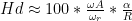On the left: a “Stereopladespiller” (Stereo Gramophone) Type 42 VF. On the right, a Beogram 1000 V Type 5203 Series 33, modified with a built-in RIAA preamp (making it a Beogram 1000 VF)
Some history today – without much tech-talk. I just finished restoring my 42VF and I thought I’d spend an hour or two taking some photos next to my BG1000.
According to the beoworld.org website, the Stereopladespiller was in production from 1960 to 1976. Although Bang & Olufsen made many gramophones before 1960, they were all monophonic, for 1-channel audio. This one was originally made to support the 2-channel “SP1 / SP2” pickup developed by Erik Rørbæk Madsen after having heard 2-channel stereo on a visit to the USA in the mid-1950s (and returned to Denmark with a test record).
Sidebar: The “V” means that the players are powered from the AC mains voltage (220 V AC, 50 Hz here in Denmark). The “F” stands for “Forforstærker” or “Preamplifier”, meaning that it has a built-in RIAA preamp with a line-level output.
Internally, the SP1 and SP2 are identical. The only difference is the mounting bracket to accommodate the B&O “ST-” series tonearms and standard tonearms.
Name, Pivot – Platter Centre, Pivot – Stylus, Pickup
ST/M,190 mm, 205 mm, SP2
ST/L, 209.5 mm, 223.5 mm, SP2
ST/P, 310 mm, 320 mm, SP2
ST/A, 209.5 mm, 223.5 mm, SP1
[/table]
(I’ll do another, more detailed posting about the tonearms at a later date…)
Again, according to the beoworld.org website, the Beogram 1000 was in production from 1965 to 1973. (The overlap and the later EoP date of the former makes me a little suspicious. If I get better information, I’ll update this posting.)
The tonearm seen here on the Stereopladespiller is the ST/L model with a Type PL tonearm lifter.
Looking not-very-carefully at the photos below, you can see that the two tonearms have a significant difference – the angle of the pickup relative to the surface of the vinyl. The ST/L has a 25º angle whereas the tonearm on the Beogram 1000 has a 15º angle. This means that the two pickups are mutually incompatible. The pickup shown on the Beogram 1000 is an SP14.
This, in turn, means that the vertical pivot points for the two tonearms are different, as can be seen below.
The heights of both tonearms at the pivot are adjustable by moving a collar around the post and fixing its position with a small set screw. A nut under the top plate (inside the turntable) locks it in position.
The position of the counterbalance on the older tonearm can be adjusted with the large setscrew seen in the photo above. The tonearm on the Beogram 1000 gently “locks” into the correct position using a small spring-loaded ball that sets into a hole at the end of the tonearm tube, and so it’s not designed to have the same adjustability.
Both tonearms use a spring attached to a plastic collar with an adjustable position for fine-tuning the tracking force. At the end of this posting, you can see that I’ve measured its accuracy.
The Micro Moving Cross (MMC) principle of the SP1/2 pickup can easily be seen in the photo above (a New-Old-Stock pickup that I stumbled across at a flea market). For more information about the MMC design, see this posting. In later versions of the pickup, such as the SP14, seen below, the stylus and MMC assembly were attached to the external housing instead.
A couple of later SP-series pickups in considerably worse shape. These are also flea-market finds, but neither of them is behaving very well due to bent cantilevers.
This construction made it easier to replace the stylus, although it was also possible to do so with the SP1-2 using a replacement such as the one shown below.
A replacement stylus for the SP1/2 shown on the bremdal-radio.dk website.
Just to satisfy my own curiosity, I measured the tracking force at the stylus with a number of different adjustments on the collar. The results are shown below.
Tracking force on the Stereopladespiller with the collar aligned to each side of the gradations on the tonearm. Right-click on the photo and open it in a new window or tab to zoom in for more details.Tracking force on the Beogram 1000 with the collar aligned to each side of the gradations on the tonearm. Right-click on the photo and open it in a new window or tab to zoom in for more details.
As you can see there, the accuracy is reasonably good. This is not really surprising, since the tracking force is applied by a spring. So, as long as the spring constant hasn’t changed over the years, which it shouldn’t have unless it got stretched for some reason (say, when I was rebuilding the pivot on the tonearm, for example…) it should behave as it always did.
In a perfect sound system, all loudspeakers are identical, and they are all able to play a full frequency range at any listening level. However, most often, this is not a feasible option, either due to space or cost considerations (or both…). Luckily, it is possible to play some tricks to avoid having to install a large-scale sound system to listen to music or watch movies.
Humans have an amazing ability to localise sound sources. With your eyes closed, you are able to point towards the direction sounds are coming from with an incredible accuracy. However, this ability gets increasingly worse as we go lower in frequency, particularly in closed rooms.
In a sound system, we can use this inability to our advantage. Since you are unable to localise the point of origin of very low frequencies indoors, it should not matter where the loudspeaker that’s producing them is positioned in your listening room. Consequently, many simple systems remove the bass from the “main” loudspeakers and send them to a single large loudspeaker whose role it is to reproduce the bass for the entire system. This loudspeaker is called a “subwoofer”, since it is used to produce frequency bands below those played by the woofers in the main loudspeakers.
The process of removing the bass from the main channels and re-routing them to a subwoofer is called bass management.
It’s important to remember that, although many bass management systems assume the presence of at least one subwoofer, that output should not be confused with an (Low-Frequency Effects) LFE (Low-Frequency Effects) or a “.1” input channel. However, in most cases, the LFE channel from your media (for example, a Blu-ray disc or video streaming device) will be combined with the low-frequency output of the bass management system and the total result routed to the subwoofer. A simple example of this for a 5.1-channel system is shown below in Figure 1.
Figure 1: A simple example of a bass management system for a 5.1 channel system.
Of course, there are many other ways to do this. One simplification that’s usually used is to put a single Low Pass Filter (LPF) on the output of the summing buss after the signals are added together. That way, you only need to have the processing for one LPF instead of 5 or 6. On the other hand, you might not want to apply a LPF to an LFE input, so you may want to add the main channels, apply the LPF, and then add the LFE, for example. Other systems such as Bang & Olufsen televisions use a 2-channel bass management system so that you can have two subwoofers (or two larger main loudspeakers) and still maintain left/right differences in the low frequency content all the way out to the loudspeakers.
However, the one thing that older bass management systems have in common is that they typically route the low frequency content to a subset of the total number of loudspeakers. For example, a single subwoofer, or the two main front loudspeakers in a larger multichannel system.
In Bang & Olufsen televisions starting with the Beoplay V1 and going through to the Beovision Harmony, it is possible to change this behaviour in the setup menus, and to use the “Re-direction Level” to route the low frequency output to any of the loudspeakers in the current Speaker Group. So, for example, you could choose to send the bass to all loudspeakers instead of just one subwoofer.
There are advantages and disadvantages to doing this.
The first advantage is that, by sending the low frequency content to all loudspeakers, they all work together as a single “subwoofer”, and thus you might be able to get more total output from your entire system.
The second advantage is that, since the loudspeakers are (probably) placed in different locations around your listening room, then they can work together to better control the room’s resonances (a.k.a. room modes).
One possible disadvantage is that, if you have different loudspeakers in your system (say, for example, Beolab 3s, which have slave drivers, and Beolab 17s, which use a sealed cabinet design) then your loudspeakers may have different frequency-dependent phase responses. This can mean in some situations that, by sending the same signal to more loudspeakers, you get a lower total acoustic output in the room because the loudspeakers will cancel each other rather than adding together.
Another disadvantage is that different loudspeakers have different maximum output levels. So, although they may all have the same output level at a lower listening level, as you turn the volume up, that balance will change depending on the signal level (which is also dependent on frequency content). For example, if you own Beolab 17s (which are small-ish) and Beolab 50s (which are not) and if you’re listening to a battle scene with lots of explosions, at lower volume levels, the 17s can play as much bass as the 50s, but as you turn up the volume, the 17s reach their maximum limit and start protecting themselves long before the 50s do – so the balance of bass in the room changes.
Beosound Theatre
Beosound Theatre uses a new Bass Management system that is an optimised version of the one described above, with safeguards built-in to address the disadvantages. To start, the two low-frequency output channels from the bass management system are distributed to all loudspeakers in the system that are currently being used.
However, in order to ensure that the loudspeakers don’t cancel each other, the Beosound Theatre has Phase Compensation filters that are applied to each individual output channel (up to a maximum of 7 internal outputs and 16 external loudspeakers) to ensure that they work together instead against each other when reproducing the bass content. This is possible because we have measured the frequency-dependent phase responses of all B&O loudspeakers going as far back in time as the Beolab Penta, and created a custom filter for each model. The appropriate filters are chosen and applied to each individual outputs accordingly.
Secondly, we also know the maximum bass capability of each loudspeaker. Consequently, when you choose the loudspeakers in the setup menus of the Beosound Theatre, the appropriate Bass Management Re-direction levels are calculated to ensure that, for bass-heavy signals at high listening levels, all loudspeakers reach their maximum possible output simultaneously. This means that the overall balance of the entire system, both spatially and timbrally, does not change.
The total result is that, when you have external loudspeakers connected to the Beosound Theatre, you are ensured the maximum possible performance from your system, not only in terms of total output level, but also temporal control of your listening room.
In order to explain the significance of the following story, some prequels are required.
Prequel #1: I’m one of those people who enjoys an addiction to collecting what other people call “junk” – things you find in flea markets, estate sales, and the like. Normally I only come home with old fountain pens that need to be restored, however, occasionally, I stumble across other things.
Prequel #2:Many people have vinyl records lying around, but not many people know how they’re made. The LP that you put on your turntable was pressed from a glob of molten polyvinyl-chloride (PVC), pressed between two circular metal plates called “stampers” that had ridges in them instead of grooves. Easy of those stampers was made by depositing layers of (probably) nickel on another plate called a “metal mother” which is essentially a metal version of your LP. That metal mother was made by putting layers on a “metal master” (also with ridges instead of grooves) which was probably a lamination of tin, silver, and nickel that was deposited in layers on an acetate lacquer disc, which is the original, cut on a lathe. (Yes, there are variations on this process, I know…) The thing to remember in this process is
there are three “playable” versions of the disc in this manufacturing process: your LP, the metal mother, and the original acetate that was cut on the lathe
there are two other non-playable versions that are the mirror images of the disc: the metal master and the stamper(s).
(If you’d like to watch this process, check out this video.)
Prequel #3: One of my recurring tasks in my day-job at Bang & Olufsen is to do the final measurements and approvals for the Beogram 4000c turntables. These are individually restored by hand. It’s not a production-line – it really is a restoration process. Each turntable has different issues that need to be addressed and fixed. The measurements that I do include:
verification of the gain and response of the two channels in the newly-built RIAA preamplifier (this is done electrically, by connecting the output of my sound card into the input of the RIAA instead of using a signal from the pickup)
checking the sensitivity and response of the two channels from vinyl to output
checking the wow and flutter of the drive mechanism
checking the channel crosstalk as well as the rumble
The last three of these are done by playing specific test tracks off an LP with signals on it, specifically designed for this purpose. There are sine wave sweeps, sine waves at different signal levels, a long-term sine wave at a high-ish frequency (for W&F measurements), and tracks with silence. (In addition, each turntable is actually tested twice for Wow and Flutter, since I test the platter and bearing before it’s assembled in the turntable itself…)
Prequel #4: Once-upon-a-time, Bang & Olufsen made their own pickup cartridges (actually, it goes back to steel needles). Initially the SP series, and then the MMC series of cartridges. Those were made in the same building that I work in every day – about 50 m from where I’m sitting right now. B&O doesn’t make the cartridges any more – but back when they did, each one was tested using a special LP with those same test tracks that I mentioned above. In fact, the album that they used once-upon-a-time is the same album that I use today for testing the Beogram 4000c. The analysis equipment has changed (I wrote my own Matlab code to do this rather than to dust off the old B&K measurement gear and the B&O Wow and Flutter meter…)
If you’ve read those four pieces of information, you’ll understand why I was recently excited to stumble across a stamper of the Bang & Olufsen test LP, with a date on the sleeve reading 21 March, 1974. It’s funny that, although the sleeve only says that it’s a Bang & Olufsen disc, I recognise it because of the pattern in the grooves (which should give you an indication of how many times I’ve tested the turntables) – even if they’re the mirror image of the vinyl disc.
Below, you can see my latest treasure, pictured with an example of the B&O test disc that I use. It hasn’t “come home” – but at least it’s moved in next-door.
P.S. Since a couple of people have already asked, the short answer is “no”. The long answers are:
No, the test disc is no longer available – it never was outside of the B&O production area. However, if you can find a copy of the Brüel and Kjær QR 2010 disc, it’s exactly the same. I suspect that the two companies got together to produce the test disc in the 70s. However, there were also some publicly-available discs by B&O that included some test tones. These weren’t as comprehensive as the “real” test discs like the ones accompanying the DIN standards, or the ones from CBS and JVC.
No, the metal master is no longer in good enough shape to use to make a new set of metal mothers and stampers. Too bad… :-(
P.P.S. If you’re interested in the details of how the tests are done on the Beogram 4000c turntables, I’ve explained it in the Technical Sound Guide, which can be downloaded using the link at the bottom of this page. That document also has a comprehensive reading list if you’re REALLY interested or REALLY having trouble sleeping.
This series has flipped back and forth between talking about high resolution audio files & sources and the processing that happens in the equipment when you play it. For this posting, we’re going to deal exclusively with the playback side – regardless of the source content.
I work for a company that makes loudspeakers (among other things). All of the loudspeakers we make use digital signal processing instead of resistors, capacitors, and inductors because that’s the best way to do things these days…
Point 1: This means that our volume control is a gain (a multiplier) that’s applied to the digital signal.
We also make surround processors (most of our customers call them “televisions”) that take a multichannel audio input (these days, this is under the flag of “spatial audio”, but that’s just a new name on an old idea) and distribute the signals to multiple loudspeakers. Consequently, all of our loudspeakers have the same “sensitivity”. This is a measurement of how loud the output is for a given input.
Let’s take one loudspeaker model, Beolab 90, as an example. The sensitivity of this loudspeaker is set to be the same as all other Bang & Olufsen loudspeakers. Originally, this was based on an analogue signal, but has since been converted to digital.
Point 2: Specifically, if you send a 0 dB FS signal into a Beolab 90 set to maximum volume, then it will produce a little over 122 dB SPL at 1 m in a free field (theoretically).
Let’s combine points 1 and 2, with a consideration of bit depth on the audio signal.
If you have a DSP-based loudspeaker with a maximum output of 122 dB SPL, and you play a 16-bit audio signal with nothing but TPDF dither, then the noise floor caused by that dither will be 122 – 93 = 29 dB SPL which is pretty loud. Certainly loud enough for a customer to complain about the noise coming from their loudspeaker.
Now, you might say “but no one would play a CD at maximum volume on that loudspeaker” to which I say two things:
I do. The “Banditen Galop” track from Telarc’s disc called “Ein Straussfest” has enough dynamic range that this is not dangerous. You just get very loud, but very short spikes when the gunshots happen.
That’s not the point I’m trying to make anyway…
The point I’m trying to make is that, if Beolab 90 (or any other Bang & Olufsen loudspeaker) used 16-bit DACs, then the noise floor would be 29 dB SPL, regardless of the input signal’s bit depth or dynamic range.
So, the only way to ensure that the DAC (or the bit depth of the signal feeding the DAC) isn’t the source of the noise floor from the loudspeaker is to use more than 16 bits at that point in the signal flow. So, we use a 24-bit DAC, which gives us a (theoretical) noise floor of 122 – 141 = -19 dB SPL. Of course, this is just a theoretical number, since there are no DACs with a 141 dB dynamic range (not without doing some very creative cheating, but this wouldn’t be worth it, since we don’t really need 141 dB of dynamic range anyway).
So, there are many cases where a 24-bit DAC is a REALLY good idea, even though you’re only playing 16-bit recordings.
Similarly, you want the processing itself to be running at a higher resolution than your DAC, so that you can control its (the DAC’s) signal (for example, you want to create the dither in the DSP – not hope that the DAC does it for you. This is why you’ll often see digital signal processing running at floating point (typically 32-bit floating point) or fixed point with a wider bit depth than the DAC.
Imagine water coming out of a garden hose, filling up a watering can (it’s nice outside, so this is the first analogy that comes to mind…). The water is pushed out of the hose by the pressure of the water behind it. The higher the pressure, the more water will come out, and the faster the watering can will fill.
If you want to reduce the amount of water coming out of the hose, you can squeeze it, restricting the flow by making a resistance that reduces the water pressure. The higher the resistance of the restriction to the flow, the less water comes out, and the slower the watering can fills up.
Electricity works in a similar fashion. There is an electrical equivalent of the “pressure”, which is called Electromotive Force or EMV, measured in Volts (which is why most people call it “Voltage” instead of its real name). The “flow” – the quantity of electrons that are flowing through the wire – is the current, measured in Amperes or Amps. A thing that restricts the flow of the electrons is called a resistor, since it resists the current. A resistor can be a thing that does nothing except restrict the current for some reason. It could also be something useful. A toaster, for example, is just a resistor as far as the power company is concerned. So is a computer, your house, or an entire city.
So, if we measure the current coming through a wire, and we want to increase it, we can increase the voltage (the electrical pressure) or we can reduce the resistance. These three are locked together. For example, if you know the voltage and the resistance, you can calculate the current. Or, if you know the current and the resistance, you can calculate the voltage. This is done with a very simple equation known as Ohm’s law:
V = I*R
Where V is the Voltage in Volts, I is the current in Amperes, and R is the resistance in Ohms.
For example, if you have a toaster plugged into a wall socket that is delivering 230 V, and you measure 2 Amperes of current going through it, then :
R = V / I
R = 230 / 4
R = 57.5 Ohms
However, to be honest, I don’t really care what the resistance of my toaster is. What concerns me most is how much I have to pay the power company every time I make toast. How is this calculated? Well, the power company promises to always give me 230 V at my disposal in the wall socket. The amount of current that I use is up to me. If I plug in a big resistance (like an LED lamp) then I don’t use much current. If I plug in a small resistance (say, to charge up the battery in the electric car) then I use lots. What they’re NOT doing is charging me for the current – although it does enter into another equation. The power company is charging me for the amount of Power that I’m using – because they’re charging me for the amount of work that they have to do to generate it for me.
When I use a toaster, it’s converting electrical energy into heat. The amount of heat that it generates is dependent on the voltage (the electrical pressure) and the current going through it. This can be calculated using another simple equation knowns as “Watt’s Law”:
P = V * I
So, let’s say that I plug my toaster into a 230 V outlet, and, because it is a 115 Ohm resistor, 2 Amperes goes through it. In this case, then the amount of Power it’s consuming is
P = 230 * 4
P = 920 Watts
If I’m going to be a little specific, then I should say that the Power (in Watts) is a measure of how much energy I’m transferring per second – so there’s an aspect of time here that I’m ignoring, but this won’t be important until the end of this posting.
Also, if I’m going to bring this back to the power company’s bill that they send me at the end of the month, it will be not only based on how much power I used (in Watts), but how long I used it for (in hours). So, if I make toast for 1 minute, then I used 920 Watts for 1/60th of an hour, therefore I have to pay for
920 / 60 = 15.33 Watt hours
Normally, of course, I do more than make toast once a month. In fact, I use a LOT more, so it’s measured in thousands of Watt hours or “kilowatt hours”.
For example, if I pull into the driveway with an almost-flat battery in our car, and I plug it into the special outlet we have for charging it to charge, I know that it’s using about 26 Amperes and the outlet is fixed at 380 V. This means that I’m using 10,000 Watts, and it will therefore take about 6.4 hours to charge the car (because it has a 64,000 Wh or 64 kWh battery). This means, at the end of the month, I’ll have to pay for those 64 kWh that I used to charge up the car.
So what? (So watt?)
When you play music in a loudspeaker driver, the amplifier “sees” the driver as a resistor.* Let’s say, for the purposes of this discussion, that the driver has a resistance of 8 Ohms. (It doesn’t, but today, we’ll pretend.) To play the music, the amplifier sends a signal that, on an oscilloscope, looks like the signal that came out of a microphone once-upon-a-time (yes – I’m oversimplifying). That signal that you’re looking at is the VOLTAGE that the amplifier is creating to make the signal. Since the loudspeaker driver has some resistance, we can therefore calculate the current that it “asks” the amplifier to deliver. As the voltage goes up, the current goes up, because the resistance stays the same (yes – I’m oversimplifying).
Now, let’s think about this: The amplifier is generating a voltage, and therefore it has to deliver a current. If I multiply those two things together, I can get the power: P = V*I. Simple, right?
Well, yes…. but remember that thing I said above about how power, in Watts, has an element of time. One watt is a measure of energy that is transferred into a thing (in our case, a loudspeaker driver) in one second. And this is where things get complicated, and increasingly irrelevant.
The problem is that power, measured in watts, has an underlying assumption that the consumption is constant. Turn on an old-fashioned light bulb or start making toast, and the power that you consume over time will be the same. However, when you’re playing Stravinsky on a loudspeaker, the voltage and the current are going up and down all the time – if they weren’t, you’d be listening to a sine wave, which is boring.
So, although it’s easy to use Watts to specify a the amount of energy an amplifier can deliver or a loudspeaker driver’s capabilities, it’s not really terribly useful. Instead, it’s much more useful to know how many volts the amplifier can deliver, and how many amperes it can push out before it can’t deliver more (and therefore distorts). However, although you know the maximum voltage and the maximum current, this is not necessarily the maximum power, since it might only be able to deliver those maxima for a VERY short period of time.
For example, if you measure the peak voltage and the peak current that comes out of all of the amplifiers in a Beolab 90 for less than 5 thousandths of a second (5 milliseconds), the you’ll get to a crazy number like 18,000 Watts. However, after about 5 ms, that number drops very rapidly. It can deliver the peak, but it can’t deliver it continuously (if it could, you’d trip a circuit breaker). (Similarly, you can drive a nail into wood by hitting it with a hammer – but you can’t push it in like a thumbtack. The amount of force you can deliver in a short peak is much higher than the amount you can deliver continuously.)
This is why, when we are specifying a power amplifier that we’ll need for a new loudspeaker at the beginning of the development process, we specify it in Peak Voltage and Peak Current (also the continuous values as well, of course) – but not Watts. Yes, you can use one to calculate the other, but consider this:
Amplifier #1: 1000 W amplifier, capable of delivering 10 V and 100 Amps
Amplifier #2: 1000 W amplifier, capable of delivering 100 V and 10 Amps
These are two VERY different things – so just saying a “1000 W amplifier” is not nearly enough information to be useful to anyone for anything. However, since advertisers have a long history of talking about a power amplifier’s capabilities in terms of watts, the tradition continues, regardless of its irrelevance. On the other hand, if you’re buying a toaster, the power consumption is a great thing to know…
* I’m pretending for this posting that a loudspeaker driver acts as a resistor to keep things simple. It doesn’t – but I’m not going to talk about phase or impedance today.
P.S. Yes, I cut MANY corners and oversimplified a LOT of issues in this posting – I know. Don’t send me hate mail because I didn’t mention reactance or crest factor…
Occasionally, a question that comes into the customer communications department to Bang & Olufsen from a dealer or a customer eventually finds its way into my inbox.
This week, the question was about nomenclature. Why is it that, on some loudspeakers, for example, we say there is a tweeter, mid-range, and woofer, whereas on other loudspeakers we say that we’re using a “full range” driver instead? What’s the difference? (Folded into the same question was another about amplifier power, but I’ll take that one in another posting.)
So, what IS the difference? There are three different ways to answer this question.
Answer #1: It’s how you use it.
My Honda Civic, the motorcycle that passed me on the highway this morning, and an F1 car all have a gear in the gearbox that’s labelled “3”. However, the gear ratio of those three examples of “third gear” are all different. In other words, if you showed a mechanic the gear ratio of one of those gearbox settings without knowing anything else, they wouldn’t be able to tell you “ah! that’s third gear…”
So, in this example, “third gear” is called “third” only because it’s the one between “second” and “fourth”. There is nothing physical about it that makes it “third”. If that were the case then my car wouldn’t have a first gear, because some farm tractor out there in the world would have a gear with a lower ratio – and an F1 car would start at gear 100 or so… And that wouldn’t make sense.
Similarly, we use the words “tweeter”, “midrange”, “woofer”, “subwoofer”, and “full range” to indicate the frequency range that that particular driver is looking after in this particular device. My laptop has a 1″ “woofer” – which only means that it’s the driver that’s taking care of the low frequencies that come out of my laptop.
So, using this explanation, the Beolab 90 webpage says that it has midranges and tweeters and no “full range” drivers because the midrange drivers look after the midrange frequencies, and the tweeters look after the high frequencies. However, the Beolab 28’s webpage says that it has a tweeter and full range drivers, but no midranges. This is because the drivers that play the midrange frequencies in the Beolab 28 also play some of the high-frequency content as part of the Beam Width control. Since they’re doing “double duty”, they get a different name.
Answer #2: Excruciating minutiae
The description I gave above isn’t really an adequate answer. For example, I said that my laptop has a 1″ “woofer”. Beolab 90 has a 1″ “tweeter” – but these two drivers are not designed the same way. Beolab 90’s tweeter is specifically designed to be used to produce high frequencies. One consequence of this is that the total mass of the moving parts (the diaphragm and voice coil, amongst other things) is as low as possible, so that it’s easy to move. This means that it can produce high frequency signals without having to use a lot of electrical power to push it back and forth.
However, the 1″ “woofer” in my laptop is designed differently. It probably has a much higher total mass for the moving parts. This means that its resonant frequency (the frequency that it would “ring” at if you hit it like a drum head) is much lower. Therefore it “wants” to move easily at a lower frequency than a tweeter would.
For example, if you put a child on a swing and you give them a push, they’ll swing back and forth at some frequency. If the child wanted to swing SLOWER (at a lower frequency), you could
move to a swing with longer ropes so this happens naturally, or
you can hold on to the ropes and use your muscles to control the rate of swinging instead.
The smarter thing to do is the first choice, that way you can keep sipping your coffee instead of getting a workout.
So, a 1″ woofer and a 1″ tweeter are not really the same thing.
Answer #3: Compromise
We live in a world that has been convinced by advertisers that “compromise” is a bad thing – but it’s not. Someone who does never accepts to compromise is destined to live a very lonely life. When designing a loudspeaker, one of the things to consider is what, exactly, each component will be asked to do, and choose the appropriate components accordingly.
If we’re going to be really pedantic – there’s really no such thing as a tweeter, woofer, or anything else with those kinds of names. Any loudspeaker driver can produce sound at any frequency. The only difference between them is the relative ease with which the driver plays a signal at a given frequency. You can get 20 Hz to come out of a “tweeter” – it will just be naturally a LOT quieter than the signals at around 5 kHz. Similarly, a woofer can play signals at 20 kHz, but it will be a lot quieter and/or take a lot more power than signals at 50 Hz.
What this means is that, when you make an active loudspeaker, the response (the relative levels of signals at different frequencies) is really a result of the filters in the digital signal processing and the control from the amplifier (ignoring the realities of heat and time…). If we want more or less level at 2 kHz from a loudspeaker driver, we “just” change the filter in the signal processing and use the amplifier to do the work (the same as the example above where you were using your muscle power to control the frequency of the child on the swing).
However, there are examples where we know that a driver will be primarily used for one frequency band, but actually be extending into another. The side-facing drivers on Beolab 28 are a good example of this. They’re primarily being used to control the beam width in the midrange, but they’re also helping to control the beam width in the high frequencies. Since, they’re doing double-duty in two frequency ranges, they can’t really be called “midranges” or “tweeters” – they’d be more accurately called “midranges that also play as quiet tweeters”. (They don’t have to play high frequencies loudly, since this is “only” to control the beam width of the front tweeter.) However, “midranges that also play as quiet tweeters” is just too much information for a simple datasheet – so “full range” will do as a compromise.
P.S.
I’ve got some extra things to add here…
Firstly, it has become common over the past couple of years to call “woofers” “subwoofers” instead. I don’t know why this happened – but I suspect that it’s merely the result of people who write advertising copy using a word they’ve heard before without really knowing what it means. Personally, I think that it’s funny to see a laptop specified to have a “1” subwoofer”. Maybe we should make the word “subtweeter” popular instead.
Secondly, personally, I believe that a “subwoofer” is a thing that looks after the frequency range below a “woofer”. I remember a conversation I had at an AES convention once (I think it was with Günther Theile and Tomlinson Holman) where we all agreed that a “subwoofer” should look after the frequency range up to 40 Hz, which is where a decent woofer should take over.
Lastly, if you find an audio magazine from the 1970s, you’ll see that a three-way loudspeaker had a “tweeter”, “squawker”, and “woofer”. Sometime between then and now, “squawker” was replaced with “midrange” – but I wonder why the other two didn’t change to “highrange” and “lowrange” (although neither of these would be correct, since all three drivers in a three-way system have limited frequency ranges).
Bertrand Russell once said, “In all affairs it’s a healthy thing now and then to hang a question mark on the things you have long taken for granted.”
This article is a discussion, both philosophical and technical about what a volume control is, and what can be expected of it. This seems like a rather banal topic, but I find it surprising how often I’m required to explain it.
Why am I writing this?
I often get questions from colleagues and customers that sound something like the following:
Why does my Beovision television’s volume control only go to 90%? Why can’t I go to 100%?
I set the volume on my TV to 40, so why is it so quiet (or loud)?
The first question comes from people who think that the number on the screen is in percent – but it’s not. The speedometer in your car displays your speed in kilometres per hour (km/h), the tachometer is in revolutions of the engine per minute (RPM) the temperature on your thermostat is in degrees Celsius (ºC), and the display on your Beovision television is on a scale based on decibels (dB). None of these things are in percent (imagine if the speed limit on the highway was 80% of your car’s maximum speed… we’d have more accidents…)
The short reason we use decibels instead of percent is that it means that we can use subtraction instead of division – which is harder to do. The shortcut rule-of-thumb to remember is that, every time you drop by 6 dB on the volume control, you drop by 50% of the output. So, for example, going from Volume step 90 to Volume step 84 is going from 100% to 50%. If I keep going down, then the table of equivalents looks like this:
I’ve used two colours there to illustrate two things:
Every time you drop by 6 volume steps, you cut the percentage in half. For example, 60 is five drops of 6 steps, which is 1/2 of 1/2 of 1/2 of 1/2 of 1/2 of 100%, or 3.2% (notice the five halves there…)
Every time you drop by 20, you cut the percentage to 1/10. So, Volume Step 50 is 1% of Volume Step 90 because it’s two drops of 20 on the volume control.
If I graph this, showing the percentage equivalent of all 91 volume steps (from 0 to 90) then it looks like this:
Of course, the problem this plot is that everything from about Volume Step 40 and lower looks like 0% because the plot doesn’t have enough detail. But I can fix that by changing the way the vertical axis is displayed, as shown below.
That plot shows exactly the same information. The only difference is that the vertical scale is no longer linearly counting from 0% to 100% in equal steps.
Why do we (and every other audio company) do it this way? The simple reason is that we want to make a volume slider (or knob) where an equal distance (or rotation) corresponds to an equal change in output level. We humans don’t perceive things like change in level in percent – so it doesn’t make sense to use a percent scale.
For the longer explanation, read on…
Basic concepts
We need to start at the very beginning, so here goes:
Volume control and gain
An audio signal is (at least in a digital audio world) just a long list of numbers for each audio channel.
The level of the audio signal can be changed by multiplying it by a number (called the gain).
If you multiply by a value larger than 1, the audio signal gets louder.
If you multiply by a number between 0 and 1, the audio signal gets quieter.
If you multiply by zero, you mute the audio signal.
Therefore, at its simplest core, a volume control implemented in a digital audio system is a multiplication by a gain. You turn up the volume, the gain value increases, and the audio is multiplied by a bigger number producing a bigger result.
That’s the first thing. Now we move on to how we perceive things…
Perception of Level
Speaking very generally, our senses (that we use to perceive the world around us) scale logarithmically instead of linearly. What does this mean? Let’s take an example:
Let’s say that you have $100 in your bank account. If I then told you that you’d won $100, you’d probably be pretty excited about it.
However, if you have $1,000,000 in your bank account, and I told you that you’re won $100, you probably wouldn’t even bother to collect your prize.
This can be seen as strange; the second $100 prize is not less money than the first $100 prize. However, it’s perceived to be very different.
If, instead of being $100, the cash prize were “equal to whatever you have in your bank account” – so the person with $100 gets $100 and the person with $1,000,000 gets $1,000,000, then they would both be equally excited.
The way we perceive audio signals is similar. Let’s say that you are listening to a song by Metallica at some level, and I ask you to turn it down, and you do. Then I ask you to turn it down by the same amount again, and you do. Then I ask you to turn it down by the same amount again, and you do… If I were to measure what just happened to the gain value, what would I find?
Well, let’s say that, the first time, you dropped the gain to 70% of the original level, so (for example) you went from multiplying the audio signal by 1 to multiplying the audio signal by 0.7 (a reduction of 0.3, if we were subtracting, which we’re not). The second time, you would drop by the same amount – which is 70% of that – so from 0.7 to 0.49 (notice that you did not subtract 0.3 to get to 0.4). The third time, you would drop from 0.49 to 0.343. (not subtracting 0.3 from 0.4 to get to 0.1).
In other words, each time you change the volume level by the “same amount”, you’re doing a multiplication in your head (although you don’t know it) – in this example, by 0.7. The important thing to note here is that you are NOT subtracting 0.3 from the gain in each of the above steps – you’re multiplying by 0.7 each time.
What happens if I were to express the above as percentages? Then our volume steps (and some additional ones) would look like this:
100% 70% 49% 34% 24% 17% 12% 8%
Notice that there is a different “distance” between each of those steps if we’re looking at it linearly (if we’re just subtracting adjacent values to find the difference between them). However, each of those steps is a reduction to 70% of the previous value.
This is a case where the numbers (as I’ve expressed them there) don’t match our experience. We hear each reduction in level as the same as the other steps, but they don’t look like they’re the same step size when we write them all down the way I’ve done above. (In other words, the numerical “distance” between 100 and 70 is not the same as the numerical “distance” between 49 and 34, but these steps would sound like the same difference in audio level.)
SIDEBAR: This is very similar / identical to the way we hear and express frequency changes. For example, the figure below shows a musical staff. The red brackets on the left show 3 spacings of one octave each; the distance between each of the marked frequencies sound the same to us. However, as you can see by the frequency indications, each of those octaves has a very different “width” in terms of frequency. Seen another way, the distance in Hertz in the octave from 440 Hz to 880 Hz is equal to the distance from 440 Hz all the way down to 0 Hz (both have a width of 440 Hz). However, to us, these sound like very different intervals.
SIDEBAR to the SIDEBAR: This also means that the distance in Hertz covered by the top octave on a piano is larger than the the distance covered by all of the other keys.
SIDEBAR to the SIDEBAR to the SIDEBAR: This also means that changing your sampling rate from 48 kHz to 96 kHz doubles your bandwidth, but only gives you an extra octave. However, this is not an argument against high-resolution audio, since the frequency range of the output is a small part of the list of pro’s and con’s.)
This is why people who deal with audio don’t use percent – ever. Instead, we use an extra bit of math that uses an evil concept called a logarithm to help to make things make more sense.
What is a logarithm?
If I say the following, you should not raise your eyebrows:
2*3 = 6, therefore 6/2 = 3 and 6/3 = 2
In other words, division is just multiplication done backwards. This can be generalised to the following:
if a*b=c, then c/a=b and c/b=a
Logarithms are similar; they’re just exponents done backwards. For example:
102 = 100, therefore Log10(100) = 2
and generally:
AB=C, therefore LogA(C) = B
Why use a logarithm?
The nice thing about logarithms is that they are a convenient way for a mathematician to do addition instead of multiplication.
For example, if I have the following sequence of numbers:
2, 4, 8, 16, 32, 64, and so on…
It’s easy to see that I’m just multiplying by 2 to get the next number.
What if I were to express the number sequence above as a series of exponents? Then it would look like this:
21, 22, 23, 24, 25, 26
Not useful yet…
What if I asked you to multiply two numbers in that sequence? Say, for example, 1024 * 8192. This would take some work (or at least some scrambling, looking for the calculator app on your phone…). However, it helps to know that this is the same as asking you to multiply 210 * 213 – to which the answer is 223. Notice that 23 is merely 10+13. So, I’ve used exponents to convert the problem from multiplication (1024*8192) to addition (210 * 213 = 2(10+13)).
How did I find out that 8192 = 213? By using a logarithm : Log2(8192) = 13.
In the old days, you would have been given a book of logarithmic tables in school, which was a way of looking up the logarithm of 8192. (Actually, those books were in base 10 and not base 2, so you would have found out that Log10(8192) = 3.9013, which would have made this discussion more confusing…) Nowadays, you can use an antique device called a “calculator” – a simulacrum of which is probably on a device you call a “phone” but is rarely used as such.
I will leave it to the reader to figure out why this quality of logarithms (that they convert multiplication into addition) is why slide rules work.
So what?
Let’s go back to the problem: We want to make a volume slider (or knob) where an equal distance (or rotation) corresponds to an equal change in level. Let’s do a simple one that has 10 steps. Coming down from “maximum” (which we’ll say is a gain of 1 or 100%), it could look like these:
The gain values for four different versions of a 10-step volume control.
The plot above shows four different options for our volume controller. Starting at the maximum (volume step 10) and working downwards to the left, each one drops by the same perceived amount per step. The Black plot shows a drop of 90% per step, the red plot shows a drop of 70% per step (which matches the list of values I put above), Blue is 50% per step, and green is 30% per step.
As you can see, these lines are curved. As you can also see, as you get lower and lower, they get to the point where it gets harder to see the value (for example, the green curve looks like it has the same gain value for Volume steps 1 through 4).
However, we can view this a different way. If we change the scale of our graph’s Y-Axis to a logarithmic one instead of a linear one, the exact same information will look like this:
The same data plotted using a different scale for the Y-Axis.
Notice now that the Y-axis has an equal distance upwards every time the gain multiplies by 10 (the same way the music staff had the same distance every time we multiplied the frequency by 2). By doing this, we now see our gain curves as straight lines instead of curved ones. This makes it easy to read the values both when they’re really small and when they’re (comparatively) big (those first 4 steps on the green curve don’t look the same on that plot).
So, one way to view the values for our Volume controller is to calculate the gains, and then plot them on a logarithmic graph. The other way is to build the logarithm into the gain itself, which is what we do. Instead of reading out gain values in percent, we use Bels (named after Alexander Graham Bell). However, since a Bel is a big step, we we use tenths of a Bel or “decibels” instead. (… In the same way that I tell people that my house is 4,000 km, and not 4,000,000 m from my Mom’s house because a metre is too small a division for a big distance. I also buy 0.5 mm pencil leads – not 0.0005 m pencil leads. There are many times when the basic unit of measurement is not the right scale for the thing you’re talking about.)
In order to convert our gain value (say, of 0.7) to decibels, we do the following equation:
20 * Log10(gain) = Gain in dB
So, we would say
20 * Log10(0.7) = -3.01 dB
I won’t explain why we say 20 * the logarithm, since this is (only a little) complicated.
I will explain why it’s small-d and capital-B when you write “dB”. The small-d is the convention for “deci-“, so 1 decimetre is 1 dm. The capital-B is there because the Bel is named after Alexander Graham Bell. This is similar to the reason we capitalize Hz, V, A, and so on…
So, if you know the linear gain value, you can calculate the equivalent in decibels. If I do this for all of the values in the plots above, it will look like this:
Notice that, on first glance, this looks exactly like the plot in the previous figure (with the logarithmic Y-Axis), however, the Y-Axis on this plot is linear (counting from -100 to 0 in equal distances per step) because the logarithmic scaling is already “built into” the values that we’re plotting.
For example, if we re-do the list of gains above (with a little rounding), it becomes
100% = 0 dB 70% = -3 dB 49% = -6 dB 34% = -9 dB 24% = -12 dB 17% = -15 dB 12% = -18 dB 8% = -21 dB
Notice coming down that list that each time we multiplied the linear gain by 0.7, we just subtracted 3 from the decibel value, because, as we see in the equation above, these mean the same thing.
This means that we can make a volume control – whether it’s a slider or a rotating knob – where the amount that you move or turn it corresponds to the change in level. In other words, if you move the slider by 1 cm or rotate the knob by 10º – NO MATTER WHERE YOU ARE WITHIN THE RANGE – the change is level will be the same as if you made the same movement somewhere else.
This is why Bang & Olufsen devices made since about 1990 (give or take) have a volume control in decibels. In older models, there were 79 steps (0 to 78) or 73 steps (0 to 72), which was expanded to 91 steps (0 to 90) around the year 2000, and expanded again recently to 101 steps (0 to 100). Each step on the volume control corresponds to a 1 dB change in the gain. So, if you change the volume from step 30 to step 40, the change in level will appear to be the same as changing from step 50 to step 60.
Volume Step ≠ Output Level
Up to now, all I’ve said can be condensed into two bullet points:
Volume control is a change in the gain value that is multiplied by the incoming signal
We express that gain value in decibels to better match the way we hear changes in level
Notice that I didn’t say anything in those two statements about how loud things actually are… This is because the volume setting has almost nothing to do with the level of the output, which, admittedly, is a very strange thing to say…
For example, get a DVD or Blu-ray player, connect it to a television, set the volume of the TV to something and don’t touch it for the rest of this experiment. Now, put in a DVD copy of any movie that has ONLY dialogue, and listen to how loud it sounds. Then, take out the DVD and put in a CD of Metallica’s Death Magnetic, press play. This will be much, much louder. In fact, if you own a B&O TV, the difference in level between those two things is the same as turning up the volume by 31 steps, which corresponds to 31 dB. Why?
When re-recording engineers mix a movie, they aim to make the dialogue sit around a level of 31 dB below maximum (better known as -31 dB FS or “31 decibels below Full Scale”). This gives them enough “headroom” to get much louder for explosions and gunshots to be exciting.
When a mixing engineer and a mastering engineer work on a pop or rock album, it’s not uncommon for them to make it as loud as possible, aiming for maximum (better known as 0 dB FS).
This means that a movie’s dialogue is much quieter than Metallica or Billie Eilish or whomever is popular when you’re reading this, because Metallica is as loud as the explosions in the movie.
The volume setting is just a value that changes that input level… So, If I listen to music at volume step 42 on a Beovision television, and you watch a movie at volume step 73 on the same Beovision television, it’s possible that we’re both hearing the same sound pressure level in our living rooms, because the music is 31 dB louder than the movie, which is the same amount that I’ve turned down my TV relative to yours (73-42 = 31).
In other words, the Volume Setting is not a predictor of how loud it is. A Volume Setting is a little like the accelerator pedal in your car. You can use the pedal to go faster or slower, but there’s no way of knowing how fast you’re driving if you only know how hard you’re pushing on the pedal.
What about other brands and devices?
This is where things get really random:
take any device (or computer or audio software)
play a sine wave (because thats easy to measure)
measure the change in output level as you change the volume setting
graph the result
Repeat everything above for different devices
You’ll see something like this:
The gain vs. Volume step behaviours of 8 different devices / software players
there are two important things to note in the above plot.
These are the measurements of 8 different devices (or software players or “apps”) and you get 8 different results (although some of them overlap, but this is because those are just different version numbers of the same apps).
Notice as well that there’s a big difference here. At a volume setting of “50%” there’s a 20 dB difference between the blue dashed line and the black one with the asterisk markings. 20 dB is a LOT.
None of them look like the straight lines seen in the previous plot, despite the fact that the Y-axis is in decibels. In ALL of these cases, the biggest jumps in level happen at the beginning of the volume control (some are worse than others). This is not only because they’re coming up from a MUTE state – but because they’re designed that way to fool you. How?
Think about using any of these controllers: you turn it 25% of the way up, and it’s already THIS loud! Cool! This speaker has LOTS of power! I’m only at 25%! I’ll definitely buy it! But the truth is, when the slider / knob is at 25% of the way up, you’re already pushing close to the maximum it can deliver.
These are all the equivalent of a car that has high acceleration when starting from 0 km/h, but if you’re doing 100 km/h on the highway, and you push on the accelerator, nothing happens.
First impressions are important…
On the other hand (in support of thee engineers who designed these curves), all of these devices are “one-offs” (meaning that they’re all stand-alone devices) made by companies who make (or expect to be connected to) small loudspeakers. This is part of the reason why the curves look the way they do.
If B&O used those style of gain curves for a Beovision television connected to a pair of Beolab 90s, you’d either
be listening at very loud levels, even at low volume settings;
or you wouldn’t be able to turn it up enough for music with high dynamic range.
Some quick conclusions
Hopefully, if you’ve read this far and you’re still awake:
you will never again use “percent” to describe your volume level
you will never again expect that the output level can be predicted by the volume setting
you will never expect two devices of two different brands to output the same level when set to the same volume setting
you understand why B&O devices have so many volume steps over such a large range.
The magnitude response* of any audio device is a measure of how much its output level deviates from the expected level at different frequencies. In a turntable, this can be measured in different ways.
Usually, the magnitude response is measured from a standard test disc with a sine wave sweep ranging from at least 20 Hz to at least 20 kHz. The output level of this signal is recorded at the output of the device, and the level is analysed to determine how much it differs from the expected output. Consequently, the measurement includes all components in the audio path from the stylus tip, through the RIAA preamplifier (if one is built into the turntable), to the line-level outputs.
Because all of these components are in the signal path, there is no way of knowing immediately whether deviations from the expected response are caused by the stylus, the preamplifier, or something else in the chain.
It’s also worth noting that a typical standard test disc (JVC TRS-1007 is a good example) will not have a constant output level, which you might expect if you’re used to measuring other audio devices. Usually, the swept sine signal has a constant amplitude in the low frequency bands (typically, below 1 kHz) and a constant modulation velocity in the high frequencies. This is to avoid over-modulation in the low end, and burning out the cutter head during mastering in the high end.
* This is the correct term for what is typically called the “frequency response”. The difference is that a magnitude response only shows output level vs. frequency, whereas the frequency response would include both level and phase information.
Rumble
In theory, an audio playback device only outputs the audio signal that is on the recording without any extra contributions. In practice, however, every audio device adds signals to the output for various reasons. As was discussed above, in the specific case of a turntable, the audio signal is initially generated by very small movements of the stylus in the record groove. Therefore, in order for it to work at all, the system must be sensitive to very small movements in general. This means that any additional movement can (and probably will) be converted to an audio signal that is added to the recording.
This unwanted extraneous movement, and therefore signal, is usually the result of very low-frequency vibrations that come from various sources. These can include things like mechanical vibrations of the entire turntable transmitted through the table from the floor, vibrations in the system caused by the motor or imbalances in the moving parts, warped discs which cause a vertical movement of the stylus, and so on. These low-frequency signals are grouped together under the heading of rumble.
A rumble measurement is performed by playing a disc that has no signal on it, and measuring the output signal’s level. However, that output signal is first filtered to ensure that the level detection is not influenced by higher-frequency problems that may exist.
The characteristics of the filters are defined in internal standards such as DIN 45 539 (or IEC98-1964), shown below. Note that I’ve only plotted the target response. The specifications allow for some deviation of ±1 dB (except at 315 Hz). Notice that the low-pass filter is the same for both the Weighted and the Unweighted filters. Only the high-pass filter specifications are different for the two cases.
The magnitude responses for the “Unweighted” (black) and “Weighted” filters for rumble measurements, specified in DIN 45 539
If the standard being used for the rumble measurement is the DIN 45 539 specification, then the resulting value is stated as the level difference between the measured filtered noise and a the standard output level, equivalent to the output when playing a 1 kHz tone with a lateral modulation velocity of 70.7 mm/sec. This detail is also worth noting, since it shows that the rumble value is a relative and not an absolute output level.
Rotational speed
Every recording / playback system, whether for audio or for video signals, is based on the fundamental principle that the recording and the playback happen at the same rate. For example, a film that was recorded at 24 frames (or photos) per second (FPS) must also be played at 24 FPS to avoid objects and persons moving too slowly or too quickly. It’s also necessary that neither the recording nor the playback speed changes over time.
A phonographic LP is mastered with the intention that it will be played back at a rotational speed of 33 1/3 RPM (Revolutions Per Minute) or 45 RPM, depending on the disc. (These correspond to 1 revolution either every 1.8 seconds or every 1 1/3 seconds respectively.) We assume that the rotational speed of the lathe that was used to cut the master was both very accurate and very stable. Although it is the job of the turntable to duplicate this accuracy and stability as closely as possible, measurable errors occur for a number of reasons, both mechanical and electrical. When these errors are measured using especially-created audio signals like pure sine tones, the results are filtered and analyzed to give an impression of how audible they are when listening to music. However, a problem arises in that a simple specification (such as a single number for “Wow and Flutter”, for example) can only be correctly interpreted with the knowledge of how the value is produced.
Accuracy
The first issue is the simple one of accuracy: is the turntable rotating the disc at the correct average speed? Most turntables have some kind of user control of this (both for the 33 and 45 RPM settings), since it will likely be necessary to adjust these occasionally over time, as the adjustment will drift with influences such as temperature and age.
Stability
Like any audio system, regardless of whether it’s analogue or digital, the playback speed of the turntable will vary over time. As it increases and decreases, the pitch of the music at the output will increase and decrease proportionally. This is unavoidable. Therefore, there are two questions that result:
How much does the speed change?
What is the rate and pattern of the change?
In a turntable, the amount of the change in the rotational speed is directly proportional to the frequency shift in the audio output. Therefore for example, if the rotational speed decreases by 1% (for example, from 33 1/3 RPM to exactly 33 RPM), the audio output will drop in frequency by 1% (so a 440 Hz tone will be played as a 440 * 0.99 = 435.6 Hz tone). Whether this is audible is dependent on different factors including
the rate of change to the new speed (a 1% change 4 times a second is much easier to hear than a 1% change lasting 1 hour)
the listener’s abilities (for example, a person with “absolute pitch” may be able to recognise the change)
the audio signal (It is easier to detect a frequency shift of a single, long tone such as a note on a piano or pipe organ than it is of a short sound like a strike of claves or a sound with many enharmonic frequencies such as a snare drum.)
In an effort to simplify the specification of stability in analogue playback equipment such as turntables, four different classifications are used, each corresponding to different rates of change. These are drift, wow, flutter, and scrape, the two most popular of which are wow and flutter, and are typically grouped into one value to represent them.
Drift
Frequency drift is the tendency of a playback device’s speed to change over time very slowly. Any variation that happens slower than once every 2 seconds (in other words, with a modulation frequency of less than 0.5 Hz) is considered to be drift. This is typically caused by changes such as temperature (as the playback device heats up) or variations in the power supply (due to changes in the mains supply, which can vary with changing loads throughout the day).
Wow
Wow is a modulation in the speed ranging from once every 2 seconds to 6 times a second (0.5 Hz to 6 Hz). Note that, for a turntable, the rotational speed of the disc is within this range. (At 33 1/3 RPM: 1 revolution every 1.8 seconds is equal to approximately 0.556 Hz.)
Flutter
Flutter describes a modulation in the speed ranging from 6 to 100 times a second (6 Hz to 100 Hz).
Scrape
Scrape or scrape flutter describes changes in the speed that are higher than 100 Hz. This is typically only a problem with analogue tape decks (caused by the magnetic tape sticking and slipping on components in its path) and is not often used when classifying turntable performance.
Measurement and Weighting
The easiest accurate method to measure the stability of the turntable’s speed within the range of Wow and Flutter is to follow one of the standard methods, of which there are many, but they are all similar. Examples of these standards are AES6-2008, CCIR 409-3, DIN 45507, and IEC-386. A special measurement disc containing a sine tone, usually with a frequency of 3150 Hz is played to a measurement device which then does a frequency analysis of the signal. In a perfect system, the result would be a 3150 Hz sine tone. In practice, however, the frequency of the tone varies over time, and it is this variation that is measured and analysed.
There is general agreement that we are particularly sensitive to a modulation in frequency of about 4 Hz (4 cycles per second) applied to many audio signals. As the modulation gets slower or faster, we are less sensitive to it, as was illustrated in the example above: (a 1% change 4 times a second is much easier to hear than a 1% change lasting 1 hour).
So, for example, if the analysis of the 3150 Hz tone shows that it varies by ±1% at a frequency of 4 Hz, then this will have a bigger impact on the result than if it varies by ±1% at a frequency of 0.1 Hz or 40 Hz. The amount of impact the measurement at any given modulation frequency has on the total result is shown as a “weighting curve” in the figure below.
Weighting applied to the Wow and Flutter measurement in most standard methods. See the text for an explanation.
As can be seen in this curve, a modulation at 4 Hz has a much bigger weight (or impact) on the final result than a modulation at 0.315 Hz or at 140 Hz, where a 20 dB attenuation is applied to their contribution to the total result. Since attenuating a value by 20 dB is the same as dividing it by 10; a ±1% modulation of the 3150Hz tone at 4 Hz will produce the same result as a ±10% modulation of the 3150 Hz tone at 140 Hz, for example.
This shows just one example of why comparing one Wow and Flutter measurement value should be interpreted very cautiously.
Expressing the result
When looking at a Wow and Flutter specification, one will see something like <0.1%, <0.05% (DIN), or <0.1% (AES6). Like any audio specification, if the details of the measurement type are not included, then the value is useless. For example, “W&F: <0.1%” means nothing, since there is no way to know which method was used to arrive at this value.(Similarly, a specification like “Frequency Range: 20 Hz to 20 kHz” means nothing, since there is no information about the levels used to define the range.)
If the standard is included in the specification (DIN or AES6, for example), then it is still difficult to compare wow and flutter values. This is because, even when performing identical measurements and applying the same weighting curve shown in the figure above, there are different methods for arriving at the final value. The value that you see may be a peak value (the maximum deviation from the average speed), the peak-to-peak value (the difference between the minimum and the maximum speeds), the RMS (a version of the average deviation from the average speed), or something else.
The AES6-2008 standard, which is the currently accepted method of measuring and expressing the wow and flutter specification, uses a “2-sigma” method, which is a way of looking at the peak deviation to give a kind of “worst-case” scenario. In this method, the 3150 Hz tone is played from a disc and captured for as long a time as is possible or feasible. Firstly, the average value of the actual frequency of the output is found (in theory, it’s fixed at 3150 Hz, but this is never true). Next, the short-term variation of the actual frequency over time is compared to the average, and weighted using the filter shown above. The result shows the instantaneous frequency variations over the length of the captured signal, relative to the average frequency (however, the effect of very slow and very fast changes have been reduced by the filter). Finally, the standard deviation of the variation from the average is calculated, and multiplied by 2 (“2-Sigma”, or “two times the standard deviation”), resulting in the value that is shown as the specification. The reason two standard deviations is chosen is that (in the typical case where the deviation has a Gaussian distribution) the actual Wow & Flutter value should exceed this value no more than 5% of the time.
The reason this method is preferred today is that it uses a single number to express not only the wow and flutter, but the probability of the device reaching that value. For example, if a device is stated to have a “Wow and Flutter of <1% (AES6)”, then the actual deviation from the average speed will be less than 1% for 95% of the time you are listening to music. The principal reason this method was not used in the “old days” is that it requires statistical calculations applied to a signal that was captured from the output of the turntable, an option that was not available decades ago. The older DIN method that was used showed a long-term average level that was being measured in real-time using analogue equipment such as the device shown in below.
Bang & Olufsen WM1, analogue wow and flutter meter.
Unfortunately, however, it is still impossible to know whether a specification that reads “Wow and Flutter: 1% (AES6)” means 1% deviation with a modulation frequency of 4 Hz or 10% deviation with a modulation frequency of 140 Hz – or something else. It is also impossible to compare this value to a measurement done with one of the older standards such as the DIN method, for example.
As was discussed in Part 3, when a record master is cut on a lathe, the cutter head follows a straight-line path as it moves from the outer rim to the inside of the disk. This means that it is always modulating in a direction that is perpendicular to the groove’s relative direction of travel, regardless of its distance from the centre.
The direction of travel of the cutting head when the master disk is created on a lathe.
A turntable should be designed to ensure that the stylus tracks the groove made by the cutter head in all aspects. This means that this perpendicular angle should be maintained across the entire surface of the disk. However, in the case of a tonearm that pivots, this is not possible, since the stylus follows a circular path, resulting in an angular tracking error.
Any tonearm has some angular tracking error that varies with position on the disk.
The location of the pivot point, the tonearm’s shape, and the mounting of the cartridge can all contribute to reducing this error. Typically, tonearms are designed so that the cartridge is angled to not be in-line with the pivot point. This is done to ensure that there can be two locations on the record’s surface where the stylus is angled correctly relative to the groove.
A correctly-designed and aligned pivoting tonearm has a tracking error of 0º at only two locations on the disk.
However, the only real solution is to move the tonearm in a straight line across the disc, maintaining a position that is tangential to the groove, and therefore keeping the stylus located so that its movement is perpendicular to the groove’s relative direction of travel, just as it was with the cutter head on the lathe.
A tonearm that travels sideways, maintaining an angle that is tangent to the groove at the stylus.
In a perfect system, the movement of the tonearm would be completely synchronous with the sideways “movement” of the groove underneath it, however, this is almost impossible to achieve. In the Beogram 4000c, a detection system is built into the tonearm that responds to the angular deviation from the resting position. The result is that the tonearm “wiggles” across the disk: the groove pulls the stylus towards the centre of the disk for a small distance before the detector reacts and moves the back of the tonearm to correct the angle.
Typically, the distance moved by the stylus before the detector engages the tracking motor is approximately 0.1 mm, which corresponds to a tracking error of approximately 0.044º.
An exaggerated representation of the maximum tracking error of the tonearm before the detector engages and corrects.
One of the primary artefacts caused by an angular tracking error is distortion of the audio signal: mainly second-order harmonic distortion of sinusoidal tones, and intermodulation distortion on more complex signals. (see “Have Tone Arm Designers Forgotten Their High-School Geometry?” in The Audio Critic, 1:31, Jan./Feb., 1977.) It can be intuitively understood that the distortion is caused by the fact that the stylus is being moved at a different angle than that for which it was designed.
It is possible to calculate an approximate value for this distortion level using the following equation:
Where is the harmonic distortion in percent, is the angular frequency of the modulation caused by the audio signal (calculated using ), is the peak amplitude in mm, is the tracking error in degrees, is the angular frequency of rotation (the speed of the record in radians per second. For example, at 33 1/3 RPM, ) and is the radius (the distance of the groove from the centre of the disk). (see “Tracking Angle in Phonograph Pickups” by B.B. Bauer, Electronics (March 1945))
This equation can be re-written, separating the audio signal from the tonearm behaviour, as shown below.
which shows that, for a given audio frequency and disk rotation speed, the audio signal distortion is proportional to the horizontal tracking error over the distance of the stylus to the centre of the disk. (This is the reason one philosophy in the alignment of a pivoting tonearm is to ensure that the tracking error is reduced when approaching the centre of the disk, since the smaller the radius, the greater the distortion.)
It may be confusing as to why the position of the groove on the disk (the radius) has an influence on this value. The reason is that the distortion is dependent on the wavelength of the signal encoded in the groove. The longer the wavelength, the lower the distortion. As was shown in Figure 1 in Part 6 of this series, the wavelength of a constant frequency is longer on the outer groove of the disk than on the inner groove.
Using the Beogram 4000c as an example at its worst-case tracking error of 0.044º: if we have a 1 kHz sine wave with a modulation velocity of 34.1 mm/sec on a 33 1/3 RPM LP on the inner-most groove then the resulting 2nd-harmonic distortion will be 0.7% or about -43 dB relative to the signal. At the outer-most groove (assuming all other variables remain constant), the value will be roughly half of that, at 0.3% or -50 dB.
In order to keep the stylus tip in the groove of the record, it must have some force pushing down on it. This force must be enough to keep the stylus in the groove. However, if it is too large, then both the vinyl and the stylus will wear more quickly. Thus a balance must be found between “too much” and “not enough”.
Figure 1: Typical tracking force over time. The red portion of the curve shows the recommendation for Beogram 4002 and Beogram 4000c.
As can be seen in Figure 1, the typical tracking force of phonograph players has changed considerably since the days of gramophones playing shellac discs, with values under 10 g being standard since the introduction of vinyl microgroove records in 1948. The original recommended tracking force of the Beogram 4002 was 1 g, however, this has been increased to 1.3 g for the Beogram 4000c in order to help track more recent recordings with higher modulation velocities and displacements.
Effective Tip Mass
The stylus’s job is to track all of the vibrations encoded in the groove. It stays in that groove as a result of the adjustable tracking force holding it down, so the moving parts should be as light as possible in order to ensure that they can move quickly. The total apparent mass of the parts that are being moved as a result of the groove modulation is called the effective tip mass. Intuitively, this can be thought of as giving an impression of the amount of inertia in the stylus.
It is important to not confuse the tracking force and the effective tip mass, since these are very different things. Imagine a heavy object like a 1500 kg car, for example, lifted off the ground using a crane, and then slowly lowered onto a scale until it reads 1 kg. The “weight” of the car resting on the scale is equivalent to 1 kg. However, if you try to push the car sideways, you will obviously find that it is more difficult to move than a 1 kg mass, since you are trying to overcome the inertia of all 1500 kg, not the 1 kg that the scale “sees”. In this analogy, the reading on the scale is equivalent to the Tracking Force, and the mass that you’re trying to move is the Effective Tip Mass. Of course, in the case of a phonograph stylus, the opposite relationship is desirable; you want a tracking force high enough to keep the stylus in the groove, and an effective tip mass as close to 0 as possible, so that it is easy for the groove to move it.
Compliance
Imagine an audio signal that is on the left channel only. In this case, the variation is only on one of the two groove walls, causing the stylus tip to ride up and down on those bumps. If the modulation velocity is high, and the effective tip mass is too large, then the stylus can lift off the wall of the groove just like a car leaving the surface of a road on the trailing side of a bump. In order to keep the car’s wheels on the road, springs are used to push them back down before the rest of the car starts to fall. The same is true for the stylus tip. It’s being pushed back down into the groove by the cantilever that provides the spring. The amount of “springiness” is called the compliance of the stylus suspension. (Compliance is the opposite of spring stiffness: the more compliant a spring is, the easier it is to compress, and the less it pushes back.)
Like many other stylus parameters, the compliance is balanced with other aspects of the system. In this case it is balanced with the effective mass of the tonearm (which includes the tracking force(1), resulting in a resonant frequency. If that frequency is too high, then it can be audible as a tone that is “singing along” with the music. If it’s too low, then in a worst-case situation, the stylus can jump out of the record groove.
If a turntable is very poorly adjusted, then a high tracking force and a high stylus compliance (therefore, a “soft” spring) results in the entire assembly sinking down onto the record surface. However, a high compliance is necessary for low-frequency reproduction, therefore the maximum tracking force is, in part, set by the compliance of the stylus.
If you are comparing the specifications of different cartridges, it may be of interest to note that compliance is often expressed in one of five different units, depending on the source of the information:
“Compliance Unit” or “cu”
mm/N millimetres of deflection per Newton of force
µm/mN micrometres of deflection per thousandth of a Newton of force
x 10^-6 cm/dyn hundredths of a micrometre of deflection per dyne of force
x 10^-6 cm / 10^-5 N hundredths of a micrometre of deflection per hundred-thousandth of a Newton of force
Since
mm/N = 1000 µm / 1000 mN
and
1 dyne = 0.00001 Newton
Then this means that all five of these expressions are identical, so, they can be interchanged freely. In other words:









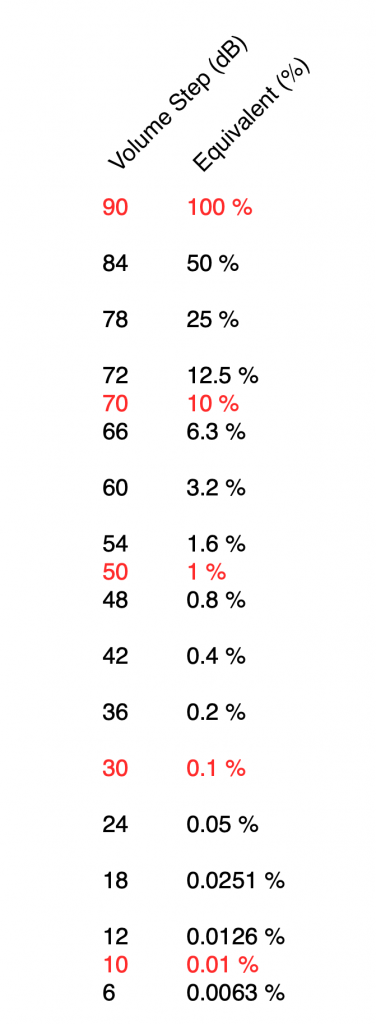
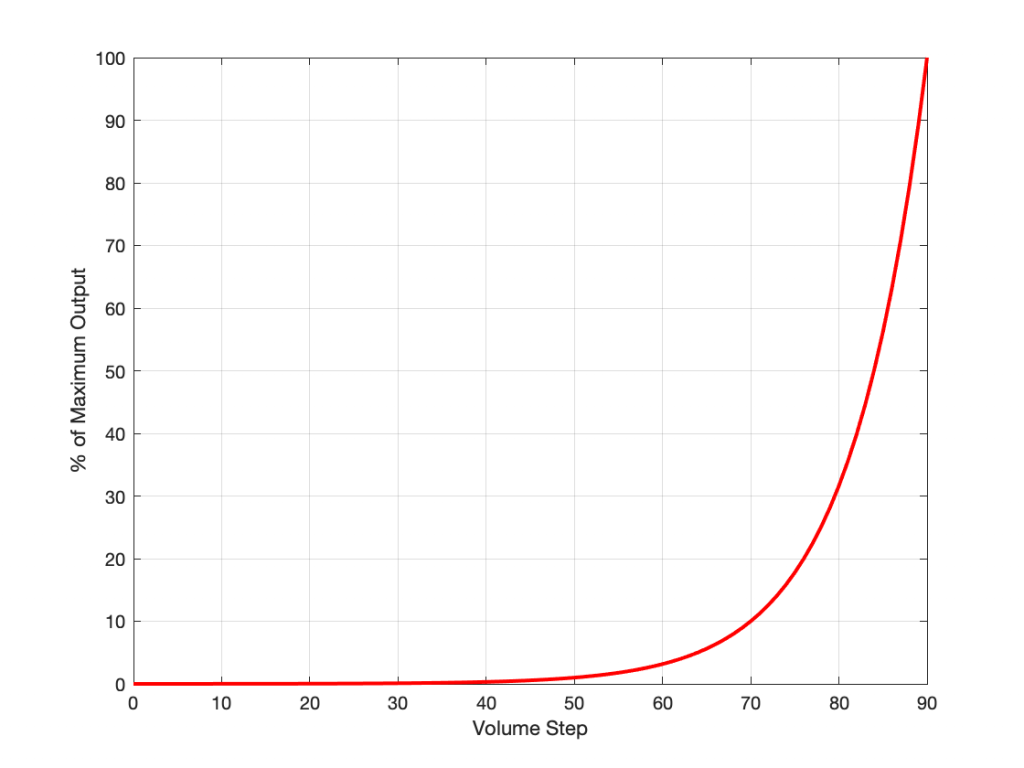
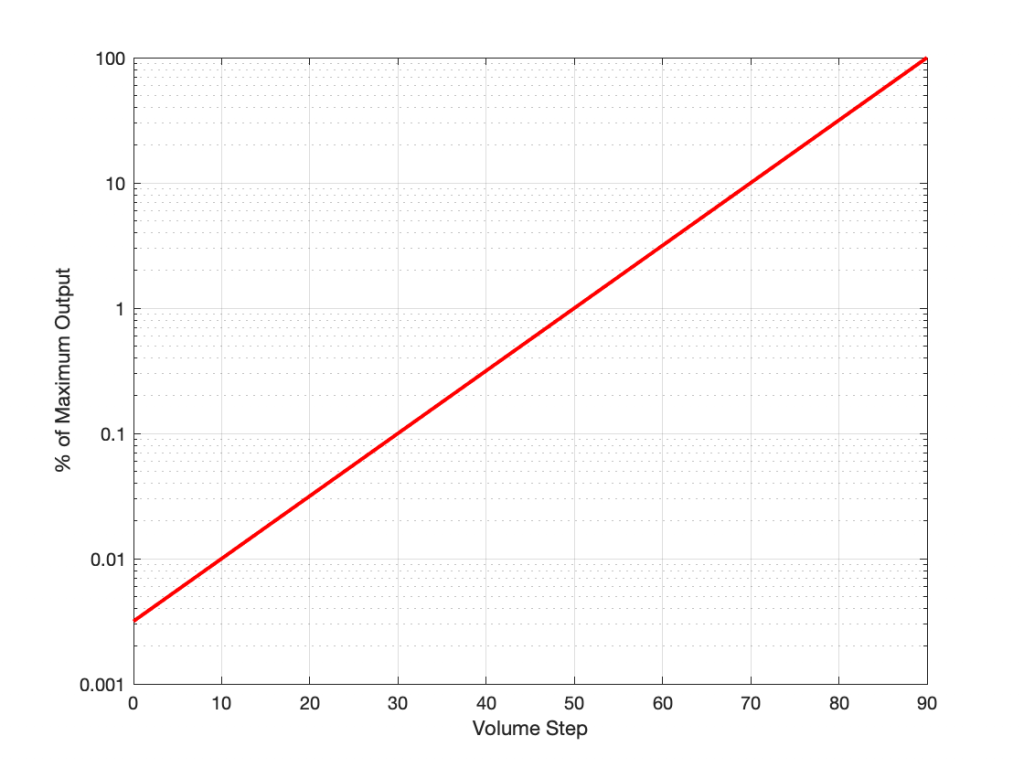
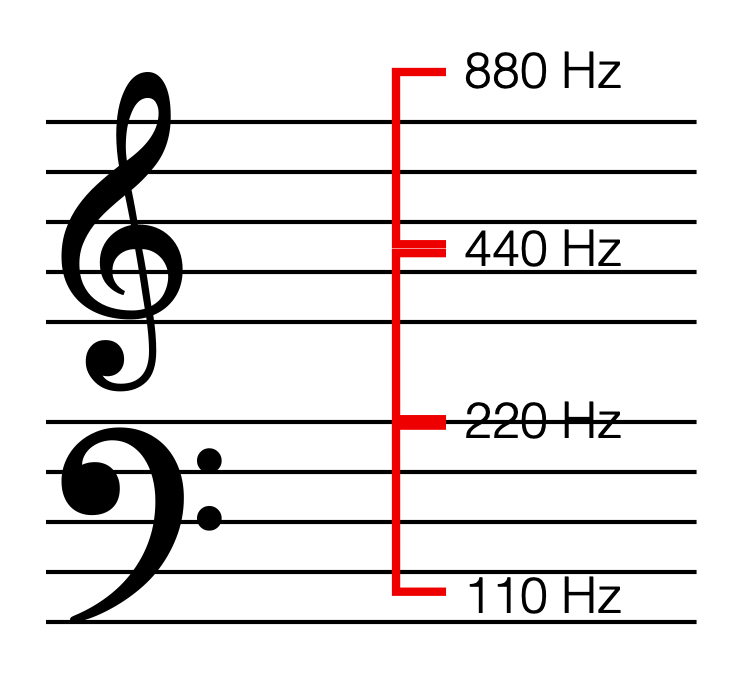
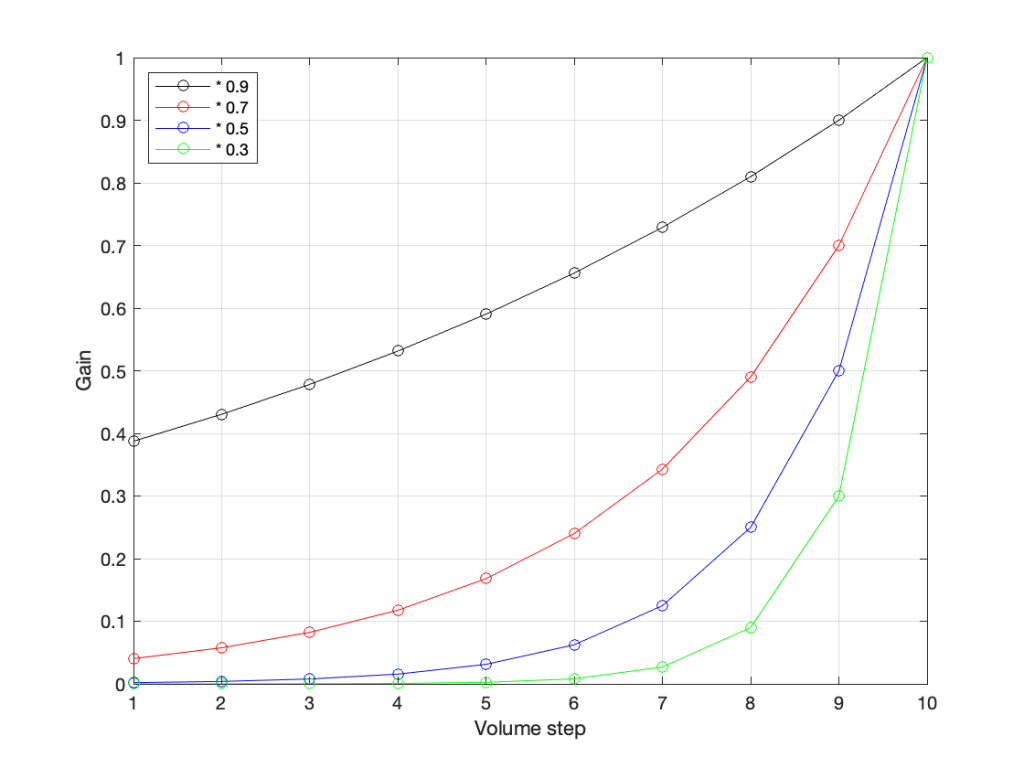
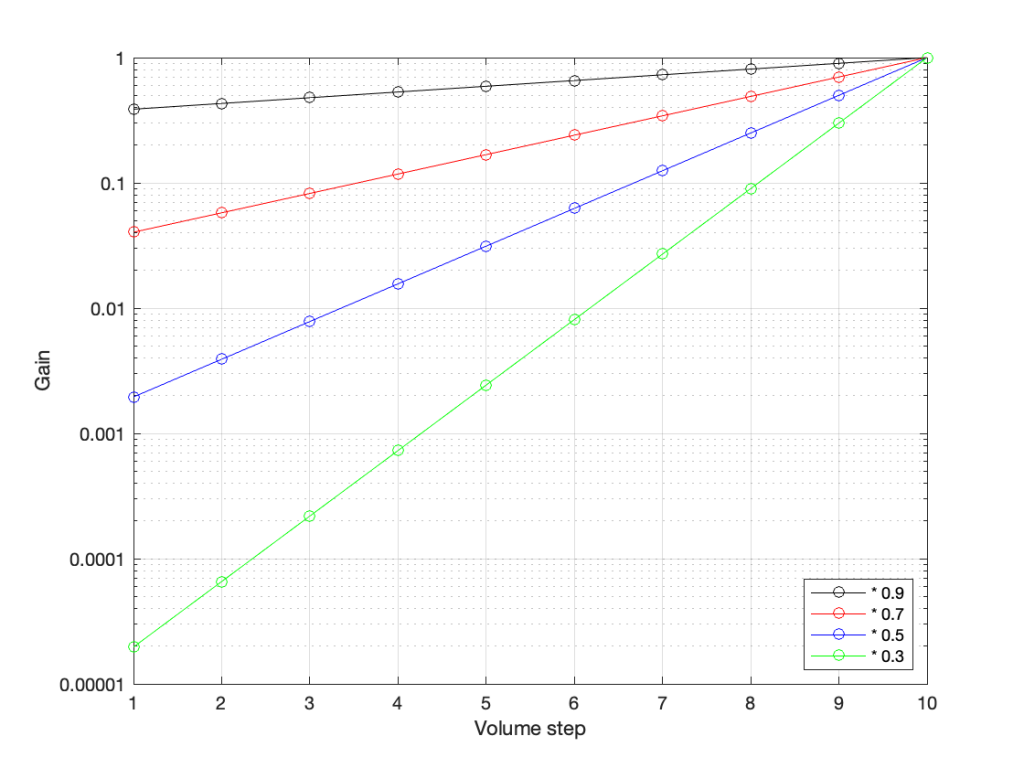
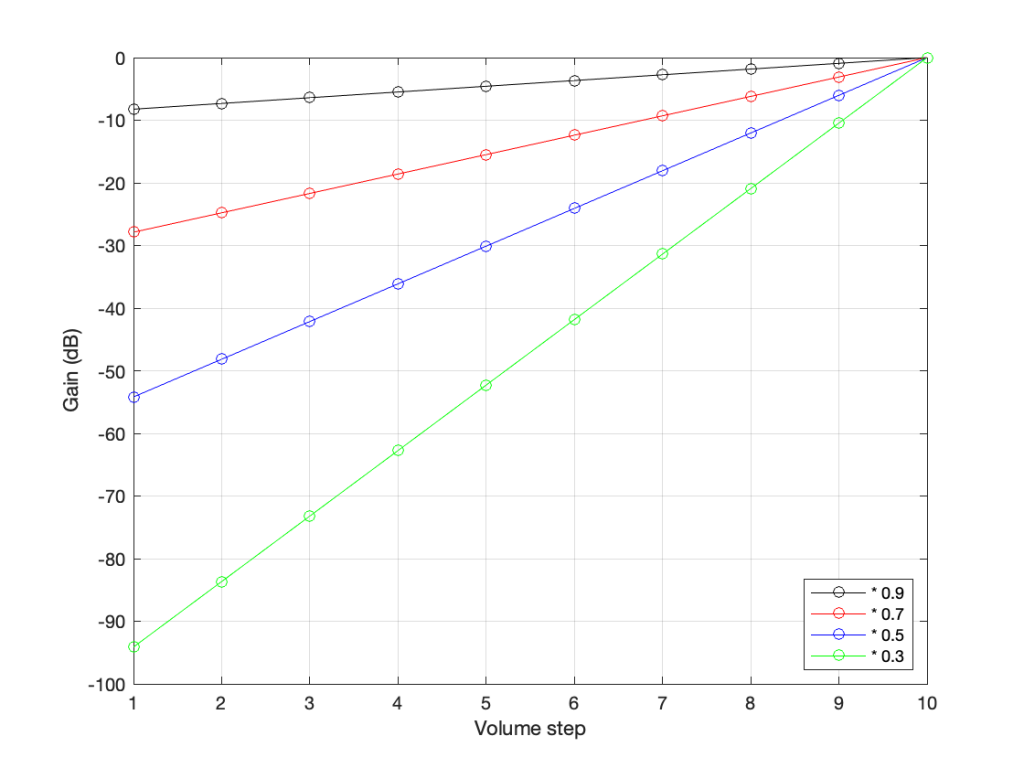
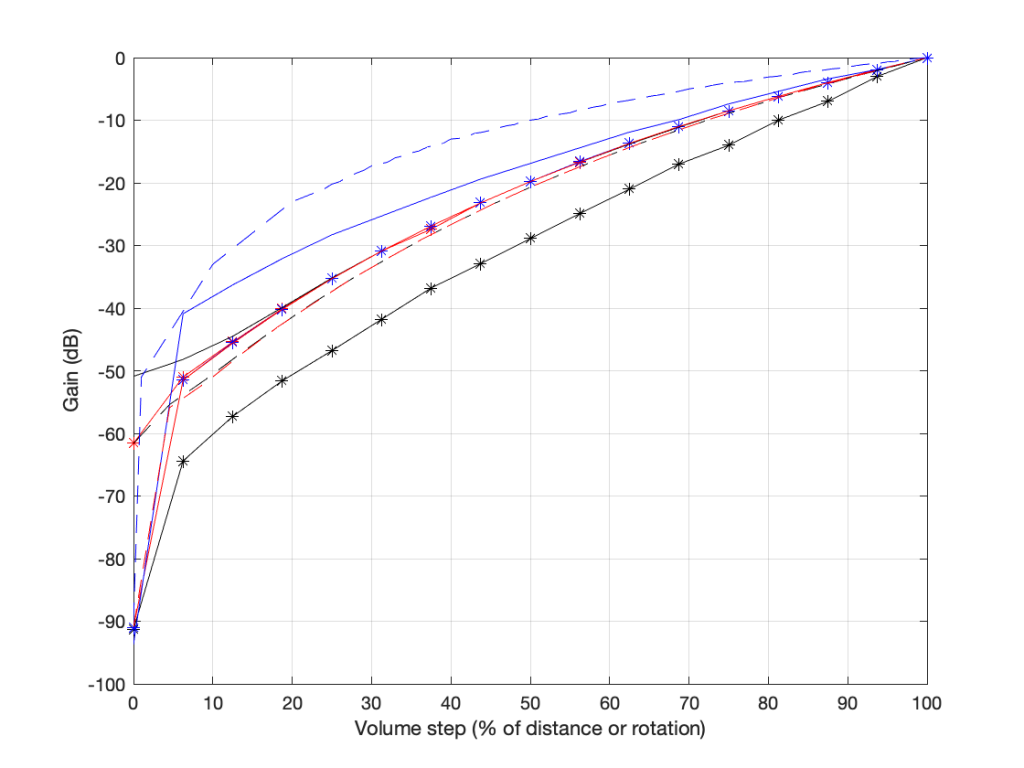
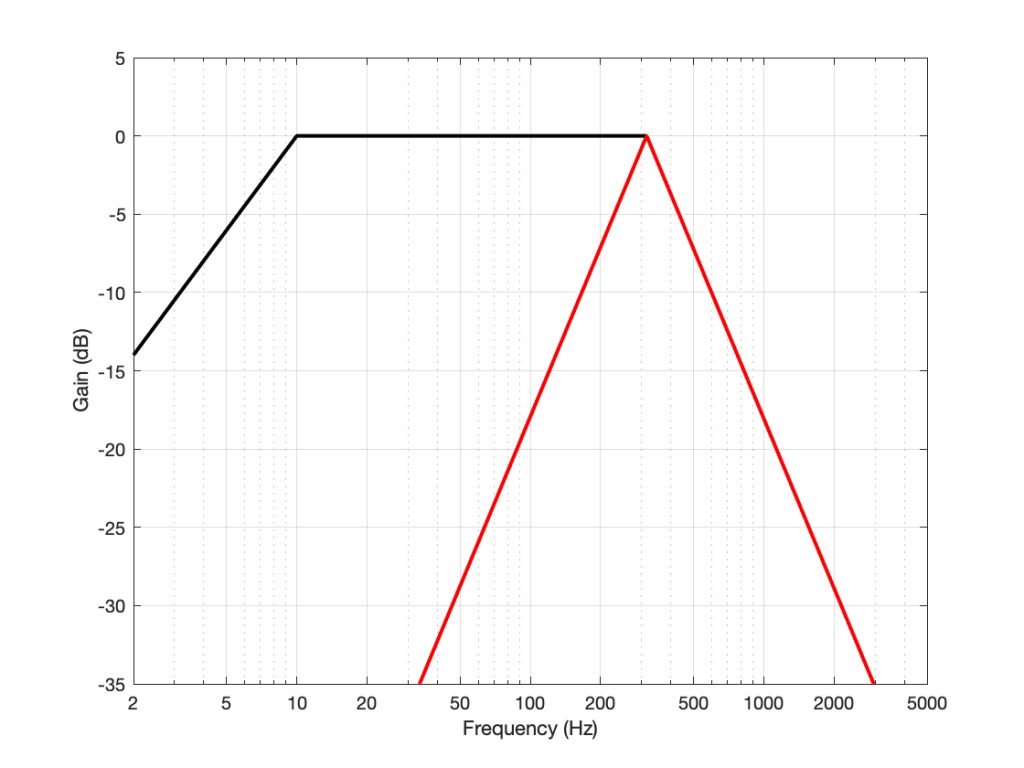
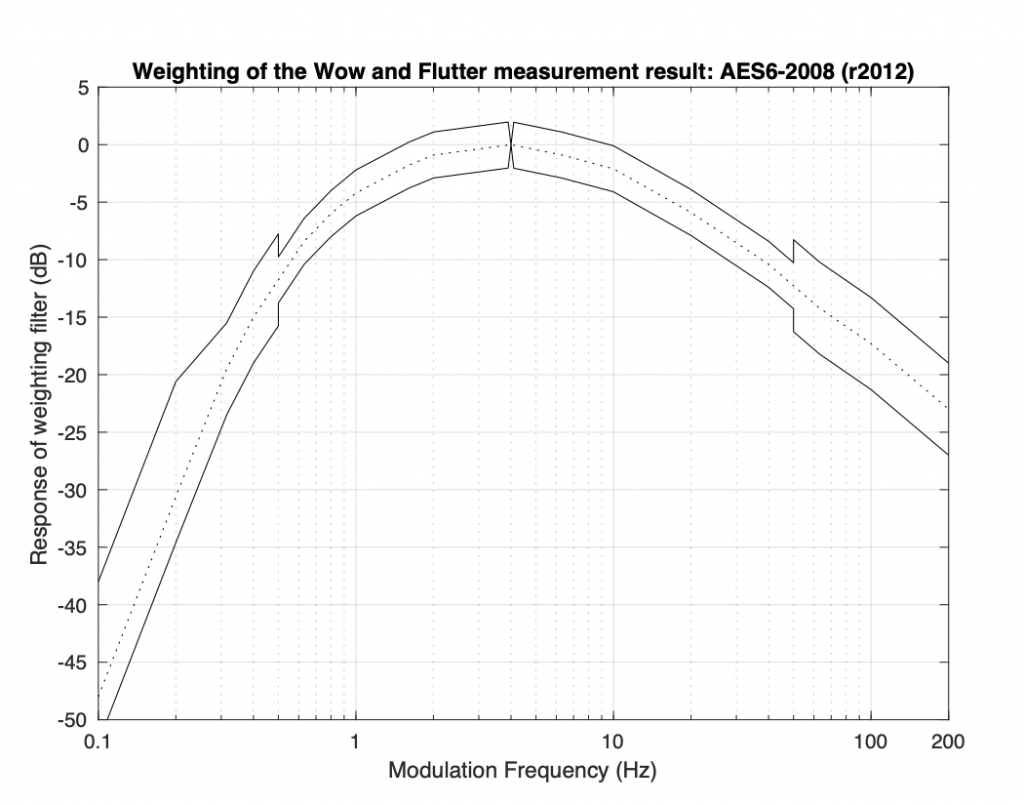

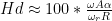
 is the harmonic distortion in percent,
is the harmonic distortion in percent, 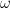 is the angular frequency of the modulation caused by the audio signal (calculated using
is the angular frequency of the modulation caused by the audio signal (calculated using 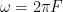 ),
),  is the peak amplitude in mm,
is the peak amplitude in mm,  is the tracking error in degrees,
is the tracking error in degrees, 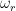 is the angular frequency of rotation (the speed of the record in radians per second. For example, at 33 1/3 RPM,
is the angular frequency of rotation (the speed of the record in radians per second. For example, at 33 1/3 RPM, 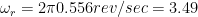 ) and
) and  is the radius (the distance of the groove from the centre of the disk). (see “Tracking Angle in Phonograph Pickups” by B.B. Bauer, Electronics (March 1945))
is the radius (the distance of the groove from the centre of the disk). (see “Tracking Angle in Phonograph Pickups” by B.B. Bauer, Electronics (March 1945))