As a setup for this posting, I have to start with some background information…
Back when I was doing my bachelor’s of music degree, I used to make some pocket money playing background music for things like wedding receptions. One of the good things about playing such a gig was that, for the most part, no one is listening to you… You’re just filling in as part of the background noise. So, as the evening went on, and I grew more and more tired, I would change to simpler and simpler arrangements of the tunes. Leaving some notes out meant I didn’t have to think as quickly, and, since no one was really listening, I could get away with it.
If you watch the short video above, you’ll hear the same composition played 3 times (the 4th is just a copy of the first, for comparison). The first arrangement contains a total of 71 notes, as shown below.

The second arrangement uses only 38 notes, as you can see in Figure 2, below.

The third arrangement uses even fewer notes – a total of only 27 notes, shown in Figure 3, below.

The point of this story is that, in all three arrangements, the piece of music is easily recognisable. And, if it’s late in the night and you’ve had too much to drink at the wedding reception, I’d probably get away with not playing the full arrangement without you even noticing the difference…
A psychoacoustic CODEC (Compression DECompression) algorithm works in a very similar way. I’ll explain…
If you do an “audiometry test”, you’ll be put in a very, very quiet room and given a pair of headphones and a button. in an adjacent room is a person who sees a light when you press the button and controls a tone generator. You’ll be told that you’ll hear a tone in one ear from the headphones, and when you do, you should push the button. When you do this, the tone will get quieter, and you’ll push the button again. This will happen over and over until you can’t hear the tone. This is repeated in your two ears at different frequencies (and, of course, the whole thing is randomised so that you can’t predict a response…)
If you do this test, and if you have textbook-quality hearing, then you’ll find out that your threshold of hearing is different at different frequencies. In fact, a plot of the quietest tones you can hear at different frequencies it will look something like that shown in Figure 4.
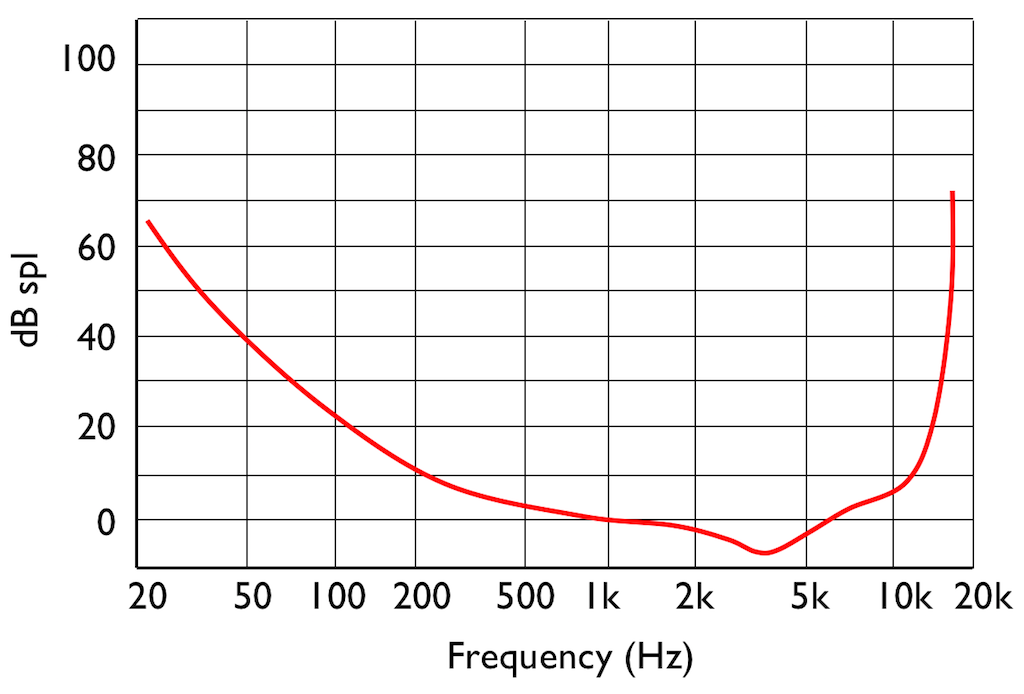
This red curve shows a typical curve for a threshold of hearing. Any frequency that was played at a level that would be below this red curve would not be audible. Note that the threshold is very different at different frequencies.

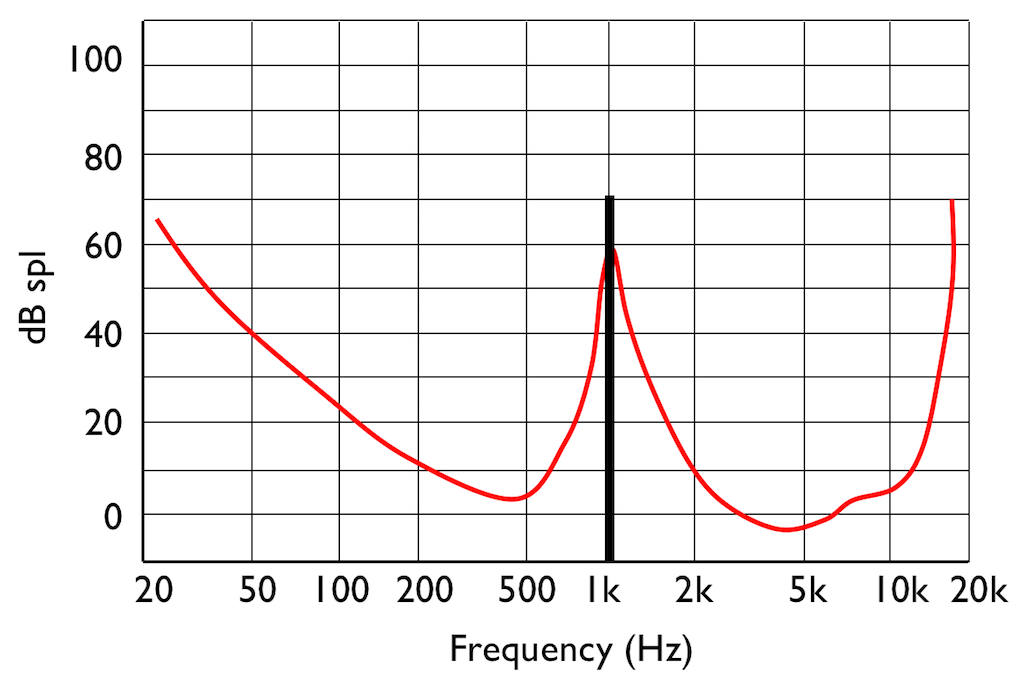
Interestingly, if you do play this tone shown in Figure 5, then your threshold of hearing will change, as is shown in Figure 6.
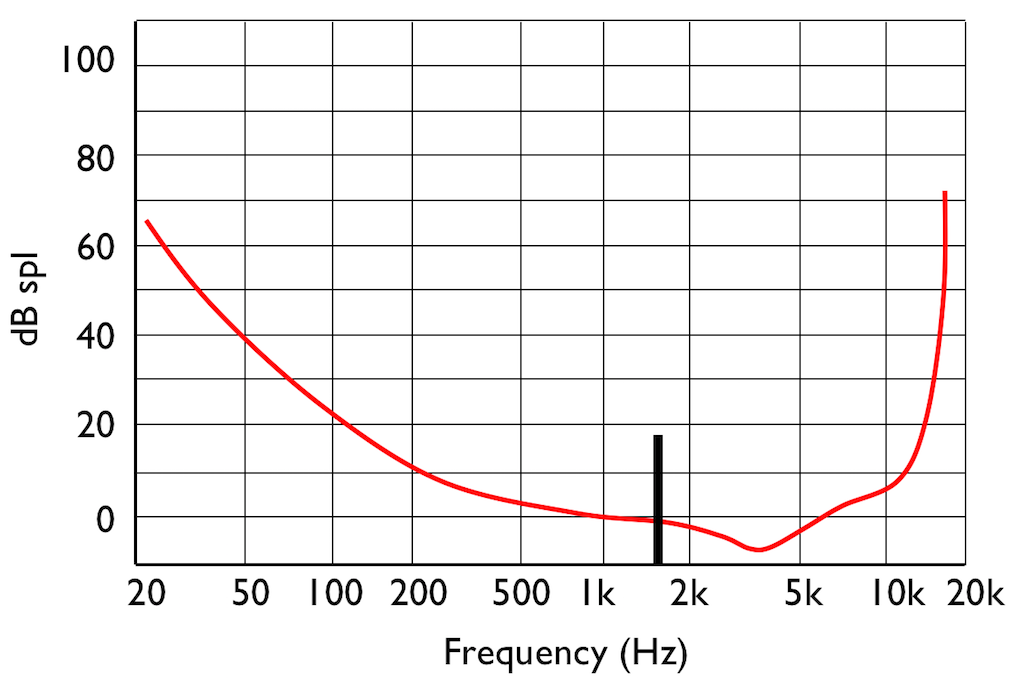
IF you were not playing that loud 1 kHz tone, and, instead, you played a quieter tone just below 2 kHz, it would also be audible, since it’s also above the threshold of hearing (shown in Figure 7.
However, if you play those two tones simultaneously, what happens?
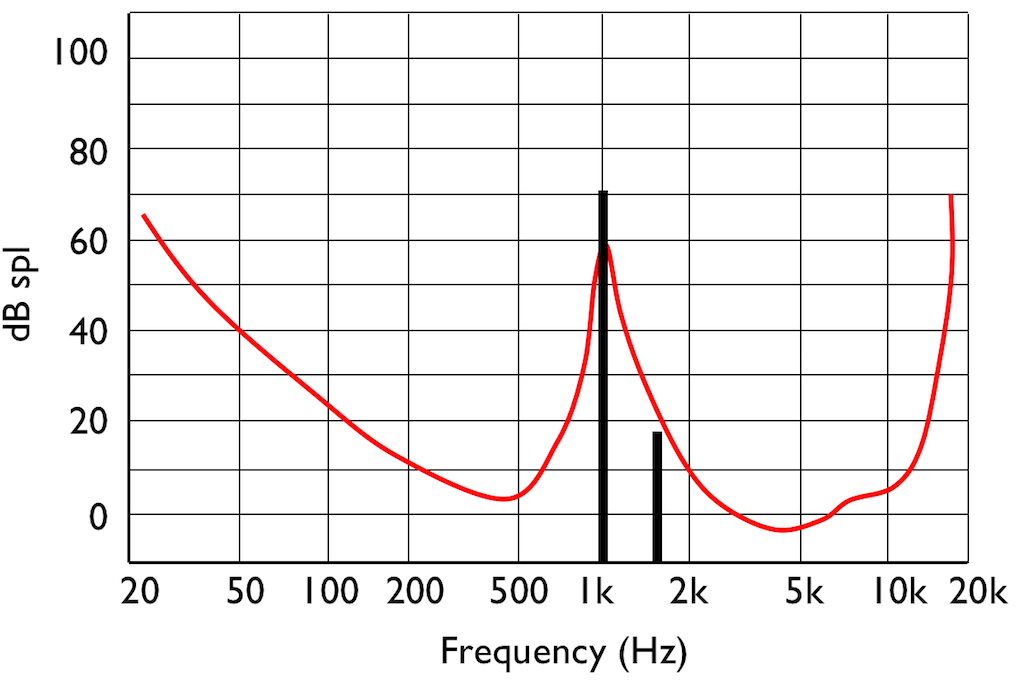
This effect is called “psychoacoustic masking” – the quieter tone is masked by the louder tone if the two area reasonably close together in frequency. This is essentially the same reason that you can’t hear someone whispering to you at an AC/DC concert… Normal people call it being “drowned out” by the guitar solo. Scientists will call it “psychoacoustic masking”.
Let’s pull these two stories together… The reason I started leaving notes out when I was playing background music was that my processing power was getting limited (because I was getting tired) and the people listening weren’t able to tell the difference. This is how I got away with it. Of course, if you were listening, you would have noticed – but that’s just a chance I had to take.
If you want to record, store, or transmit an audio signal and you don’t have enough processing power, storage area, or bandwidth, you need to leave stuff out. There are lots of strategies for doing this – but one of them is to get a computer to analyse the frequency content of the signal and try to predict what components of the signal will be psychoacoustically masked and leave those components out. So, essentially, just like I was trying to predict which notes you wouldn’t miss, a computer is trying to predict what you won’t be able to hear…
This process is a general description of what is done in all the psychoacoustic CODECs like MP3, Ogg Vorbis, AC-3, AAC, SBC, and so on and so on. These are all called “lossy” CODECs because some components of the audio signal are lost in the encoding process. Of course, these CODECs have different perceived qualities because they all have different prediction algorithms, and some are better at predicting what you can’t hear than others. Also, depending on what bitrate is available, the algorithms may be more or less aggressive in making their decisions about your abilities.
There’s just one small problem… If you remove some components of the audio signal, then you create an error, and the creation of that error generates noise. However, the algorithm has an trick up its sleeve. It knows the error it has created, it knows the frequency content of the signal that it’s keeping (and therefore it knows the resulting elevated masking threshold). So it uses that “knowledge” to shape the frequency spectrum of the error to sit under the resulting threshold of hearing, as shown by the gray area in Figure 9.
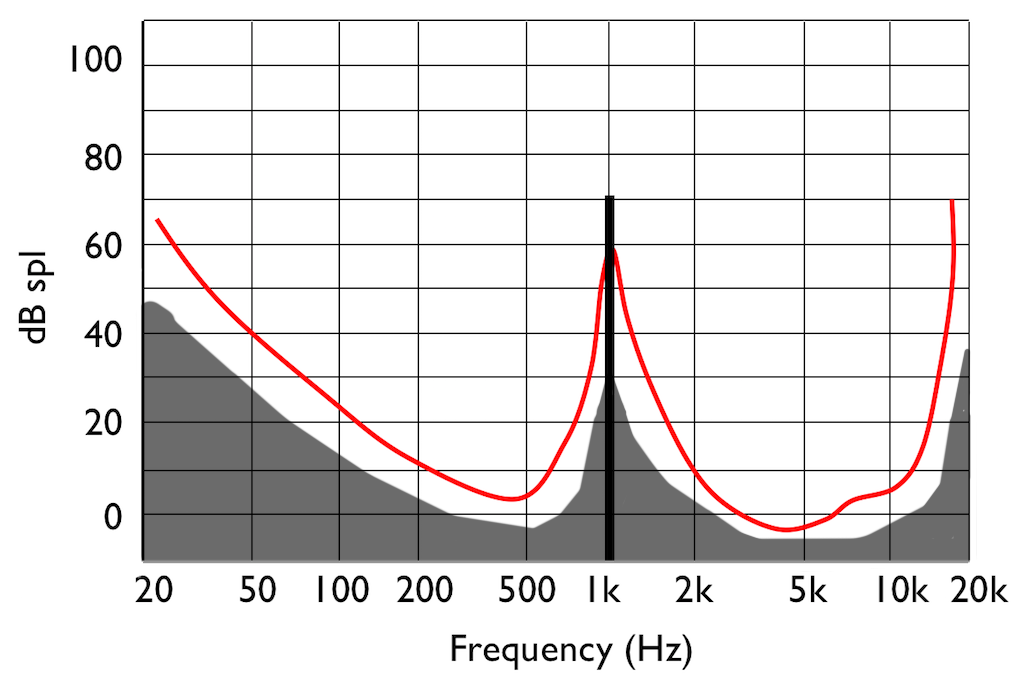
Let’s assume that this system works. (In fact, some of the algorithms work very well, if you consider how much data is being eliminated… There’s no need to be snobbish…)
Now to the real part of the story…
Okay – everything above was just the “setup” for this posting.
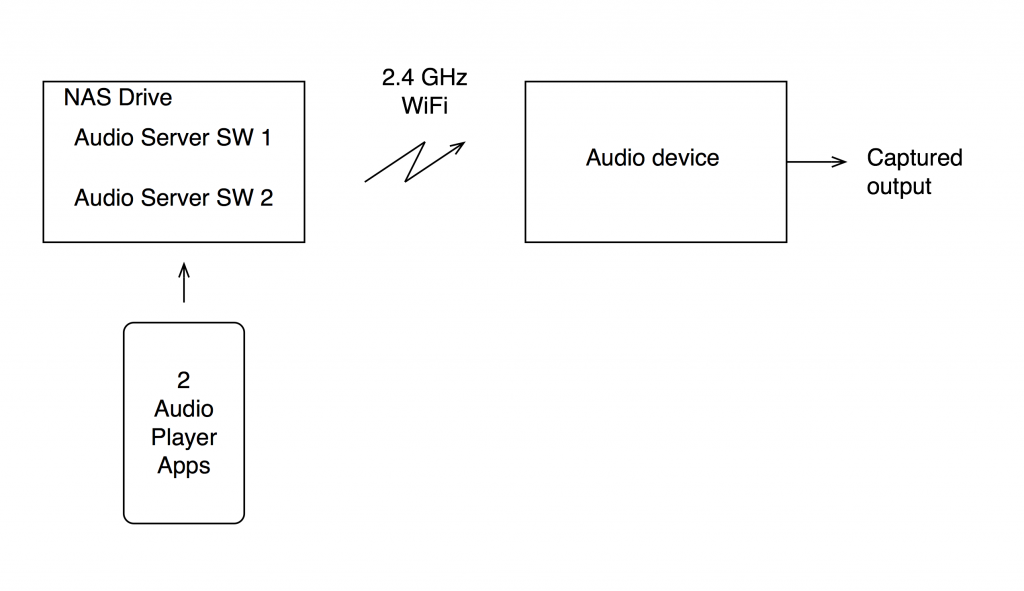
For this test, I put two .wav files on a NAS drive. Both files had a sampling rate of 48 kHz, one file was a 16-bit file and the other was a 24-bit file.
On the NAS drive, I have two different applications that act as audio servers. These two applications come from two different companies, and each one has an associated “player” app that I’ve put on my phone. However, the app on the phone is really just acting as a remote control in this case.
The two audio server applications on the NAS drive are able to stream via my 2.4 GHz WiFi to an audio device acting as a receiver. I captured the output from that receiver playing the two files using the two server applications. (therefore there were 4 tests run)
The content of the signal in the two .wav files was a swept sine tone, going from 20 Hz to 90% of Nyquist, at 0 dB FS. I captured the output of the audio device in Figure 10 and ran a spectrogram of the result, analysing the signal down to 100 dB below the signal’s level. The results are shown below.
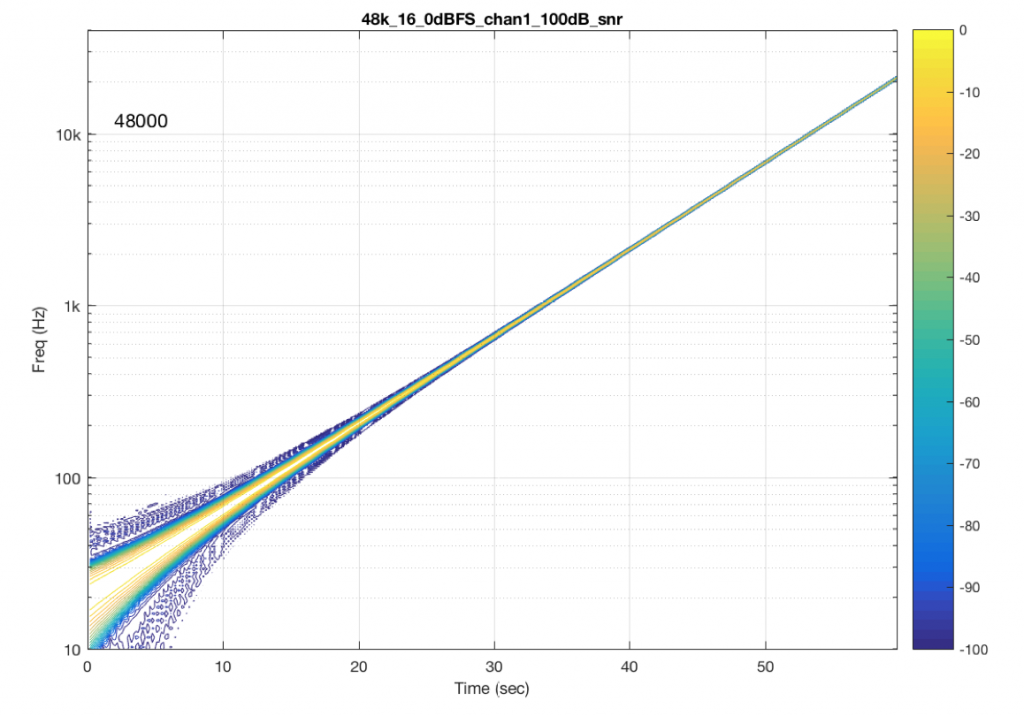
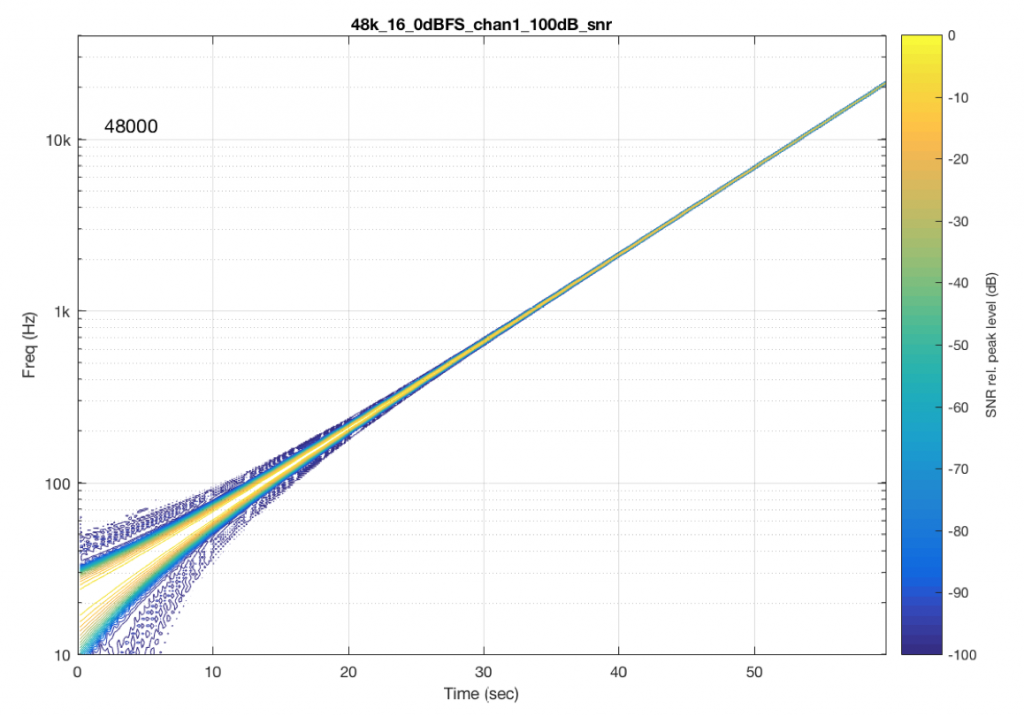

So, Figures 11 and 13 show the same file (the 16-bit version) played to the same output device over the same network, using two different audio server applications on my NAS drive.
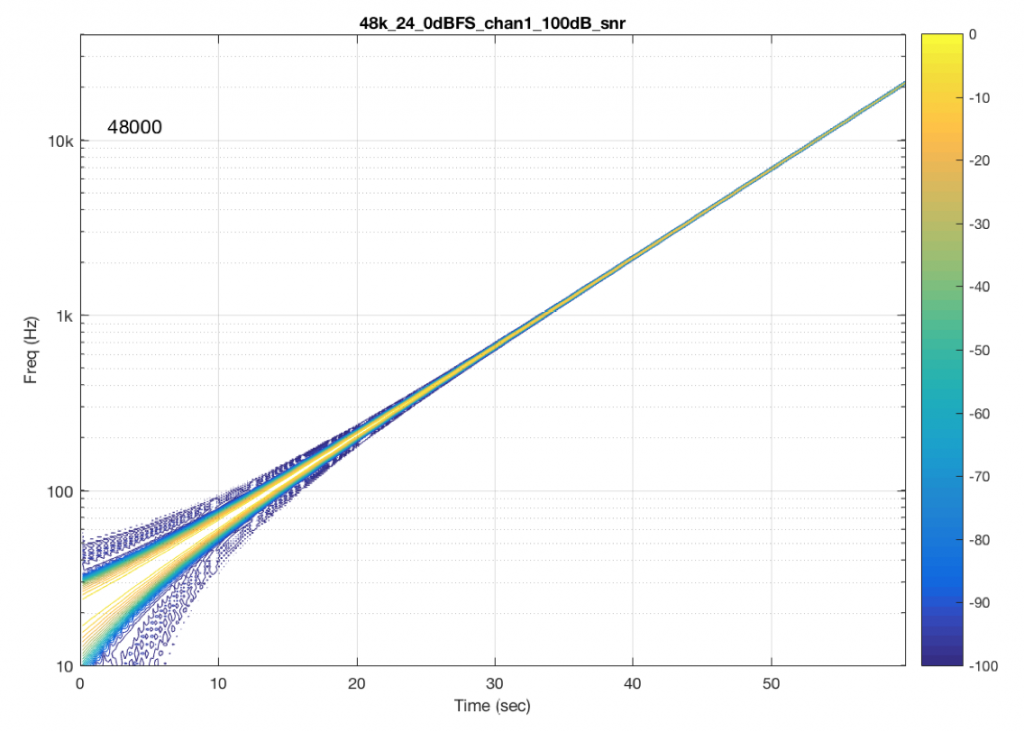
Figures 12 and 14 also show the same file (the 24-bit version). As is immediately obvious, the “Audio Server SW 2” is not nearly as happy about playing the 24-bit file. There is harmonic distortion (the diagonal lines parallel with the signal), probably caused by clipping. This also generates aliasing, as we saw in a previous posting.
However, there is also a lot of visible noise around the signal – the “fuzzy blobs” that surround the signal. This has the same appearance as what you would see from the output of a psychoacoustic CODEC – it’s the noise that the encoder tries to “fit under” the signal, as shown in Figure 9… One give-away that this is probably the case is that the vertical width (the frequency spread) of that noise appears to be much wider when the signal is a low-frequency. This is because this plot has a logarithmic frequency scale, but a CODEC encoder “thinks” on a linear frequency scale. So, frequency bands of equal widths on a linear scale will appear to be wider in the low end on a log scale. (Another way to think of this is that there are as many “Hertz’s” from 0 Hz to 10 kHz as there are from 10 kHz to 20 kHz. The width of both of these bands is 10000 Hz. However, those of us who are still young enough to hear up there will only hear the second of these as the top octave – and there are lots of octaves in the first one. (I know, if we go all the way to 0 Hz, then there are an infinite number of octaves, but I don’t want to discuss Zeno today…))
Conclusion
So, it appears that “Audio Server SW 2” on my NAS drive doesn’t like sending 24 bits directly to my audio device. Instead, it probably decodes the wav file, and transcodes the lossless LPCM format into a lossy CODEC (clipping the signal in the process) and sends that instead. So, by playing a “high resolution” audio file using that application, I get poorer quality at the output.
As always, I’m not going to discuss whether this effect is audible or not. That’s irrelevant, since it’s dependent on too many other factors.
And, as always, I’m not going to put brand or model names on any of the software or hardware tested here. If, for no other reason, this is because this problem may have already been corrected in a firmware update that has come out since I tested it.
The take-home messages here are:
- an entire audio signal path can be brought down by one piece of software in the audio chain
- you can’t test a system with one audio file and assume that it will work for all other sampling rates, bit depths and formats
- Normally, when I run this test, I do it for all combinations of 6 sampling rates, 2 bit depths, and 2 formats (WAV and FLAC), at at least 2 different signal levels – meaning 48 tests per DUT
- What I often see is that a system that is “bit perfect” in one format / sampling rate / bit depth is not necessarily behaving in another, as I showed above..
So, if you read a test involving a particular NAS drive, or a particular Audio Server application, or a particular audio device using a file format with a sampling rate and a bit depth and the reviewer says “This system worked perfectly.” You cannot assume that your system will also work perfectly unless all aspects of your system are identical to the tested system. Changing one link in the chain (even upgrading the software version) can wreck everything…
This makes life confusing, unfortunately. However, it does mean that, if someone sounds wrong to you with your own system, there’s no need to chase down excruciating minutiae like how many nanoseconds of jitter you have at your DAC’s input, or whether the cat sleeping on your amplifier is absorbing enough cosmic rays. It could be because your high-res file is getting clipped, aliased, and converted to MP3 before sending to your speakers…
Addendum
Just in case you’re wondering, I tested these two systems above with all 6 standard sampling rates (44.1, 48, 88.2, 96, 176.4, and 192 kHz), 2 bit depths (16 & 24). I also did two formats (WAV and FLAC) and three signal levels (0, -1, and -60 dB FS) – although that doesn’t matter for this last comment.
“Audio Server SW 2” had the same behaviour in the case of all sampling rates – 16 bit files played without artefacts within 100 dB of the 0 dB FS signal, whereas 24-bit files in all sampling rates exhibited the same errors as are shown in Figure 14.