Up to now in the book, we’ve been talking about physical characteristics of sound – things that can be measured with equipment. We haven’t thought about what happens from the instant a pressure wave in the air hits the side of your head to the moment you think “I wish that dog in the neighbour’s yard would stop barking” or “Won’t someone please answer that phone!?” This section is about exactly that – how does a change in air pressure get translated into you brain recognizing what and where the sound is and, even further, what you think about the sound.
This process is separable into three different fields of research:
It makes sense to think of these three in chronological order – that is to say, we can’t talk about how you perceive the sound until we know what sound is in your brain (psychoacoustics) and we can’t do that until we know what signal your brain is getting (physiological acoustics). Consequently, this chapter is loosely organized so that it deals with physiology, psychoacoustics and perception, in that order.
We have seen that sound is simply a change in air pressure over time, but we have not yet given much thought to how that sound is received and perceived by a human being. The changes in air pressure arrive at the side of your head at what we normally call your “ear.” That wrinkly flap of cartilage and skin on the side of your head is more precisely called your pinna (plural is pinnae). The pinna performs a very important role in that it causes the sound wave to reflect differently for sounds coming from different directions. We’ll talk more about this later.
The sound wave makes its way down the ear canal, a short tube that starts at the pinna and ends at your tympanic membrane, better known as your eardrum. The eardrum is a thin piece of tissue, about 10 mm in diameter, and is shaped a bit like a cone pointing towards inside your head. The eardrum moves back and forth depending on the relative pressures on either side of it. The pressure on the inside of the eardrum cannot change rapidly because your head is relatively sealed, somewhat like an omnidirectional microphone. So, if the pressure wave in the ear canal is high, then the eardrum is pushed into your head. If the pressure wave is low, then the eardrum is pulled out of your head.
Just like in the case of an omnidirectional microphone, there has to be some way of equalizing the pressure on the inside of the eardrum so that large changes in pressure over time (caused by changes in weather or altitude) don’t cause the it to get pushed too far in or out (this would hurt...). To equalize the pressure, you have to have a hole that connects the outside world to the inside of your head. This hole is a connection between the back of your mouth and the inside of your ear called the eustachian tube. When you undergo large changes in barometric pressure (like when you’re sitting in an airplane that’s taking off or landing) you open up your eustachian tube (by yawning) to relieve the pressure difference between the two sides of the eardrum.
We said above that the eardrum is cone-shaped. This is because it’s constantly being pulled inwards by the tensor tympani muscle which keeps it taut. The tension on the eardrum is regulated by that muscle – if a very loud sound hits the eardrum, the muscle tightens to make the eardrum more rigid, preventing it from moving as much, and therefore making the ear less sensitive to protect itself. This is also true when you shout.
Just on the inside of the eardrum are three small bones called the ossicles. The first of these bones, called the malleus (sometimes called the hammer) is connected to the eardrum and is pushed back and forth when the eardrum moves. This, in turn, causes the second bone, the incus (or anvil) to move which, in turn pushes and pulls the third bone, the stapes (or stirrup).
The stapes is a piston that pushes and pulls on a small piece of tissue called the fenestra ovalis (or oval window) which is a membrane that separates the middle ear from something called the cochlea. Looking at Figure 5.2, you’ll see that the cochlea looks a bit like a snail from the outside. On the inside, shown in Figure 5.3, it consists of three adjacent tubes called the perilymphatic ducts called the scala vestibuli, the scala media, and the scala tympani. Separating the scala tympani from the other two is a an important little piece of tissue called the basilar membrane.

When the oval window vibrates back and forth, it causes a pressure wave to travel in the fluid inside the cochlea (called the perilymph in the scala vestibuli and the scala tympani and the endolymph in the scala media), and down the length of the basilar membrane. Sitting on the basilar membrane are something like 30,000 very short hairs. At the end of the basilar membrane near the oval window, the hairs are shorter and stiffer than they are at the opposite end. These hairs can be considered to be tuned resonators: a pressure wave inside the cochlea at given frequency will cause specific hairs on the basilar membrane to vibrate. Different frequencies cause different hairs to resonate.
Just to give you an idea of how much these hairs are vibrating, if you’re listening to a sine wave at 1 kHz at the threshold of hearing, 20x10-6 Pa, the excursion of the hairs as they vibrate back and forth is much less than the diameter of a hydrogen atom. This is not very far...

To prevent standing waves inside the fluid in the cochlea, there is a second tissue called the fenestra rotunda (or round window) at the end of the scala tympani which, like the oval window, separates the middle air from the cochlea. The round window dissipates excess energy, preventing things from getting too loud inside the cochlea.

When the hair cells vibrate back and forth, they generate electrical impulses that are sent through the cochlear nerve to the brain. The brian decodes the pitch or frequency of the sound by determining which hair cells are moving at which location on the basilar membrane. The level of the sound is determined by how many hair cells are moving.
We have already seen that anything that changes a signal can be called a filter – this could mean a device that we normally call a filter (like a high pass filter or a low pass filter) or it could be the result of the combination of an acoustic signal with a reflection, or reverberation. We have also seen that the filter can be described by its transfer function – this doesn’t tell us how a filter does something, but it at least tells us what it does.
Let’s pretend that we have a perfect loudspeaker and a perfect microphone in a perfectly anechoic room exactly 1 m apart. If we do an impulse response measurement of this system, we’ll see a perfect impulse at the output of our microphone, meaning that it and the loudspeaker have perfectly flat frequency and phase responses. Now, we’ll take away the microphone and put you in its place so that you are facing the loudspeaker and that your eardrum is exactly where the microphone diaphragm used to be. If we could magically get an electrical output directly from your eardrum proportional to its excursion, then we could make another impulse response measurement of the signal that arrives at your eardrum. If we could do that, we would see a measurement that looks something very similar to Figure 5.6
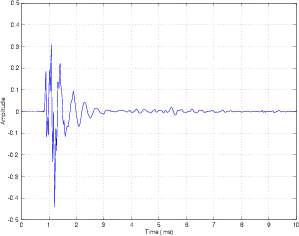
You will notice that this is not a perfect impulse, and there are a number of reasons for this. Remember that in between the sound source and your eardrum there are a number of obstructions that cause reflections and absorption. These obstructions include shadowing and boundary effects of the head, reflections off the the pinna and shoulders, and resonance in the ear canal. The signal that reaches your eardrum includes all of the effects caused by these components and more.
The combination of these effects changes with different locations of the sound source (measured by its rotation and its azimuth) and different orientations of the head. The result is that your physical body creates different filter effects for different relationships between the location of the sound source and your two ears. Also, remember that, unless the sound source is on the median plane (see Figure 5.7), then the signals arriving at your two ears will be different.
If we consider the effect of the body on the signal arriving from a given direction and with a given head rotation as a filter, then we can measure the transfer function of that filter. This measurement is called a head-related transfer function or HRTF. Note that typically, an HRTF typically includes the effects of reflections off the shoulders and body and therefore are not just the transfer function of the effects of the head itself.
www.howstuffworks.com
Our ability to perceive things using any of our senses is limited by two things:
Physical limitations determine the absolute boundaries of range for things like hearing and sight. For example, there is some maximum frequency (which may or may not be something about 20 kHz, depending on who you ask and how old your are...) above which we cannot hear sound. This ceiling is set by the physical construction of the ear and its internal components.
The brain’s ability to process information is a little tougher to analyze. For example, we’ll talk about a thing called “psychoacoustic masking” which basically says that if you are presented with a loud sound and a soft sound simultaneously, you won’t “hear” the soft sound (for example, if I whisper something to you at a Motorhead concert, chances are you won’t know that I exist...). Your ear is actually receiving both sounds, but your brain is ignoring one of them.
We said earlier that the limits on human frequency response are about 20 Hz in the low frequency range and 20 kHz in the upper end. This has been disputed recently by some people who say that, even though tests show that you cannot hear a single sine wave at, say, 25 kHz, you are able to perceive the effects a 25 kHz harmonic would have on the timbre of a violin. This subject provides audio people with something to argue about when they’ve agreed about everything else...
It’s also important to point out that your hearing doesn’t have a flat frequency response from 20 Hz up to 20 kHz and then stop at 20,001 Hz... As we’ll see later, it’s actually a little more complicated than that.
The dynamic range of your hearing is determined by two limits called the threshold of hearing and the threshold of pain.
The threshold of hearing is the quietest sound that you are able to hear, specified at 1 kHz. This value is 20 μPa or 20*10-6 Pascals. Just to give you an idea of how quiet this is, the sound of blood rushing in your head is louder to you than this. Also, at 20 μPa of sound pressure level, the hair cells inside your inner ear are moving back and forth with a total peak-to-peak displacement that is much less than the diameter of a hydrogen atom [].
Note that the reference for calculating sound pressure level in dBspl is 20 μPa, therefore, a 1 kHz sine tone at the threshold of hearing has a level of 0 dBspl.
One important thing to remember is that the threshold of hearing is not the same sound pressure level at all frequencies, but we’ll talk about this later.
The threshold of pain is a sound pressure level that is so loud that it causes you to be in pain. This level is somewhere around 200 Pa, depending on which book you read, how masochistic you are and how often you go clubbing. This means that the threshold of pain is around 140 dBspl. This is very loud.
So, based on these two numbers, we can calculate that the human hearing system has a total dynamic range (the difference between the maximum – the threshold of pain – and the minimum –the threshold of hearing) of about 140 dB.
In the previous chapter, we said that the threshold of hearing at 1 kHz is 20 μPa or 0 dBspl. If a sine tone is quieter than this, you will not hear it. If you tried to find the threshold of hearing for a frequency lower than 1 kHz, you would find that it’s higher than 20 μPa. In other words, in order to hear a tone at 100 Hz, it will have to be louder than 0 dBspl – in fact, it will be about 25 dBspl. So, in order for a 100 Hz tone to sound the same level as a 1 kHz tone, the 100 Hz tone will have to be higher in measurable level.
Take a look at the red curve in Figure 5.8. This line shows you the threshold of hearing for different frequencies. There are a couple of important characteristics to notice here. Firstly, notice that frequencies higher lower than 1 kHz and higher than about 5 kHz must be higher than 0 dBspl in order to be audible. Secondly, for frequencies lower than 100 kHz, the lower in frequency, the higher the threshold. Thirdly, for frequencies higher than 5 kHz, the higher the frequency the higher the threshold. Finally, notice that there is a dip in the threshold of hearing between 2 kHz and 5 kHz. This means that you are able to hear frequencies in this range even if they are lower than 0 dBspl. This frequency band in which our hearing is most sensitive is an interesting area for two reasons. Firstly, the bulk of our speech (specifically consonant sounds) relies on information in this frequency range (although it’s likely that the speech evolved to capitalize on the sensitive frequency range). Secondly, the anthropologically-minded will be interested to note that the sound of a snapping twig has lots of information which is smack in the middle of the 2 kHz – 5 kHz range. This is a useful characteristic when you look like lunch to a large-toothed animal that’s sneaking up behind you...
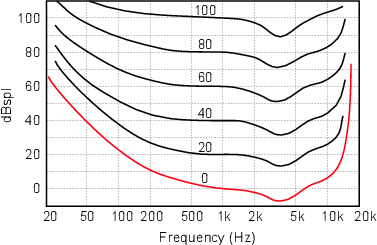
One interesting thing to note here is that points along the red curve in this graph all indicate the threshold of hearing, meaning that two sinusoidal tones with sound pressure level indicated by the curve will appear to us to be the same level, even though they aren’t in reality. For example, looking at Figure 5.8, we can see that a tone at 50 Hz and a sound pressure level of 40 dBspl will be on the threshold of hearing, as will a 1 kHz tone at 0 dBspl and a 10 kHz tone at about 5 dBspl. These three tones at these levels will have the same perceived level – they will appear to have equal loudness.
The point that I’m making here is that, if you change the frequency of a sinusoidal tone, you’ll have to change the sound pressure level to keep the perceived level the same. This is true even if you’re not at the threshold of hearing. Take a look at the remaining curves in Figure 5.8. For example, look at the curve that intersects 1 kHz at 20 dBspl. You’ll see that this curve also intersects 100 Hz at about 38 dBspl. This indicates that, in order for a 1 kHz tone at 20 dBspl to sound the same perceived loudness as a 100 Hz tone, the lower frequency will have to be about 38 dBspl. Consequently, the curve that we’re looking at is called an equal loudness contour – it tells us what the actual levels of multiple tones have to be in order to have the same apparent level.
These curves were first documented in 1933, by a couple of researchers by the names of Fletcher and Munson [Fletcher and Munson, 1933]. Consequently, the equal loudness contours are sometimes called the Fletcher and Munson Curves. They were verified and updated in 1956 by Robinson and Dadson [Robinson and Dadson, 1956].
Notice that the curves tend to flatten out when the level goes up. What does this mean? Firstly, when you turn down your stereo, you are less sensitive to low and high frequencies (compared to the mid-range frequencies) than when the stereo was turned up. Therefore the timbral balance changes, particularly in the low end. If the level is low, then you’ll think that you hear less bass. This is why there’s a loudness switch on your stereo. It boosts the bass to compensate for your low-level equal loudness curves. Secondly, things simply sound better when they’re louder. This is because there’s a “better balance” in your hearing perception than when they’re at a lower level. This is why the salesperson at the stereo store will crank up the volume when you’re buying speakers... they sound good that way because a higher level means you hear more bass.
SOME INFORMATION TO GO HERE ABOUT dB HEARING LEVEL, WHAT IT MEANS AND HOW IT WAS CREATED.
| Frequency (Hz) | dB SPL | dB HL |
| 250 | 15.0 | 0.0 |
| 500 | 9.0 | 0.0 |
| 1000 | 3.0 | 0.0 |
| 2000 | -3.0 | 0.0 |
| 4000 | -4.0 | 0.0 |
| 8000 | 13.0 | 0.0 |
Most of the world measures things in dBspl. This is a good thing because it’s a valid measurement of pressure referenced to some fixed amount of pressure. As Fletcher and Munson discovered, though, those numbers have fairly little to do with how loud things sound to us. So someone decided that it would be a really good idea to come up with a system which was related to dBspl but “fixed” according to how we perceive things.
The system they came up with measures the amplitude of sounds in something called phons. 1
Here’s how to find a value in phons for a given measured amplitude.
The idea is that all sounds along a single equal loudness contour have the same apparent loudness level, and therefore are given the same value in phons. If you look at Figure 5.8 you’ll notice that the black curves are numbered. These numbers match the value of the curve where it intersects 1 kHz, consequently, they indicate the value of a frequency in phons if you know the value in dBspl. For example, if you have a sinusoidal tone at 100 Hz and a level of 70 dBspl, it’s on the 60 phon curve. Therefore that tone will sound the same loudness as a 1 kHz sinuoidal tone with a level of 60 dBspl. Since all the points on this curve will sound the same loudness to us, the curves are called equal loudness contours.
Let’s say that you’re hired to go measure the level of background noise in an office building. So, you wait until everyone has gone home, you set up your band-new and very expensive sound pressure level meter and you’ll find out that the noise level is really high – something like 90 dBspl or more.
This is a very strange number, because it doesn’t sound like the background noise is 90 dBspl... so why is the meter giving you such a high number? The answer lies in the quality of your meter’s microphone. Basically, the meter can hear better than you can – particularly at very low frequencies. You see, the air conditioning system in an office building makes a lot of noise at very low frequencies, but as we saw earlier, you aren’t very good at hearing very low frequencies.
The result is that the sound pressure level meter is giving you a very accurate reading, but it’s pretty useless at representing what you hear. So, how do we fix this? Easy! We just make the meter’s “hearing” as bad as yours.
So, what we have to do is to introduce a filter in between the microphone output and the measuring part of the meter. This filter should simulate your hearing abilities.
There’s a problem, however. As we saw in Section 5.4, the “EQ curve” of your hearing changes with level. Remember, the louder the sound, the flatter your personal frequency response. This means that we’re going to need a different filter in our sound pressure level meter according to the sound pressure of the signal that we’re measuring.
The filter that we use to simulate human hearing is called a weighting filter (sometimes called a weighting network) because it applies different weights (or levels of importance) to different frequencies. The frequency response characteristics of the filter is usually called a weighting curve.
There are three standard weighting curves, although we typically only use two of them in most situations. These three curves are shown in Figure 5.9 and are called the A-weighting, B-weighting, and C-weighting curves.
These curves show the frequency response characteristics of the three weighting filters. The question then is, how do you know which filter to use for a given measurement? As you can see in Figure 5.9, the A-weighting curve has the most attenuation in the low and high frequency bands. Therefore, of the three, it most closely matches your hearing at low levels. The B- and C-weighting curves have less attenuation in high frequencies than the A-weighting curve. The B-weighting curve has more attenuation in the low frequencies than the C-curve. Therefore, if your measuring a sound with a higher sound pressure level, you use the B-weighting curve. Even higher sound pressure levels require the C-weighting curve. Table 5.2 shows a list of suggestions for which weighting curve to use based on the sound pressure level.
| Sound Level | Weighting |
| Range (dBspl) | Network |
| 20 – 55 | A |
| 55 – 85 | B |
| 85 – 140 | C |
Notice that the A-weighting curve has a great deal of attenuation in the low and high frequencies. Therefore, if you have a piece of equipment that is noisy, and you want to make its specifications look better than they really are, you can use an A-weighting curve to reduce the noise level. Manufacturers who want to make their gear have better specifications will use an A-weighting curve to improve the looks of their noise specifications.
You may also see instances where people use an A-weighting curve to measure acoustical noise floors even when the sound pressure level of the noise is much higher than 55 dBspl. This really doesn’t make much sense, since the frequency response of your hearing is better than an A-weighting filter at higher levels. Again, this is used to make you believe that things aren’t as loud as they appear to be.
Take a noise signal with a white spectrum and band-limit it with a filter that has a centre frequency of 2 kHz. Play that noise at the same time as you play a sinusoidal tone at 2 kHz and make the tone very quiet relative to the noise. You will not be able to detect the tone because the noise signal will mask it (“mask” is a psychoacoustician’s fancy word that means “drowns out” in everyday speech). This is true even if you would normally be able to hear the tone if the noise wasn’t there. It’s because of the noise that you can’t hear the tone. Now, turn up the level of the tone until you can hear it and write down its level (if there was no masking noise) in dBspl.
Increase the bandwidth of the noise signal (but do not turn up its level) and repeat the experiment. You’ll find that your threshold for detection of the tone will be higher. In other words, if the bandwidth of the masking signal is increased, you have to turn up the tone more in order to be able to hear it.
Increase the bandwidth and do the experiment again. Then do it again. If you keep doing this, you’ll notice that something interesting will happen. As you increase the bandwidth of the masker, the threshold for detection of the tone will increase up to a certain bandwidth. Then it won’t increase any more. This is illustrated in Figure 5.10.
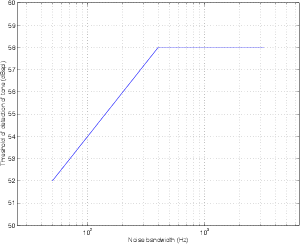
This means that, for a given frequency, once you get far enough away in frequency, the noise does not contribute to the masking of the tone. (As an example, take an extreme case: you cannot mask a tone at 100 Hz with noise centered at 10 kHz.) The tone can only be masked by signals that are near it in frequency – anything outside that frequency range is irrelevant.
The bandwidth at which the threshold for the detection of the tone stops increasing is called the critical bandwidth. So, in the case of the 2 kHz tone illustrated in Figure 5.10, the critical bandwidth is 400 Hz.
If noise outside the critical bandwidth does not help to mask the tone, then we can assume that the auditory system is like a number of bandpass filters connected in parallel. If a tone and a noise are in the same filter (called an auditory filter), then the noise will contribute to the masking of the tone. If they are in different filters, then the noise cannot mask the tone. The width of these filters is measurable for any given centre frequency using the technique described above for measuring critical bandwidth. Consequently, these filters are called critical bands.
So far, we have been talking about a tone being masked by a noise band where the tone has the same frequency as the centre frequency of the masking noise. Let’s look at what happens if we change the frequency of the tone.
Figure 5.11 shows your threshold of hearing contour when you’re in a very quiet environment. As we saw above, if white noise is played, band limited to a critical bandwidth with a centre frequency of 1 kHz, it will mask a 1 kHz tone. In other words, we can say that the threshold of detection of the tone is raised by the masking noise. However, that noise will also be able to mask a tone at other frequencies. The further you get from the centre frequency of the masking noise, the lower the threshold of detection until, if the tone’s frequency is outside the critical band, the threshold of detection is the threshold of hearing.
We can therefore think of a masking noise as raising the threshold of hearing in an area around its centre frequency. Figure 5.12 shows the change in the threshold of detection caused by a masking noise with a centre frequency of 1 kHz and an level of 60 dBspl. As you can see, that threshold is not raised at only 1 kHz, but at surrounding frequencies.

As we discussed earlier, the amount that a masking noise will change the threshold of detection of a tone at its centre frequency depends on the bandwidth of the noise. It is also probably obvious that it will be dependent on the level of the masking noise. Figure 5.13 shows the change in the threshold of detection caused by a masking noise with a bandwidth equal to the critical bandwidth with a centre frequency of 1 kHz and various levels.

Note that everything we’ve discussed in this chapter is known as simultaneous masking – meaning that the masking noise and the tone are presented to the listener simultaneously. You should also know that forwards masking (where the masking noise comes before the tone) and backwards masking (where the masking noise comes after the tone) exist as well. For more information on this, read [Moore, 1989] and [Zwicker and Fastl, 1999].
How do you localize sound? For example, if you close your eyes and you hear a sound and you point and say “the sound came from over there,” how did you know? And, how good are you at doing this?
Well, you have two general things to sort out
We determine the direction of the sound using a couple of basic components that rely on the fact that we have two ears
The first thing you rely on is the interaural time difference2 (or ITD) of the sound. If the right ear hears the sound first, then the sound is on your right, if the left ear hears the sound first, then the sound is on your left. If the two ears get the sound simultaneously, then the sound is directly ahead, or above, or below or behind you.
The next thing you rely on is the interaural amplitude difference (or IAD). If the sound is louder in the right ear, then the sound is probably on your right. Interestingly, if the sound is louder in your right ear, but arrives in your left ear first, then your brain decides that the interaural time of arrival is the more important cue and basically ignores the amplitude information.
You also have these things sticking out of your head which most people call their ears but are really called your pinnae. These things bounce sound around inside them differently depending on which direction the sound is coming from. They tend to block really high frequencies coming from the rear (because they stick out a bit...) so rear sources sound “darker” than front sources. These are of a little more help when you turn your head back and forth a bit (which you do involuntarily anyway).
A long time ago, a guy named Lord Rayleigh wrote a book called “The Theory of Sound”[Rayleigh, 1945a][Rayleigh, 1945b] in which he said that the brain uses the phase difference of low frequencies to sort out where things are, whereas for high frequencies, the amplitude differences between the two ears are used. This is a pretty good estimation, although there’s a couple of people by the names of Wightman and Kistler that have been doing a lot of research in the matter.
Exactly how good are you at the localization of sound sources? Well, if the sound is in front of you, you’ll be accurate to within about 2∘ or so. If the sound is directly to one side, you’ll be up to about 7∘ off, and if the sound is above you, you’re really bad at it... typical errors for localizing sources above your head are about 14∘ – 20∘[Blauert, 1997].
Why? Well, probably because, anthropologically speaking, more stuff was attacking from the ground than from the sky. You’re better equipped if you can hear where the sabre-toothed tiger is rather than the large now-extinct human-eating flying penguin...
If you play a sound for someone on one side of their head and asked them to point at the direction of the sound source, they would typically point in the wrong direction, but be pointing in the correct angle. That is, if the sound is 5∘ off-centre in the front, some people will point 5∘ off-centre in the back, Some people will point 5∘ above centre and so on. If you made a diagram of the incorrect (and correct) guesses, you’d wind up drawing a cone sticking out of the test subject’s ear. This is called the cone of confusion.
INCLUDE A DRAWING OF THE CONE OF CONFUSION
Stand about 10 m from a large flat wall outdoors and clap your hands. You should hear an echo. It’ll be pretty close behind the clap (in fact it ought to be about 60 ms behind the clap...) but it’s late enough that you can hear it. Now, go closer to the wall, and keep clapping as you go. How close will you be when you can no longer hear a distinct echo? (not one that goes “echo........echo” but one that at least appears to have a sound coming from the wall which is separate from the one at your hands...)
It turns out that you’ll be about 5 m away. You see, there is this small time window of about 30 ms or so where, if the echo is outside the window, you hear it as a distinct sound all to itself; if the echo is within the window, you hear it as a component of the direct sound.
It also turns out that you have a predisposition to hear the direction of the combined sound as originating near the earlier of the two sounds when they’re less than 30 ms apart.
This localization tendency is called the precedence effect or the Haas effect or the law of the first wavefront [Blauert, 1997].
Okay, okay so I’ve oversimplified a bit. Let’s be a little more specific. The actual time window is dependent on the signal. For very transient sounds, the window is much shorter than for sustained sounds. For example, you’re more likely to hear a distinct echo of a xylophone than a quacking duck. (And, in case you’re wondering, a duck’s quack does echo [Cox, 2003]...) So the upper limit of the Haas window is between 5 ms and 40 ms, depending on the signal.
When the reflection is within the Haas window, you tend to hear the location of the sound source as being in the direction of the first sound that arrives. In fact, this is why the effect is called the precedence effect, because the preceding sound is perceived as the important one. This is only true if the reflection is not much louder than the direct sound. If the reflection is more than about 10 – 15 dB louder than the direct sound, then you will perceive the sound as coming from the direction of the reflection instead[Moore, 1989]
Also, if the delay time is very short (less than about 1 ms), then you will perceive the reflection as having a timbral effect known as a comb filter (explained in Section 3.2.4). Also, if the two sounds arrive within 1 ms of each other, you will confuse the location of the sound source and think that it’s somewhere between the direction of the direct sound and the reflection (a phenomenon known as summing localization)[Blauert, 1997]. This is basically how stereo panning works.
Go outdoors, close your eyes and stand there and listen for a while. Pay attention to how far away things sound and try not to be distracted by how far away you know that they are. Chances are that you’ll start noticing that everything sounds really close. You can tell what direction things are coming from, but you won’t really know how far away they are. This is because you probably aren’t getting enough information to tell you the distance to the sound source. So, the question becomes, “what are the cues that you need to determine the distance to the sound source?”
There are a number of cues that we rely on to figure out how far away a sound source is. These are, in no particular order...
One of the most important cues that you get when it comes to determining the distance to a sound source lies in the pattern of reflections that arrive after the direct sound. Both the level and time of arrival relationships between these reflections and the direct sound tell you not only how far away the sound source is, but where it is located relative to walls around you, and how big the room is.
Go to an anechoic chamber (or a frozen pond with snow on it...). Take a couple of speakers and put them directly in front of you, aimed at your head with one about 2 m away and the other 4 m distant. Then, make the two speakers the same apparent level at your listening position using the amplifier gains. If you switch back and forth between the two speakers you will not be able to tell which is which – this is because the lack of reflections in the anechoic chamber rob you of your only cues that give you this information.
Anyone who has used a digital reverberation unit knows that the way to make things sound farther away in the mix is to increase the level of the reverb relative to the dry sound. This is essentially creating the same effect we have in real life. We’ve seen earlier that, as you get farther and farther away from a sound source in a room, the direct sound gets quieter and quieter, but the energy from the room’s reflections – the reverberation – stays the same. Therefore the direct-to-reverberant level ratio gets smaller and smaller.
MAKE SURE THAT CRITICAL DISTANCE IS COVERED IN ROOM ACOUSTICS CHAPTER
If you know how loud the sound source is normally, then you can tell how far away it is based on how loud it is. This is particularly true of sound sources with which we are very familiar like human speech, for example.
Of course, if you have never heard the sound before, or if you really don’t know how loud it is (like the sound of thunder, for example) then the sound’s loudness won’t help you tell how far away it is.
As we saw in Section 3.2.3, air has a tendency to absorb high-frequency information. Over short distances, this absorption is minimal, and therefore not detectable by humans. However, over long distances, the absorption becomes significant enough for us to hear the difference. Of course, we are again assuming that we are familiar with the sound source. If you don’t know the normal frequency balance of the sound, then you won’t know that the high end has been rolled off due to distance.
Once upon a time, it was easy to determine whether one piece of audio gear was better than another. All that was required was to do a couple of measurements like the frequency response and the THD+N. Whichever of the two pieces of gear measured the best, won. Then, one day, someone invented perceptual coding (see Section 8.10). Suddenly we entered a new era where an algorithm that measured horribly with standard measurement techniques sounded fine. So, the big question became “how do we tell which algorithm is better than another if we can’t measure it?” The answer: listening tests!
Of course, listening tests were done long before codec’s were tested. People were testing things like equal loudness contours for decades before that... However, generally speaking, that area was confined to physiologists and physiologists – not audio engineers and gear developers. So, today, you need to know how to run a real listening test, even if you’re not a psychoacoustician.
This, short and intentionally distorted history lesson illustrates an important point that I want to make here regarding the question of exactly what it is that you’re intending to find out when you do a listening test. Many people will say that they’re doing “subjective testing” which may not be what they’re actually doing.
Option 1: You’re interested in testing the physical limits of human hearing. For example, you want to test someone’s threshold of hearing at different frequencies, or limits of frequency range at different sound pressure levels, or just noticeable differences of loudness perception. These kinds of measurements of a human hearing system are typically not what people are talking about when the words “listening test” are used.
Option 2: You’re interested in testing how sounds are perceived. For example, you want to test whether people perceive a mono signal produced by two stereo speakers differently than a stereo signal from the same speakers. Almost everyone will agree that these two stimuli sound different. We might even agree on which is wider, or more spacious, or more distant, or more boomy... we can test for various descriptions and see if people agree on the differences in the two stimuli.
Option 3: You’re interested in what people like – or maybe what they think is ‘better’ or ‘worse’ – or maybe just what their preference is.
As we’ll see in the next section, all of these options require that you do a listening test, but only one of them requires a subjective test...
In 1999, Carsten Fog and Torben Holm Pedersen from Delta Acoustics in Denmark published a paper describing what they call the filter model of the perception of sound quality [Fog and Pedersen, 1999]. This model is an excellent way of describing how sound is translated by the nervous system, and how that is, in turn, translated into a judgment of quality or preference by your cognition. These two translation systems are described as “filters” which convert one set of descriptions of the sound into another. This is shown in Figure 5.14.

In the far left side of Figure 5.14 we can see that the initial description of the sound is a physical one. This can be as simple as recording of the sound, an equation describing it (as in the case of a sinusoidal waveform, for example) or a set of measurements on the signal (i.e. frequency response, THD+N etc...). In a perfect world, this would tell us everything there is to know about how we perceive the sound to be, but in reality this is very far from the case. For example, I could tell you that my loudspeakers have a frequency response from 20 Hz to 20 kHz ±0.001 dB and you’ll probably think that they’re good. However, if their THD is 50%, you might think that they’re not so good after all.
So, the sound comes out of the gear, through the ear and reaches our eardrums. That signal gets to the brain and is immediately processed into perceptual attributes. These are descriptions like “bright” and “dark” or “narrow” and “wide.” These perceptual attributes are pretty constant from listener to listener. We can both agree that this sound is wider than that one (whether we prefer one or the other comes later). (An good example of this is if we do a taste test. We can say that one cup of coffee tastes sweeter than another. We’ll both agree on which one is sweeter – but that doesn’t mean that we’ll agree on which one is better...) So, Filter 1 in the model is our sensory perception – this translates technical descriptions of the sound hitting our eardrums into concepts that normal people can understand. Note that this filter actually contains at least two components – the first is the limitations of our hearing system itself. Maybe you can’t hear a 40 kHz tone, so you never perceive it. The second component is the translation into the perceptual attributes.
Then we get to the far right side of the model. This is where you make your hedonic (as in “hedonism” – the pursuit of pleasure of the senses) or affective judgment of the sound. You decide whether you like the sound or not – or whether you like it more than another sound. The filter that is used to translate the perceptual attributes into preference (your subjective evaluation of the stimulus). Going back to the coffee example, we’ll both agree that one cup of coffee is sweeter than the other, but we might disagree on which one each of us prefers.
So, from this model, we can see that we can make an objective measurement of a perceptual attribute. If you do a test where you live using your group of subjects, and I do a test where I live on my group of subjects, and we both use the same stimuli, we’ll get the same results from our evaluation of the perceptual attributes. Both groups will independently agree that 3 spoonfuls of sugar in a cup of coffee makes it sweeter than having none. However, if we do a subjective test (“Which of these two cups of coffee do you prefer?”) we might get very different results – particularly if you have a group made of Greek vari glykos drinkers and Danes (my experience in Denmark is that many people don’t even bother putting cream and sugar on the table when they serve coffee because almost everyone drinks it black).
So, be careful when you talk about doing subjective testing – or at least make sure that you mean “subjective testing” when you use that phrase.
When you’re designing a listening test, you have two types of variables to worry about independent variables and dependent variables. What’s the difference?
An independent variable is the thing that you (the experimenter) are changing during the test. For example, let’s say that you are testing how people rate the quality of MP3 encoded sounds. You want to find out whether one bitrate sounds better than another, so you take a single original sound file and you encode it at different bitrates. The test subject is then asked to compare one sound (with one bitrate) against another (with a different bitrate). The independent variable in this case is the bitrate of the signal. Note that it’s independent because it has nothing to do with the subject – the bitrate would be the same whether the subject listened to the sounds or not.
A dependent variable is the thing that you’re measuring in the subject’s responses. In the example test in the previous paragraph, the dependent variable is the subjects’ judgment of the quality of the sound. The variable is dependent on the subject – if the subject never hears the sounds, they can’t make a judgment on the quality.
Here’s another example. Do a test where you have people taste two cups of coffee. One cup of coffee has no sugar in it. The other cup has 2 spoonfuls of sugar. You ask the people to rate the sweetness of each cup of coffee. In this test, the amount of sugar in each cup is the independent variable. The perception of sweetness is the dependent variable.
Let’s do a taste test to see how detectable sugar is in a cup of coffee. First, you’ll need to make a pot of coffee. Pour the coffee into 101 cups (hope you made a big pot...). In the first cup, don’t add any sugar. Put 1 mg of sugar in the second cup, 2 mg of sugar in the third cup, and so on until you get 100 mg (about 21 teaspoons) of sugar in the 101st cup.
Now let’s design the test. We’ll give each subject two cups of coffee, one without sugar, and the second with some amount of sugar between 1 and 100 mg. The question to the subject will be ”which of these two cups of coffee is the one with sugar in it?” Then we’ll give the subject another two cups of coffee (one without sugar and one with) and ask the question again. We’ll do this again and again, making sure to repeat pairs of cups of coffee to check the answers.
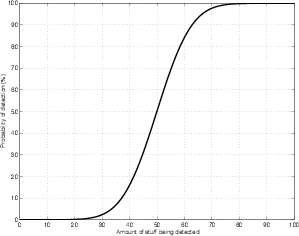
Once the taste test is over, we’ll see that, if there is just a very small amount of sugar in the coffee, people will just be guessing as to which cup has the sugar in it. If there is a large amount of sugar in the coffee, everyone will get the right answer. If the amount of sugar in the coffee is somewhere in between, then some people will get it right, some will get it wrong. Or, another way to think of it is that a single person will have a reduced probability of getting the right answer when they’re asked. They won’t be guessing completely, but they won’t get it right every time either...
If we were to make a graph to show this behaviour, it would look like Figure 5.15. This graph shows the number of subjects that, on average, got the correct answer on our taste test plotted against the amount of sugar in the second cup of coffee. If there is no sugar in the coffee, everyone will be guessing. If there is a lot of sugar in the coffee 100% of the answers will be correct. The shape of this graph has a specific shape and is called the psychometric function.
If you test enough people, asking them to detect any change in a stimulus, you’ll get this same shape of curve every time. This is because it’s directly dependent on a standard normal distribution which describes everybody... This is shown in Figure 5.16.
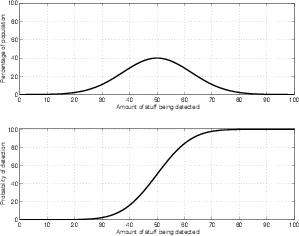
Let’s say, for example, that we’re asking people to detect sugar in coffee. If you add 1 mg of sugar in the cup, almost nobody will be able to detect that sugar has been added. The top plot in Figure 5.16 shows this – for a small amount of sugar, you get almost no one being able to detect it. As you add more and more sugar, you get to a point where you’re at the threshold of detection for the most people, and therefore you get a peak in the graph. There are some people with a very poor sense of taste, and they will require much more sugar in the coffee before they detect it. However, this type of person is rare, therefore, for large quantities of sugar, you get a small percentage of the population on the Y-axis. The result is a standard normal distribution – better known as a bell curve.
This bell curve tells us the relationship between a given amount of sugar and the threshold of detection. So, for example, using that top plot in Figure 5.16, we can see that 40% of the population has a threshold of detection of 50 mg of sugar (remember that these are completely hypothetical values – I didn’t really do this test...). Some people have a lower threshold, and some people have a higher threshold.
This particular piece of information isn’t really that useful to us. A more interesting question is “If I put 50 mg of sugar in the coffee, how many people will detect it?” This means that we’re looking for the people whose threshold of detection is 50 mg or less – not just 50 mg. This number of people can be found by looking at the area under the bell curve up to and including the value for 50 mg. Since the bell curve is symmetrical, and since its peak is at 50 mg of sugar in our graph, then the area under it on the left of that value must be 50% of the total area under the graph. As we go higher and higher on the X-axis, we include a higher and higher percentage of the total area under the graph. The bottom plot in Figure 5.16 shows exactly this – it’s the area under the top plot to the left of a given value on the X-axis expressed as a percentage of the total area under the graph. This is the psychometric function.

Let’s design a test to see how loud two different sounds are perceived to be. We could do this in two general ways, using either direct scaling or indirect scaling.
If we use direct scaling, then we play the first sound for the test subject and ask them to rate how loud it is on a scale (say, from 0 to 10). Then we play the next sound and ask them to rate that one. In this case, we are directly asking the subject to tell us how loud each sound is. We can then compare the two answers to see whether one sound is louder than the other. Or, we could see if two people rate the same sound with the same perceived loudness.
A different way to do this test would be to play one sound, then the other and ask “which is the louder of the two sounds?” In this way, we find out whether one sound is louder than the other indirectly. We are not asking “how loud is it” – we are asking ”which one is louder” and figuring out later how loud they are by using the results. This is called indirect scaling because we’re not directly asking the subject for the answer for which we’re looking.
Typically, when people who don’t do listening tests (or perceptual tests in general) for a living talk about listening tests, they mean a hedonic listening test. What they’re usually interested in is which product people prefer – because they’re interested in selling more of something. So, in a hedonic test, you’re trying to find out what people like, or what they prefer. If I put a Burger King Whopper and a McDonald’s Big Mac in front of you, which one would you prefer to eat (assuming that you are able to eat at least one of them...)?
A second question after “which one do you prefer” is “how much more do you you like it?” This allows the greedy bean counters to set pricing levels. If you like a Whopper two times as much as a Big Mac, then you’ll pay two times more for it. This makes the accountants at Burger King happy.
Unfortunately, doing a hedonic test is not easy. Let’s say that you’re comparing two brands of loudspeakers. Your subjects must not, under any circumstances, know what they’re listening to – they can’t know the brands of the speakers, they shouldn’t even be able to see empty speaker boxes on the way into the listening room. This will distort their response. In other words, it absolutely must be a blind test – where the subject knows nothing about what it is that you’re testing, they can’t even be allowed to think they know what you’re testing.
Also, you have to make sure that, apart from the independent variable, all other aspects of the comparison are equal. For example, if you were testing preference for amount of sugar in coffee by giving people coffee cup “A” with 1 teaspoon of sugar compared to cup “B” with no sugar, you have to make sure that the coffee in both cups is the same brand of coffee, they’re both the same temperature, the two mugs look and feel identical etc. etc... If there are any differences other than the independent variable(s) then you will never know what you tested. If you’re testing loudspeakers, you have to ensure that both pairs of speakers play at the same output level, and that they’re in exactly the same location in the room, otherwise, you might be comparing the subject’s preference for loudness, or room placement, for example.
The danger with hedonic testing is that the results are almost always multidimensional. This means that your decision as to whether you prefer or like something is dependent on more than one thing. For example, if we do a “how much do your like it” test for loudspeakers, your answers will be dependent on the music that’s used in the test. If you hate the music, you might like the speakers less. If your boyfriend broke up with you or your dog died the day before the test, you might like the speakers less (unless you hated your boyfriend and your dog, in which case, your might like the speakers more...). Think of the implications of doing a taste test on beer using a subject with a hangover – you probably won’t be able to trust the results of that test...
Everyone who does the test will have a different opinion about how much they like what’s being tested, and you may not be able to figure out what attribute of the things being tested contribute to the person liking something or not, because it’s possible that the reason they like it or not might have nothing to do with anything you know about what’s being tested. Of course, you also have to consider that different people have different preferences. I like coffee with cream and sugar. Other people prefer it black.
For this reason, you have to use a very large group of subjects when you do a hedonic test. It’s not unusual to require something on the order of hundreds of people doing the test until you can get some reliable data that indicates what the general population will think about what you’re testing.
Usually, but not always, non-hedonic tests (where the subject is asked to grade an aspect of the sound and you don’t care whether he or she likes or prefers it) are a little easier to design. Again, you must be absolutely certain that, if you’re comparing stimuli, the only differences between them are the independent variables. For example, if you’re testing perception of image width with a centre speaker vs. a phantom centre, you must ensure that the two stimuli are the same loudness, since loudness might affect the perception of image width.
Often, one of the big problems with doing a non-hedonic test is that you have to be absolutely certain that the subject understands the question you’re asking them. For example, if you’re testing sweetness of coffee, you give the subject 5 cups of coffee, each with a different amount of sugar, and you ask them to rank the cups from least sweet to most sweet. You have to be certain in this test that a subject that knows in advance that they like sweet coffee is not rating them from worst to best. You could ensure that this is the case by having one of the cups being much too sweet, or you could just make sure that your subjects are trained well enough to know how to answer the question they’ve been asked (and not another question that they’ve invented in their head...).
You will have to know when you use a person as a subject in a listening test what kind of listener they are. There are four basic categories that you can put people into when you’re doing this.
There are many different methods used for doing perceptual tests, whether hedonic or non-hedonic. The following list should only be taken as an introduction for these methods. If you’re planning on doing a real test that produces reliable results, you should either consult someone who has experience in experimental design, or go read a lot of books before you continue.
In a paired comparison, the subject is presented with two stimuli and is asked to rate how one compares to the other. For example, you are given two cups of coffee, “Cup A” and “Cup B” and you are asked “Which of the two cups of coffee is sweetest?” (or hottest, or most bitter, or “Which cup of coffee do you prefer?”)
In this case, you’re comparing a pair of stimuli. There is no real reference, each of the two stimuli in the pair is referenced to the other.
The nice thing about this test is that you can design it to check your answers. For example, let’s say that you have 3 cups of coffee to test in total (A, B, and C), and you do a paired comparison test (so you ask the subject to compare the sweetness of A and B, then B and C, then A and C). Let’s also say that A was rated sweeter than B, and B was rated sweeter than C. It should therefore follow that A will be rated sweeter than C. If it isn’t, then the subject is confused, or lying, or just not paying attention, or doesn’t understand the question, or the differences in sweetness are imperceptible. The good thing is that you can check the subjects’ answers if the test is properly designed and includes all possible pairs within your set of all stimuli.
Sometimes, you want to run a test to see if the differences between two stimuli are perceptible. For example, you’ve just invented a new codec and you think that its output sounds just as good as the original signal off a CD. So, you want to test if people can hear the difference between the original and the coded signal. One way to do this is with an A/B/X test. In this test, we still have two stimuli, in this example, the original and the output of the codec. You present the subject with three things to which to listen, stimulus A might be the codec output, stimulus B will be the other (the original sound) and stimulus X will be the same as one of them. The subject is asked “X is identical to either A or B - which one is it?” The subject knows in advance that one of them (A or B) will definitely be identical to the reference signal (X) – they have to just figure out which one it is.
If you do this test properly, randomizing the presentation of the stimuli, you can use this test to determine how often people will recognize the difference between the two stimuli. For example, if everyone gets 100% on your test, then everyone will recognize the difference. If everyone gets 50% on the test, then they are all just guessing (they would have gotten 50% if they never heard the stimuli at all...), and there is no noticeable difference.
Of course, the thing to be careful of here is the question of the training of your subjects. If you’ve never heard a sound in MP3 format before, then you probably will not score very well on a original vs. MP3 detection test done as an A/B/X test. If you’ve been trained to hear MP3 artifacts, then you’ll score much better. This is how the original marketing was done for things like DCC and Mini-Disc. The advertising said that these formats provided “CD quality” because the people that were tested weren’t trained on how to hear the codec’s. The A/B/X test was valid, but only for the group tested (naive listeners as opposed to trained, experienced or expert ones...).
There is an interesting alternative to the A/B/X test that is just as easy to set up and just as easy for the subjects to do, but that might give you better results. In the A/B/X test, the subject knows that A and B are different, and has to select whether X is the same as A or X is the same as B. Therefore, the subject has a 50% chance of getting the right answer.
What if you presented the three stimuli to the subject and called them, say, A, B and C. Tell the subject that two of the three stimuli are identical and get them to choose the different one. Now, if the subject is guessing, he or she only has a 33.3% chance of getting the correct answer, so you can get the same results as an A/B/X test with the same degree of certainty in your responses, but with fewer questions.
Let’s say that you want to do a test to determine what the smallest perceptible difference in loudness is. This would be better known as a Just Noticeable Difference or JND. You can test for this by playing two stimuli (the same sound, but with two different loudness levels) and asking “Which sound was louder?” This is called a two-alternative forced choice (TAFC or 2AFC test because the subject is forced to make a choice between two stimuli, even if he or she cannot detect a difference.
This probably sounds a little like a paired-comparison test, and as far as the subject is concerned, these two tests are the same. The difference is is how the questions change throughout the test.
For example, let’s think of the loudness test that I just described. You make stimulus A 6 dB louder than stimulus B, and ask which is louder? The subject answers correctly (A is louder), so you repeat the test, this time with B only 3 dB louder than A. Ask again.... Each time the subject gets the correct answer, you make the difference in level smaller. Each time the subject gets the wrong answer, you make the difference in level bigger. So, in a TAFC test, the difference is adapting to the response the subject gives.
As the subject gets closer and closer to the JND, they’ll start alternating between correct and incorrect answers. If the difference is greater than the JND, then they will probably get the correct answer, the difference is reduced to less than the JND, and they have a 50% chance of getting the wrong answer, so the difference is increased to greater than the JND and so on and so on. This can go on forever, so, we stop asking questions after a given number of reversals. This means that you constantly keep track of correct and incorrect answers, therefore decreases and increases in the difference that you’re testing. After a number of reversals (from decreases to increases or vice versa) you stop the test and move on to the next one. This is illustrated in Figure 5.18.
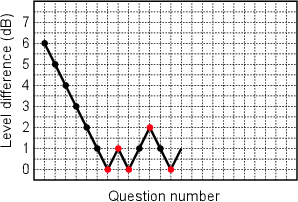
Take a look at the example results shown in Figure 5.18. This shows a test where the level difference between two stimuli was changed, and the subject was asked which of the two stimuli was loudest. If the subject answered correctly, then the difference in level was reduced by 1 dB. If the subject got the wrong answer, then the level was increased by 1 dB. The test was stopped after 5 reversals. So, to get the “answer” to the question (what is the just noticeable difference in level for this subject and this program material?) we take the level differences at the 5 reversals (0 dB, 1 dB, 0 dB, 2 dB and 0 dB) and find the mean (0.6 dB) and that’s the answer.
There are a couple of other issues to mention here... If you look at the first 6 responses, you can see that the subject got these all correct, therefore the level difference was reduced each time. This is called a run – a consecutive string of correct (or incorrect) answers.
Also, you can modify the way the test changes the level. For example, maybe you want to say that if the subject gets the answer correct, you drop the level difference by 1 dB, but if they get it incorrect, you increase by 3 dB. This is not only legal, but standard practice. You can choose how your results reflect the real word in this way. This is described in a paper that is cited everywhere by Levitt [Levitt, 1971] and we’ll talk about later. If you’re doing any number of serious listening tests, you should get your hands on a copy of this paper.
One important thing to remember about a TAFC test is that the subject must choose one or the other stimulus. They can never answer “I don’t know” or “I can’t hear a difference.” Interestingly, it turns out that, if you don’t allow people to say “I don’t know” then they still might give you the correct answer, even through they aren’t able to tell that they’re giving the right answer. This is why you force them to choose – you decide when they don’t know instead of them deciding for you.
There is another way of doing the test for JND in loudness I described in the second on TAFC tests. You could give the subject a reference stimulus (play a tune at a certain level) and give the person a second stimulus (same tune, different level) and a volume knob. Ask them to change the volume of the second stimulus so that it matches the reference. Repeat this test over and over and average your results.
In this test, the subject is adjusting the level, so we call the test a method of adjustment (MOA) test.
If you put a bunch of psychologists and audio people in a room, they’ll get into an argument about which is better, a TAFC or an MOA test. The psychologists will argue that an MOA test gives you a more accurate result. The audio people will tell you that the MOA test is less tiring to perform. There is a small, sane group of people that thinks that both types of tests are fine – pick the one you like and use it.
Once upon a time, the International Telecommunications Union was asked to some up with a standard way for testing how much a perceptual codec screwed up an audio signal. So, they put together a group of people who decided on a way to do this test, and the document they published was called Recommendation BS.1116-1: Methods for the subjective assessment of small impairments in audio systems including multichannel sound systems which can be purchased from the ITU here.
The BS.1116 test gives the subject three stimuli to hear, just like an A/B/X test. There’s the Reference, an A stimulus and a B stimulus. The Reference stimulus is the original sound, and either A or B is identical to the Reference. The other remaining stimulus (either B or A) is the sound that has gone through the codec. The response display shows two sliders as is shown in Figure 5.19. The subject is basically asked two questions:
At least one of the two stimuli should have a rating of 5, otherwise the subject didn’t understand the question.
Note that some over-educated people might classify this as a ”double-blind triple-stimulus with hidden reference” test.
There are a couple of other minor rules to follow for this test (including some important stuff about training of your subjects), and the instructions on how to analyze your results are described in the document if you understand statistics. If, like me, you don’t understand statistical methods, then the document won’t help you very much. Unfortunately, neither can I. My apologies.
I have a couple of personal problems with this type of test (he said, standing on his soapbox...). Firstly, it assumes that, if you can hear a difference, then the stimulus under test cannot be better than the reference. It can be various levels of annoying, but not preferable, so subjects tend to get confused and use the scales to rate their preference instead of the amount of degradation of the signal. In essence, they do not answer the question they are asked. Secondly, it’s a little confusing for the subject to do this test. Whereas A/B/X or paired comparison tests are very easy to perform, the BS.1116 method is more complicated.
A rank order test is one of the easier ones for your subjects to understand. You give them a bunch of stimuli, and ask them to put them in order of least to most of some attribute. For example, give the subject five cups of coffee and ask them to rate them in order of least to most sweet. Or give them 10 different recordings of an orchestra and ask them to rate them from least to most spacious.
The nice thing about this type of test is that it’s pretty easy for subjects to understand the task. We put things in rank order all the time in day to day life. The problem with this test is that you’ll never find out the relative levels of the ratings. You know that this cup of coffee was sweeter than that cup of coffee, but you don’t know how much sweeter it is...
The MUSHRA test developed by the EBU is, in some ways, similar to the BS.1116 test, however, it’s designed for bigger impairments. Let’s say that you wanted to test 3 different codec’s applied to the same signal. You give the subject the original reference, labeled ”Reference” and four different stimuli to rate. One of these stimuli is an exact copy of the Reference, and the other three are the same sound, processed using the codec’s under test. The subject is asked to directly rate each stimulus on a continuous 5-point scale (1. Bad, 2. Poor, 3. Fair, 4. Good, 5. Excellent) as is shown in Figure 5.20
The nice thing about this test is that you can get ratings of many different stimuli all in the same test, instead of one at a time like the BS.1116 test. Therefore, you get more results quicker. The disadvantage is that it’s not designed for very small impairments, so if your codec’s are all very good, you’ll just see a lot of “Excellent” ratings...
Up to now, we have been assuming that you already know what you’re looking for. For example, you’re asking subjects to rate loudness, or coffee sweetness, or codec quality. However, there will be times when you don’t know what you’re looking for. Two people bring in two different cups of coffee and you want to find out what the difference is. You can assume that the difference is “sweetness” and ask your subjects to rate this, but if it turns out that the actual difference is “temperature” then your test wasn’t very helpful.
Consequently, there are a number of different test methodologies that are used for finding out what the differences between stimuli are, so that you can come back later and rate those differences. The big two in use by most people are called Repertory Grid Technique and Descriptive Analysis.
In both of these cases, the goal is to find out what words best describe the attributes that make your stimuli different.
For both types of tests, let’s use the example of coffee. There are four different coffee shops in your neighbourhood, A, B, C, and D. You want to find out what makes their coffee different from each other, and how different those attributes are... Let’s use the two techniques to find this information...
If you were using the Repertory Grid Technique (or RGT), you begin with the knowledge elicitation phase where you try and see into how your subject perceives the stimuli. You present three cups of coffee (say, A, B, and C) to the subject and ask “Pick the two cups of coffee that are most similar and tell me what makes the other one different.” You now have two attributes – for example, the subject might say something like “These two are bitter whereas the third is sweet.” So you write down the word “bitter” under the heading “Similarities” and “Sweet” under the heading “Contrasts” as is shown in Table 5.3
| Similarity | Coffee A | Coffee B | Coffee C | Coffee D | Contrast |
| Pole | Pole | ||||
| Bitter | Sweet | ||||
| Cold | Hot | ||||
| Light | Dark | ||||
| Strong | Weak | ||||
| Etc. | Etc. | ||||
Repeat this process with three different cups of coffee, randomly selected from the four different types. Keep doing this until the subject stops giving you new words.
Now you have a “rating grid” (shown in Figure 5.3, ready to be filled in by the subject). So, you ask the subject to taste each of the four cups of coffee and rate them on each attribute scale using a number from 1 to 5 where 1 indicates the word in the Similarity Pole and 5 indicates the word in the Contrast Pole. For example, the subject might taste Coffee A and think it’s very sweet, so Coffee A gets a rating of 5 on the Bitter-Sweet line. If the same person thinks that Coffee B is neither too bitter nor too sweet, it might get a 3 on the Bitter-Sweet line.
An example of the ratings to come out of this rating grid phase is shown in Table 5.4.
| Similarity | Coffee A | Coffee B | Coffee C | Coffee D | Contrast |
| Pole | Pole | ||||
| Bitter | 5 | 3 | 2 | 1 | Sweet |
| Cold | 4 | 4 | 5 | 4 | Hot |
| Light | 2 | 4 | 3 | 5 | Dark |
| Strong | 1 | 3 | 2 | 4 | Weak |
| Etc. | Etc. | ||||
The nice advantage of this technique is that each individual subject rates the stimuli using attributes that they understand because they came up with those attributes. The problem might be that they came up with these attributes because they thought you wanted to hear those words, not because they actually think they’re good descriptors. Also, there is the problem that every person in your panel will come up with a different set of words (some of which may be the same and mean different things, or may be different and mean the same thing...) This can be a bit confusing and will make your life a little difficult, but there are some statistical software packages out there that can tell you that two people mean the same thing with different words (because their ratings will be similar) or that they’re using the same words to mean different things (because their ratings will be different...)
In order to analyze the results of an RGT rating grid phase, people use various methods such as factor analysis, principal component analysis, multidimensional scaling and cluster analysis. I will not attempt to explain any of these because I don’t know anything about them.
The biggest disadvantage of the RGT is that you get different sets of words from each of your subjects, so you can’t go back one of the coffee shops and tell them that everyone rated their coffee more bitter than everyone else’s, because some people used the word “sharp” or “harsh” instead of “bitter.” You can pretend to yourself that you know what your subjects mean (as opposed to what they say) but you can’t really be certain that you’re translating accurately...
So, to alleviate this problem, you get the subjects to talk to each other. This is done in a different technique called Quantitative Descriptive Analysis (or QDA).
In the QDA technique, there is a word elicitation phase similar to the knowledge elicitation phase in the RGT. Put all of your subjects in a room, each with a little booth all to themselves. Give them the four cups of coffee and ask them to write down all of the words that they can think of that describe the coffees. You’ll get longs lists from people that will include words like sweet, bitter, brown, liquid, dark, light, sharp, spicy, cinnamon, chocolate, vanilla.... and so on... tons and tons of words. The only words they aren’t allowed to use are preference words like good, better, awful, tasty and so on. No hedonic ratings allowed (although some people might argue this rule).
Then you collect all the subjects’ lists, sit everyone around a table and write down all of the words on a blackboard at the front of the room. With everyone there, you start grouping words that are similar. For example, maybe everyone agree that bitter, harsh and sharp all belong together in a group and that hot, cold, and lukewarm all belong together in a different group. Notice that these groups of words can contain opposites (hot and cold) as long as everyone agrees that they are opposites that belong together.
Once you’re done making groups (you’ll probably end up with about 10 or 12 groups give or take a couple) you put headings on each. For example, the group with hot and cold might get the heading “Temperature.” You then pick two representative anchor words from each column that represent the two extreme opposite cases (i.e. extremely hot and extremely cold, or bitter and sweet).
So, what you’re left with, after a bunch of debating and fighting and meeting after meeting with your entire group of people, is a list of about 10 attributes (the headings for your word groups), each with a pair of anchor words that describe opposite ends of the scale for that attribute. Hopefully, everyone agreed on the words that were chosen by the group, but if they don’t, then at least they were at the meetings and so they know what the group means when they use a certain word.
Your next step is going back to the stimuli (the cups of coffee) and asking people to rate each one on each attribute scale. You can do this by giving the subject all cups of coffees, and asking for one attribute to be rated at a time, or you could give the subject one cup of coffee and ask for all attributes to be rated, or if you want to be really confusing, you give them all cups of coffee and a big questionnaire with all attributes. This is up to you and how comfortable your subjects will be with the rating phase.
The nice thing about this technique is that everyone is using the same words. You can then use correlation analysis to determine whether or not people are rating the attributes unidimensionally (which is to say that people aren’t confused and using two different attributes to say the same thing. For example, there might be a “Bitterness” attribute ranging from “bitter” to “not bitter” and a separate “Sweetness” attribute ranging from “Not sweet” to “Sweet”. After you’re finished your test, you might notice that any coffee that was rates as bitter was also rated as not sweet and that all the sweet coffees were also rated as not bitter. In this case, you would have a negative correlation between attributes, and you might want to consider folding them into one attribute that ranged from bitter to sweet. The results show that this is what people are doing in their heads anyway, so you might as well save people’s time and ask them one question instead of two....
There is one minor philosophical issue here that you might want to know about regarding the issue of training of your subjects. In theory, all of your subjects after the word elicitation phase know what all of the words being used by the group mean. You may find, however, that one person has completely different ratings of one of the attributes than everyone else. This can mean one of two things: either that person understands the group’s definition of the word and perceives the stimulus differently than everyone else (this is unlikely) or the person doesn’t really understand the group’s definition of the word (this is more likely). In other words, the best way to know that everyone in your group understands the definitions of the words they are using is if they all give you the same results. However, if they all give you the same results, then they become redundant. Consequently, the better trained your listening panel member is, the less you need that person, because he or she will just give you the same answers as everyone else in the group. This is a source of a lot of guilty feelings for me, because I hate wasting people’s time...
Whenever you’re doing any listening test you have to be careful to randomize everything to avoid order effects. Subjects should hear the stimuli in different orders from each other, and the stimuli presentation (whether a sound is A or B in an A/B/X test for example) should also be randomized. This is because there is a training effect that happens during a listening test. For example, if you were testing codec degradation, and you presented all of the worst codec’s to all the subjects first, they will gradually learn to hear the artifacts that are under test, while they’re doing the test. As a result, the better codec will be graded more harshly because the subjects better knew what to listen for. If you randomize the presentation order and use that same order for all the subjects, then the training will not be as obvious, but you might get situations where one codec made then next one look really bad, and since everyone got them in that order, the second was unfairly judged. The only way to avoid this is to have each person get a different presentation order that is completely random.
The (potentially incorrect) moral of the story here... just randomize everything.
There are exceptions. Let’s say that you’re doing a listening test to evaluate who should be on a listening panel. In this case, you want everyone to have done exactly the same test so that they’re all treated fairly. So, in this case, everyone would get the same presentation order, because it’s the subjects themselves that are under test, not the sound stimuli.
As I’ve confessed earlier in this book, I’m really bad at statistics, and frankly I’m not really that interested in learning any more than I absolutely have to... So you’ll have to look elsewhere ([Søren Bech, 2006] is a good place to start) for information on how to analyze your data from your listening tests. Sorry...
Estimate the amount of time required to do the test wisely. Listening tests take much longer than one would expect in order to do them properly and get reliable results. This doesn’t just mean the amount of time that the subject is sitting there answering questions. It also means the amount of experimental design time, the stimulus preparation time, scheduling subjects, the actual running of the test time (remember to not tire your subjects... no more than 20 or 30 minutes per sitting, and no more than 1 or 2 tests per day), clean up and analysis time... Whatever you think it will take, double or triple that amount to get a better idea of how much time you’ll need.
Run a pilot experiment! Nothing will give you better experience than running your listening test with 2 or 3 people in advance. Pretend it’s the real thing - analyze the data and everything... You’ll probably find out that you made a mistake in your experimental design or your setup and you would have wasted 30 people’s time (and lost them, because after the ruined test, they’re trained and you have to find more people...). Pilot experiments are also good for finding out a rough idea of ranges to be testing. For example, if you’re doing a JND experiment on loudness, you can use your pilot experiment to get an idea that the numbers are going to be around 0.5 dB or so, so you won’t need to start with a difference of 20 dB... your pilot experiment will tell you that everyone can hear that, so you don’t need to include it in your test.
Test what you think you’re testing! Equalize everything that you can that isn’t under test. For example, if you’re testing spaciousness of two stereo widening algorithms, make sure that the stimuli are the same loudness. This isn’t as easy as it sounds... do it right, don’t just set the levels on your mixer to the same value. You have to ensure that the two stimuli have the same perceptual loudness (discussed in Section ??).






