mostly audio, but with some other stuff occasionally
One way to compare CODEC quality
I’m often asked about my opinion regarding sound quality vs. compression formats or sampling rates or bit depths or psychoacoustic CODEC’s or other things like that…
Of course, there are lots of ways to decide on such an opinion, depending on what parameters you use to define “sound quality” and therefore what it is you’re asking specifically…
One way to think of this is to consider that the original sound file is the “reference” (regardless of how “good” or “bad” it is…), and when you encode it somehow (say, by changing sampling rates, or making it an MP3 file, for example), AND that encoding makes it different, then the resulting difference from the original can be considered an error.
So, I took a compilation of tracks that I often use for listening to loudspeakers. This is about 13 minutes long and is made of excerpts of many different recordings and recording styles, ranging from anechoic female speech, through a cappella choral, orchestral music, jazz, hard rock, heavy metal, and hip hop. The original tracks were all taken from 44.1 kHz / 16-bit CD’s, and the compilation is a 44.1 kHz / 16 bit result. This is what we’ll call the “reference”.
I then used LAME to encode the compilation in different bitrates of MP3. I re-encoded as 320, 256, and 128 CBR (Constant Bit Rate). I also used the “–preset” option to make encodings in the “insane”, “extreme”, “standard”, and “medium” settings (I’ve included the details of this at the bottom in the “Appendix”). Three of these four presets are VBR – the “Insane” setting is a CBR 320 kbps with some tweaked parameters.
I decoded those MP3 files back to PCM, and compared them to the original, of course making sure that everything was time- and gain-aligned. (There are some small differences in the overall level of the original file and the MP3 output – which is different for different bitrates. If I did not do this, then I would be exaggerating the differences between the original and the encoded versions – so this gain difference was calculated and compensated for, before subtracting the original from the MP3.)
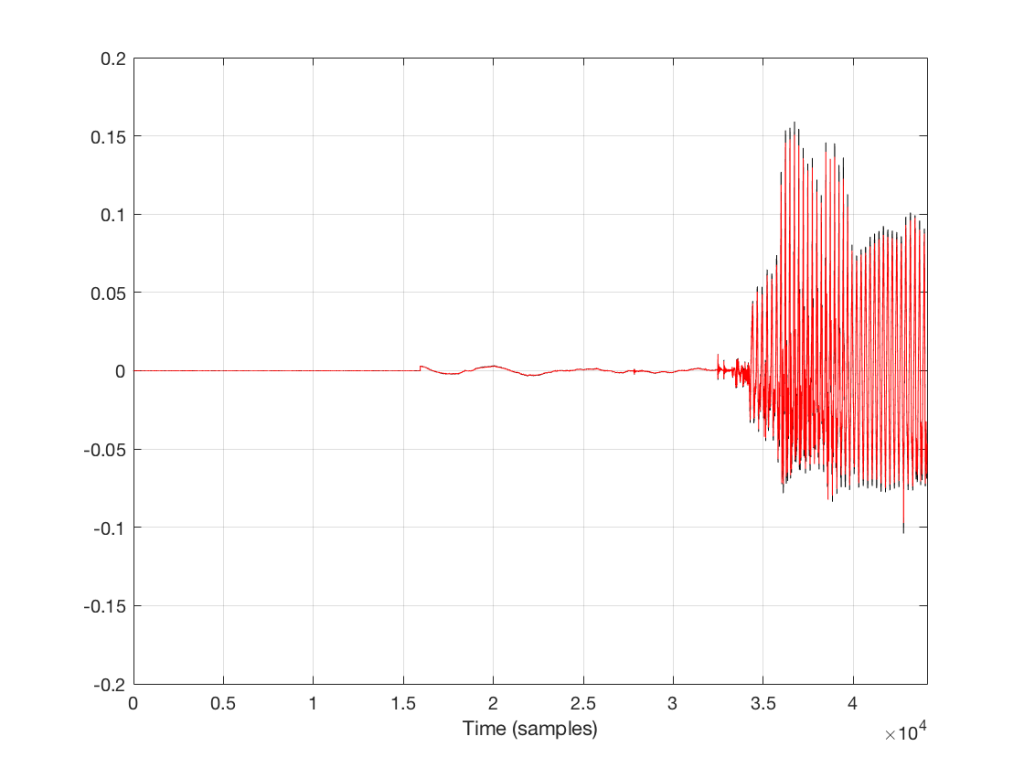
Let’s take a look at a plot of the sample values in the left channel of the beginning of the track.
Figure 1. The original (in black) and the decoded 128 kbps MP3 file.
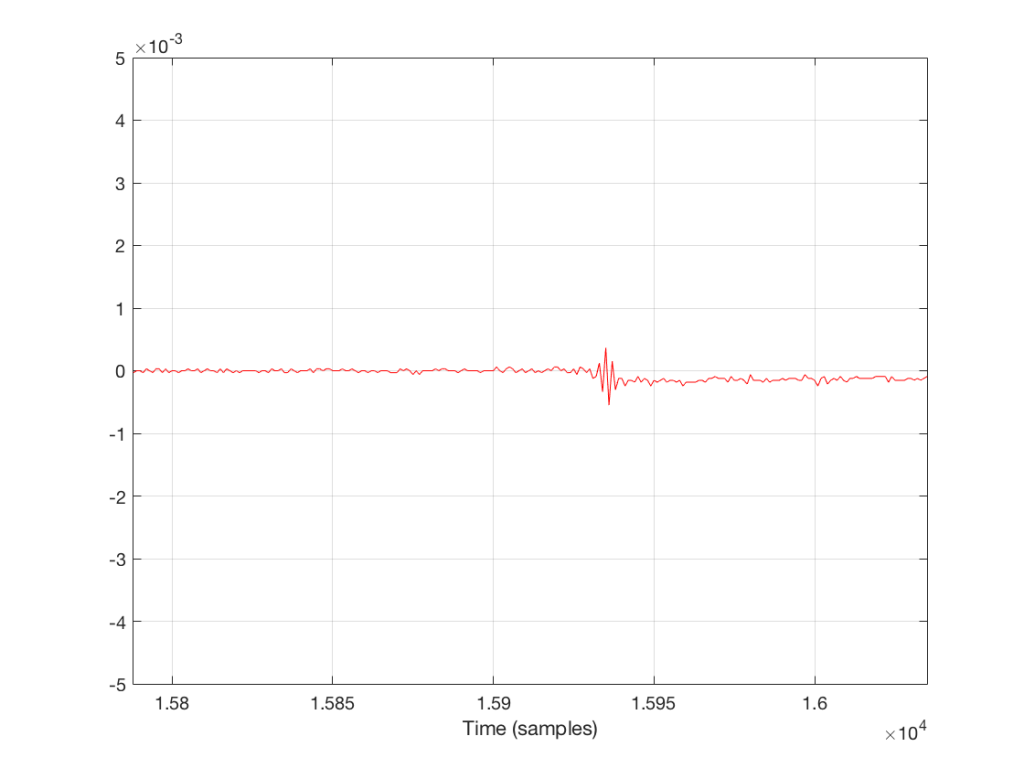
The plot above shows the first 44100 samples in the track (the first second of sound). The red plot is the decoded 128 kbps MP3. The black plot (which is difficult to see because it is overlapped by the red plot – except in the signal peaks) is the original file. For example, if I zoom into the area around the beginning of the sound (say, starting around sample number 15800) then we see this
Figure 2. A close-up of a portion of Figure 1.
So, as you can see in the two plots above, the decoded 128 kbps MP3 and the original 44.1/16 file are different. But, the difference is small relative to the levels of the signals themselves. The question is, how small is the difference, exactly?
We can find this out by subtracting the original signal from the decoded MP3 output, sample by sample. The result of this is shown in the plot below.
Figure 3. The difference between the two plots in Figure 2.
Notice that the vertical scale of the plot in Figure 3 is small. This is because it shows the difference between the two lines in Figure 2, which is also quite small.
Let’s think for a minute about how I arrived at the signal in Figure 3. I subtracted the Original signal from the MP3 output. In other words:
MP3 output – Original = Difference
If we consider that the difference between the MP3 output and the Original can be thought of as an “error”, and if I move the terms in the equation above, I get the following:
MP3 output – Original = Error
Original + Error = MP3 output
So, the question is: how loud is that error relative to the signal we’re listening to? The idea here is that, the louder the error, the easier it will be to detect.
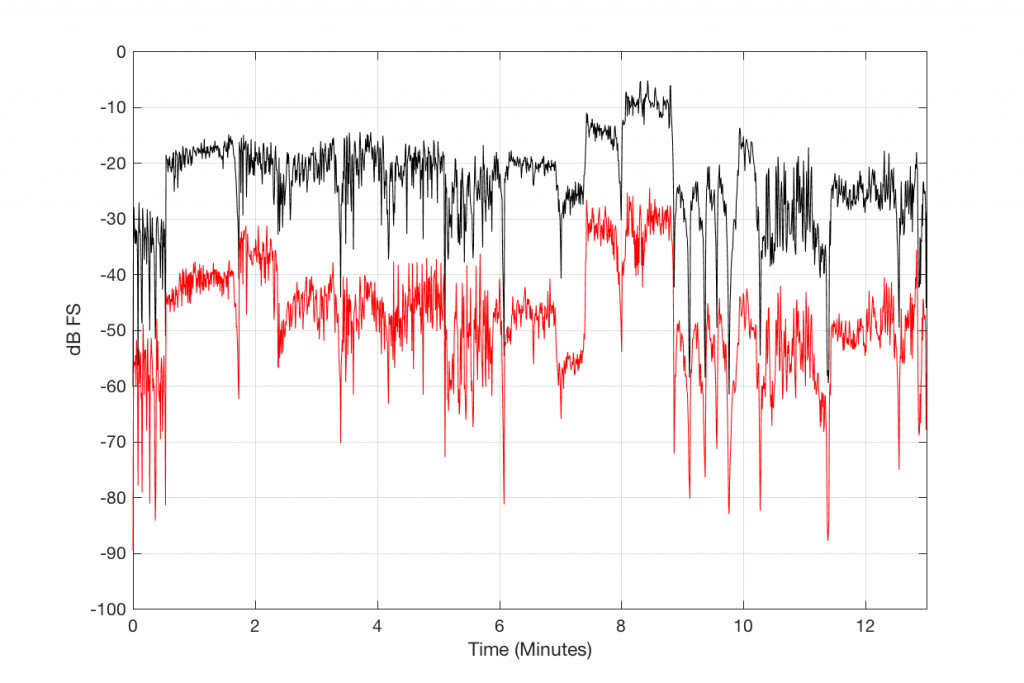
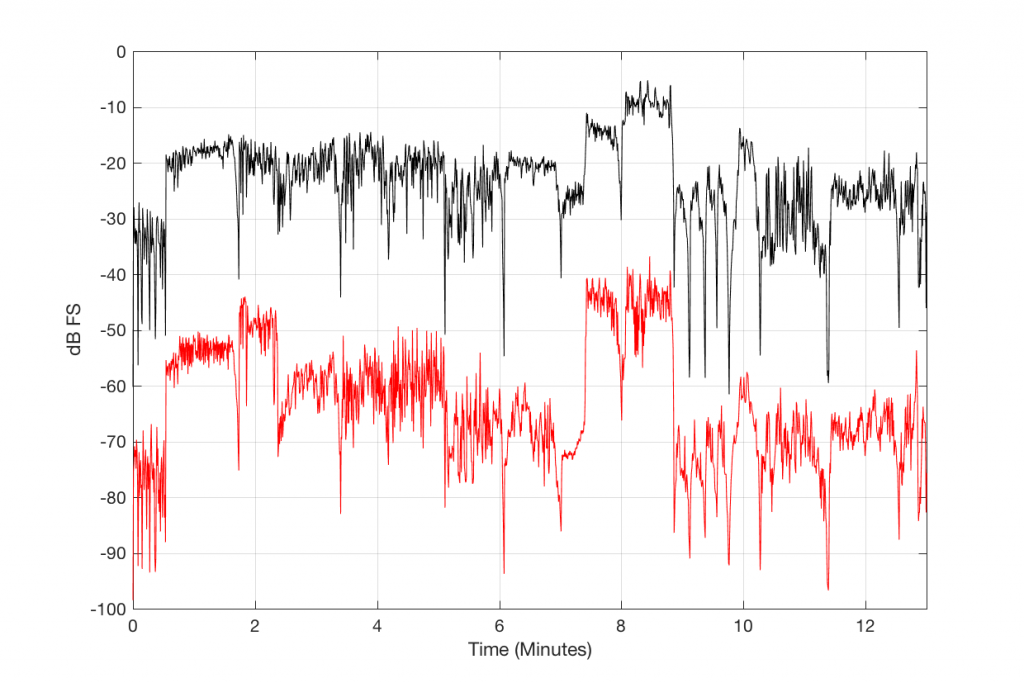
Figure 4, below, shows this level difference over time. The black curve is a running RMS level of the decoded 128 kbps MP3 file. As you can see there, it ranges from about -30 dB FS to about +10 dB FS. You may think that it’s strange that it “only” goes to -10 dB FS – but this is because the time window I’m using to calculate the RMS value of the signal is 500 ms long. The peaks of the track reach full scale, but since my time window is long, this tends to pull down the apparent level (because the peaks are short). (NB: If you want to argue about the choice of a 500 ms time window, please wait until I’ve followed up this posting with another one that divides things up by frequency band…)
The res curve in Figure 4 is a running RMS value of the Error signal – the difference between the MP3 file and the original. As you can see there, that error signal ranges from about -50 dB FS to about -30 dB FS, give or take…
Figure 4. Running measures of the level of the decoded 128 kpbs MP3 file (in black) and the error signal (in red).
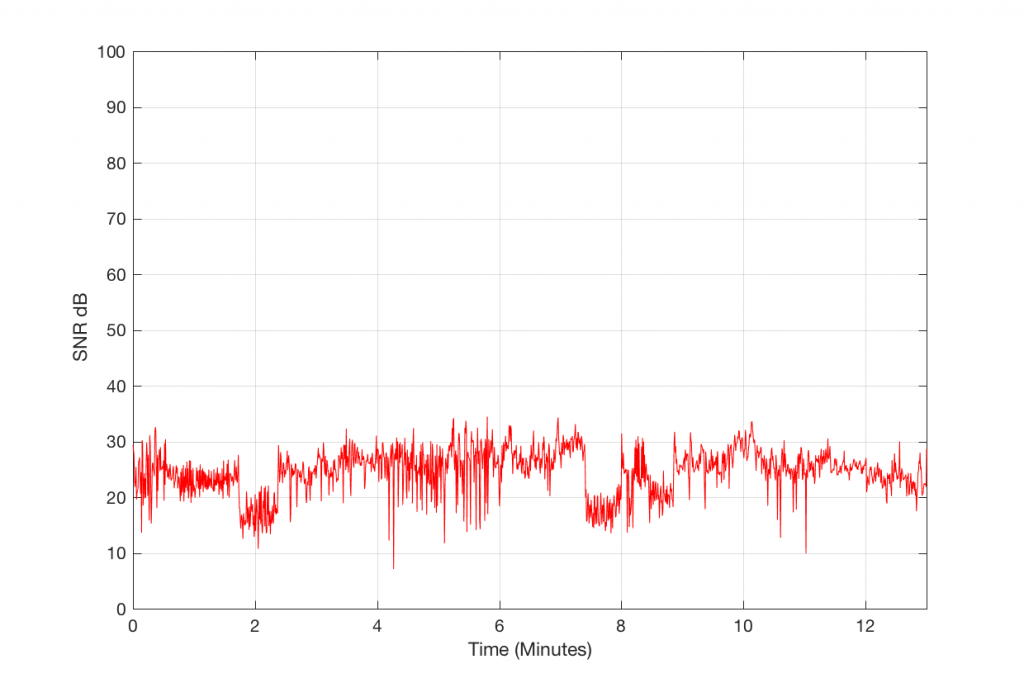
We can find the running value of the difference between the level of the MP3 file and the level of the Error it contains by subtracting the black curve from the red curve. The result of this is shown in Figure 5, below.
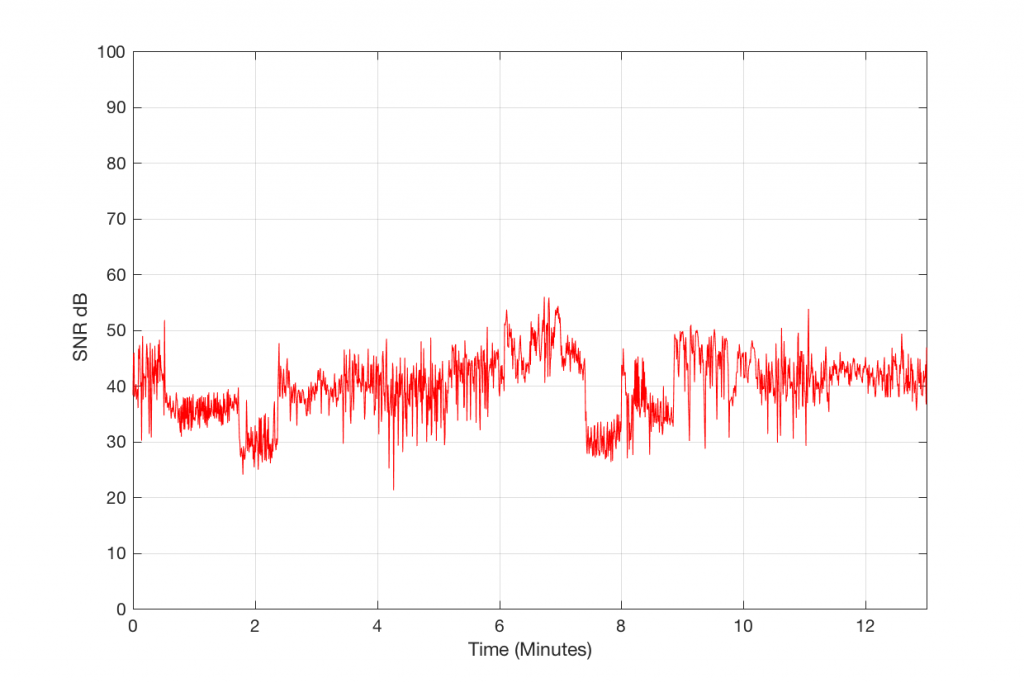
Figure 5: The difference in level between the error signal and the decoded 128 kbps MP3 file.
So, Figure 5, therefore, shows the measure of how loud the signal is relative to the error that makes it different from the original. If this error signal were just harmonic distortion, then we could call this a measure of THD in dB. If it were just good-old-fashioned noise, like on a magnetic tape, then we could call it a signal-to-noise ratio. However, this is neither distortion or noise in the traditional sense – or, maybe more accurately, it’s both…
So, let’s call the plot in Figure 5 a “signal-to-error ratio”. What we can see there is that, for this particular track, for the settings that I used to make the 128 kbps MP3 file, the error – the MP3 artefacts – are only 20 to 25 dB below the signal most of the time. Now, don’t jump to conclusions here. This does not mean that they would be as audible as white noise that is only 25 dB below the signal. This is because part of the “magic” of the MP3 encoder is that it tries to ensure that the error can “hide” under the signal by placing the error signal in the same frequency band(s) as the signal. Typically, white noise is in a different band than the signal, so it’s easier to hear because it’s not masked. So, be very careful about interpreting this plot. This is a measurable signal-to-error ratio, but it cannot be directly compared to a signal-to-noise ratio.
Let’s now increase the bitrate of the MP3 encoding, allowing the encoder to increase the quality.
Figure 6. A running RMS of a decoded 256 kbps MP3 file (black) and the difference between that signal and the original (red).
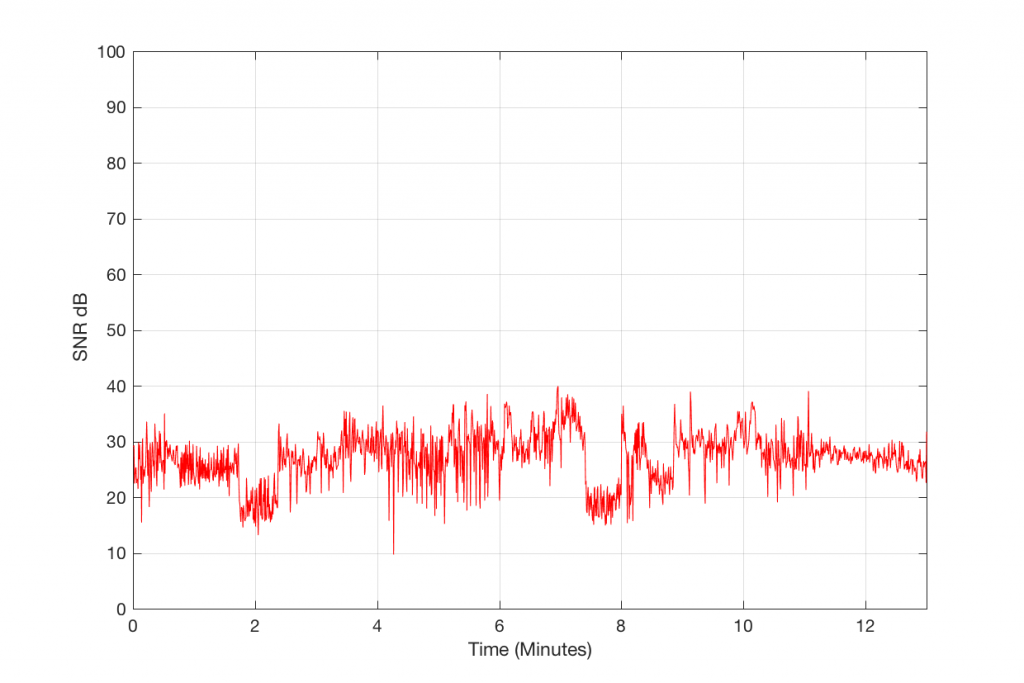
Figure 7: The Signal-to-Error ratio of a 256 kbps MP3 file.
Figure 6 and 7 show the same information as before, but for a 256 kpbs encoding of the same track. As you can see there, by doubling the bitrate of the MP3, we have increased our signal-to-error ratio by about 10 to 15 dB or so – to about 35 or 40 dB.
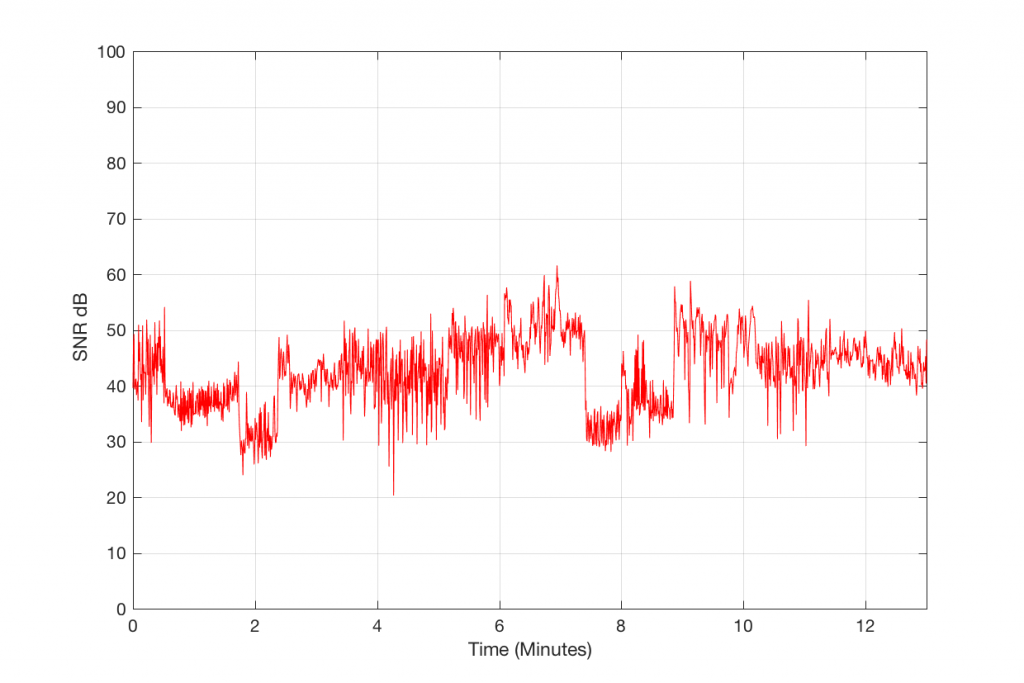
Figure 8: A running RMS of a decoded 320 kbps MP3 file (black) and the difference between that signal and the original (red).Figure 9: The Signal-to-Error ratio of a 320 kbps MP3 file.
As you can see in Figures 8 and 9 above, increasing the MP3 bitrate to 320 kbps can improve the Signal-to-Error ratio from about 25 dB (for 128 kbps) to about 40 dB or so.
Now, if you’re looking carefully, you might notice that, some times in the track that I used for testing, the signal-to-error ratio is actually worse for the 320 kbps file than it is for the 256 kbps file – all other things being equal in the LAME converter parameters. This is a bit misleading, since what you cannot see there is the frequency spectrum of the error signal. I’ll deal with that in a future posting – with some more analysis and explanation to go with it.
For now, let’s play with the VBR presets in LAME. I’ll just show the signal-to-error plots for the 4 settings.
Figure 10: The Signal-to-Error ratio of an MP3 file converted using LAME’s “medium” quality preset.Figure 11: The Signal-to-Error ratio of an MP3 file converted using LAME’s “standard” quality preset.Figure 12: The Signal-to-Error ratio of an MP3 file converted using LAME’s “extreme” quality preset.Figure 13: The Signal-to-Error ratio of an MP3 file converted using LAME’s “insane” quality preset.
So, as you can see in Figures 10 through 13, the signal-to-error ratio can be improved with the VBR presets, reaching a peak of over 60 dB for the “Insane” setting, for this track…
As I said a couple of times above:
You have to be careful about interpreting these graphs from a background of “knowing” what a SNR is… This error is not normal “distortion” or “noise” – at least from a perceptual point of view…
I’ll go further with this, including some frequency-dependent information in a future posting.
One Response on “One way to compare CODEC quality”
david moran says:
This analysis assumes the coder preserves the waveform, a blunt assumption, and would fall apart with a coder which preserves the perceived sound but not the waveform (e.g. SE-AAC).
An expert points to some sophisticated analysis programs (PEAQ) doing a moderately good job of predicting audible changes.
It remains area of investigation.





david moran says:
This analysis assumes the coder preserves the waveform, a blunt assumption, and would fall apart with a coder which preserves the perceived sound but not the waveform (e.g. SE-AAC).
An expert points to some sophisticated analysis programs (PEAQ) doing a moderately good job of predicting audible changes.
It remains area of investigation.