Every four years there is a meeting held in Paris with representatives of the governments of 51 countries who are part of a group called the Metre Convention. This meeting is called the Conférence Générale des Poids et Measures or CGPM. This group oversees a standard set of measurements for things like time, mass, and distance, just to name a few. That set of measures is called the Système International d’Unités or SI, although most normal people call it the metric system.
If you think back, way back to a time before clocks and watches, back before we even discovered fire, and then think about how people would have marked time. There were two clues – light and dark. The sun goes up, you wait a while, the sun goes down, you wait a while and the cycle repeats itself. So, we had the concept of a day.
In many early civilizations, the time between sunrise and sunset was was divided into 12 equal divisions. Similarly the time between sunset and sunrise was also divided into 12. Why 12? Well, many counting systems were based on 12 once upon a time - which is why we have leftovers still today like 12 eggs in a dozen, 12 inches in a foot, 12 months in a year, and 12 zodiacal symbols. It helped that we have 12 bones in our fingers (3 on each), so you can count to 12 by using your thumb and touching each of your phalanges (look it up if you think that I’m being rude...). The division of one-twelfth of a day was the basis of what we now call an hour. Interestingly, since it was originally based on the amount of daylight in a day, its length would vary depending on when in the year it was measured.
The hour was subdivided into 60 equal divisions called prime minutes (60 was used a lot in the counting system of the ancient Babylonians). The prime minute was further subdivided into 60 divisions called second minutes, but these days we’re lazy and we just call them seconds.
So, for a long time, a second was simply 1/60th of a minute, which was 1/60th of an hour which was 1/24th of a day, which was 1/365th of a year. Therefore, a second was 1/31,536,000th of a year, give or take... (It may be of interest to know that this means there are approximately π x 107 seconds in a year.[wik, ])
However, this definition of a second is not really good enough, since it is based on the length of time that takes the earth to go around the sun, or at least for the earth to spin around its own axis. Since this a variable amount of time (the spin of the earth is slowing down, but I wouldn’t worry about it affecting your work week...) a new, more stable definition had to be found. That new definition was accepted in 1967 and refined in 1997 by the CGPM as being “the duration of 9,192,631,770 periods of the radiation corresponding to the transition between the two hyperfine levels of the ground state [in a zero magnetic field] of the caesium-133 atom ... at rest at a temperature of 0 K.”[bip, ] That makes much more sense!
On the 7th April, 1795 the French Academy of Sciences had little else to do, so they decided that they would define a unit of length called a mètre (from the Greek word metron meaning “a measure”) as “la mesure de longueur égale à la dix-millionième partie de l’arc du méridien terrestre compris entre le pôle boréal et l’équateur”[cot, 1999] (one ten-millionth of the distance from the equator to the North Pole on a meridian1 that goes through Paris). In 1795, they produced a prototype “metre bar.” This was an actual bar of brass that was officially 1 metre long. The final version was made of platinum and was made in 1799 and put in the French National Archives.
The official definition of the meter changed a number of times since the 1700’s. The version we use today was defined (finally!) on October 21, 1983 at the seventeenth (CGPM). It states that 1 metre is “the length of the path travelled by light in vacuum during a time interval of 1 / 299,792,458 of a second.”[bip, ]
This definition is interesting (depending on what you consider to be interesting...) because it makes the speed of light a nice number – exactly 299,792,458 m/s.
Another interesting point is that one of the original definitions of the metre that was being considered was the length that you had to make a pendulum to make its travelling time 1 second. If you don’t believe this one, take a piece of string 1 m long and tie something heavy to one end. Tie the other end to something that doesn’t move and time how long it takes to swing back and forth. If it’s shorter than a metre, then it will take less than a second, longer than a metre will result in it taking longer. (Also note that it doesn’t matter how heavy the weight is... Galileo Galilei proved that one to us.)
In the mid-1600’s, there was an English clergyman named John Wilkins2 who tried to come up with a definition of a standard unit of mass using a standard volume of water. (This was a good idea, since lots of people have access to water.) However, it wasn’t until almost 150 years later (on the 7th April 1795, to be exact) that it was announced that a gram would be defined as “le poids absolu d’un volume d’eau pure égal au cube de la centième partie du mètre , et à la température de la glace fondante.”[cot, 1999] (the absolute weight of a volume of pure water equal to a cube with sides of 1/100th of a meter at the temperature where ice melts – in other words, a block of water with the dimensions 1 cm x 1cm x 1cm at 0∘C). This is a good definition, since it makes one litre (a cube with sides of 10 cm) of water equal to one kilogram of water.
Pick up a block of lead – you’ll notice that it’s heavy. (If you don’t have a block of lead lying around, print this book and pick it up instead... It’s also heavy.) Take the same block of lead to the moon and lift it up – you’ll notice that it’s lighter than it was back home. Now take the same block of lead to Jupiter and it will be so heavy, you can’t lift it at all... So, in the presence of different gravitational forces, the same block of lead will weigh different amounts. However, in all cases the same block of lead will have the same mass.
Let’s try another experiment to illustrate the difference. Take the same block of lead and put it on perfectly smooth ice that is a perfectly horizontal surface – let’s make it perfect ice that has absolutely no friction. Now push the block hard enough so that, in 1 second, it reaches 1 m/s, skidding along the ice. While you do this, pay attention to how hard you had to push.
Now take the same block to the moon, place it on a similar ice surface and push it so that reaches 1 m/s in 1 second. Do the same thing again on Jupiter. In all three cases, you will push equally hard.
So, on the moon, the block weighs less than it does on Earth, where it weighs less than on Jupiter. However, if you’re just trying to move it on a frictionless surface, you have to push equally hard in all three places to get the same acceleration. This is because the block’s mass, which determines its inertia (or its “desire” to keep doing what it’s doing – be it staying still or moving in a given direction) is the same regardless of gravitational pull, so the block will be equally easy to move sideways in all three places. However, the block’s mass and the gravitational field it’s in determine its weight, and therefore how hard it is to lift.
Take a 1-kilogram block of anything and put it on a surface that is completely frictionless – and I mean completely frictionless. No friction between it and the table it’s sitting on, no air friction... nothing. If you push the block, it will start to accelerate to a new velocity. If you stop pushing, it will stay at that velocity and keep going forever. The harder you push, the faster the block will accelerate. In other words, if you push harder, you’ll get to a higher velocity in the same amount of time.
Let’s look at an example. The block is stopped, sitting there, waiting to be pushed (so its velocity equals 0 m/s). You push it for exactly one second and then stop pushing. The block has some new velocity that you can now measure. Let’s say that you pushed the block hard enough that it is now travelling at 1 m/s. Therefore, the acceleration of the block was 1 m/s per second (because you only pushed for exactly 1 second). This can also be stated as an acceleration of 1 m/s2.
The amount that you push is called force – you can say that you are applying force to the block instead of saying that you are pushing it. Force is usually measured in pounds, but that is actually for a different system of measurement as we’ll see later. If we’re thinking in the SI, then we measure force in newtons, abbreviated N.
One additional thing about force – if you drop something on the Earth, it will accelerate as it falls at a rate of about 9.8 m/s each second. So, after one second it’s falling 9.8 m/s, after 2 seconds, it’s falling 19.6 m/s and so on. There’s a nice law that says that Force (in newtons) is equal to mass times acceleration or
|
| (1.1) |
Where F is force in newtons, m is mass in kilograms and a is acceleration in m/s2.
We already know that 1 newton is equal to 1 kg accelerated at 1 m/s2 (1 N = 1 kg * 1 m/s2) but we can also think of it the other way – 1 kg on the surface of the Earth weighs 9.8 N (because 1 kg * 9.8 m/s2 = 9.8 N).
The Système International is pretty widely used, particularly in the scientific community around the world. There have been some incidents caused by conflict with other systems, however. Take for example, do an Internet search for the “Gimli Glider” and you’ll find an amazing story about a Boeing 767 that ran out of fuel in mid-flight because the people that did the re-fueling in Montreal confused kilograms with pounds. Or the 1983 Black Sabbath “Born Again” tour where the band had to squeeze themselves onto a stage with a massive model of Stonehenge because the people that designed the set thought in feet and the people who built the set thought in metres.
In older books, you may come across the “cgs” system. This is similar to the SI, however, instead of metres, kilograms and seconds, the standard units are centimetres, grams and seconds. Most of the conversions from SI to cgs are pretty simple. There’s one unit however, that we should mention here, and that’s the dyne (abbreviated dyn) which is the cgs unit for force. 1 dyne of force will accelerate 1 gram at 1 centimetre per second squared. If you need to convert to newtons, use the following conversion formula:
1 N = 105 dynes
It may initially seem that a section explaining geometry is a very strange place to start a book on sound recording, but as we’ll see later, it’s actually the best place to start. In order to understand many of the concepts in the chapters on acoustics, electronics, digital signal processing and electroacoustics, you’ll need to have a very firm and intuitive grasp of a couple of simple geometrical concepts. In particular, these two concepts are the right triangle and the idea of slope.
I’ll assume at this point that you know what a triangle is. If you do not understand what a triangle is, then I would recommend backing up a bit from this textbook and reading other tomes such as Trevor Draws a Triangle and the immortal classic, Baby’s First Book of Euclidean Geometry. (Okay, okay... I lied... Those books don’t really exist... I hope that this hasn’t put a dent in our relationship, and that you can still trust me for the rest of this book...)
Once upon a time, a Greek by the name of Pythagoras had a minor obsession with triangles. 3 Interestingly, Pythagoras, like many other Greeks of his time, recognized the direct link between mathematics and musical acoustics, so you’ll see his name popping up all over the place as we go through this book.
Anyways, back to triangles. The first thing that we have to define is something called a right triangle. This is just a regular old everyday triangle with one specific characteristic. One of its angles is a right angle meaning that it’s 90∘ as is shown in Figure 1.1. One other new word to learn. The side opposite the right angle (in Figure 1.1, that would be side a) is called the hypotenuse of the triangle.
One of the things Pythagoras discovered was that if you take a right triangle and make a square from each of its sides as is shown in Figure 1.2, then the sum of the areas of the two smaller squares is equal to the area of the big square.
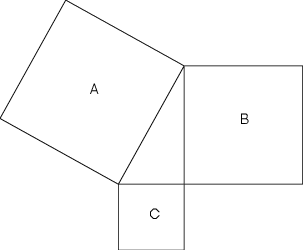
So, looking at Figure 1.2, then we can say that A = B+C. We also should know that the area of a square is equal to the square of the length of one of its sides. Looking at Figures 1.1 and 1.2 this means that A = a2, B = b2, and C = c2.
Therefore, we can put this information together to arrive at a standard equation for right triangles known as the Pythagorean Theorem, shown in Equation 1.2.
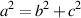 | (1.2) |
and therefore
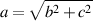 | (1.3) |
This equation is probably the single most important key to understanding the concepts presented in this book, so you’d better remember it.
Let’s go downhill skiing. One of the big questions when you’re a beginner downhill skier is “how steep is the hill?” Well, there is a mathematical way to calculate the answer to this question. Essentially, another way to ask the same question is “how many metres do I drop for every metre that I ski forward?” The more you drop over a given distance, the steeper the slope of the hill.
So, what we’re talking about when we discuss the slope of the hill is how much it rises (or drops) for a given run. Mathematically, the slope is written as a ratio of these two values as is shown in Equation 1.4.
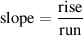 | (1.4) |
but if we wanted to be a little more technical about this, then we would talk about the ratio of the difference in the y-value (the rise) for a given difference in the x-value (the run), so we’d write it like this:
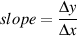 | (1.5) |
Where Δ is a symbol (it’s the Greek capital letter delta) commonly used to indicate a difference or a change.
Let’s just think about this a little more for a couple of minutes and consider some different slopes.
When there is no rise or drop for a change in horizontal distance, (like sailing on the ocean with no waves) then the value of Δy is 0, so the slope is 0.
When you’re climbing a sheer rock face that drops straight down, then the value of Δx is 0 for a large change in y therefore the slope is ∞.
If the change in x and y are both positive (so, you are going forwards and up at the same time) then the slope is positive. In other words, the line goes up from left to right on a graph.
If the change in y is negative while the change in x is positive, then the slope is negative. In other words you’re looking at a graph of a line that goes downwards from left to right.
If you look at a real textbook on geometry then you’ll see a slightly different equation for slope that looks like Equation 1.6, but we won’t bother with this one. If you compare it to Equation 1.5, then you’ll see that, apart from the k they’re identical, and that the k is just a sort of altitude reading.
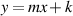 | (1.6) |
where m is the slope.
An exponent is just a lazy way to write down that you want to multiply a number by itself.
If I say 102, then this is just a short notation for “10 multiplied by itself 2 times” – therefore, it’s 10*10 = 100. For example, 34 = 3*3*3*3 = 81.
Sometimes you’ll see a negative number as the exponent. This simply means that you
have to include a little division in your calculation. Whenever you see a negative
exponent, you just have to divide 1 by the same thing without the negative sign. For
example, 10-2 = 
Once upon a time you learned to do multiplication, after which someone explained that you can use division to do the reverse. For example:
if
 | (1.7) |
then
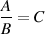 | (1.8) |
and
 | (1.9) |
Logarithms sort of work in the same way, except that they are the backwards version of an exponent. (Just as division is the backwards version of multiplication.) Logarithms (or logs) work like this:
If
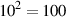 | (1.10) |
then
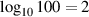 | (1.11) |
Actually, it’s:
If
 | (1.12) |
then
 | (1.13) |
Now we have to go through some properties of logarithms.
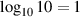 | (1.14) |
in other words...
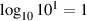 | (1.15) |
 | (1.16) |
in other words...
 | (1.17) |
 | (1.18) |
in other words...
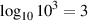 | (1.19) |
This should come as no great surprise – you can check them on your calculator if you don’t believe me. Now, let’s play with these three equations.
 | (1.20) |
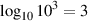 | (1.21) |
 | (1.22) |
Therefore:
 | (1.23) |
I once learned that you should never assume, because when you assume you make an ass out of you and me... (get it? ass—u—me... okay... dumb joke). One small problem with logarithms is the way they’re written. People usually don’t write the base of the log so you’ll see things like log(3) written which usually means log103 – if the base isn’t written, it’s assumed to be 10. This also holds true on most calculators. Punch in 100 and hit LOG and see if you get 2 as an answer – you probably will. Unfortunately, this assumption is not true if you’re using a computer to calculate your logarithms. For example, if you’re using MATLAB and you type log(100) and hit the RETURN button, you’ll get the answer 4.6052. This is because MATLAB assumes that you mean base e (a number close to 2.7182)4 instead of base 10. So, if you’re using MATLAB, you’ll have to type in log10(100) to indicate that the logarithm is in base 10. If you’re in Mathematica, you’ll have to use Log[10, 100] to mean the same thing.
Note that many textbooks write log and mean log10 just like your calculator. When the books want you to use loge like your computer they’ll write “ln” (pronounced “lawn”) meaning the natural logarithm.
The moral of the story is: BEWARE! Verify that you know the base of the logarithm before you get too many wrong answers and have to do it all again.
I’ve got an idea for a great invention. I’m going to get a flat piece of wood and cut it out in the shape of a circle. In the centre of the circle, I’m going to drill a hole and stick a dowel of wood in there. I think I’m going to call my new invention a wheel.
Okay, okay, so I ran down to the patent office and found out that the wheel has already been invented... (In fact, it’s patented in Australia... Really! I’m not kidding! Look it up yourself!) But, since it’s such a great idea let’s look at one anyway. Let’s drill another hole out on the edge of the wheel and stick in a handle so that it looks like the contraption in Figure 1.3. If I turn the wheel, the handle goes around in circles.

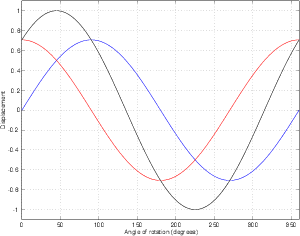
Now let’s think of an animation of the rotating wheel. In addition, we’ll look at the height of the handle relative to the centre of the wheel. As the wheel rotates, the handle will obviously go up and down, but it will follow a specific pattern over time. If that height is graphed in time as the wheel rotates, we get a nice wave as is shown in Figure 1.4.

That nice wave tells us a couple of things about the wheel:
Firstly, if we assume that the handle is right on the edge of the wheel, it tells us the diameter of the wheel itself. The total height of the wave from the positive peak to negative trough is a measurement of the total vertical travel of the handle, equal to the diameter. The maximum displacement from 0 is equal to the radius of the wheel.
Secondly, if we consider that the wave is a plot of vertical displacement over time, then we can see the amount of time it took for the handle to make a full rotation. Using this amount of time, we can determine how frequently the wheel is rotating. If it takes 0.5 seconds to complete a rotation (or for the wave to get back to where it started half a second ago) then the wheel must be making two complete rotations per second.
Thirdly, if the wave is a plot of the vertical displacement versus time, then the slope of the wave is proportional to the vertical speed of the handle. When the slope is 0 the handle is stopped. (Remember that slope = rise/run, therefore the slope is 0 when the “rise” or the change in vertical displacement is 0 – this happens at the peak and trough because the handle is finished going in one direction and is instantaneously stopped in order to start heading in the opposite direction.) Note that the handle isn’t really stopped – it’s still turning around the wheel – but for that moment in time, it’s not moving in the vertical plane.
Finally, if we think of the wave as being a plot of the vertical displacement vs. the angular rotation, then we can see the relationship between these two as is shown in Figure 1.5. In this case, the horizontal (X) axis of the waveform is the angular rotation of the wheel and the vertical height of the waveform (the Y-value) is the vertical displacement of the handle.
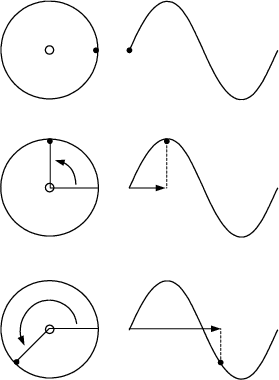
This wave that we’re looking at is typically called a sine wave – the word sine coming from the same root as words like “sinuous” and “sinus” (as in “could you hand me a tissue, please... my sinuses are all blocked up...”) – from the Latin word “sinus” meaning “a bay”. This specific waveshape describes a bunch of things in the universe – take, for example, a weight suspended on a spring or a piece of elastic. If the weight is pulled down, then it’ll bob up and down, theoretically forever. If you graphed the vertical displacement of the weight over time, you’d get a graph exactly like the one we’ve created above – it’s a sine wave.
Note that most physics textbooks call this behaviour simple harmonic motion.
There’s one important thing that the wave isn’t telling us – the direction of rotation of the wheel. If the wheel were turning clockwise instead of counterclockwise, then the wave would look exactly the same as is shown in Figure 1.6.
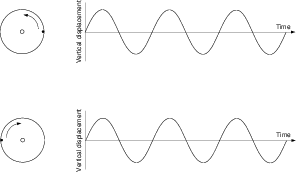
So, how do we get this piece of information? Well, as it stands now, we’re just getting the height information of the handle. That’s the same as if we were sitting to the side of the wheel, looking at its edge, watching the handle bob up and down, but not knowing anything about it going from side to side. In order to get this information, we’ll have to look at the wheel along its edge from below. This will result in two waves – the sine wave that we saw above, and a second wave that shows the horizontal displacement of the handle over time as is shown in Figure 1.7.

As can be seen in this diagram, if the wheel were turning in the opposite direction as in the example in Figure 1.6, then although the vertical displacement would be the same, the horizontal displacement would be opposite, and we’d know right away that the wheel was turning in the opposite direction.
This second waveform is called a cosine wave (because it’s the complement of the sine wave). Notice how, whenever the sine wave is at a maximum or a minimum, the cosine wave is at 0 – in the middle of its movement. The opposite is also true – whenever the cosine is at a maximum or a minimum, the sine wave is at 0. The four points that we talked about earlier (regarding what the sine wave tells us) are also true for the cosine – we know the diameter of the wheel, the speed of its rotation, and the horizontal (not vertical) displacement of the handle at a given time or angle of rotation.
Keep in mind as well that if we only knew the cosine, we still wouldn’t know the direction of rotation of the wheel – we need to know the simultaneous values of the sine and the cosine to know whether the wheel is going clockwise or counterclockwise.
Now then, let’s assume for a moment that the circle has a radius of 1. (1 centimeter, 1 foot... it doesn’t matter so long as we keep thinking in the same units for the rest of this little chat.) If that’s the case then the maximum value of the sine wave will be 1 and the minimum will be -1. The same holds true for the cosine wave. Also, looking back at Figure 1.5, we can see that the value of the sine is 1 when the angle of rotation (also known as the phase angle) is 90∘. At the same time, the value of the cosine is 0 (because there’s 0 horizontal displacement at 90∘). Using this, we can complete Table 1.1.
| Phase | Vertical displacement | Horizontal displacement | |
| (degrees) | (Sine) | (Cosine) | |
| 0∘ | 0 | 1 | |
| 45∘ | 0.707 | 0.707 | |
| 90∘ | 1 | 0 | |
| 135∘ | 0.707 | -0.707 | |
| 180∘ | 0 | -1 | |
| 225∘ | -0.707 | -0.707 | |
| 270∘ | -1 | 0 | |
| 315∘ | -0.707 | 0.707 | |
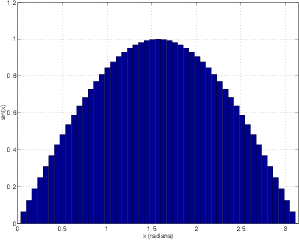
In fact, if you get out your calculator and start looking for the Sine (“sin” on a calculator) and the Cosine (“cos”) for every angle between 0 and 359∘ (no point in checking 360 because it’ll be the same as 0 – you’ve made a full rotation at that point...) and plot each value, you’ll get a graph that looks like Figure 1.8.
As can be seen in Figure 1.8, the sine and cosine intersect at 45∘
(with a value of 0.707 or  ) and at 215∘ (with a value of -0.707 or
-
) and at 215∘ (with a value of -0.707 or
- ).5
Also, you can see from this graph that a cosine is essentially a sine wave, but 90∘ earlier.
That is to say that the value of a cosine at any angle is the same as the value of the sine
90∘ later. These two things provide a small clue as to another way of looking at this
relationship.
).5
Also, you can see from this graph that a cosine is essentially a sine wave, but 90∘ earlier.
That is to say that the value of a cosine at any angle is the same as the value of the sine
90∘ later. These two things provide a small clue as to another way of looking at this
relationship.
Look at the first 90∘ of rotation of the handle. If we draw a line from the centre of the wheel to the location of the handle at a given angle, and then add lines showing the vertical and horizontal displacements as in Figure 1.7, then we get a triangle like the one shown in Figure 1.9.

Now, if the radius of the wheel (the hypotenuse of the triangle) is 1, then the vertical line is the sine of the inside angle indicated with a red arrow. Likewise, the horizontal leg of the triangle is the cosine of the angle.
Also, we know from Pythagoras that the square of the hypotenuse of a right triangle is equal to the sum of the squares of the other two sides (remember a2 +b2 = c2 where c is the length of the hypotenuse). In other words, in the case of our triangle above where the hypotenuse is equal to 1, then the sine of the angle squared + the cosine of the angle squared = 1 squared... This is a rule (shown below) that is true for any angle.
 | (1.24) |
This is usually written as
 | (1.25) |
where α is any angle.
Since this is true, then when the angle is 45∘, then we know that the right triangle is
isoceles – meaning that the two legs other than the hypotenuse are of equal
length (take a look at the graph in Figure 1.8). Not only are they the same length,
but, their squares add up to 1. Remember that a2 +b2 = c2 and that c2 = 1.
Therefore, with a little bit of math, we can see that the value of the sine and
the cosine when the angle is 45∘ is  because it’s the square root of
because it’s the square root of 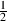 and
and
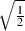 =
= 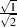 =
=  .
.
Once upon a time, someone discovered that there is a relationship between the radius of a circle and its circumference. It turned out that, no matter how big or small the circle, the circumference was equal to the radius multiplied by 2 and multiplied again by the number 3.141592645... That number was given the name “pi” (written π) and people have been fascinated by it ever since. In fact, the number doesn’t stop where I said it did – it keeps going for at least a billion places without repeating itself... but 9 places after the decimal is plenty for our purposes.
So, now we have a new little equation:
 | (1.26) |
where r is the radius of the circle and π is 3.141592645...
Normally we measure angles in degrees where there are 360∘ in a full circle, however, in order to measure this way, we need a protractor to tell us where the degrees are. There’s another way to measure angles using only a ruler and a piece of string...
Let’s go back to the circle above with a radius of 1. Since we have the new equation, we know that the circumference is equal to 2πr – but r = 1, so the circumference is 2π (say “two pi”). Now, we can measure angles using the circumference – instead of saying that there are 360∘ in a circle, we can say that there are 2π radians. We call them radians becase they’re based on the radius. Since the circumference of the circle is 2πr and there are 2π radians in the circle, then 1 radian is the angle where the corresponding arc on the circle is equal to the length of the radius of the same circle.
Using radians is just like using degrees – you just have to put your calculator into a
different mode. Look for a way of getting it into “RAD” instead of “DEG” (RADians
instead of DEGrees). Now, remember that there are 2π radians in a circle which is
the same as saying 360 degres. Therefore, 180∘ which is half of the circle is
equal to π radians. 90∘ is  radians and so on. You should be able to use these
interchangeably in day to day conversation. This will impress your friends and strangers
immensely.
radians and so on. You should be able to use these
interchangeably in day to day conversation. This will impress your friends and strangers
immensely.
If I take any two sinusoidal waves that have the same frequency, but they have different
amplitudes, and they’re offset in phase, and I add them, the result will be a sinusoidal
wave with the same frequency with another amplitude and phase. For example, take a
look at Figure 1.10. The top plot shows one period of a 1 kHz sinusoidal wave starting
with a phase of 0 radians and a peak amplitude of 0.5. The second plot shows one period
of a 1 kHz a sinusoidal wave starting with a phase of  radians (45∘) and a peak
amplitude of 0.8. If these two waves are added together, the result, shown on the bottom,
is one period of a 1 kHz sinusoidal wave with a different peak amplitude and
starting phase. The important thing that I’m trying to get across here is that
the frequency and wave shape stay the same – only the amplitude and phase
change.
radians (45∘) and a peak
amplitude of 0.8. If these two waves are added together, the result, shown on the bottom,
is one period of a 1 kHz sinusoidal wave with a different peak amplitude and
starting phase. The important thing that I’m trying to get across here is that
the frequency and wave shape stay the same – only the amplitude and phase
change.
So what? Well, most recording engineers talk about phase. They’ll say things like “a sine wave, 135∘ late” which looks like the curve shown in Figure 1.11.
If we wanted to be a little geeky about this, we could use the equation below to say the same thing:
 | (1.27) |
which means the value of y at a given value of α is equal to A multiplied by the sine of the sum of the values α and ϕ. In other words, the amplitude y at angle α equals the sine of the angle α added to a constant value ϕ and the peak value will be A. In the above example, y(α) would be equal to 1*sin(α +135∘) where α can be any value.
Unfortunately, we have to be even more geeky than that. We have to talk about cosine waves instead of sine waves. We’ve already seen that these are really the same thing, just 90∘ apart, so we can already figure out that a sine wave that’s starting 135∘ late is the same as a cosine wave that’s starting 45∘ late.
Now that we’ve made that transition, there is another way to describe a wave. If we scale the sine and cosine components correctly and add them together, the result will be a sinusoidal wave at any phase and amplitude we want. Take a look at the equation below:
 | (1.28) |
where A is the amplitude
ϕ is the phase angle
α is any angle
a = Acos(ϕ)
b = Asin(ϕ)
What does this mean? Well, all it means is that we can now specify values for a and b and, using this equation, wind up with a sinusoidal waveform of any amplitude and phase that we want. Essentially, we just have an alternate way of describing the waveform.
For example, where you used to say “A cosine wave with a peak amplitude of 0.93
and  radians ( or 60∘) late” you can now say:
radians ( or 60∘) late” you can now say:
A = 0.93
ϕ = 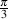
a = 0.93*cos( ) = 0.93*0.5 = 0.4650
) = 0.93*0.5 = 0.4650
b = 0.93*sin(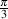 ) = 0.93*0.8660 = 0.8054
) = 0.93*0.8660 = 0.8054
Therefore
 | (1.29) |
So we could say that it’s the combination of an upside-down sine wave (upside-down because the sine component is subtracted in the equation) with a peak amplitude of 0.8054 and a cosine wave with a peak amplitude of 0.4650. We’ll see in Chapter 1.6 how to write this a little more easily.
Remember that, if you’re used to thinking in terms of a peak amplitude and a fixed phase offset, then this might seem less intuitive. However, if your job is to build a synthesizer that makes a sinusoidal wave with a given phase offset, you’d much rather just mix (in other words, add) an appropriately scaled cosine and sine rather than having to build a delay.
Once upon a time you learned how to count. You were probably taught to count your fingers... 1, 2, 3, 4 and so on. Although no one told you so at the time, you were being taught a set of numbers called whole numbers.
Sometime after that, you were probably taught that there’s one number that gets tacked on before the ones you already knew – the number 0.
A little later, sometime after you learned about money and the fact that we don’t have enough, you were taught negative numbers... -1, -2, -3 and so on. These are the numbers that are less than 0.
That collection of numbers is called integers – all “countable” numbers that are negative, zero and positive. So the collection is typically written
... -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5 ...
Eventually, after you learned about counting and numbers, you were taught how to
divide. When someone said “20 divided by 5 equals 4” then they meant “if you have 20
sticks, then you could put those sticks in 4 piles with 5 sticks in each pile.” Eventually,
you learned that the division of one number by another can be written as a fraction like 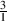 or
or  or
or  or
or  .
.
If you do that division the old-fashioned way, you get numbers like this:
3∕1 = 3.000000000 etc...
20∕5 = 4.00000000 etc...
5∕4 = 1.200000000 etc...
1∕3 = 0.333333333 etc...
The thing that I’m trying to point out here is that eventually, these numbers start repeating sometime after the decimal point. These numbers are called rational numbers.
What happens if you have a number that doesn’t start repeating, no matter how many numbers you have? Take a number like the square root of 2 for example. This is a number that, when you multiply it by itself, results in the number 2. This number is approximately 1.4142. But, if we multiply 1.4142 by 1.4142, we get 1.99996164 – so 1.4142 isn’t exactly the square root of 2. In fact, if we started calculating the exact square root of 2, we’d result in a number that keeps going forever after the decimal place and never repeats. Numbers like this (π is another one...) that never repeat after the decimal are called irrational numbers
All of these number types – rational numbers (which includes integers) and irrational numbers fall under the general heading of real numbers. The fact that these are called “real” implies immediately that there is a classification of numbers that are “unreal” – in fact this is the case, but we call them “imaginary” instead.
Let’s think about the idea of a square root. The square root of a number is another number which, when multiplied by itself is the first number. For example, 3 is the square root of 9 because 3*3 = 9. Let’s consider this a little further: a positive number muliplied by itself is a positive number (for example, 4*4 = 16... 4 is positive and 16 is also positive). A negative number multiplied by itself is also positive (i.e. -4*-4 = 16).
Now, in the first case, the square root of 16 is 4 because 4*4 = 16. (Some people would be really picky and they’ll tell you that 16 has two roots: 4 and -4. Those people are slightly geeky, but technically correct.) There’s just one small snag – what if you were asked for the square root of a negative number? There is no such thing as a number which, when multiplied by itself results in a negative number. So asking for the square root of -16 doesn’t make sense. In fact, if you try to do this on your calculator, it’ll probably tell you that it gets an error instead of producing an answer.
Mathematicians as a general rule don’t like loose ends – they aren’t the type of people who leave things lying around... and having something as simple as the square root of a negative number lying around unanswered got on their nerves so they had a bunch of committee meetings and decided to do something about it. Their answer was to invent a new number called i (for imaginary) although some people call it j just to screw everyone up.6 Generally speaking, mathematicians use i and physicists and engineers use j so we’ll stick with j – we’ll see why in a later chapter.)
“What is j?” I hear you cry. Well, j is the square root of -1. Of course, there is no number that is the square root of -1, but since that answer is inadequate, j will do the trick, so we just define it with the equation
 | (1.30) |
and therefore
 | (1.31) |
Now, remember that j * j = -1. This is useful for any square root of any negative
number, you just calculate the square root of the number pretending that it was positive,
and then stick an j after it. So, since the square root of 16, abbreviated 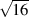 = 4 and
= 4 and
 = j, then
= j, then 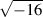 = j4. Let’s do a couple:
= j4. Let’s do a couple:
 | (1.32) |
 | (1.33) |
Another way to think of this is  =
=  =
=  *
* = j
= j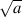 so:
so:
 | (1.34) |
Of course, this also means that
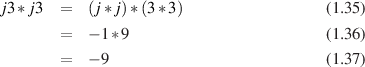
Now that we have real and imaginary numbers, we can combine them to create a complex number. Remember that you can’t just mix real numbers with imaginary ones – you keep them separate most of the time, so you see numbers like
3+j2
This is an example of a complex number that contains a real component (the 3) and an imaginary component (the j2). In some cases, these numbers are further abbreviated with a single Greek character, like α or β, so you’ll see things like
α = 3+j2
In other cases, you’ll see a bold letter like the following:
A = 3+j2
A lot of people do this because they like reserving Greek letters like α and ϕ for variables associated with angles.
Personally, I like seeing the whole thing - the real and the imaginary components - no Greek letters (they’re for angles!) or bold letters.
Let’s say that you have to add complex numbers. In this case, you have to keep the real and imaginary components separate, but you just add the separate components separately. For example:
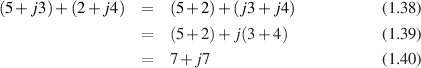
If you’d like the short-cut rule, it’s
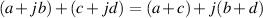 | (1.41) |
The multiplication of two complex numbers is similar to multiplying regular old real numbers. For example:
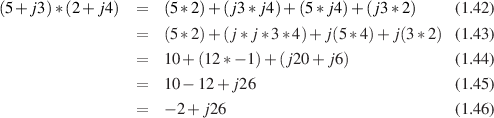
The shortened rule is:
 | (1.47) |
There are a couple of basic rules that we can get out of the way at this point when it comes to complex numbers. These are similar to their corresponding rules in normal mathematics.
This law says that the order of the numbers doesn’t matter when you add or multiply. For example, 3 + 5 is the same as 5 + 3, and 3 * 5 = 5 * 3. In the case of complex math:
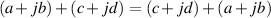 | (1.48) |
and
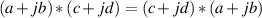 | (1.49) |
This law says that, when you’re adding more than two numbers, it doesn’t matter which two you do first. For example (2 + 3) + 5 = 2 + (3 + 5). The same holds true for multiplication.
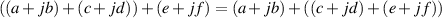 | (1.50) |
and
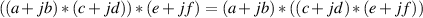 | (1.51) |
This law says that, when you’re multiplying a number by the sum of two other numbers, it’s the same as adding the results of multiplying the numbers one at a time. For example, 2 * (3 + 4) = (2 * 3) + (2 * 4). In the case of complex math:
 | (1.52) |
These are laws that are pretty obvious, but sometimes they help out. The corresponding laws in normal math are x + 0 = x and x * 1 = x.
 | (1.53) |
and
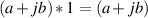 | (1.54) |
Every number has what is known as an additive inverse – a matching number which when added to its partner equals 0. For example, the additive inverse of 2 is -2 because 2 + -2 = 0. This additive inverse can be found by mulitplying the number by -1 so, in the case of complex numbers:
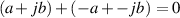 | (1.55) |
Therefore, the additive inverse of (a + jb) is (-a - jb)
Similarly to additive inverses, every number has a matching number, which, when the
two are multiplied, equals 1. The only exception to this is the number 0, so, if x does not
equal 0, then the multiplicative inverse of x is 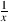 because x*
because x* = *
= *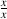 = 1. Some books
write this as x*x-1 = 1 because x-1 =
= 1. Some books
write this as x*x-1 = 1 because x-1 =  . In the case of complex math, things are
unfortunately a little different because 1 divided by a complex number is... well...
complex.
. In the case of complex math, things are
unfortunately a little different because 1 divided by a complex number is... well...
complex.
if (a + jb) is not equal to 0 then:
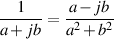 | (1.56) |
We won’t worry too much about how that’s calculated, but we can establish that it’s true by doing the following:

There’s one interesting thing that results from this rule. What if we looked for the
multiplicative inverse of j? In other words, what is  ? Well, let’s use the rule above and
plug in (0+j1).
? Well, let’s use the rule above and
plug in (0+j1).
 | (1.60) |
 | (1.61) |
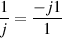 | (1.62) |
 | (1.63) |
Weird, but true.
The multiplicative inverse rule can be used if you’re trying to divide. For example,  is
the same as a*
is
the same as a* therefore:
therefore:

Complex math has an extra relationship that doesn’t really have a corresponding equivalent in normal math. This relationship is called a complex conjugate but don’t worry – it’s not terribly complicated. The complex conjugate of a complex number is defined as the same number, but with the polarity of the imaginary component inverted. So:
the complex conjugate of (a + bj) is (a - bj)
A complex conjugate is usually abbreviated by drawing a line over the number. So:
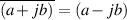 | (1.66) |
The absolute value of a complex number is a little weirder than what we usually think of as an absolute value. In order to understand this, we have to look at complex numbers a little differently:
Remember that j*j = -1. Also, remember that, if we have a cosine wave and we delay it by 90∘ and then delay it by another 90∘, it’s the same as inverting the polarity of the cosine, in other words, multiplying the cosine by -1. So, we can think of the imaginary component of a complex number as being a real number that’s been rotated by 90∘, we can picture it as is shown in Figure 1.12.

Notice that Figure 1.12 actually winds up showing three things. It shows the real component along the x-axis, the imaginary component along the y-axis, and the absolute value or modulus of the complex number as the hypotenuse of the triangle. This is shown in mathematical notation in exactly the same way as in normal math – with vertical lines. For example, the modulus of 2+3i is written |2+3i|
This should make the calculation for determining the modulus of the complex number almost obvious. Since it’s the length of the hypotenuse of the right triangle formed by the real and imaginary components, and since we already know the Pythagorean theorem then the modulus of the complex number (a+jb) is

Given the values of the real and imaginary components, we can also calculate the angle of the hypotenuse from horizontal using the equation
 | (1.68) |
 | (1.69) |
This will come in handy later.
This is probably the most important question for us. Imaginary numbers are great for mathematicians who like wrapping up loose ends that are incurred when a student asks “what’s the square root of -1?” but what use are complex numbers for people in audio? Well, it turns out that they’re used all the time, by the people doing analog electronics as well as the people working on digital signal processing. We’ll get into how they apply to each specific field in a little more detail once we know what we’re talking about, but let’s do a little right now to get a taste.
In the chapter that introduces the trigonometric functions sine and cosine, we looked at how both functions are just one-dimensional representations of a two-dimensional rotation of a wheel. Essentially, the cosine is the horizontal displacement of a point on the wheel as it rotates. The sine is the vertical displacement of the same point at the same time. Also, if we know either of these two components, we know
but we need to know both components to know the direction of rotation.
At any given moment in time, if we froze the wheel, we’d have some contribution of these two components – a cosine component and a sine component for a given angle of rotation. Since these two components are effectively identical functions that are 90∘ apart (for example, a sine wave is the same as a cosine that’s been delayed by 90∘) and since we’re thinking of the real and imaginary components in a complex number as being 90∘ apart, then we can use complex math to describe the contributions of the sine and cosine components to a signal.
Huh? Let’s look at an example. If the signal we wanted to look at a signal that consisted only of a cosine wave as is shown in Figure 1.13, then we’d know that the signal had 100% cosine and 0% sine. So, if we express the cosine component as the real component and the sine as the imaginary, then what we have is:
 | (1.70) |
If the signal was an upside-down cosine, then the complex notation for it would be (-1+0j) because it would essentially be a cosine * -1 and no sine component. Similarly, if the signal was a sine wave, it would be notated as (0-j1).
This last statement should raise at least one eyebrow... Why is the complex notation for a positive sine wave (0-j1)? In other words, why is there a negative sign there to represent a positive sine component? Well... Actually there is no good explanation for this at this point in the book, but it should become clear when we discuss a concept known as the Fourier Transform in Section 9.2. For now, you’ll just have to trust me.
This is fine, but what if the signal looks like a sinusoidal wave that’s been delayed a little like the one in Figure 1.14?
This signal was created by a specific combination of a sine and cosine wave. In fact, it’s 70.7% sine and 70.7% cosine. (If you don’t know how I arrived that those numbers, check out Equation 1.27.) How would you express this using complex notation? Well, you just look at the relative contributions of the two components as before:
 | (1.71) |
It’s interesting to notice that, although Figure 1.14 is actually a combination
of a cosine and a sine with a specific ratio of amplitudes (in this case, both
at 0.707 of “normal”), the result looks like a sine wave that’s been shifted in
phase by -45∘ or - radians (or a cosine that’s been phase-shifted by 45∘ or
radians (or a cosine that’s been phase-shifted by 45∘ or  radians). In fact, this is the case – any phase-shifted sine wave can be expressed as
the combination of its sine and cosine components with a specific amplitude
relationship.
radians). In fact, this is the case – any phase-shifted sine wave can be expressed as
the combination of its sine and cosine components with a specific amplitude
relationship.
Therefore, any sinusoidal waveform with any phase can be simplified into its two elemental components, the cosine (or real) and the sine (or imaginary). Once the signal is broken into these two constituent components, it cannot be further simplified.
If we look at the example at the end of Section 1.5, we calculated using the equation
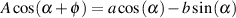 | (1.72) |
that a cosine wave with a peak amplitude of 0.93 and a delay of  radians was
equivalent to the combination of a cosine wave with a peak amplitude of 0.4650 and an
upside-down sine wave with a peak amplitude of 0.8054. Since the cosine is the real
component and the sine is the imaginary component, this can be expressed using the
complex number as follows:
radians was
equivalent to the combination of a cosine wave with a peak amplitude of 0.4650 and an
upside-down sine wave with a peak amplitude of 0.8054. Since the cosine is the real
component and the sine is the imaginary component, this can be expressed using the
complex number as follows:
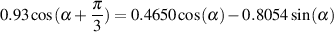 | (1.73) |
which is represented as
0.4650 + j 0.8054
which is a much simpler way of doing things. (Notice that I flipped the “-” sign to a “+.”) For more information on this, check out The Scientist and Engineer’s Guide to Digital Signal Processing available at www.dspguide.com

So far, we’ve looked at logarithms with a base of 10. As we’ve seen, a logarithm is just an exponent backwards, so if AB = C then logAC = B. Therefore log10100 = 2.
There is a beast in mathematics known as a natural logarithm which is just like a regular old everyday logarithm except that the base is a very specific number – it’s e. “What’s e?” I hear you cry... Well, just like π is an irrational number close to 3.14159, e is an irrational number that is pretty close to 2.718281828459045235360287 but it keeps on going after the decimal place forever and ever. (If it didn’t, it wouldn’t be irrational, would it?) How someone arrived at that number is pretty much inconsequential – particularly if we want to avoid using calculus, but if you’d like to calculate it, and if you’ve got a lot of time on your hands, the math is:
 | (1.74) |
(If you’re not familiar with the mathematical expression “!” you don’t have to panic! It’s short for factorial and it means that you multiply all the whole numbers up to and including the number. For example, 5! = 1*2*3*4*5.)
How is this e useful to us? Well, there are a number of reasons, but one in particular. It turns out that if we raise e to an exponent x, we get the following.
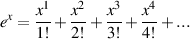 | (1.75) |
Unfortunately, this isn’t really useful to us. However, if we raise e to an exponent that is an imaginary number, something different happens.
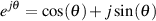 | (1.76) |
This is known as Euler’s identity or Euler’s formula.
Notice now that, by putting an j up there in the exponent, we have an equation that links trigonometric functions to an algebraic function. This identity, first proved by a man named Leonhard Euler7 , is really useful to us.
There’s just a couple of extra things to take note of:
Since cos(π) = -1 and sin(π) = 0 then:
 | (1.77) |
 | (1.78) |
therefore
 | (1.79) |
Here’s where the beauty of all this math actually becomes apparent. What we’ve essentially done is to make things look complicated in order to simplify working with the equations.
We saw in the last two chapters how an arbitrary wave like a cosine with a peak
amplitude of 0.93 and 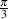 radians late could be expressed in a number of different ways.
We can say 0.93cos(n+
radians late could be expressed in a number of different ways.
We can say 0.93cos(n+ ) or 0.4650cos(n)-0.8054sin(n) or we can represent it with
the complex number 0.4650+j0.8054. I argued at the time that using these
weird complex notations would make life simpler. For example, it’s easier to
add two complex numbers to get a third complex number than it is to try and
add two waves with different amplitudes and delays. However, if you were the
arguing type, you’d have pointed out that multiplying two complex numbers
really isn’t all that attractive a proposition. This is where Euler becomes our
friend.
) or 0.4650cos(n)-0.8054sin(n) or we can represent it with
the complex number 0.4650+j0.8054. I argued at the time that using these
weird complex notations would make life simpler. For example, it’s easier to
add two complex numbers to get a third complex number than it is to try and
add two waves with different amplitudes and delays. However, if you were the
arguing type, you’d have pointed out that multiplying two complex numbers
really isn’t all that attractive a proposition. This is where Euler becomes our
friend.
Using Euler’s identity, we can convert the complex representation of our waveform into a complex exponential notation as shown below
 | (1.80) |
Which is represented as
 | (1.81) |
There’s a really important thing to remember here. The two values shown in Equation 1.81 are only representations of the values shown in Equation 1.80. They are not the same thing mathematically.
In other words, if you calulated 0.93cos(α +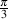 ) and 0.4650cos(α)-0.8054sin(α),
you’d get the same answer. If you calculated 0.4650+j0.8054 and 0.93ej
) and 0.4650cos(α)-0.8054sin(α),
you’d get the same answer. If you calculated 0.4650+j0.8054 and 0.93ej , you’d get
the same answer. However, the two answers that you just got would not be the same. We
just use the notation to make life a little simpler.
, you’d get
the same answer. However, the two answers that you just got would not be the same. We
just use the notation to make life a little simpler.
The nice thing about this, and the thing to remember is the way that the 0.93 and the
 on the left-hand side of Equation 1.80 correspond to the same numbers on the
right-hand side of Equation 1.81.
on the left-hand side of Equation 1.80 correspond to the same numbers on the
right-hand side of Equation 1.81.
Of course, now the question is “Why the hell do we go through all of this hassle?” Well, the answer lies in the simplicity of dealing with complex numbers represented as exponents, but I will leave it to other books to explain this. A good place to start with this question is The Scientist and Engineer’s Guide to Digital Signal Processing by Steven W. Smith and found at www.dspguide.com.
Let’s count. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Fun isn’t it? When we count we’re using the words “one,” “two” and so on (or the symbols “1,” “2” and so on) to represent a quantity of things. Two eyes, two ears, two teeth... The word “two” or the symbol “2” is just used to denote how many of something we have.
One of the great things about our numbering system is that we don’t need a symbol for every quantity – we recycle. What I mean by this is, we have individual symbols that we can write down which indicate the quantities zero through to nine. Once we get past nine, however, we have to use two symbols to denote the number ten – we write “one zero” but we mean “ten.” This is very efficient for lots of reasons, not the least of which is the fact that, if we had to have a different symbol for every number, our laptop computers would have to be much bigger to accomodate the keyboard.
This raises a couple of issues:
We have ten symbols because most of us have ten fingers. When we learned to count, we started by counting our fingers. In fact, another word for “finger” is “digit” which is why we use the word digit for the symbols that we use for counting – the digit “0” represents the quantity (or the number) “zero.”
How does the system work? This won’t come as a surprise, but we’ll go through it anyway... Let’s look at the number 7354. What does this represent? Well, one way to write is to say “seven thousand, three hundred and fifty-four.” In fact, this tells us right away how the system works. Each digit represents a different “power” of ten... Take a look at Table 1.2.
| 7 | 3 | 5 | 4 | |||
| Thousand’s place | Hundred’s place | Ten’s place | One’s place | |||
| 7*1000 | + | 3*100 | + | 5*10 | + | 4*1 |
| 7*103 | + | 3*102 | + | 5*101 | + | 4*100 |
| = 7354 | ||||||
Following this table, we can see that if we write a string of digits together, each of the digits is multiplied by a power of ten where the placement of the digit in question determines the exponent. The right-most digit multiplied by the 0th power of ten, the next digit to the left is multiplied by the 1st power of ten, the next is multiplied by the 2nd power of ten and so on until you run out of digits. Also, we can see why we’re taught phrases like “the thousand’s place” – the digit 7 in the number above is multiplied by 1000 (103 because of its location in the written number – it’s in the “thousand’s place”)
This is a very efficient method of writing down a number because each time you add an extra digit, you increase the number of possible numbers you can represent by a factor of ten. For example, if I have three digits, I can represent a total of one thousand different numbers (000 – 999). If I add one more digit and make it a four-digit number, I can represent ten thousand different numbers (0000 – 9999) – an increase by a factor of ten.
This particular property of the system makes some specific mathematical functions very easy. If you want to multiply a number by ten, you just stick a “0” on the right end of it. For example, 346 multiplied by ten is 3460. By adding a zero, you shift all the digits to the left and the multiplication is automatic. In fact, what you’re doing here is using the way you write the number to do the multiplication for you – by shifting digits, you wind up multiplying the digits by new powers of ten in your head when you read the number aloud.
Similarly, if you don’t mind a little inaccuracy, you can divide by ten by removing the right-most digit. This is a little less effective because it’s not perfect – you are throwing some details away – but it’s pretty close. For example, 346 divided by ten is pretty close to 34.
We typically call this system the decimal numbering system (because the root “dec” means “ten” – therefore words like “decimate” – to reduce in number by a power of ten, and “decathalon” – a sporting contest with 10 different events). There are those among us, however, who like our lives to be a little more ordered – they use a different name for this system. They call it base 10 – indicating that there are a total of ten different digits at our disposal and that the location of the digits in a number correspond to some power of 10.
Imagine if we all had only two fingers instead of ten. We would probably have wound up with a different way of writing down numbers. We have ten digits (0 – 9) because we have ten fingers. If we only had two fingers, then it’s reasonable to assume that we’d only have two digits – 0 and 1. This means that we have to re-think the way we construct the recycling of digits to make bigger numbers.
Let’s count using this new two-digit system...
000 (zero)
001 (one)
Now what? Well, it’s the same as in decimal, we increase our number to two digits and keep going.
010 (two)
011 (three)
100 (four)
This time, because we only have two digits, we multiply the digits in different locations by powers of two instead of powers of ten. So, for a big number like 10011, we can follow the same procedure as we did for base 10.
| 1 | 0 | 0 | 1 | 1 | ||||
| Sixteen’s | Eight’s | Four’s | Two’s | One’s | ||||
| 1 *24 | + | 0 *23 | + | 0 *22 | + | 1 *21 | + | 1 *20 |
| 1*16 | + | 0*8 | + | 0*4 | + | 1*2 | + | 1*1 |
| 16 | + | 0 | + | 0 | + | 2 | + | 1 |
| = 19 | ||||||||
So, the binary number 10011 represents the same quantity as the decimal number 19. Remember, all we’ve done is to change the method by which we’re writing down the same thing. “19” in base 10 and “10011” in base 2 both mean “nineteen.”
This would be a good time to point out that if we add an extra digit to our binary number, we increase the number of quantities we can represent by a factor of two. For example: if we have a three-digit binary number, we can represent a total of eight different numbers (000 – 111 or zero to seven). If we add an extra digit and make it a four-digit number we can represent sixteen different quantities (0000 – 1111 or zero to fifteen).
There are a lot of reasons why this system is good. For example, let’s say that you had to send a number to a friend using only a flashlight to communicate. One smart way to do this would be to flash the light on and off with a short “on” corresponding to a “0” and a long “on” corresponding to a “1” – so the number nineteen would be “long – short – short – long – long.” Some less-than-smart ways would be to bang your flashlight on a table nineteen times – or you could write the number “19” on the flashlight and throw it at your friend...
In the world of digital audio we typically use slightly different names for things in the binary world. For starters, we call the binary digits bits (get it? binary digits). Also, we don’t call a binary number a “number” – we call it a binary word. Therefore “1011010100101011” is a sixteen-bit binary word.
Just like in the decimal system, there are a couple of quick math tasks that can be accomplished by shifting the bits (programmers call this bit shifting but be careful when you’re saying this out loud to use it in context, thereby avoiding people getting confused and thinking that you’re talking about dogs...)
If we take a binary word and bit shift it one place to the left (i.e. 111 becoming 1110) we are multiplying by two (in the previous example, 111 is seven, 1110 is fourteen).
Similarly, if we bit shift to the right, removing the right-most bit, we are dividing by two quickly, but frequently inaccurately. (i.e. 111 is seven, 11 is 3 – nearly half of seven) Note that, if it’s an even number (therefore ending in a “0”) a bit shift to the right will be a perfect division by zero (i.e. 1110 is fourteen, 111 is seven – half of fourteen). So if we bit shift for division, half of the time we’ll get the correct answer and the other half of the time we’ll wind up ignoring a remainder of a half.
The advantage of binary is that we only need two digits (0 and 1) or two “states” (on and off, short and long etc...) to represent the binary word. The disadvantage of binary is that it takes so many bits to represent a big number. For example, the fifteen-bit word 111111111111111 is the same as the decimal number 32768. I only need five digits to express in decimal the same number that takes me fifteen digits in binary. So, let’s invent a system that has too much of a good thing: we’ll go the other way and pretend we all have sixteen fingers.
Let’s count again: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ... now what? We can’t go to “10” yet because we have six more fingers left... so we need some new symbols to take care of the gap. We’ll use letters! A, B, C, D, E, F, 10, 11, 12, huh?
Remember, we’re assuming that we have sixteen digits to use, therefore there have to be sixteen individual symbols to represent the numbers zero through to fifteen. Therefore, we can make the Table 1.4:
| Number | Decimal | Hexadecimal | Binary |
| zero | 0 | 0 | 0000 |
| one | 1 | 1 | 0001 |
| two | 2 | 2 | 0010 |
| three | 3 | 3 | 0011 |
| four | 4 | 4 | 0100 |
| five | 5 | 5 | 0101 |
| six | 6 | 6 | 0110 |
| seven | 7 | 7 | 0111 |
| eight | 8 | 8 | 1000 |
| nine | 9 | 9 | 1001 |
| ten | 10 | A | 1010 |
| eleven | 11 | B | 1011 |
| twelve | 12 | C | 1100 |
| thirteen | 13 | D | 1101 |
| fourteen | 14 | E | 1110 |
| fifteen | 15 | F | 1111 |
| sixteen | 16 | 10 | 10000 |
So, now we wind up with these strange numbers that include the letters A through F. So we’ll see something like 3D4A. What number is this exactly?
| 3 | D | 4 | A | |||
| 4096’s | 256’s | 16’s | 1’s | |||
| 3*163 | + | D*162 | + | 4*161 | + | A*160 |
| 3*4096 | + | D*256 | + | 4*16 | + | A*1 |
| 3*4096 | + | 13*256 | + | 4*16 | + | 10*1 |
| 12288 | + | 3328 | + | 64 | + | 10 |
| = 15690 | ||||||
If this seems a little confusing at this point, don’t panic. It does for everyone. I think that the confusion with hexadecimal arises from the fact that it’s so close to decimal – you can have the number 246 in decimal and the number 246 in hexadecimal – but these are not the same number, so you have to translate. (For example, the German word for “poison” is “Gift” – so if you’re reading in German, this is not a word that you should think in English. An English “gift” and a German “Gift” are different things... hopefully...)
Of course, this raises the question “Why would we use such a confusing system in the first place!?” The answer actually lies back in the binary system. All of our computers and DSP and digital audio everything use the binary system to fire numbers around. This is inescapable. The problem is that those binary words are just so long to write down that, if you had to write them in a book, you’d waste a lot of paper. You could translate the numbers into decimal, but there’s no correlation between binary and decimal – it’s difficult to translate. However, check back to Table 3. Notice that going from the number fifteen to the number sixteen results in the hexadecimal number going from a 1-digit number to a 2-digit number. Also notice that, at the same time, the binary word goes from 4 bits to 5. This is where the magic lies. A single hexadecimal digit (0 – F) corresponds directly to a four-bit binary word (0000 – 1111). Not only this, but if you have a longer binary word, you can slice it up into four-bit sections and represent each section with its corresponding hexadecimal digit. For example, take the number 38069:
1001010010110101
Slice this number into 4-bit sections (start slicing from the right)
1001 0100 1011 0101
Now, look up the corresponding hexadecimal equivalents for each 4-bit section using Table 1.4:
9 4 B 5
94B5
So, as can be seen from the example above, there is a direct relationship between each 4-bit “slice” of the binary word and a corresponding hexadecimal number. If we were to try to convert the binary word into decimal, it would be much more of a headache. Since this translation is so simple, and because we use one quarter the number of digits, you’ll often see hexadecimal used to denote numbers that are actually sent through the computer as a binary word.
This chapter only describes 3 different numbering systems, base 10, base 2 and base 16, but there are lots of others – even some that used to be used, that aren’t anymore, but still have vestiges hidden in our language. American readers should recognize the phrase “Four score and seven years ago” meaning “4 * 20 + 7 years ago” or “87 years ago.” This is a leftover from the days when years were grouped into “scores.” 1 score = 20 years, so we were working in base 20. The concept of a week is a form of base 7. Three weeks is 3 * 7 = 21 days (in other words, the number 3 is in the “seven’s” place). Twelve inches in a foot (base 12), Fourteen pounds in a stone (base 14), Twelve eggs in a dozen (base 12), Three feet in a yard (base 3). Eight furlongs in a mile, 24 hours in a day, 60 seconds in a minute... We use these strange systems all the time without even really knowing it.
Warning! This chapter is not intended to teach you how to “do” calculus. It’s just here to give you an intuitive feel for what’s being calculated when you see a nasty-looking equation. If you want to learn calculus, this is probably not going to help you at all.
Calculus can be thought of as math that can cope with the idea of infinity. In normal,
everyday math, we generally stick with finite numbers because they’re easier to
deal with. Whenever a problem starts to use infinity, we just bail out and say
something like “that’s undefined” or “you can’t do that” or “I’m sorry, I have
to leave to go make a previous engagement.”. For example, let’s think about
division for a moment. If you take the equation y = 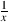 , then you know that, the
smaller x gets, the bigger y becomes. The problem is that, as x approaches 0, y
approaches infinity which makes people nervous. Consequently, if x = 0, then we
just back away and say “you can’t divide by zero” and your calculator gives
you a little complaint like “ERROR.” Calculus lets us cope with this minor
problem.
, then you know that, the
smaller x gets, the bigger y becomes. The problem is that, as x approaches 0, y
approaches infinity which makes people nervous. Consequently, if x = 0, then we
just back away and say “you can’t divide by zero” and your calculator gives
you a little complaint like “ERROR.” Calculus lets us cope with this minor
problem.
When you have an equation, you are saying that something is equal to something else. For example, look at Equation 1.82.
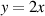 | (1.82) |
This says that the value of y is calculated by getting a value for x and multiplying that by 2 (I really hope that this is not coming as a surprise...).
A function is basically the busy side of an equation. Frequently, you will see books talking about a function f(x) which just means that you do something to x to come up with something else. For example, in Equation 1.82, the function f(x) (when you read this out loud, you say “f of x”) is 2x. Of course, this can be much more complicated, but it can still just be thought of as a function - do some math using x and you’ll get your answer.
Let’s pretend that we’re standing in a concert hall with a very long reverb time. If I clap my hands and create a sound, it starts dying away as soon as I’ve stopped making the noise. Each second that goes by, the sound in the concert hall gets closer and closer to no sound.
One interesting thing about this model is that, if it were true, the sound level would be reduced each second and, since half of something can never equal nothing, there will be sound in the room forever, always getting quieter and quieter. The level of sound is always getting closer and closer to 0, but it never actually gets there.
This is the idea behind a limit. In this particular example, the limit of the sound pressure level in the decaying reverb is 0 – we never get to 0, but we always get closer to it.
There are lots of things in nature that follow this idea of a limit. The radioactive half-life of a material is one example. If a radioactive substance loses half of its radioactivity in one year, then the next year it will lose half of the remaining amount, and the next year, half that amount. So, each year it loses less and less of the original amount. One implication of this is that it never gets to a state of “no radioactivity” because half of something is never nothing.8
Just remember that a limit is a boundary that is never reached, but you can always get closer to it.
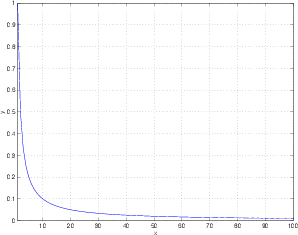
Think about Equation 1.83.
 | (1.83) |
This is a pretty simple equation that says that y is inversely proportional to x. Therefore, if x gets bigger, y gets smaller. For example, if we calculate the value of y in this equation for a number of values of x, we’ll get a graph that looks like Figure 1.17.
As x gets bigger and bigger, y will get closer and closer to 0, but it will never reach it. If x = ∞ then y = 0, but you don’t have an ∞ button on your calculator. If x is less than ∞ but greater than 0, then y has to be a number that is greater than 0 because 1 divided by something can never be nothing.
This is exactly the idea of a limit, the first concept to learn when delving into the
world of calculus. It’s the number that a function (like 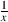 for example) gets closer and
closer to, but never reaches. In the case of the function
for example) gets closer and
closer to, but never reaches. In the case of the function  , its limit is 0 as x approaches
∞.) For example, take a look at Equation 1.84.
, its limit is 0 as x approaches
∞.) For example, take a look at Equation 1.84.
 | (1.84) |
Equation 1.84 says “z is equal to the number that the function  approaches as x gets
closer to ∞.” This does not mean that x will ever get to ∞, but that it will forever get
closer to it.
approaches as x gets
closer to ∞.” This does not mean that x will ever get to ∞, but that it will forever get
closer to it.
In the example above, x is getting closer and closer to ∞ but this isn’t always the case in a limit. For example, Equation 1.85 shows that you can have a limit where a number is getting closer and closer to something other than ∞.
 | (1.85) |
If x = 0, then we get a nasty number from f(x), but as x approaches 0, then f(x) approaches 1 because sin(x) gets closer and closer to x as x gets closer and closer to 0.
As I said in the introduction, calculus is just math than can cope with infinity. In the case of limits, we’re talking about numbers that we get infinitely close to, but never reach.
Back in Chapter 1.2 we looked at how to find the slope of a straight line, but what about if the line is a curve? Well, this gets us into a small problem because if the line is curved, then its slope is different in different places. For example, take a look at the sinusoidal curve in Figure 1.18.

Our goal is to find the slope at the point marked on the plot where x = 2. In other words, we’re looking for the slope of the tangent of the curve at x = 2 as is shown in Figure 1.19.

We could estimate the slope at this point by drawing a line through two points where x1 = 2 and x2 = 3 and then measuring the rise and run for that line as is shown in Figure 1.20.

As we can see in this example, the run for the line we’ve created is 1 (because it’s 3-2) and the rise is -0.768 (because it’s sin(3)-sin(2)). Therefore the slope is -0.768.
This method of approximating will give us a slope that is pretty close to the slope at the point we’re interested in, but how do we make a better approximation? One way to do it is to reduce the distance between the point we’re looking for and the points where we’re drawing the line. For example, looking at Figure 1.21, we’ve changed the nearby points to x1 = 2 and x2 = 2.5, which gives us a line with a slope of -0.622. This is a little closer to the real answer, but still not perfect.

As we get the points closer and closer together, the slope of the line gets closer and closer to the right answer. When the two points are infinitely close to x = 2 (therefore, they are at x1 = 2 and x2 = 2 because two points that are infinitely close are in the same place) then the slope of the line is the slope of the curve at that point.
What we’re doing here is using the idea of a limit – as the run of the line (the horizontal distance between our two points) approaches the limit of 0, then the slope of the line approaches the slope of the curve at the point we’re looking at.
This is the idea behind something called the derivative of a function. The curve that we’re looking at can be described by an equation where the value of y is determined by some math that we do using the value of x. For example, if the equation is
 | (1.86) |
then we get the curve seen above in Figure 1.18. In this particular case, given a value of x, we can figure out the value of y. As a result we say that y is a function of x or
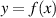 | (1.87) |
So, the derivative of f(x) is just another equation that gives you the slope of the curve at any value of x. In mathematical language, the derivative of f(x) is written in one of two ways. This simplest is if we just we write f′(x) which means “the derivative (or the slope) of the function f(x)” (remember: derivative is just a fancy word for slope).
If you’re dealing with an equation where y = f(x) as we’ve seen above in this chapter, then you’re looking for the “derivative of y with respect to x.” This is just a fancier way of saying “what’s the slope of f(x)?” We don’t need to say “f of x” because it’s easier to say “y” but we need to say “with respect to x” because the slope changes as x changes. Therefore there is a relationship between the derivative of y and the value of x. If you want to use mathematical language to write “derivative of y with respect to x,” you write
 | (1.88) |
But, always remember, if y = f(x) then
 | (1.89) |
There is one important thing to remember when you see this symbol.  is one thing
that means “the derivative of y with respect to x.” It is not something divided by
something else. This is a stand-alone symbol that doesn’t have anything to do with
division.
is one thing
that means “the derivative of y with respect to x.” It is not something divided by
something else. This is a stand-alone symbol that doesn’t have anything to do with
division.
Let’s look at a practical example. Any introductory calculus book will tell you that the derivative of a sine function is a cosine. (We don’t need to ask why at this point, but if you think back to the spinning wheel and the horizontal and vertical components of its movement, then it might make sense intuitively.) What does this mean? Well, that means that the slope of a sine wave at some value of x is equal to the cosine of the same value of x. This is written as is shown in Equation 1.90.
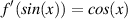 | (1.90) |
Just remember, if somebody walks up to you on the street and asks “what’s the derivative of the curve at x = 2?” what they’re saying is “what’s the slope of the curve at x = 2?”
If you want to calculate a derivative, then you can use the idea of a limit to do it. Think back a bit to when we were trying to find the tangent of a sine wave by plotting lines that crossed the sine wave at points closer and closer to the point we were interested in. Mathematically, what we were doing was finding the limit of the slope of the line, as the run between the two points approached 0. This is described in Equation 1.91
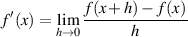 | (1.91) |
Huh? What Equation 1.91 says is that we’re looking for the value that the slope of the line drawn between two points separated in the x-axis by the value h approaches as h approaches 0. For example, in Figure 1.20, h = 1. In Figure 1.21, h = 0.5. Remember that h is just the “run” and f(x+h)-f(x) is just the rise of the triangle shown in those plots. As h approaches 0, the slope of the hypotenuse gets closer and closer to the answer that we’re looking for.
Just to make things really miserable, I’ll let you know that you can have beasts like the vicious double derivative written f′′(x). This just means that you’re looking for the slope of the slope of a function. So, we’ve already seen that the derivative of a sine function is a cosine function (or f′(sin(x)) = cos(x)), therefore the double derivative of a sine function is the derivative of a cosine function (or f′′(sin(x)) = f′(cos(x))). It just so happens that f′(cos(x)) = -sin(x), therefore f′′(sin(x)) = -sin(x).
A Σ (the Greek capital letter Sigma) in an equation is just a lazy way of writing “the sum of” whatever follows it. The stuff under and over it give you an indication of when to start and when to stop adding. Let’s look at a simple example shown in Equation 1.92...
 | (1.92) |
Equation 1.92 says “y equals the sum of all of the values of x from x = 1 to x = 10. The Σ sign says “add up everything from...” the “x = 1” at the bottom says where to start adding, the “10” on top says when to stop, and the “x” after the Σ tells you what you’re adding. So:
 | (1.93) |
This, of course, can get a little more complicated, as is shown in Equation 1.94 but if you don’t panic, it should be reasonably easy to figure out what you’re adding.
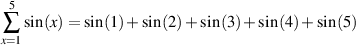 | (1.94) |
A Δ (a Greek capital Delta) means “the change in...” or “the difference in.” So, Δx means “the change in x.” This is useful if you’re looking at a value that’s changing like the speed of a car when you’re accelerating.
If I asked you to calculate the area of a rectangle with the dimensions 2 cm x 3 cm, you’d probably already know that you calculate this by multiplying the length by the width. Therefore 2 cm x 3 cm = 6 cm2 or 6 square centimeters.
If you were asked to calculate the area of a triangle, the math would be a little bit more complicated, but not much more.
What happens when you have to find the area of a more complicated shape that includes a curved side? That’s the problem we’re going to look at in this section.
Let’s look at the graph of the function y = sin(x) from x = 0 to x = π as is shown in Figure 1.22.
We’ve seen in the previous section how to express the equation for finding the slope of this function, but what if we wanted to find the area under the graph? How do we find this? Well, the way we found the slope was initially to break the curve into shorter and shorter straight line components. We’ll do basically the same thing here, but we’ll make rectangles by creating simplified slices of the area under the curve.
For example, compare Figure 1.22 to Figure 1.23. What we’ve done in the second
one is to consider the sine wave as 10 discrete values, and draw a rectangle for each. The
width of each rectangle is equal to 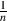 of the total length of the curve where n is the
number of rectangles. For example, in Figure 1.23, there are 10 rectangles (so
n = 10) in a total width of π (the length of the curve on the x-axis) so each
rectangle is
of the total length of the curve where n is the
number of rectangles. For example, in Figure 1.23, there are 10 rectangles (so
n = 10) in a total width of π (the length of the curve on the x-axis) so each
rectangle is  wide. The height of each rectangle is the value of the function
(in our case, sin(x) for the series of values of x,
wide. The height of each rectangle is the value of the function
(in our case, sin(x) for the series of values of x,  ,
, 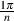 ,
,  , and so on up to
, and so on up to
 .
.
If we add the areas of these 10 rectangles together, we’ll get an approximation of the area under the curve. How do we express this mathematically? This is shown in Equation 1.95.
 | (1.95) |
What does this mess mean? Well, we already know that n is the number of
rectangles. The An on the left side of the equation means “the area contained in n
rectangles.” The right side of the equation says that we’re going to add up the product of
the sin of some changing number and 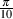 ten times (because the number under the ∑ is 1
and the number above is 10).
ten times (because the number under the ∑ is 1
and the number above is 10).
Therefore, Equation 1.95 written out the long way is shown in Equation 1.96
 | (1.96) |
Each component in this sum of ten components that are added together is the product
of the height (sin ) and width (
) and width ( ) of each rectangle. (All of those 10’s in there are
there because we have divided the shape into 10 rectangles.) Therefore, each component
is the area of a rectangle, which, when all added together give an approximation of the
area under the curve.
) of each rectangle. (All of those 10’s in there are
there because we have divided the shape into 10 rectangles.) Therefore, each component
is the area of a rectangle, which, when all added together give an approximation of the
area under the curve.
There is a general equation that describes the way we divided up the area called the Riemann Sum. This is the general method of cutting a shape into a number of rectangles to find an approximation of its area. If you want to learn about this, you’ll just have to look in a calculus textbook.
Using rectangular slices of the area under the curve gives you an approximation of that area. The more rectangles you use and the thinner they are, the better the approximation. As the number of rectangles approaches infinity, the approximation approaches the actual area under the curve.
There is a notation that says the same thing as Equation 1.95 but with an infinite number of rectangles. This is shown in Equation 1.97.
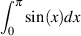 | (1.97) |
What does this weird notation mean? The simplified version is that you’re adding the areas of infinitely thin rectangles under the curve sin(x) from x = 0 to x = π. The 0 and π are indicated below and above the S-shaped ∫ sign.9 On the right side of the equation you’ll see a dx which means that’s it’s the x that’s changing from 0 to π.
This equation is called an integral which is just a fancy word for “the area under a function.” Essentially, just like “derivative” is another word for “slope,” “integral” is another word for “area.”
The general form of an integral is shown in Equation 1.98.
 | (1.98) |
Compare Equation 1.98 to Figure 1.27. What it’s saying is that the area A is equal to all of the vertical “slices” of the space under the curve f(x) from a to b. Each of these vertical slices has a width of dx. Essentially, dx has an infinitely small width (in other words, the width is 0) but there are an infinite number of the slices, so the whole thing adds up to a number.

Scientific notation is a method used to write very small or very big numbers without using up a lot of ink on the page. In order to write the number “one-million,” it is faster to write 106 than it is to write 1,000,000. If the number is “two-million,” then we just multiply the appropriate number – 2*106.
The same system is used for very small numbers. 0.00000035 is more easily written as 3.5*10-7.
A good trick to remember is that the exponent of the 10 shows you how far to move the decimal place to get the number. For example, 4.3*103 means that you just move the decimal three places to the right to make the number 4300. If the number is 8.94*10-5 you move the decimal five places to the left (negative exponents move to the left) making the number 0.0000894.
If you’d like to use scientific notation on your calculator, you use the button that’s marked “E” (on some calculators it’s marked “EXP”). So, 6*105 is entered by pressing 6 E 5.
Similarly, prefixes make our lives much easier by acting as built-in multipliers in our spoken numbers. It’s too difficult to talk about very short distances in meters – so we use millimeters. A large resistance is more easily expressed in kΩ than Ω.
| Prefix | Abbrev. | Normal | Computer |
| Multiplier | Multiplier | ||
| (Decimal) | (Binary) | ||
| atto- | a | 10-18 | |
| femto- | f | 10-15 | |
| pico- | p | 10-12 | |
| nano- | n | 10-9 | |
| micro- | μ | 10-6 | |
| milli- | m | 10-3 | |
| centi- | c | 10-2 | |
| deci- | d | 10-1 | |
| 1 | 1 | ||
| deca- | da | 101 | |
| hecto- | h | 102 | |
| kilo- | k | 103 | 210 |
| mega- | M | 106 | 220 |
| giga- | G | 109 | 230 |
| tera- | T | 1012 | 240 |
| peta- | P | 1015 | 250 |
So, for example, if you see something written in kilometers (abbreviated km), then you know that you must multiply the number you see by 103 to convert to metres. 5 km = 5 * 103 m = 5,000 m. If the unit is milligrams (mg), then you multiply by 10-3 to convert to grams (g). 15 mg = 15 * 10-3 g = 0.015 g.
If you’re dealing with computer memory, however, you use the other column in Table 1.6. A computer with 20 Gigabytes (GB) of hard disk space has 20 * 230 bytes = 21,474,836,480 bytes.
Note that, if the prefix denotes a multiplier that is less than 1, it starts with a small letter (i.e. milli- or m). If the multiplier is greater than one, then a capital letter is used (i.e. mega- and M). The odd exceptions to this case are those of deca- (da), hecto- (h), and kilo- (k). I don’t know why these are different, I guess somebody has to be...
Note 1: One of my favourite pet peeves is people who say kil-AH-muh-ters instead of KILL-o-meet-ers. This doesn’t bother me so much as it does amuse me, since the same people would never think of saying ”mil-LILL-lit-ters” instead of ”MILL-o-leet-ers” or ”mil-LIM-muh-ters” instead of ”MILL-luh-meet-ers”.
Note 2: Be careful with your capitalisation when you’re abbreviating. Sometimes, you’ll see someone write ”mb/s” to mean ”megabits per second” when they’re actually saying ”millibits per second” which is silly. A similar problem might occur with peta- and pico-, but neither is used as often as milli- or mega-... yet...
Note 3: There are those who claim that the power-of-two versions of these prefixes are abominations (or, at least, they ought to be...), but they’re in too-widespread use to eliminate them. They are not a part of the ISO 1000:1992 standard, which is why that was superceded by the ISO 80000-13:2008 standard.