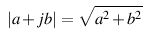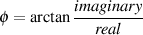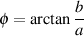I spent some time this week helping to track down the source of an error in a digital audio signal flow chain, and we wound up having a discussion that I thought might be worth repeating here.
Let’s start at the very beginning.
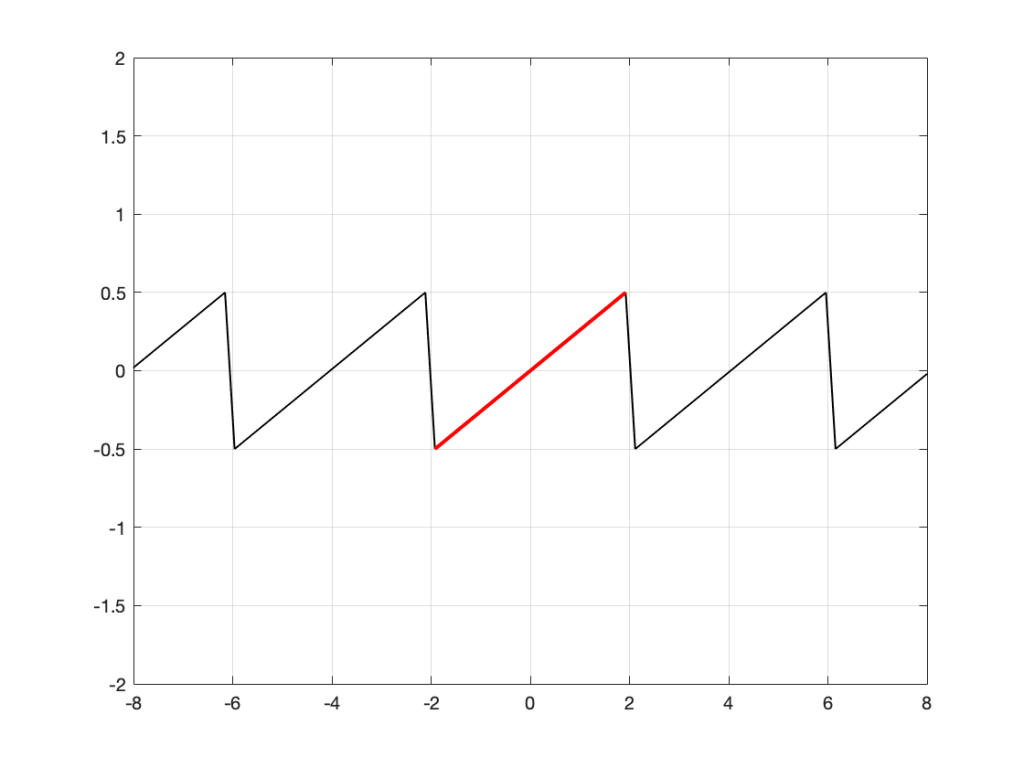
Let’s take an analogue audio signal and convert it to a Linear Pulse Code Modulation (LPCM) representation in the dumbest possible way.
Fig 1. A simple analogue signal that we’ll use for the purposes of this discussion.
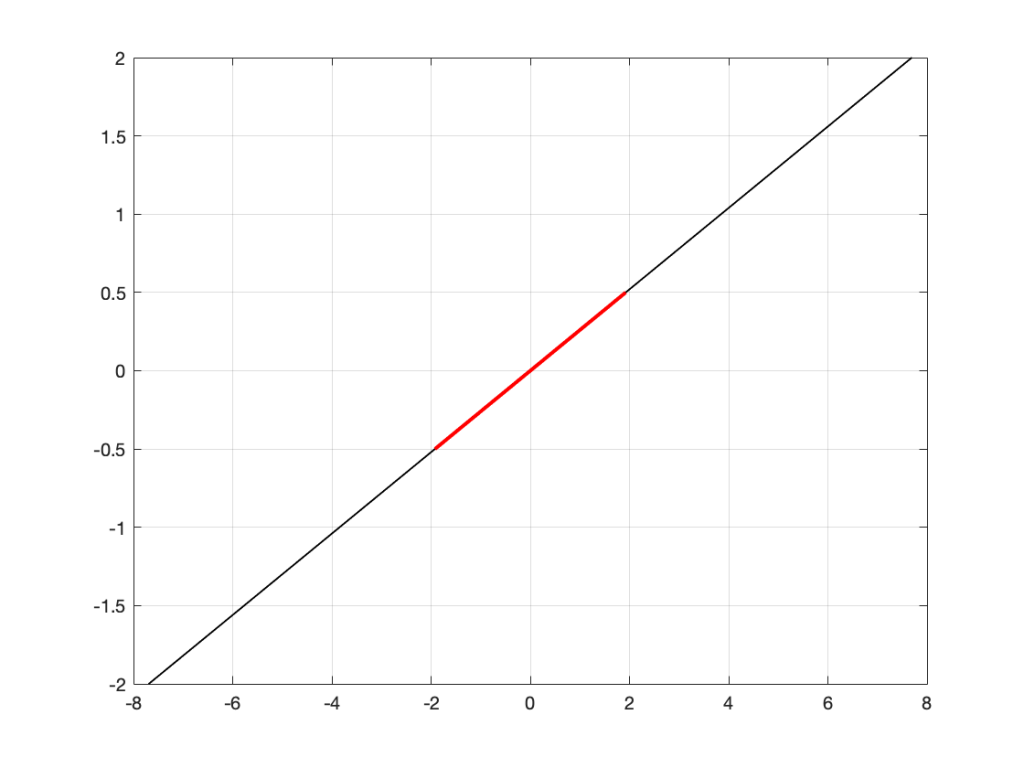
In order to save this signal as a string of numerical values, we have to first accept the fact that we don’t have an infinite number of numbers to use. So, we have to round off the signal to the nearest usable value or “quantisation value”. This process of rounding the value is called “quantisation”.
Let’s say for now that our available quantisation values are the ones shown on the grid. If we then take our original sine wave and round it to those values, we get the result shown below.
Fig 2. The original signal is shown as the blue line. The quantized version of it is shown as the red line.
Of course, I’m leaving out a lot of important details here like anti-aliasing filtering and dither (I said that we were going to be dumb…) but those things don’t matter for this discussion.
So far so good. However, we have to be a bit more specific: an LPCM system encodes the values using binary representations of the values. So, a quantisation value of “0.25”, as shown above isn’t helpful. So, let’s make a “baby” LPCM system with only 3 bits (meaning that we have three Binary digITs available to represent our values).
To start, let’s count using a 3-bit system:
Binary Value
4s place
2s place
1s place
Decimal Value
000
=
0 x 4 +
0 x 2 +
0 x 1
=
0
001
=
0 x 4 +
0 x 2 +
1 x 1
=
1
010
=
0 x 4 +
1 x 2 +
0 x 1
=
2
011
=
0 x 4 +
1 x 2 +
1 x 1
=
3
100
=
1 x 4 +
0 x 2 +
0 x 1
=
4
101
=
1 x 4 +
0 x 2 +
1 x 1
=
5
110
=
1 x 4 +
1 x 2 +
0 x 1
=
6
111
=
1 x 4 +
1 x 2 +
1 x 1
=
7
Table 1: The 8 numbers that can be represented using a 3-bit binary representation
and that’s as far as we can go before needing 4 bits. However, for now, that’s enough.
Take a look at our signal. It ranges from -1 to 1 and 0 is in the middle. So, if we say that the “0” in our original signal is encoded as “000” in our 3-bit system, then we just count upwards from there as follows:
Fig 3. Starting at 000 for the “0” value, and counting upwards into the positive values.
Now what? Well, let’s look at this a little differently. If we were to divide a circle into the same number of quantisation values, make the “12:00” position = 000, and count clockwise, it would look like this:
Fig 4. Counting from 000 to 111 around a circle
The question now is “how do we number the negative values?” but the answer is already in the circle shown above… If I make it a little more obvious, then the answer is shown below.
Fig 5. Relating the values on the circle to the values we’ll need to represent the audio signal…
If we use the convention shown above, and represent that on the graph of our audio signal, then it looks like this:
Fig. 6
One nice thing about this way of doing things is that you just need to look at the first digit in the binary word to know whether the value is positive or negative. A 0 means it’s positive, and a 1 means it’s negative.
However, there are two issues here that we need to sort out… The first is that, since we have an even number of values, but an odd number of quantisation steps (4 above zero, 4 below zero, and zero = 9 steps) then we had to do something asymmetrical. As you can see in the plot above, there are no numbers assigned to the top quantisation value, which actually means that it doesn’t exist.
So, if we’re still being dumb, then the result of our quantisation will either look like this:
Fig 7. The dumb way to deal with the asymmetrical quantisation problem. Notice that the result is asymmetrically clipped on the positive side, but not the negative.
or this:
Fig 8. A smarter way to deal with the asymmetrical quantisation problem. Notice that we’ll never use the bottom value.
Wrapping up…
But what happens when you make two mistakes simultaneously? Let’s go back and look at an earlier plot.
Fig 9.
Let’s say that you’re writing some DSP code, and you forget about the asymmetry problem, so you scale things so they’ll TRY to look like the plot above.
However, as we already know, that top quantisation value doesn’t exist – but the code will try to put something there. If you’ve forgotten about this, then the system will THINK that you want this:
Fig 10. Notice that top quantisation value. I’ve labeled it as (100) because that’s the binary number after 011 – but 100 is ACTUALLY already used for the bottom-most negative value… Bad things are about to happen.
As you can see there, your code (because you’ve forgotten to write an IF-THEN statement) will think that the top-most positive quantisation value is just the number after 011, which is 100. However, that value means something totally different… So, the result coming out will ACTUALLY look like this:
Fig 11. The actual output resulting from the mistakes described above.
As you can see there, the signal is very different from what we think it should be.
This error is called a “wrapping” error, because the signal is “wrapped” too far around the circle shown in Figure 5, shown above. It sounds very bad – much worse than “normal” clipping (as shown in Figure 7) because of that huge nearly-instantaneous transition from maximum positive to maximum negative and back.
Of course, the wrapping can also happen in the opposite direction; a negatively-clipped signal can wrap around and show up at the top of the positive values. The reason is the same because the values are trying to go around the same circle.
As I said: this is actually the result of two problems that both have to occur in the same system:
The signal has to be trying to get to a level that is beyond the limits of the quantisation values
Someone forgot to write a line of code that makes sure that, when that happens, the signal is “just” clipped and not wrapped.
So, if the second of these issues is sitting there, unresolved, but the signal never exceeds the limits, then you’ll never have a problem. However, I will never need the airbags in my car, unless I have an accident. So, it’s best to remember to look after that second issue… just in case.
P.S.
This method of encoding the quantisation values is called the “Two’s Complement” method. If you want to know more about it, read this.
As I’ve talked about in a previous posting, when a reciprocal peak/dip filter says “Q”, there’s no knowing what it might mean, because there are at least 7 different definitions of Q (3 for boosts and 4 for dips).
For many people, this doesn’t really matter. If you’re just playing with an EQ to make things sound better right now, then the values on the display really don’t matter: it’s the sound that counts.
If you’re like me, you need to be able to navigate between different pieces of software and hardware, and to get the same EQ response from them, then you’ll also need to know firstly that you can’t trust the display, and secondly, how to “translate” from device to device when necessary.
For example, take a look at Figure 1
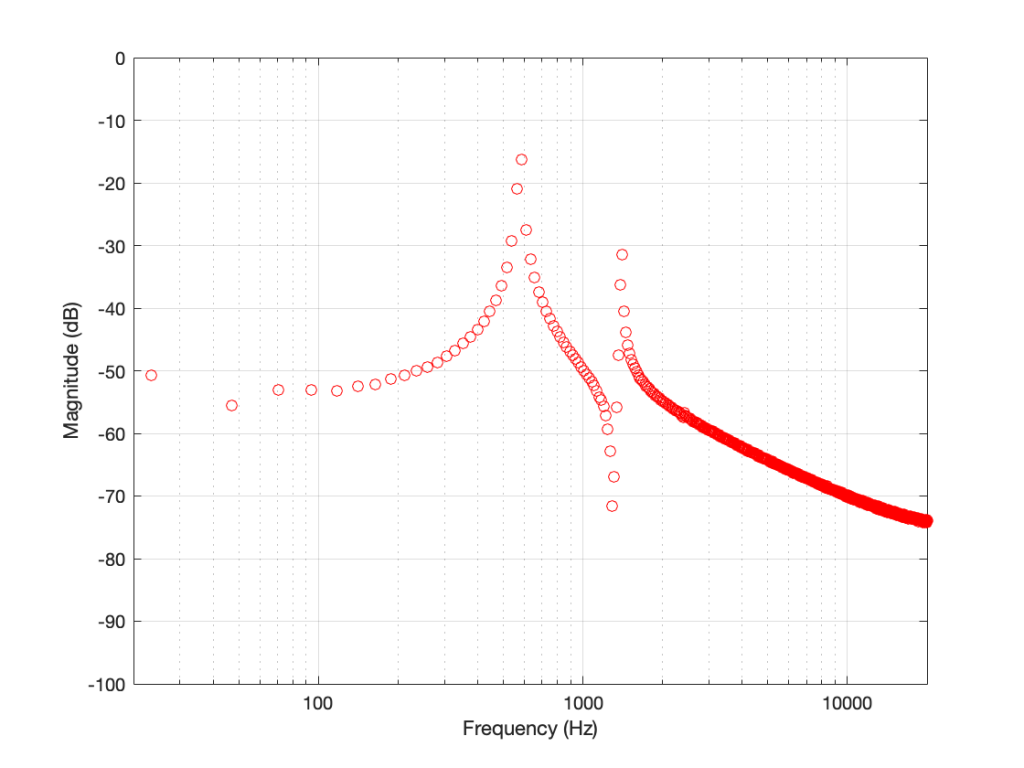
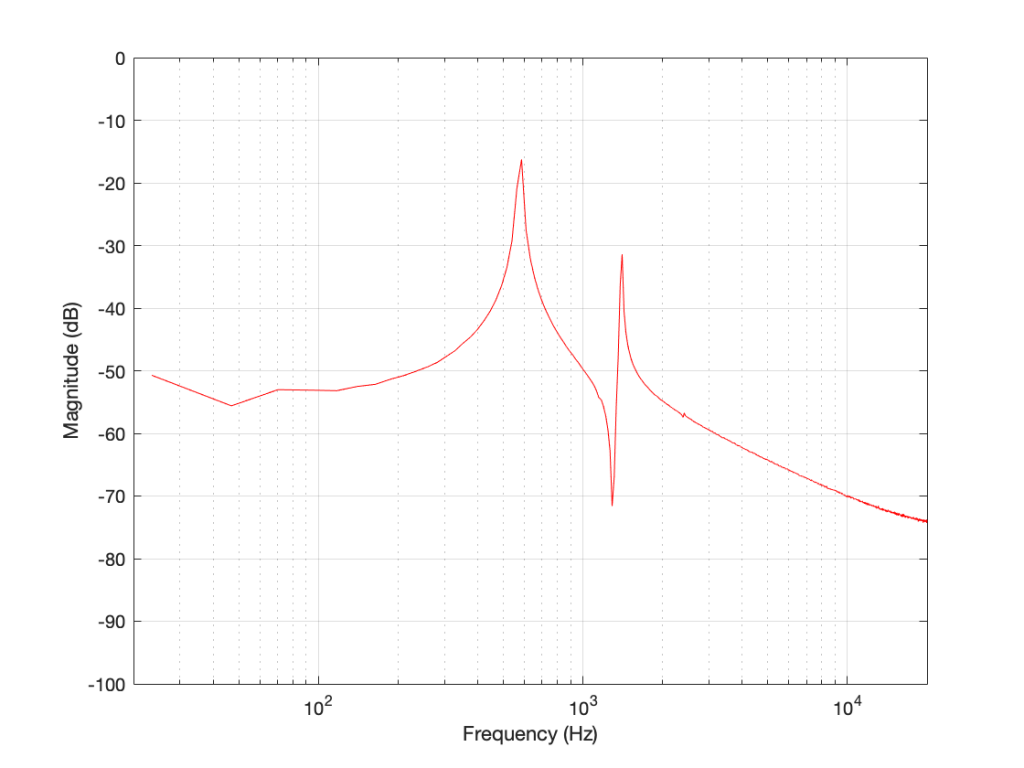
Figure 1: The magnitude response of two peaking filters, both with Fc=1 kHz, Gain = +12 dB, Q = 2
This shows two magnitude responses, however, these are the measurements of two equalisers with identical settings: Fc = 1 kHz, Gain = +12 dB, Q = 2.
The black curve shows the response of an equaliser that uses the -3 dB points to define the bandwidth of the filter, and therefore the Q is based on 1/(2 zeta). The red curve shows the response of an equaliser that uses the mid-point (in this case, +6 dB because the Gain is +12 dB) to define the bandwidth of the filter.
The difference between these two plots is shown below in Figure 2.
Figure 2: The difference between the two curves in Figure 1.
We’d have a similar problem if we were cutting instead of boosting, as shown in Figure 3.
Figure 3: The magnitude response of two peaking filters, both with Fc=1 kHz, Gain = -12 dB, Q = 2
You have to think upside down in this case, because the 1/(2 zeta) filter is actually using the 3 dB UP points to measure bandwidth; but we’ll ignore that and move on.
If you need to translate between the two systems shown above, there’s a pretty easy way to do it.
I’ll assume that you are implementing your filter using the mid-point definition of the bandwidth, so you need to convert into that system rather than out of it. (I’m making this assumption because it’s the one that Robert Bristow-Johnson used in his Audio Cookbook, which was freely copy-and-pasteable, which means that you find it everywhere these days.) Get the parameters from the filter you want to copy.
We’ll call these parameters Fc (for centre frequency, in Hz), (Gain in dB), and . I’m calling it because it’s a Q based on 1/(2 zeta) and we’ll need to keep it separate from our other Q, which I’ll call (for Robert Bristow-Johnson).
Convert the gain into linear.
Then do the following:
IF
ELSEIF
ELSE your filter isn’t doing anything because
END
Example 1
If you have a -3 dB-based filter with the following parameters:
and you want to implement that using the Bristow-Johnson equations, then you’ll have to use the following parameters:
Example 2
If you have a -3 dB-based filter with the following parameters:
and you want to implement that using the Bristow-Johnson equations, then you’ll have to use the following parameters:
Two Extra Things…
If the filter that you’re translating FROM is based on Andy Moorer’s design (which is based on the gain mid-point if the gain is within the ±6 dB range, but based on the 3 dB points if it’s outside that), then you’ll have to write your own IF/THEN statements.
If you’re implementing a filter that was specified for RBJ’s equations in a system that’s based on 1/(2 zeta), then you’re probably smart enough to figure out how to do the above in reverse.
One additional addendum
IF you don’t like IF/THEN statements for some reason or another (code optimisation, for example)
THEN you could do it this way instead:
What I’ve done there is to fold the decibel-to-linear conversion into the equation. I’ve also converted the gain in dB to an absolute value before converting to linear. That way, it’s always positive, so you always divide.
When it comes to audio, the “signal” is an easy thing to define. It’s what you want to listen to – a song, the dialogue in the movie – whatever it was that you wanted to hear that made you turn on the loudspeaker in the first place.
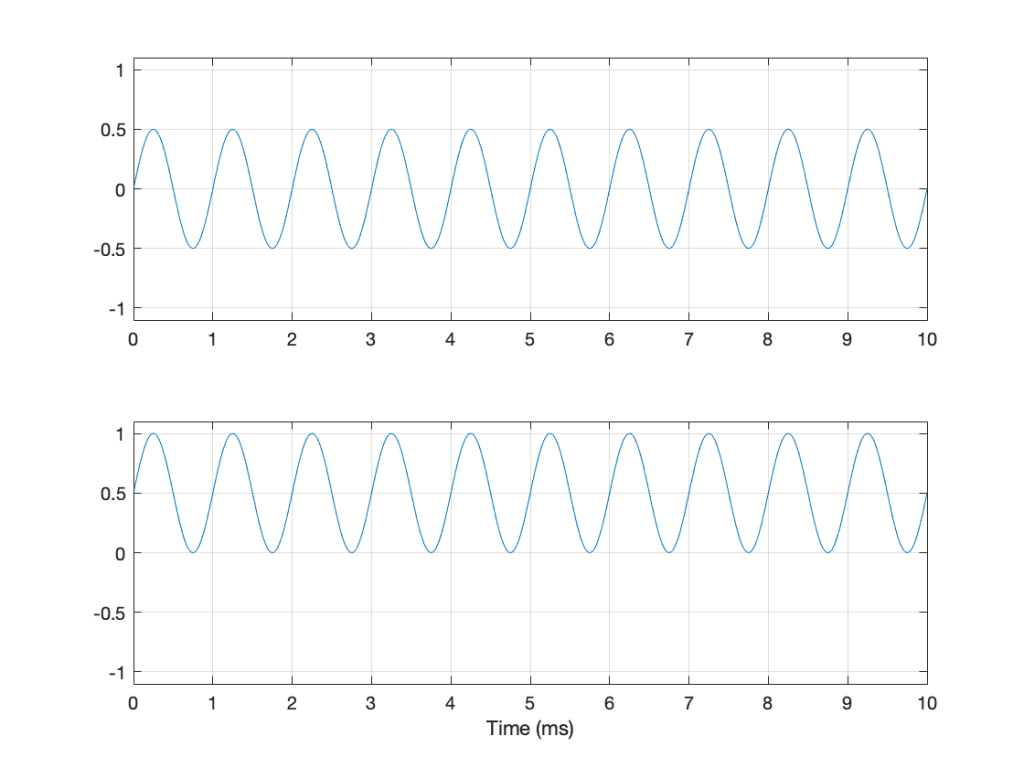
Let’s say that, normally, we listen to music – so that’s the signal. And, although “music” means different things to different people, most of the time, “music” will contain energy at more than one frequency, and its level will change over time. For example, compare the two plots in Figure 1.
Figure 1: The top plot is a 1-second slice from Jennifer Warnes’s “Bird on a Wire”. The bottom plot is a 1-second slice of a 997 Hz sine tone.
Looking at Figure 1, it seems obvious that the level of “Bird on a Wire” changes over time, but the level of a sine wave doesn’t. However, that’s not as obvious when we zoom into that plot, as is shown in Figure 2, below.
Figure 2: a 10-ms slice out of Figure 1.
From Figure 2, we can easily establish the obvious fact that “Bird on a Wire” and a sine wave are different. However, now it’s not as obvious that the sine wave as a constant level – it repeats itself periodically – which is why we call it “periodic” – but what is its level?
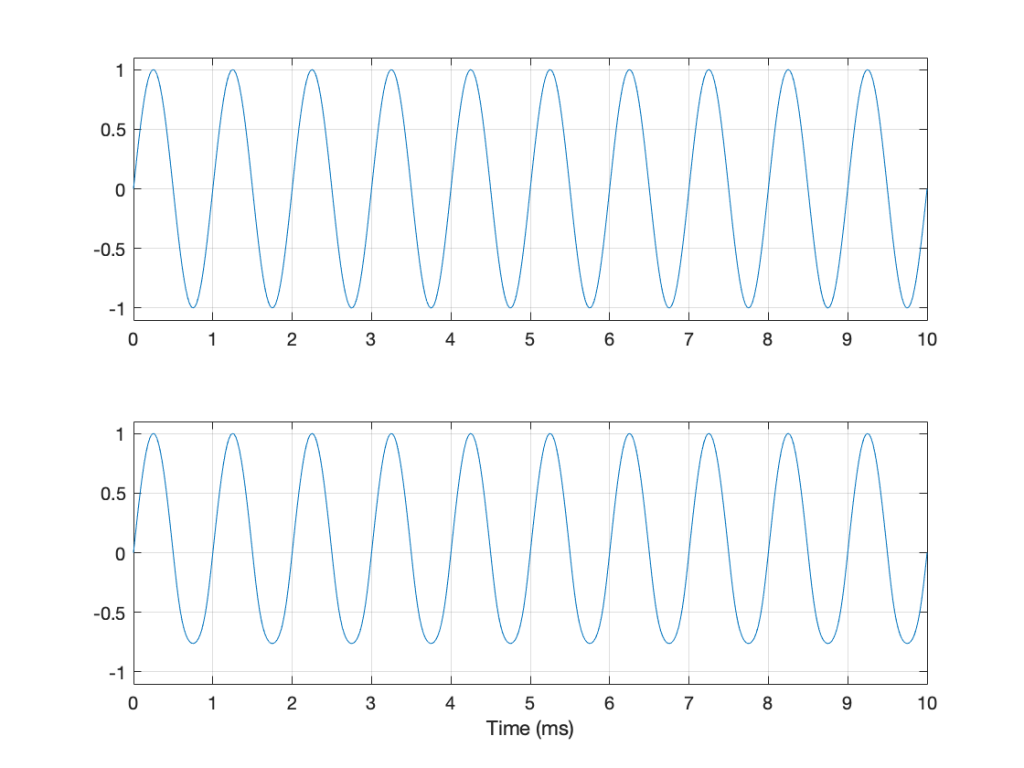
The simplest way to determine the level of a signal is similar to the way yesterday’s share prices are shown in the financial section of the newspaper. In that case, you are told the highest price and the lowest price for the day. In audio, we sometimes talk to the “peak-to-peak” amplitude of a signal. This is the difference between the highest and and the lowest peak (more accurately called a “trough”) of the signal in whatever amount of time you’ve been measuring. For example, take a look at Figure 3.
Figure 3: Two different signals with the same peak-to-peak amplitude.
In Figure 3, I’ve drawn two signals. The top one is a 100 Hz sine wave with a peak-to-peak amplitude of 2 (because the difference between the highest peak (+1) and the lowest peak (-1) is 2). The bottom signal is a 100 Hz sine wave with a peak-to-peak amplitude of 0.1 – but with two clicks – one hitting +1 and the other hitting -1. So, if I just look at the peaks of that second signal, it also has a peak-to-peak amplitude of 2.
So, although it was easy to find the peak-to-peak amplitudes of those two signals, it should be obvious that this does not give a fair indication of how loud they appear to be.
However, if you’re building a piece of audio equipment (like an amplifier or an EQ, for example), this measurement does give you an idea of the “worst case” limits of the signal that might come through the system. So it’s not a useless measurement.
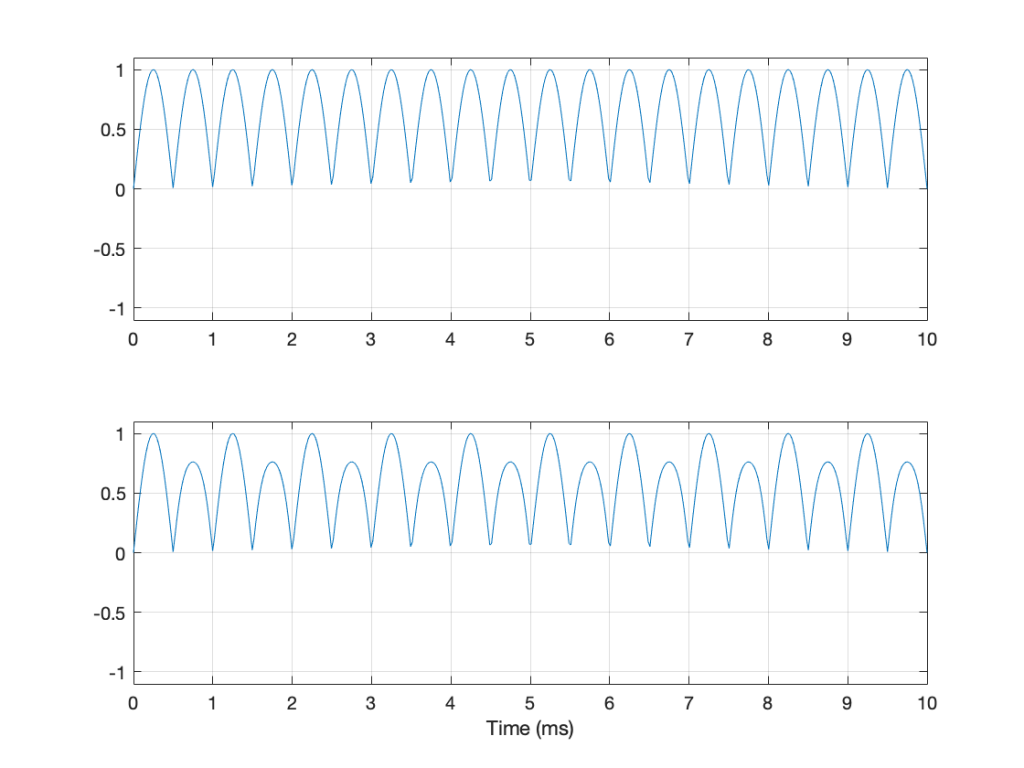
An additional problem with a peak-to-peak measurement of a signal is that it doesn’t tell you anything about asymmetry across the 0 line. (In an analogue world, we’d call that a “DC offset” because there would be a DC voltage that is added to the AC waveform.) For example, both of the signals in Figure 4 have a peak-to-peak amplitude of 1, but they are different…
Figure 4: Two sine waves with the same frequency and the same peak-to-peak amplitude. One of them will be nice to a loudspeaker driver (the top one…) but the other will not (the bottom one)
If you’re lazy, you can do half of a peak-to-peak measurement. This is where you just check the maximum value of either the peak or the trough. We call this a “peak” amplitude measurement.
This has its problems, though. For example, take a look at Figure 5.
Figure 5: Two signals, each with a peak amplitude of 1.
Here, we see two signals. The top one is a sine wave. The bottom one was a sine wave until I squished its negative-going half with a cheap compressor. As you can probably see, the top waveform is symmetrical – the negative half of the signal is the same as the positive half of the signal, just upside-down. It is also easily obvious that the second signal on the lower plot is not symmetrical. Its positive peak is higher than its negative peak.
However, both of these signals have a maximum positive peak of 1 – therefore their peak amplitudes are both 1 (but their peak-to-peak amplitudes and their apparent loudnesses are different).
You might think that an easy way around this problem is to look at the absolute value of the signals and find the peaks that way. However, as you can see in Figure 6, in the case of asymmetrical signals, this does not change anything.
Figure 6: The same signals shown in Figure 5 – but the plot shows the absolute values of the signals. Note that their peak amplitudes are still the same here.
Another way to look at the signal is to take an average of the level over time. However, if the signal is symmetrical (like a sine wave, for example) this would not work, since the average will probably be 0. This is because, if the signal is symmetrical, then the average of all of the negative values in the signal (over time) average out to be the negative equal of the average of all of the positive values. So we can’t just use the average of the signal directly… However, with a little extra math, we can do something useful.
I’m going to skip quickly over some old-fashioned math here in order to jump to the punchline which is: “the power in an AC signal (like a sine wave) is proportional to the square of the signal.”
The reason for this can be explained by combining Ohm’s Law and Watt’s Law as follows:
V = IR
where V is electromotive force (or voltage) in volts, I is current in amperes, and R is the resistance in ohms.
P = VI
where P is the power in watts, and V and I are the same as above.
If we fiddle with Ohm’s Law like this:
V = IR
therefore
I = V/R
Then we can replace the “I” in Watt’s Law like this
P = VI
P = V * V/R
P = V2 / R
So, with that last equation, we can see that the Power (in watts) is proportional to the square of the Voltage (in volts). So, if you double the voltage, you get 4 times the power (because 22 = 4).
We could do the same thing for current, as follows:
P = VI
P = IR * I
P = I2 R
So what? Well, one thing this tells us is that, if you want double the power (for example, from a loudspeaker’s output or the heat from a hair dryer) then you’ll need 4 times the amplitude of the signal feeding it (for example, 4 times the voltage at the same current level or 4 times the current with the same voltage).
Now, let’s come back to the problem at hand… What’s the level of the signal? Well, we start by taking our signal and find its equivalent power (by squaring its instantaneous amplitude value over time – so, for example, if it’s a digital signal, we take the value of each sample and multiply it by itself). Part of the effect of this squaring of the signal is that it removes the negative portion of the signal (because a negative number multiplied by a negative number is a positive number).
We then take a slice of time, and average all of the values that we just created by squaring the original values. Now we have the average (or “mean”) power in the signal.
However, we’re not interested in the power of the signal, we’re interested in its “average” amplitude (say, its voltage). So, to get back from power, we take the square root of the average that we just calculated.
By doing all of this, we are finding the Root of the Mean of the Square of the voltage – the RMS level.
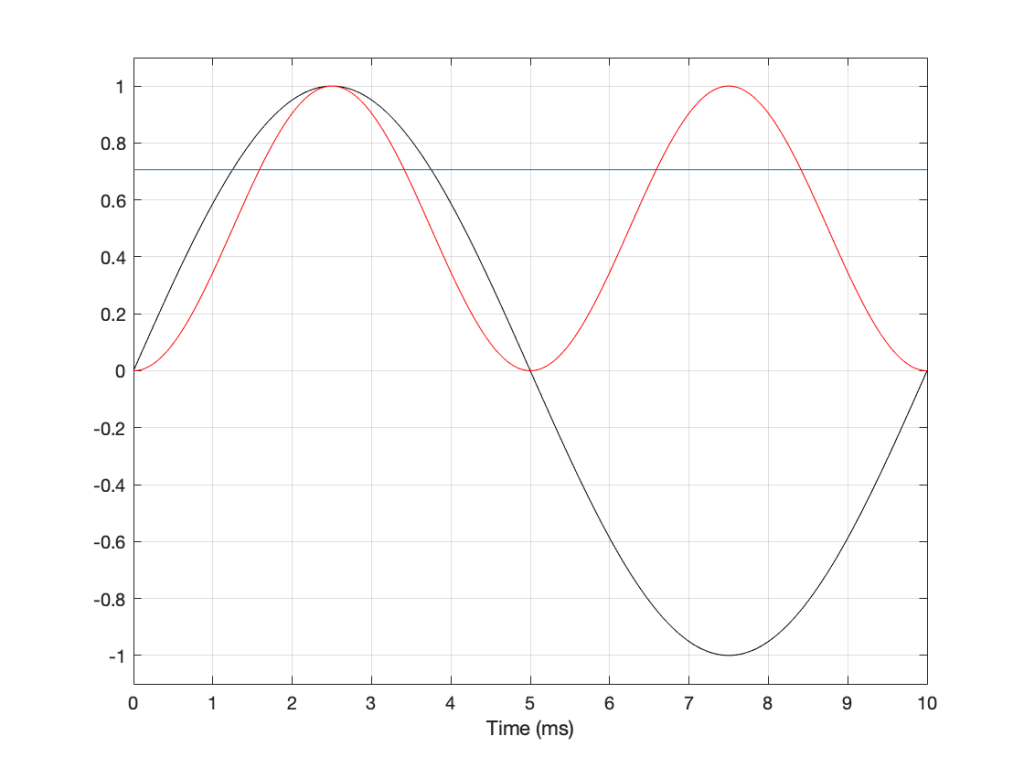
If we apply this math to a sine wave, the result will be something like what’s shown in Figure 6.
Figure 6. See the following text.
In Figure 6, the black curve is the original sine wave with a frequency of 100 Hz and a peak amplitude of 1.0 (and no DC offset). The red curve shows the result of squaring all the values in the sine wave (which is why it’s called a “sine squared” wave or sin2 wave). If we find the average of all of the values in the red curve, the result would be 0.5. The square root of 0.5 is approximately 0.707 – which is shown as the blue line in the plot.
So, the RMS value of a sine wave with a peak value of 1 is 0.707. What does this mean? The easiest way to think of this is that if you had an old-fashioned incandescent light bulb and you powered it with a 1Vp (1 Volt Peak) AC voltage sine wave, it would be exactly the same brightness as if you connected it to a 0.707 V DC battery instead. If you wanted to use a battery to power your toaster, and you wanted it to make toast just as quickly as it normally does, then the battery will have to have a voltage that is 0.707 * the peak value of the AC voltage that normally feeds it. (Note that, if you live in North America, then the electrical signal feeding your toaster is 110 V RMS – so you’ll need a 110 V battery. If you live in Europe, then your toaster is fed with 220 V RMS – so you’ll need a 220 V battery. If you live somewhere else, you might need something else… Note that the electrical company has already done the RMS calculation for you…)
So, an RMS measurement of an AC signal tells us what DC value would result in the same power consumption.
There is just one problem: part of the RMS calculation is the “M” part – we are finding the mean of the values over some period of time. The length of time that we’re going to use is easy to choose if it’s a sine wave – we just make sure that the length of time (we call it a “time constant”) is at least as long as one period of the sine wave itself. If it’s smaller, then the RMS value will bob up and down as the sine wave goes up and down.
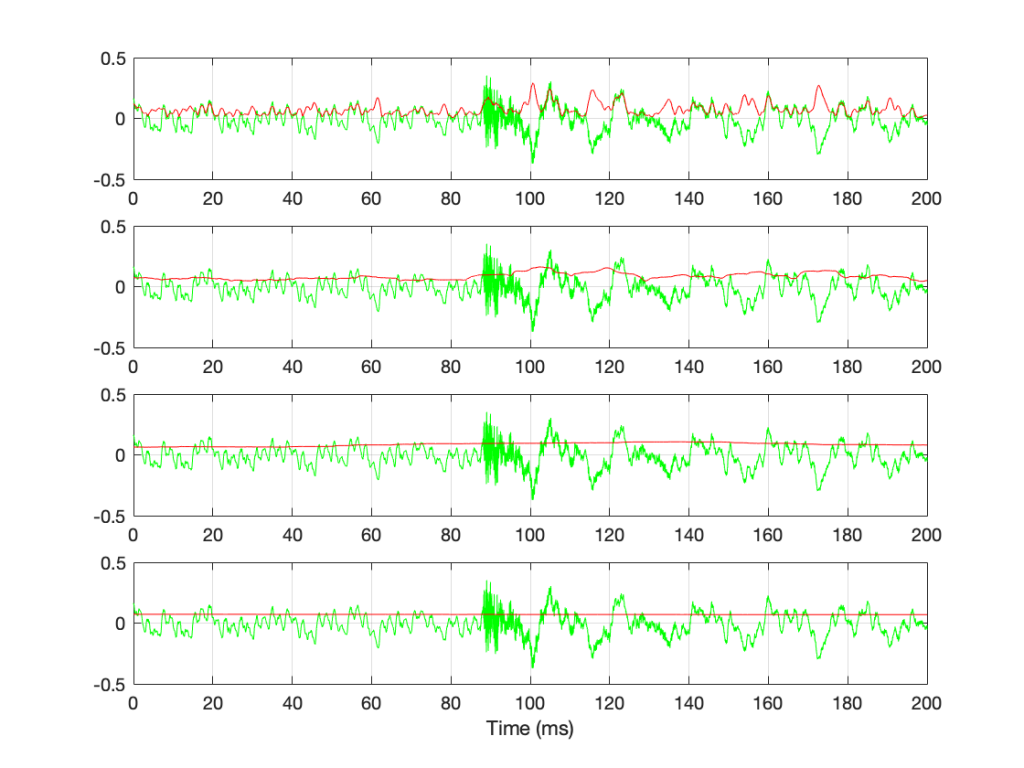
However, if we’re going to try to use the RMS method to find the level of a music signal, we’re going to have to make some tough choices… For example, let’s find the RMS value of the “Bird on a Wire” sample, using different time constants, shown below.
Figure 7: The green plots show the same thing: a 200-ms slice out of Bird on a Wire. The red plots show the RMS level of the green signal for 4 different time constants – from top to bottom: 1 ms, 10 ms, 100 ms, and 1 second.
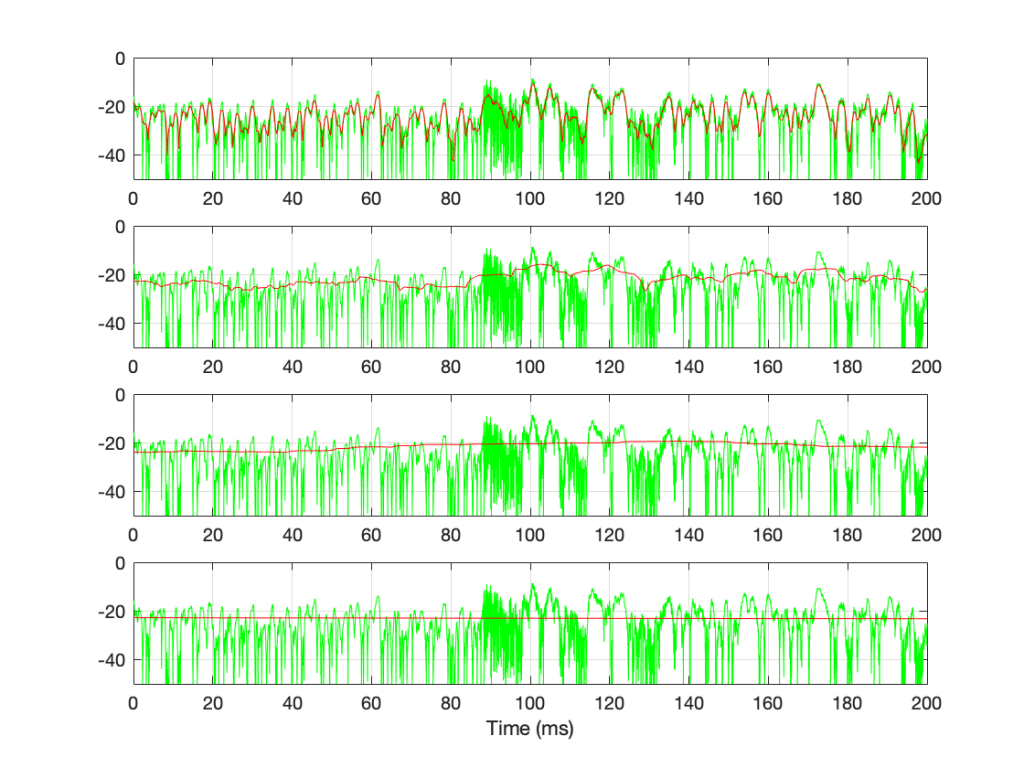
If we convert the plot in Figure 7 to a decibel representation by taking 20*log10 of each sample value, we get the plots in Figure 8. (Note that this is not the same as dB FS, since we are not comparing the result to the RMS value of a full-scale sine wave… but that’s a topic for another posting.)
Figure 8: The decibel equivalents of the plots shown in Figure 7.
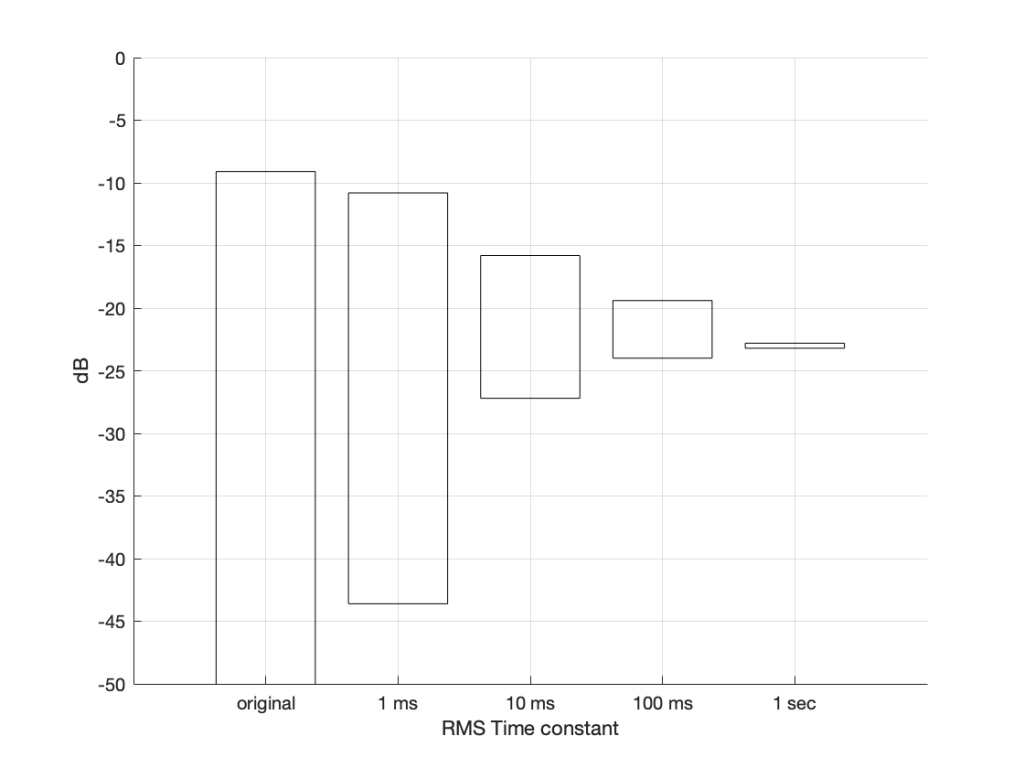
There are some things that are evident in Figure 8. The most obvious one is that there is a link between the RMS time constant and the variability of the RMS level when the signal that you’re analysing is not periodic. Looking at this short 200 ms-long example from Bird on a Wire, with the four time constants that I used, the range of results are as shown below in Figure 9.
Figure 9. The ranges of RMS levels in Figure 8
[table]
RMS Time constant, Min (dB), Max (dB), Range (dB)
Original signal, -∞, -9.1, ∞
1 ms, -43.6, -10.8, 32.8
10 ms, -27.2, -15.8, 11.4
100 ms, -24.0, -19.4, 4.6
1 sec, -23.2, -22.8, 0.4
[/table]
Of course, it’s important to remember that if I had picked a different signal or different RMS time constants, I would have gotten different results.
The question to ask here is:
“If I want to know the level of that 200 ms slice of Bird on a Wire, which RMS time constant should I use?”
or
“which of those four plots tells me the signal’s level?”
The answer is that none of these is correct – or all of them are, even though they show different things. The problem is that music has such a wide frequency range – from 20 Hz to 20,000 Hz. Therefore, if you choose a time constant that is long enough to give you a stable measurement at 20 Hz (which will be at least 50 ms – 1/20th of a second or one period of a 20 Hz wave), then it will be the length of 1000 periods of the 20 kHz portion of the signal.
Of course, you could argue that you care more about the 20 Hz part than the 20,000 Hz part – but that’s dependent on what you’re doing. If you’re measuring the signal that’s being sent to a tweeter, then you’re probably not interested in what’s going on at 20 Hz at all…
So what?
We’re heading (in a future posting) towards talking about measuring a system’s (or a devices’s) ability to deliver a wide range of signal levels. We’re going to talk about its “signal to noise ratio” which is a measurement of how much louder the signal (the music) is than the noise that the system itself generates. The idea in the design of all audio systems is that you want to make that ratio as big as possible so that you cannot hear the noise because it’s so much quieter than the signal.
The problem is that we’re going to have to measure how loud the signal can be – and compare that to how loud the signal actually is at any given moment. In order to understand the concepts in that discussion, then it’s necessary to understand the concepts that I introduced above, namely the following:
Peak-peak level
Peak level
RMS level
the relationship between RMS Time constant and the RMS level
This is the start of what will be a series of posts that are an attempt to answer a question about the pro’s and con’s of implementing a volume control in the digital domain. When I first thought about how to answer this question, I thought I could do it in a couple of sentences – but the more I thought about it, the more I realised that the answer is complicated…
There’s no doubt in my mind that I’m making this answer more complicated than necessary, but, as Carl Sagan once said, “If you wish to make apple pie from scratch, you must first create the universe.”
So, to begin, we have to define what “noise” is from the point of view of audio engineering.
On the one hand, we can define it simply. “Noise” is a random signal. We can be more accurate and say that this means that the amplitude of a noise signal cannot be predicted using a knowledge of what has come before in time.
If I flip a coin, it will be either heads or tails. I can’t predict this. It will be random. If I flip it 100 times, and, by some strange coincidence, I get 100 “tails”, there is still a 50% chance of getting a tails on the 101st flip. What has happened before can, in no way, be used to predict what is about to happen.
Of course, what is about to happen on the 101st flip has a limited number of possible outcomes. I cannot flip the coin and get “dog” as a result… (this sounds silly, but it will come in handy later…) Just like I cannot roll two dice and get a 13…
In LPCM digital audio, a noise signal is one where each individual sample in the signal has a random value that is in no way related to any of the previous samples. Its range (the set of possible values from which we can pick our random number) may be limited (depending on the specific characteristics of the noise signal and what may have come before), but it will be random.
Typically, when you are talking to someone in audio about noise, they describe it using a colour as the first descriptor. So, you’ll hear of “white noise” and “pink noise”, as the two most popular examples. For the purposes of this series of postings, we’ll only be talking about white noise. So, what is this?
One definition that you’ll see thrown around a lot says something like “white noise is a random signal that has equal energy per linear bandwidth” or “… equal energy per hertz” or “…equal intensity at different frequencies” or something like this. These descriptions are sort of true if you don’t want to get into temporal details, which, unfortunately, is exactly where we’re headed…
The good thing about those definitions is that they describe a general characteristic of white noise. If you take a white noise signal, and you measure the intensity of (or the energy in) the signal for a given bandwidth (say, a bandwidth of 100 Hz ranging from 200 Hz to 300 Hz) then it will be the same in another frequency range with the same bandwidth (say, a bandwidth of 100 Hz ranging from 1,000 Hz to 1,100 Hz). Note that these two bandwidths are the same in hertz – not in a multiplier like octaves or semitones or decades. So, if you have white noise that has a total bandwidth of 0 Hz to 20,000 Hz, then you will have the same amount of energy in the 0 – to – 10,000 Hz band as you will in the 10,000 – to – 20,000 Hz band. In other words (to us humans), there is as much energy in the top octave of the signal as in the rest of the bandwidth combined.
This is why white noise sounds like “bright” and “hissy” (similar to the “ss” sound in “hissy”) and not “darker” like the “sh” sound in “ash” (as they incorrectly claim here…). Since white is a “bright” colour, then we use the word “white” to describe the frequency-dependent energy distribution of “white” noise.
However, this is not really true. The truth is that a white noise signal has an equal probability per bandwidth of having the same energy level. This little detail is usually left out, partly because it’s complicated, and partly because it doesn’t matter in most cases in the real world. However, in our case, it does.
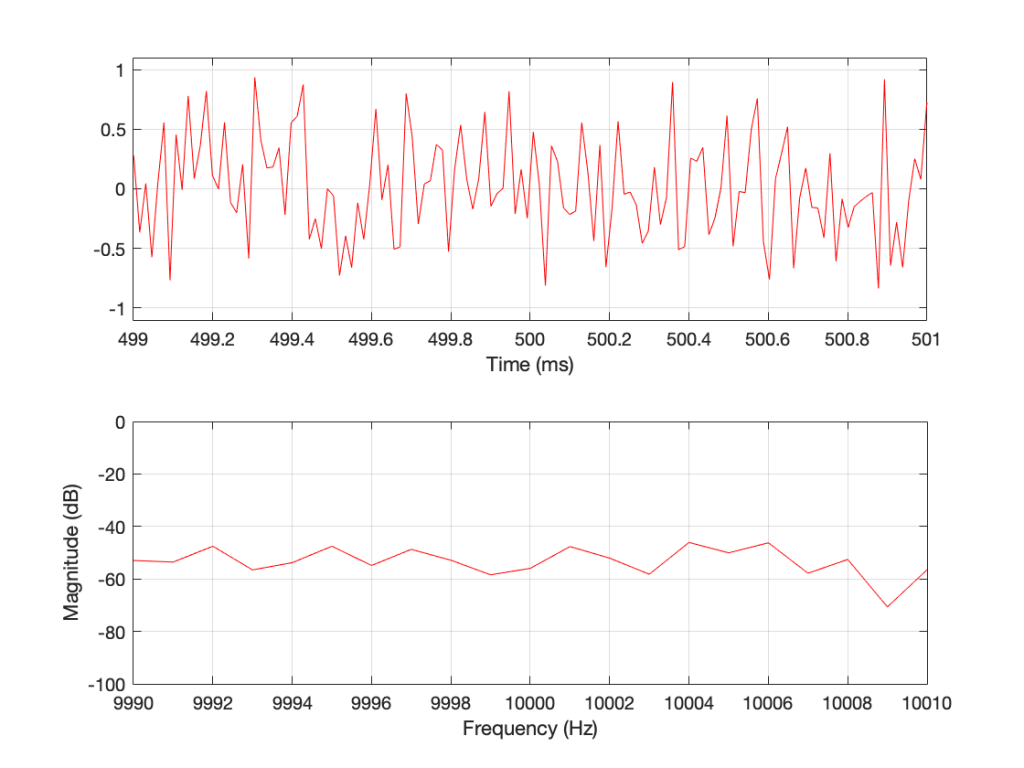
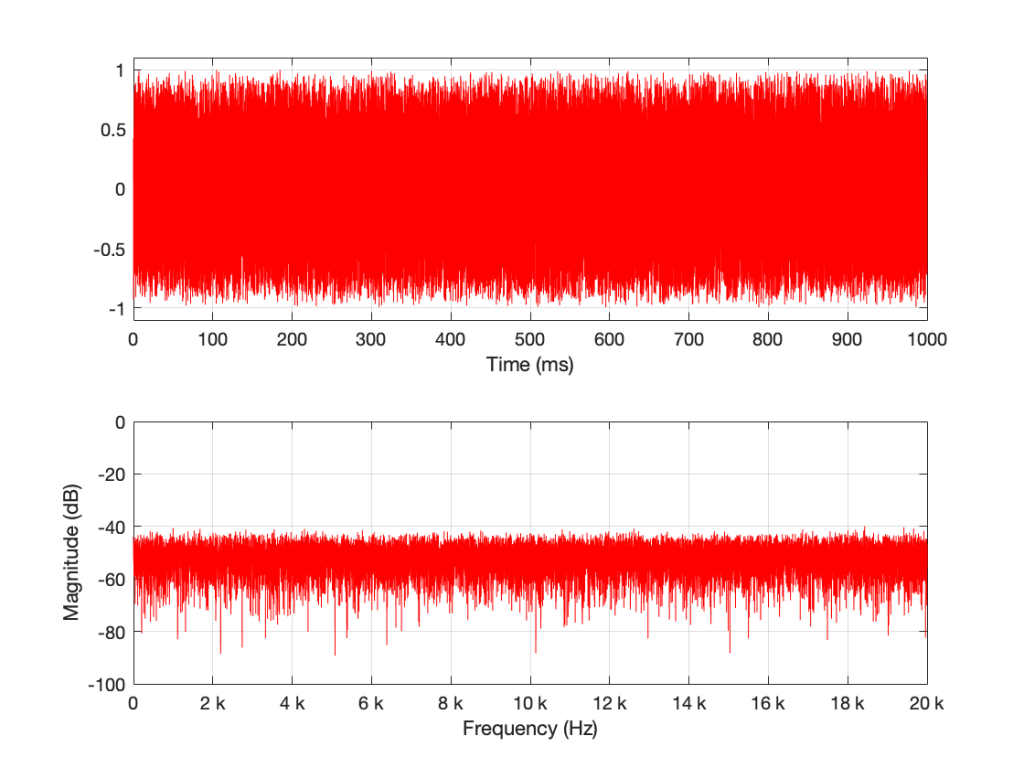
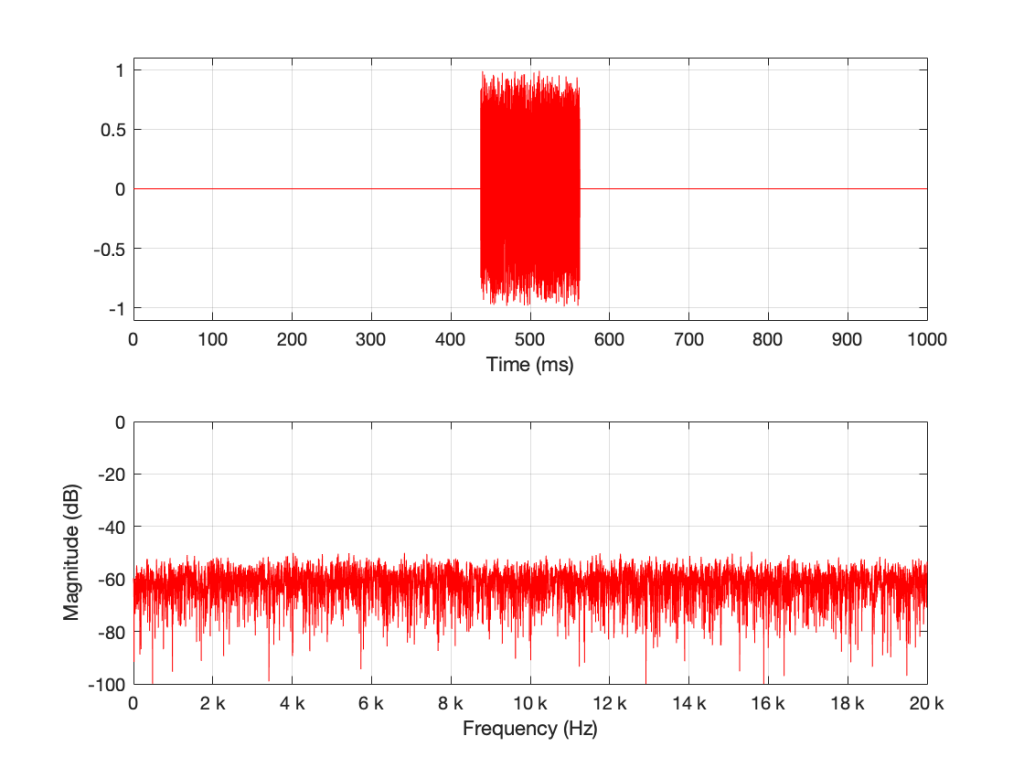
Let’s look at an example. I made a white noise signal in Matlab using the statement rand(SignalLength, 1) – rand(SignalLength, 1) where SignalLength is the length of the noise signal in samples, and the 1 means that I’m doing this for 1 audio channel…. mono is so retro…
You may be wondering why I did a rand() – rand() instead of just a rand(). the simple answer for now was that I wanted to make the signal “balanced” on either side of the zero line and the rand() function in Matlab has a range of 0 to 1.
I know… I could have done this by saying 2 * (rand(SignalLength, 1) – 0.5) but there is another reason that we’ll get into later…)
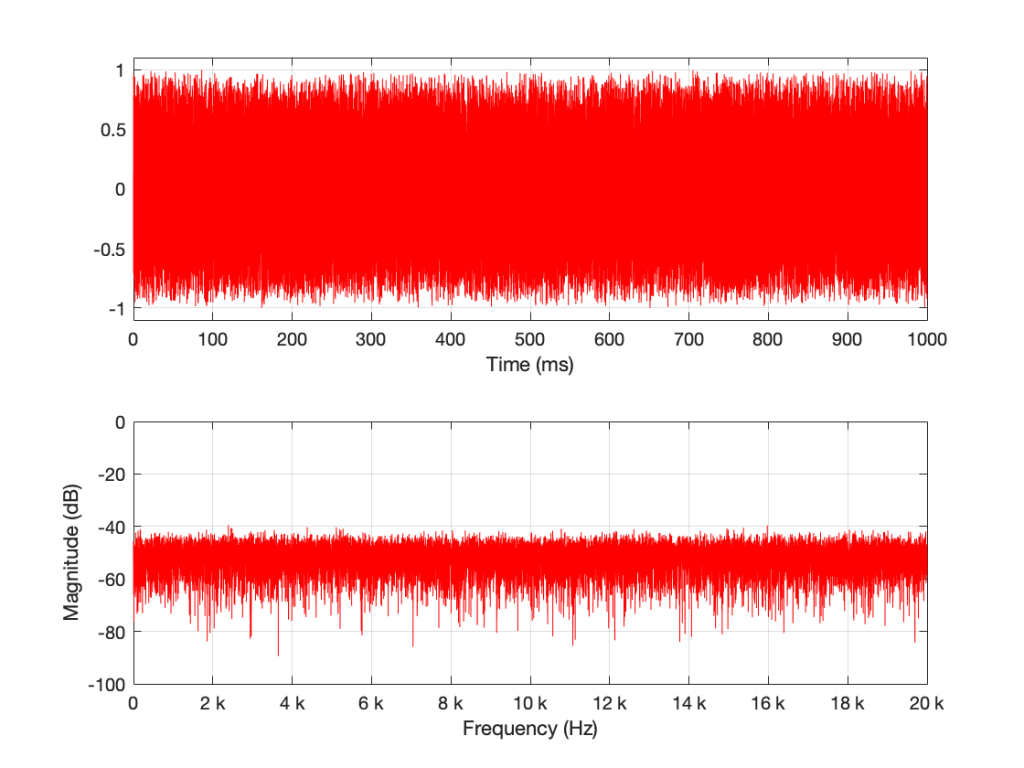
I then used a DFT to find the magnitude response of this signal. The result – both the signal and its magnitude response – are shown below in Figure 1.
Figure 1: A random signal shown in the time domain (top plot) and its magnitude response (bottom plot).
Some additional information that is really not important: The sampling rate of this signal is 2^16 (65,536 Hz), and I did a 2^16 point DFT, so I have one frequency bin per hertz. (If this last bit of information is confusing, but interesting, please start reading this…)
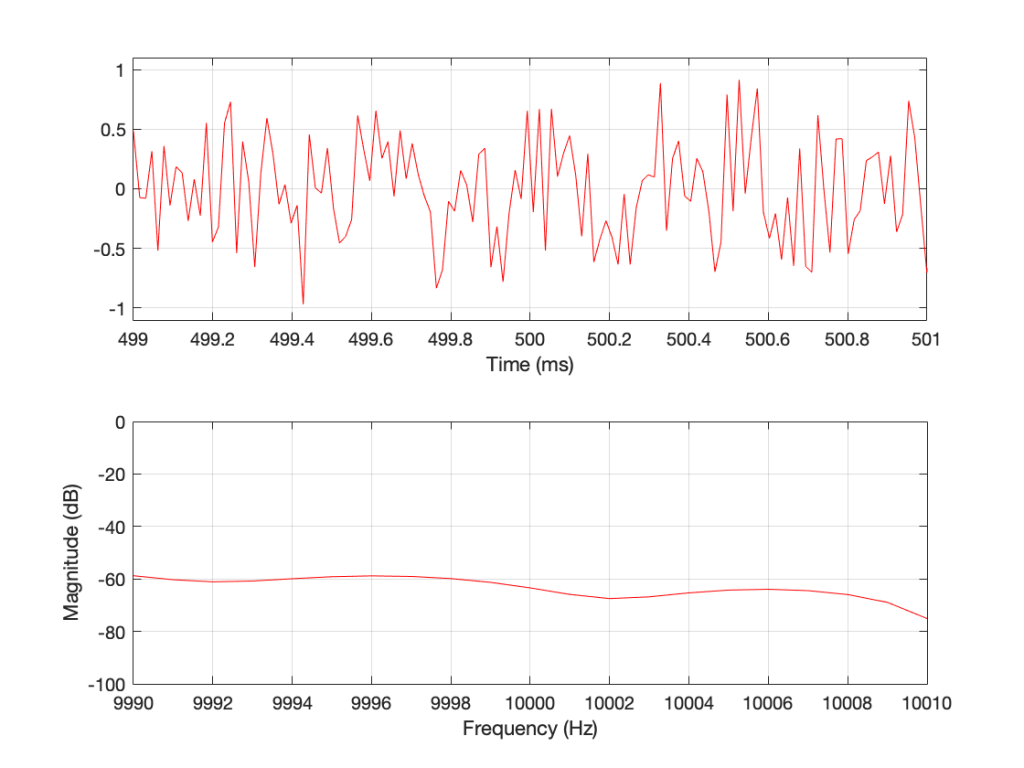
You may notice that the magnitude is “flat” – meaning that it generally doesn’t slope upwards or downwards. However, you will also notice that it is certainly not “flat” – meaning that it is not a perfectly straight line. In fact, if we zoom in on both plots, we can see Figure 2.
Figure 2: A portion of Figure 1, zoomed in to show some details.
Notice that we do NOT have an equal amount of energy per hertz… if we did, then the bottom plot would be a flat line.
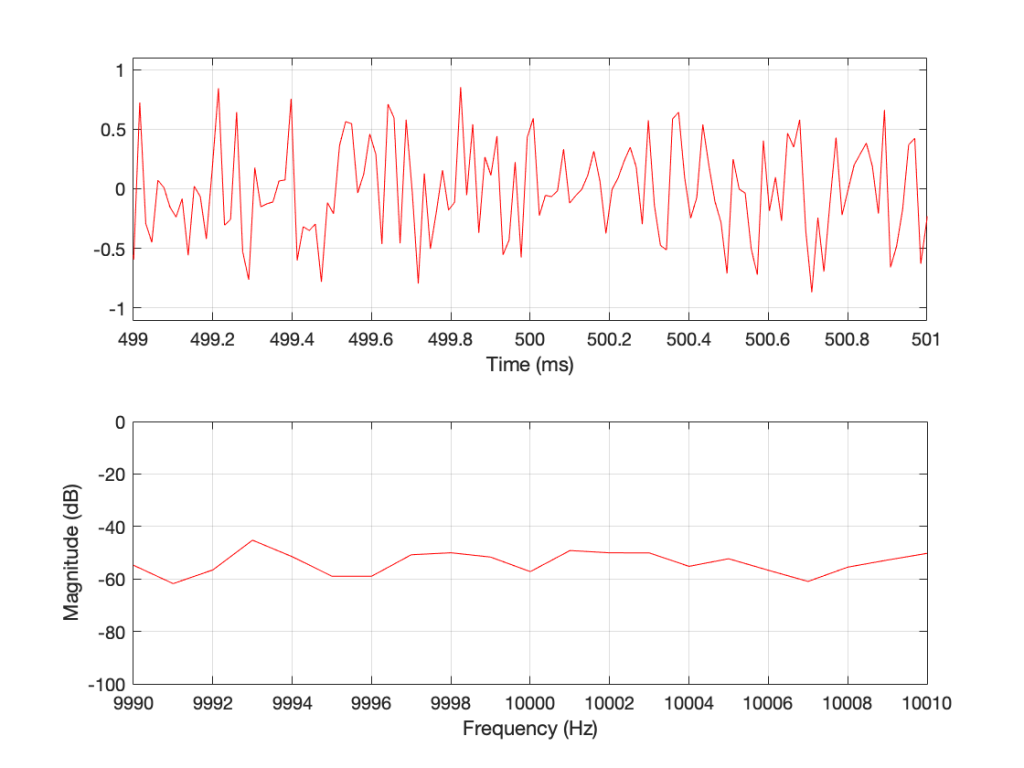
If I do all of that again – make a new noise sample the same way (with a new set of random numbers) and plot the result, and a zoomed in version, I get Figures 3 and 4.
Figure 3: The result of running the same code that generated Figure 1. However, this is a new set of random numbers. Notice that, on first glance, it is the same as Figure 1, but if you look carefully, it is completely different.Figure 4: A detail from Figure 3. Notice that, on first glance, it is the same as Figure 2, but if you look carefully, it is completely different.
Compare Figures 1 and 3 or Figure 2 and 4. You’ll notice that they have similar characteristics overall – but not only are they NOT identical, they are completely different (on a sample-by-sample or a DFT bin-by-bin comparison).
Let’s say that I run this code and generate a white noise signal 1 second long, and I then calculate the magnitude response of that noise signal and store it. Then, I’ll repeat this, and average the new magnitude response to the first one. Then, I’ll do it again, each time, including the magnitude response to the average of all of the magnitude responses that I’ve done….
For each 1-second slice of time, the noise signal does not have equal energy per bandwidth – however, it is certainly white noise.
This is because, each time I do this, the average magnitude response will get flatter and flatter… and eventually, after doing this an infinite number of times, it will be a flat line.
This means that, white noise will have an equal amount of energy per bandwidth only if I wait long enough. The question is “how long is long enough?” The answer to that question depends on what you’re doing with it.
Another way to look at this…
In the each of the examples above, I made 1 second-long white noise signals and used the entire signal – all 65,536 samples – to calculate the magnitude response.
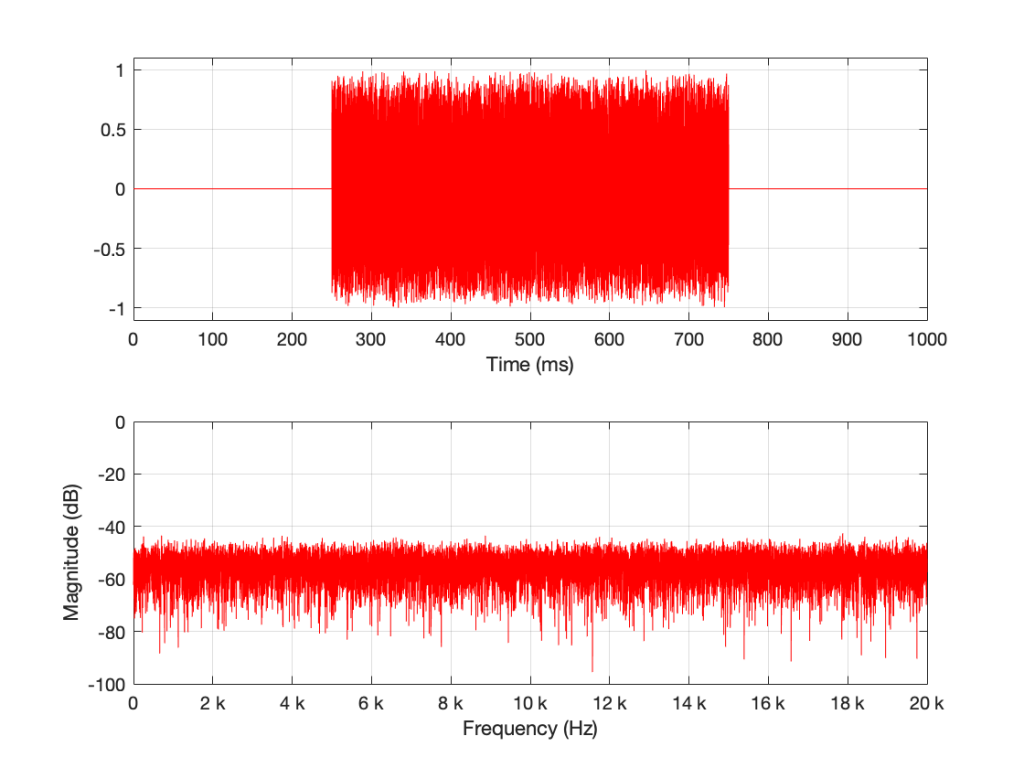
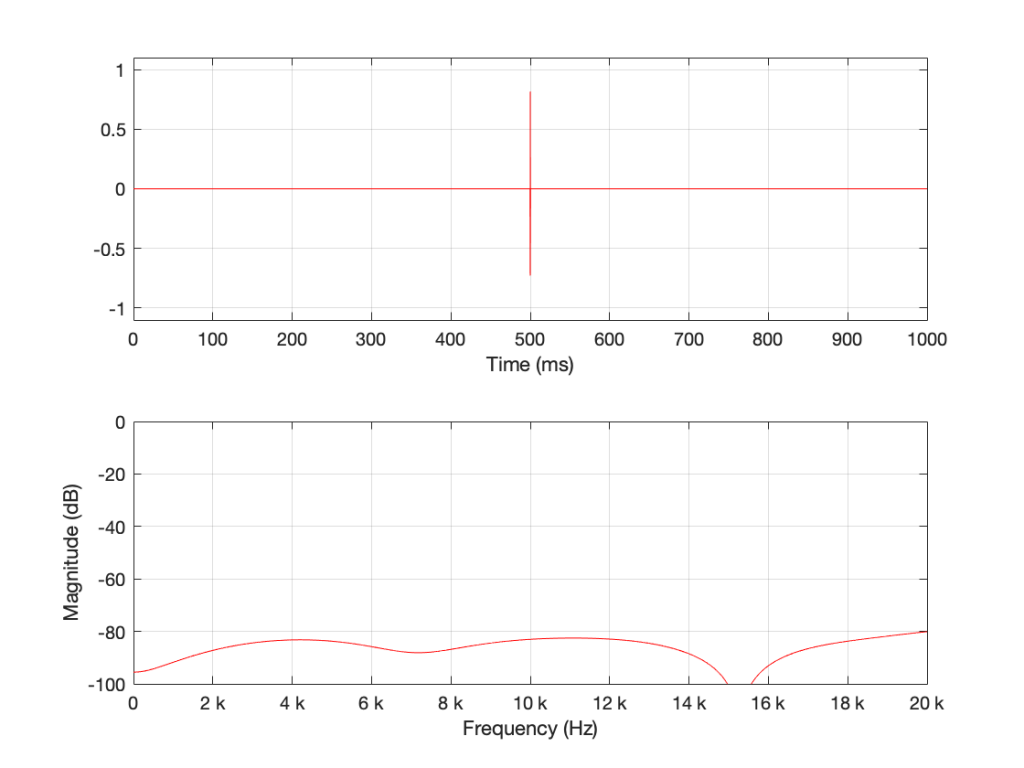
What happens if I have a one-second long signal, but only a portion of it is a burst of white noise, and the rest is silence? For example, look at Figure 5.
Figure 5: A 1-second long signal that contains a burst of white noise for 0.5 seconds.
Figure 5’s magnitude response looks similar to the ones we’ve seen before (apart from being a little lower overall than the plots in Figures 1 and 3 – because there’s less energy overall in 0.5 sec of noise than there is in 1 second of noise). I’ll keep going to show what happens if we take this to an extreme.
Figure 6. 1/8-second of noise in a 1-second signalFigure 7. A detail from Figure 6. Notice how smooth the magnitude response has become…
The magnitude response shown in Figure 7 looks very different from the ones we’ve seen before. It’s much smoother… We’ll keep going…
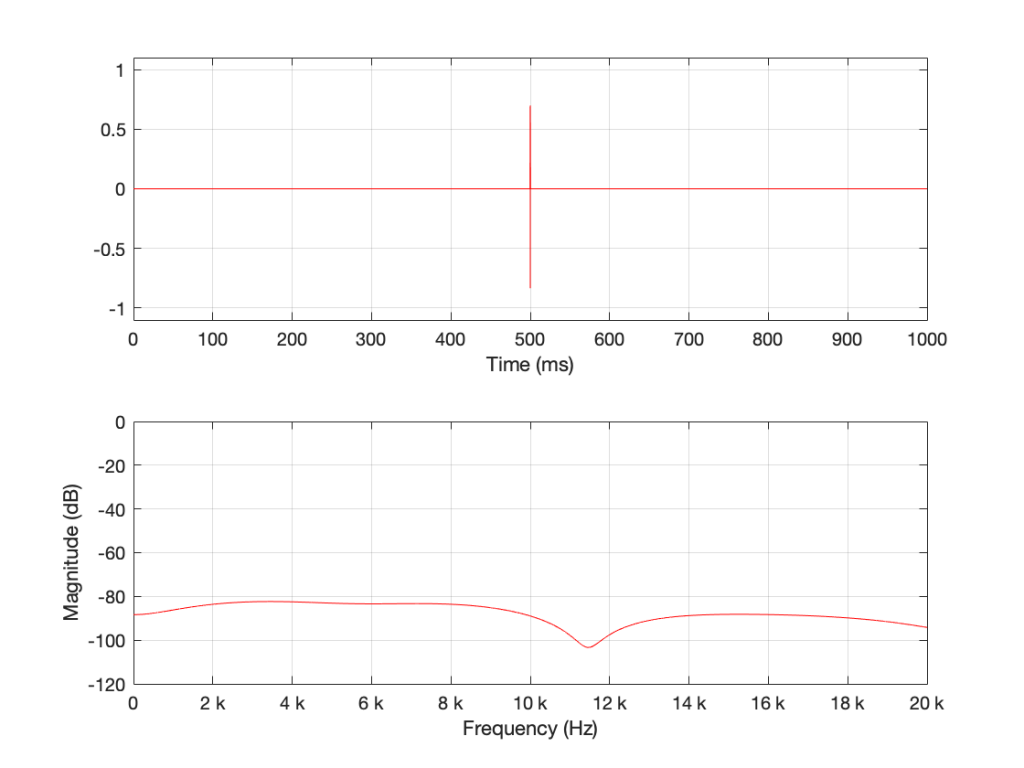
Figure 8. 16 samples of white noise in the middle of a 65,536 sample long signal of silence. Notice that, even when not “zoomed in”, the magnitude response is smooth
Figure 8 is very different again… The total magnitude response, even when not “zoomed in” is smooth. It’s important here to note that the actual response that we see there will be different every time I run the random generator again. For example, look at Figure 9, which is also a 16-sample long white noise signal.
Figure 9. 16 samples of white noise in the middle of a 65,536 sample long signal of silence. Notice that, even when not “zoomed in”, the magnitude response is smooth – but it is not identical to the one in Figure 8 because the random numbers are not the same.
If we keep getting shorter and shorter, eventually we’ll get down to a single sample with a random value. However, since it’s a single sample (that is very probably non-zero) in a long string of zeros, then its magnitude response will be completely flat. It will not be noise – it will be an impulse with a random level. And it won’t sound like noise – it will sound like a click.
Summary
There are two basic important things to know at this point.
White noise has the frequency content you expect only if you average over time.
The shorter the time the noise is present, the less energy you will have, overall.
Thanks to David for emailing and pointing out that it’s “Hz” and “hertz” but not “Hertz”. I’ve corrected the text above… Being reminded of this reminds me of a Steven Wright joke – “I’m having amnesia and déjà vu at the same time. I think I’ve forgotten this before…”
In Part 5, we talked about the idea of using a windowing function to “clean up” a DFT of a signal, and the cost of doing so. We talked about how the magnitude response that is given by the DFT is rarely “the Truth” – and that the amount that it’s not True is dependent on the interaction between the frequency content of the signal, the signal envelope, the windowing function, the size of the FFT, and the sampling rate. The only real solution to this problem is to know what-not-to-believe when you look at a DFT output.
However, we “only” looked at the artefacts on the magnitude response in the previous posting. In this last posting, we’ll dig a little deeper and NOT throw away the phase information. The problem is that, when you’re windowing, you’re not just looking at a screwed up version of the magnitude response, you’re also looking at a screwed up phase response as well.
We saw in Part 1 and Part 2 how the phase of a sinusoidal waveform can be converted to the sum of a real and an imaginary component. (In other words, if you add a cosine and a sine of the same frequency with very specific separate gains applied to them, the result will be a sinusoidal waveform with any amplitude and phase that you want.) For this posting, we’ll be looking at the artefacts of the same windowing functions that we’ve been working on – but keeping the real and imaginary components separate.
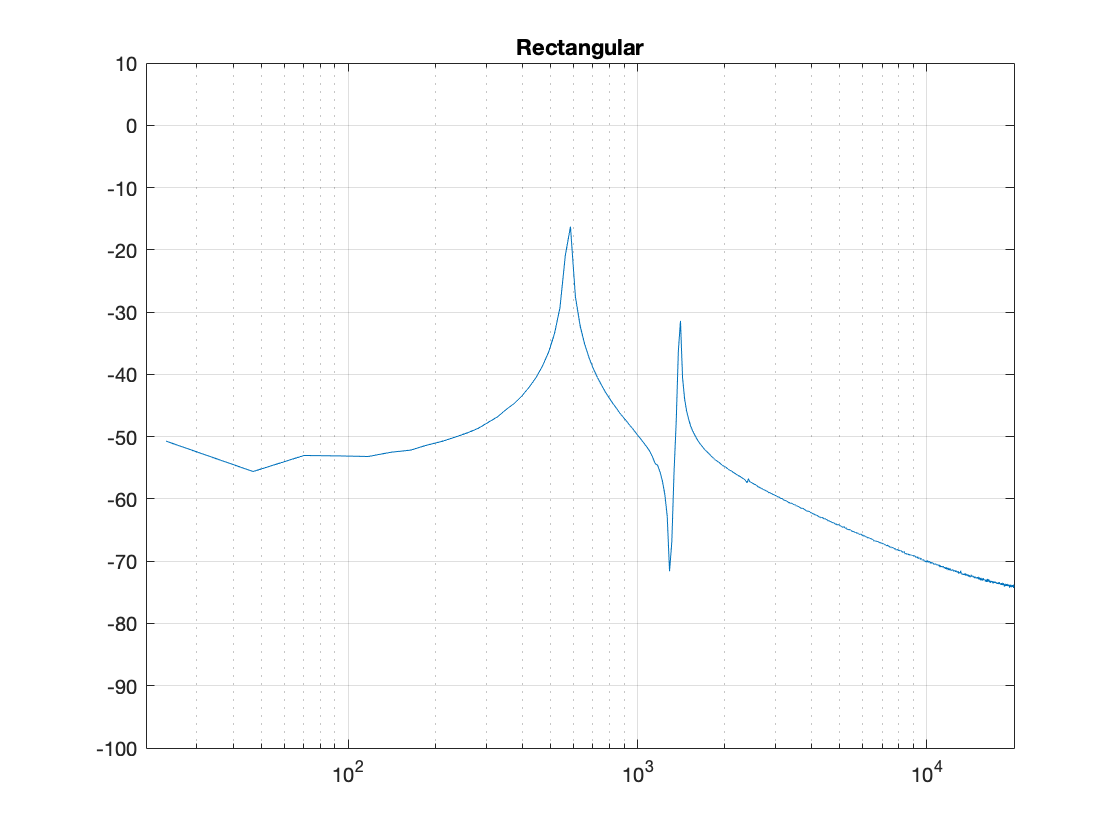
Rectangular windowing
We’ll start by looking at a plot from the previous post, which I’ve duplicated below.
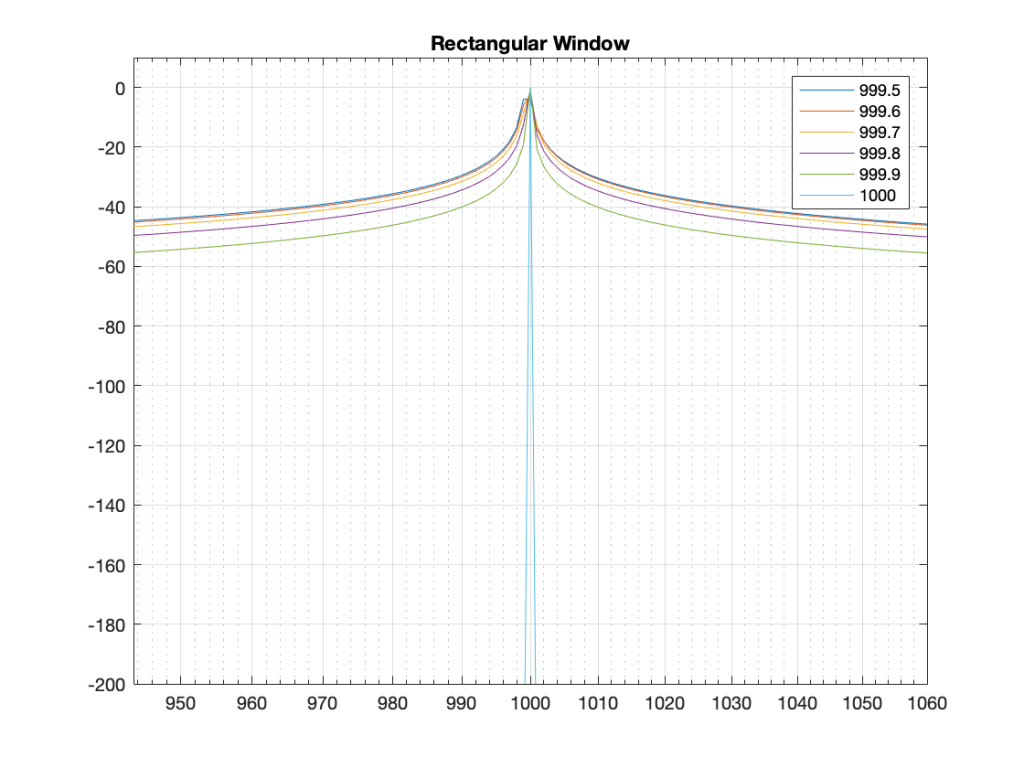
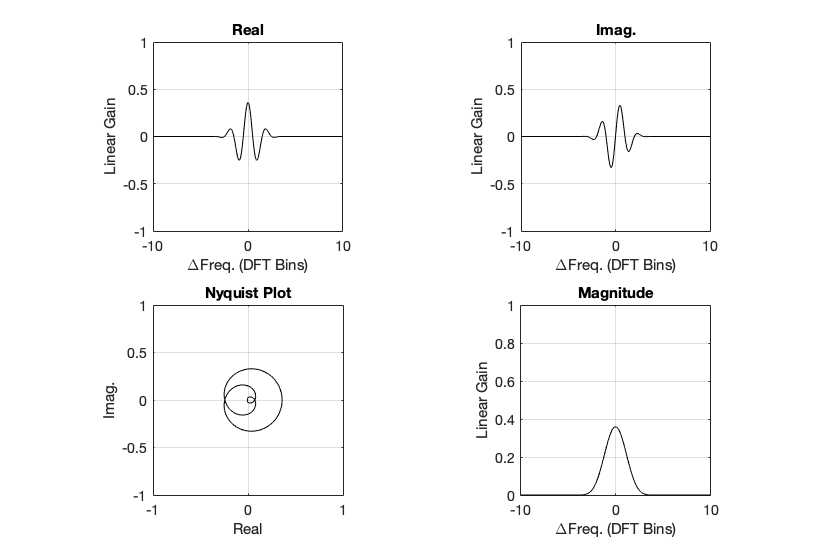
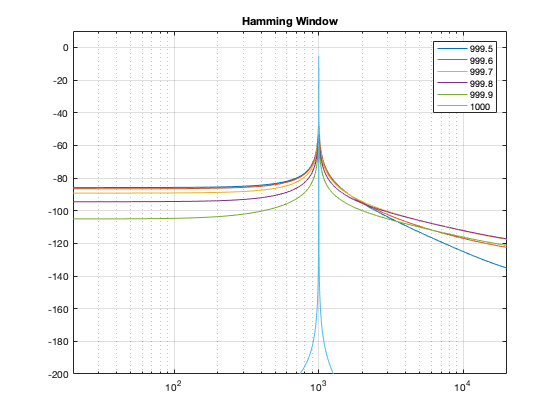
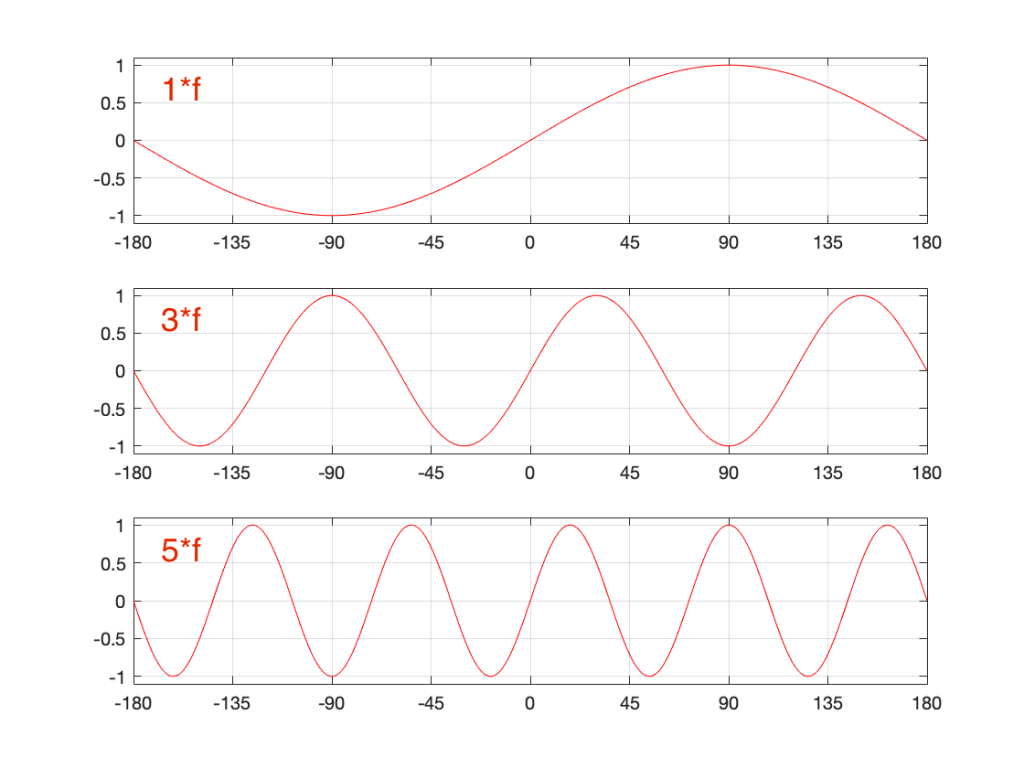
Figure 1: The magnitude responses calculated by a DFT for 6 different frequencies. Note that the bin centre frequency is 1000.0 Hz.
The way I did the plot in Figure 1 was to create a sine wave with a given frequency, do a DFT of that, and plot the magnitude of the result. I did that for 6 different frequencies, ranging from 1000 Hz (exactly on a bin centre frequency) to 999.5 Hz (halfway to the adjacent bin centre frequency).
There’s a different way to plot this, which is to show the result of the DFT output, bin by bin, for a sinusoidal waveform with a frequency relative to the bin centre frequency. This is shown below in Figure 2.
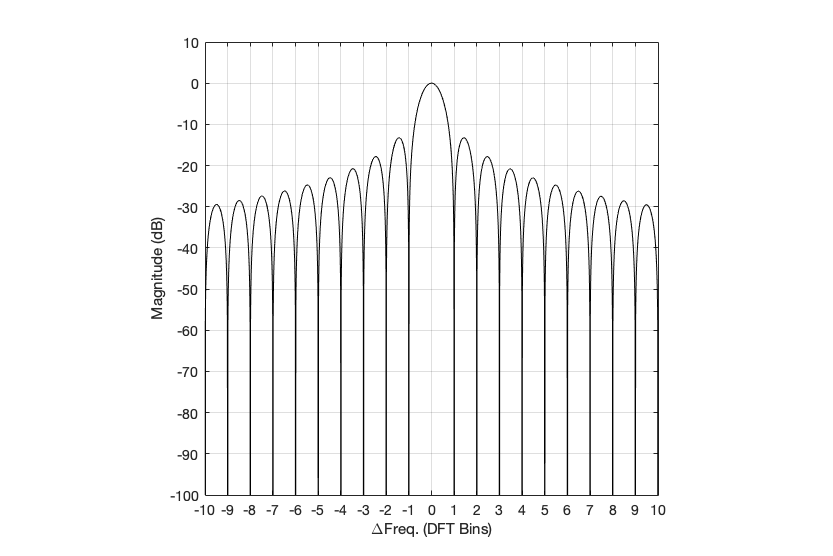
Figure 2: Rectangular window: The relationship between the frequency of the signal, the frequency centres of the DFT bin, and the resulting magnitude in dB. Note that the X-axis is frequency, measured in distance between bin frequencies or “bin widths”.
Now we have to talk about how to read that plot… This tells me the following (as examples):
If the bin centre frequency EXACTLY matches the frequency of the signal (therefore, the ∆ Freq. = 0) then the magnitude of that bin will be 0 dB (in other words, it will give me the correct answer).
If the bin centre frequency is EXACTLY an integer number of bin widths away from the frequency of the signal (therefore, the ∆ Freq. = … -10, -9, – 8… -3, -2, -1, 1, 2, 3, … 8, 9, 10, …) then the magnitude of that bin will be -∞ dB (in other words, it will have no output).
These two first points are why the light blue curve is so good in Figure 1.
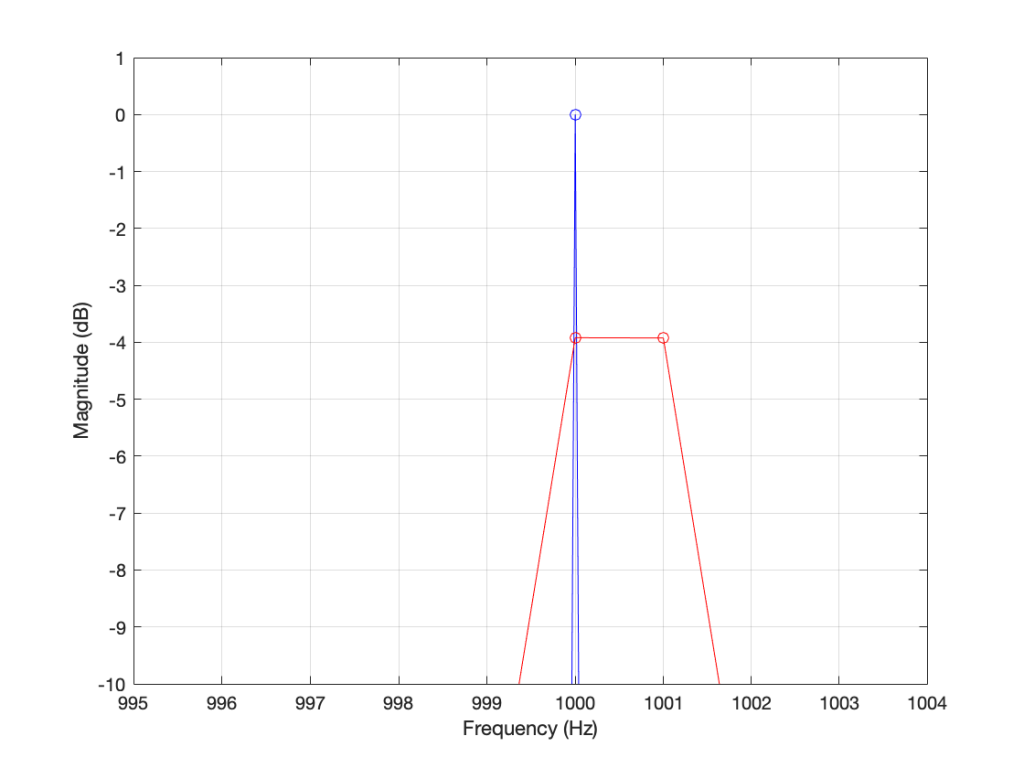
If the frequency of the signal is half-way between two bins (therefore, the ∆ Freq. = -0.5 or +0.5), then you get an output of about -4 dB (which is what we also saw in the blue curve in Figure 25 in Part 5.
If the frequency of the signal is an integer number away from half-way between two bins (for example, ∆ Freq. = -2.5, -1.5, 1.5, or 2.5, etc… ) then the output of that bin will be the value shown at the tops of those bumps in the plots… (For example, if you mark a dot at each place where ∆ Freq. = ±x.5 on that curve above, and you join the dots, you’ll get the same curve as the curve for 999.5 Hz in Figure 1.)
So, Figure 2 shows us that, unless the signal frequency is exactly the same as the bin centre frequency, then the DFT’s magnitude will be too low, and there will be an output from all bins.
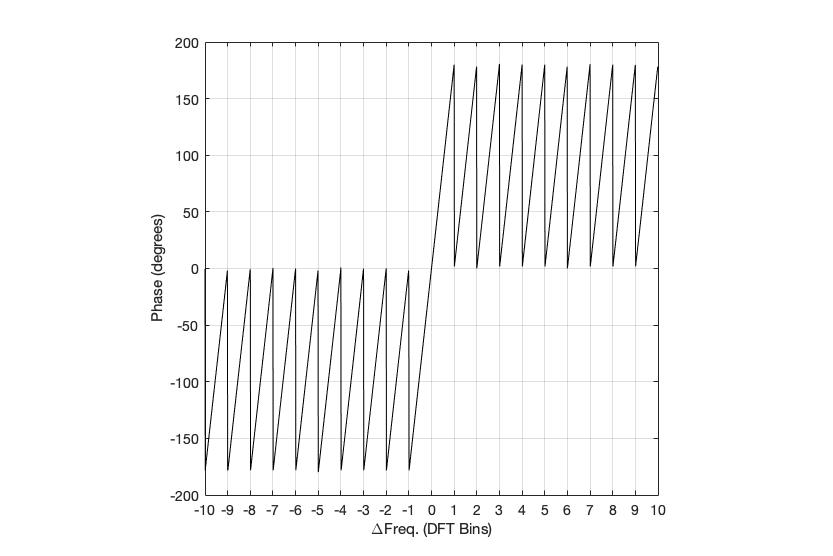
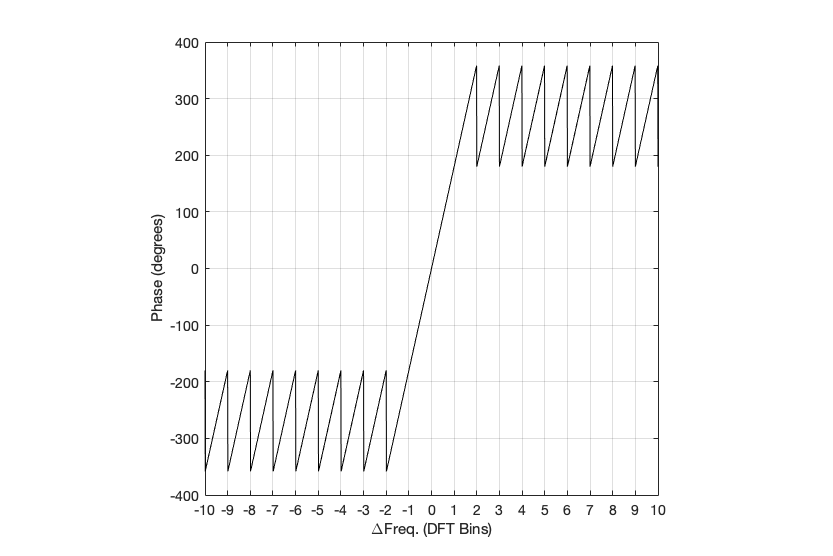
Figure 3: Rectangular window: The relationship between the frequency of the signal, the frequency centres of the DFT bin, and the resulting phase in degrees.
Figure 3 shows us the same kind of analysis, but for the phase information instead. The important thing when reading this plot is to keep the magnitude response plot in mind as well. For example:
when the bin frequency matches the signal frequency (∆ Freq. = 0) then the phase error is 0º.
When the signal frequency is an integer number of bin widths away from the bin frequency, then it appears that the phase error is either 0º or ±180º, but neither of these is true, since the output is -∞ dB – there is no output (remember the magnitude response plot).
There is a gradually increasing error from 0º to ±180º (depending on whether you’re going up or down in frequency)( as the signal frequency moves from being adjacent to one bin or the next.
When you signal frequency crosses the bin frequency, you get a polarity flip (the vertical lines in the sawtooth shape in the plot).
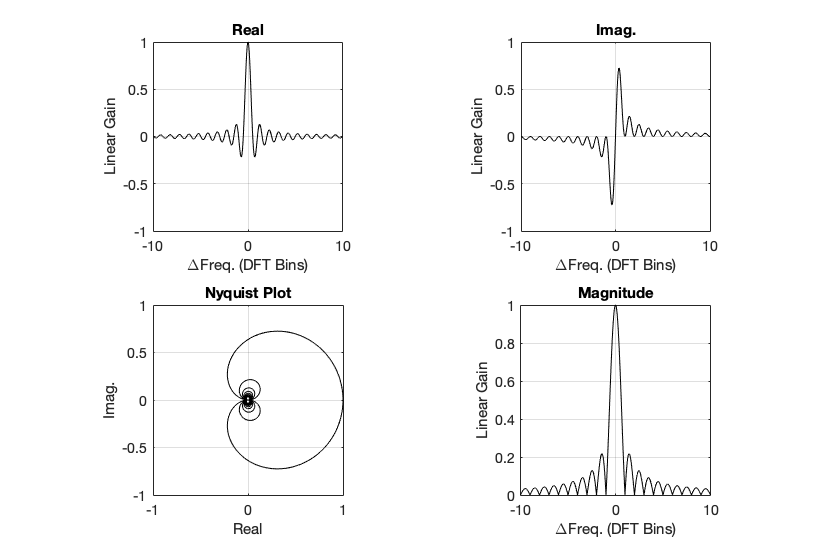
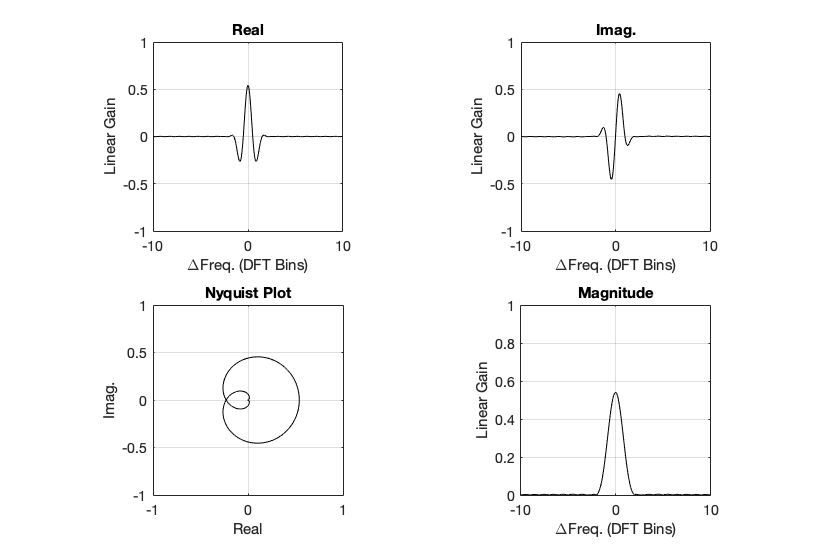
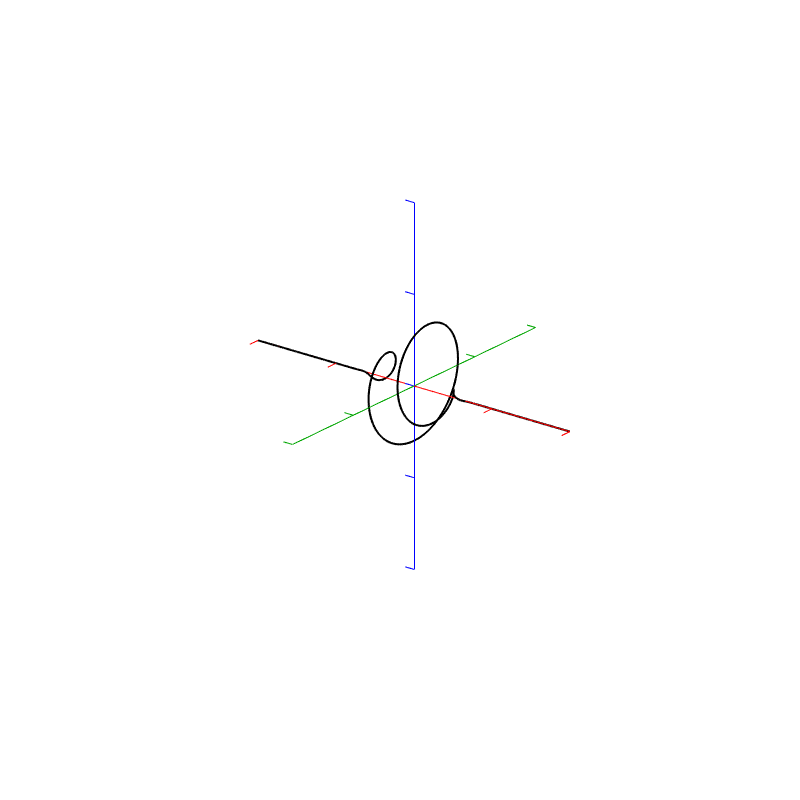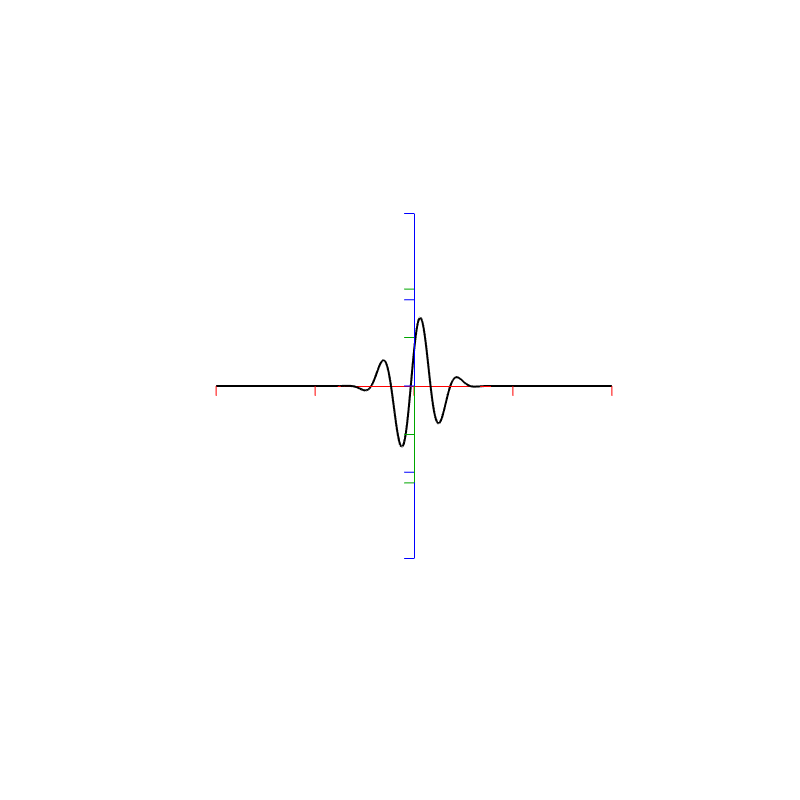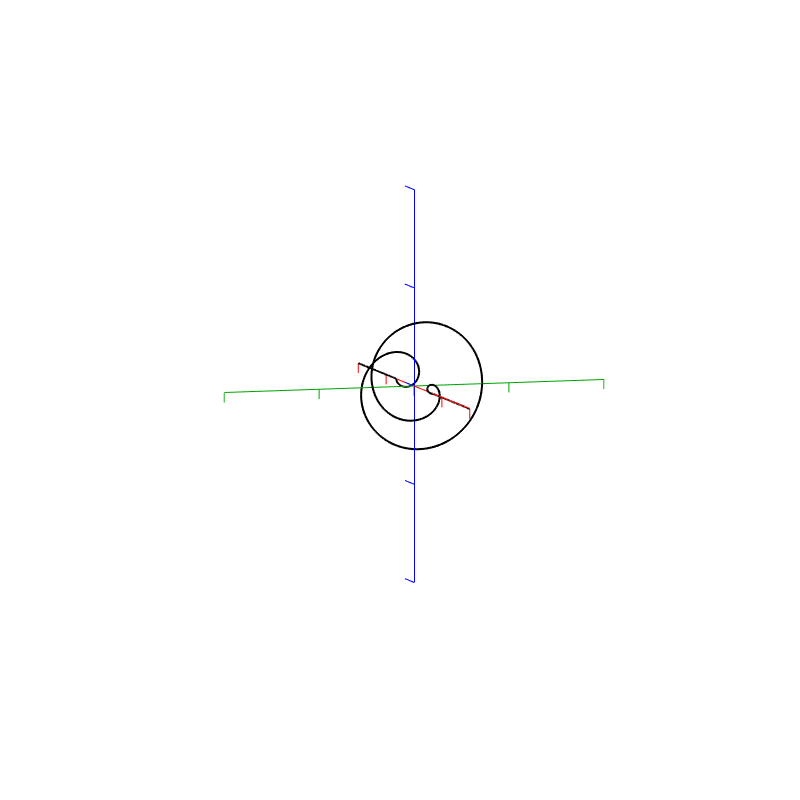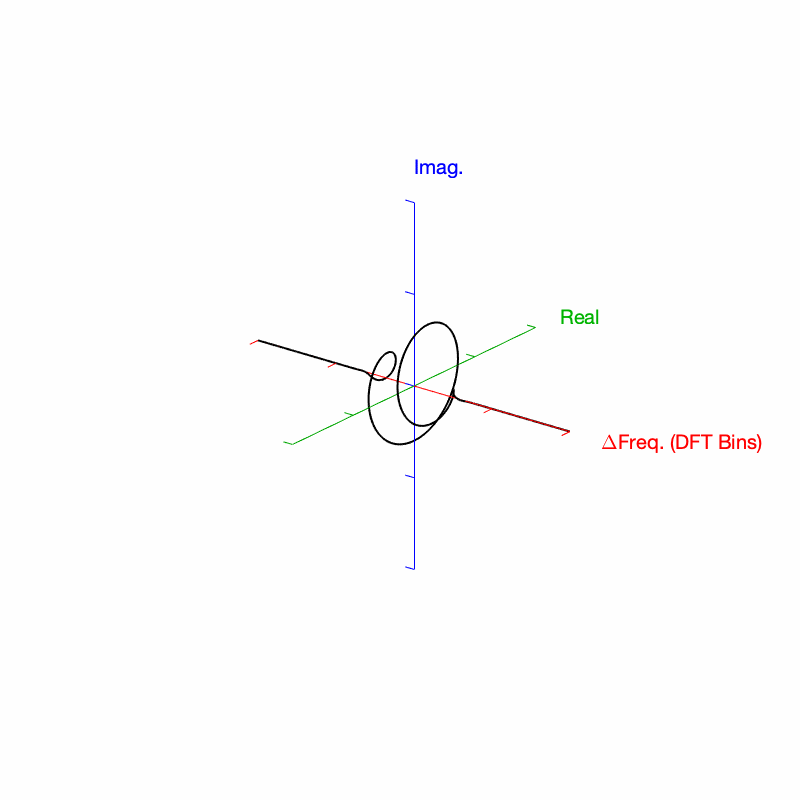
Figure 4. Rectangular window: The top two plots show the same relationship as in Figures 2 and 3, but divided into the various components, as explained below.
Figure 4, above, shows the same information, plotted differently.
The bottom right plot shows the magnitude response (exactly the same as shown in Figure 2) on a linear scale instead of in dB.
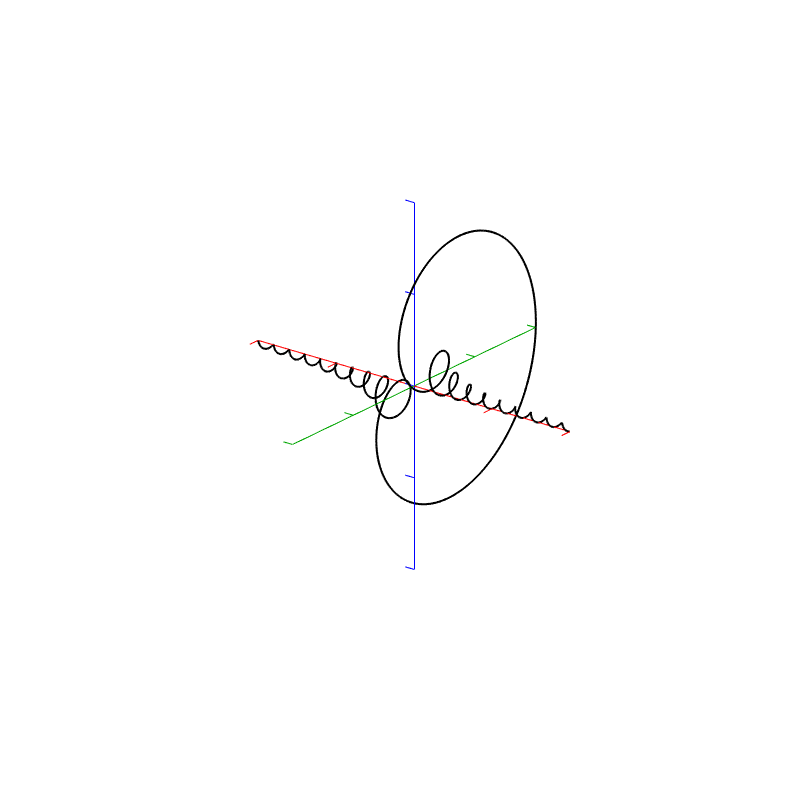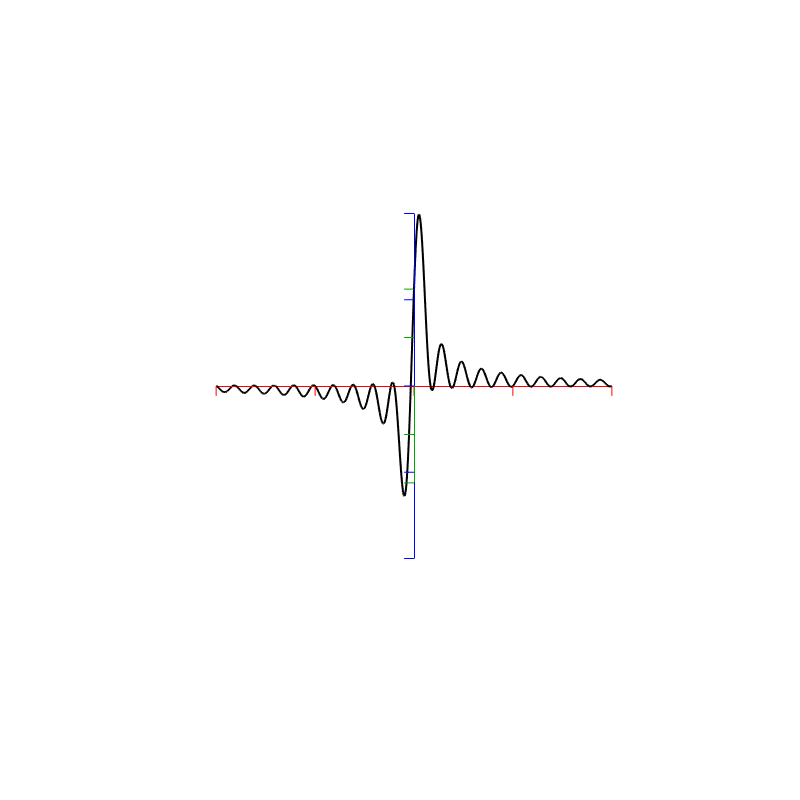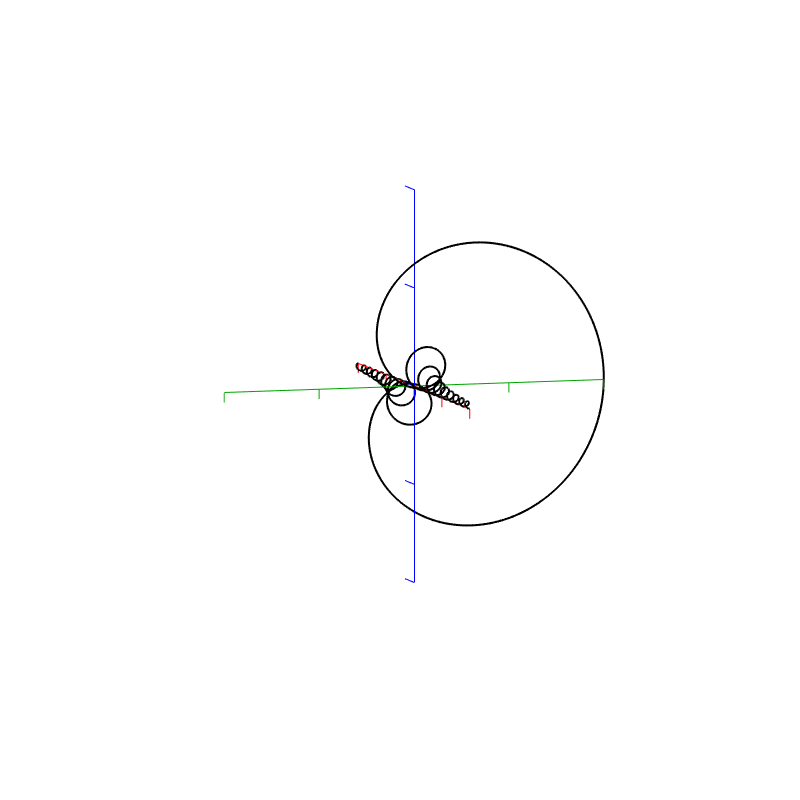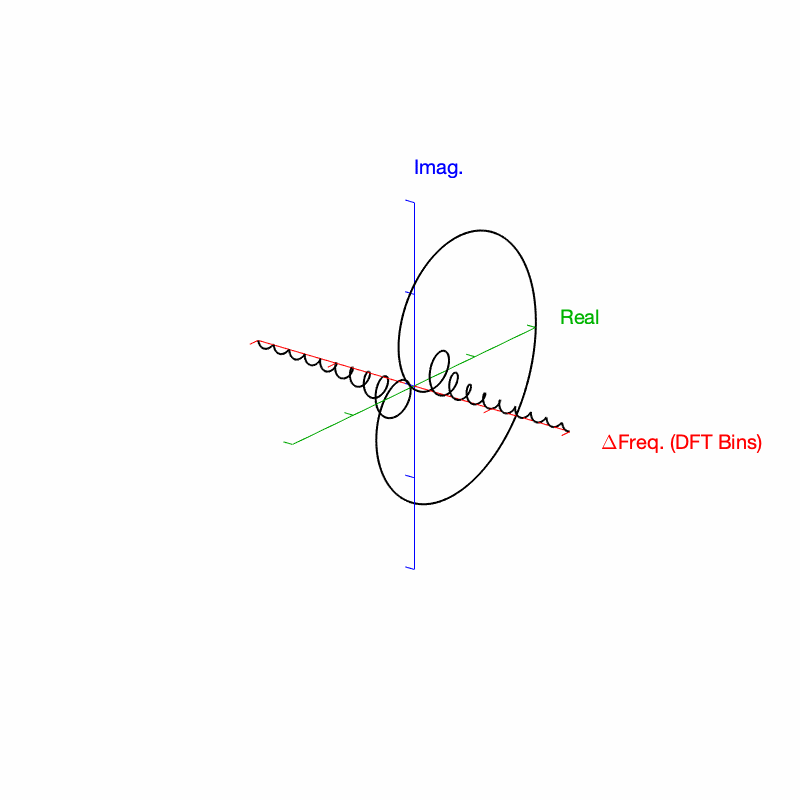
The top two plots show the Real and Imaginary components, which, combined, were used to generate the Magnitude and Phase plots. (Remember from Parts 1 and 2 that the Real component is like looking at the response from above, and the Imaginary component is like looking at the response from the side.)
The Nyquist plot is difficult, if not impossible to understand if you’ve never seen one before. But looking at the entire length of the animation in Figure 5, below, should help. I won’t bother explaining it more than to say that it (like the Real vs. Freq. and the Imaginary vs. Freq. plots) is just showing two dimensions of a three-dimensional plot – which is why it makes no sense on its own without some prior knowledge.
Figure 5. Rectangular window: The Real, Imaginary, and Nyquist plots from Figure 4, viewed from different angles.
Hopefully, I’ve said enough about the plots above that you are now equipped to look at the same analyses of the other windowing functions and draw your own conclusions. I’ll just make the occasional comment here and there to highlight something…
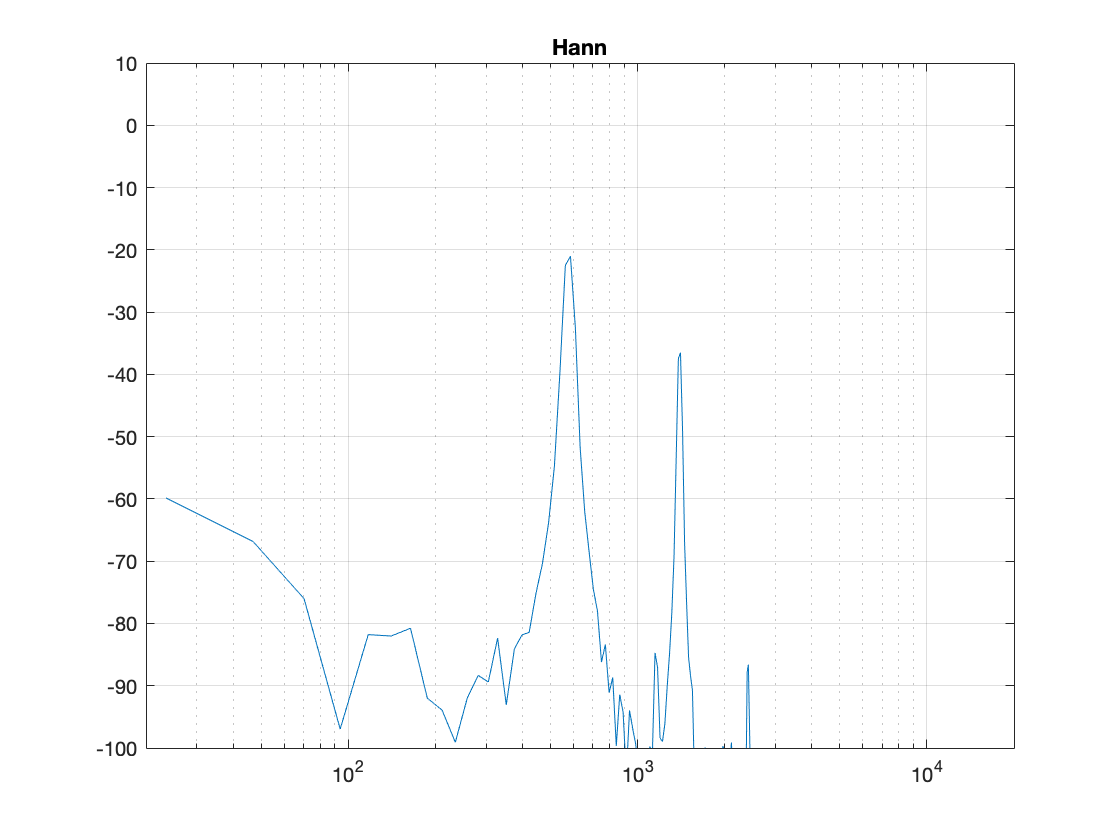
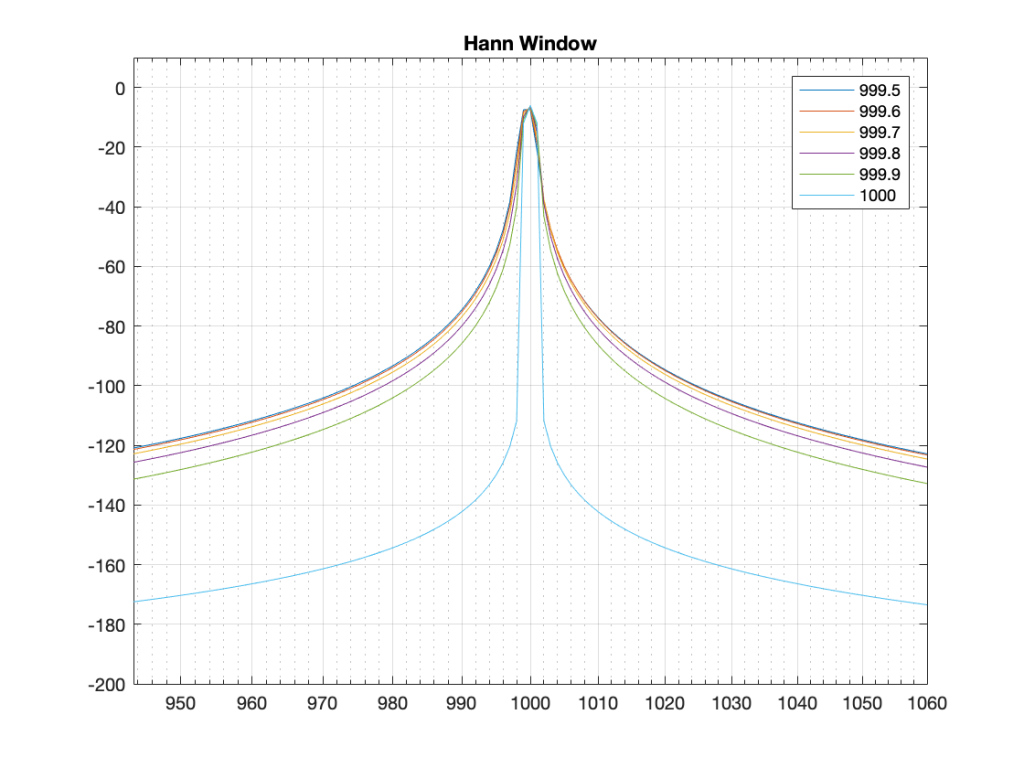
Hann Window
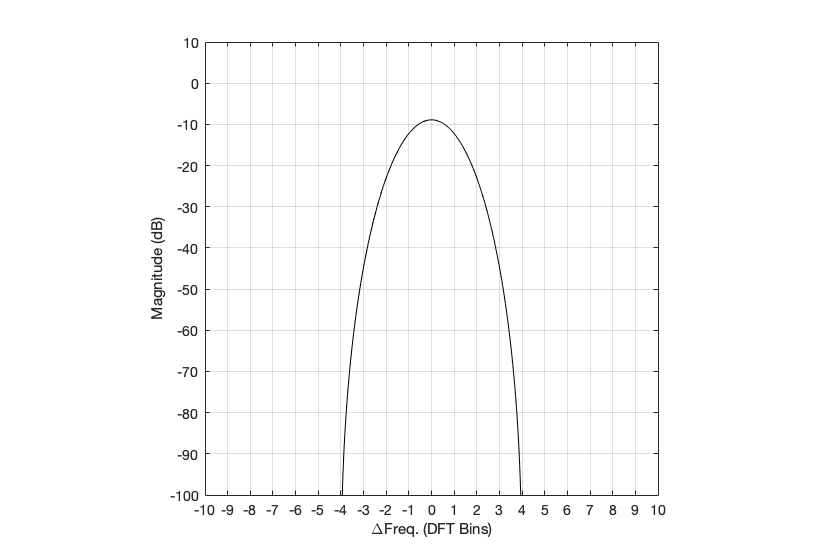
Figure 6: Hann window: magnitude response error
Generally, the things to note with the Hann window are the wider centre lobe, but the lower side lobes (as compared to the rectangular windowing function).
Figure 7: Hann window: Phase response errorFigure 8: Hann window: Real, Imaginary, and Nyquist plotsFigure 9: Hann window: Real, Imaginary, and Nyquist plots in all three dimensions.
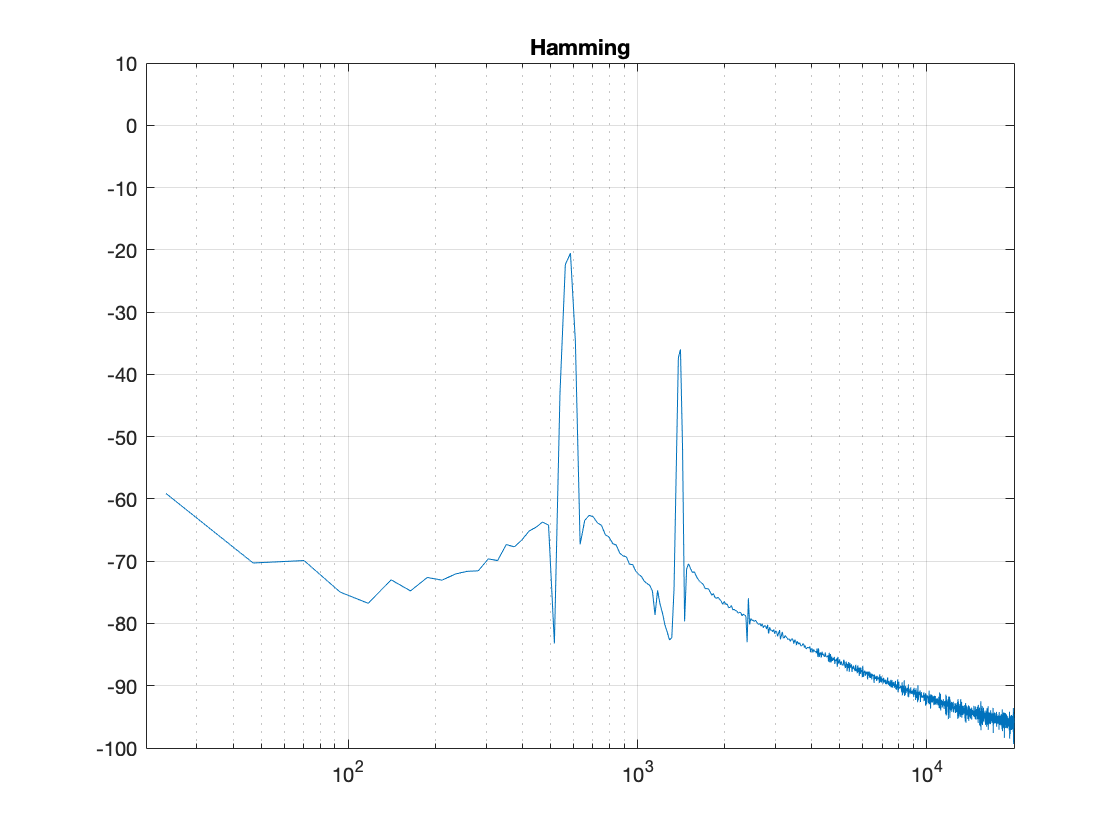
The interesting thing about the Hamming window is that the lobes adjacent to the main lobe in the middle are lower. This might be useful if you’re trying to ignore some frequency content next to your signal’s frequency.
Figure 11: Hamming window: Phase response error.Figure 12: Hamming window: Real, Imaginary, and Nyquist plotsFigure 13: Hamming window: Real, Imaginary, and Nyquist plots in all three dimensions
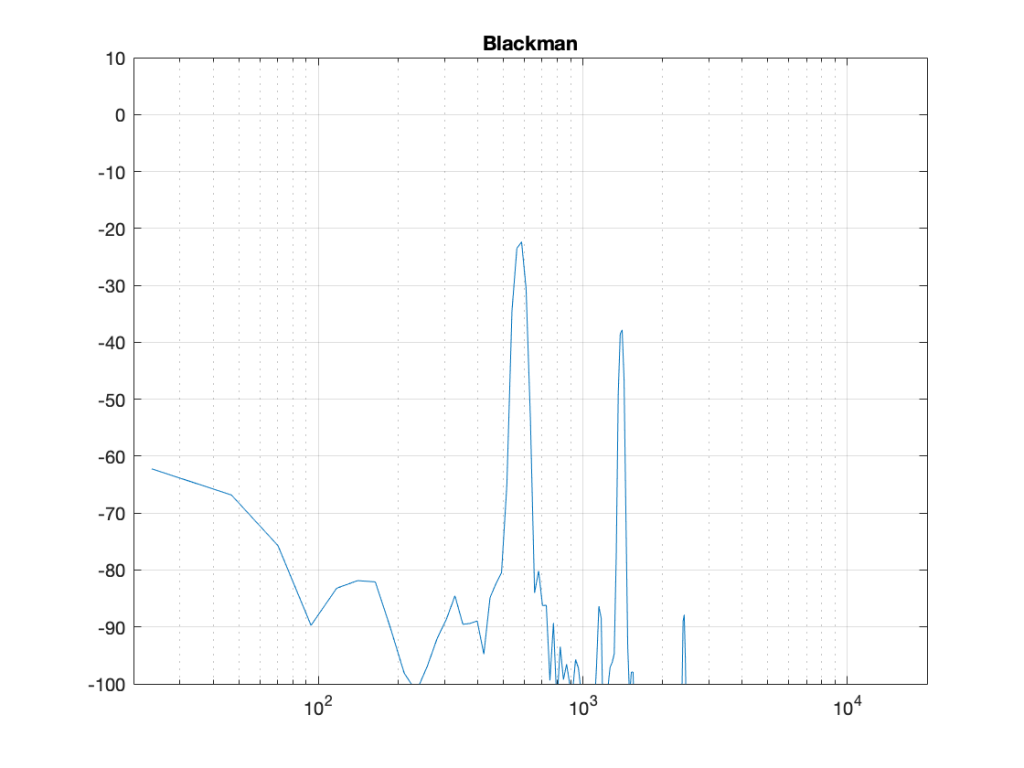
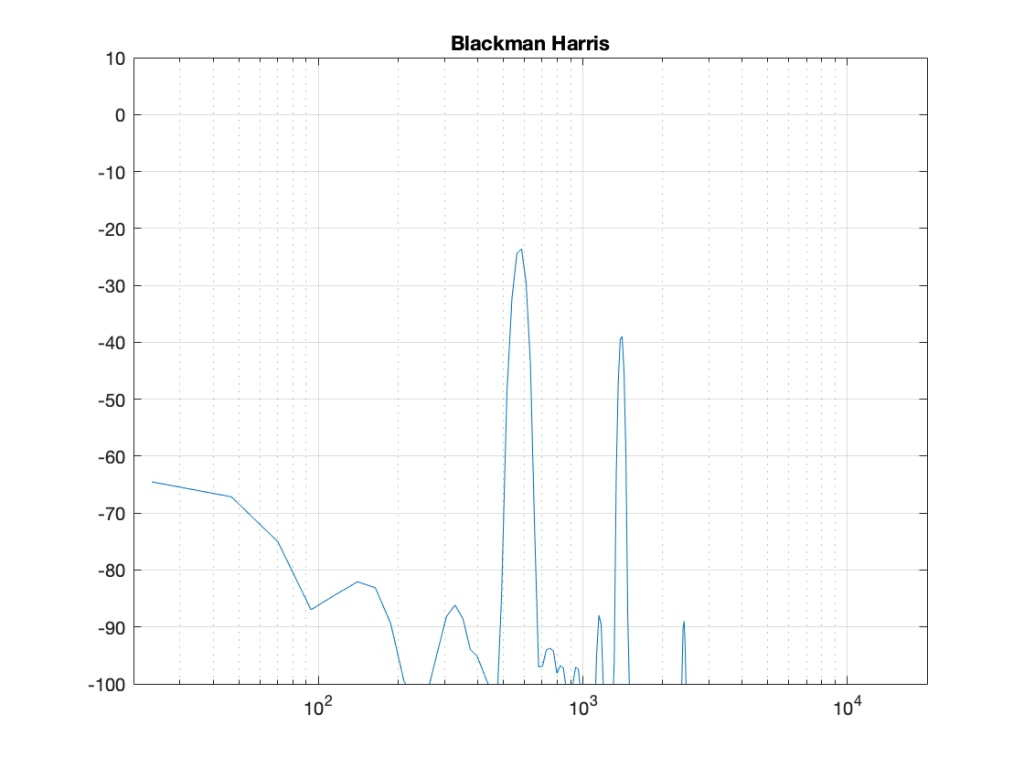
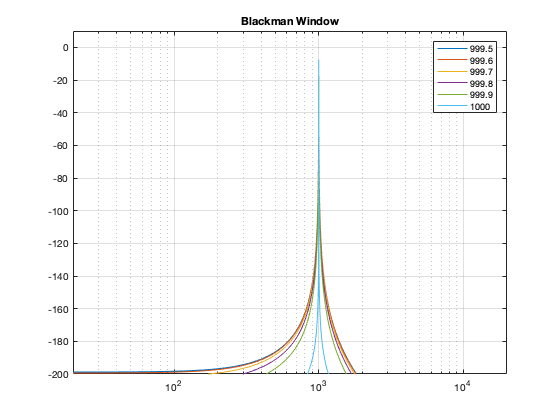
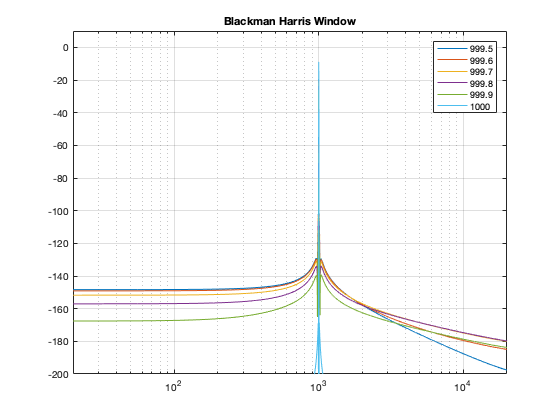
Although the Blackman-Harris window results in a wider centre lobe, as you can see in Figure 18, the side lobes are all at least 90 dB down from that…
Figure 19: Blackman-Harris window: Phase response error.Figure 21: Blackman-Harris window: Real, Imaginary, and Nyquist plotsFigure 22: Blackman-Harris window: Real, Imaginary, and Nyquist plots in all three dimensions.
Wrapping up
I know that there’s lots left out of this series on DFT’s. There are other windowing functions that I didn’t talk about. I didn’t look at the math that is used to generate the functions… and I just glossed over lots of things. However, my intention here was not to do a complete analysis – it was a just an introductory discussion to help instil a lack of trust – or a healthy suspicion about the results of a DFT (or FFT – depending on how fast you do the math….).
Also, a reason I did this series was as a set-up, so when I write about some other topics in the future (like the actual resolution of 16-bit LPCM audio in a fixed point world, or the implications of making a volume control in the digital domain as just two examples…), I can refer back to this, pointing out what you can and cannot believe is the plots that I haven’t even made yet…
The previous posting in this series showed that, if we just take a slice of audio and run it through the DFT math, we get a distorted view of the truth. We’ll see the frequencies that are in the audio signal, but we’ll also see that there’s energy at frequencies that don’t really exist in the original signal. These are artefacts of slicing a “window” of time out of the original signal.
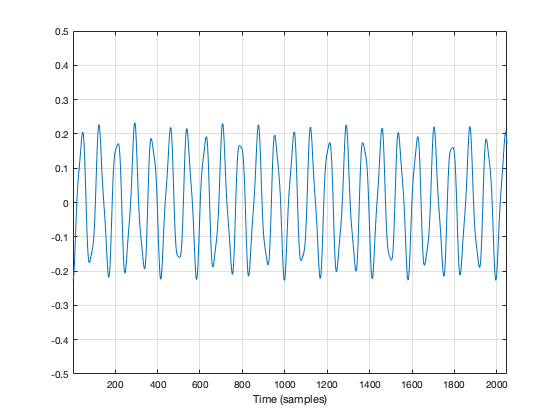
Let’s say that I were a musician, making samples (in this sentence, the word “sample” means what it means to musicians – a slice of a recording of a sound that I will play using a sampler) to put into my latest track in my new hip hop album. (Okay, I use the word “musician” loosely here… but never mind…) I would take a sample – say, of the bell that I recorded, which looks like this:
Figure 1: My original bell recording – or 2048 samples of it, at least…
We’ve already seen that the first sample (now I’m back to using the technical definition of the word “sample” – an instantaneous measurement of the amplitude of the signal) and the last sample aren’t on the 0 line. So, if we just play this recording, it will start and end with a “click”.
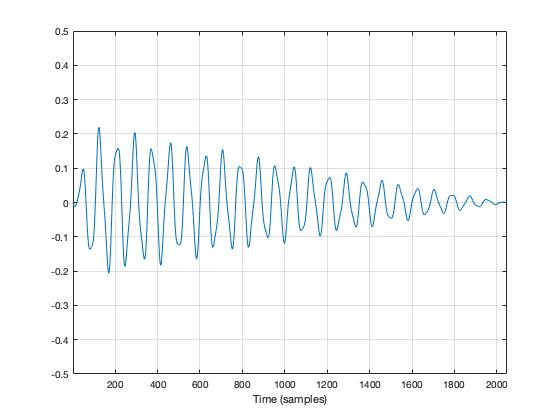
We get rid of the click by applying a “fade” on the start and the end of the recording, resulting in something like the following:
Figure 2: The same recording with a fade in and a fade out applied to it. Now it will sound more like a bell because it has a fast attack (a short fade in) and a longer decay (fade out).
So, the moral of the story so far is that, in order to get rid of an audible “click”, we need to fade in and fade out so that we start and end on the 0 line.
We can do the same thing to our slice of audio (from now on, I’m going to call it a “window”) to help the computer that’s doing the DFT math so that it doesn’t get all the extra frequency content caused by the clicks.
In Figure 2, above, I was being artistic with my fade in and fade out. I made the fade in fast (100 samples long) and I made the fade in slow (2000 samples long) so that the end result would look and sound more like a bell. A computer doesn’t care if we’re artistic or not – we’re just trying to get rid of those clicks. So, let’s do it.
Option 1 is to do nothing – which is what we’ve done so far. We take all of the individual samples in our window, and we multiply them by 1. (All other samples (the ones that we’re not using because they’re outside the window) are multiplied by 0.) If you think about what this looks like if I graph it in time, you’ll imagine a rectangle with a height of 1 and a length equal to the length of the window in samples.
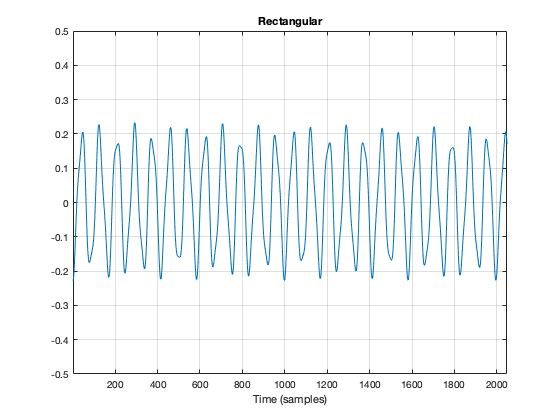
If I do that to my original bell recording, I get the result shown in Figure 3.
Figure 3. The original bell sound, where each sample was multiplied by 1.
You may notice that Figure 3 is almost identical to Figure 1. The only difference is that I put the word “Rectangular” at the top. The reason for this will become clear later.
As we’ve already seen, this rectangular windowing of our recording is what gives us the problems in the first place. So, if I do a DFT of that window, I’ll get the following magnitude response.
Figure 4. The magnitude response of the bell sound with a rectangular window, as shown in Figure 3.
What we know already is that we want to fade in and fade out to get rid of those clicks. So, let’s do that.
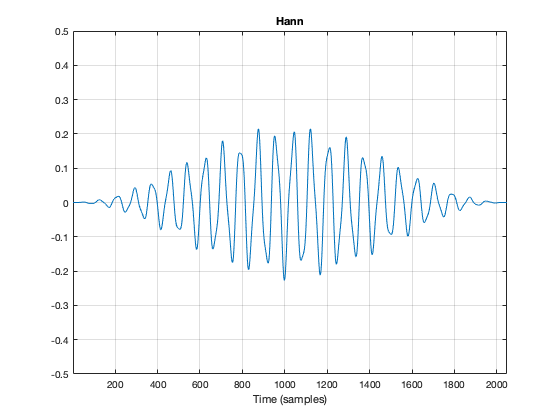
Figure 5. The original bell sound, with a fade in and fade out applied to it.
Figure 5, above, shows the result. the ramp in and the ramp out are not straight lines – in fact, they look very much like the shape of an upside-down cosine wave (which is exactly what they are…). If we do a DFT of that window, we get the result shown in Figure 6.
Figure 6. The magnitude response of the bell sound with a Hann window, as shown in Figure 5.
There are now some things to talk about.
The first is to say that the shape of this “envelope” or “windowing function” – the gain over time that we apply to the audio signal – is named after the Austrian meteorologist Julius von Hann. He didn’t invent this particular curve – but he did come up with the idea of smoothing data (but in his case, he was smoothing meteorological data over geographical regions – not audio signals over time). Because he came up with the general idea, they named this curve after him.
Important sidebar: Some people will call this a “Hanning” window. This is not strictly correct – it’s a Hann function. However, you can use the excuse that, if you apply a Hann window to the signal, then you are hanning it… which is the kind of obfuscated back-pedalling and revisionist history used to cover up a mistake that is typically only within the purview of government officials.
The second thing is to notice is that the overall response at frequencies that are not in the original signal has dropped significantly. Where, in Figure 4, we see energy around -60 dB FS at all frequencies (give or take….) the plot in Figure 6 drops down below -100 dB FS – off the plot. This is good. It’s the result of getting rid of those non-zero values at the start and stop of the window… No clicks means no energy spread all over the frequency spectrum.
The third thing to discuss is the levels of the peaks in the plots. Take a look at the highest peak in Figure 4. It’s about -17 dB FS or so. The peak at the same frequency in Figure 6 is about -21 dB or so… 4 dB lower… This is because, if you look at the entire time window, there is indeed less energy in there. We made portions of the signal quieter, so, on average, the whole thing is quieter. We’ll look at how much quieter later.
This is where things get a little interesting, because some people think that the way that we faded in and faded out of the window (specifically, using a Hann function) can be improved in some way or another… So, let’s try a different way.
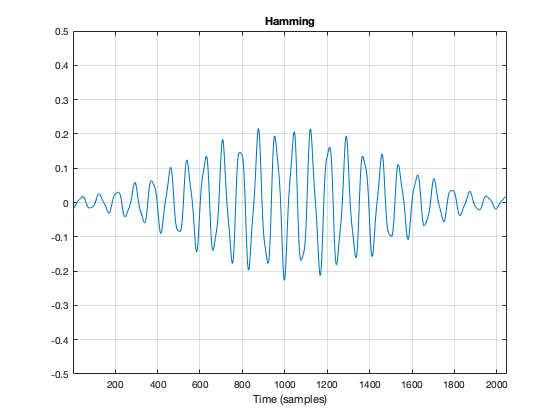
Figure 7. The original bell sound, with a different kind of fade in and fade out applied to it.
Figure 7, above, shows the same bell sound again, this time processed using a Hamming function instead. It looks very similar to the Hann function – but it’s not identical. For starters, you may notice that the start and stop values are not 0 – although they’re considerably quieter than they would have been if we had used a rectangular windowing function (or, in other words “done nothing”). The result of a DFT on this signal is shown in Figure 8.
Figure 8: The magnitude response of the bell sound with a Hamming window, as shown in Figure 7.
There are two things about Figure 8 that are different from Figure 6. The first is that the overall apparent level of the wide-band artefacts is higher (although not as high as that in Figure 4…). This is because we have a “click” caused by the fact that we don’t start and stop at 0. However, the advantage of this function is that the peaks are narrower – so we get a better idea of the actual signal – we just need to learn to ignore the bottom part of the plot.
Figure 9, shows yet another function, called a Blackman function.
Figure 9. The original bell sound, with a different kind of fade in and fade out applied to it.
You can see there that it takes longer for the signal to ramp in from 0 (and to ramp out again at the end), so we can expect that the peaks will be even lower than those for the Hann window. This can be seen in Figure 10.
Figure 10: The magnitude response of the bell sound with a Blackman window, as shown in Figure 7.
Indeed, the peaks are lower….
Another function is called the Blackman-Harris function, shown in Figures 11 and 12.
Figure 11.Figure 12.
There are other windowing functions. And there are some where you can change some variables to play with width and things. Or you can make up your own. I won’t talk about them all here… This is just a brief introduction…
The purpose of this is to show some basic issues with windowing. You can play with the windowing function, but there will be subsequent effects in the DFT result like:
the apparent magnitude of the actual signal (the peaks in the plots above)
the apparent magnitude in frequency bands that aren’t in the signal
the apparent width of the frequency band of the actual signal
Also, you have to remember that a DFT shows you the complete frequency content of the slice of time that you fed it. So, if the frequency content changes over time (the sound of a sitar string being plucked, or the “pew pew” sound of Han Solo’s laser, for example) then this change over time will not be shown…
Some more details…
Let’s dig a little into the differences in the peaks in the DFT plots above. As we saw in Part 4, if the frequency of the signal you’re analysing is not exactly the same as the frequency of the DFT bin, then the energy will “bleed” into adjacent bins. The example I showed in that posting compared the levels shown by the DFT when the frequency of the signal is either exactly the same as a frequency bin, or half-way between two of them – a reminder of this is shown below in Figure 13.
Figure 13. The results of a DFT analysis of two signals. The blue plot shows the result when the signal frequency is 1000.0 Hz (exactly the same as the DFT bin frequency). The red plot shows the result when the signal frequency is 1000.5 Hz (half-way between two bins).
As you can see in that plot, the energy in the 1000.5 Hz bleeds into the two adjacent bins. In fact, it’s more accurate to say that there is energy in all of the DFT bins, due to the discontinuity of the signal when the beginning is wrapped around to meet its end.
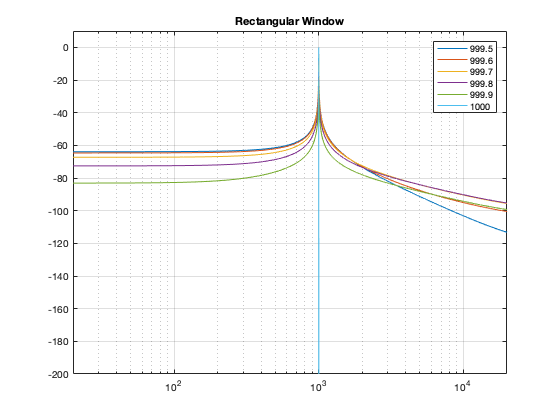
So, let’s analyse this a little further. I’ll create a signal that is on a frequency bin (therefore it’s a sine wave with a carefully-chosen frequency), and do the DFT. Then, I’ll make the frequency a little lower, and do the DFT again. I’ll repeat this until I get to a signal frequency that is half-way between two bins. I’ll stop there, because once I pass the half-way point, I’ll just start seeing the same behaviour. The result of this is shown for a rectangular window in Figure 14.
Figure 14. The results of doing a DFT analysis on a sine wave with frequencies ranging from exactly on a DFT bin (1000 Hz) to half-way between two bins (999.5 Hz).
As you can see there, there is a LOT of energy bleeding into all frequency bins when the signal is not exactly on a bin. Remember that this does not mean that those frequencies are in the signal – but they are in the signal that the DFT is being asked to analyse.
Let’s do this again for the other windowing functions.
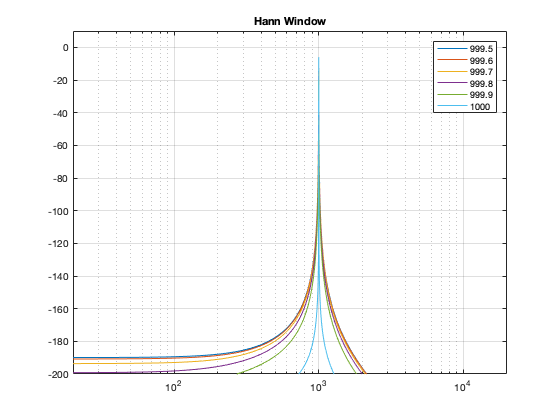
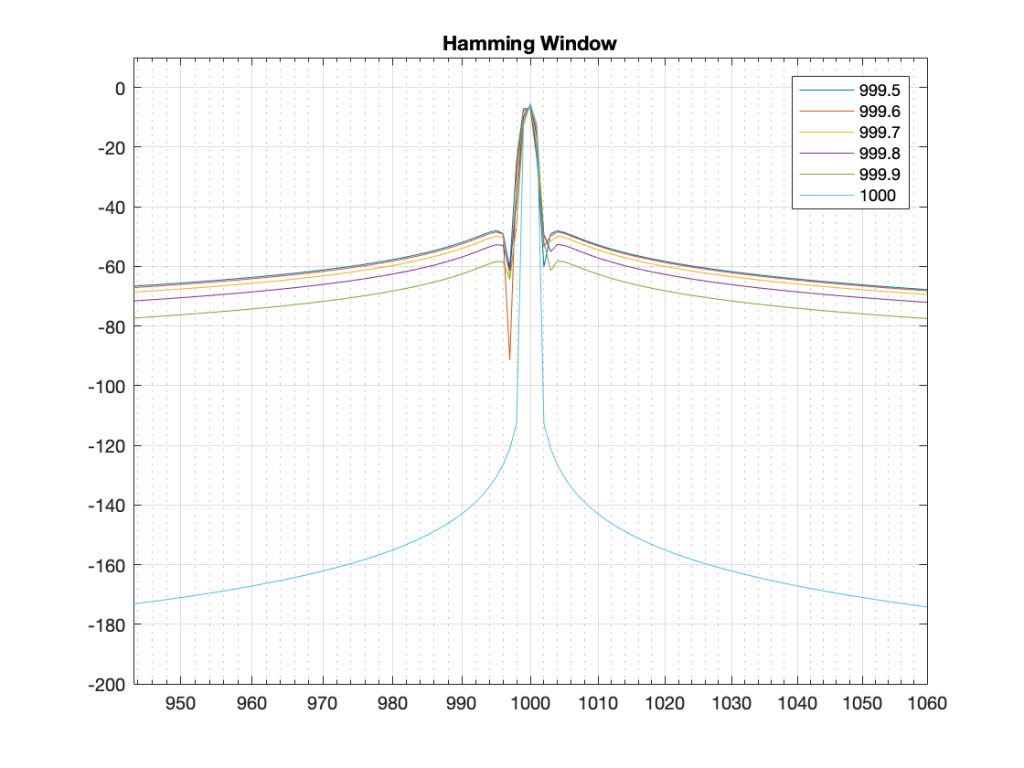
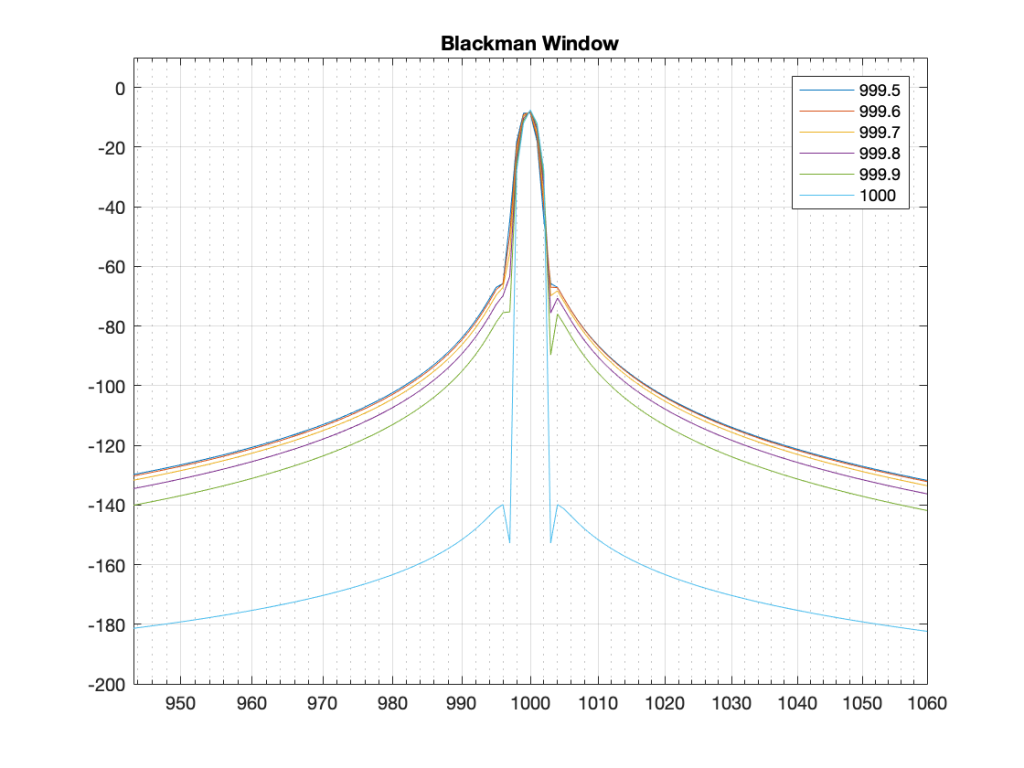
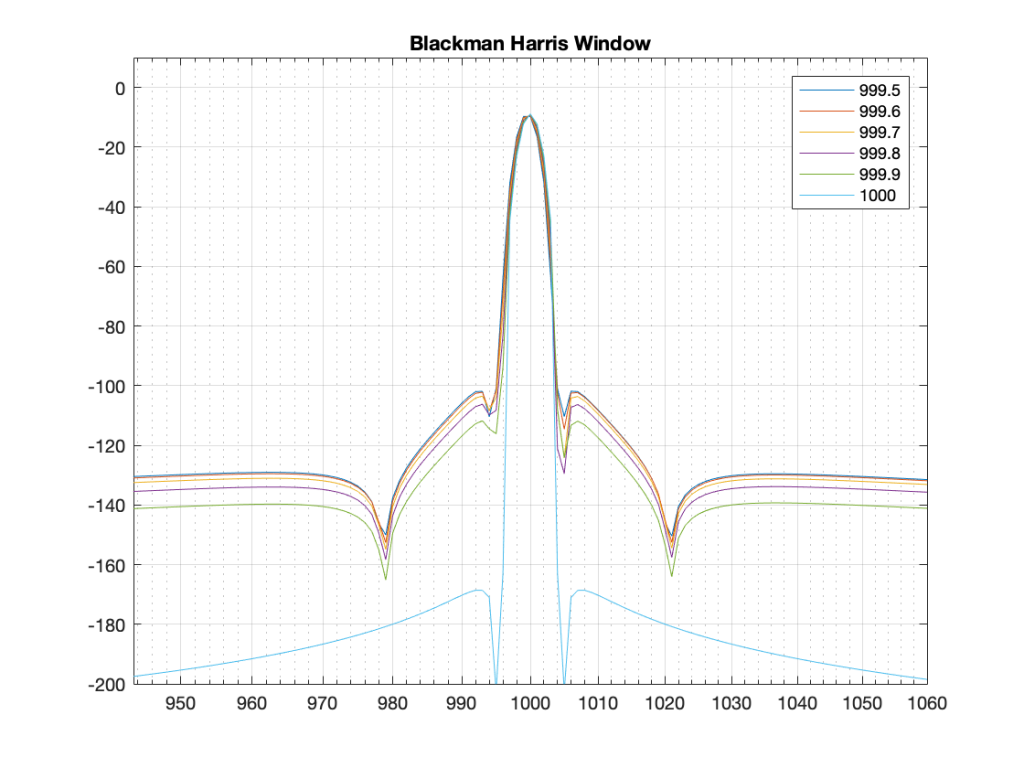
Figure 15. The same results, with a Hann window applied to the signal. Notice that the 1000 Hz result is now not as precise – but all of the other frequencies are “cleaner”.Figure 16. The same results with a Hamming window. The 1000 Hz is narrower than with the Hann window – but all other frequencies are “noisier” due to the fact that the start and stop gains of the Hamming window are not 0.Figure 17. The same analysis for the Blackman windowing function.Figure 18. The same analysis for the Blackman Harris function.
What you may notice when you look at Figures 14 to 18 is that there is a relationship between the narrowness of the plot when the signal is on a bin frequency and the amount of energy that’s spread everywhere else when it’s not. Generally, you have to make a trade between accuracy and precision at the frequency where there’s energy to truth at all other frequencies.
However, if you look carefully at those plots around the 1000 Hz area, you can see that it’s a little more complicated. Let’s zoom into that area and have a look…
Figure 19. A zoom-in of the plot in Figure 14.Figure 20. A zoom-in of the plot in Figure 15.Figure 21. A zoom-in of the plot in Figure 16.Figure 22. A zoom-in of the plot in Figure 17.Figure 22. A zoom-in of the plot in Figure 18.
The thing to compare in plots 19 to 22 is the how similar the plots in each figure is, relative to each other. For example, in Figure 19, the six plots are very different from each other. In Figure 22, the six plots are almost identical from 995 Hz to 1005 Hz.
Depending on what kind of analysis you’re doing, you have to decide which of these behaviours is most useful to you. In other words, each type of windowing function screws up the result of the DFT. So you have to choose which one screws it up the least for the type of signal and the type of analysis you’re doing.
Alternatively, you can choose a favourite windowing function, and always use that one, and just get used to looking at the way your results are screwed up.
Some final details
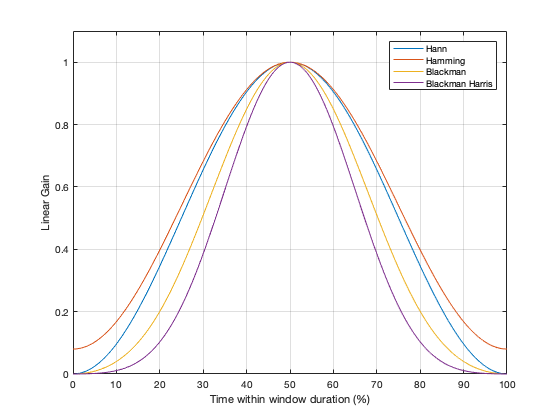
So far, I have not actually defined the details of any of the windowing functions we’ve looked at here. I’ve just said that they fade in and fade out differently. I won’t give you the mathematical equations for creating the actual curves of the functions. You can get that somewhere else. Just look them up on the Internet. However, we can compare the shapes of the gain functions by looking at them on the same plot, which I’ve put in Figure 23.
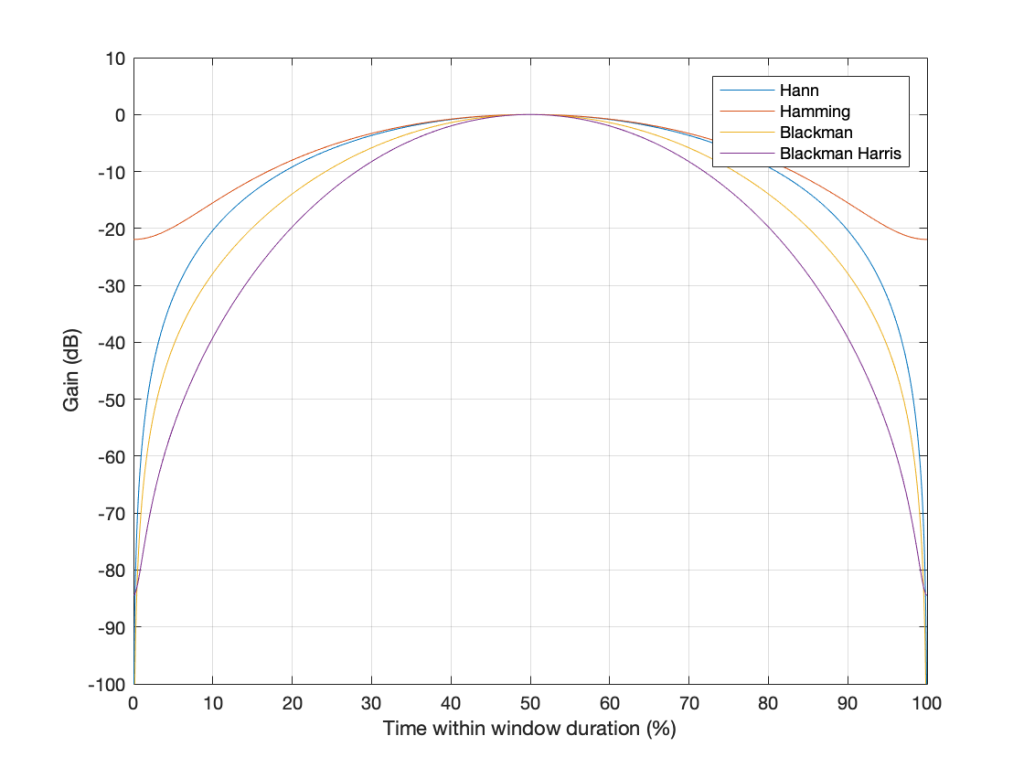
Figure 23. The gain vs. time for 4 of the 5 windowing functions I’ve talked about.
You may notice that I left out the rectangular window. If I had plotted it, it would just be a straight line of 1’s, which is not a very interesting shape.
What may surprise you is how similar these curves look, especially since they have such different results on the DFT behaviour.
Another way to look at these curves (which is almost never shown) is to see them in decibels instead, which I’ve done in Figure 24.
Figure 24. The sample plots that were shown in Figure 23, on a decibel scale.
The reason I’ve plotted them in dB in Figure 24 is to show that, although they all look basically the same in Figure 23, you can see that they’re actually pretty different… For example, notice that, at about 10% of the way into the time of the window, there is a 40 dB difference between the Blackman Harris and the Hann functions… This is a lot.
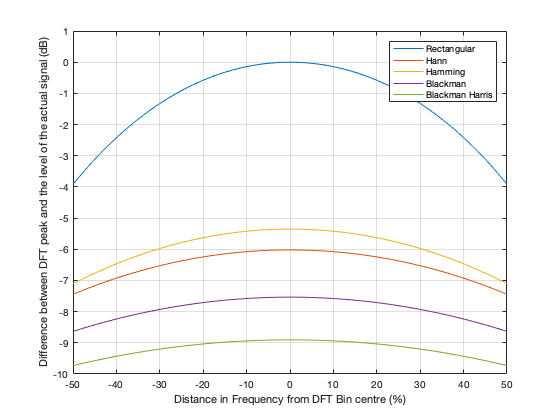
One thing that I’ve only briefly mentioned is the fact that the windowing functions have an effect on the level that is shown in the DFT result, even when the signal frequency is exactly the same as the DFT bin frequency. As I said earlier, this is because there is, in fact, less energy in the time window overall, because we made the signal quieter at the beginning and end. The question is: “exactly how much quieter?” This is shown in Figure 25.
Figure 25. The relationship between the signal frequency, the maximum level shown in the DFT results, and the windowing function used.
So, as you can see there, a DFT of a rectangular windowed signal can show the actual level of the signal if the frequency of the signal is exactly the same as the DFT bin centre. All of the other windowing functions will show you a lower level.
HOWEVER, all of the other windowing functions have less variation in that error when the signal frequency moves away from the DFT bin. In other words, (for example) if you use a Blackman Harris window for your DFT, the level that’s displayed will be more wrong than if you used a rectangular window, but it will be more consistent. (Notice that the rectangular window ranges from almost -4 dB to 0 dB, whereas the Blackman Harris window only ranges from about -10 to -9 dB.)
And, you should be left with a question… Why does that plot in Figure 12 look like it’s got lots of energy at a bunch of frequencies – not just two clean spikes? We’ll get into that in the next posting.
Let’s begin by taking a nice, clean example…
If my sampling rate is 65,536 Hz (2^16) and I take one second of audio (therefore 65,536 samples) and I do a DFT, then I’ll get 65,536 values coming out, one for each frequency with an integer value (nothing after the decimal point. The frequencies range from 0 to 65,535 Hz, on integer values (so, 1 Hz, 2 Hz, 3 Hz, etc…) (And we’ll remember to throw away the top half of those values due to mirroring which we talked about in the last post.)
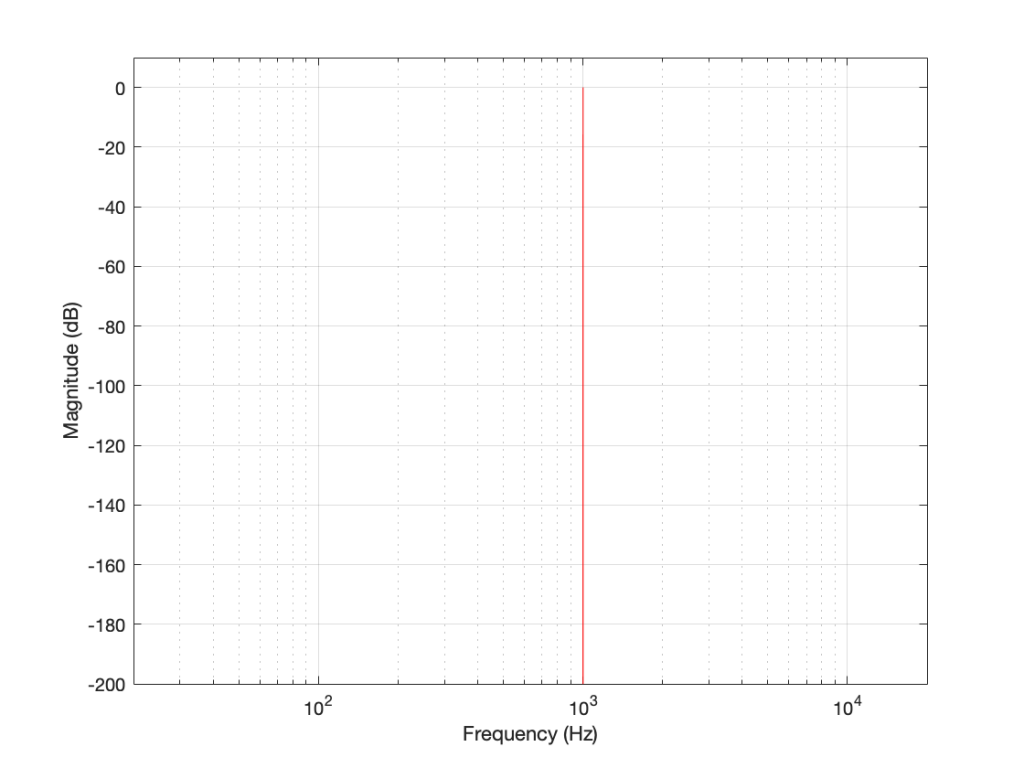
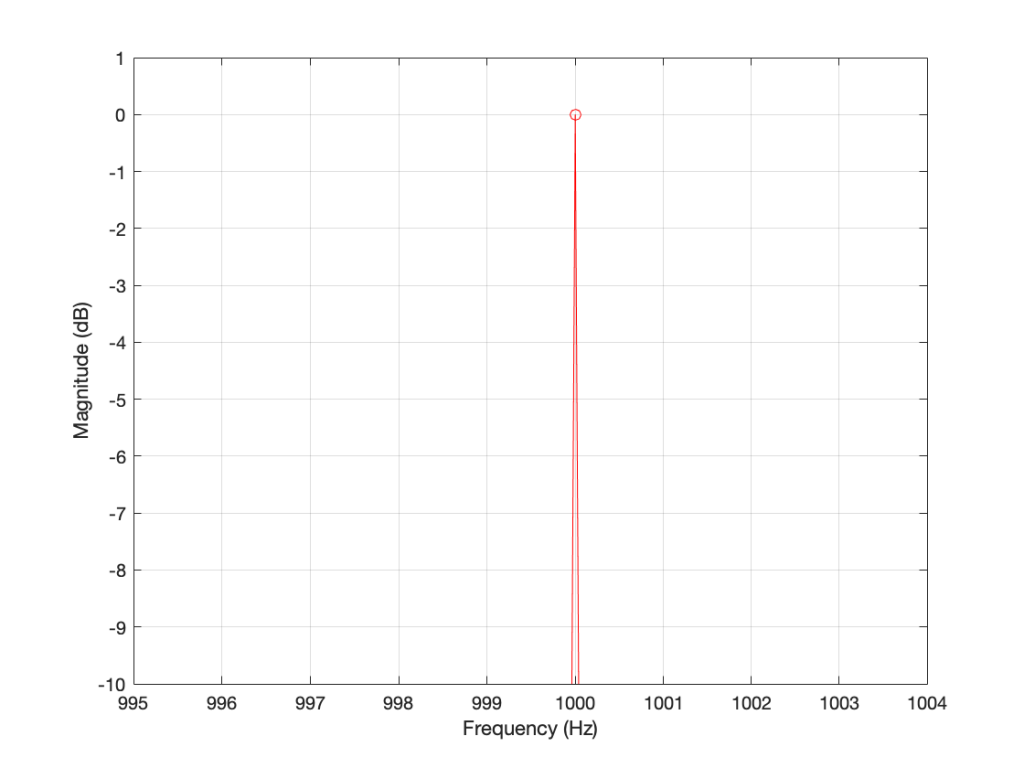
I then make a sine wave with an amplitude of 0 dB FS and a frequency of 1,000 Hz for 1 second, and I do an DFT of it, and then convert the output to show me just the magnitude (the level) of the signal (so I’m ignoring phase). The result would look like the plot below.
Figure 1. The magnitude response of a 1000 Hz sine tone, sampled at 65,536 Hz, calculated using a 65,536-point DFT.
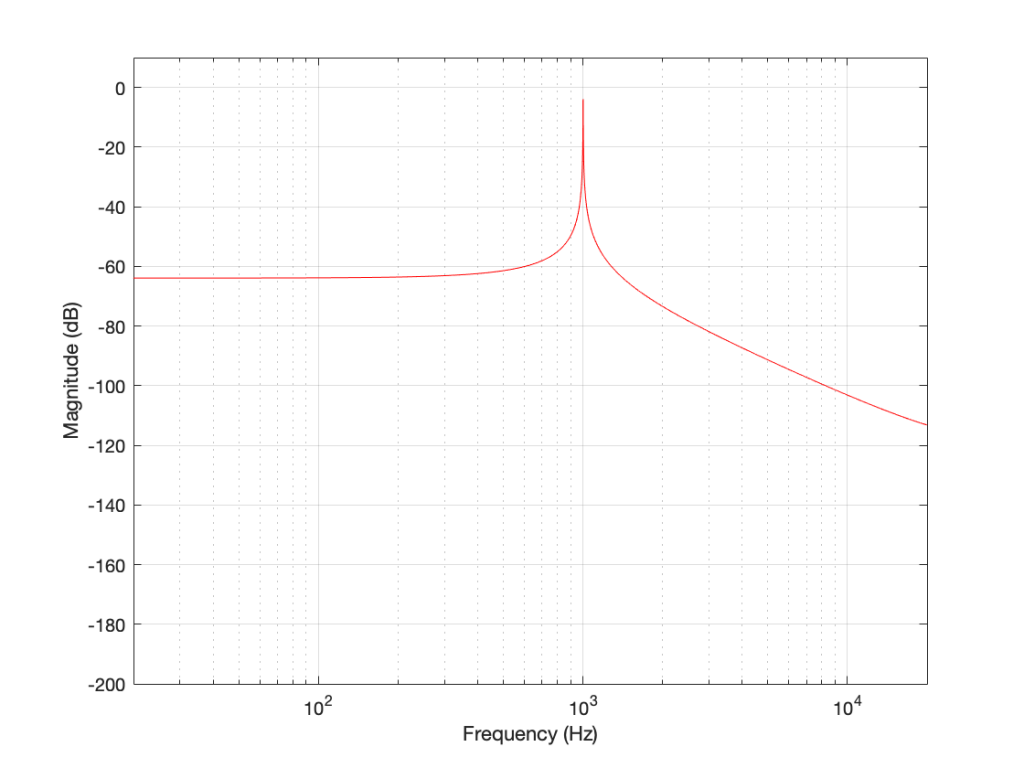
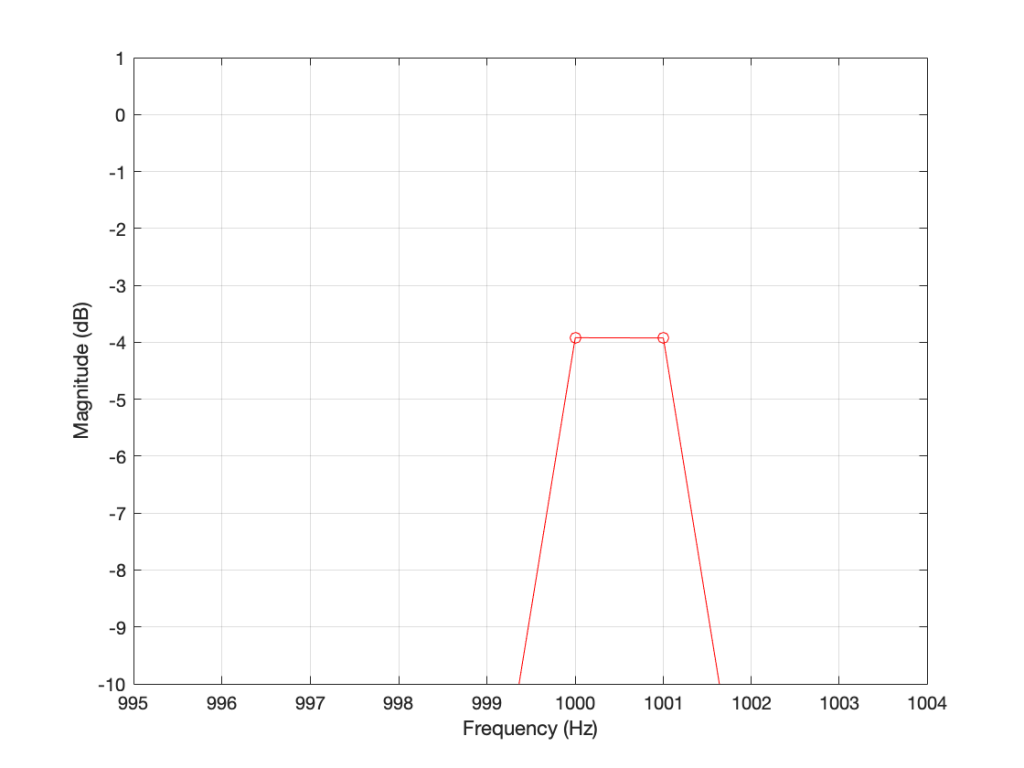
The plot above looks very nice. I put in a 1,000 Hz sine wave at 0 dB FS, and the plot tells me that I have a signal at 1,000 Hz and 0 dB FS and nothing at any other frequency (at least with a dynamic range of 200 dB). However, what happens if my signal is 1000.5 Hz instead? Let’s try that:
Figure 2. The magnitude response of a 1000.5 Hz sine tone, sampled at 65,536 Hz, calculated using a 65,536-point DFT.
Now things don’t look so pretty. I can see that there’s signal around 1000 Hz, but it’s lower in level than the actual signal and there seems to be lots of stuff at other frequencies… Why is this?
In order to understand why the level in Figure 2 is lower than that in Figure 1, we have to zoom in at 1000 Hz and see the individual points on the plot.
Figure 1 (Zoom)
As you can see in Figure 1 (Zoom), above, there is one DFT frequency “bin” at 1000 Hz, exactly where the sine wave is centred.
Figure 2 (Zoom)
Figure 2 (Zoom) shows that, when the sine wave is at 1000.5 Hz, then the energy in that signal is distributed between two DFT frequency bins – at 1000 Hz and 1001 Hz. Since the energy is shared between two bins, then each of their level values is lower than the actual signal.
The reason for the “lots of stuff at other frequencies” problem is that the math in a DFT has a limited number of samples at its input, so it assumes that it is given a slice of time that repeats itself exactly.
For example…
Let’s look at a portion of a plot like the one below:
Figure 3. A portion of a plot. The gray rectangles hide things…
If I asked you to continue this plot to the left and right (in other words, guess what’s under the gray rectangles), would you draw a curve like the one below?
Figure 3. An obvious extrapolation of the curve in Figure 3.
This would be a good guess. However, the figure below is also a good guess.
Figure 4. An obvious extrapolation of the curve in Figure 3.
Of course, we could guess something else. Perhaps Figure 3 is mostly correct, but we should add a drawing of Calvin and Hobbes on a toboggan, sliding down the hill to certain death as well. You never know what was originally behind those grey rectangles…
This is exactly the problem the math behind a DFT has – you feed it a “slice” of a recording, some number of samples long, and the math (let’s call it “a computer”, since it’s probably doing the math) has to assume that this slice is a portion of time that is repeated forever – it started at the beginning of time, and it will continue repeating until the end of time. In essence, it has to make an “extrapolation” like the one shown in Figure 4 because it doesn’t have enough information to make assumptions that result in the plot in Figure 3.
For example: Part 2
Let’s go back to the bell recording that we’ve been looking at in the previous posts. We have a portion of a recording, 2048 samples long. If I plot that signal, it looks like the curve in Figure 5.
Figure 5. The bell recording we saw in previous postings, hiding the information that comes before and after.
When the computer does the DFT math, the assumption is that this is a slice that is repeated forever. So, the computer’s assumption is that the original signal looks like the one below, in Figure 6.
Figure 6. The signal, as assumed by the computer when it’s doing the DFT math.
I’ve put rectangles around the beginning (at sample 1) and end (at sample 2048) of the slice to highlight what the signal looks like, according to the computer… The signal in the left half of the left rectangle (ending at sample 0) is the end of the slice of the recording, right before it repeats. The signal starting at 2049 is the beginning again – a repeat of sample 1.
If we zoom in on the signal in the left rectangle, it looks like Figure 7.
Figure 7. the signal inside the left rectangle in Figure 6.
Notice that vertical line at sample 1 (actually going from sample 0 to sample 1, to be accurate). Of course, our original bell recording didn’t have that “instantaneous” drop in there – but the computer assumes it does because it doesn’t have enough information to assume anything else.
If we wanted to actually make that “instantaneous” vertical change in the signal (with a theoretical slope of infinity – although it’s not really that steep….), we would have to add other frequencies to our original signal. Generally, you can assume that, the higher the slope of an audio signal, either 1) the louder the signal or 2) the more high frequency content in the signal. Let’s look at the second one of those.
Let’s look at portions of sine waves at three different frequencies. These are shown below, in Figure 8. The top plot shows a sine wave with some frequency, showing how it looks as it passes phase = 0º (which we’ll call “time = 0” (on the X-axis)). At that moment, the sine wave has a value of 0 (on the Y-axis) and the slope is positive (it’s going upwards). The middle plot shows a sine wave with 3 times the frequency (notice that there are 6 negative-and-positive bumps in there instead of just 2). Everything I said about the top plot is still true. The level is 0 at time=0, and the slope is positive. The bottom plot is 5 times the frequency (10 bumps instead of 2). And, again, at time=0, everything is the same.
Figure 8. Three sinusoidal waves at related frequencies. We’re looking at the curves as they cross time=0 (on the X-axis).
Let’s look a little more carefully at the slope of the signal as it crosses time=0. I’ve added blue lines in Figure 9 to highlight those.
Figure 9.
Notice that, as the frequency increases, the slope of the signal when it crosses the 0 line also increases (assuming that the maximum amplitude stays the same – all three sine waves go from -1 to 1 on the Y-axis.
One take-away from that is the idea that I’ve already mentioned: the only way to get a steep slope in an audio signal is to add high frequency content. Or, to say it another way: if your audio signal has a steep slope at some time, it must contain energy at high frequencies.
Although I won’t explain here, the truth is just a little more complicated. This is because what we’re really looking for is a sharp change in the slope of the signal – the “corners” in the plot around Sample 0 in Figure 7. I’ve put little red circles around those corners to highlight them, shown below in Figure 10. When audio geeks see a sharp corner like that in an audio signal, they say that the waveform is discontinuous – meaning that the level jumps suddenly to something unexpected – which means that its slope does as well.
Basically, if you see a discontinuity in an audio signal that is otherwise smooth, you’re probably going to hear a “click”. The audibility of the click depends on how big a jump there is in the signal relative to the remaining signal. (For example, if you put a discontinuity in a nice, smooth, sine wave, you’ll hear it. If you put a discontinuity in a white noise signal – which is made up of nothing but discontinuities (because it’s random) then you won’t hear it…)
Figure 10. The red circles show the discontinuities in the slope of the signal when it is assumed that it repeats.
Circling back…
Think back to the examples I started with at the beginning of this post. When I do a 65,536-point DFT of a 1000 Hz sine wave sampled at 65,536 Hz, the result is a nice clean-looking magnitude response (Figure 1). However, when I do a 65,536-point DFT of a 1000.5 Hz sine wave sampled at 65,536 Hz, the result is not nearly as nice. Why?
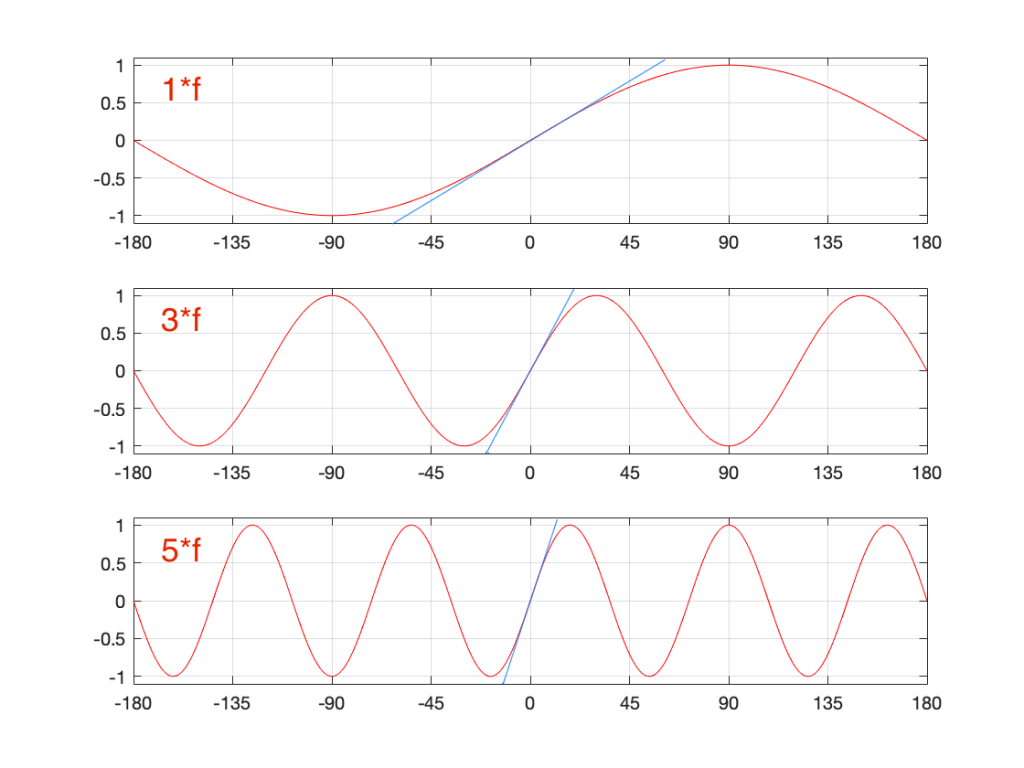
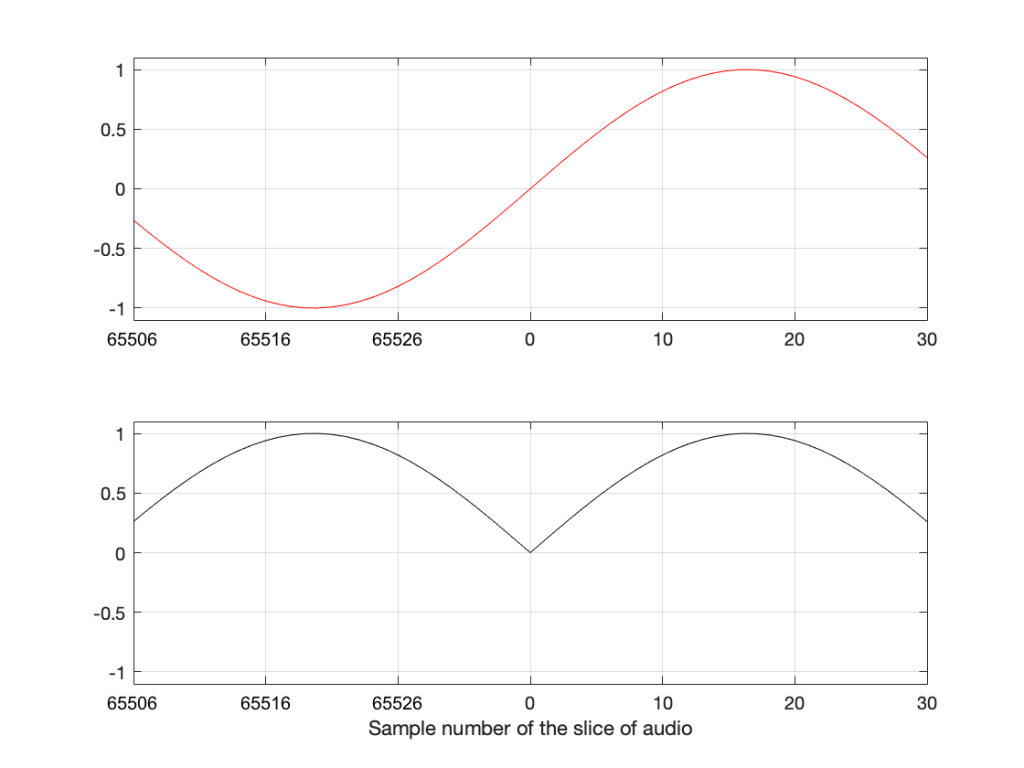
Think about how the end of the two sine waves join up with their beginnings. When you do a 65,536-point DFT on a signal that has a sampling rate of 65,536 Hz, then the slice of time that you’re analysing is exactly 1 second long. A 1000 Hz sine wave, repeats itself exactly after 1 second, so the 65,537th sample is identical to the first. If you join the last 30 samples of the slice to the first 30 samples, it will look like the red curve on the top plot in Figure 10, below.
However, if the sinusoid has a frequency of 1000.5 Hz, then it is only half-way through the waveform when you get to the end of the second. This will look like the lower black curve in Figure 10.
Figure 11. The top plot shows the a 1000 Hz sine wave at the end of exactly 1 second, joined to the beginning of the same sine wave. The bottom plot shows the same for a 1000.5 Hz sine wave
Notice that the lower plot has a discontinuity in the slope of the waveform. This means that there is energy in frequencies other than 1000.5 Hz in it. And, in fact, if you measured how much energy there is in that weird waveform that sounds like a sine wave most of the time, but has a little click every second, you’ll find out that the result is already plotted in Figure 2.
The conclusion
The important thing to remember from this posting is that a DFT tells you what the relative frequency content of the signal is – but only for the signal that you give it. And, in most cases, the signal that you give it (a slice of time that is looped for infinity) is not the same as the total signal that you took the slice from.
So, most of the time, a DFT (or FFT – you choose what you call it) is NOT showing you what is in your signal in real life. It’s just giving you a reasonably good idea of what’s in there – and you have to understand how to interpret the plot that you’re looking at.
In other words, Figure 2 does not show me how a 1000.5 Hz sine tone sounds – but Figure 1 shows me how a 1000 Hz sine tone sounds. However, Figures 1 and 2 show me exactly how the computer “hears” those signals – or at least the portion of audio that I gave it to listen to.
There is a general term applied to the problem that we’re talking about. It’s called “windowing effects” because the DFT is looking at a “window” of time (up to now, I’ve been calling it a “slice” of the audio signal. I’m going to change to using the word “time window” or just “window” from now on.
In the next posting, DFT’s Part 5: Windowing, we’ll look at some sneaky ways to minimise these windowing effects so that they’re less distracting when you’re looking at magnitude response plots.
If you have an audio signal or the impulse response measurement of an audio device (which is just the audio output of a device when the input signal is a very short “click” – how the device responds to an impulse), one way to find out its spectral content is to use a Fourier Transform. Normally, we live in a digital audio world, with discrete divisions of time, so we use a DFT or a Discrete Fourier Transform (although most people call it an FFT – a Fast Fourier Transform).
If you do a DFT of a signal (say, a sinusoidal waveform), then you take a slice of time, usually with a length (measured in samples) that is a nice power of 2 – for example 2, or 4 (2^2), or 2^12 (4096 samples) or 2^13 (8192 samples). When you convert this signal in time through the DFT math, you get out the same number of number (so, 2048 samples in, 2048 numbers out). Each of those numbers can be used to find out the magnitude (the level) and the phase for a frequency.
Those frequencies (say, 2048 of them) are linearly spaced from 0 Hz up to just below the sampling rate (the sampling rate would be the 2049th frequency in this case… we’ll see why, below…)
So, generally speaking: if I have an audio signal (a measurement of level over time) and I do a DFT (which is just a series of mathematical equations) and then I can see the relative amount of energy by frequency for that “slice” of time.
So, how does the math work? In essence, it’s just a matter of doing a lot of multiplication, and then adding the results that you get (and then maybe doing a little division, if you’re in the mood…). We’ve already seen in Parts 1 and 2 of this series that
a sinusoidal waveform is just 2 dimensions (dimension #1 is movement in space, the other dimension is time) of a three-dimensional rotation (dimensions #1 and #2 are space and #3 is time)
if we want to know the frequency, the amplitude, and the direction of rotation of the “wheel”, we will need to see the real component (the cosine) and the imaginary component (the negative sine)
the imaginary component is a negative sine wave instead of a positive sine wave because the wheel is rotation clockwise
A real-world example
I took a bell and I hit it, so it rang the way bells ring. While I was doing that, I recorded it with a microphone connected to my computer. The sampling rate was 48 kHz and I recorded with enough bits to not worry about that. The result of that recording is shown in Figure 1.
Figure 1. A 7-second long recording of a bell
Seven seconds is a lot of samples at 48,000 samples per second. (In fact, it’s 7 * 48000 samples – which is a lot…) So, let’s take a slice somewhere out of the middle of that recording. This portion (a “zoomed-in” view of Figure 1) is shown below in Figure 2.
Figure 2. A portion of the signal shown in Figure 1. The gray part is 2048 samples long.
So, for the remainder of this posting, we’ll only be looking at that little slice of time, 2048 samples long. Since our sampling rate is 48 kHz, this means that the total length of that slice is 2048 * 1/48000 = 0.0427 seconds, or approximately 42.7 ms.
Let’s start by calculating the amount of energy there is at 0 Hz or “DC” in this section. We do this by taking the value of each individual sample in the section, and adding all those values together. Some of the values are positive (they’re above the 0 line in Figure 2) and some are negative (they’re below 0). So, if we add them all up we should be somewhere close to 0… Let’s try….
Figure 3.
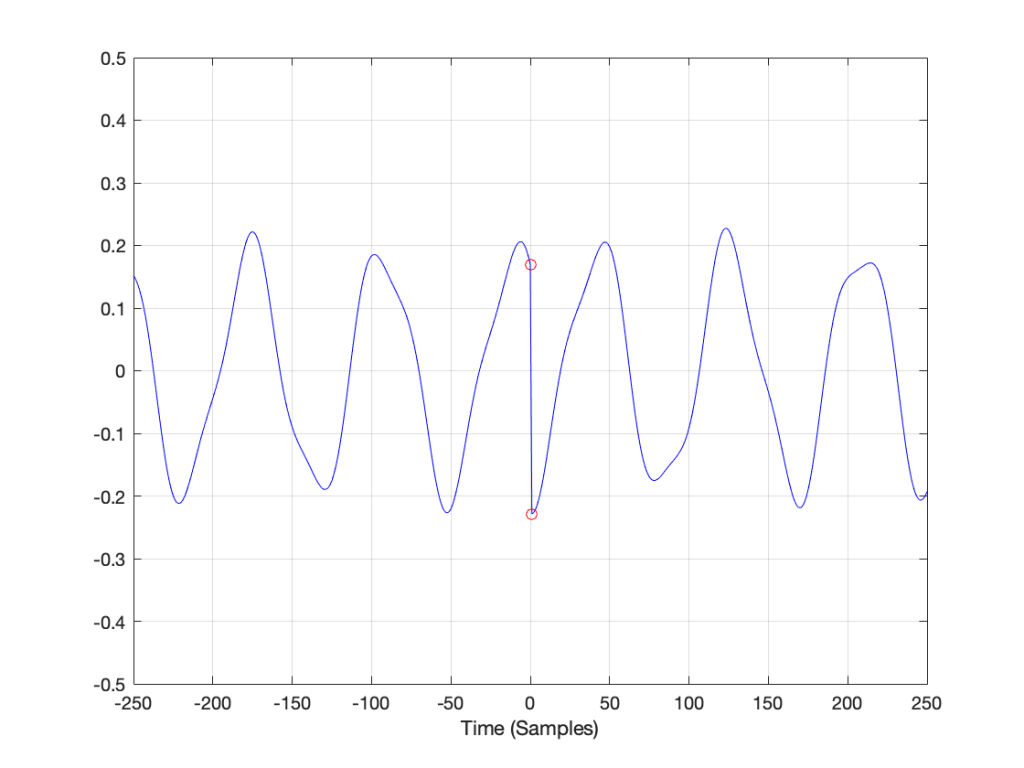
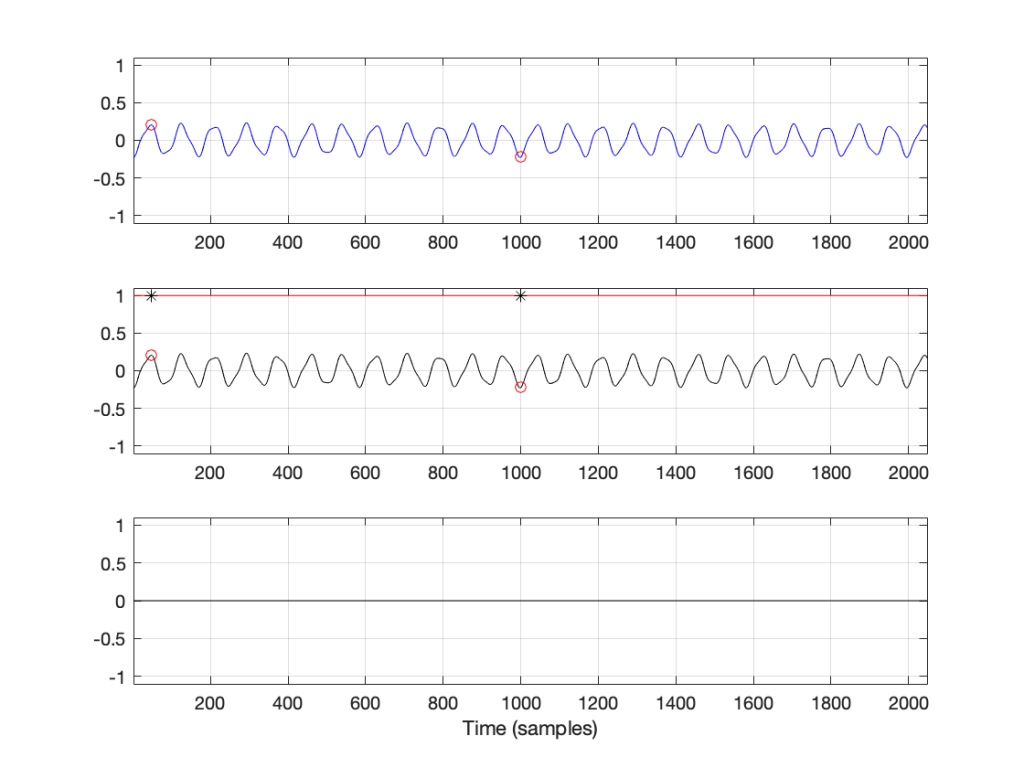
Figure 3 has three separate plots. The top plot in blue is the section of the recording that we’re using, 2048 samples long. You’ll see that I put a red circle around two samples, sample number 47 and sample number 1000. These were chosen at random, just so we have something near the beginning and something near the middle of the recording to use as examples…
So, to find the total energy at 0 Hz, we have to add the individual values of each of the 2048 samples. So, for example, sample #47 has a value of 0.2054 and sample #1000 has a value of -0.2235. We add those two values and the other 2046 sample values together and we get a total value of 2.9057. Let’s just leave that number sitting there for now. We’ll come back to it later.
For now, we’ll ignore the middle and bottom plots in Figure 3. This is because they’ll be easier to understand after Figure 4 is explained…
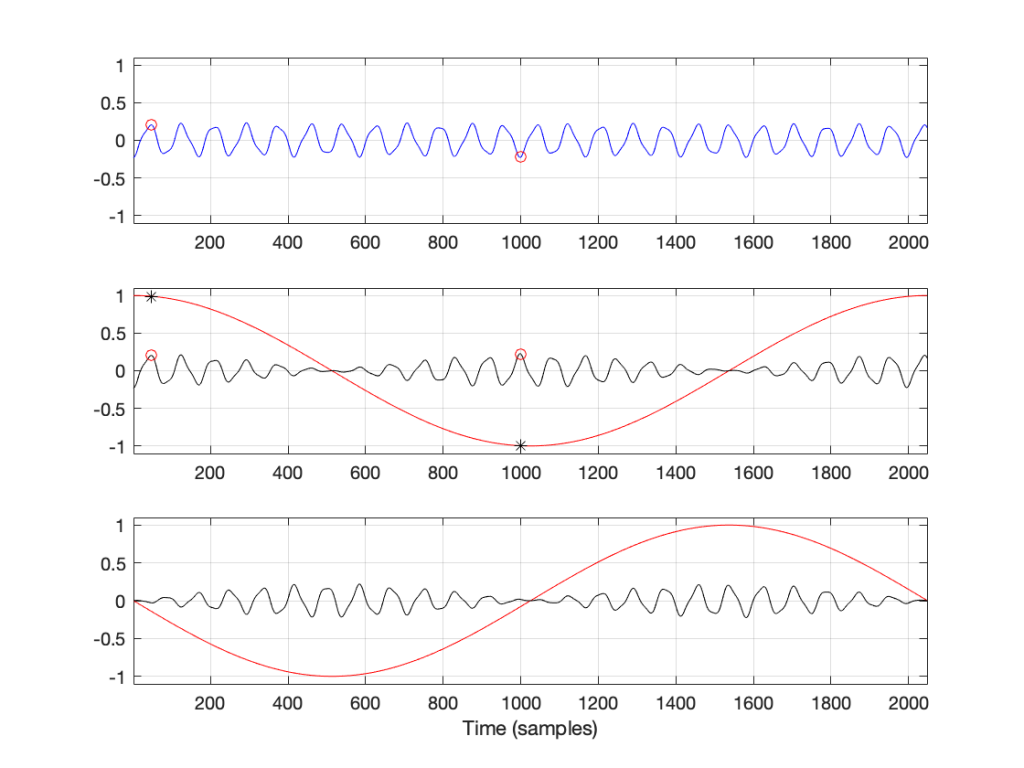
Now we want to move up to frequencies above 0 Hz. The way we do this is similar to what we did, with an extra step in the process.
Figure 4.
The top blue plot in Figure 4 shows the same thing that it showed in Figure 3 – it’s the 2048 samples in the recording, with sample numbers 47 and 1000 highlighted with red circles.
Take a look at the middle plot. The red curve in that plot is a cosine wave with a period (the amount of time it takes to complete 1 cycle) of 2048 samples. On that plot, I’ve put two * signs (“asterisks”, if you prefer…) – one on sample number 47 and the other at sample 1000.
One small, but important note here: although it’s impossible to see in that plot, the last value of the cosine wave is not the same as the first – it’s just a little lower in level. This is because the cosine wave would start to repeat itself on the next sample. So, the 2049th sample is equal to the 1st. This makes the period of the cosine wave 2048 samples.
The black curve in this plot is the result when you multiply the original recording (in blue) by the cosine curve (in red). So, for example, sample #47 on the blue curve (a value of 0.2054) multiplied by sample #47 on the red cosine curve (0.9901) equals 0.2033, which is indicated by a red circle on the black curve in the middle plot.
If you look at sample 1000, the value on the blue curve is positive, but when it’s multiplied by the negative value on the cosine curve, the result is a negative value on the black curve.
You’ll also notice that, when the cosine wave is 0, the result of the multiplication in the black curve is also 0.
So, we take each of the 2048 samples in the original recording of the bell, and multiply each of those values, one by one, by their corresponding samples in the cosine curve. This gives us 2048 sample values shown in the black curve, which we add all together, and that gives us a total of 1.5891.
We then do exactly the same thing again, but instead of using a cosine wave, we use a negative sine wave, shown as the red curve in the bottom plot. The blue curve multiplied by the negative sine wave, sample-by-sample results in the black curve in the bottom plot. We add all those sample values together and we get -2.5203.
Now, we do it all again at the next frequency.
Figure 5.
Now, the period of the cosine and the negative sine waves is 1024 samples, so they’re at two times the frequency of those shown in Figure 4. However, apart from that change, the procedure is identical. We multiply the signal by the cosine wave (sample-by-sample), add up all the results, and we get 1.3547. We multiply the signal by the negative sine wave and we get -1.025.
This procedure is repeated, increasing the frequency of the cosine (the real) and the negative sine (the imaginary) waves each time. So far we have seen 0 periods (Figure 3), 1 period (Figure 2), and 2 periods (Figure 3) – we just keep going with 3 periods, 4 periods, and so on.
Eventually we get to 1024 periods. If I were to plot that, it would not look like a cosine wave, since the values would be 1, -1, 1, -1…. for 2048 samples. (But, due to the nature of digital audio and smoothing filters that we’re not going to talk about, it would, in fact, be a cosine wave at a frequency of one half of the sampling rate…)
At that frequency, the values for the negative sine wave would be a string of 2048 zeros – exactly as it is in Figure 3.
If we keep going up, we get to 2048 periods – one period of the cosine wave for each sample. This means that, at each sample, the cosine starts, so the result is a string of 2048 ones. Similarly, the negative sine wave will be a string of 2048 zeros. Note that both of these are identical to what we saw in Figure 1 when we were looking at 0 Hz…
Since we’ve already seen in the previous posting that, at a given frequency, the cosine component (the total sum of the results of multiplying the original signal by a cosine wave) is the real component and the negative sine is the imaginary component, then we can write all of the results as follows:
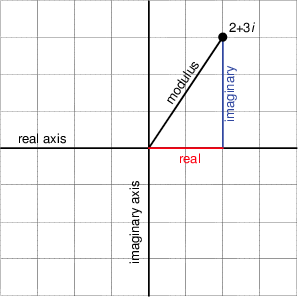
… and, as we saw in Figure 1 in the last post, for any one frequency, the real and imaginary contributions can be converted into a magnitude (a level) by using a little Pythagoras:
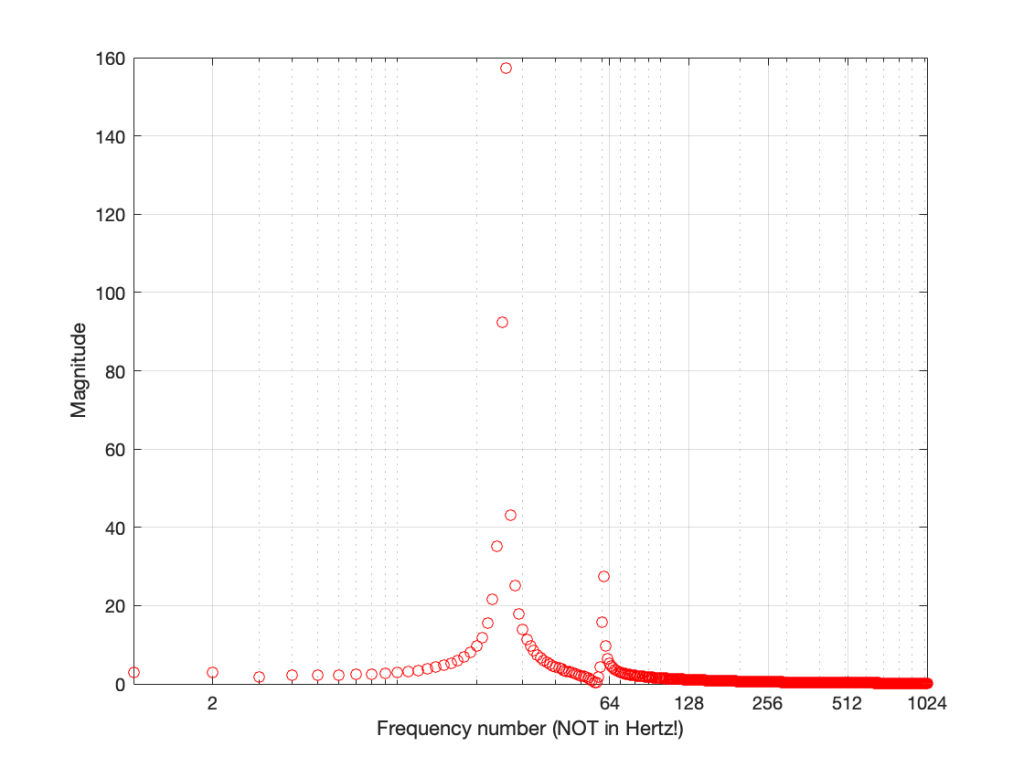
Let’s plot the first 10 values – f1 up to f10. (Remember that these are not in Hertz – they’re frequency numbers. We’ll find out what the actual frequencies are later…)
Figure 6.
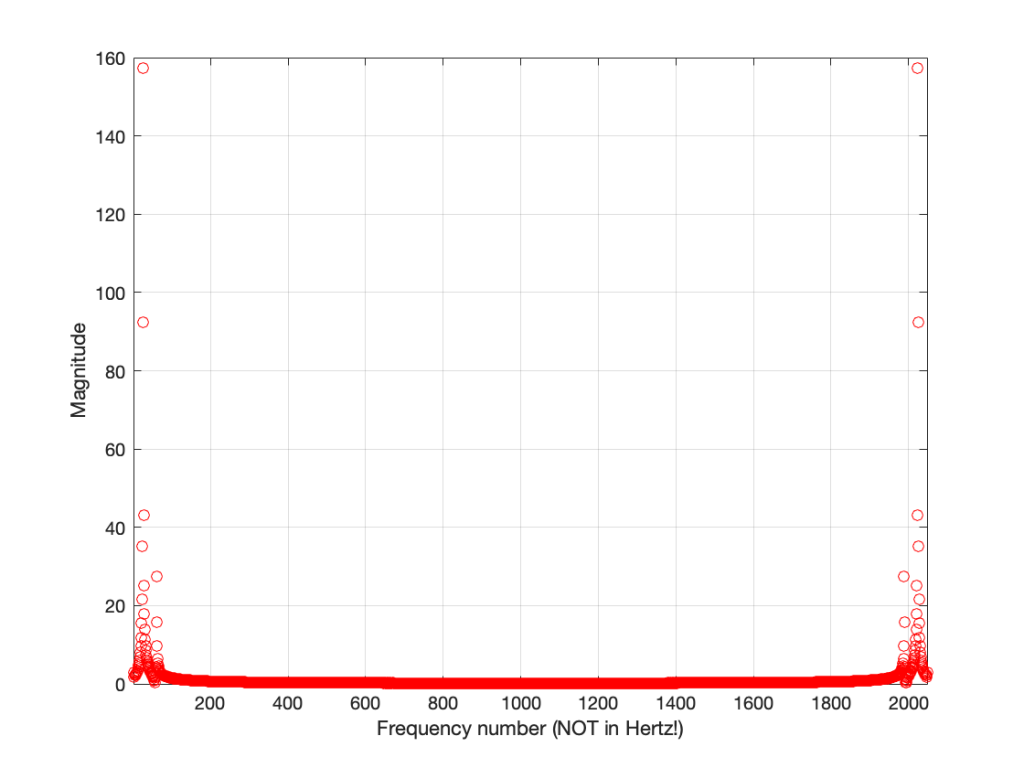
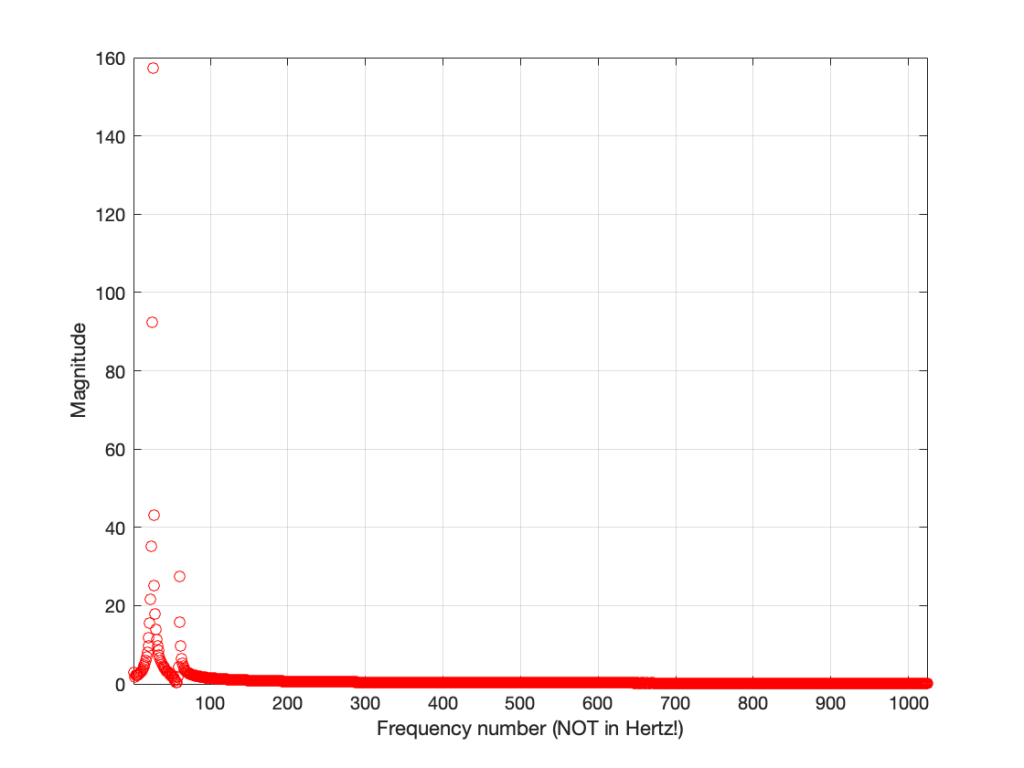
So, Figure 6 shows the beginning of the results of our calculations – the first 10 values of the 2048 values that we’re going to get. Not much interesting here yet, so let’s plot all 2048 values.
Figure 7.
Figure 7 shows two interesting things. The first is that at least one of those numbers gets very big – almost up to 160 – whatever that means. The other is that, you may notice that we have some symmetry going on here. In fact, you might have already noticed this… If you go back and look at the lists of numbers I gave earlier, you’ll see that the values for f1 and f2049 are identical (this is true in the complex world, where we see the real and imaginary components separately, and also therefore in their magnitudes). Similarly, f2 and f2048 are identical, as are f3 and f2047. If I had put in all of the values, you would have seen that the symmetry started at f1024 which is identical to f1026. (See this posting for a discussion about aliasing, which may help to understand why this happens….)
So, since the values are repeated, we only need to look at the first 1025 values that we calculated – we know that f1026 to f2048 are the same in reverse order… So, let’s plot the bottom half of Figure 7.
Figure 8.
Figure 8 shows us the same information as Figure 7 – just without the symmetrical repetition. However, it’s still a little hard to read. This is because our frequency divisions are linear. Remember that we multiplied our original signal by 1 period, 2 period, 3 periods, etc… This means that we were going up in linear frequency steps – adding equal frequencies on each step. The problem is that humans hear frequency steps logarithmically – semitones (1.06 times the frequency) and octaves (2 times the frequency) are examples – we multiply (not add) in equal steps. So, let’s plot Figure 8 again, but change the X-axis to a logarithmic scale.
Figure 9.
Figure 9 and Figure 8 show exactly the same information – I’ve just changed the way the x-axis is scaled so that it looks more like the way we hear distribution of frequency.
But what frequency is it?
There are two remaining problems with Figure 9 – the scaling of the two axes. Let’s tackle the X-axis first.
We know that, to get the value for f1, we found the average of all of the values in the recording. This told us the magnitude of the 0Hz. component of the signal.
Then things got a little complicated. To find the magnitude at f2, we multiplied the signal by a cosine (and a negative sine) with a period of 2048 sample. What is the frequency of that cosine wave in real life? Well, we know that the original recording was done with a sampling rate of 48 kHz or 48,000 samples per second, and our 2048-sample long slice of time equalled 42.66666666… milliseconds. If we divide the sampling rate by the period of the cosine wave, we’ll find its frequency, since we’ll find out how many times per second (per 48,000 samples) the wave will occur.
f2 = 48,000 / 2048 = 23.4375 Hz
The next frequency value will be the sampling rate divided the period of the next cosine wave – half the length of the first, or:
f3 = 48,000 / (2048 / 2) = 46.875 Hz
You might notice that f3 = 2 * f2… this helps the math.
f4 = 48,000 / (2048 / 3) = 70.3125 Hz
or f4 = 3 * f2
So, I can now keep going up to find all of my frequencies, and then change the labels on my X-axis so that they make sense to humans.
Figure 10.
That’s one problem solved. We now know that the bell’s loudest frequency is just under 600 Hz (the peak with a magnitude of about 160) and there’s another frequency at about 1500 Hz as well – with a magnitude of about 30 or so.
But how loud is it?
So, let’s tackle the second problem – what does a magnitude of 160 mean in real life?
Not only do humans hear changes in frequency logarithmically, we also hear changes in level logarithmically as well. We say something like “a trumpet is twice as loud as a dog barking” instead of “the loudness of a trumpet is the loudness of a dog barking plus 2”. In fact, that second one just sounds silly when you say it…
As a result, we use logarithms to convert linear levels (like the ones shown on the Y-axis of Figure 10) to something that makes more sense. Instead of having values like 1, 10, 100, and 1000 (I multiplied by 10 each time), we take the log of those values, and tell people that…
Now we can use the numbers on the right of those equations, which are small-ish instead of the other ones, which are big-ish…
We use this logarithmic conversion in the calculation of a decibel – which we will not get into here – but it would make the topic of another posting in the future. For now, you’ll just have to hang on…
What we’ll do is to take the magnitude values plotted in Figure 10 and find their logarithms, multiply those by 20, and we get their values in decibels. Cool.
The only problem is that if I were to do that, the numbers would look unusually big. This is because I left out one step way up at the top. Back when we were multiplying and adding all those samples and cosine (and negative sine) waves, we should have done one more thing. We should have found the average value instead of the total sum. This means that we should have divided by the total number of samples. However, since we’re only looking at half of the data (the lower 1025 frequency bins – and not all 2048) we divide by half of the number of samples in our slice of time.
So, we take each sample in the recording, multiply each of those by a value in the cosine (or negative sine) wave – and divide the results by half of the number of samples. When you get that average, you then find its logarithm (base 10) and multiply by 20.
If you do that for each value, you get the result shown below in Figure 11.
Figure 11.
If we connect the dots, then we get Figure 12.
Figure 12.
And there are the peaks we saw earlier. One just under 600 Hz at about -16 dB FS, and the other at about 1500 Hz with a level of about -31 dB FS.
The important stuff to remember for now…
There are two important things to remember from this posting.
The frequencies that are calculated using a DFT (or FFT) are linearly spaced. That means that (on a human, logarithmic scale) we have a poor resolution in the low frequencies and a very fine resolution in the high frequencies. (for example, in this case, the first three frequencies are 0 Hz, 23.4 Hz, and 46.9 Hz. The last three frequencies are 23953.1 Hz, 23976.6 Hz, and 24,000 Hz.)
If you want better resolution in the low frequencies, you’ll need to calculate with more samples – a longer slice of time, which means more might have happened in that time (although there are some tricks we can play, as we’ll see later).
And, you should be left with a question… Why does that plot in Figure 12 look like it’s got lots of energy at a bunch of frequencies – not just two clean spikes? We’ll get into that in the next posting: DFT’s Part 4: The Artefacts.
Once upon a time you learned how to count. You were probably taught to count your fingers… 1, 2, 3, 4 and so on. Although no one told you so at the time, you were being taught a set of numbers called whole numbers.
Sometime after that, you were probably taught that there’s one number that gets tacked on before the ones you already knew – the number 0.
A little later, sometime after you learned about money and the fact that we don’t have enough, you were taught negative numbers… -1, -2, -3 and so on. These are the numbers that are less than 0.
That collection of numbers is called integers – all “countable” numbers that are negative, zero and positive. So the collection is typically written
… -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5 …
Rational Numbers
Eventually, after you learned about counting and numbers, you were taught how to divide (the mathematical word for “sharing equally”). When someone said “20 divided by 5 equals 4” then they meant “if you have 20 sticks, then you could put those sticks in 4 piles with 5 sticks in each pile.” Eventually, you learned that the division of one number by another can be written as a fraction like 3/1 or 20/5 or 5/4 or 1/3.
If you do that division the old-fashioned way, you get numbers like this:
3 ∕ 1 = 3.000000000 etc…
20 ∕ 5 = 4.00000000 etc…
5 ∕ 4 = 1.200000000 etc…
1 ∕ 3 = 0.333333333 etc…
The thing that I’m trying to point out here is that eventually, these numbers start repeating sometime after the decimal point. These numbers are called rationalnumbers.
Irrational Numbers
What happens if you have a number that doesn’t start repeating, no matter how many numbers you have? Take a number like the square root of 2 for example. This is a number that, when you multiply it by itself, results in the number 2. This number is approximately 1.4142. But, if we multiply 1.4142 by 1.4142, we get 1.99996164 – so 1.4142 isn’t exactly the square root of 2. In fact, if we started calculating the exact square root of 2, we’d result in a number that keeps going forever after the decimal place and never repeats. Numbers like this (π is another one…) that never repeat after the decimal are called irrationalnumbers
Real Numbers
All of these number types – rational numbers (which includes integers) and irrational numbers fall under the general heading of real numbers. The fact that these are called “real” implies immediately that there is a classification of numbers that are “unreal” – but we’ll get to that later…
Imaginary Numbers
Let’s think about the idea of a square root. The square root of a number is another number which, when multiplied by itself is the first number. For example, 3 is the square root of 9 because 3*3 = 9. Let’s consider this a little further: a positive number muliplied by itself is a positive number (for example, 4*4 = 16… 4 is positive and 16 is also positive). A negative number multiplied by itself is also positive (i.e. –4*-4 = 16).
Now, in the first case, the square root of 16 is 4 because 4*4 = 16. (Some people would be really picky and they’ll tell you that 16 has two roots: 4 and -4. Those people are slightly geeky, but technically correct.) There’s just one small snag – what if you were asked for the square root of a negative number? There is no such thing as a number which, when multiplied by itself results in a negative number. So asking for the square root of -16 doesn’t make sense. In fact, if you try to do this on your calculator, it’ll probably tell you that it gets an error instead of producing an answer.
For a long time, mathematicians just called the square root of a negative number “imaginary” since it didn’t exist – like an imaginary friend that you had when you were 2… However, mathematicians as a general rule don’t like loose ends – they aren’t the type of people who leave things lying around… and having something as simple as the square root of a negative number lying around unanswered got on their nerves.
Then, in 1797, a Norwegian surveyor named Casper Wessel presented a paper to the Royal Academy of Denmark that described a new idea of his. He started by taking a number line that contains all the real numbers like this:
Figure 1: The number line containing all real numbers.
He then pointed out that multiplying a number by -1 was the same as rotating by an angle of 180º, like this:
Figure 2: Multiplying a number by -1 is the same as rotating by 180º
He then reasoned that, if this were true, then the square root of -1 must be the same as rotating by 90º.
Figure 3: This means that the square root of -1 must be the same a rotating by 90º.
This meant that the number line we started with containing the real numbers is the X-axis on a 2-dimensional plane where the Y-axis contains the imaginary numbers. That plane is called the Z plane, where any point (which we’ll call ‘Z’) is the combination of a real number (X) and an imaginary number (Y).
Figure 4: The Z-plane, where X-values are real and the Y-values are imaginary.
If you look carefully at Figure 4, you’ll see that I used a “j” to indicate the imaginary portion of the number. Generally speaking, mathematicians use i and physicists and engineers use j so we’ll stick with j. (The reason physics and engineering people use j is that they use i to mean “electrical current”.)
“What is j?” I hear you cry. Well, j is just the square root of -1. Of course, there is no number that is the square root of -1
and therefore
Now, remember that j * j = -1. This is useful for any square root of any negative number, you just calculate the square root of the number pretending that it was positive, and then stick a j after it. So, since the square root of 16, abbreviated sqrt(16) = 4 and sqrt(-1) = j, then sqrt(-16) = 4j.
Complex numbers
Now that we have real and imaginary numbers, we can combine them to create a complexnumber. Remember that you can’t just mix real numbers with imaginary ones – you keep them separate most of the time, so you see numbers like
3+2j
This is an example of a complex number that contains a real component (the 3) and an imaginary component (the 2j). In some cases, these numbers are further abbreviated with a single Greek character, like α or β, so you’ll see things like
α = 3+2j
In other cases, you’ll see a bold letter like the following:
Z= 3+2j
A lot of people do this because they like reserving Greek letters like α and ϕ for variables associated with angles.
Personally, I like seeing the whole thing – the real and the imaginary components – no reducing them to single Greek letters (they’re for angles!) or bold letters.
Absolute Value (aka the Modulus)
The absolute value of a complex number is a little weirder than what we usually think of as an absolute value. In order to understand this, we have to look at complex numbers a little differently:
Remember that j*j = -1.
Also, remember that, if we have a cosine wave and we delay it by 90º and then delay it by another 90º, it’s the same as inverting the polarity of the cosine, in other words, multiplying the cosine by -1. So, we can think of the imaginary component of a complex number as being a real number that’s been rotated by 90º, we can picture it as is shown in the figure below.
Figure 5. The relationship bewteen the real and imaginary components for the number (2 + 3 j). Notice that the X and Y axes have been labeled the “real” and “imaginary” axes.
Notice that Figure 5 actually winds up showing three things. It shows the real component along the x-axis, the imaginary component along the y-axis, and the absolute value or modulus of the complex number as the hypotenuse of the triangle. This is shown in mathematical notation in exactly the same way as in normal math – with vertical lines. For example, the modulus of 2+3jis written |2+3j|
This should make the calculation for determining the modulus of the complex number almost obvious. Since it’s the length of the hypotenuse of the right triangle formed by the real and imaginary components, and since we already know the Pythagorean theorem then the modulus of the complex number (a + b j) is
Given the values of the real and imaginary components, we can also calculate the angle of the hypotenuse from horizontal using the equation
This will come in handy later.
Complex notation or… Who cares?
This is probably the most important question for us. Imaginary numbers are great for mathematicians who like wrapping up loose ends that are incurred when a student asks “what’s the square root of -1?” but what use are complex numbers for people in audio? Well, it turns out that they’re used all the time, by the people doing analog electronics as well as the people working on digital signal processing. We’ll get into how they apply to each specific field in a little more detail once we know what we’re talking about, but let’s do a little right now to get a taste.
In the previous posting, that introduces the trigonometric functions sine and cosine, we looked at how both functions are just one-dimensional representations of a two-dimensional rotation of a wheel. Essentially, the cosine is the horizontal displacement of a point on the wheel as it rotates. The sine is the vertical displacement of the same point at the same time. Also, if we know either one of these two components, we know:
the diameter of the wheel and
how fast it’s rotating
but we need to know both components to know the direction of rotation.
At any given moment in time, if we froze the wheel, we’d have some contribution of these two components – a cosine component and a sine component for a given angle of rotation. Since these two components are effectively identical functions that are 90º apart (for example, a cossine wave is the same as a sine that’s been delayed by 90º) and since we’re thinking of the real and imaginary components in a complex number as being 90º apart, then we can use complex math to describe the contributions of the sine and cosine components to a signal.
Huh?
Let’s look at an example. If the signal we wanted to look at a signal that consisted only of a cosine wave, then we’d know that the signal had 100% cosine and 0% sine. So, if we express the cosine component as the real component and the sine as the imaginary, then what we have is:
1 + 0 j
If the signal were an upside-down cosine, then the complex notation for it would be (–1 + 0 j) because it would essentially be a cosine * -1 and no sine component. Similarly, if the signal was a sine wave, it would be notated as (0 – 1 j).
This last statement should raise at least one eyebrow… Why is the complex notation for a positive sine wave (0 – 1 j)? In other words, why is there a negative sign there to represent a positive sine component? (Hint – we want the wheel to turn clockwise… and clocks turn clockwise to maintain backwards compatibility with an earlier technology – the sundial. So, we use a negative number because of the direction of rotation of the earth…)
This is fine, but what if the signal looks like a sinusoidal wave that’s been delayed a little? As we saw in the previous posting, we can create a sinusoid of any delay by adding the cosine and sine components with appropriate gains applied to each.
So, is we made a signal that were 70.7% sine and 70.7% cosine. (If you don’t know how I arrived that those numbers, check out the previous posting.) How would you express this using complex notation? Well, you just look at the relative contributions of the two components as before:
0.707 – 0.707 j
It’s interesting to notice that, although this is actually a combination of a cosine and a sine with a specific ratio of amplitudes (in this case, both at 0.707 of “normal”), the result will look like a sine wave that’s been shifted in phase by -45º (or a cosine that’s been phase-shifted by 45º). In fact, this is the case – any phase-shifted sine wave can be expressed as the combination of its sine and cosine components with a specific amplitude relationship.
Therefore (again), any sinusoidal waveform with any phase can be simplified and expressed as its two elemental components, the gains applied to the cosine (or real) and the sine (or imaginary). Once the signal is broken into these two constituent components, it cannot be further simplified.
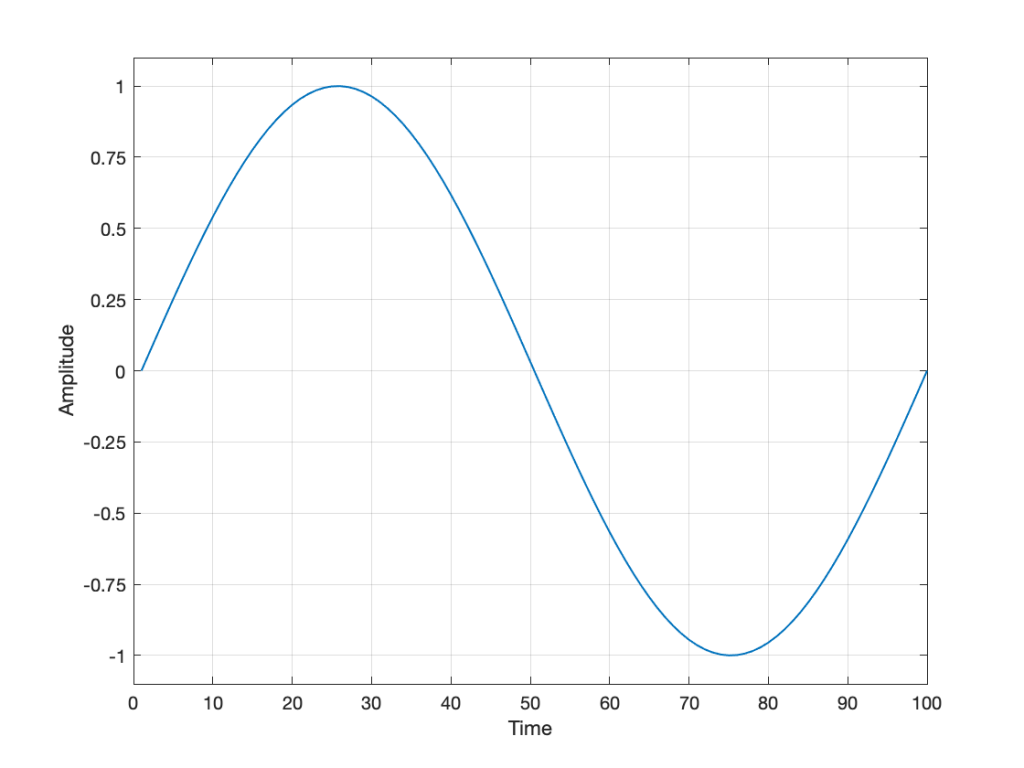
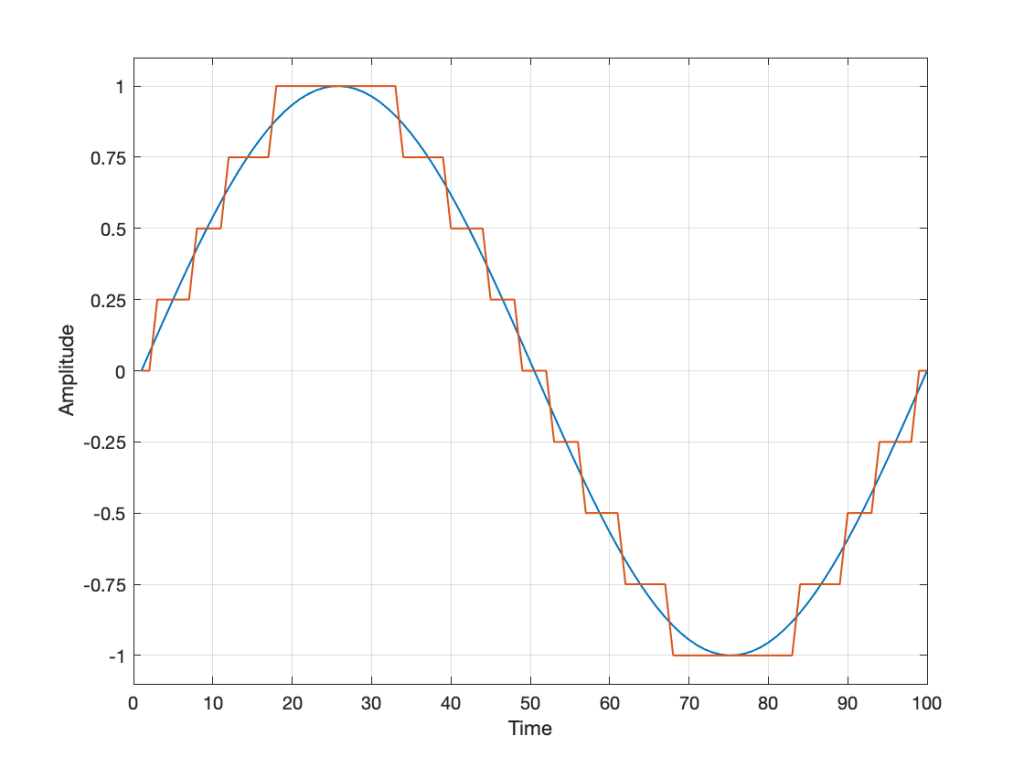
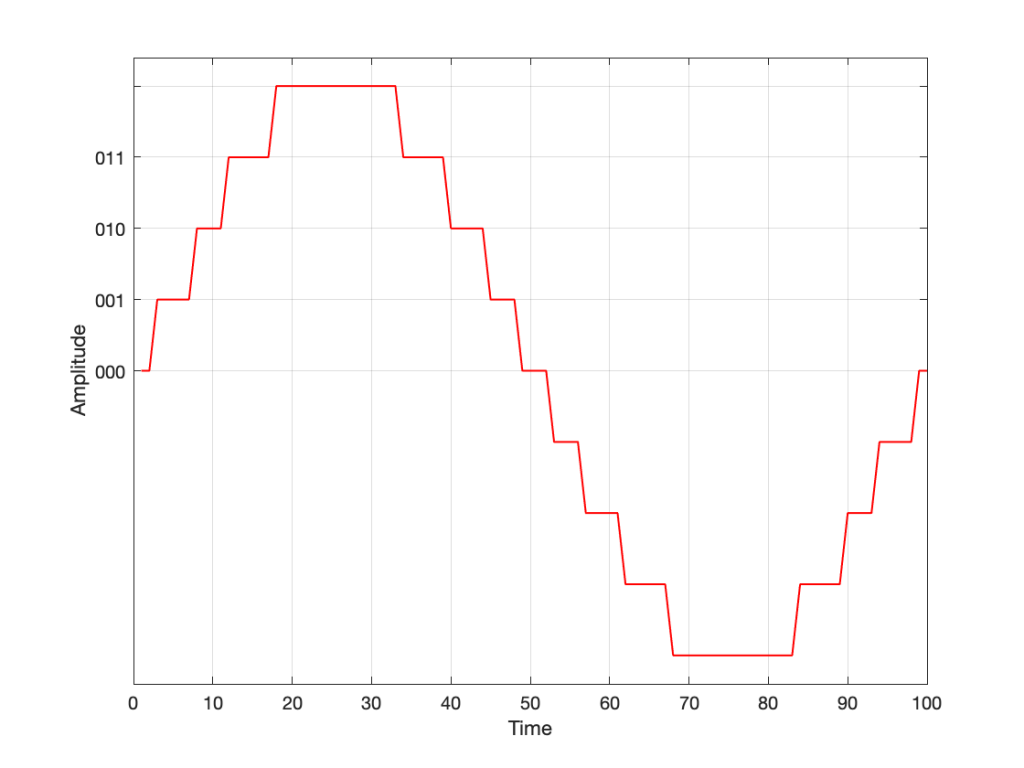


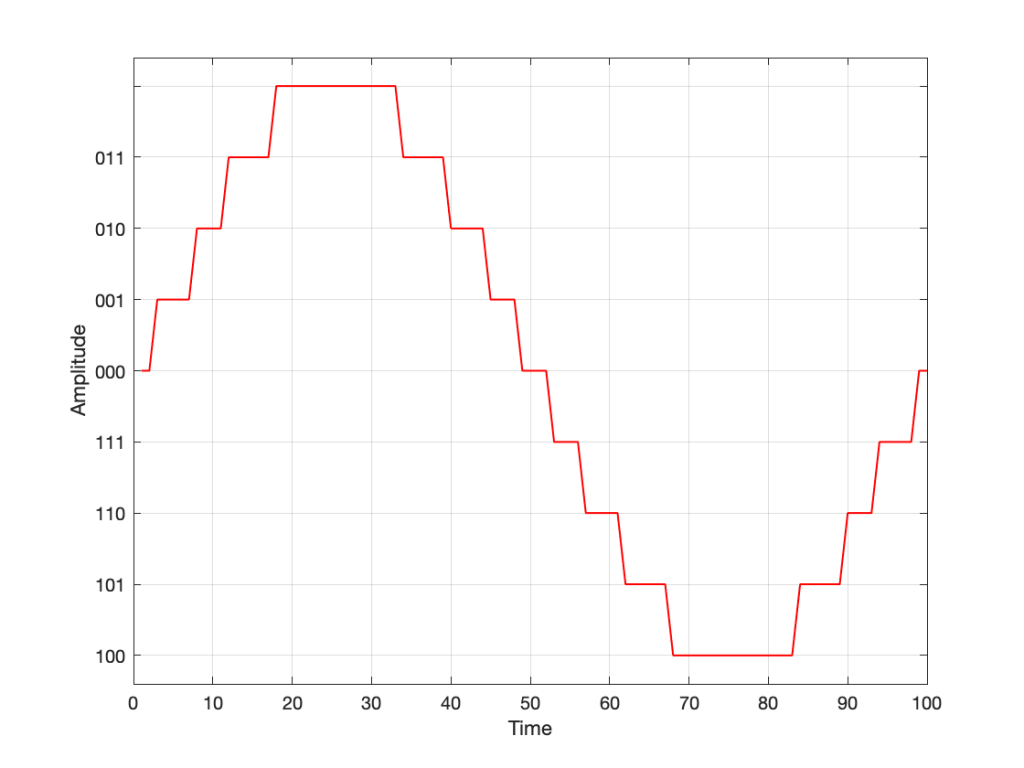
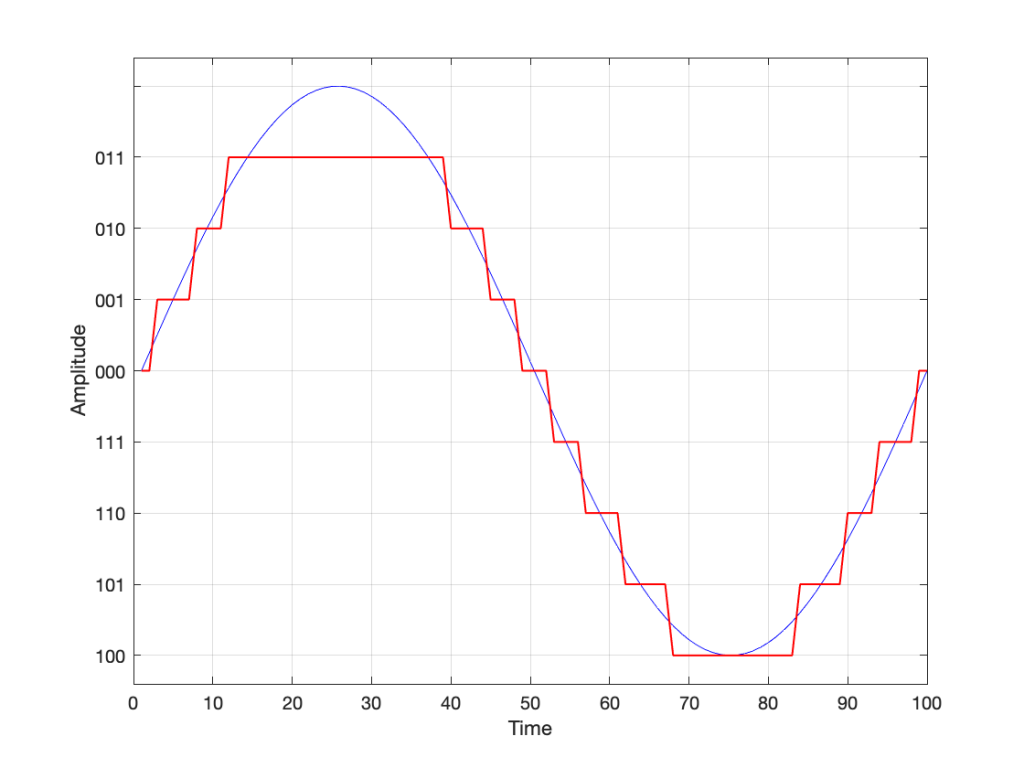
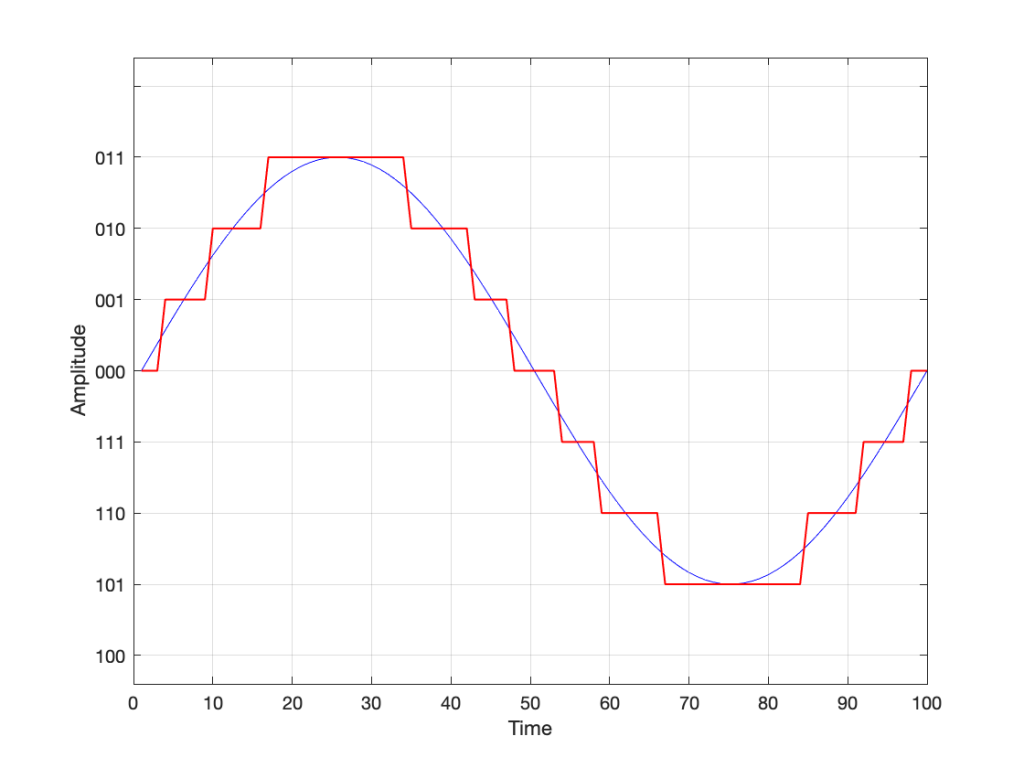
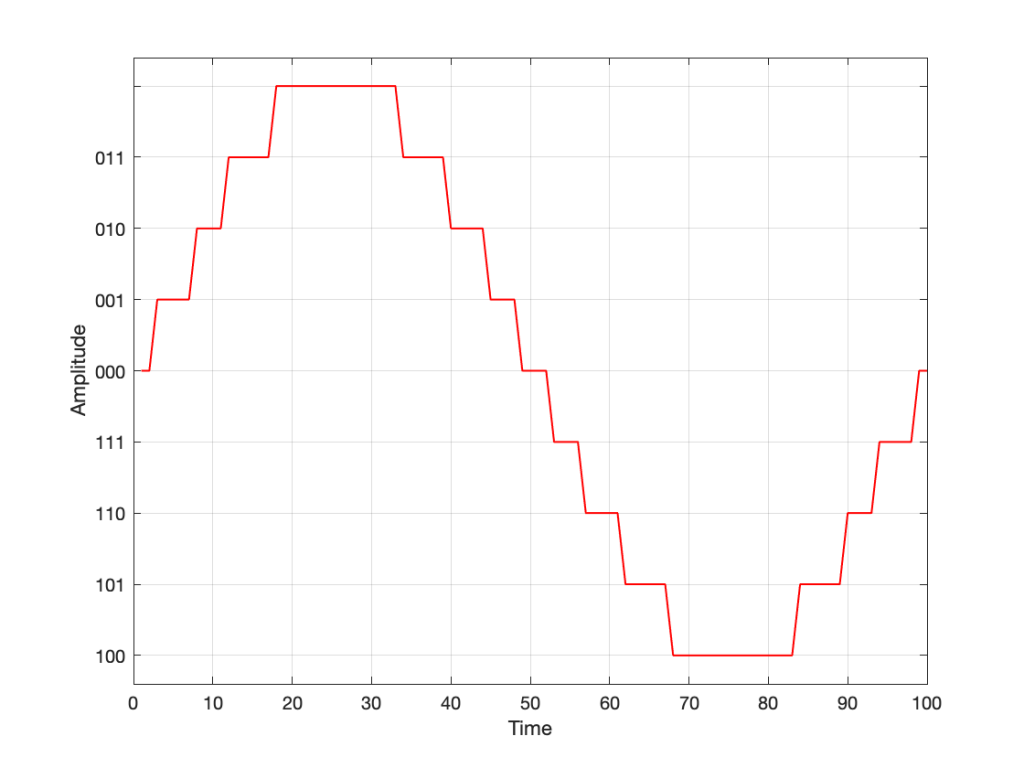
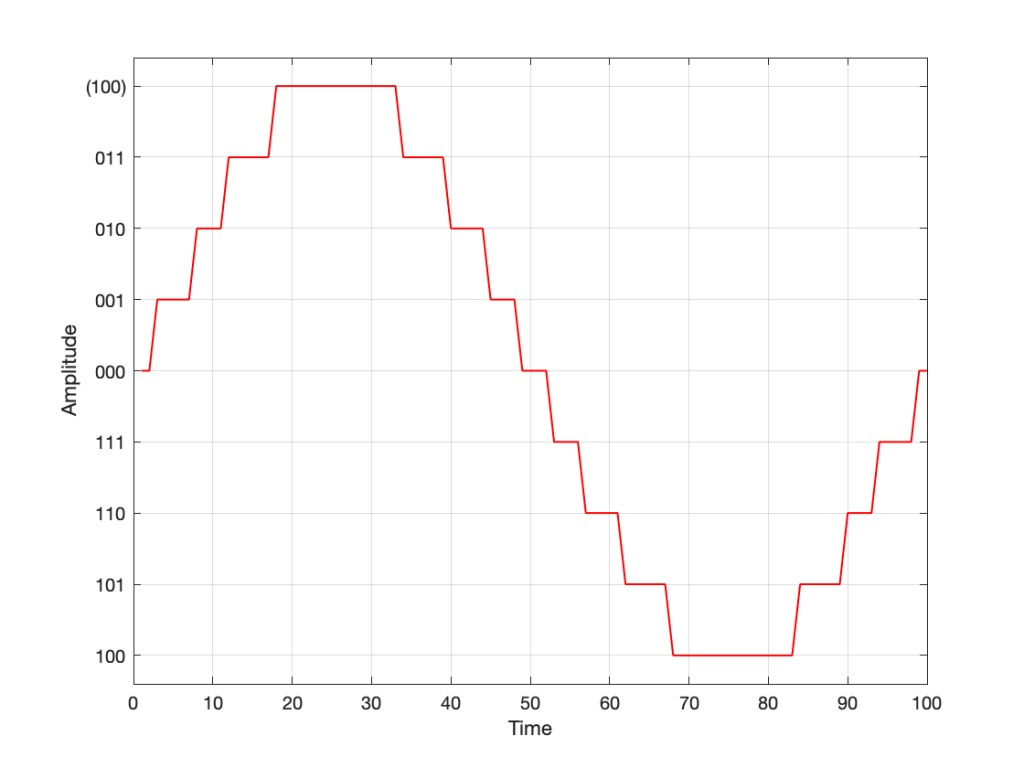
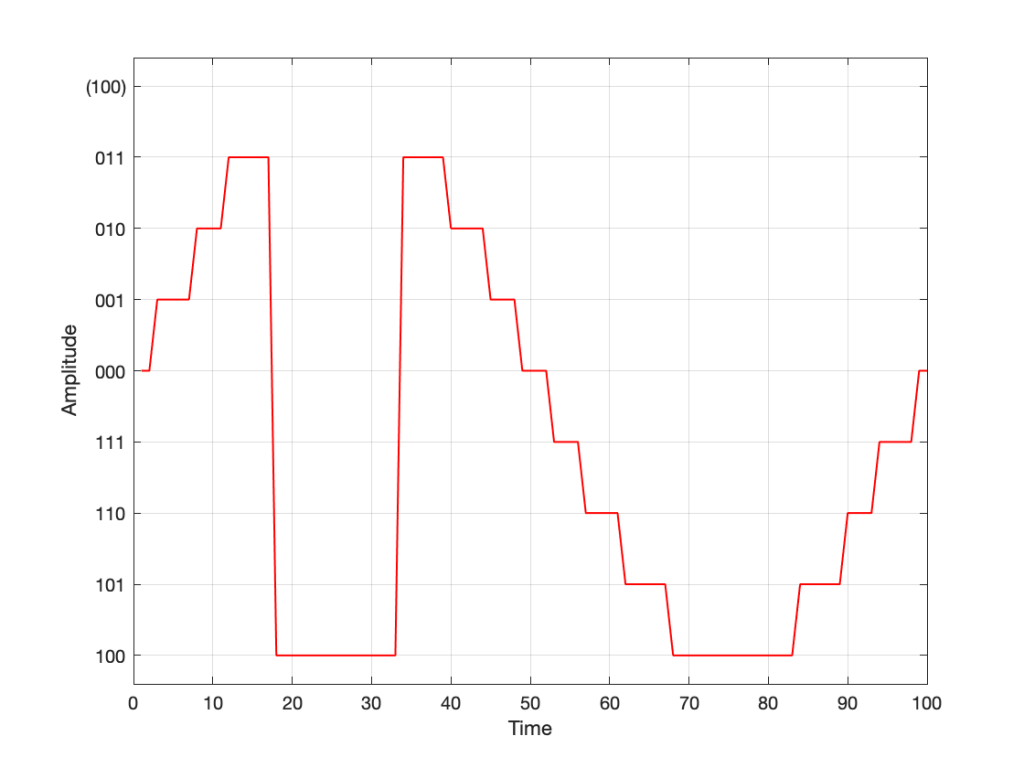
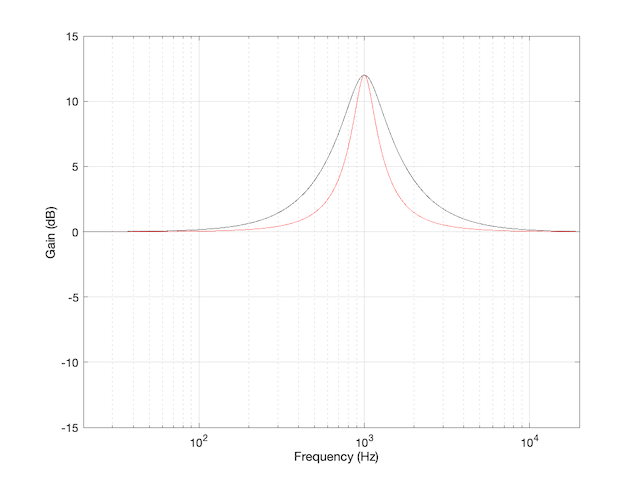
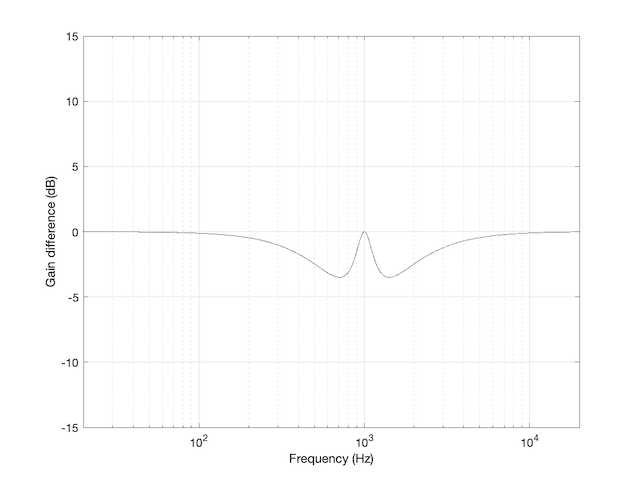
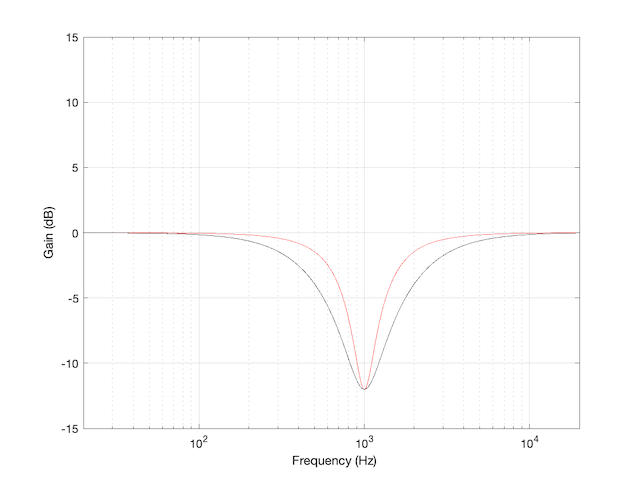
 (Gain in dB), and
(Gain in dB), and  . I’m calling it
. I’m calling it  (for Robert Bristow-Johnson).
(for Robert Bristow-Johnson).![\[G_{lin} = 10^\frac{G_{dB}}{20}\]](http://www.tonmeister.ca/wordpress/wp-content/ql-cache/quicklatex.com-5da79ddd7eef7bebd2ff0a8cb915d15f_l3.png "Rendered by QuickLaTeX.com")

![\[Q_{rbj} = \frac {Q_{z}} {\sqrt{ G_{lin}}}\]](http://www.tonmeister.ca/wordpress/wp-content/ql-cache/quicklatex.com-0d9e5308a56434a6f41d2ffd76826fd7_l3.png "Rendered by QuickLaTeX.com")

![\[Q_{rbj} = Q_{z} * \sqrt{ G_{lin}}\]](http://www.tonmeister.ca/wordpress/wp-content/ql-cache/quicklatex.com-7701b5c28ecc1e78b2213e6bcfb2cbdf_l3.png "Rendered by QuickLaTeX.com")




![\[Q_{rbj} = \frac {2} {\sqrt{ 3.9811}} = 1.0024\]](http://www.tonmeister.ca/wordpress/wp-content/ql-cache/quicklatex.com-e54e30d0230089601b1f302f89c444a7_l3.png "Rendered by QuickLaTeX.com")



![\[Q_{rbj} = 2 * \sqrt{ 0.3548} = 2.3826\]](http://www.tonmeister.ca/wordpress/wp-content/ql-cache/quicklatex.com-73ba935617322fb87a09fff66729f141_l3.png "Rendered by QuickLaTeX.com")
![\[Q_{rbj} = \frac{Q_{z} }{ \sqrt{10^\frac{\lvert G_{dB} \rvert }{20}}}\]](http://www.tonmeister.ca/wordpress/wp-content/ql-cache/quicklatex.com-9d5c89c7773d38d1f6d2801064f2fd8b_l3.png "Rendered by QuickLaTeX.com")