Part 1
Part 2
Part 3
Part 4
Part 5
Part 6
Part 7
Part 8a
Part 8b
Part 9
Part 10
If you you get an audiometry test done, you’ll be shown into a small room, about the size of a public bathroom stall. Someone will put a pair of headphones on you, and pass you a small handle with a button. Your instructions are to press the button if you hear a tone. Then the audiometrist will leave the room, closing the door, and you’ll suddenly realise that if there’s any noise in this room, it’s because you’re making it.
Then you hear a beep in your left ear. You press the button. You hear a quieter beep. Press. Quieter beep. Press…. …. …. Beep, press… …. …. …. Beep, press…. New frequency beep, loud again. Press… and so on.
What’s happening here is that you’re presented with a sine tone at some frequency, probably loud enough for you to hear. You press. The tone gets quieter, and you press again. Eventually, the tone is so quiet that you cannot hear it (this is normal) so you don’t press. So, the tone gets louder, and you press. Then it gets quieter again, until you can’t hear it again.
By crossing over that threshold of “can hear” and “can’t hear” a couple of times, the audiometrist finds out whether or not you got lucky… If you bottom out at the same level a couple of times in a row, then that’s your threshold of hearing at that frequency in that ear.
The frequency changes (usually by 1 octave, but sometimes less), and the whole process is repeated.
If you get a full test done, then this is probably done at 9 frequencies (250, 500, 1k, 1.5k, 2k, 3k, 4k, 6k, and 8kHz) in both ears individually – 18 tests in all.
You’ll then be given a sheet of paper, or at least shown a plot of your hearing threshold. Typically, if you have “normal” hearing (whatever that means) your thresholds will all be sitting on a horizontal line marked 0 dB. If you’re “better than normal” then you get a negative score, if you’re “worse than normal” you get a positive score.
What does this mean?
Let’s start over.
If a lot of people do this test, and we only test at 1 kHz, we’ll find out that, after the results are averaged, the group can hear the 1 kHz sine tone when the change in air pressure at the ear entrance is 20 µPa. We’re not going to talk about what this means other than to say that “sound is a change in air pressure over time, and that pressure is measured in pascals, abbreviated Pa”. Needless to say, 20 µPa is pretty quiet, since it’s the quietest sound a group of people can hear at 1 kHz when you take their average.
If you did that test at a much lower frequency, you would find out that people aren’t as good at hearing quiet sounds. In other words, at 100 Hz, the sine tone has to be louder than 20 µPa for people to hear it.
The same is true if you repeated the test at a much higher frequency – say, 10,000 Hz.
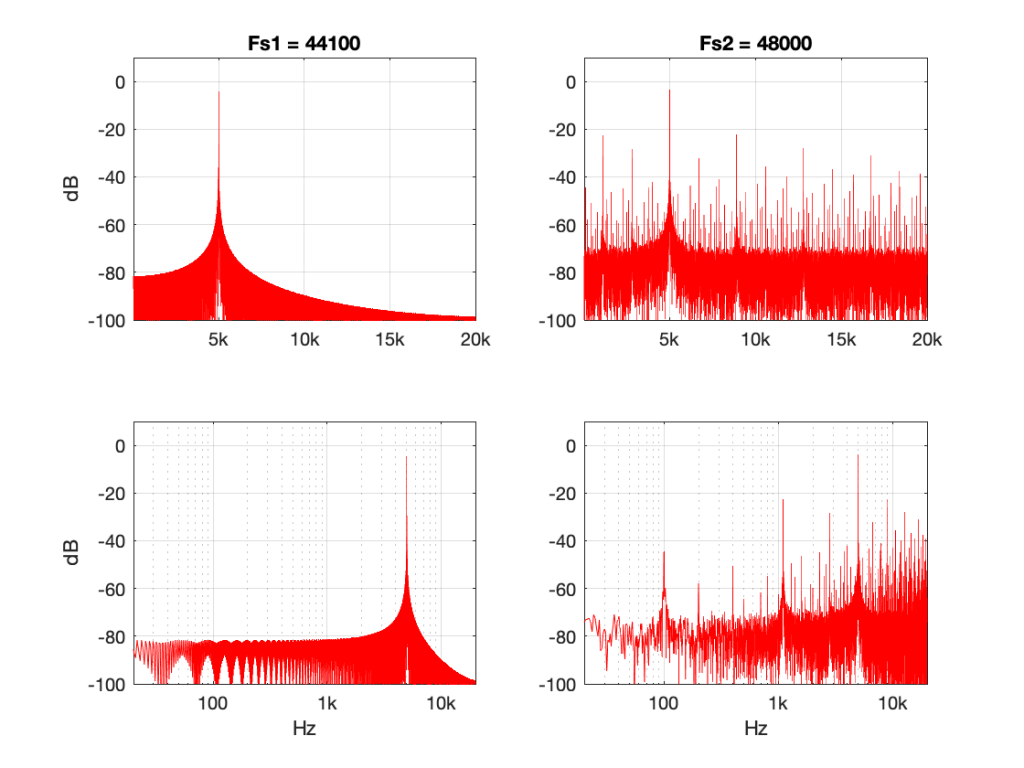
If you did this test at a lot of frequencies, then you’d find out that, on average, the threshold of hearing for a human follows the bottom red line of the plot in Figure 1, borrowed from Wikipedia.
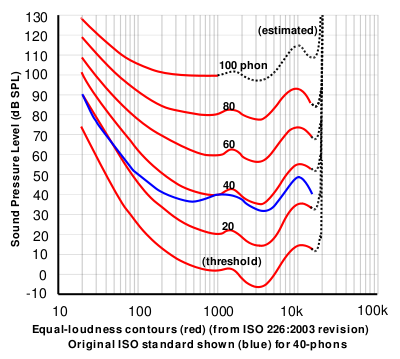
That bottom plot shows the threshold of hearing for different frequencies, plotted in dB SPL. Notice that, at 1 kHz, the line is at 0 dB SPL. This is because 0 dB SPL is defined to be the average threshold of hearing of a human at 1 kHz, which is 20 µPa. So, it’s not an accident…
Looking at that plot, you can see that, in order to hear a sine tone at 20 Hz, the tone has got to be more than 70 dB louder (that’s a LOT louder). So, a microphone “sees” a 73 dB SPL, 20 Hz sine tone as being louder than a 0 dB SPL, 1 kHz sine tone – but as far as you’re concerned, they’re both “the quietest sound you can hear” – therefore, they’re the same level.
If we take that threshold of hearing curve, and we play tones at those levels for those frequencies, then you should “just be able to” hear them. So, we’ll call those levels “0 dB” – since it’s the same as what is expected of you.
In other words, the piece of paper you got from the audiometrist tells you how much above or below that red threshold of hearing YOU sit.
Now, let’s back up a bit.
- I said that, in your test, you only went up to 8 kHz. This is because, above that (and possibly even before that) the headphones might not be trust-worthy, and even a tiny movement (say a couple of millimetres) in the position of the headphones will have a (relatively) big effect on the level at your eardrum. So, rather than get people worried about losing their hearing at 20,000 Hz (when, in fact, they were actually just wearing the headphones 1 mm too far forward), you won’t get tested.
- Notice how variable that threshold of hearing line is. There are big changes in level over the “audible” frequency range.
- Remember that the threshold of hearing curve is an AVERAGE of a lot of people. Just like no one has 2.6 children, no one has this exact response. And, if you are some freak of nature and you DO have exactly that response, you don’t for long… we all get old…
- Notice how that threshold of hearing curve only goes up to about 16 kHz, and above that it says “estimated”. See point #1.
Now, you should know that your ability to hear a sine tone at some frequency is defined as how your ability compares to an expectation based on an average, within a relatively small frequency band: 250 to 8 kHz.
Then you look at a textbook or you read a website that says “humans can hear from 20 Hz to 20 kHz”, which is not enough information to be either true or false… It’s like saying “humans are usually between 0 and 10 m tall” which is also sort of true, but also adequately vague to be potentially worse-than-useless information.
The truth is, unfortunately, much more complicated… However, it’s fair to say that, in order for you to just hear a sine tone at 20 kHz, it would have to be much, much louder than one at 1 kHz. In fact, if I played a 20 kHz sine tone loud enough for you to hear, measured that level, and then played a 1 kHz sine tone for you at the same level, you’d probably punch me – after you had passed out due to the pain, woken up, hunted me down, and found me… (I’d already have run away by then….)
So what?
We humans like nice, tidy, answers. “It will rain tomorrow” is preferable to “there is a 70 – 80% chance of scattered showers in the afternoon tomorrow”. We even get mad when the information is correct, but we interpret it tidily… For example, we’ll complain about getting rained on in the middle of our hike, when there was only a 10% chance of rain. On the other hand, if there was a 10% chance of winning 1 Million dollars in the lottery, we’d all buy a ticket.
Anyways, once-upon-a-time, when the committee for inventing the compact disc was holding meetings, they said “what should the sampling rate be?” and someone said “at least 40 kHz, because we can hear up to 20 kHz”. (The reason it’s 44100 is related to the fact that the bits were stored as black and white stripes on video tape, and NTSC and PAL come close to meeting each other close to that number, when you look at the numbers of lines per field and frames per second.)
Of course, like any first-generation thing, digital recording equipment wasn’t very good at the start (back around 1980 or so) – so the first DDD recordings that were released on CD sounded… well…. weird. There was quantisation distortion because they hadn’t figured out dither yet, only 12 or 13 of the bit values were working properly on the ADC’s, the anti-aliasing filters were implemented as analogue circuits, so they let some stuff through that aliased, and they rang (“sang along”) with the signal at a high frequency… All of that added up to “weird” – possibly even “bad”. Then, people who had good equipment (high-end turntables or, even better, 1/4″ tape running at 30 ips) listened to this new format, decided it was bad, and that was that.
Some of them asked “why is is bad?” and one answer they came up with was the band limiting… If the system can’t capture or store or play materials above 20 kHz, then it’s useless… Right? Maybe…
Then, instruments were put in front of measurement microphones and spectra were measured – and the proof was in. Trumpets with harmon (wah-wah) mutes, when pointing directly at the microphone, contain harmonics as high as 50 kHz! This must explain why CDs sound bad! Right? Maybe…
Then Rupert Neve did a demo at an AES (Audio Engineering Society) convention where he played people two tones. Both were at 7 kHz, but one was a sine wave and the other was a square wave (at some level). The question was: have a listen and tell me which is which. The results were the same as if everyone was just guessing. (Remember that, in order to make a square wave, you need to add odd harmonics – so the lowest-frequency content difference between a 7 kHz sine wave and a 7 kHz square wave is at 21 kHz.) Proof that we don’t need to go above 20 kHz, right? Maybe…
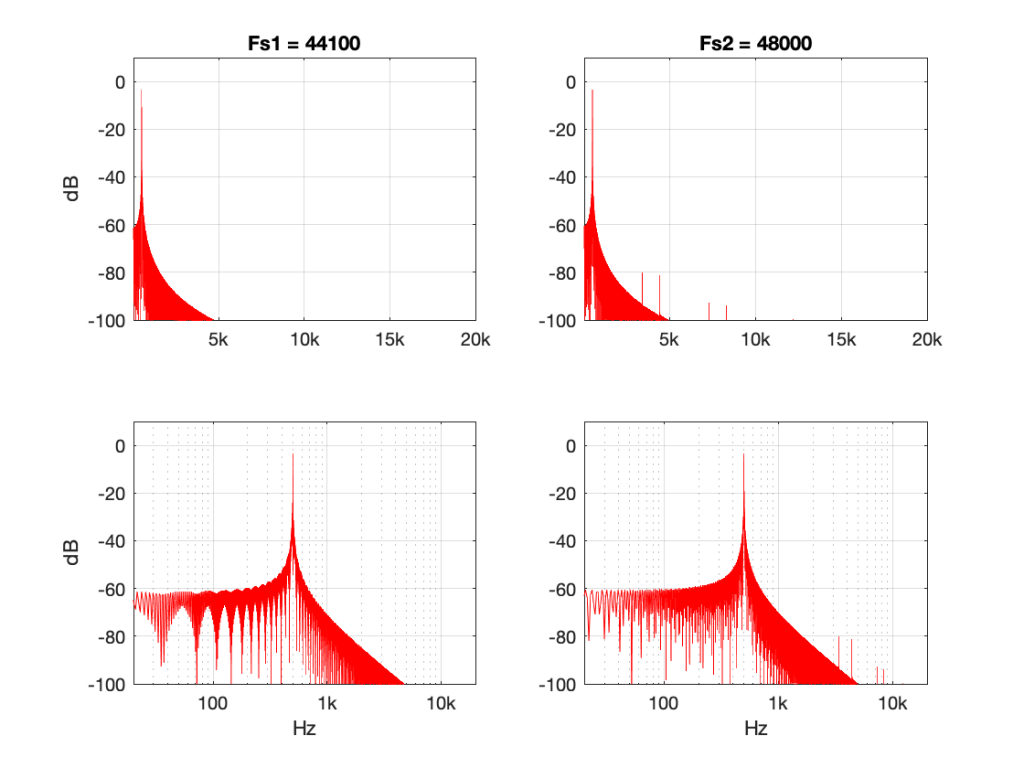
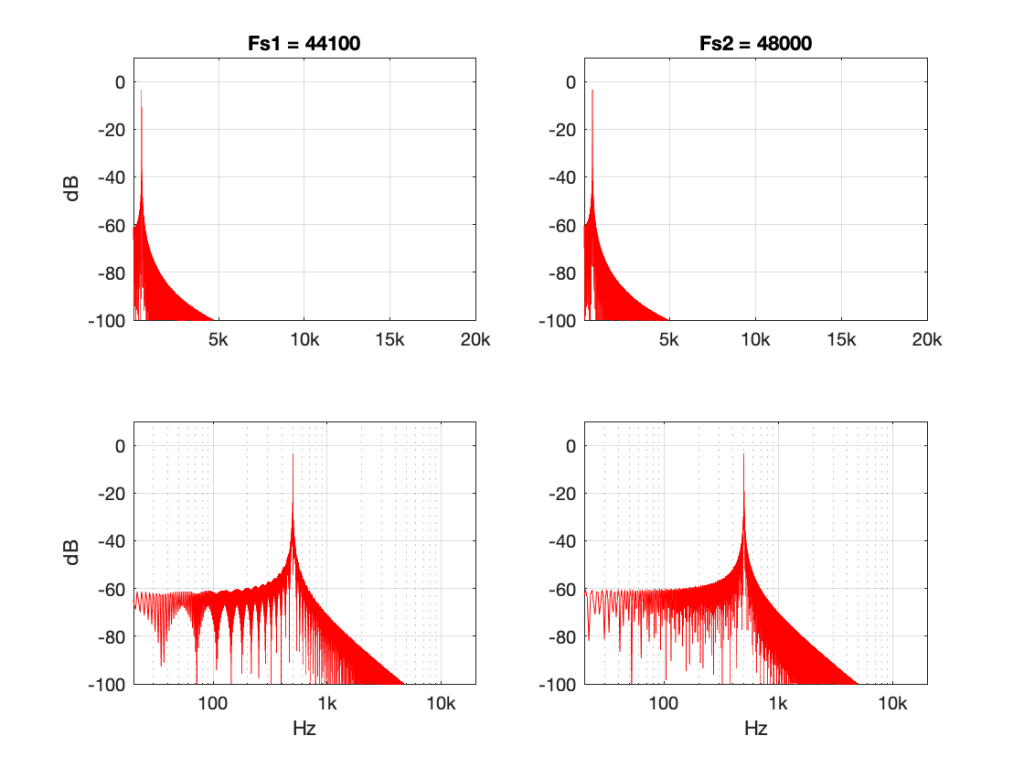
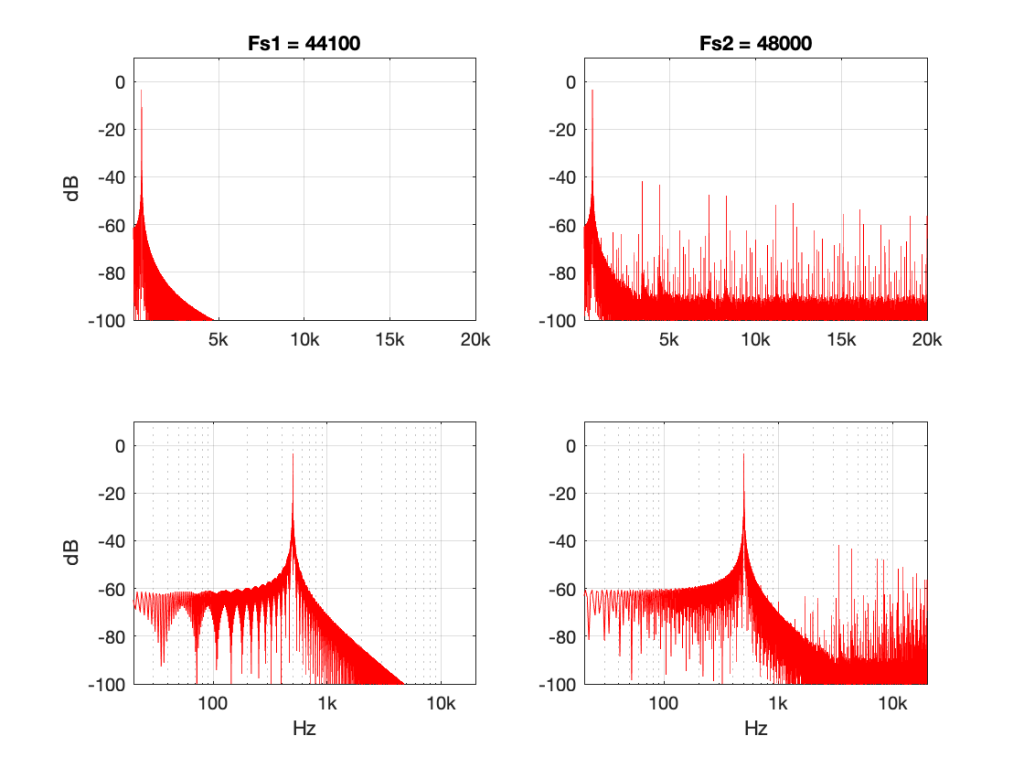
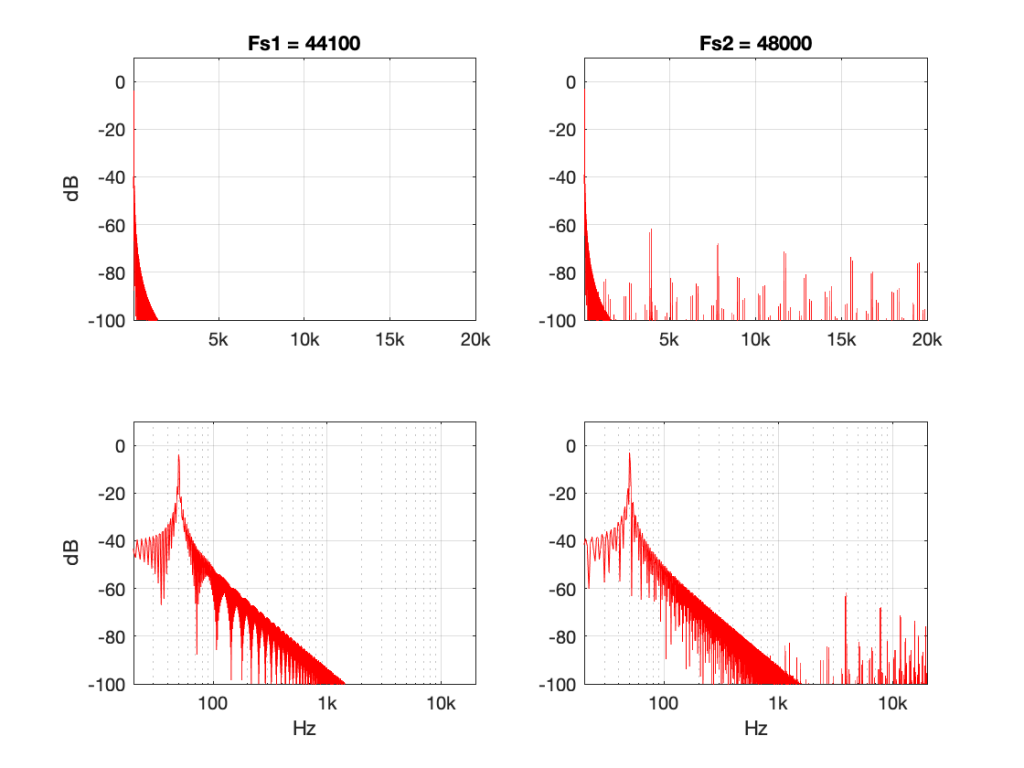
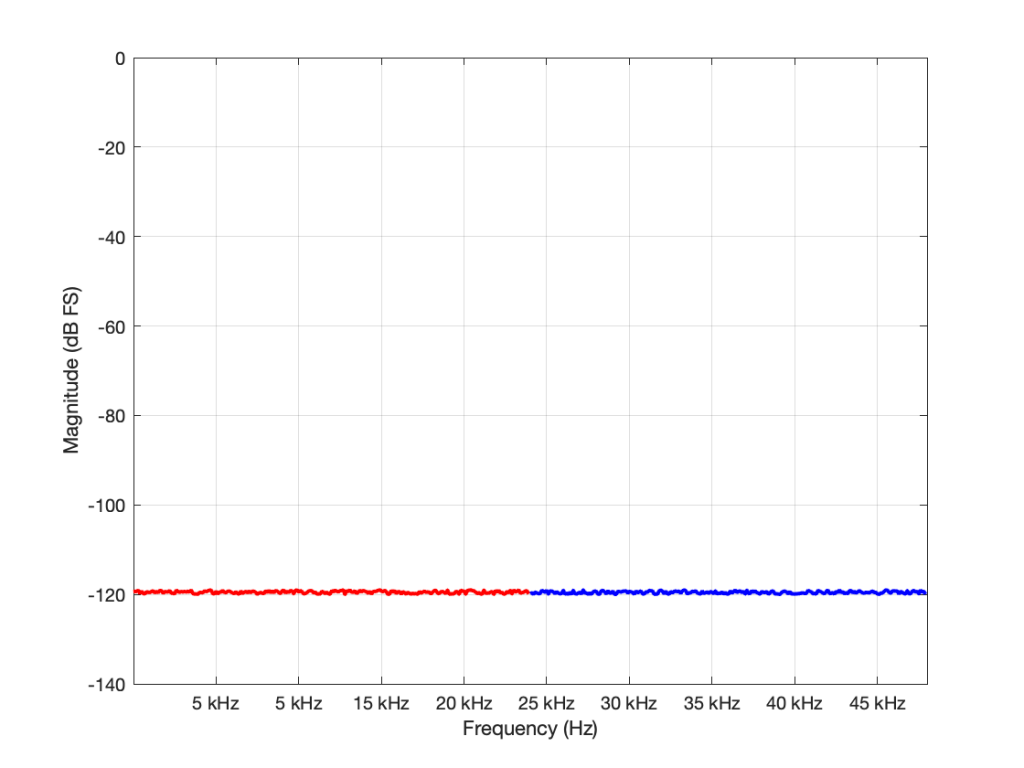
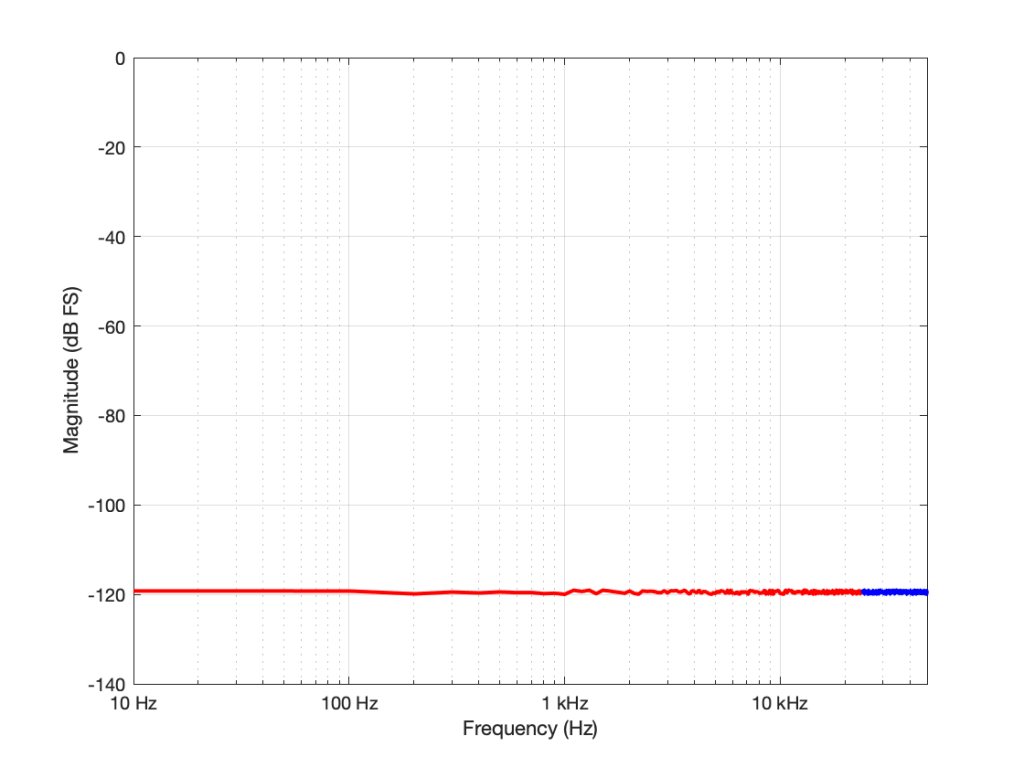
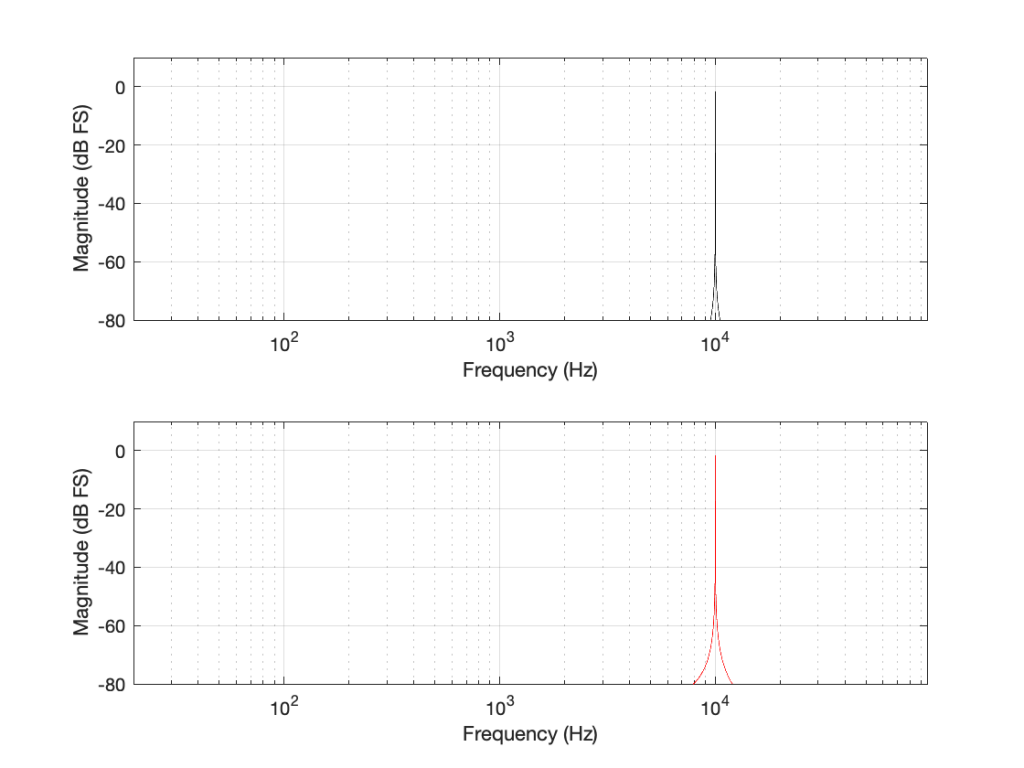
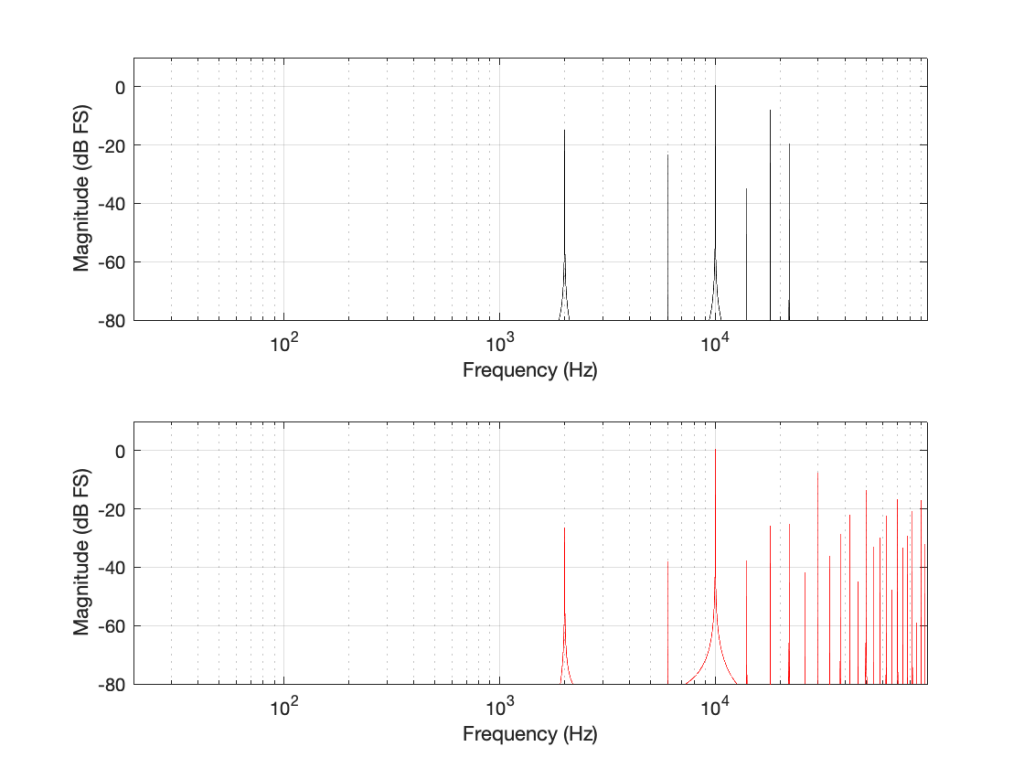
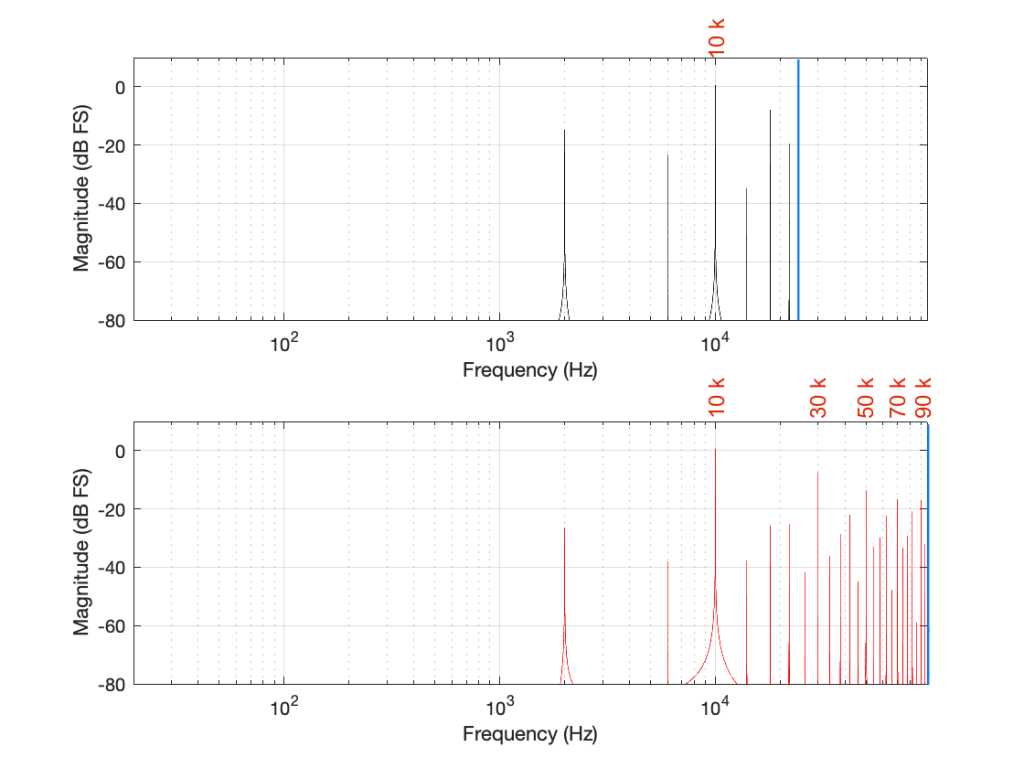
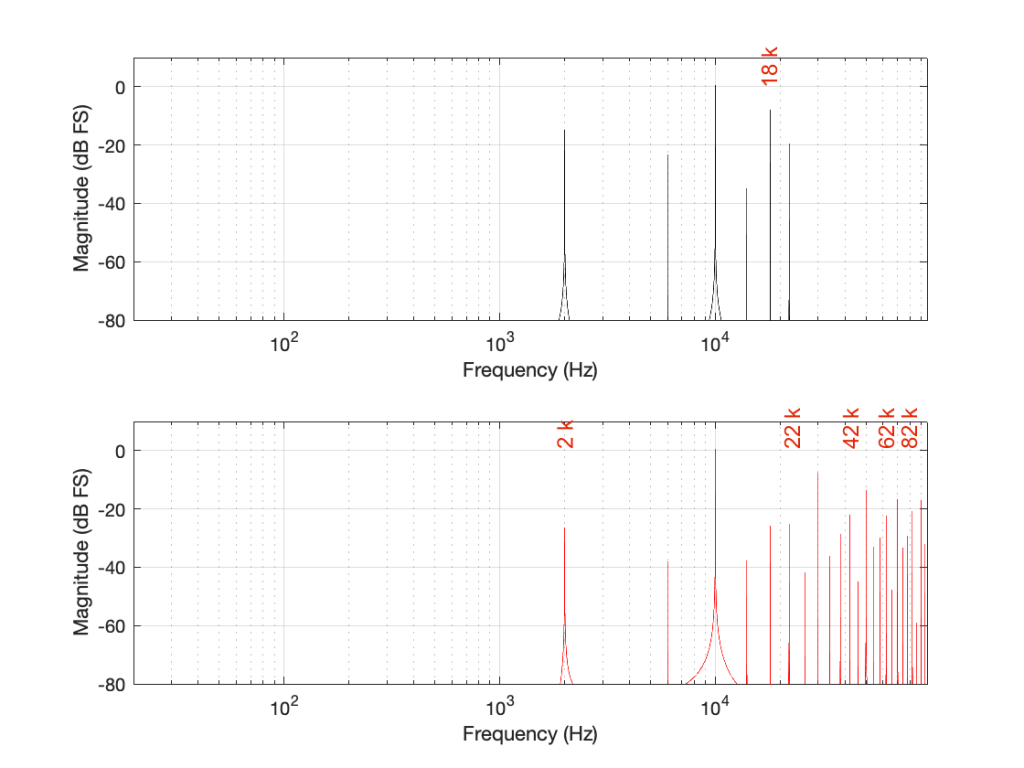
Some years ago, I took some “high resolution” audio files and measured their spectral content. One particularly interesting result is shown in Figures 2, below.
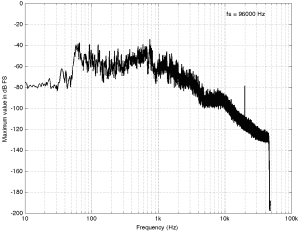
Look at that spike in the top end – around 20 kHz. What musical instrument makes that sound? The answer is “no musical instrument makes that sound – at least none of the baroque instruments in that recording make that sound. As I wrote back in 2014:
If you’re wondering what it might be, I asked a bunch of smart friends, and the best explanation we can come up with is that it’s noise from a switched-mode power supply that is somehow bleeding into the recording. HOW it’s bleeding into the recording is a potentially interesting question for recording engineers. One possibility is that one of the musicians was charging up a phone in the room where the microphones were – and the mic’s just picked up the noise. Another possibility is that the power supply noise is bleeding electrically into the recording chain – maybe it’s a computer power supply or the sound card and the manufacturer hasn’t thought about isolating this high frequency noise from the audio path. Or, maybe it’s something else.
Interestingly, this is a conflict of two engineers. The designer of the power supply (assuming that’s what it is…) said “I’ll put the switching frequency above 20 kHz so that no one will hear it” and the recording engineer said “I’ll record this at 96 kHz so that people can get the content they’re missing…” The problem is that the content you’re missing is something you don’t want…
Similarly, if you listen to Eric Clapton’s “Unplugged” album with headphones or loudspeakers that have a low-enough low-frequency range, you’ll hear a loud thump, thump, thump going along with the music. This is the sound of someone tapping their foot on a temporary stage floor, shaking a vocal microphone. In my not-very-humble opinion, that should never have made it out to the public release. However, my guess is that the speakers it was mastered on didn’t go low enough… (OR, it was an artistic decision, and I would have done it differently.) Assuming that I’m right, then this is a second example where a “better” system sounds “worse”.
Of course, through all of this, I have assumed that your loudspeakers or headphones can produce the signals that we’re talking about in the direction that you’re sitting in, and that those signals are not being masked by other sounds in the room (like phone chargers singing…) However, to complicate things with reality would just be too far to go today…
Conclusions?
I don’t have any, but I have some questions and (as usual) some opinions…
- Does a harmon mute on a trumpet produce energy at 50 kHz, if you’re sitting right in front of it?
Yes. - Do you want to sit right in front of a trumpet with a harmon mute?
Debatable. - Can a high-res audio recording include the sound of a phone charger?
Yes. - Do you want to have an expensive recording of a baroque ensemble with obligato phone charger?
Probably not – the charger is not in Buxtehude’s original score as far as I can see. - Can you hear the difference between a 7 kHz sine and a 7 kHz square wave?
Depends on the speaker / headphone, the listening position, the background noise level, and whether or not you were out clubbing last night. Heads or tails? - Will you feel better by knowing that your file contains “audio” content above 20 kHz? Probably.
Placebos have been known to work bigger miracles than this. (But don’t forget the stuff I said about sampling rate converters earlier…)