This episode of The Infinite Monkey Cage is worth a listen if you’re interested in the history of recording technologies.
There’s one comment in there by Brian Eno that I COMPLETELY agree with. He mentions that we invented a new word for moving pictures: “movies” to distinguish them from the live equivalent, “plays”. But we never really did this for music… Unless, of course, you distinguish listening to a “concert” from listening to a “recording” – but most of us just say “I’m listening to music”.
As part of a listening session today, I put together a playlist to compare piano recordings. I decided that an interesting way to do this was to use the same piece of music, recorded by different artists on different instruments in different rooms by different engineers using different microphone and techniques. The only constant was the notes on the page in front of the performer.
Playing through this, it’s interesting to pay attention to things like:
Overall level of the recording
Notice how much (typically) quieter the Dolby Atmos-encoded recording is than the 2.0 PCM encoded ones. However, there’s a large variation amongst the 2.0 recordings.
Monophonic vs. stereo recordings
Perceived width of the piano
Perceived width of the room
How enveloping the room is (this might be different from the perceived width, but these two attributes can be co-related, possibly even correlated)
Perceived distance to the piano.
On some of the recordings, the piano appears to be close. The attack of each note is quite fast, and there is not much reveberation.
On some of the recordings, the piano appears to be distant – more reveberant, with a soft, slow attack on each note.
On other recordings, it may appear that the piano is both near (because of the fast attack on each hammer-to-string strike) and far (because of the reverberation). (Probably achieved by using a combination of microphones at different distances – or using digital reverb…)
The length of the reverberation time
Whether the piano is presented as one instrument or a collection of strings (e.g. can you hear different directions to (or locations of) individual notes?)
If the piano is presented as a wide source with separation between bass and treble, is the presentation from the pianist’s perspective (bass on the left, treble on the right) or the audience’s perspective (bass on the left, treble on the right… sort of…)
In Part 1, I talked at how a binaural recording is made, and I also mentioned that the spatial effects may or may not work well for you for a number of different reasons.
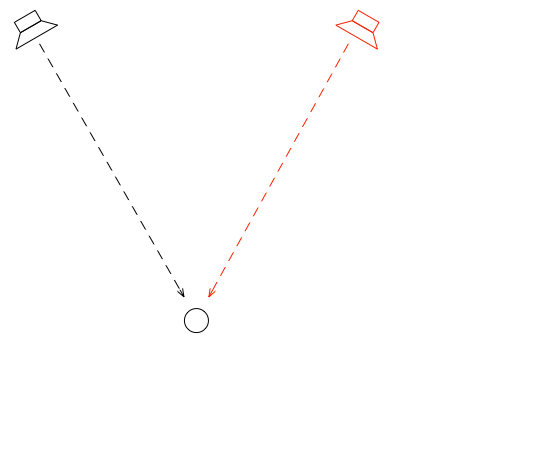
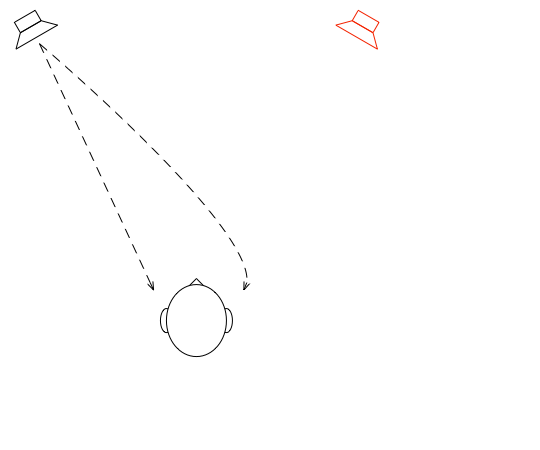
Let’s go back to the free field with a single “perfect” microphone to measure what’s happening, but this time, we’ll send sound out of two identical “perfect” loudspeakers. The distances from the loudspeakers to the microphone are identical. The only difference in this hypothetical world is that the two loudspeakers are in different positions (measuring as a rotational angle) as shown in Figure 1.
Figure 1: Two identical, “perfect” loudspeakers in a free field with a single “perfect” microphone.
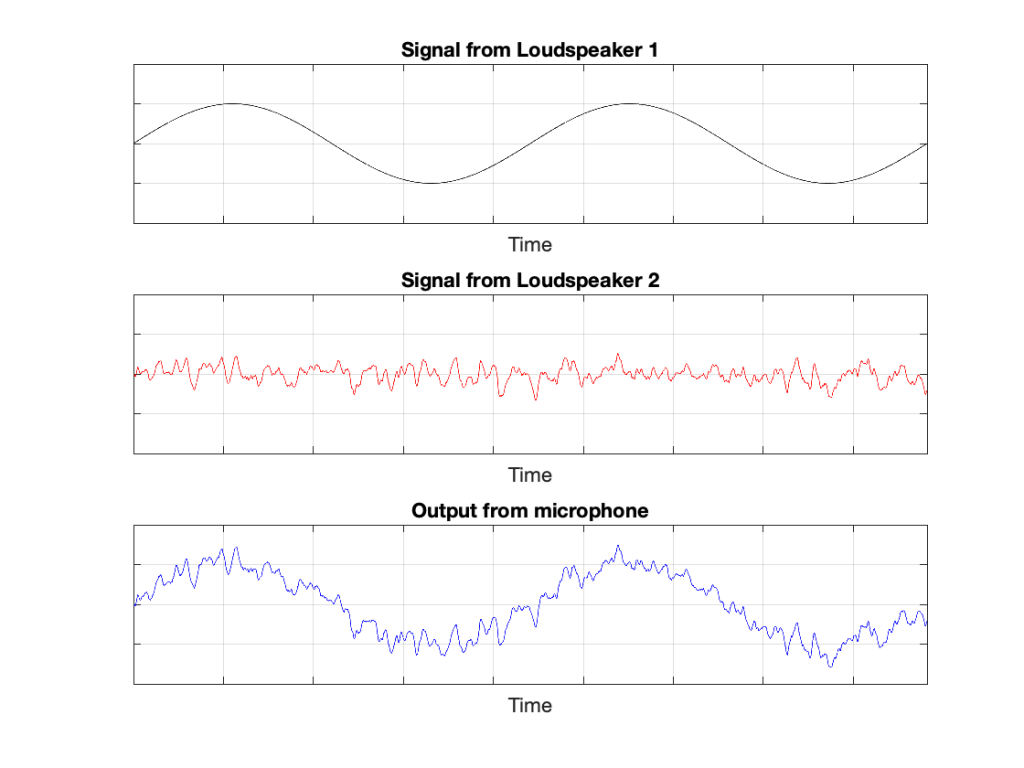
In this example, because everything is perfect, and the space is a free field, then output of the microphone will be the sum of the outputs of the two loudspeakers. (In the same way that if your dog and your cat are both asking for dinner simultaneously, you’ll hear dog+cat and have to decide which is more annoying and therefore gets fed first…)
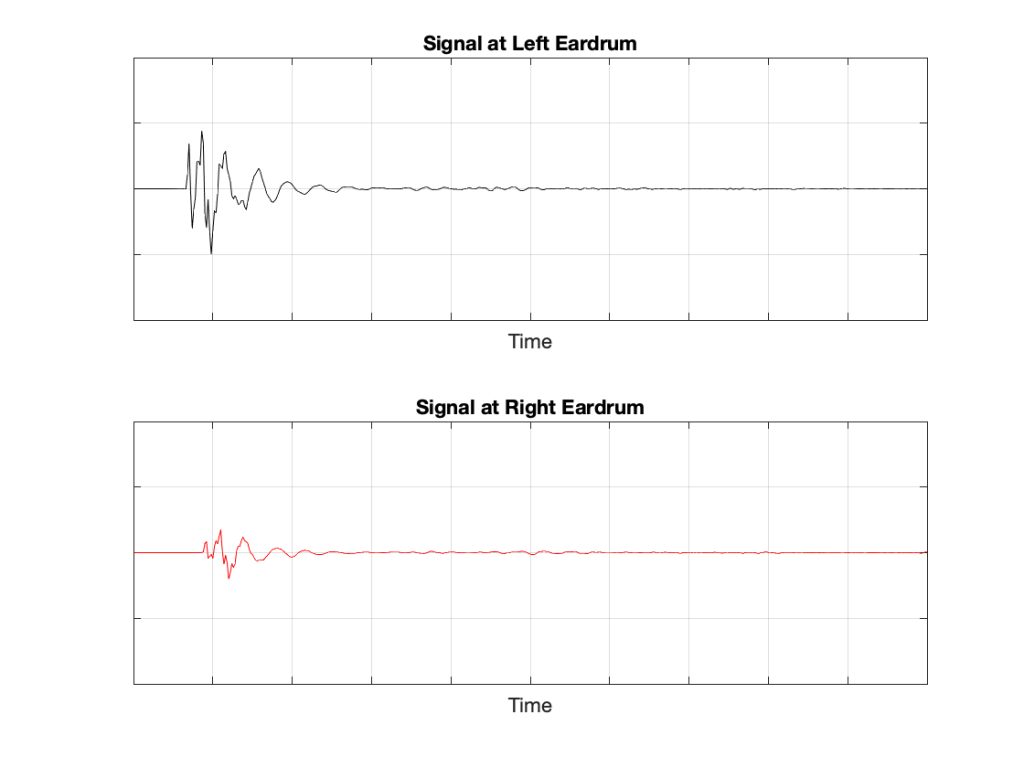
Figure 2: The output from the microphone is the sum of the outputs from the two loudspeakers. At any moment in time, the value of the top plot + the value of the middle plot = the value of the bottom plot.
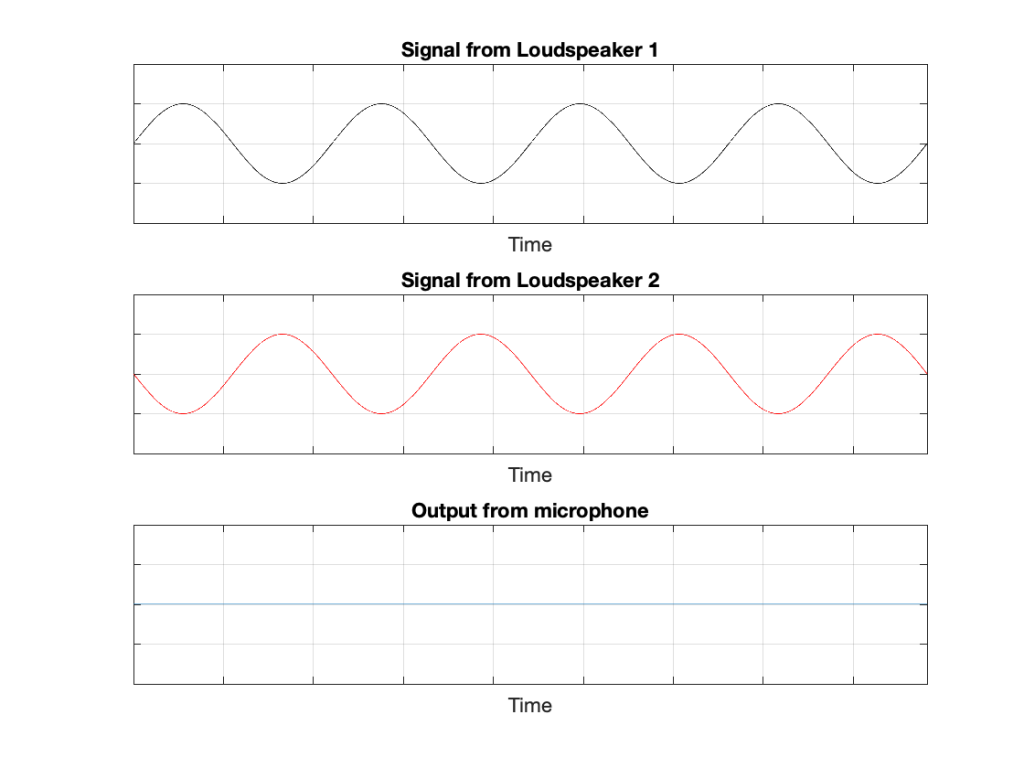
IF the system is perfect as I described above, then we can play some tricks that could be useful. For example, since the output of the microphone is the sum of the outputs of the two loudspeakers, what happens if the output of one loudspeaker is identical to the other loudspeaker, but reversed in polarity?
Figure 3: If the output of Loudspeaker 1 is exactly the same as the output of Loudspeaker 2 except for polarity, then the sum (the output of the microphone) is always 0.
In this example, we’re manipulating the signals so that, when they add together, you nothing at the output. This is because, at any moment in time, the value of Loudspeaker 2’s output is the value of Loudspeaker 1’s output * -1. So, in other words, we’re just subtracting the signal from itself at the microphone and we get something called “perfect cancellation” because the two signals cancel each other at all times.
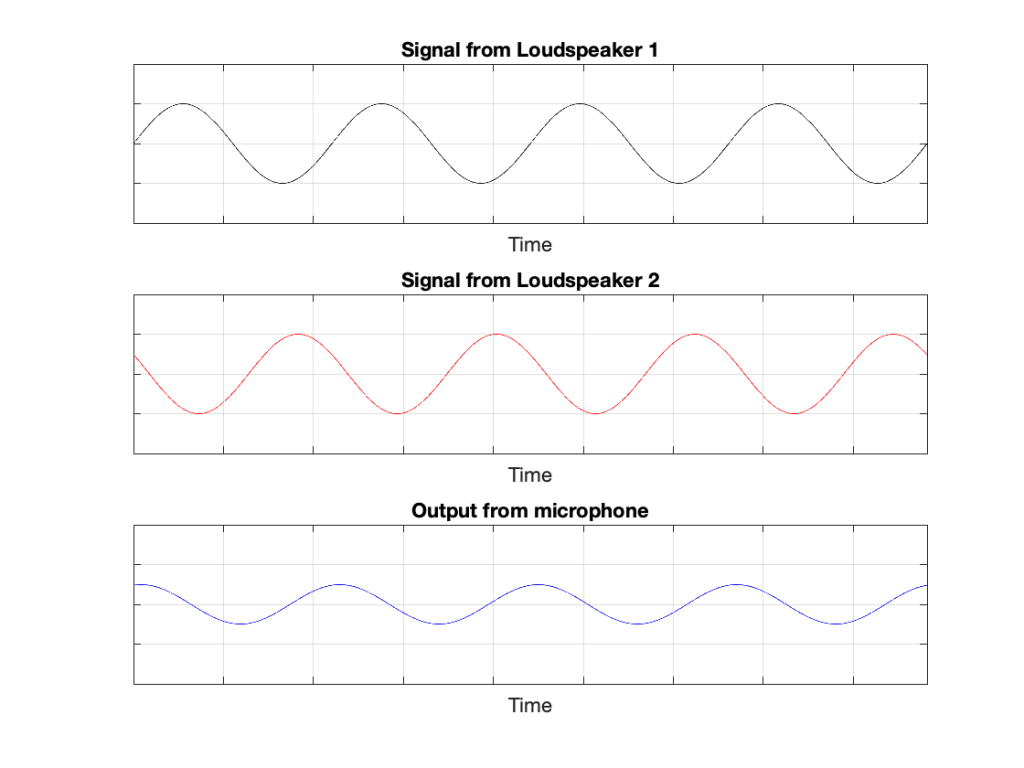
Of course, if anything changes, then this perfect cancellation won’t work. For example, if one of the loudspeakers moves a little farther away than the other, then the system is broken, as shown below.
Figure 4: A small shift in time in the output of Loudspeaker 2 cases the cancellation to stop working so well.
Again, everything that I’ve said above only works when everything is perfect, and the loudspeakers and the microphone are in a free field; so there are no reflections coming in and ruining everything.
We can now combine these two concepts:
using binaural signals to simulate a sound source in a location (although this would normally be done using playback over earphones to keep it simple) and
using signals from loudspeakers to cancel each other at some location in space as a
to create a system for making virtual loudspeakers.
Let’s suspend our adherence to reality and continue with this hypothetical world where everything works as we want… We’ll replace the microphone with a person and consider what happens. To start, let’s just think about the output of the left loudspeaker.
Figure 5: The output of the left loudspeaker reaches both ears with different time/frequency characteristics caused by the HRTF associated with that sound source location.
If we plot the impulse responses at the two ears (the “click” sound from the loudspeaker after it’s been modified by the HRTFs for that loudspeaker location), they’ll look like this:
Figure 6: The impulse responses of the HRTFs for a sound source at 30º left of centre.
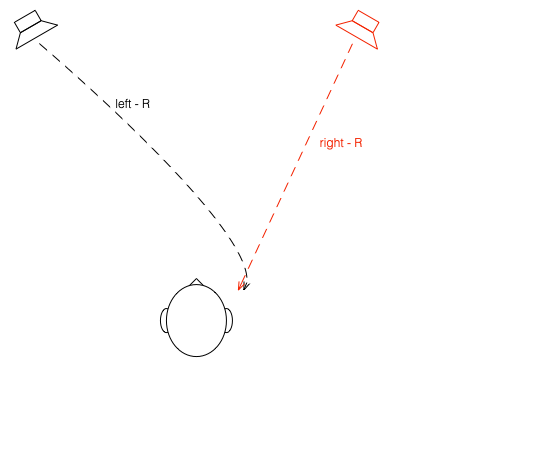
What if were were able to send a signal out of the right loudspeaker so that it cancels the signal from the left loudspeaker at the location of the right eardrum?
Figure 7: What if we could cancel the signal from the left loudspeaker at the right ear using the right loudspeaker?
Unfortunately, this is not quite as easy as it sounds, since the HRTF of the right loudspeaker at the right ear is also in the picture, so we have to be a bit clever about this.
So, in order for this to work we:
Send a signal out of the left loudspeaker. We know that this will get to the right eardrum after it’s been messed up by the HRTF. This is what we want to cancel…
…so we take that same signal, and
filter it with the inverse of the HRTF of the right loudspeaker (to undo the effects of the HRTF of the right loudspeaker’s signal at the right ear)
filter that with the HRTF of the left loudspeaker at the right ear (to match the filtering that’s done by your head and pinna)
multiply by -1 (so that it will cancel when everything comes together at your right eardrum)
and send it out the right loudspeaker.
Hypothetically, that signal (from the right loudspeaker) will reach your right eardrum at the same time as the unprocessed signal from the left loudspeaker and the two will cancel each other, just like the simple example shown in Figure 3. This effect is called crosstalk cancellation, because we use the signal from one loudspeaker to cancel the sound from the other loudspeaker that crosses to the wrong side of your head.
This then means that we have started to build a system where the output of the left loudspeaker is heard ONLY in your left ear. Of course, it’s not perfect because that cancellation signal that I sent out of the right loudspeaker gets to the left ear a little later, so we have to cancel the cancellation signal using the left loudspeaker, and back and forth forever.
If, at the same time, we’re doing the same thing for the other channel, then we’ve built a system where you have the left loudspeaker’s signal in the left ear and the right loudspeaker’s signal in the right ear; just like a pair of headphones!
However, if you get any of these elements wrong, the system will start to under-perform. For example, if the HRTFs that I use to predict your HRTFs are incorrect, then it won’t work as well. Or, if things aren’t time-aligned correctly (because you moved) then the cancellation won’t work.