This “series” of postings was intended to describe some of the errors that I commonly see when I measure and evaluate digital audio systems. All of the examples I’ve shown are taken from measurements of commercially-available hardware and software – they’re not “beta” versions that are in development.
There are some reasons why I wrote this series that I’d like to make reasonably explicit.
Unfortunately, the only thing that I have concluded after having done lots of measurements of lots of systems is that, unless you do a full set of measurements on a given system, you don’t really know how it behaves. And, it might not behave the same tomorrow because something in the chain might have had a software update overnight.
However, there are two more thing that I’d like to point out (which I’ve already mentioned in one of the postings).
Firstly, just because a system has a digital input (or source, say, a file) and a digital output does not guarantee that it’s perfect. These days the weakest links in a digital audio signal path are typically in the signal processing software or the clocking of the devices in the audio chain.
Secondly, if you do have a digital audio system or device, and something sounds weird, there’s probably no need to look for the most complicated solution to the problem. Typically, the problem is in a poor implementation of an algorithm somewhere in the system. In other words, there’s no point in arguing over whether your DAC has a 120 dB or a 123 dB SNR if you have a sampling rate converter upstream that is generating aliasing at -60 dB… Don’t spend money “upgrading” your mains cables if your real problem is that audio samples are being left out every half second because your source and your receiver can’t agree on how fast their clocks should run.
So, the bad news is that trying to keep track of all of this is complicated at best. More likely impossible.
On the other hand, if you do have a system that you’re happy with, it’s best to not read anything I wrote and just keep listening to your music…
As a setup for this posting, I have to start with some background information…
Back when I was doing my bachelor’s of music degree, I used to make some pocket money playing background music for things like wedding receptions. One of the good things about playing such a gig was that, for the most part, no one is listening to you… You’re just filling in as part of the background noise. So, as the evening went on, and I grew more and more tired, I would change to simpler and simpler arrangements of the tunes. Leaving some notes out meant I didn’t have to think as quickly, and, since no one was really listening, I could get away with it.
If you watch the short video above, you’ll hear the same composition played 3 times (the 4th is just a copy of the first, for comparison). The first arrangement contains a total of 71 notes, as shown below.

The second arrangement uses only 38 notes, as you can see in Figure 2, below.

The third arrangement uses even fewer notes – a total of only 27 notes, shown in Figure 3, below.

The point of this story is that, in all three arrangements, the piece of music is easily recognisable. And, if it’s late in the night and you’ve had too much to drink at the wedding reception, I’d probably get away with not playing the full arrangement without you even noticing the difference…
A psychoacoustic CODEC (Compression DECompression) algorithm works in a very similar way. I’ll explain…
If you do an “audiometry test”, you’ll be put in a very, very quiet room and given a pair of headphones and a button. in an adjacent room is a person who sees a light when you press the button and controls a tone generator. You’ll be told that you’ll hear a tone in one ear from the headphones, and when you do, you should push the button. When you do this, the tone will get quieter, and you’ll push the button again. This will happen over and over until you can’t hear the tone. This is repeated in your two ears at different frequencies (and, of course, the whole thing is randomised so that you can’t predict a response…)
If you do this test, and if you have textbook-quality hearing, then you’ll find out that your threshold of hearing is different at different frequencies. In fact, a plot of the quietest tones you can hear at different frequencies it will look something like that shown in Figure 4.
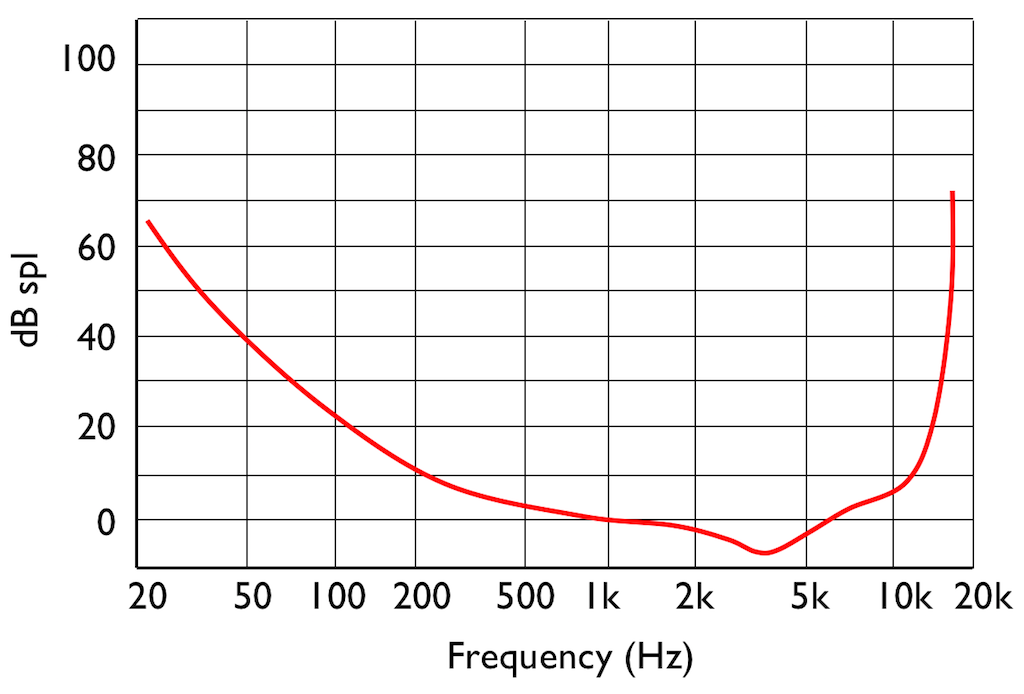
This red curve shows a typical curve for a threshold of hearing. Any frequency that was played at a level that would be below this red curve would not be audible. Note that the threshold is very different at different frequencies.

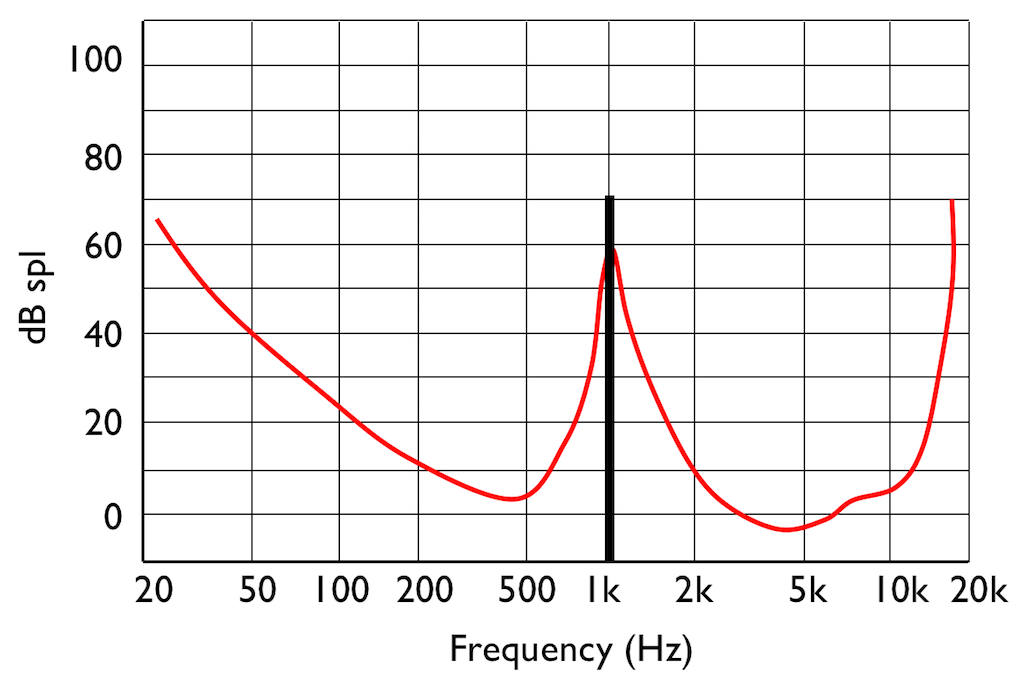
Interestingly, if you do play this tone shown in Figure 5, then your threshold of hearing will change, as is shown in Figure 6.
IF you were not playing that loud 1 kHz tone, and, instead, you played a quieter tone just below 2 kHz, it would also be audible, since it’s also above the threshold of hearing (shown in Figure 7.
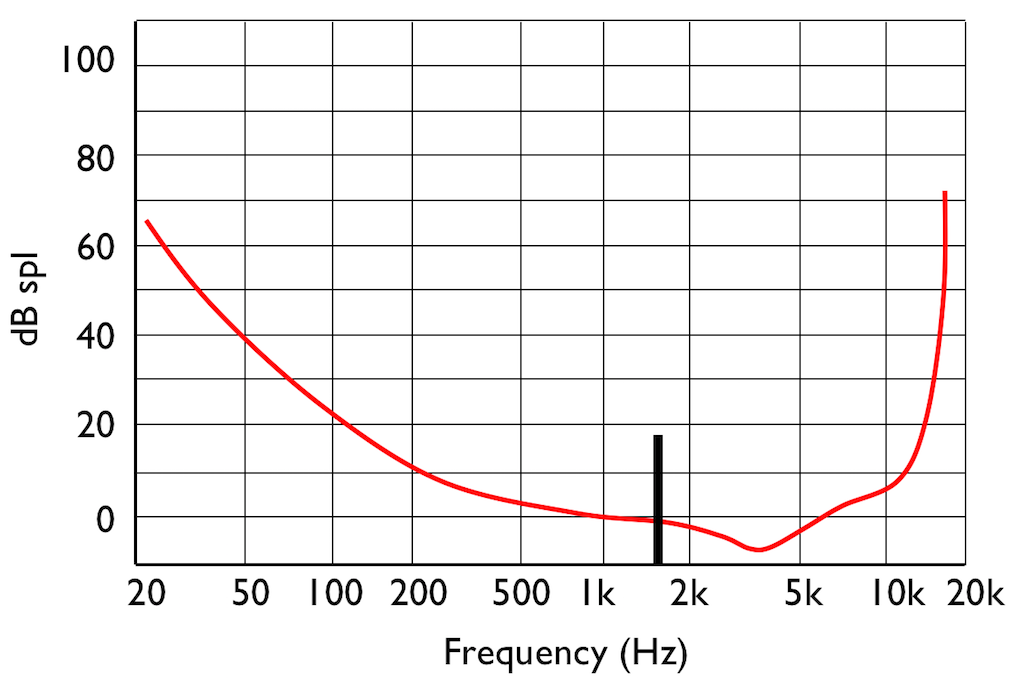
However, if you play those two tones simultaneously, what happens?
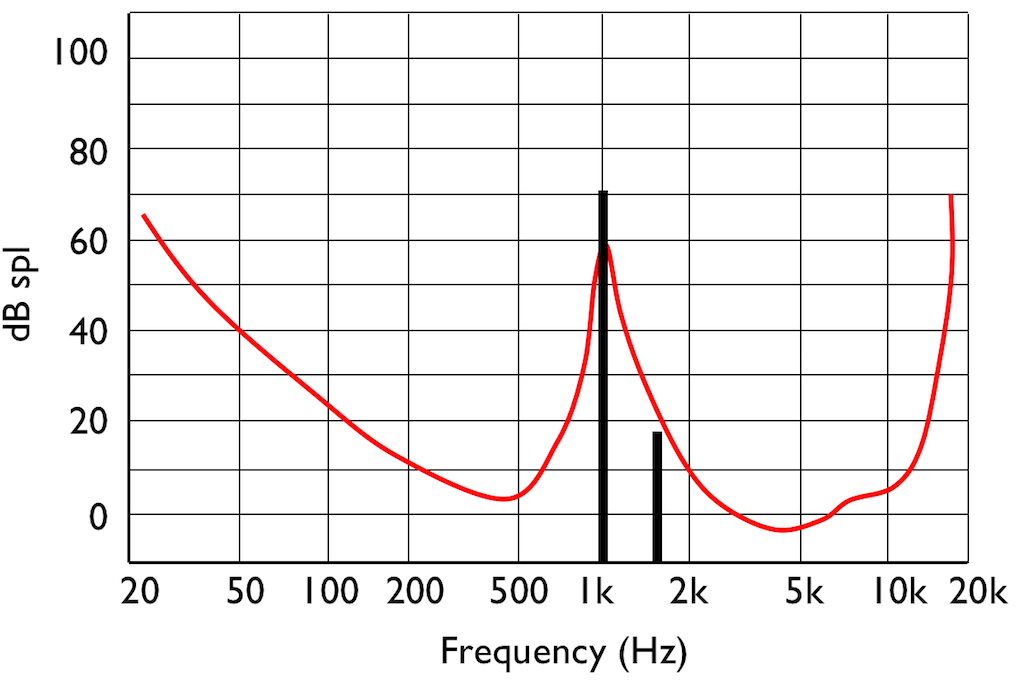
This effect is called “psychoacoustic masking” – the quieter tone is masked by the louder tone if the two area reasonably close together in frequency. This is essentially the same reason that you can’t hear someone whispering to you at an AC/DC concert… Normal people call it being “drowned out” by the guitar solo. Scientists will call it “psychoacoustic masking”.
Let’s pull these two stories together… The reason I started leaving notes out when I was playing background music was that my processing power was getting limited (because I was getting tired) and the people listening weren’t able to tell the difference. This is how I got away with it. Of course, if you were listening, you would have noticed – but that’s just a chance I had to take.
If you want to record, store, or transmit an audio signal and you don’t have enough processing power, storage area, or bandwidth, you need to leave stuff out. There are lots of strategies for doing this – but one of them is to get a computer to analyse the frequency content of the signal and try to predict what components of the signal will be psychoacoustically masked and leave those components out. So, essentially, just like I was trying to predict which notes you wouldn’t miss, a computer is trying to predict what you won’t be able to hear…
This process is a general description of what is done in all the psychoacoustic CODECs like MP3, Ogg Vorbis, AC-3, AAC, SBC, and so on and so on. These are all called “lossy” CODECs because some components of the audio signal are lost in the encoding process. Of course, these CODECs have different perceived qualities because they all have different prediction algorithms, and some are better at predicting what you can’t hear than others. Also, depending on what bitrate is available, the algorithms may be more or less aggressive in making their decisions about your abilities.
There’s just one small problem… If you remove some components of the audio signal, then you create an error, and the creation of that error generates noise. However, the algorithm has an trick up its sleeve. It knows the error it has created, it knows the frequency content of the signal that it’s keeping (and therefore it knows the resulting elevated masking threshold). So it uses that “knowledge” to shape the frequency spectrum of the error to sit under the resulting threshold of hearing, as shown by the gray area in Figure 9.
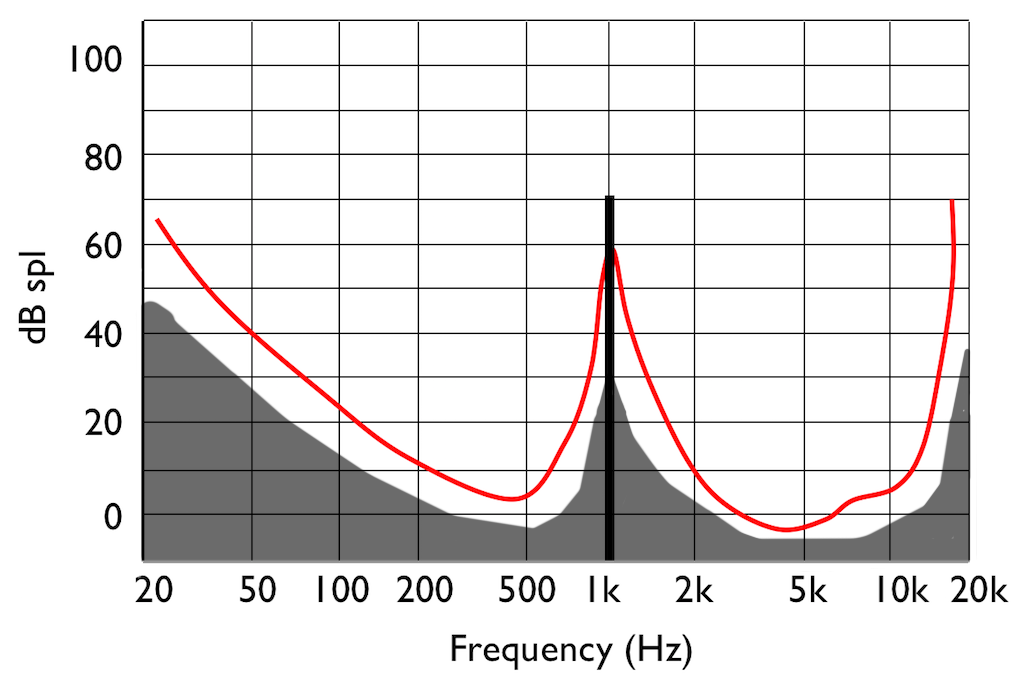
Let’s assume that this system works. (In fact, some of the algorithms work very well, if you consider how much data is being eliminated… There’s no need to be snobbish…)
Okay – everything above was just the “setup” for this posting.
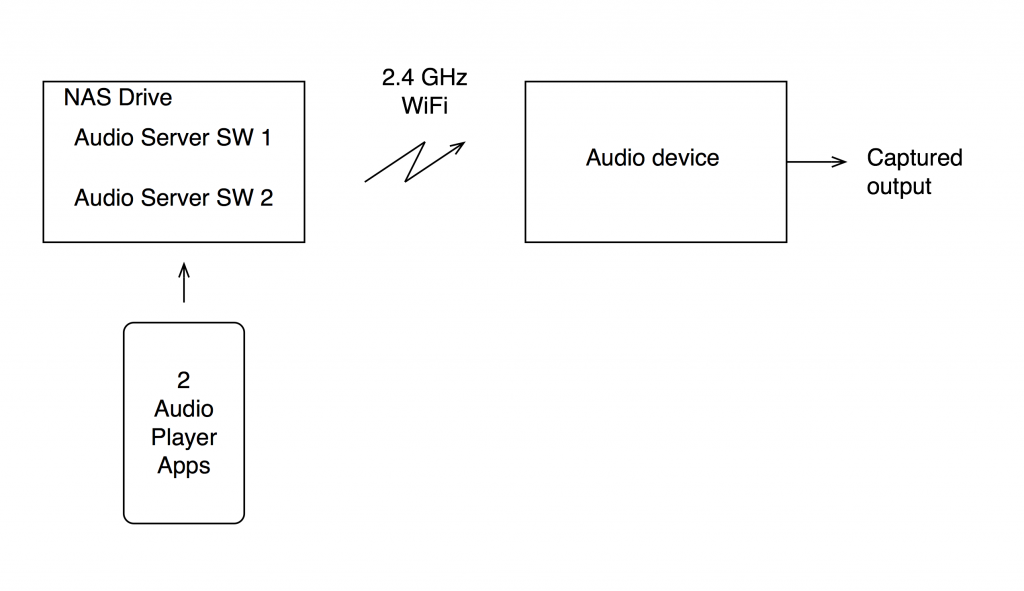
For this test, I put two .wav files on a NAS drive. Both files had a sampling rate of 48 kHz, one file was a 16-bit file and the other was a 24-bit file.
On the NAS drive, I have two different applications that act as audio servers. These two applications come from two different companies, and each one has an associated “player” app that I’ve put on my phone. However, the app on the phone is really just acting as a remote control in this case.
The two audio server applications on the NAS drive are able to stream via my 2.4 GHz WiFi to an audio device acting as a receiver. I captured the output from that receiver playing the two files using the two server applications. (therefore there were 4 tests run)
The content of the signal in the two .wav files was a swept sine tone, going from 20 Hz to 90% of Nyquist, at 0 dB FS. I captured the output of the audio device in Figure 10 and ran a spectrogram of the result, analysing the signal down to 100 dB below the signal’s level. The results are shown below.
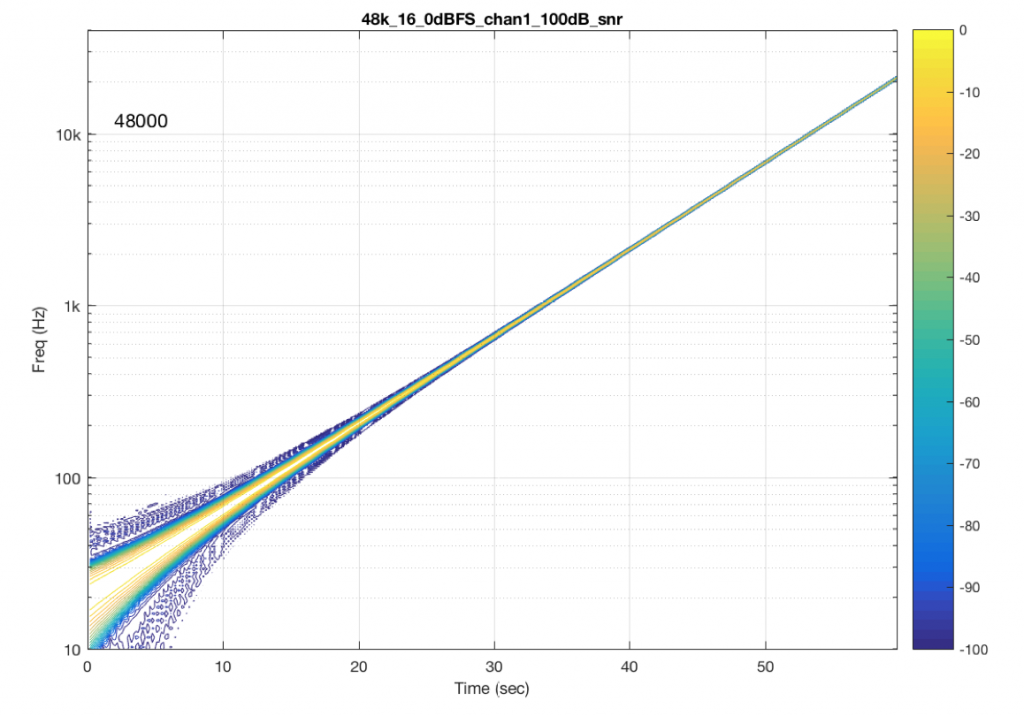
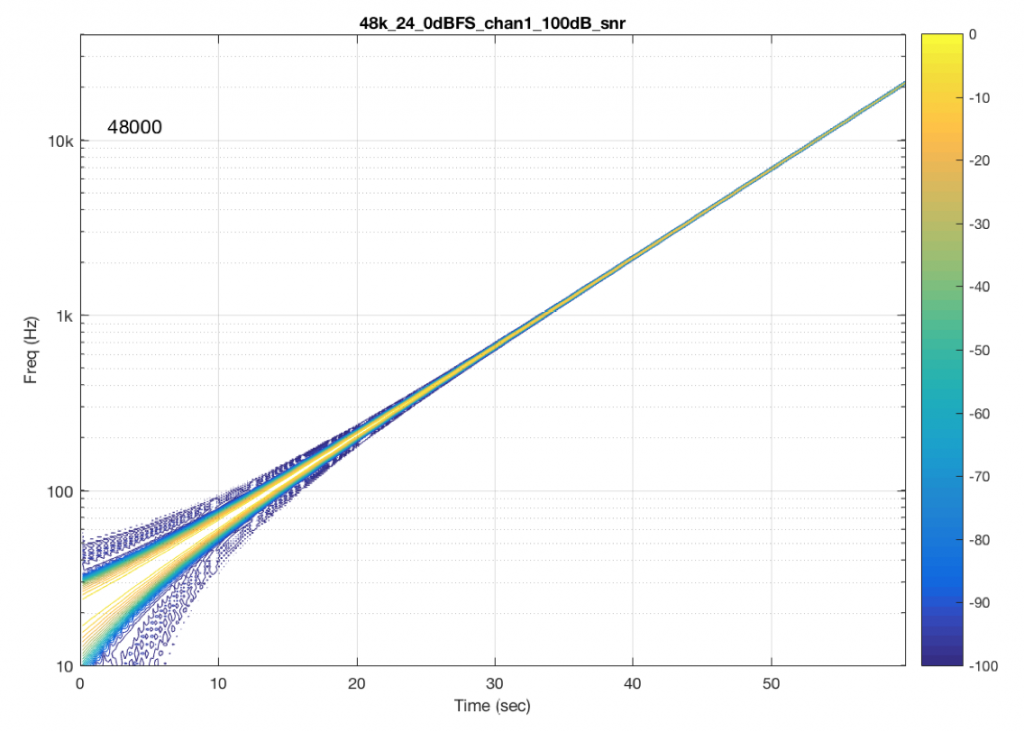
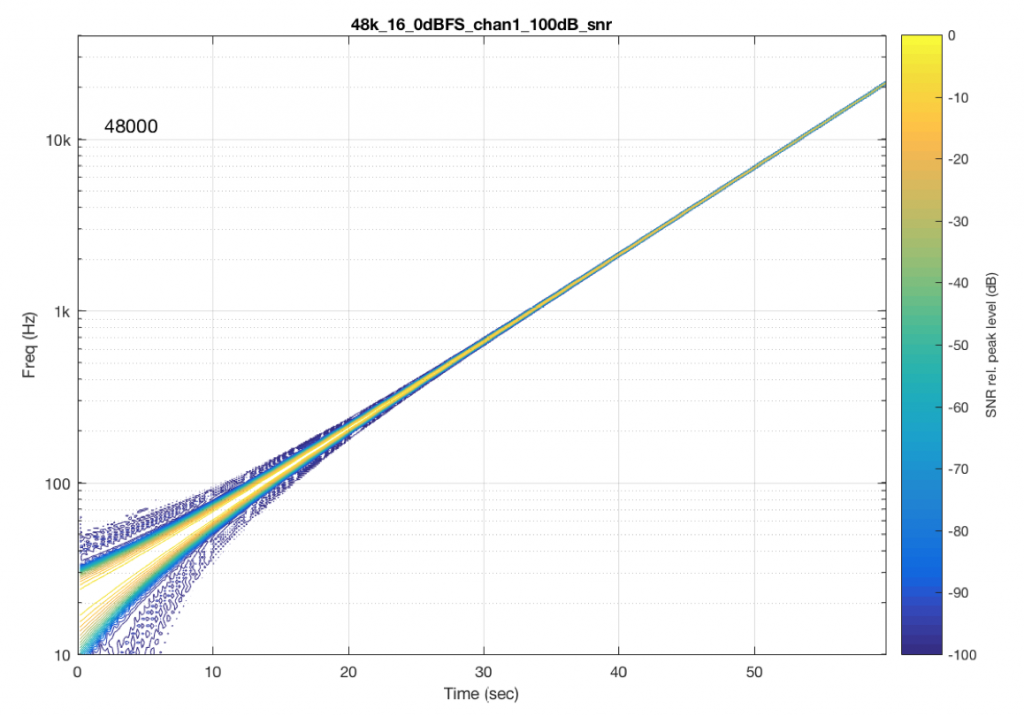

So, Figures 11 and 13 show the same file (the 16-bit version) played to the same output device over the same network, using two different audio server applications on my NAS drive.
Figures 12 and 14 also show the same file (the 24-bit version). As is immediately obvious, the “Audio Server SW 2” is not nearly as happy about playing the 24-bit file. There is harmonic distortion (the diagonal lines parallel with the signal), probably caused by clipping. This also generates aliasing, as we saw in a previous posting.
However, there is also a lot of visible noise around the signal – the “fuzzy blobs” that surround the signal. This has the same appearance as what you would see from the output of a psychoacoustic CODEC – it’s the noise that the encoder tries to “fit under” the signal, as shown in Figure 9… One give-away that this is probably the case is that the vertical width (the frequency spread) of that noise appears to be much wider when the signal is a low-frequency. This is because this plot has a logarithmic frequency scale, but a CODEC encoder “thinks” on a linear frequency scale. So, frequency bands of equal widths on a linear scale will appear to be wider in the low end on a log scale. (Another way to think of this is that there are as many “Hertz’s” from 0 Hz to 10 kHz as there are from 10 kHz to 20 kHz. The width of both of these bands is 10000 Hz. However, those of us who are still young enough to hear up there will only hear the second of these as the top octave – and there are lots of octaves in the first one. (I know, if we go all the way to 0 Hz, then there are an infinite number of octaves, but I don’t want to discuss Zeno today…))
So, it appears that “Audio Server SW 2” on my NAS drive doesn’t like sending 24 bits directly to my audio device. Instead, it probably decodes the wav file, and transcodes the lossless LPCM format into a lossy CODEC (clipping the signal in the process) and sends that instead. So, by playing a “high resolution” audio file using that application, I get poorer quality at the output.
As always, I’m not going to discuss whether this effect is audible or not. That’s irrelevant, since it’s dependent on too many other factors.
And, as always, I’m not going to put brand or model names on any of the software or hardware tested here. If, for no other reason, this is because this problem may have already been corrected in a firmware update that has come out since I tested it.
The take-home messages here are:
So, if you read a test involving a particular NAS drive, or a particular Audio Server application, or a particular audio device using a file format with a sampling rate and a bit depth and the reviewer says “This system worked perfectly.” You cannot assume that your system will also work perfectly unless all aspects of your system are identical to the tested system. Changing one link in the chain (even upgrading the software version) can wreck everything…
This makes life confusing, unfortunately. However, it does mean that, if someone sounds wrong to you with your own system, there’s no need to chase down excruciating minutiae like how many nanoseconds of jitter you have at your DAC’s input, or whether the cat sleeping on your amplifier is absorbing enough cosmic rays. It could be because your high-res file is getting clipped, aliased, and converted to MP3 before sending to your speakers…
Just in case you’re wondering, I tested these two systems above with all 6 standard sampling rates (44.1, 48, 88.2, 96, 176.4, and 192 kHz), 2 bit depths (16 & 24). I also did two formats (WAV and FLAC) and three signal levels (0, -1, and -60 dB FS) – although that doesn’t matter for this last comment.
“Audio Server SW 2” had the same behaviour in the case of all sampling rates – 16 bit files played without artefacts within 100 dB of the 0 dB FS signal, whereas 24-bit files in all sampling rates exhibited the same errors as are shown in Figure 14.
We’ve seen in a previous posting that timing errors can occur in wireless audio systems. As we saw there, the wrong way to deal with this is to simply drop or repeat samples when the receiver realises it’s out of synchronisation with the transmitter. A better way to do it is to smoothly drift the sampling rate to either catch up or slow down – although this causes the modern-day equivalent of “wow and flutter”, since variations in the sampling rate will cause pitch shifts at the output. The trick here is to make changes slowly so as to get away with it…
However, what I didn’t address in that posting was how bad the problem can be – I only talked about how not to correct the problem when you know you have one.
So, let’s do a different (but related) test. I made a signal that consists of “digital black” – a long string of zeros – and therefore silence. Then, I made a single-sample spike every second (for example, every 44100 samples in a 44.1 kHz sampling rate system). In order to not make anything unhappy, I gave the clicks a value of 0.5 – so nothing is close to overloading…
Then, I transmitted that signal to an audio device wirelessly and recorded its output.
Figure 1, below, shows the original signal on top, and the recorded output of the device under test (the “DUT”) on the bottom.
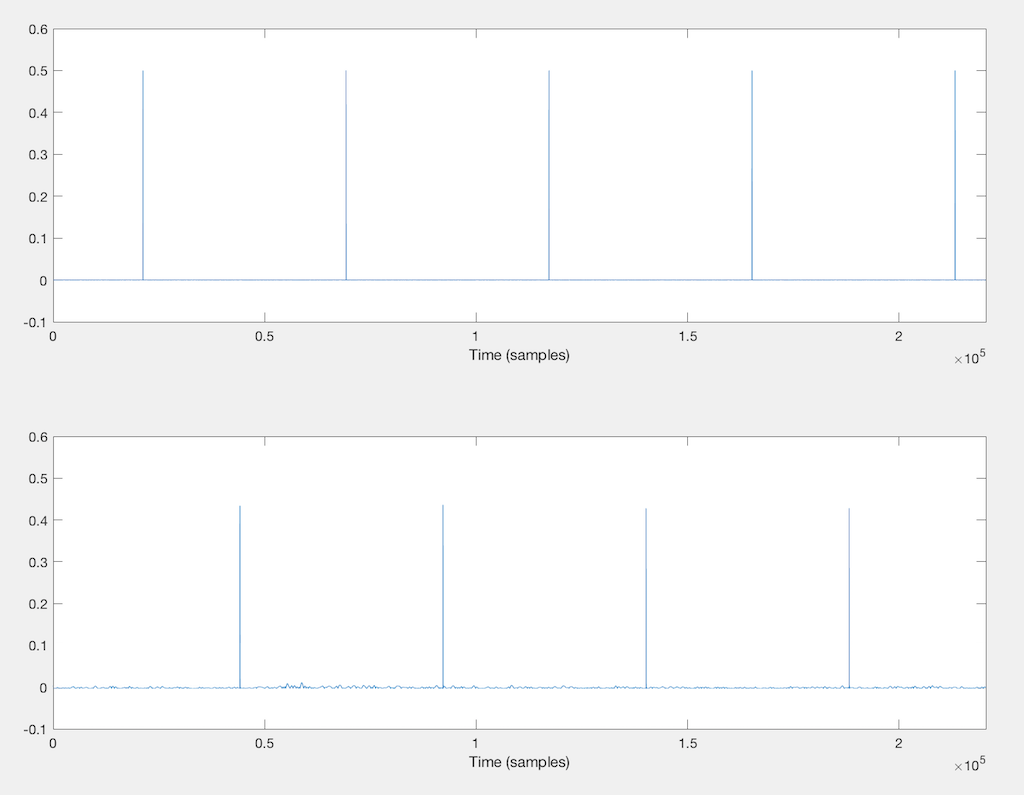
You may notice that there is a little noise in the bottom plot. This is because this particular DUT has an acoustical output, and the noise you see there (partly) is acoustical noise in the room and measurement system.
Note that this plot shows only the first 5 seconds of a test that actually ran for 10 minutes.
Then, I wrote a little Matlab script that finds the spikes in each signal, and counts the number of samples between spikes. So, in a system running at 44.1 kHz I would expect that there is 1 spike every 44100 samples – both at the input to the system (the original signal) and its output. In other words, I’m finding out how far apart those spikes are with a resolution of 1 sample.
So, I find the duration between clicks at the output of the DUT, convert from samples to milliseconds, and plot the error over the full 600 seconds (10 minutes) of the test. In theory, there is no error – and each duration is exactly 1 second ±0 ms. In practice, however, this is not true.
For this posting, I tested two commercially-available devices, transmitting from the same device.
Figure 2 shows the results for that first device. As you can see there, one second at the device’s input does not correspond to 1 second at its output. It drifts from a little under 999.7 ms to a little over 1000.2 ms. Note that, for this test, I don’t know from the measurement how that change takes place – whether it’s shifting slowly or using a skip/insert strategy. I just know one version of how bad the problems is over time on a second-by-second basis.
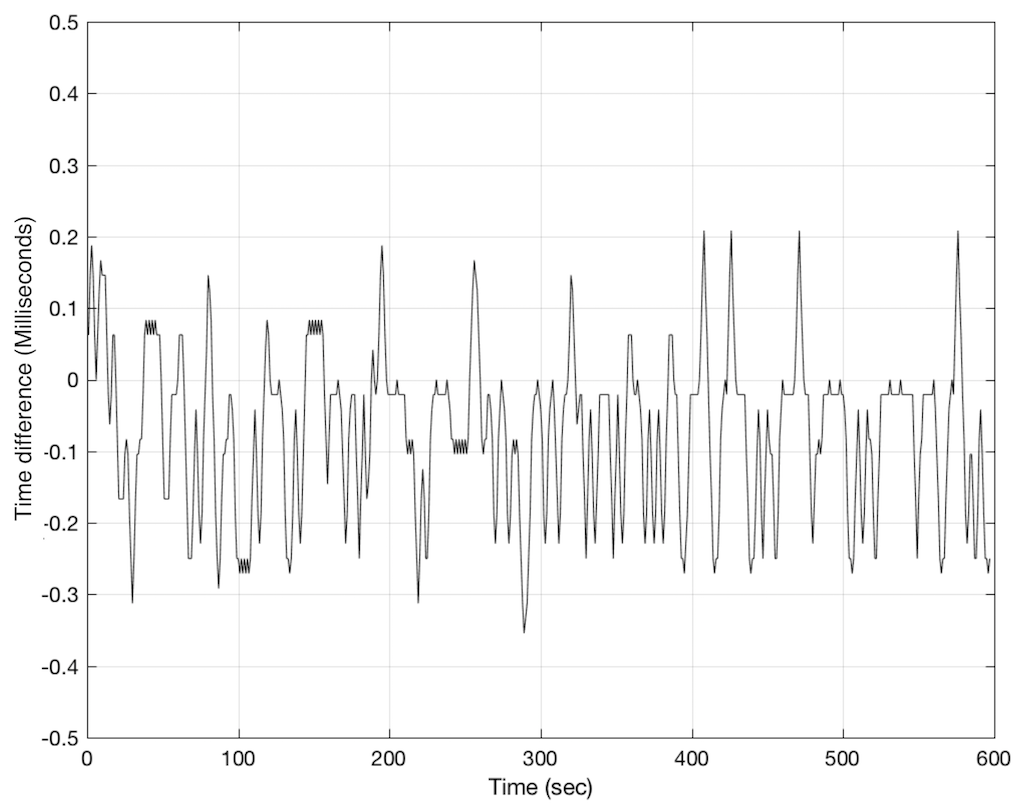
Figure 3, below, shows the same analysis for another device. Notice that there are three colours in this plot, corresponding to three separate tests of the same device…
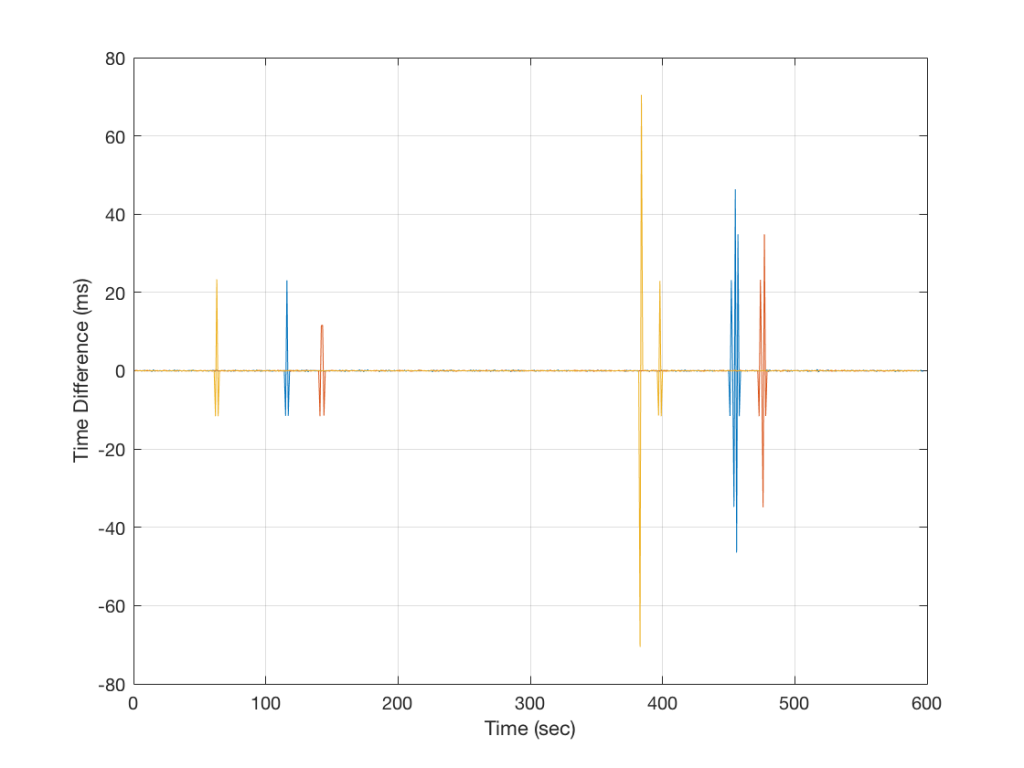
As you can see there, this device seems to be behaving most of the time, but occasionally gets a little lost and jumps by to about ±70 ms in a worst case. This means that, for this test, we can see that “1 second” can last anything between about 930 ms and 1070 ms. Note that this analysis doesn’t show what happens at the moment (or during the time) that jump occurs – we only know that it has happened sometime between clicks at the output.
You may be wondering why the plot in Figure 2 is more “jagged” than the one in Figure 3. This is mostly because the scale of the two plots is so different. If we were to zoom in to the plot in Figure 3, we would see that it is roughly as busy, as is shown below in Figure 4.
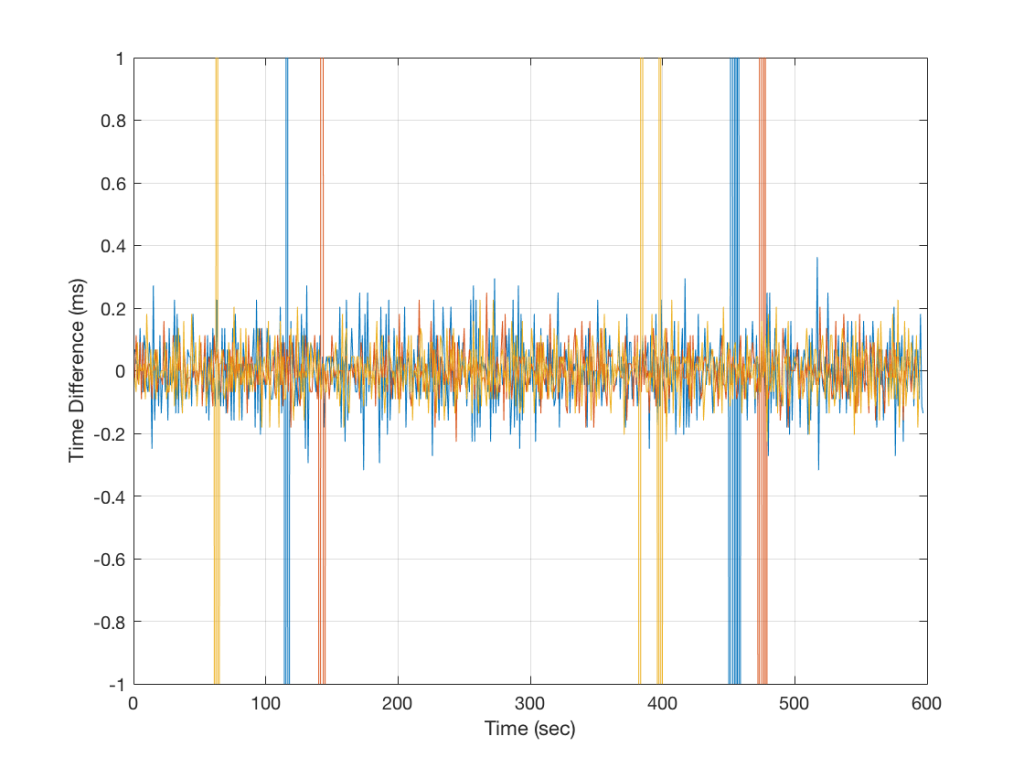
One significant difference between these two devices is that the first has an acoustical output and the second has an electrical output. This may cause you to wonder whether the acoustical noise in the first measurement contributes to the error. This may be possible. However, a 0.2 ms (or 200 µs) error is roughly equivalent to 9 samples at 44.1 kHz (or a 6.9 cm shift in distance between the DUT and the microphone). This is well outside the range of the error generated by acoustical noise – so that cannot be held responsible as being the only contributor to the error measurement.
I should say that the wireless audio protocol that was used for these two tests were the same… So, this is not a comparison of two different transmission systems. Also, as I mentioned above, the transmitter was the same for both DUT’s. So, the difference in results here are attributable to the skill and attention to the execution of the manufacturers of the two receiving devices.
As always, don’t bother asking which devices these DUT’s are. I’m not telling – primarily because it doesn’t matter. I’m just using these two devices as examples of errors I often see when I measure audio equipment…
One additional thing that might be of interest to geeks like me. That second DUT has a digital audio output, which is what I used to capture its signal. Interestingly, when I measure the sampling rate of that output with a digital audio signal analyser, the sampling rate is typically within 2 ppm of the correct frequency. So, ignoring the big spikes in Figure 3 (which are probably the result of buffer over- or under-runs) if the timing errors we see in Figure 4 were solely caused by a clock error that was visible on the digital audio output, then we should not see deviations of no more than approximately 2 microseconds per second. Instead, we see changes on the order of 1 to 2 milliseconds per second, which indicates a sample rate drift of 1000 to 2000 ppm… So, this means that, although the sampling rate of my transmitter and the output sampling rate of my receiver (the DUT) are nominally the same, AND there is very low jitter / error on the DUT’s output sampling rate, something else in the audio signal path is causing this error. In other words, a simple measurement of the digital output’s sampling rate is not adequate to verify that the DUT’s clock is behaving.
In a previous posting, I tried to explain the concept of aliasing. The easiest way to illustrate this is to try to sample an audio signal that has a frequency that is higher than the Nyquist frequency – one half of the sampling rate. If you do this, then the signal that will come out of your digital audio system will have a different frequency than the original signal. In fact, it will be the Nyquist frequency minus the difference between the original signal and the Nyquist frequency.
For example, if we have an LPCM audio system that has a sampling rate of 48 kHz, then its Nyquist frequency is 24 kHz. If you allow any audio signal to be sampled by that system, and you record a sine wave with a frequency of 30 kHz, then the signal that will be played back by the system will be
Nyquist – (signal freq – Nyquist)
24 kHz – (30 kHz – 24 kHz)
24 kHz – 6 kHz
18 kHz
The example I gave above is only part of the story. It’s the part of the story that’s told because it’s easy to tell, and relatively easy to grasp. However, let’s look into this a little more…
If I ask you “what is the square root of 4?” you’ll probably say that the answer is “2”. However, this is also only part of the story. The square root of 4 is also -2, since -2 * -2 = 4. So, there are two correct answers to the question – in other words, both answers exist and are equally valid.
Aliasing is somewhat similar. If we manage to get a 30 kHz sine wave into an LPCM recording system with a sampling rate of 48 kHz, we will appear to have recorded an 18 kHz sine wave. However, the samples that we have captured are also equally valid for the original 30 kHz sine wave. In fact, both the 18 kHz and the 30 kHz tones can be thought of as being equally valid answers to the set of samples we recorded.
This means that, if I record an 18 kHz sine tone in the 48 kHz system, we can consider the 30 kHz sine tone to also exist simultaneously, inside the digital domain.
Oddly, this is also true at other frequencies. So, you do not only get a mirror effect around the Nyquist, but you also get it at the 1.5 times the sampling rate (or the sampling rate + Nyquist).
I won’t go into this any deeper for now – but if you want to continue, the section on “Folding” at the Wikipedia page on Aliasing is a good place to start.
Normally, we try to prevent audio signals higher with frequency content higher than the Nyquist frequency from getting into an LPCM system. This is done by low-pass filtering the audio signal to eliminate any content that might cause aliasing. That’s why the low-pass filter at the input of an analogue-to-digital converter is called an anti-aliasing filter. (At least, that’s the theory. In reality, the anti-aliasing filter of many ADC’s allow a little signal to get through above Nyquist…)
However, what happens if you create signals with a frequency above the Nyquist within the digital domain? Is this possible? Can it happen accidentally?
The short answer to this question is “yes”.
For example, let’s take a sine wave with a frequency of 2212 Hz (this is an arbitrary number… it could have been something else…), record it with an LPCM system with a sampling rate of 48 kHz. Then, after the signal is in the digital domain, I clip it at 85% of the peak value, so it looks like the waveform shown in Figure 1.
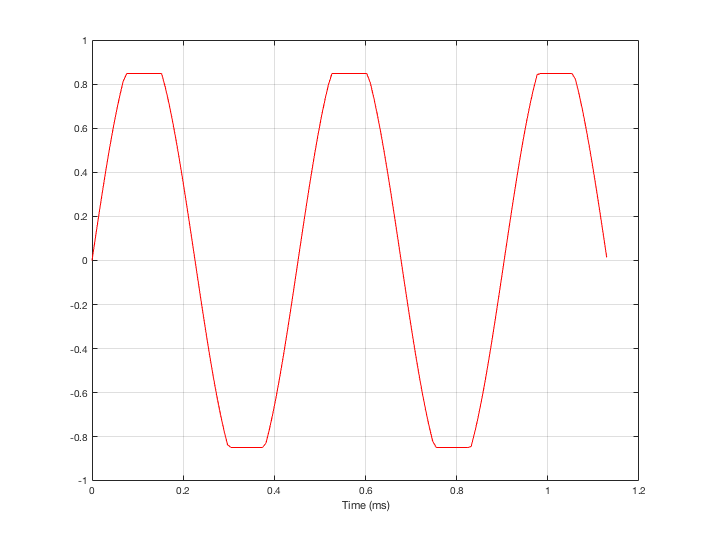
By clipping the sine wave symmetrically (meaning that we have made the same change in the wave’s shape on the top and the bottom), we create odd-order harmonics. This means that, when we look at the spectrum of the signal’s frequency content, we will see energy at the fundamental frequency (the original sine wave’s frequency) and also peaks at 3x, 5x, 7x, 9x, that frequency – and so on.
(If I had clipped only on the top or the bottom, and therefore made asymmetrical distortion, we would see energy in the even-order harmonics at 2x, 4x, 6x, 8x, the fundamental frequency – and so on.)
So, let’s look at the frequency content of the clipped signal shown in Figure 1. This is shown in Figure 2, below.
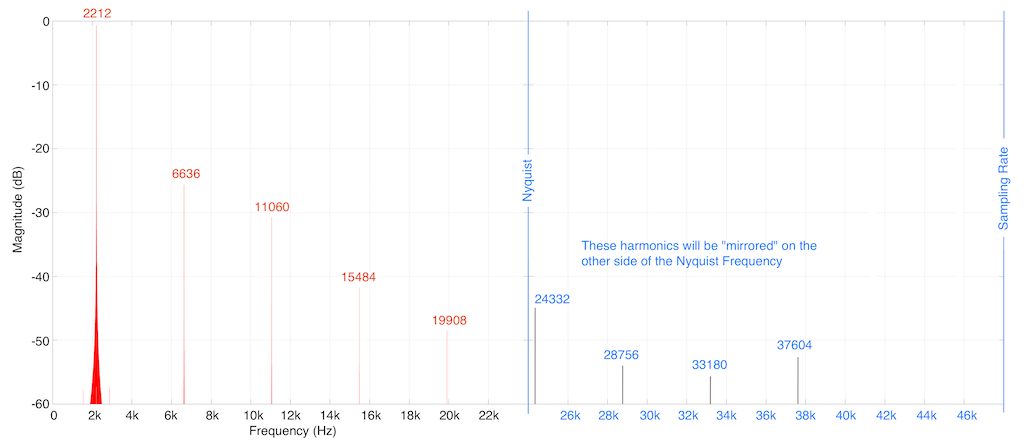
As you can see in Figure 2, we are expecting to see harmonics that extend (at least in this plot) up to 37604 Hz (or 17 x 2212 Hz). Of course, there are harmonics that go higher than this – but they aren’t visible in this plot because I’m only plotting signals with a level down to -60 dB FS.
You may notice that the width of the plot at 2212 Hz increases at the bottom. This is just an artefact of the math being done to find the frequency components in the signal. That spread in the frequency domain isn’t actually in the signal itself, so it can be ignored.
As I said above, the signal was clipped in the digital domain, in an LPCM system running at 48 kHz. So, just for reference, I’ve put in blue lines in Figure 2 that show the sampling rate and the Nyquist frequency – one half the sampling rate.
So: we can see that some of the artefacts created by clipping the signal are sitting at frequencies above the Nyquist frequency in this system. This means that this content will be “mirrored” or “folded down” or – more correctly – aliased to other frequencies below the Nyquist frequency. For example, the harmonic at 24332 Hz will be mirrored to 23668 Hz, according to the following math:
Nyquist – (signal freq – Nyquist)
24000 – (24332 – 24000)
24000 – 332
23668 Hz
So, looking at the top 60 dB of the signal content (shown in Figure 3): the resulting actual output of the LPCM signal will contain:
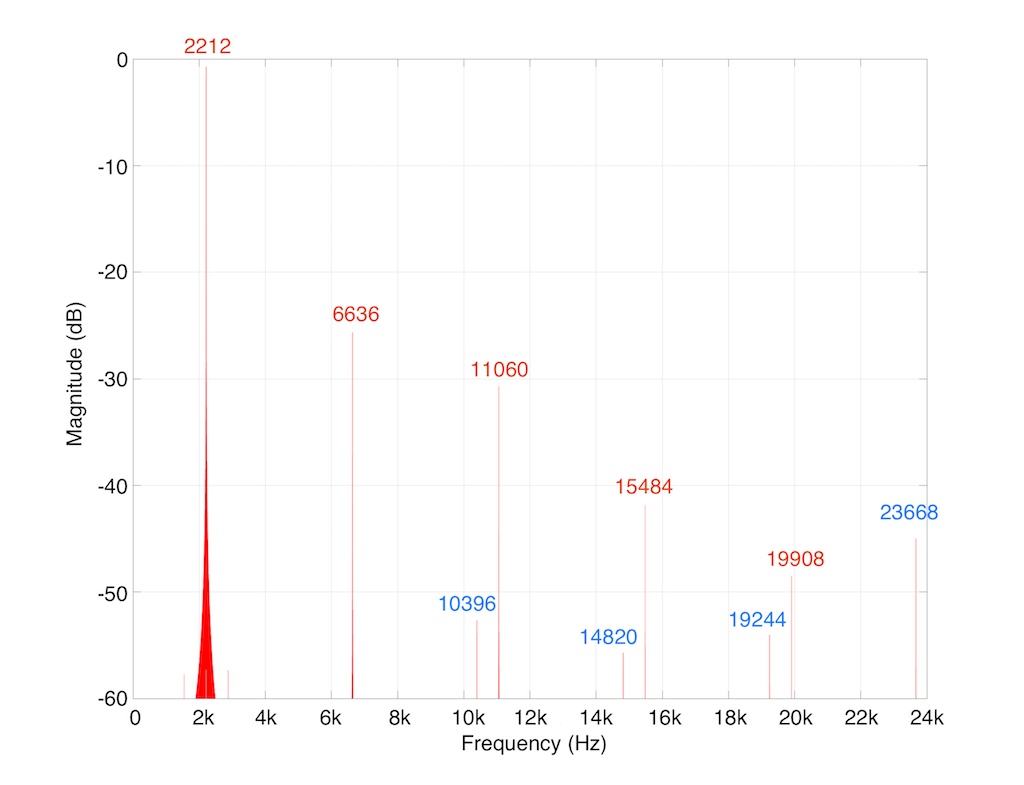
As you may already know, an LPCM system has a low-pass filter at its output stage – part of the system that is used to convert the signal back to an analogue output. However, that low pass filter typically has a cutoff frequency around the Nyquist frequency of the system. However, the artefacts that we have created here have aliased down to frequencies below the Nyquist within the digital domain – so, by the time the signal reaches the low pass filter at the output (known as a “reconstruction filter”) they’re already in the audio band, and therefore they’re not filtered out.
So, as we can see in this rather simple example: it is easily possible that a digital audio system that has some processing (specifically “non-linear” processing) can create harmonics that are higher than the Nyquist frequency and will have “aliases” below the Nyquist frequency, and therefore will not be removed by an anti-aliasing filter.
Since the aliased artefacts are not harmonically related to the fundamental frequency, they are more easily audible than “normal” distortion artefacts that generate harmonically-related artefacts. There are a couple of reasons for this, but the most obvious one can be demonstrated by sweeping the frequency of the fundamental. If the artefacts are harmonically related, then as the fundamental frequency of the signal goes up, so do the artefacts. However, if the artefacts are the result of aliasing, then as the fundamental frequency of the signal goes up, some of the artefacts go down in frequency, which sounds quite strange…
The example I gave above (of clipping) is just one way to create distortion that generates harmonically-related artefacts that alias in the system. Lots of different processes can create those artefacts. One of the usual suspects is a poorly-made sampling rate converter.
Many systems use sampling rate converters for different reasons. For example, if you have a loudspeaker or processor that has a lot of filtering in its processing chain, the best architecture is to run the digital signal processing (the DSP) at a constant (or “fixed”) sampling rate, regardless of the sampling rate of the incoming signal. This is because, if you were to change sampling rates in the DSP to match the incoming signal, you would have to load an entirely new set of coefficients (a fancy word that basically means “multiplications values inside the digital filters”) into the processor. This takes some time, and you don’t want to miss the first part of the song every time the sampling rate changes while you’re waiting to load a bunch of new coefficients into your filters… So, instead, the smart thing to do is to keep the DSP running at a constant rate, and sample rate convert all incoming signals to the internal sampling rate. This way, there’s no dropout at the start of the song.
However, you have to be careful if you do this, since a poorly-made sampling rate converter will certainly create aliasing artefacts.
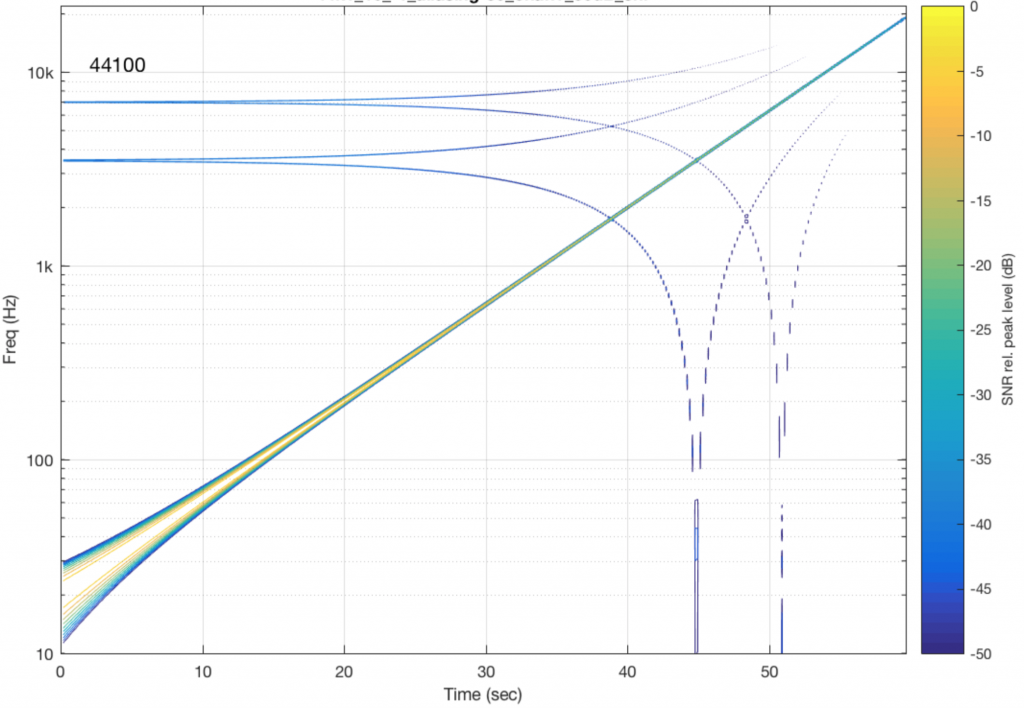
In part 5 of this series of postings, I described one kind of test that can be made on an audio system. This test consists of sending a sine wave with a swept frequency into the system and recording its output. You then do a spectrogram of the output, looking for signals at frequencies other than the one you sent in.
To get an idea of what aliasing will look like in this plot, I made a DSP algorithm that creates the same kinds of artefacts. The resulting plot is shown in Figure 4, below. (Remember that this is a measurement of a system that I made to intentionally generate similar artefacts to aliasing – this isn’t actually the output of a system that is aliasing).
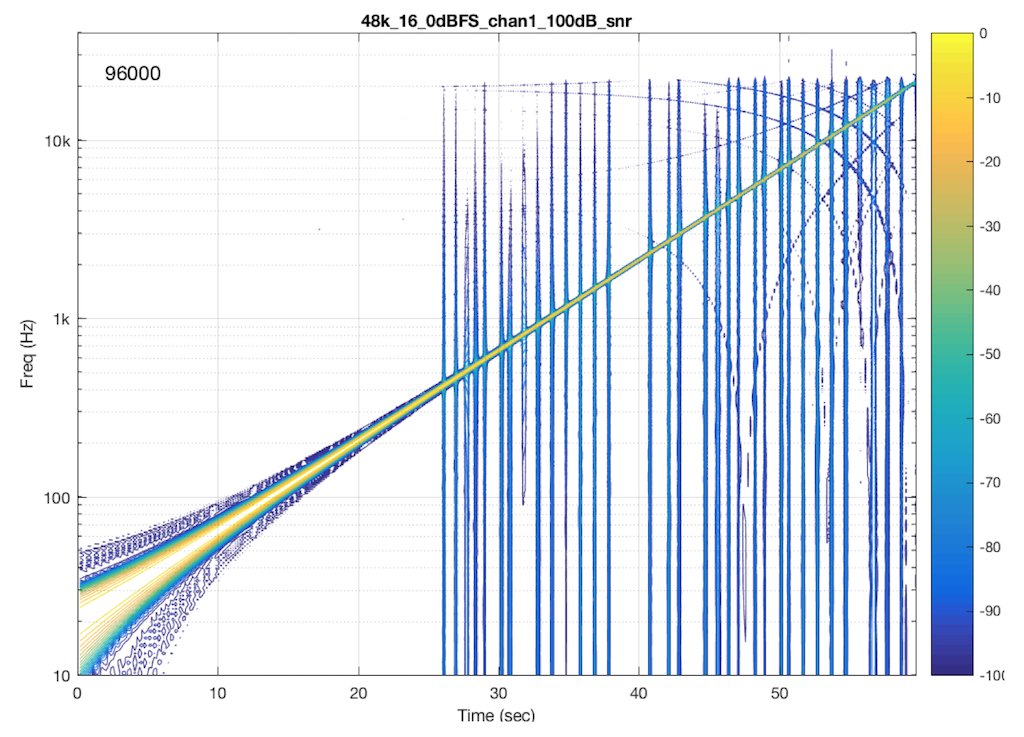
Now that you know what to look for in the plot, let’s look at the measurements of some commercially-available systems. Figure 5, below is a measurement of a system that has two problems. One can be seen as the vertical lines – these are “skip/insert” artefacts that I described in an earlier posting. The aliasing artefacts can also be seen in this plot. Note that, in this case, the input and output of the system are both digital connections to my measurement equipment.
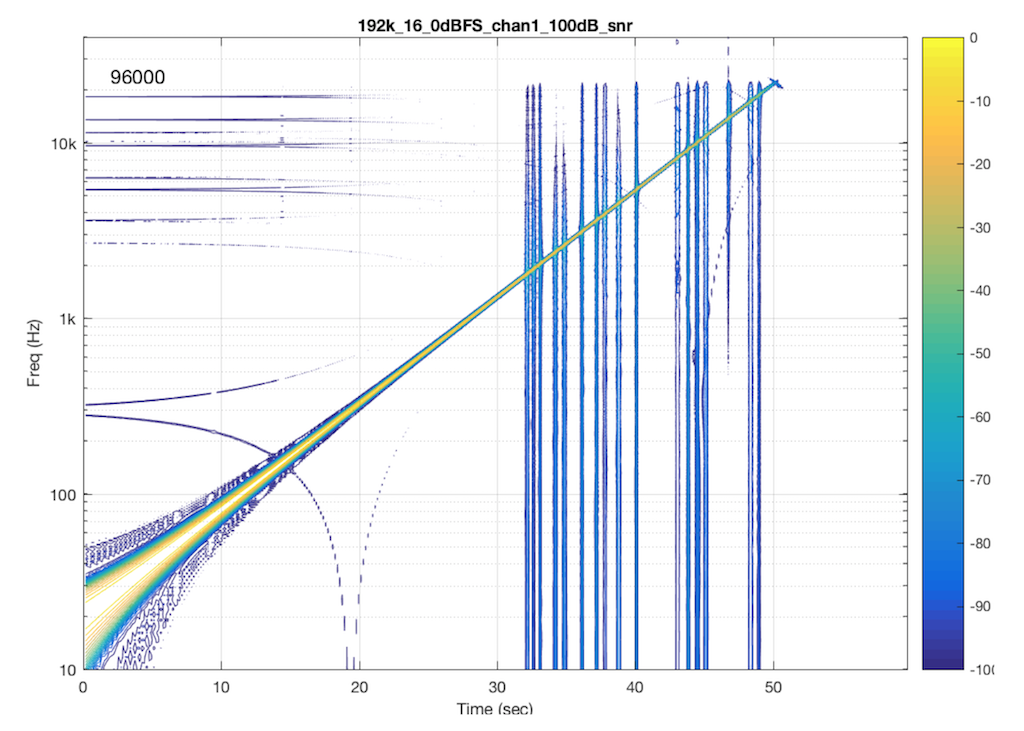
If I send a signal at a different sampling rate into the same system, I get a different behaviour. This is not unusual in systems with sampling rate converters. In this plot, you can see the skip/insert artefacts (the vertical stripes) the aliasing artefacts, and the obvious band-limiting of the system. Notice that nothing above about 24 kHz comes out of the system, which would mean that, internally, it is probably running at a sampling rate of 48 kHz. (The input signal in this measurement was at 192 kHz and my analysis system was running at 96 kHz.)
Let’s look at another system. In this case, I put a 48 kHz, 16-bit .flac file on a hard drive, and played it through another digital audio system, again capturing its digital output. The result of this is shown in Figure 7.
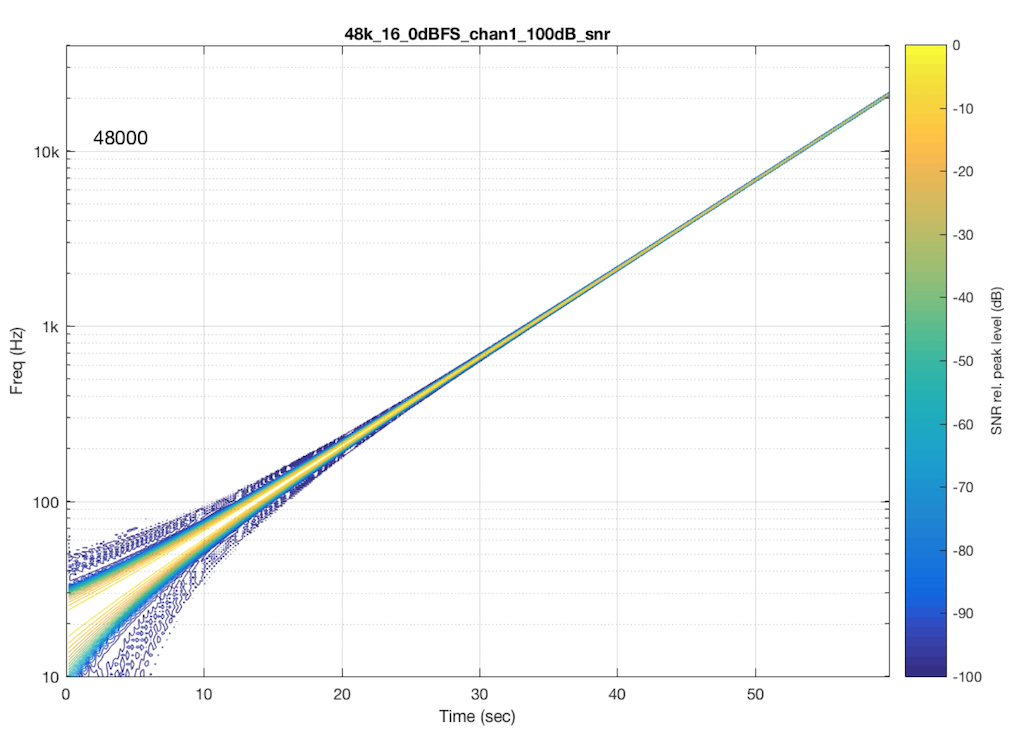
As you can see in Figure 6, this system is behaving very well in this particular test. I see the nice, clean signal with only one frequency at only one time. No artefacts down to 100 dB below the signal level. This is good.
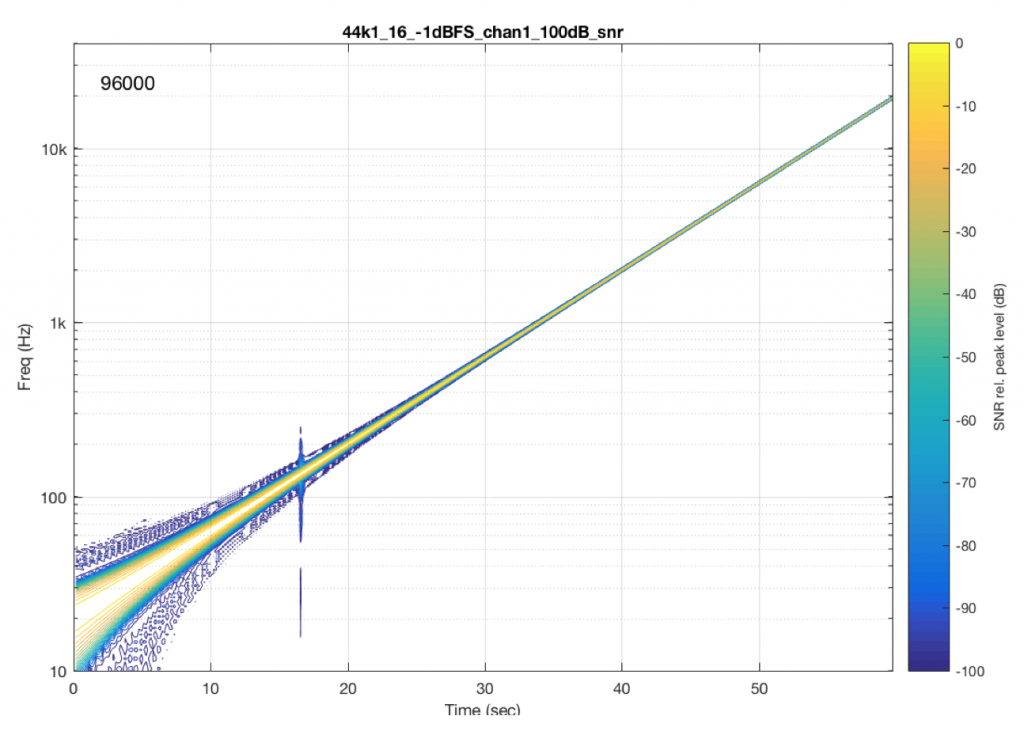
Now let’s test exactly the same system, at exactly the same sampling rate, again with a .flac file – but this time with a 24-bit word length in the file. The result of this is shown in Figure 7.
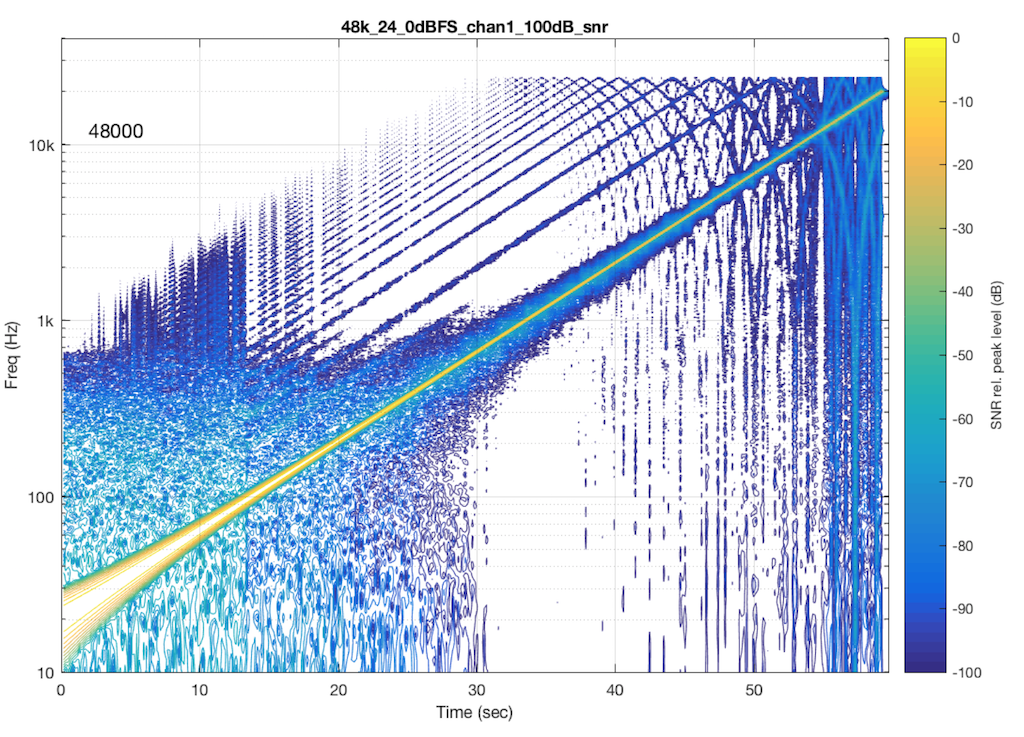
So, by going from a 16-bit file to a 24-bit file, this system obviously behaves very, very differently. It now has harmonic distortion (the straight diagonal lines running parallel to the fundamental frequency), aliasing of those harmonics when they go beyond 24 kHz, and strange noises as well (the large area of blue blobs in the lower left corner, and surrounding the fundamental frequency all the way up.
Those “strange noises” – the blobs – are probably artefacts caused by a lossy codec similar to MP3. Typically, systems like this are built to reduce the data rate of the audio signal by trying to predict what you can’t hear in the signal – and leaving that out. In doing so, they create errors that produce noise, so the encoder tries to shape that noise so that it “hides” under the signal that it keeps. The end result looks something like the blobs shown in Figure 7… For a more thorough discussion of this, see this posting.
So, based only on the information from this test, we can guess that the system might be decoding the 24-bit file, “transcoding” it to a lossy format, and transmitting that through the system. However, this is just a guess based on one test… So it could easily be wrong.
One thing we can conclude, however, is that the 48 kHz / 16-bit file behaves MUCH better than a 48 kHz / 24-bit file in this system… So, in this particular case, a higher resolution is not necessarily better…
I should also point out that the digital output of that system was capable of outputting 24 bits. The reason I’m pointing this out is that many persons think that if a system or device has a digital output, then it is good. This is too simple a conclusion to make, because, as I’m trying to illustrate with this series of postings, the “weak link” in the chain is very likely NOT the physical output of the system. It’s more likely some part of the processing in the DSP chain (for example, a poorly-made sampling rate converter that aliases) or a poorly-implemented clocking system (for example, a skip/insert strategy).
If you’re intrigued by this, and you’d like to compare the aliasing caused by other sampling rate converters, I’d recommend checking out the page at http://src.infinitewave.ca. They plot the signals with a linear frequency scale instead of a logarithmic one. Consequently, the sweep of the fundamental looks like a curve (instead of the straight lines in my plots) but the harmonic distortion and aliasing artefacts are easier to see as being related to the fundamental.
Last week, I ran a quick test on another commercially-available device – this time, a stand-alone audio file player with a digital output. I was running the test using a 44.1 kHz, 16-bit FLAC file, but the device had a 48 kHz output. The interesting thing about this one was that the artefacts that showed up were almost exclusively aliasing errors. So, I thought it would be interesting to show the plots here.
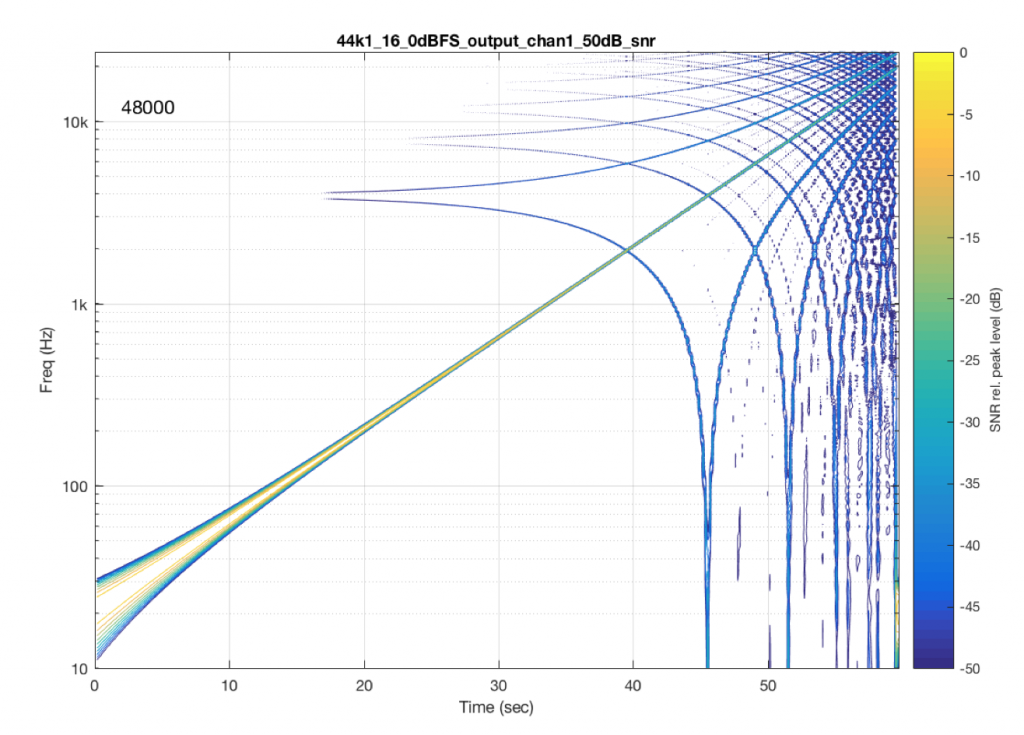
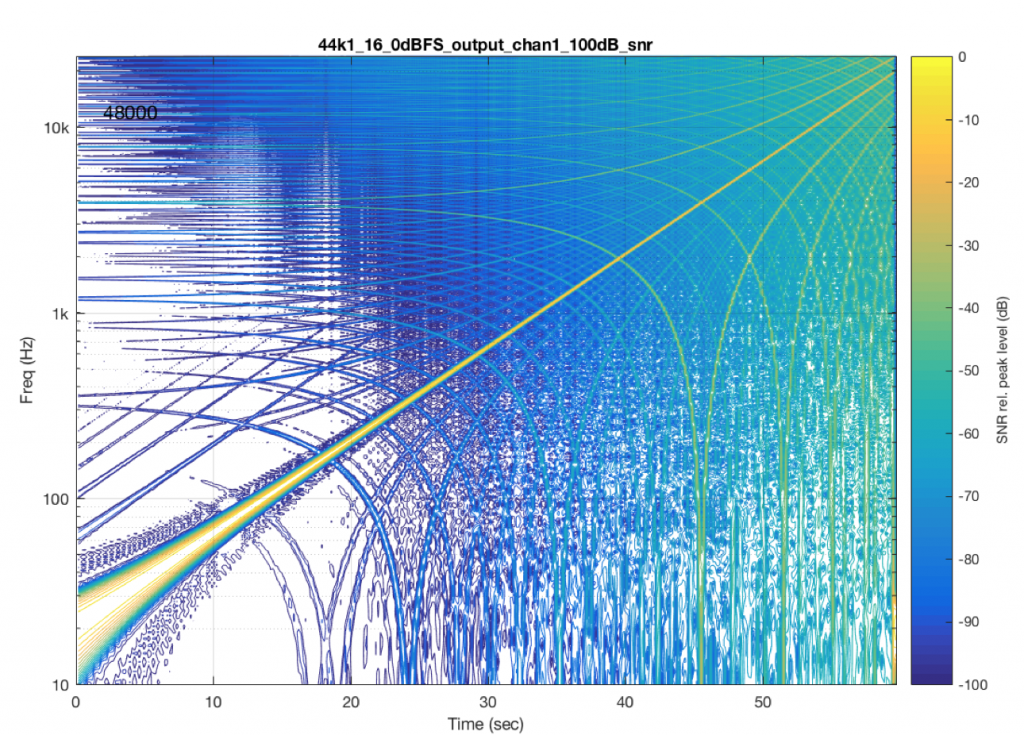
I’m originally from Newfoundland – one of the few places in the world with a 1/2-hour time zone. So, when it’s 10:00 a.m. in Montreal, it’s 11:30 a.m. in St. John’s – my home town. This meant that, when I was a kid 40 years ago, and we would call our relatives in Toronto or Germany to wish them a Merry Christmas, there were two questions that you could always rely on being asked: (1) what’s the weather like there? and (2) what time is it there?
These days, I have a similar problem that is well-described by “Segal’s Law“. My iPhone and my wristwatch (an old analogue one with hands that go around pointing at the floor and the fridge…) are never synchronised… This is because of two things: (1) I probably did a bad job of setting my watch and (more importantly) (2) my watch runs just a little bit slowly…
So, let’s say, for example, that I set my watch to be EXACTLY in sync with my phone on a Monday morning at 9:00 a.m. As the week goes by, my iPhone and my watch drift apart, and, just for the sake of argument let’s say that, one week later, when my iPhone turns over to 9:00 a.m. on Monday morning, my wristwatch turns over to 8:59 a.m. So, I lose 1 minute per week on my watch.
(It’s pretty safe to assume that my iPhone is also not perfect – but it’s different because, every once in a while, it compares its internal clock with another, more accurate clock somewhere else via a connection across the Internet (which, we will assume, for the purposes of this discussion, works).)
Let’s consider this from a strange point of view. Let’s assume that
If we think about this from my perspective, I’ll live in a strange world where 8:59 on Mondays never exists. This is because at 8:58 and 30 seconds (on my watch), my friend re-sets the time to 8:59 and 30 seconds (while I’m not looking) to synchronise with the iPhone…
IF my watch was running fast – say, gaining one minute each week, then I would live in a different strange universe where 9:00 happens twice every Monday morning…
The basic problem here is that we have two clocks that do not run at the same rate – but they are expected to do so. So, we synchronise them regularly (in the above example, on Monday mornings at 9:00) – but between those synchronisation events, they drift apart in time.
The example above is very, very similar to the way a digital audio streaming system works – especially if you’re using a wireless connection between the transmitting device and a receiver.
Lets say that you’re playing a sound file that was recorded at 44.1 kHz and streaming it wirelessly to a receiver. I’m trying to be as generic as possible here, but I could be talking about a Bluetooth connection to a pair of headphones or a WiFi connection via DLNA to a device connected to a pair of loudspeakers, for example…
It is not unusual with such a connection for the transmitter to collect up a block of audio samples – say, 64 of them – and send them to the receiver’s input buffer. The receiver then pulls those samples out, one by one, and (eventually) sends them to a digital-to-analogue converter that produces a signal that (eventually) comes out as an audio signal. Then, 64/44100’ths of a second later (64 samples later) the transmitter sends another block, and so on and so on until the song ends.
This system works well if the clock inside the transmitter and the clock inside the receiver are perfectly synchronised. We can even be a little generous and say that they can drift apart a little – but not so much that we either run out of samples to play (because the receiver is playing them out faster than they’re coming in from the transmitter) or that we have samples left over to play when the next block comes in (because the receiver is playing them out slower than they’re coming in from the transmitter).
The right way to deal with this issue is for the receiver to always be checking what time it thinks it is when the block arrives from the transmitter. If the block arrives a little early, then the receiver should think “hmmmm, my clock is going too slowly – I’ll speed it up a bit”. If the block arrives a little late, then the receiver should adjust its clock to go a little slower.
So, in this case, the receiver has a basic, nominal speed for its internal clock – but it’s constantly adjusting it to be faster and slower to try and match the clock of the transmitter – but it can only do this adjustment at the block rate – the frequency at which the blocks of samples arrive, which is dependent on the block length (how many samples are in each block) and the sampling rate (how many samples per second). (Of course, this can result in “jitter and wander” problems if you’re not careful (I won’t talk about this here…) – so you have to pay a little attention to how quickly you’re adjusting your clock rate… but that’s “just” a matter of correct implementation.)
There is another way to deal with this problem, which, unfortunately, has measurable and possibly audible consequences. This implementation is basically the same as my original example, where I had a friend “fixing” my wristwatch once a week. You have a transmitter that sends blocks of samples to the receiver – and although these two devices should have exactly the same clock rate, they don’t.
Let’s say, for example, that the receiver is playing the samples faster than they’re being sent by the transmitter. This means that the two will slowly drift farther and farther apart until, eventually, the receiver will have to play a sample, but nothing has come in from the transmitter yet, so there’s no sample there to play. In this case, the receiver says “no problem, I’ll just play the last sample again, and the next block will come in while I’m doing that” – so it inserts an extra sample that is just a duplicate of the previous one.
If the receiver’s clock is going slower than the transmitter’s, then, as the two drift farther apart, we will get to a moment where the receiver will receive a new block of samples but it’s not done playing all of the samples in the previous block yet. In this event, it says “no problem, I’ll just leave that last sample out and move on to the next block to catch up” – so it skips a sample.
This is called a “Skip / Insert” strategy for dealing with clock synchronisation. It’s done by software and hardware engineers because it’s simple to implement, and, in many cases, a manufacturer can get away with this, since it is rarely audible for a couple of reasons.
The simple answer to this is “yes” – and it can be measured in a number of different ways. I’ll show one way below…
The honest answer to this question is “sometimes” – but it’s not as easy to detect as one might think. Of course, a skip/insert event (a duplicated sample or a dropped one) creates an artefact. However, the magnitude of this artefact relative to the “correct” signal is dependent on when it happens.
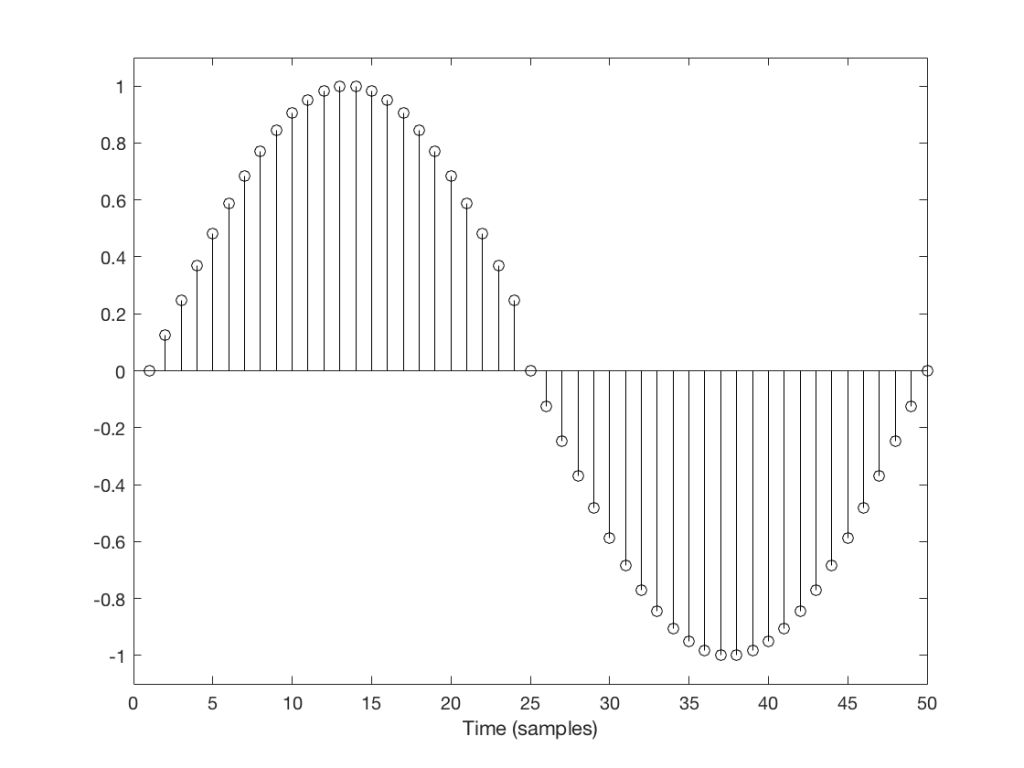
Let’s take a look at a couple of simple cases. We’ll “transmit” one period of a sine wave that should come out on the other side of the system looking like Figure 1.
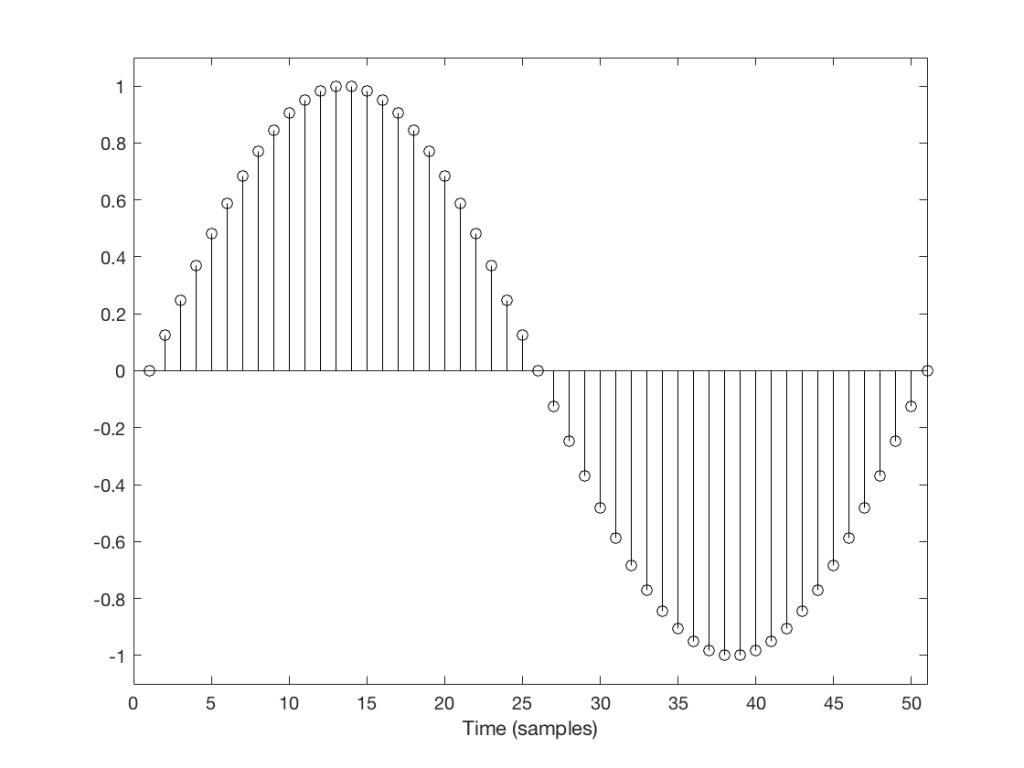
But what happens if we don’t get a block in time to keep outputting a signal? We insert a duplicate sample and hope that the block comes in before I have to send out another one. Examples of this are shown in Figures 2 and 3, below.
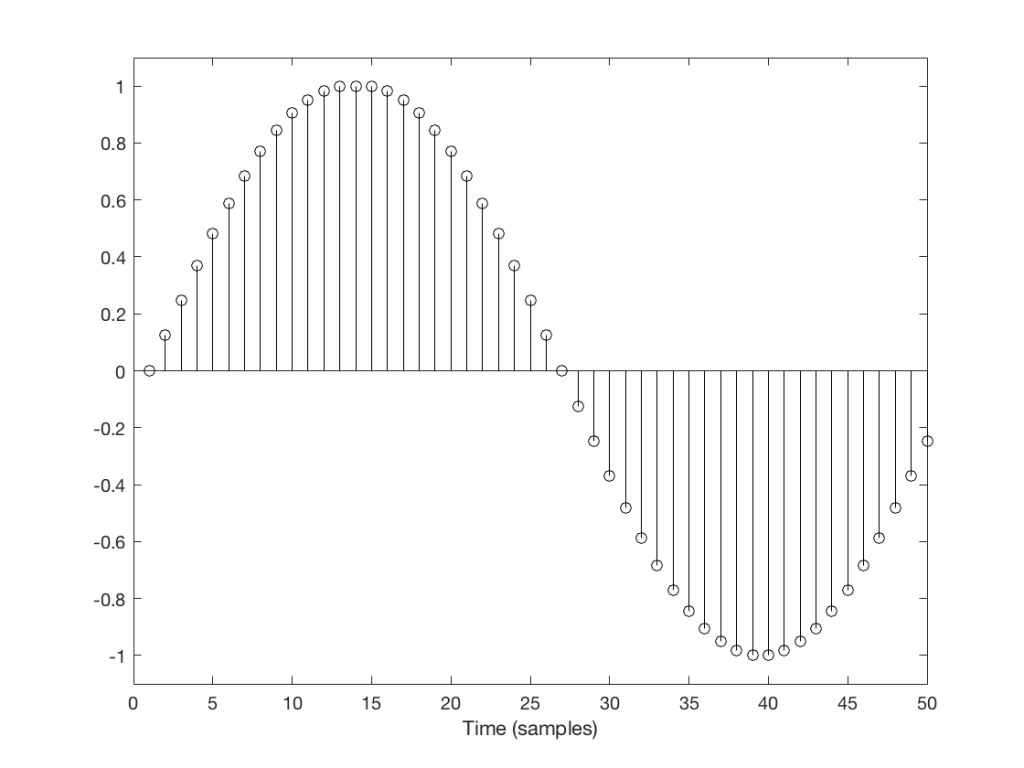
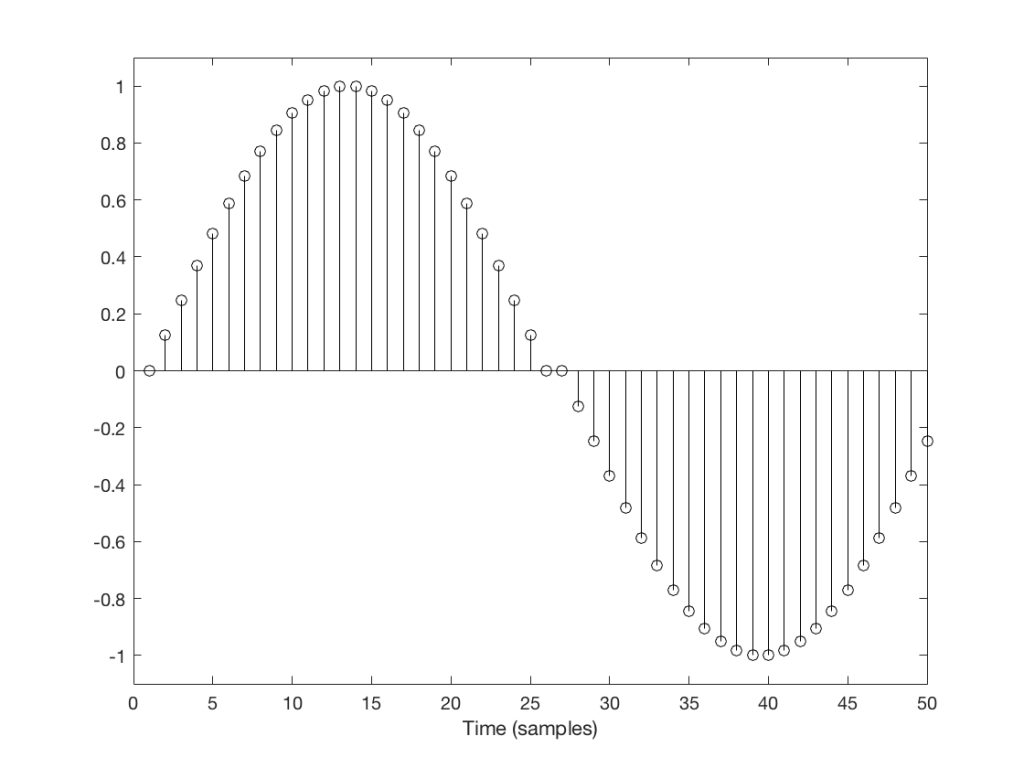
You’ll probably notice that it’s much easier to see which sample I duplicated in Figure 3 than in Figure 2. In Figure 3 it was sample number 26 that was duplicated. In Figure 2 it’s sample number 13.
The reason it’s easier to see the error in Figure 3 is that duplicating the sample causes an obvious change in the slope of the signal, whereas in Figure 2 it does not – the slope of the signal is 0, and by duplicating a sample, I am also making it 0 – but for a slightly longer time.
This does not mean that we did not generate an error. It just means that we’ll probably “get away with it” in the case of Figure 2, and we probably won’t in the case of Figure 3.
However, since the drifting of the two clocks (in the receiver and transmitter) are not dependent on the signal, there’s no way to know when this is going to happen.
And, of course, if this happens in the middle of a snare drum hit or a ssssinger sssstarting a word in a ssssong with the letter “s” – then we also won’t hear it because there’s so much going on (frequency-wise) that the artefact will be buried in the mess.
Also, since this clock drifting is usually not completely regular, the errors do not usually come in at a regular rate (although I’ve seen exceptions…). So, it’s not like you can listen for “a click every second” or “one per minute”. They happen when they happen – hopefully when you’re not listening and/or when the tune is busy enough to hide it.
A skip event is similar to an insert, as you can see in the two examples in Figures 4 and 5.
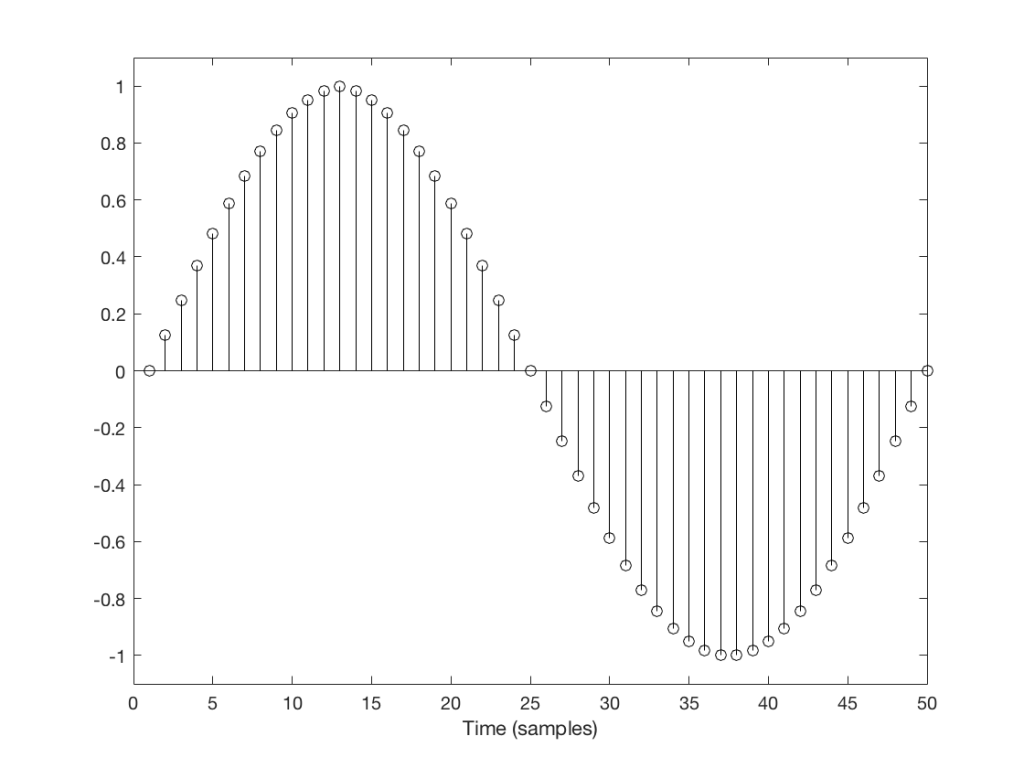
Again, I’ve intentionally put in these two skips in places where they are least obvious (Figure 4) and most obvious (Figure 5).
One of the tests that can be done on an audio system is to send a sinusoidal signal with a swept frequency through a system, capture the output, and then do a spectrogram of the result. In theory, if you see anything other than a single frequency at any one time at the output, then you know that something has happened to the signal. You would probably then need to go back and look at the output signal itself to start evaluating exactly what happened… This is a test that is used to evaluate one aspect of the performance of different sampling rate converters, for example, at this site.
Let’s take a sine sweep and run it through a system. The sweep goes up logarithmically in frequency from 20 Hz to about 90% of Nyquist (which would correspond to 20,000 Hz in a system running at 44.1 kHz) over 60 seconds and has a level of -1 dB FS. We’ll then capture the output in a system that is behaving perfectly and do a spectrogram of this, looking for artefacts down to some level below the signal level. (If you’re really geeky, you’ll know that this signal-to-error ratio is dependent on the window length of the FFT I’m using to create the spectrogram – but this is beyond our discussion today…).
An example of the output of a system that is behaving well is shown in Figure 6.
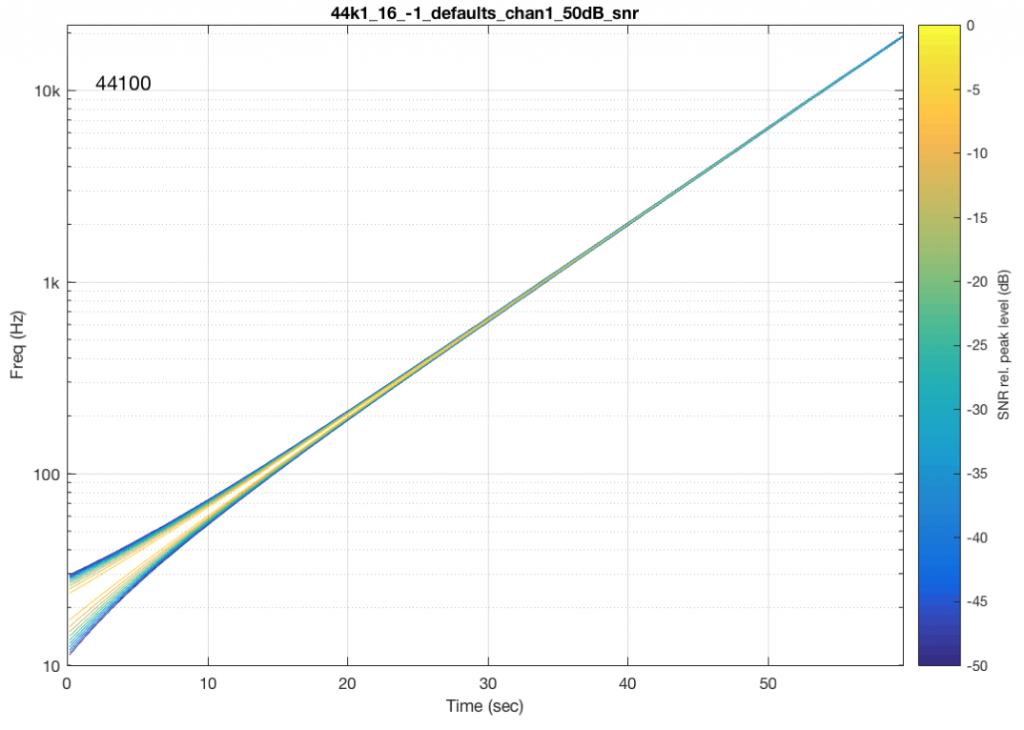
You may notice that the plot looks a little “wide” in the beginning. This is because the window length of the FFT I’m using to analyse the signal isn’t long enough to get a precise analysis of a low-frequency signal. So, this is an artefact of the analysis – not an error in the playback system.
What happens if we have random skip/insert events in the system? This is shown in Figure 7.
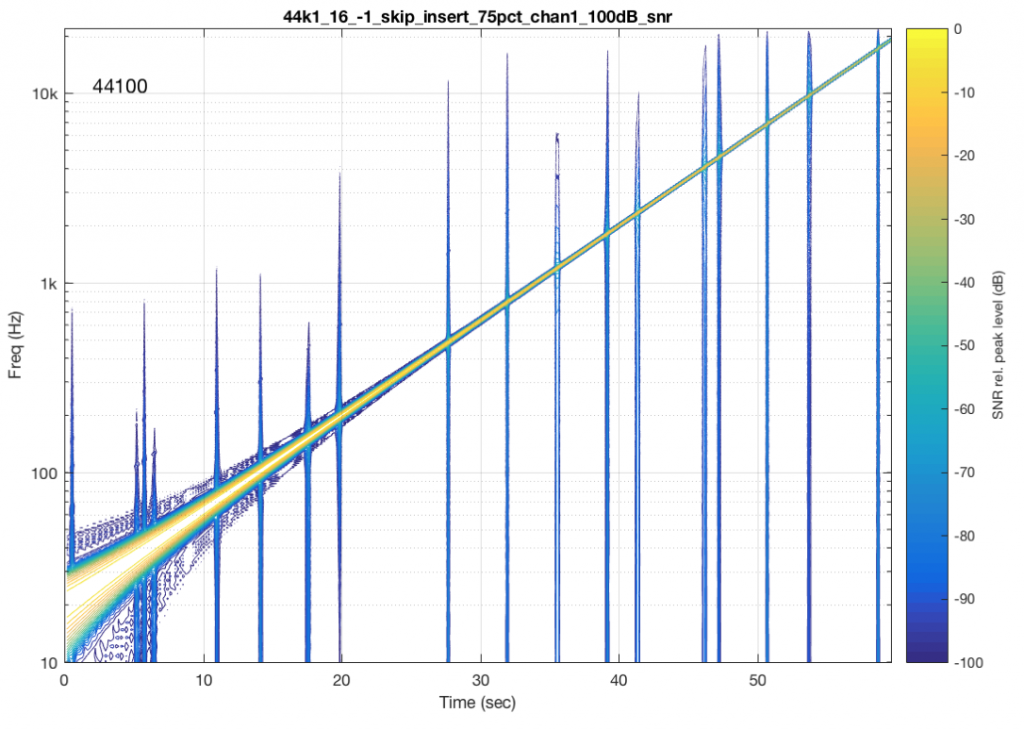
The signal in Figure 7 was one that I created – I intentionally made skip/insert events at random times and applied them to my test signal.
There are two things to notice here. The first is that each event is visible as a vertical “spike” in the plot. This is because a skip/insert event will cause a short, wide-band “burst” that sounds like a click. However, the bandwidth of the click is dependent on when it happens relative to the signal. For example, the skip/insert events in Figure 2 and 4 would not create as much high-frequency energy as the ones in Figure 3 and 5. So, the bigger the effect on the slope of the signal, the more high frequency energy we’ll get in our “click” sound. Since the slope of a signal increases with frequency, then this also means that low-frequency signals will likely produce lower-bandwidth artefacts.
Now let’s look at the results from some real-world devices and systems that are commercially available.
As you can see in Figure 8, there was one skip/insert event that happened during the 60 seconds I was running this test. Remember that the time that that event happened had nothing to do with the frequency it was playing. It just happens when it happens due to the relationship between the transmitter’s and the receiver’s clock speeds.
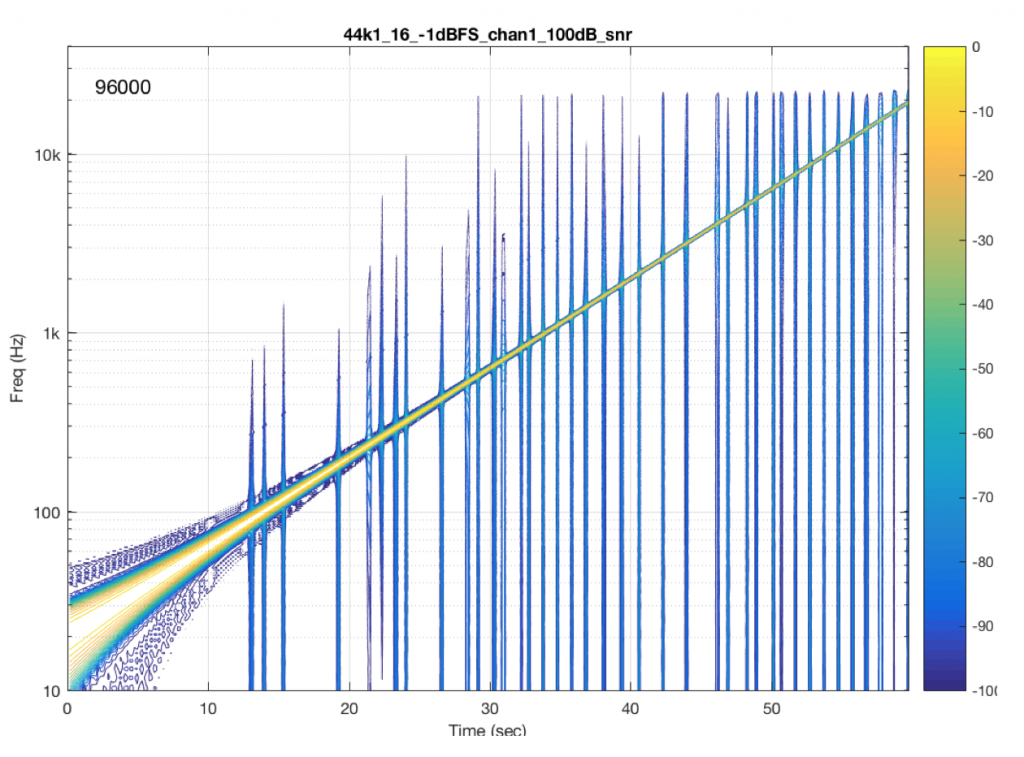
Figure 9 shows the results from a different system/device that obviously uses a skip/insert strategy to deal with clock synchronisation problems. It also obviously has some serious clock issues, since it has to correct on the order of approximately once a second…
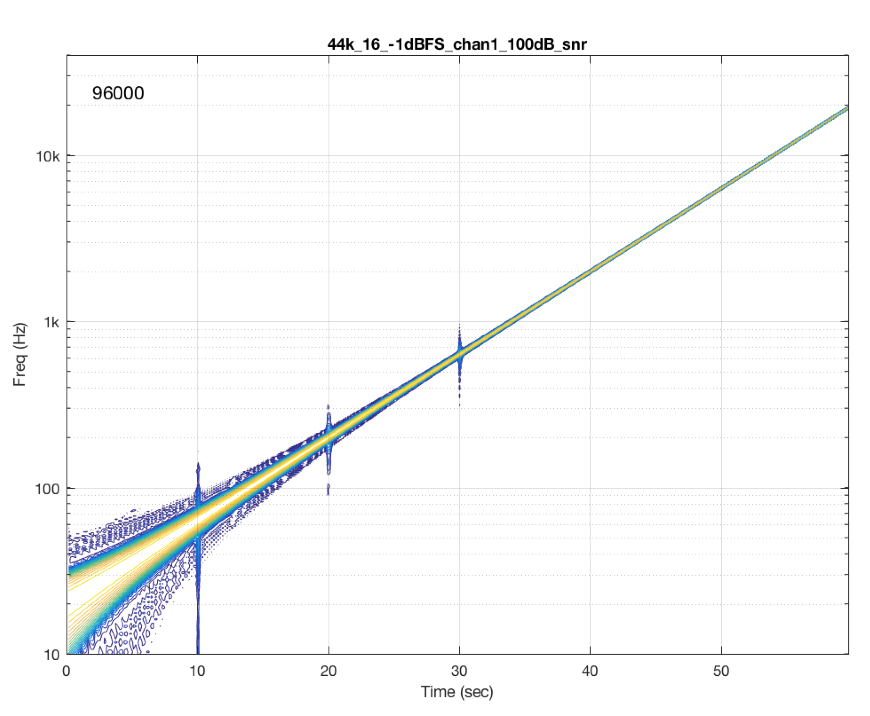
Figure 10 shows the results from a different system/device that uses a skip/insert strategy – but appears to do so at scheduled intervals. In this case, there is a high probability of getting a skip/insert event every 10 seconds with the counter starting at the instant I starting hearing the music.
Inquisitive readers may be asking why it is that, although I’m doing an analysis down to -101 dB FS (100 dB below the signal level of -1 dB FS), you can’t see the effects of the dither noise floor in my original 16-bit file (which is normally assumed to be at -93 dB FS). This is because the -93 dB FS estimate of a dither signal assumes that you are looking at the total energy from the entire frequency band. The spectrograms above are based on FFT’s that split up the total frequency band into “slices” (called frequency bins) – and the total energy in each of these bins is less than the total energy in all of them (one person clapping is not as loud as 1000 people clapping at the same time…). If we wanted to see the dither noise, I would have had to set my analysis to go down approximately 30 dB lower – but the actual value for this is dependent on the relationship between the sampling rate, the window length of the FFT’s, and the windowing function that I’m using.
Do not bother contacting me to ask which “commercially-available system/device” I measured and in which I found these errors. I’m not doing this to get anyone in trouble. I’m just doing this to try to illustrate common errors that I see often when I evaluate and test audio devices.
An besides, it would not be fair for me to rat on specific companies, systems, or devices, since, in some cases, these errors may have already been fixed with a firmware update, meaning that “naming names” would be irrelevant and unnecessarily detrimental.
But, I will say that I see this problem often. A rough estimate is that I would see errors like this on roughly half of the commercially-available devices and systems I test. It can also be sneaky, as we saw in Figures 8 and 10. Sometimes you get one of these clicks only once in a minute. So, if you do a 10-second measurement to test if your wireless audio receiver is “bit accurate” – the answer can be “yes” – but if you keep measuring for 1 or 2 minutes, you find out the answer is “no”…
If it helps, I could have used the example of a leap year instead of two clocks at the beginning. The reason we have a February 29 every 4 years is that our calendar “runs” a little faster than the time it takes us to get around the sun (because a “year” is actually 365.25 days long…). So, every 4 years we have to “insert” a day to put the two clocks back in sync.
Also, since a “year” is not exactly 365.25 days long, we also have the occasional “leap second” as well. But most people don’t notice this, since it’s rarely useful as an excuse when you’ve missed a meeting…
It was the third of June, another sleepy, dusty Delta day
I was out choppin’ cotton, and my brother was balin’ hay
I’ve always liked the song “Ode to Billy Joe”. It starts on a 7-chord, so you know it’s going to go somewhere… I love how Papa, when he hears that Billy Joe jumped off the Tallahatchie Bridge just says that he “never had a lick of sense”, and asks for more biscuits. And who, exactly, did Brother Taylor see with Billy Joe? What did they throw off the bridge?
I like the fact that there are many questions and few answers – and life just goes on anyway…
But we’re not here to talk about songwriting, we’re here to talk about typical errors in digital audio – specifically today – streaming services.
This error is an easy one to discuss – but an important one nonetheless…
When I’m sitting at work, typing on my computer, I listen to music a lot. Usually, I use the “Audirvana” software on my Mac, with an external Teac UD-501 USB-Audio headphone DAC (which does the digital-to-analogue conversion and the amplification for the headphones, all in one box). The reasons I choose to use Audirvana are (1) that it can play all of my files (I have some DSD stuff on my hard drive), it can stream directly to my external DAC without routing the audio through Mac’s OS, and it can also see my Tidal account.
Now, just to be clear, this posting is not an advertisement for Apple, Audirvana, Teac, or Tidal. I mention all of that just as background information… I also drive an 11-year old base-model Honda Civic (that will come up later in this posting) and I wear Ecco shoes (which is completely irrelevant…).
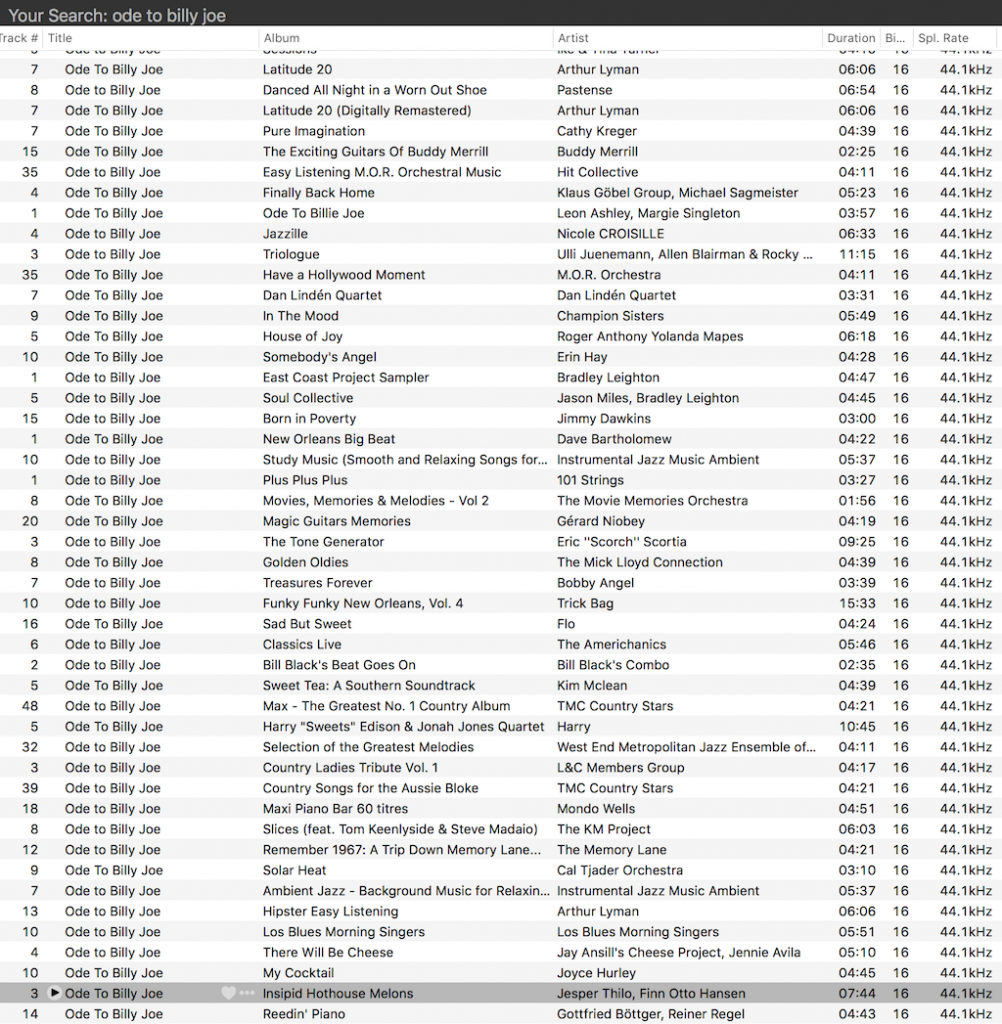
If you use Audirvana to search Tidal for tracks called “Ode to Billy Joe” You will get 300 hits. I don’t know if this is because there are 300 covers of that song on Tidal (I doubt it) or if 300 is a limit on the number of tracks either Tidal or Audirvana will report in a Search function (I suspect that this is the case…)
As you can see in the screenshot in Figure 1, all of them are 16 bit, 44.1 kHz files. So far so good…
I have two favourite versions of this song. One of them is by Paula Cole (the other is by Patty Smyth). If I press “play” on the Paul Cole version, and I look at the top of the screen, I see something like the screenshot in Figure 2.

One of the nice things about Audirvana is that it tells you a little technical information about the track to which you’re listening. Notice there on the right-hand side of the screenshot above, that we’re listening to a 16-bit, 44.1 kHz FLAC file.
This makes sense. In fact, it’s what I expect, since my Tidal subscription promises “lossless high fidelity sound quality” – that’s why I pay extra for a Tidal HiFi subscription…
So far so good.
One of my less-favourite renditions of “Ode to Billy Joe” is performed by The Stadium Saxophone Players on their album “Timeless Sax Instrumentals – Volume 2”. IF I press play on this version, and look at the top of my Audirvana window, I see the information in Figure 3.

Interesting…. Notice that I am now listening to a 96 kbps AAC file with a 16-bit word length, and a sampling rate of “22.1 kHz” (actually 22.05 kHz – half of 44.1). So much for “lossless high fidelity sound quality”.
This calls for more investigation.
So, I pressed “Play” on the top hits in my search, one by one, and checked the file format displayed on the screen. The results of this “test” was that, in the first 66 “Ode to Billy Joe’s” listed, 6 of them were 96 kbps AAC files, 60 of them were FLAC.
So, for this sampling, roughly 9% of the available tracks were not in a lossless format, and were not even full bandwidth. Admittedly, the tracks that were in the lower-quality format were versions that I would not listen to anyway – so, to be honest, I don’t really care too much.
Now, before you mis-interpret me, I want to be very explicit and state that this is NOT Tidal’s fault. Of course they did not ask for an AAC version of the file they put on their hard drives. This was the file format supplied to them by the record label (to use an increasingly old-fashioned term…). So, we can’t blame Tidal for this – and I’m quite certain that they’re not the only streaming service that “suffers” from this issue.
However, what my little test shows is that what Tidal is actually selling me is the capability of streaming “lossless high fidelity sound quality” – and not a guarantee that what is in the “pipe” really is lossless.
Of course, this is not just true for streaming services. Other people have shown that some higher-priced “high resolution” audio files that you can purchase online are actually just a bit-for-bit copy of the “normal resolution” version of the same track. I have at least one CD that contains at least one track that has MP3 artefacts obvious enough that I can hear them on my unbranded audio system in my 11-year old Honda Civic while I’m driving… (It’s a compilation disc, so I guess the label was supplied with an MP3 version that they decoded to PCM and put on the CD.)
So, just like Ode to Billy Joe – there are some questions here… and you don’t need to know much about digital audio to answer them… But the basic moral of this part of the story is that the format that is used to deliver your music is not a guarantee of higher quality…