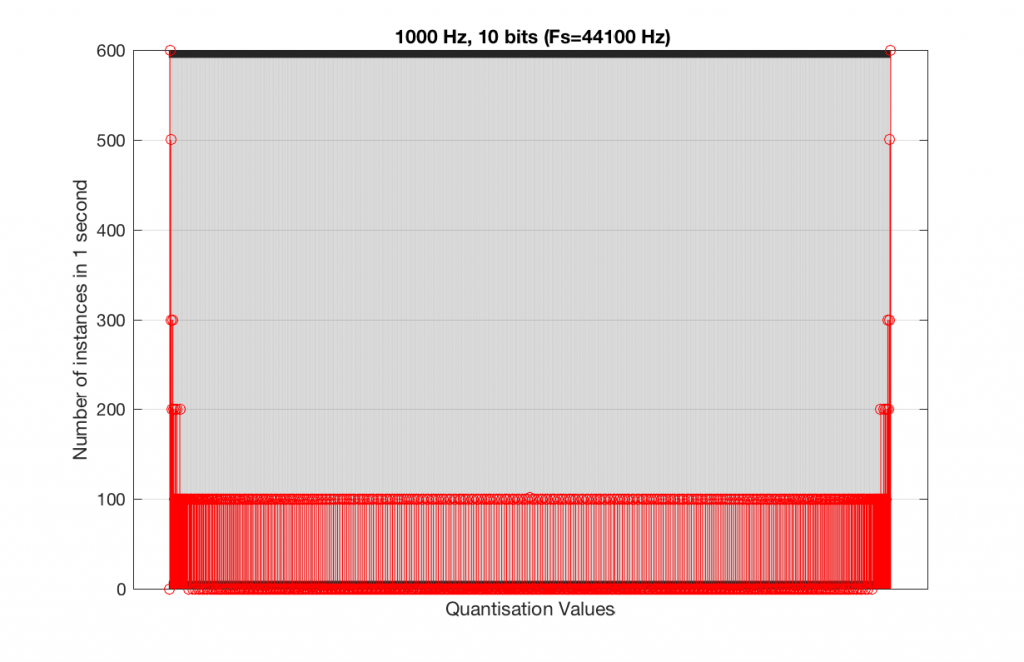
As you can see in Figures 15 and 16, lots of quantisation values are unused in both sampling rates with a 1 kHz signal. By comparison, if we used a 997 Hz tone, the results would be very different, as is shown in Figures 17 and 18.
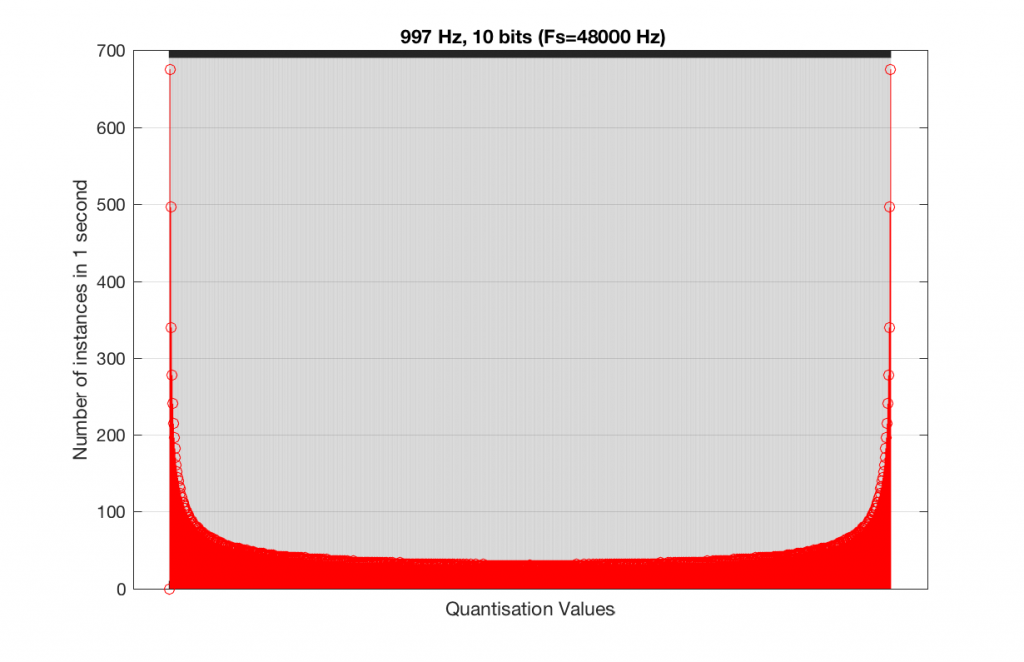
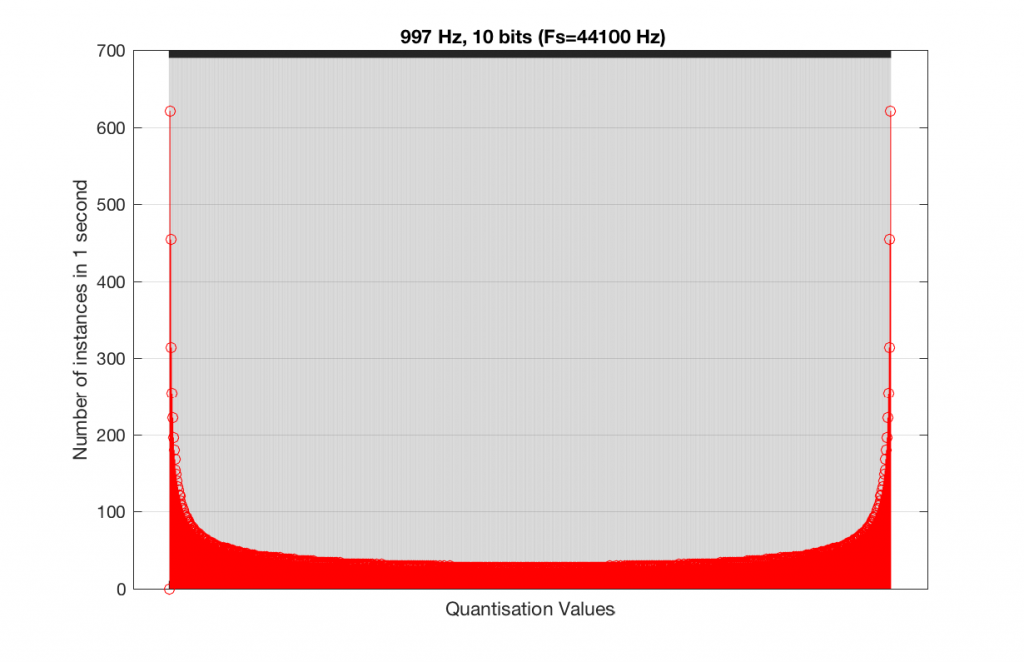
In fact, as we get more and more bits of resolution, the worse the problem gets, since we have an increasing number of available of quantisation values (increasing by a factor of 2 every time we add another bit), but the number of values that we use does not increase.
This is because, at some time, we start repeating the cycle. If the sampling rate divided by the signal frequency is an integer value (like a 1 kHz tone in a 48 kHz system), then we don’t use any new quantisation values after the first cycle of the tone (or 1 ms, in this case). If the sampling rate divided by the signal frequency is not an integer value (like a 997 Hz tone in a 48 kHz system) then we don’t start repeating ourselves until 1 second has passed.
However, think back to a comment that I made up at the top – if signal does start repeating itself after 1 second (in other words, if the frequency is an integer value), and if the number of samples per second is smaller than the number of quantisation values, then we will start repeating ourselves after 1 second, and we will only test the number of quantisation values that is equal to the sampling rate.
For example, if you have a 16-bit system, then you have 65536 possible quantisation values. If the sampling rate is 48000 Hz then we could only test a maximum of 48000 possible quantisation values out of the 65536 possible ones in one second, regardless of the frequency that we choose. Typically, however, we test fewer than this, because of the repetition of some values (e.g. the maximum value, if you have a periodic signal with a frequency greater than 1 Hz).
If we do this for the two frequencies we’ve been looking at – 1 kHz and 997 Hz, for two sampling rates, 44.1 kHz and 48 kHz, at different bit depths, the results look like the following figures.
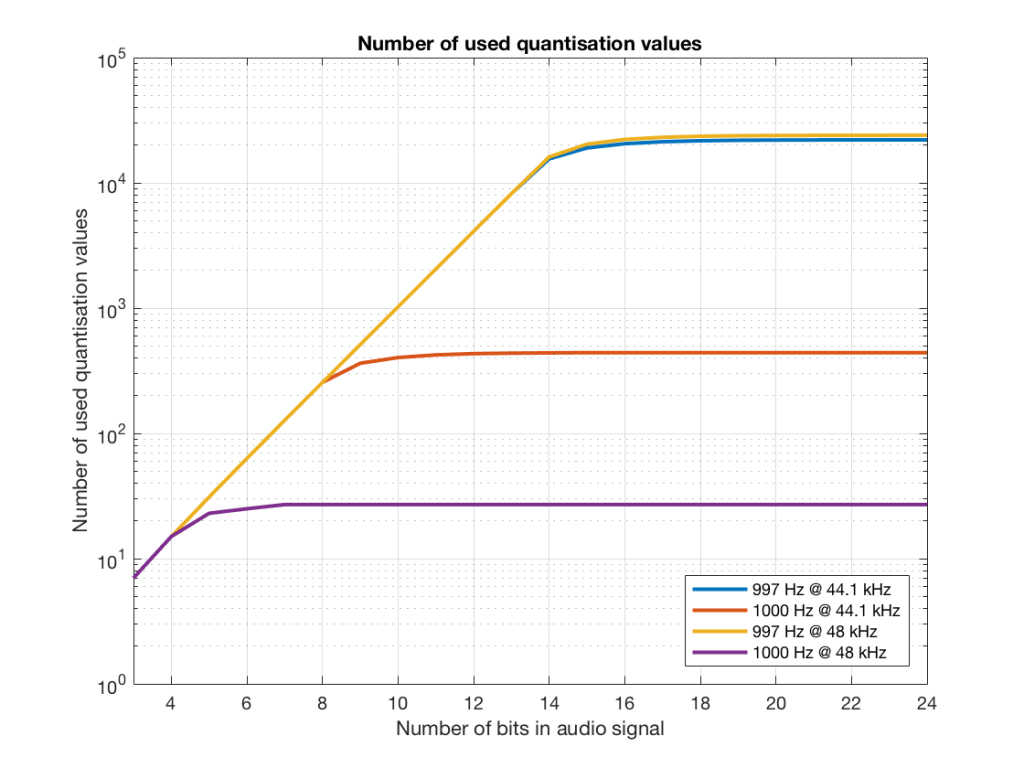
Notice in Figure 17 that the total number of quantisation values that are used when you have a 1 kHz tone in a 48 kHz system does not increase once you hit a word length of 7 bits. That does not mean that the signal’s representation does not improve – it does, since the quantisation values that you are using have a better resolution – so you’re rounding off less, so the error is smaller.
Notice as well that the 997 Hz tone not only results in us using far more quantisation values (topping out at the sampling rates) than the 1000 Hz tone, but that they are more similar in the two sampling rates.
If we plot the number of unused samples instead, it looks like Figure 18.
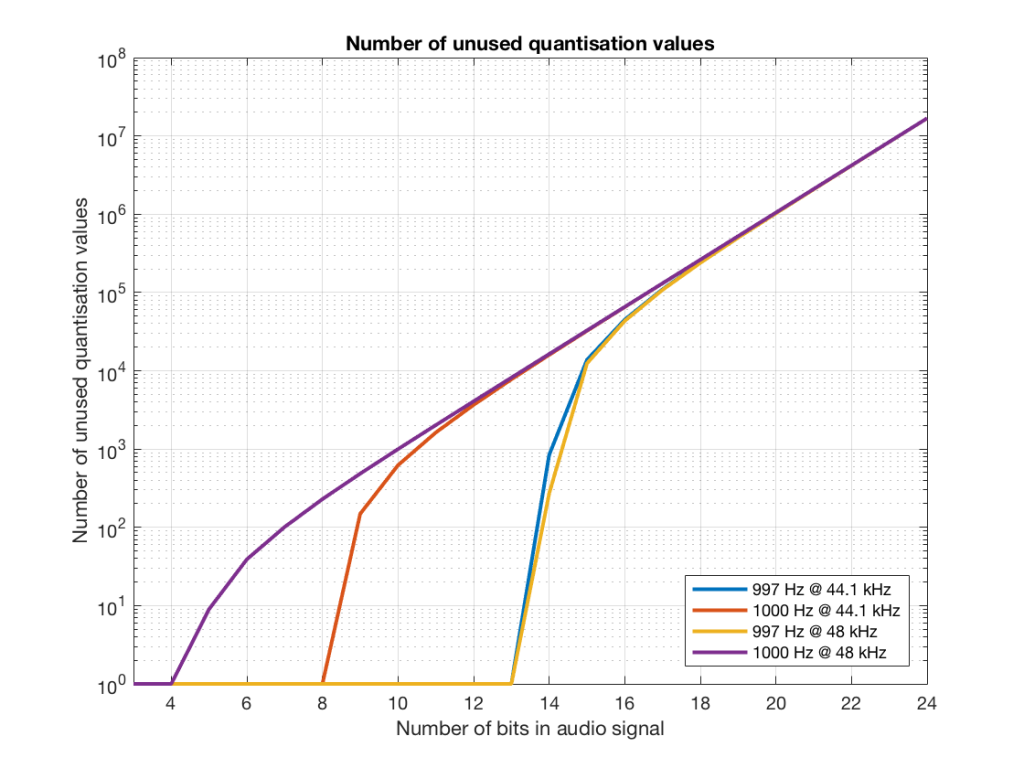
Figure 18 is a little misleading, since as the bit depth increases, the total possible number of quantisation values also increases, however, since the two frequencies that we are analysing are integer values, the maximum number cannot go past the sampling rate. So, in an extreme case (if you choose your frequency or signal carefully), only 48000 values out of a possible 16777216 values are used in a 24-bit system per second in a system with a sampling rate of 48 kHz.
Figure 19 shows the same information as Figure 18, except that I’ve displayed the values in percent.
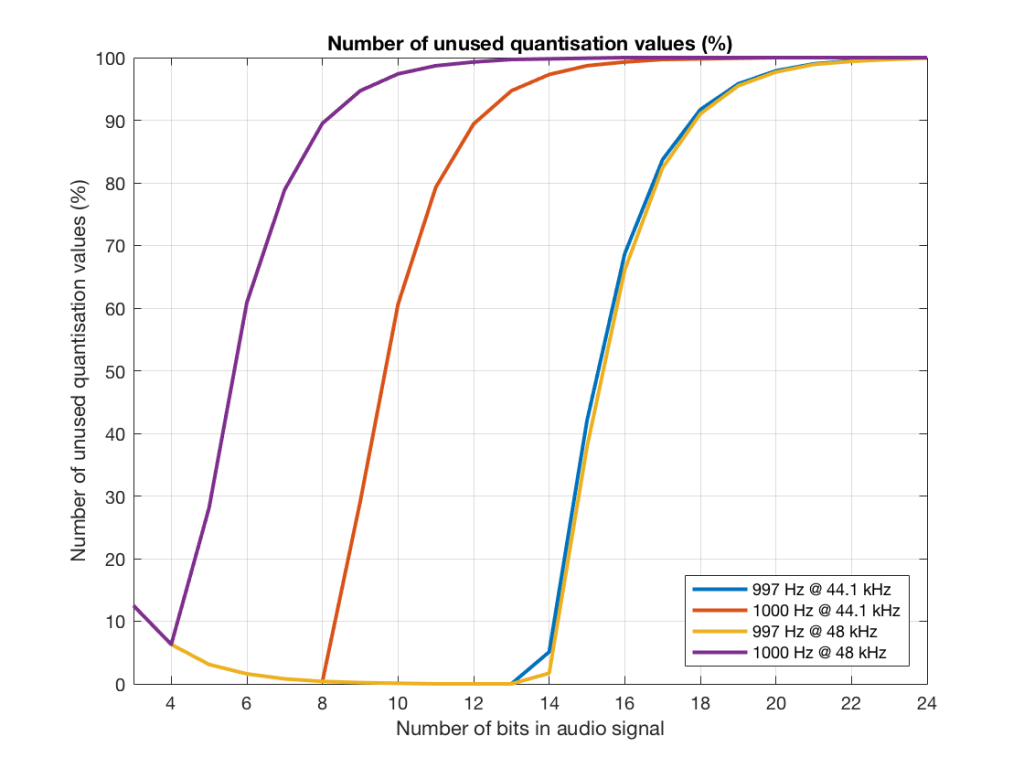
So, as you can see there, in a 16-bit system, even if you use a 997 Hz tone, about 70% of the total possible quantisation values are used.
Caveat
Of course, the signals that I used here were generated digitally, and did not include dither. If I had included proper dithering, then more of the quantisation values would have been used. However, the point of this posting was not to talk about correct ways of creating PCM signals – it was an attempt to explain why we use 997 Hz instead of 1 kHz when we test digital audio systems.
Sometimes, someone will use a plot to show the relative levels of different frequency bands in a signal. Even I have done this from time to time…. However, it’s important to have the skills to be able to read these plots with a little-more-knowledge-than-normal in order to not be distracted into thinking something that isn’t true.
One way to calculate the relative levels of frequency bands of a signal (whether it’s a measurement of a loudspeaker, a black box, or your favourite track on your favourite CD) is to so something called a “Fourier Transform”. This is a set of calculations that can be used to show how much energy there is in a signal, by frequency.
Typically, we do a Discrete Fourier Transform or “DFT” – although most people call it a Fast Fourier Transform or “FFT”. We will not discuss the difference between these things in this posting. I’ll just use the term “FFT” here, in order to be like everyone else…
(If you’d like to know how to do your own FFT’s by hand, this is one place to start learning…)
In order to give me something to analyse, I made a signal comprised of a sine tone with a frequency around 997 Hz. (I’ll explain at the end why it’s not exactly 997 Hz. I’ll also explain in another posting why I chose 997 Hz instead of a good-old-fashioned 1 kHz.)
I set that sine tone to have a level of -1 dB FS.
Then, I made some white noise and set its level to be exactly 80 dB below the level of the sine tone. In order to calculate this, I found the total RMS value of the noise signal, and used this to create a gain that makes it a level of -81 dB FS. (Just for the sake of being as pedantic as possible, the white noise that I created was the result of a “rand” function in Matlab, which, as you can see in this posting, has a rectangular probability density function.)
Therefore, I have an input that has a signal-to-noise ratio of 80 dB. (Note that this measurement does not use any band-limiting on the white noise… Typically a SNR measurement would apply some low pass filter to the noise.)
To keep things looking pretty on my graphs, I set the sampling rate to 65536 Hz (2^16).
Then, I pretended that this signal was coming in from some unknown device, and I do an FFT on it to find out the relative balance between the signal (the sine tone) and the noise (which I already “secretly” know is 80 dB lower)
If I do an FFT of 256 points on the signal (and therefore, I’m only looking at the first 256 samples of the signal – this is an important point that we’ll come back to later…), the result looks like Figure 1.
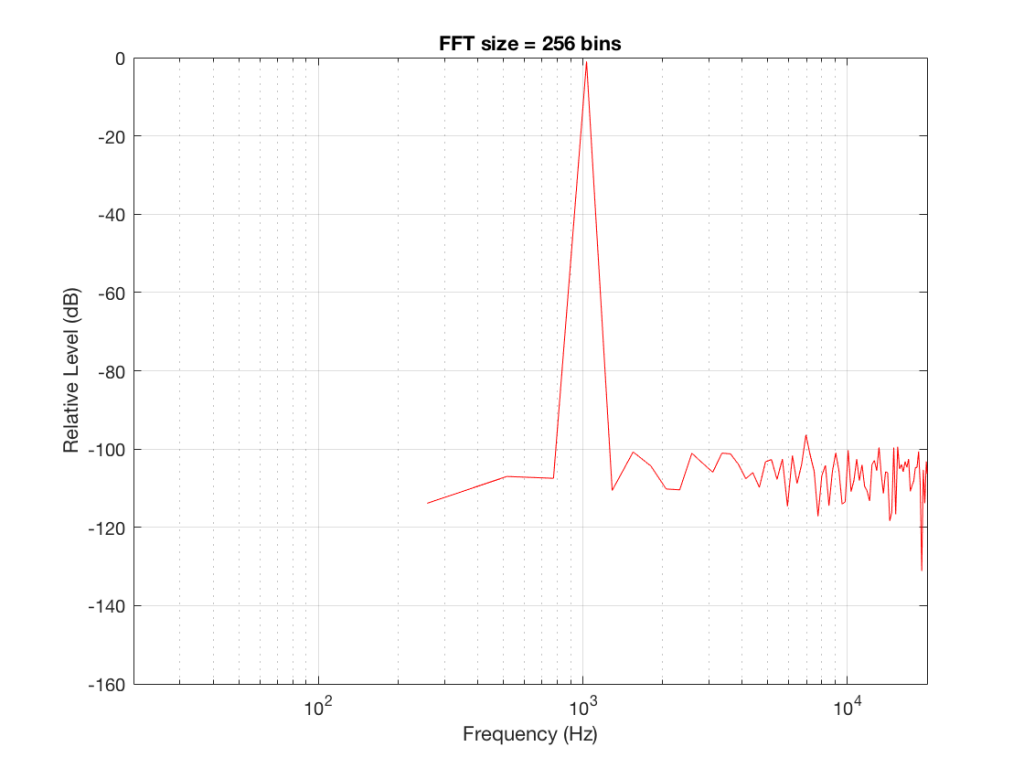
Note that the sine tone is a little higher than 997 Hz – but this is not really important. (the explanation is at the end!).
There are some things to notice here:
The first is that the plot does not extend lower than a frequency of 256 Hz. This is because the resolution of a 256-point FFT is 256 Hz – so, there is a “point” on the plot every 256 Hz – typically called a “bin” – since it contains information about the level of a collection of frequencies around its centre frequency. (If you’re new to FFT’s, don’t jump to the conclusion that the frequency resolution is equal to the length of the FFT. This is incorrect. The frequency resolution is equal to the sampling rate divided by the FFT length – 65536 Hz / 256 bins = 256 Hz.) Limiting the length of the FFT limits its resolution, which has an obvious impact when we plot the results on a logarithmic frequency scale.
The second is that, although the SNR of the signal is 80 dB, on the magnitude response, it appears that the noise is generally lower than -100 dB. This is not that difficult to believe, since the noise is spread over a wide frequency range – so, although any one frequency may, indeed, be more than 100 dB below the signal – the sum of the energy in all of those frequency bands totals more than any of the individual contributions. (In the same way that 1000 people can shout louder than 1 person – even if all 1000 people are, individually, shouting at the same level.)
One thing that is not obvious from the plot, but that we have to keep in mind is that this shows us the level of the different frequency ranges over the entire length of the signal (all 256 samples of it). However, the noise that I created that is part of that signal is exactly that – noise. Since it is noise, there is no guarantee that all frequencies are represented at the same level at any one time – in fact, they’re not. “White noise” has the characteristic of having equal probability of having the same level at all frequencies. But if 1000 people have equal probability of winning a lottery, that doesn’t mean than 1000 of them will win. In order to ensure that you actually get the same level at all frequencies, you would have to listen to white noise forever – and I’m not willing to wait that long…
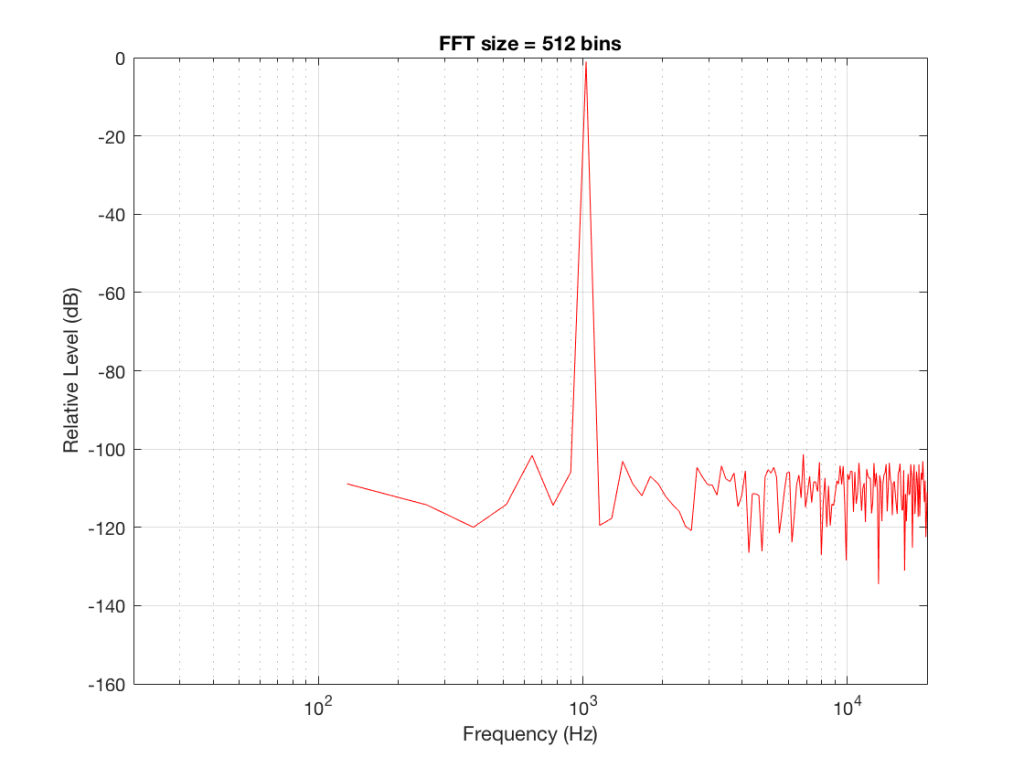
Figure 2 shows the same analysis done on the same signal, but with a 512-bin FFT instead. There, you can see that the the resolution of the plot is better – we have a bin or point every 128 Hz (remember 65536 Hz / 512 bins = 128 Hz). Also, the sine tone has the same level (-1 dB FS) but the noise, which we know is 80 dB lower, appears to be even lower than it does in Figure 1… Strange…
Let’s do some more FFT’s with more and more bins to see what happens…
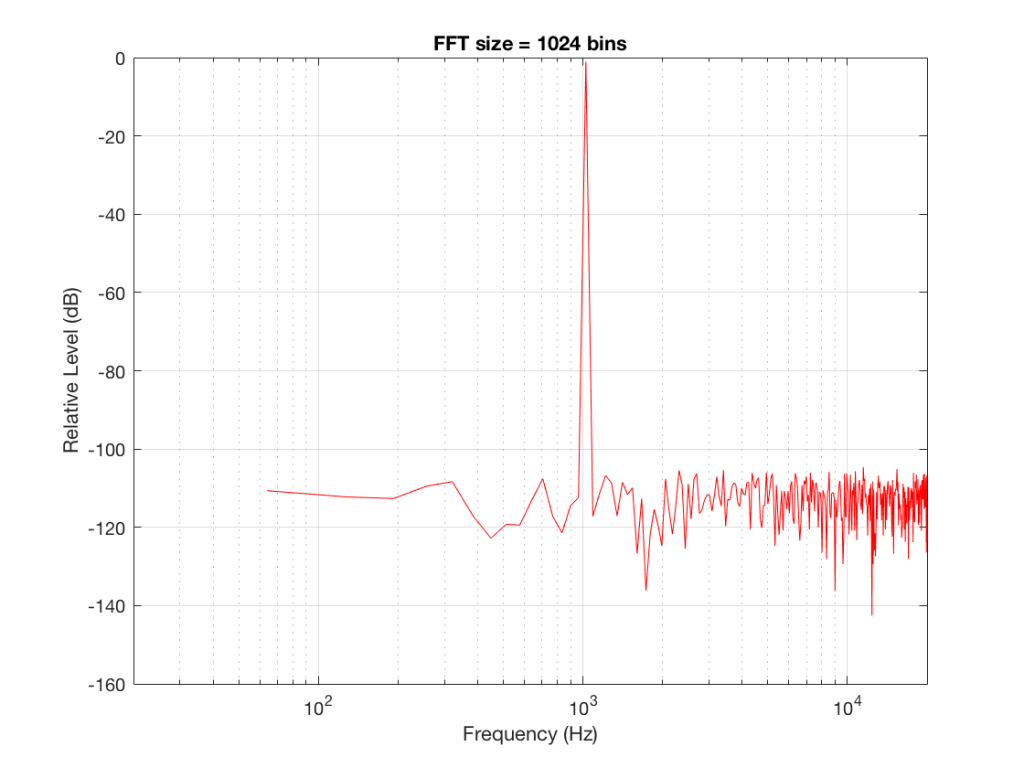
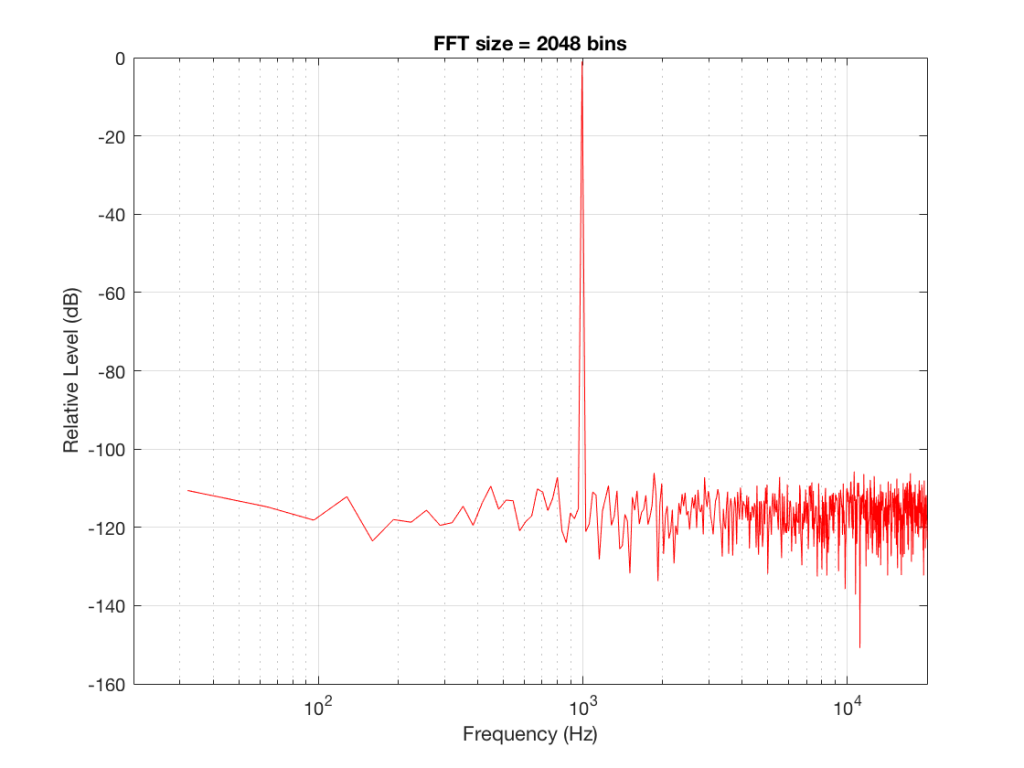
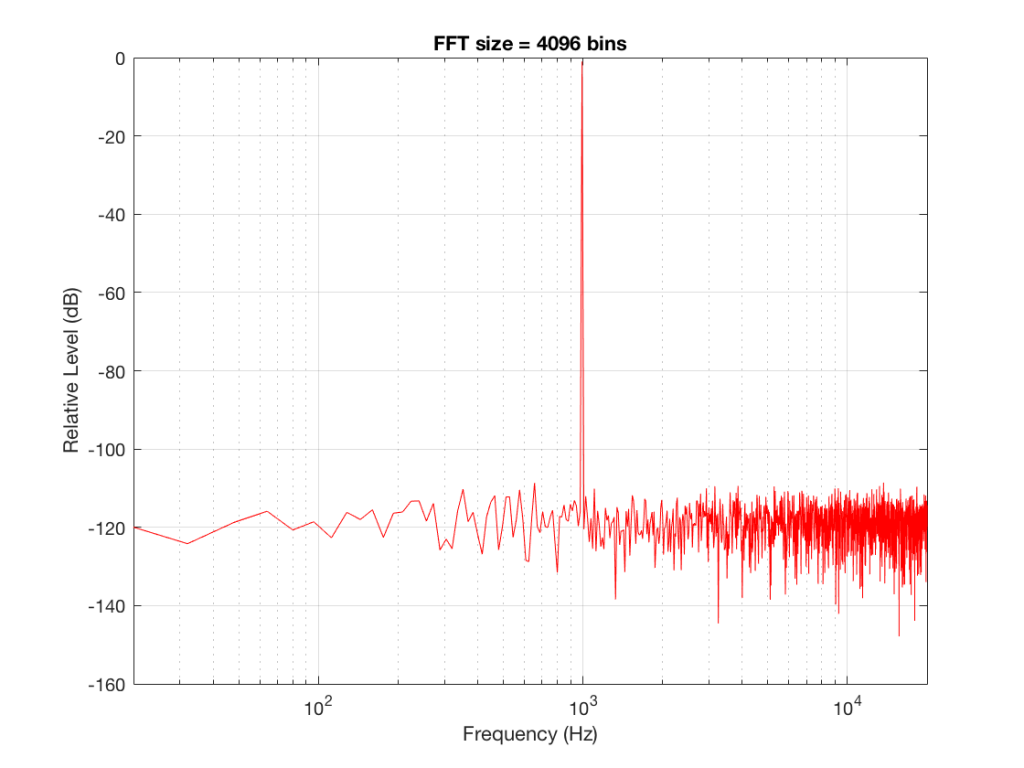
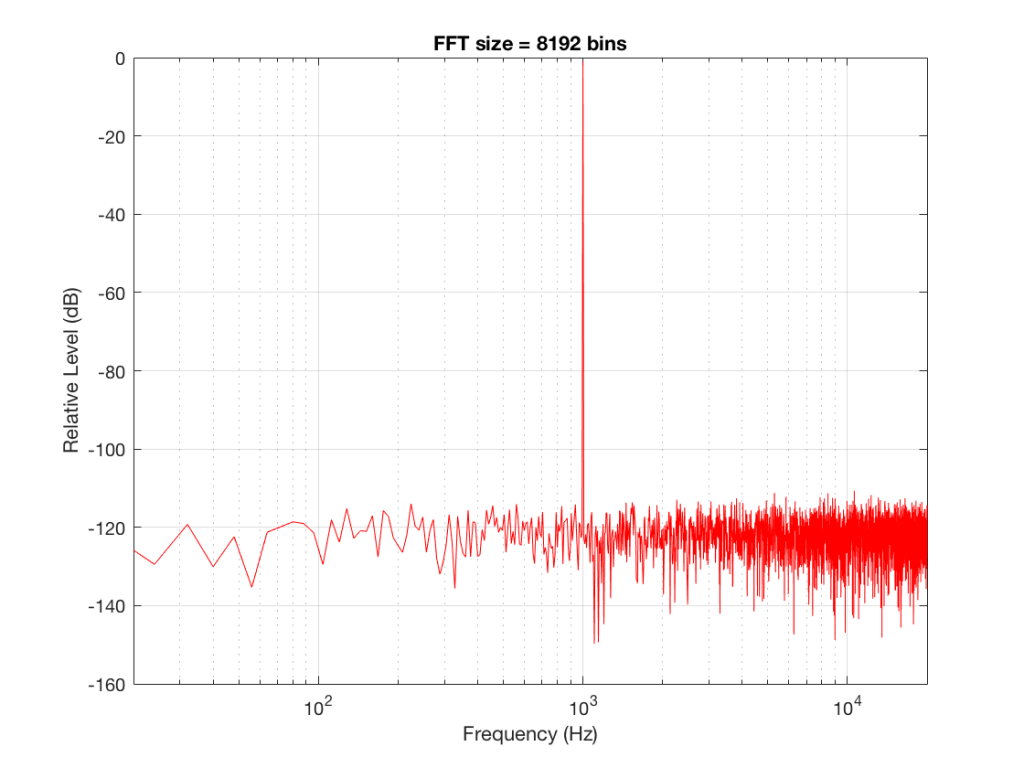
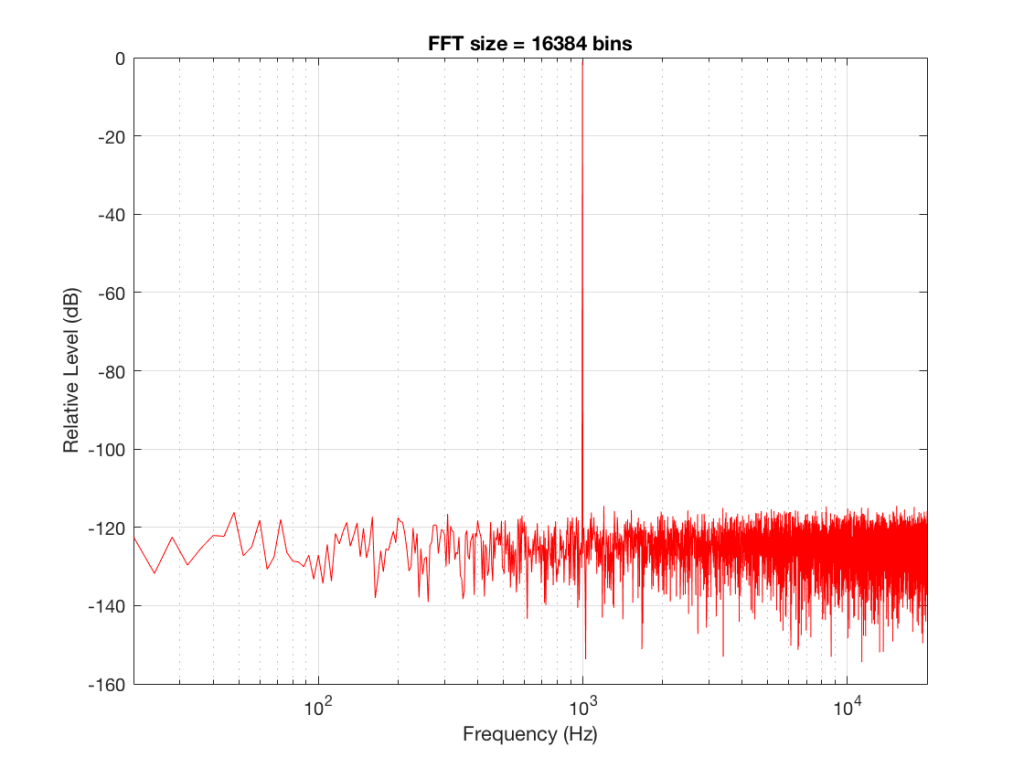
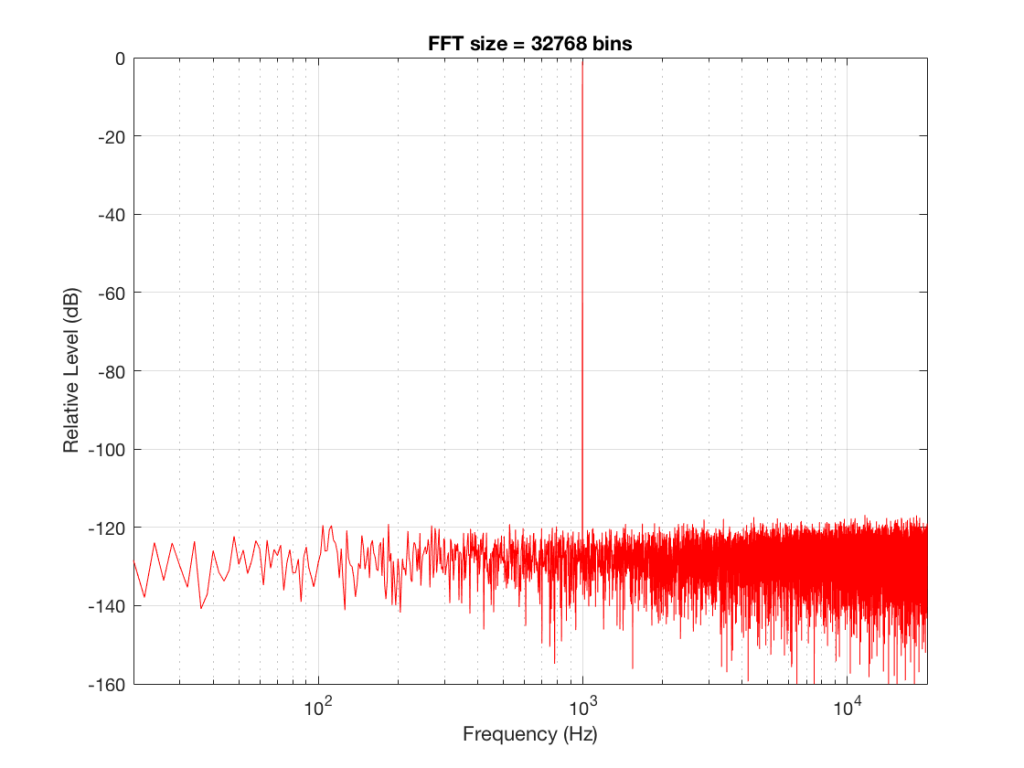
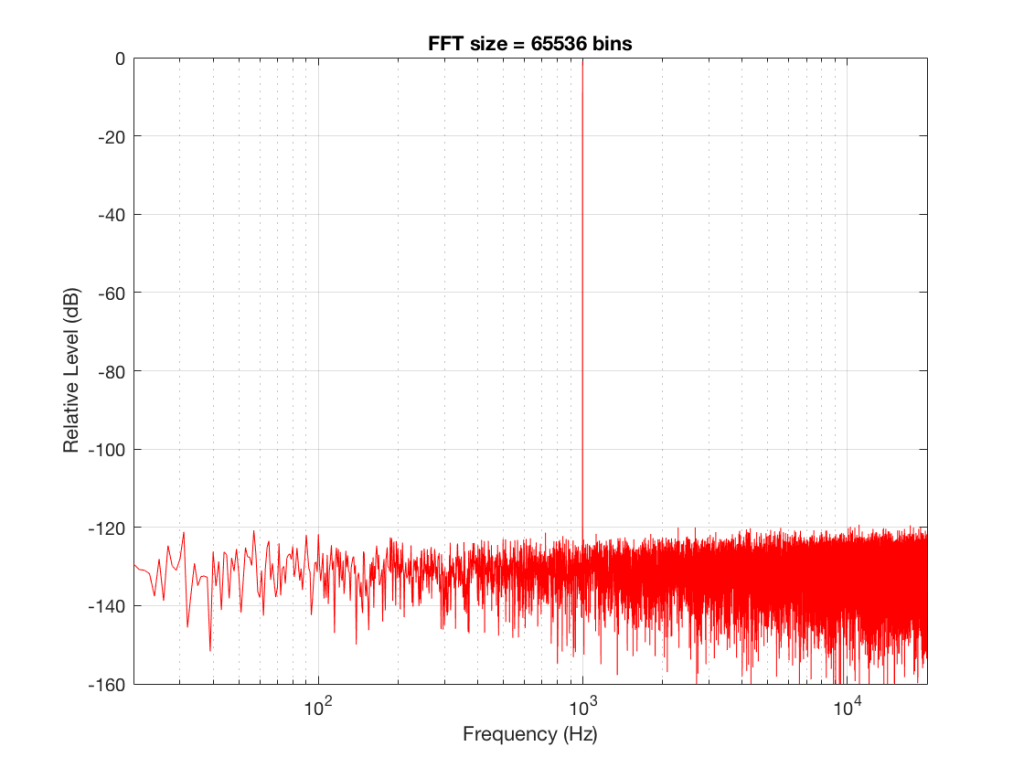
So, by going from a 256-bin FFT to a 65536-bin FFT, we appear to have dropped the noise floor by more than 20 dB.
Weird? No. Why?
Remember that every time we double the length of the FFT, we double the number of frequency bins in its output. So, that plot in Figure 9 has more individual frequencies contributing to add together to the same noise signal, 80 dB lower than the sine tone. (If you asked 1000 people to shout as loudly as 10 people, each individual in the larger group would have to be quieter to produce the same total output.)
The “punch line” here is that we cannot make a direct conclusion about the overall Signal-to-Noise ratio of the signal by looking at any of the plots above. Of course we can say that the “signal” (the sine tone) is obviously louder than the noise – by a lot. But we can’t be much more detailed than that.
So, if someone jumps between a SNR number and a spectral plot like the ones above, in an effort to convince you of something, be very careful about being led down a garden path.
Some extra information:
We also have to remember that, although the signal that I used to make these graphs was initially the same, the actual signal that was used by each of the FFT’s was different. This is because, by default, the length of the signal used by an FFT calculation is the same as the number off bins in the FFT. So, for example, a 256-bin (or 256-point) FFT only uses 256 samples as its input. A 32768-point FFT uses 32768 samples (the first 256 of which were the ones used by the 256-point FFT). So, for example, if you load a recording of Britney Spears singing “Toxic” into Matlab, and you type the command FFT(toxic, 256) – you’ll get a 256-bin FFT of the first 5 .8 milliseconds (256 samples) of the recording – not a representation of the spectral content of the entire song.
Initially, I started out by saying that I would use a 997 Hz sine tone. This might look a little weird because it’s not a nice number like 1000 Hz. There’s a good reason for this, and I’ll write a posting about it some other day.
Then, I said that it’s not really 997 Hz – I moved it a little. This is because I wanted the frequency of my sine tone to land exactly on one of the bins of my FFT. So for example, in the case of the 256-bin FFT, I had a frequency resolution of 256 Hz – so my bins are at the following:
256 Hz
512 Hz
768 Hz
1024 Hz
1024 Hz is the closest value to 997 Hz that occurs in the sequence so I used that instead. If I had kept the sine tone fixed at 997 Hz, the plots would not have looked as pretty, because the information about its level would have “leaked” or “been spread out” into the adjacent bins. So, instead of a nice clean spike, we would have seen a big, round bump.
Let’s talk about the subject of noise. To begin with, we have to agree on a definition, which might become the biggest part of the problem. For normal people, going about their daily lives, “noise” is a word that usually means “unwanted sound”, as the Grinch explained, just before hitching up his dog to a sleigh:
However, “noise” means something else to an audio professional, who is consequently not “normal” and does not have a life – daily or otherwise.
When an audio professional says “noise”, they mean something very specific – “noise” is an audio signal that is random. For example, if the noise signal is digital, there would be no way to predict the value of the next sample – even if you know everything about all previous samples.
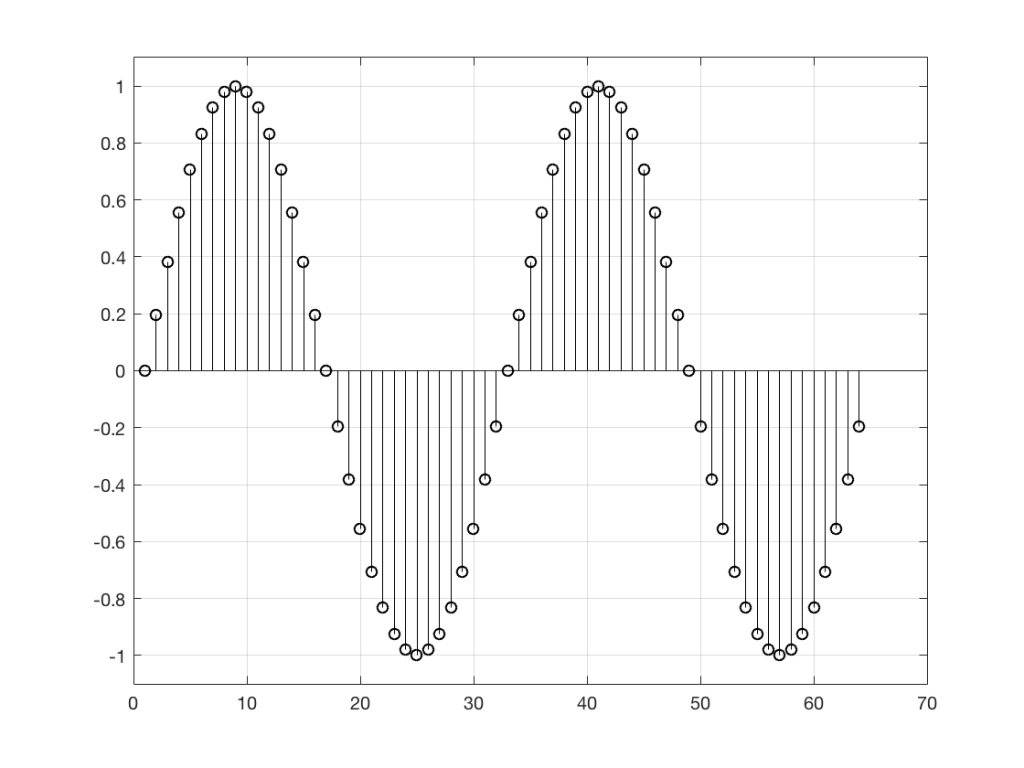
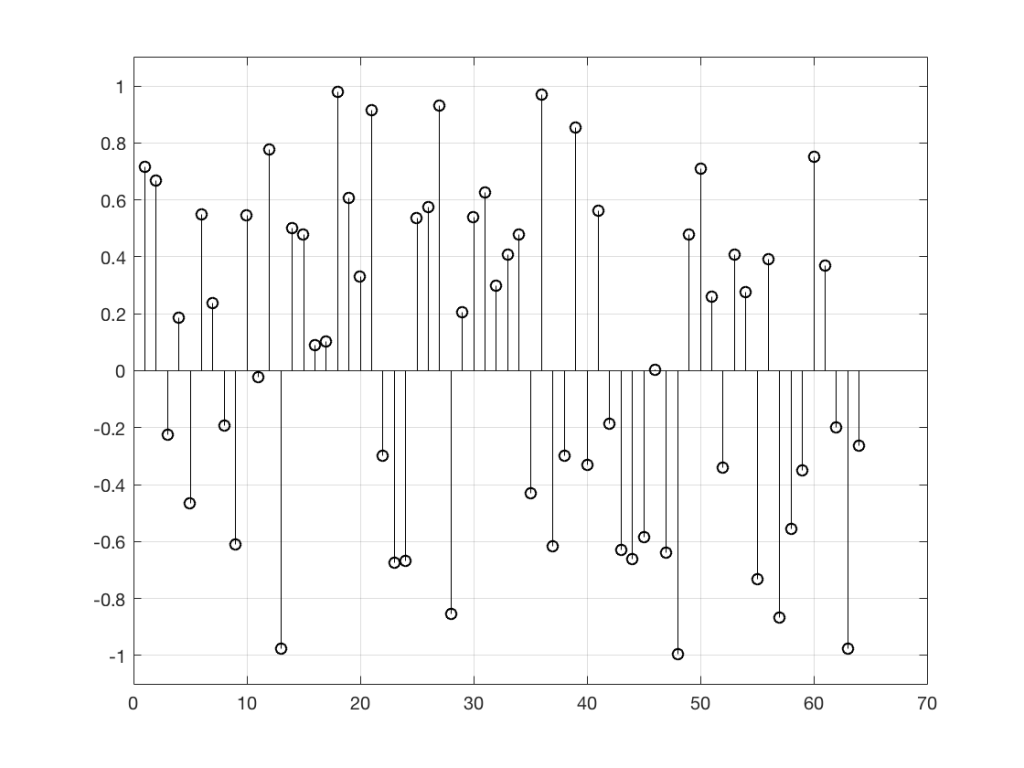
So, “noise”, according to the professionals, is a signal made of a random sequence. However, we can be a little more specific than this. For example, in order to make the noise plotted in Figure 2, above, I asked Matlab to generate 64 random numbers between -1 and 1 using the code
rand(1,64)*2-1
So, although this will generate random numbers for me (we’ll assume for the purposes of this discussion that Matlab is able to generate truly random numbers… actually they’re “pseudorandom” – but let’s pretend for today…), there are some restrictions on those values. No matter how many random values I ask for using this code, I will never get a value greater than 1 or less than -1.
However, if I used a slightly different Matlab function – “randn” instead of “rand”, using the following code
randn(1,64)
I would get 64 random numbers, but they are not restricted as my previous bunch were, as you can seen in Figure 2a, below.
Again, it’s impossible to guess what the next value will be, but now you can see that it might be greater than 1 or less than -1 – but it will more likely to be closer to 0 than to be a “big” number.
So, Figures 2 and 2a show two different types of noise. Both are random numbers, but the distribution of the numbers in those two sequences are different.
To be more specific:
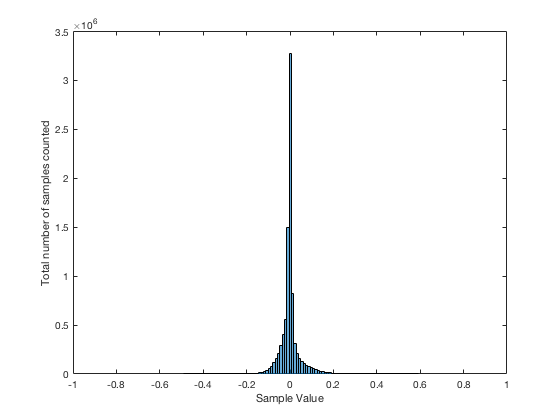
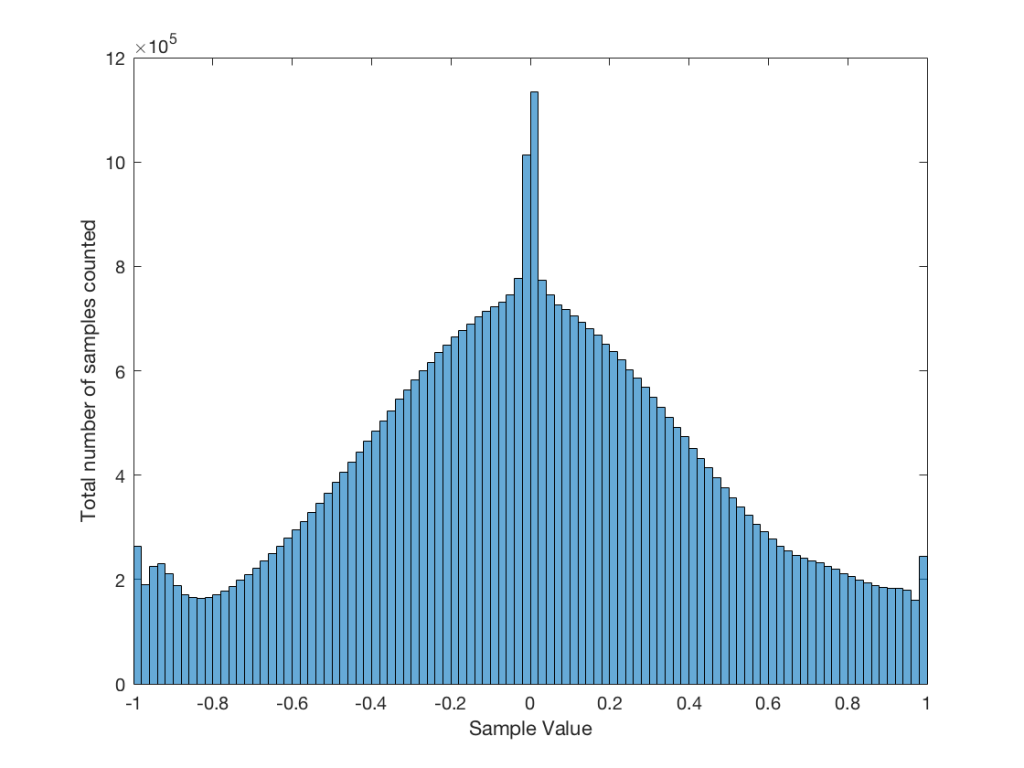
Let’s use the “rand(1,1000000)*2-1” function to make a sequence of 1,000,000 samples. We know that this will produce values ranging from -1 to 1. So, we’ll divide this range into 100 steps (-1.00 to -0.98, -0.98 to -0.96, -0.96 to -0.94, … and so on up to 0.98 to 1.00 – I know, I know, there’s some overlap here, but I didn’t want to use a bunch of less than or equal to symbols… The concept is the important point here… Back off!). For each of those divisions, we’ll count how many of the 1,000,000 samples fall inside that smaller range, and we’ll plot it. This is shown in Figure 3a.
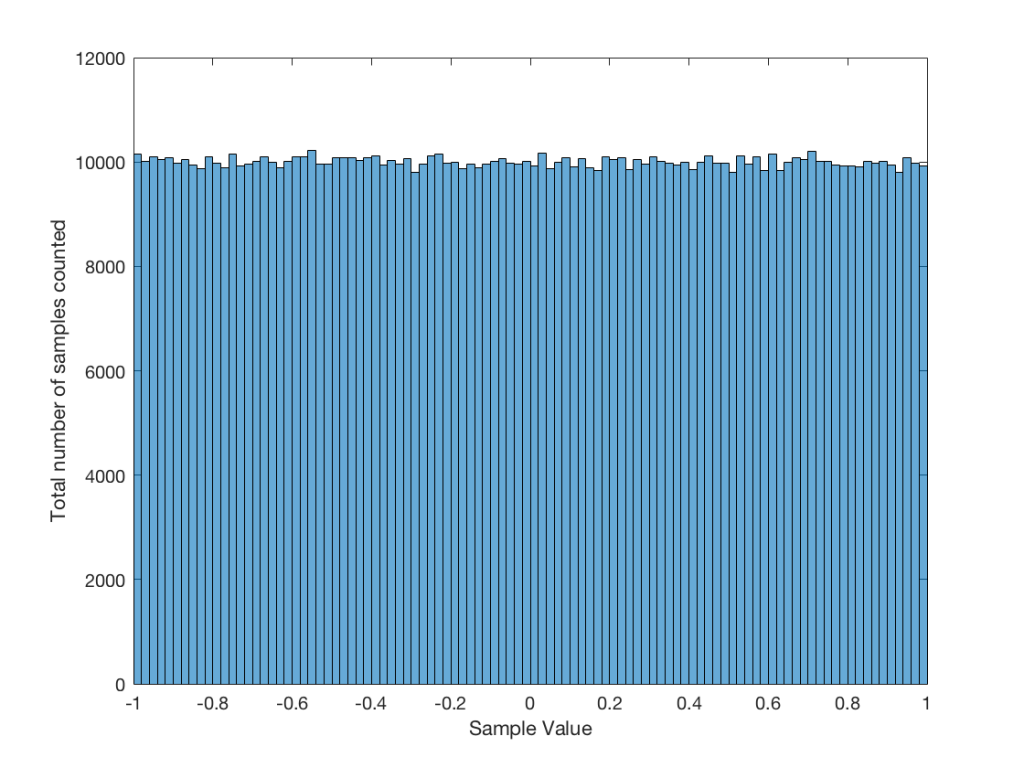
As you can see in Figure 3a, there are about 10,000 samples in each “bin”. This means that about 10,000 samples have a value that fall within each of the smaller slices of the total range. Also, if I added up the values of all 100 of those numbers plotted in 3a, I would get 1,000,000, since that’s the total number of values that we analysed.
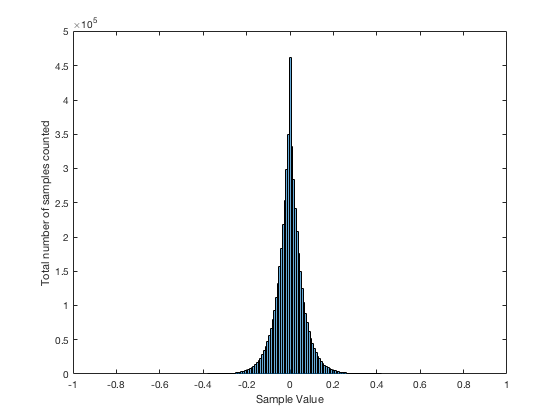
If I do the same thing to the numbers coming out of the other function: “randn(1,1000000)” it would look very different. As we already saw, the numbers can be outside the range of -1 to 1, and they’re more likely to be around 0 than to be far away from it. This can be seen in Figure 3b.
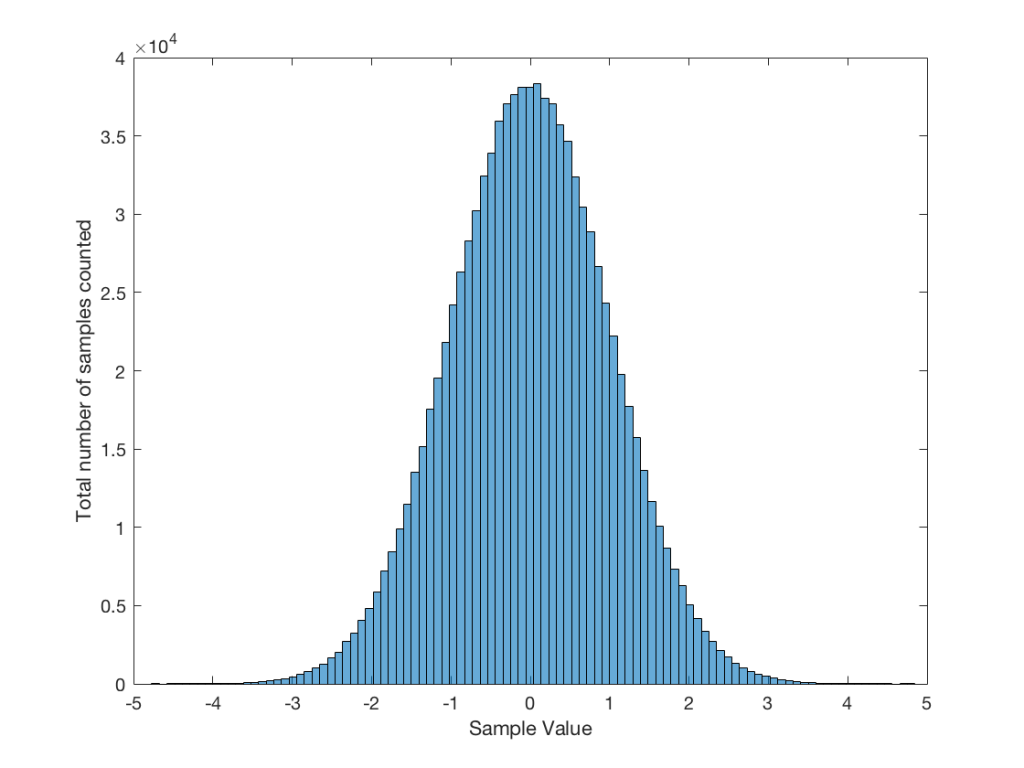
Just to clean up a loose end – there are official terms to describe these differences. The noise plotted in Figure 2 has what is called a “rectangular distribution” because a plot of the distribution of the values in it (if we measure enough sample values) eventually looks like a rectangle (a blue rectangle, in the case of Figure 3a). The noise plotted in Figure 2a has a “normal distribution”, as can be seen in the bell-like shape of the plot in Figure 3b. There are many other types of distributions (for example, rolling 2 dice will give you random numbers with a “triangular distribution”), but we’ll leave it at 2 for now.
So, we’ve seen that we can have at least two different “types” of random number sets – but let’s do a little more digging.
Here’s where things get a little interesting. If I take the 1,000,000 samples that I used to make the plot in Figure 3a and I pretend it’s an audio signal, and then calculate the frequency content (or spectrum) of the signal, it would look like the green plot in Figure 4a, below. If I did a frequency analysis of the signal used to make the plot in Figure 3b, it would look like the red plot.
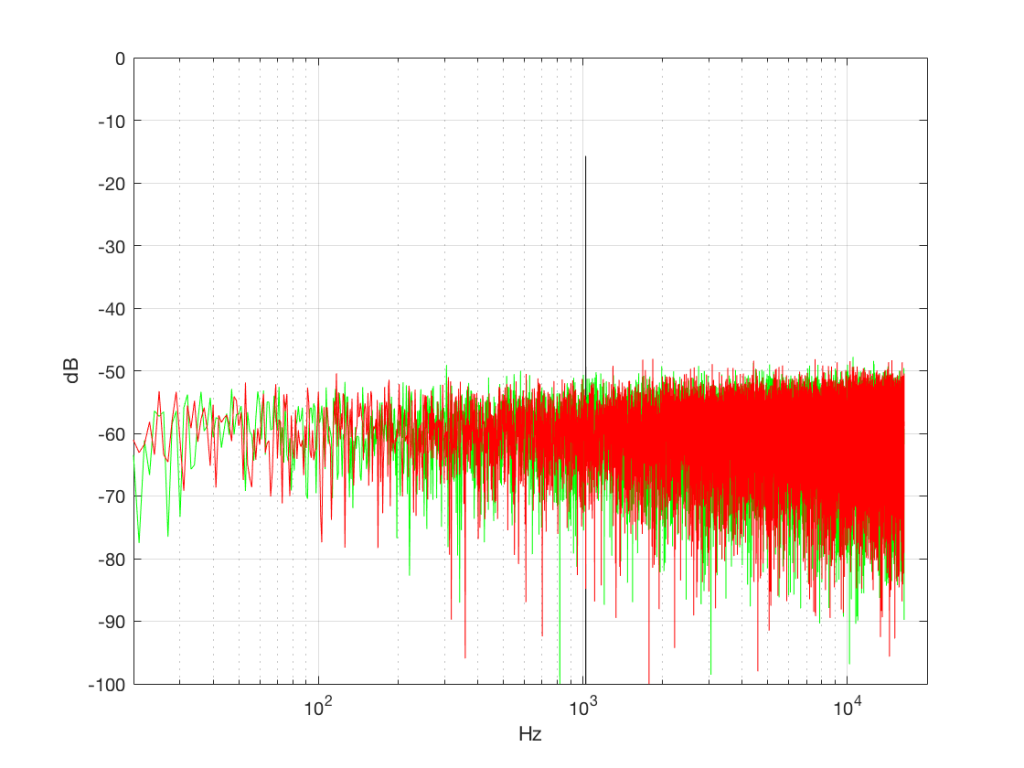
What’s interesting about this is that, basically speaking, the two signals, although they’re very different, have basically the same spectra – meaning they have the same frequency content, and therefore they’ll sound the same. This is really evident if I smooth these two plots using, for example, a 1/3 octave smoothing function, as is shown below in Figure 4b.
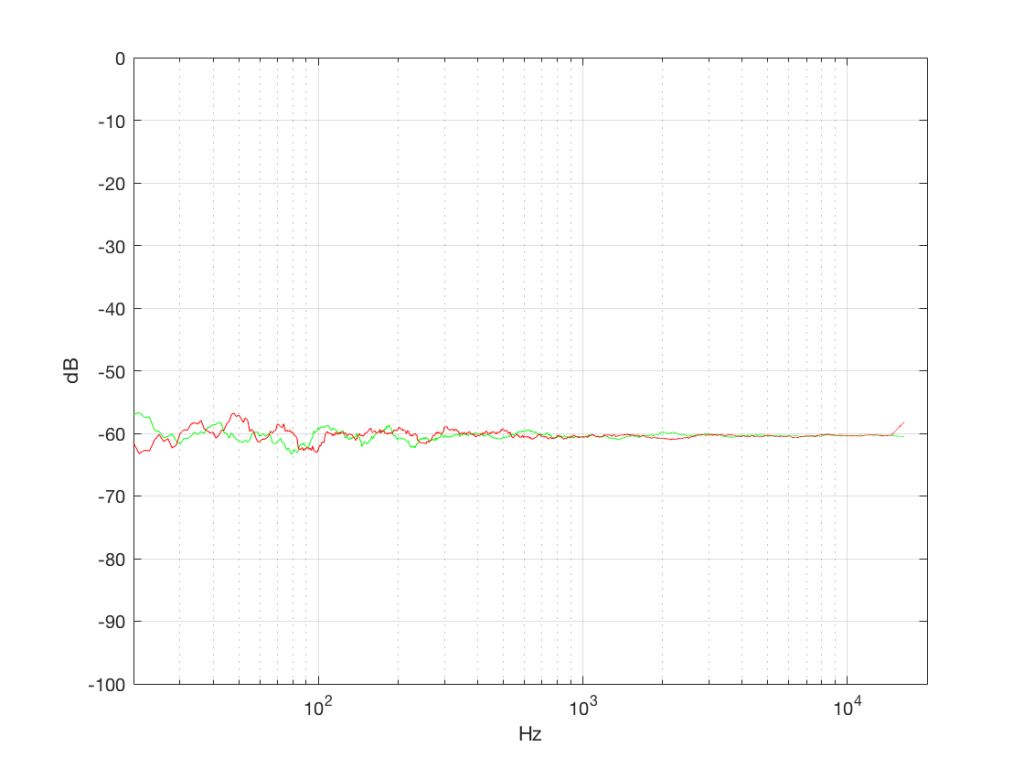
As you can see there, the very fine peaks and dips in the response shown in Figure 4a, when averaged, smooth to the flat response shown in Figure 4b.
Now we have to clear up a couple of issues…
The first is that, as you can see in the plot above, the spectrum of both random signals (both noise generators) is flat. However, due to the way that I did the math to calculate this, this means that we have an equal amount of energy in equal-sized frequency ranges throughout the entire frequency range of the signal. So, for example, we have as much energy from 20-30 Hz as we do from 1000-1010 Hz as we do from 10,000 – 10,010 Hz. In other words, we have equal energy per Hz. This might be a little counter-intuitive, since we’re looking at a semilogarithmic plot (notice the scale of the x-axis) but trust me, it’s true. This means that, in both cases, we have what is known as a “white noise” signal – which is a colourful way of saying “noise with an equal amount of energy per Hz”.
The second thing is that I just lied to you. In order to get the pretty plots in Figures 4a and 4b, I had to take long signals and analyse how much energy we got, over a long period of time. If I had taken a shorter slice of time (say, 100 samples long) then the spectra plots would not have looked as pretty – or as flat. For example, if I just take the first 100 samples of both of those noise generator outputs, and calculate the spectra in those, I get the plots in Figure 4c, below.
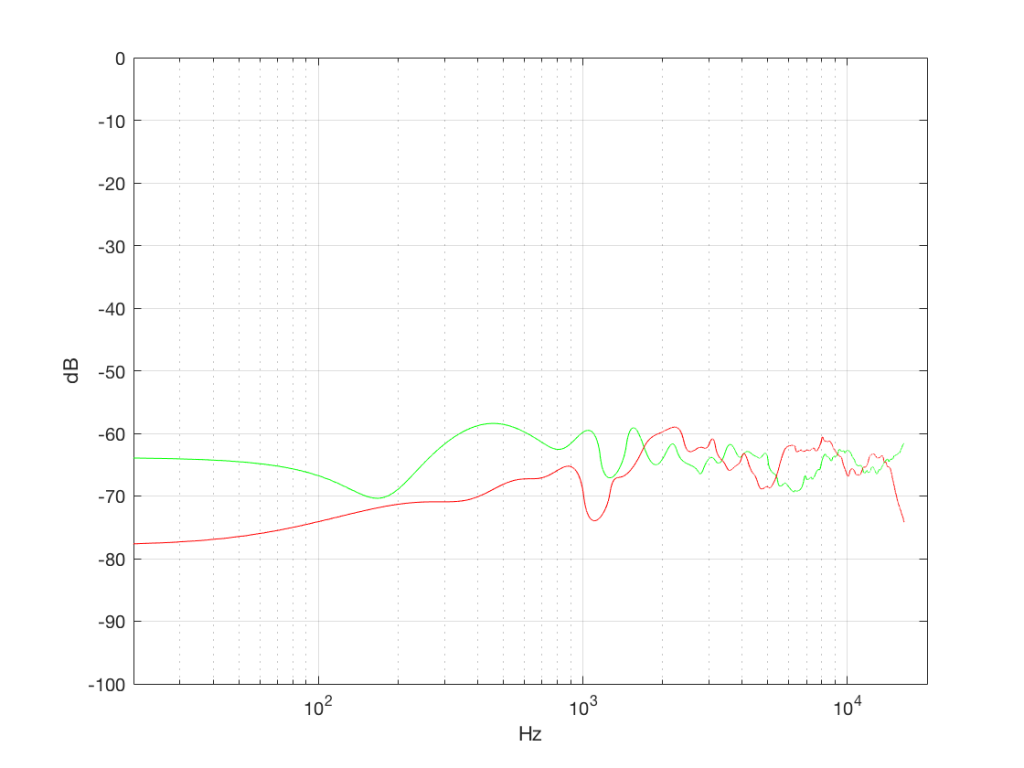
Notice that these plots do not look nearly as flat – even though I’ve smoothed them with a 1/3 octave smoothing filter again. Why is this?
Well, the problem is probability. Since the two signals are random, there is no guarantee that all frequencies will be contained in them for any one little slice of time. However, there is an equal probability of getting energy at all frequencies over time. So, in a really strange universe, you might get all frequencies below 1000 Hz for one second, and then all frequencies above 1000 Hz for the next second – over two seconds, you get all frequencies, but at any one moment, you don’t.
What this means is that “white noise” doesn’t necessarily contain energy at all frequencies equally – unless you wait for a long time. If you listen for long enough, all frequencies will be represented, but the shorter the measurement, the less “flat” your response.
Just for the purposes of comparison, let’s also find out what the distribution of values is for a sine wave – since this might be interesting later… This is shown in Figure 5, below.
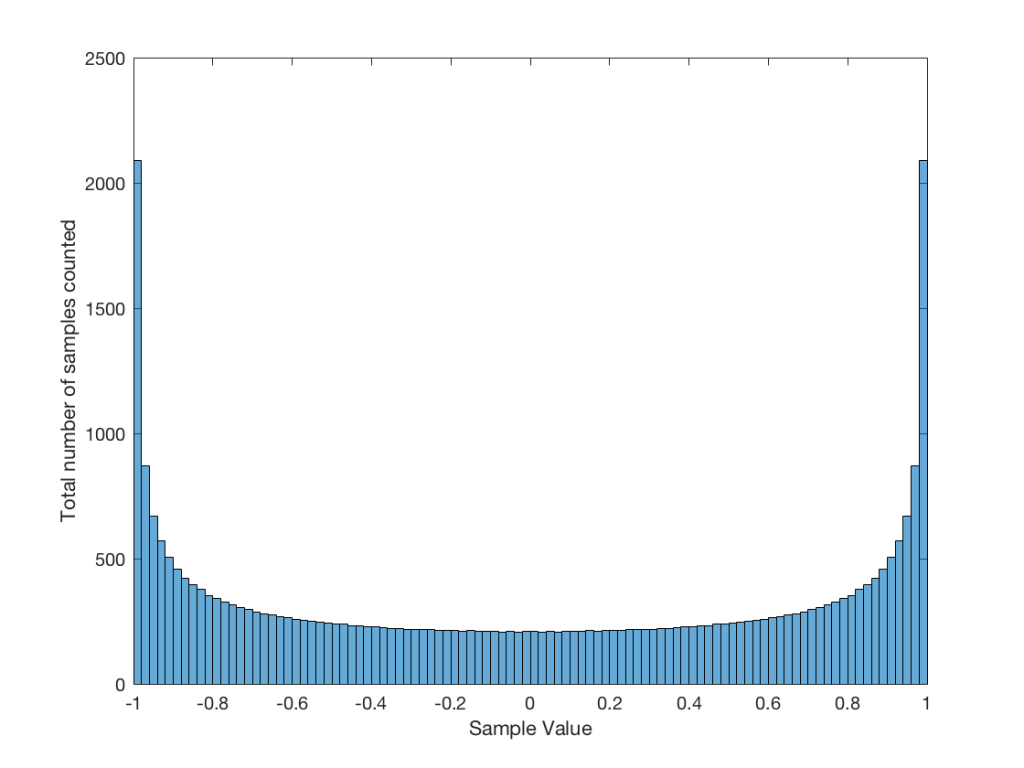
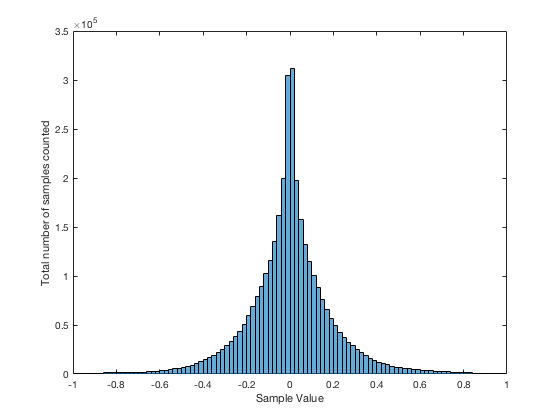
It may be interesting to note that “normal” sounds like music and speech have distributions that look much more like Figure 3b than like Figure 5, as is shown in the examples in Figures 6, 7, and 8. This is why you shouldn’t necessarily use a sine wave to measure a piece of audio equipment and draw a conclusion about how music will sound…
If I play the first kind of white noise (the one shown in Figure 2) and measure how loud it is with a sound pressure level meter, I’ll get a number – probably higher than 0 dB SPL (or else I can’t hear it) and hopefully lower than 120 dB SPL (or else I’ll probably be in pain…). Let’s say that we turn up the volume until the meter says 70 dB SPL – which is loud enough to be useful, but not loud enough to be uncomfortable.
Then, I switch to playing the other kind of white noise (the one shown in Figure 2a) and turn up the volume until it also measures 70 dB SPL on the same meter.
Then, I switch to playing a sine wave at 1 kHz and turn up the volume until it also reads 70 dB SPL.
If I were to compare what is coming into the loudspeaker for each of those three signals, after they have been calibrated to have the same output level, they would look like the three signals in Figure 9.
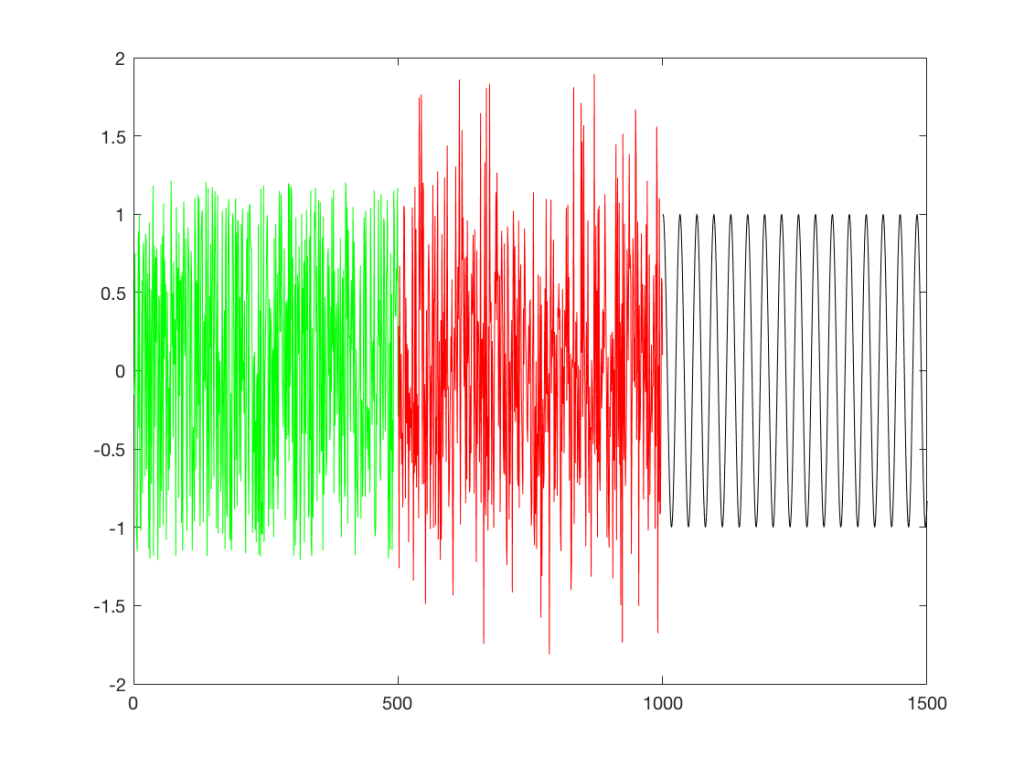
These will all sound roughly the same level, but as you can see in the plot in Figure 9, they do not have the same PEAK level – they have the same average level – averaged over time…
However, if we were to do a frequency-dependent analysis of these three signals, one of these things would not look like the others… Check out Figure 4a, which I’ve copied below…
Notice that, in a frequency-dependent analysis, the sine wave (the black line sticking up around 1000 Hz) looks much louder (35 dB louder is a lot!) than the green plot and the red plot (our two types of white noise). So, even though all three of these signals sound and measure to have roughly the same level, the distribution of energy in frequency is very different.
Another way to think about this is to say that each of the three signals has the same energy – but the sine wave has all of it at only one frequency all the time – so there’re more energy right there. The noise signals have the energy at that frequency only some of the time (as was explained above…).
ANOTHER way to think about this is to put a glass of water in the bottom of an empty bathtub. If the depth of the water in the glass is 10 cm – and you pour it out into the tub, the depth of the water will be less, since it’s distributed over a larger area.
As you can see in the title of this posting, this is “Part 1″… All of this was to set up for Part 2, which will (hopefully) come next week. As a preview: the topic will be the use (and mis-use) of weighting functions (like “A-weighting”) when doing measurements…