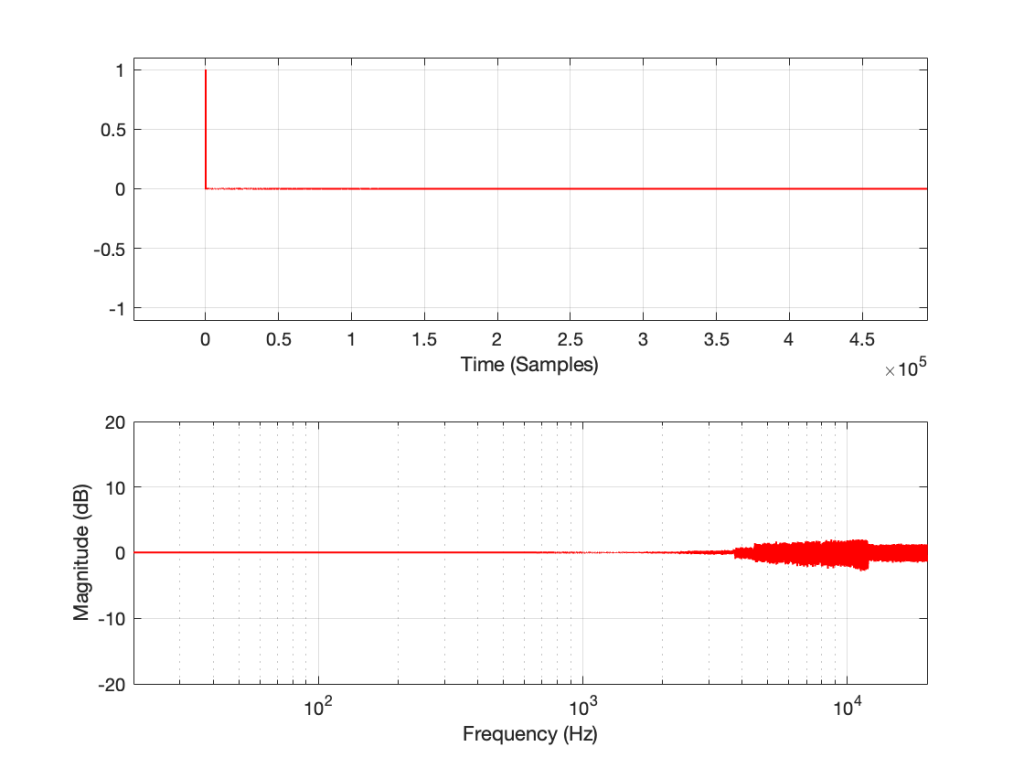
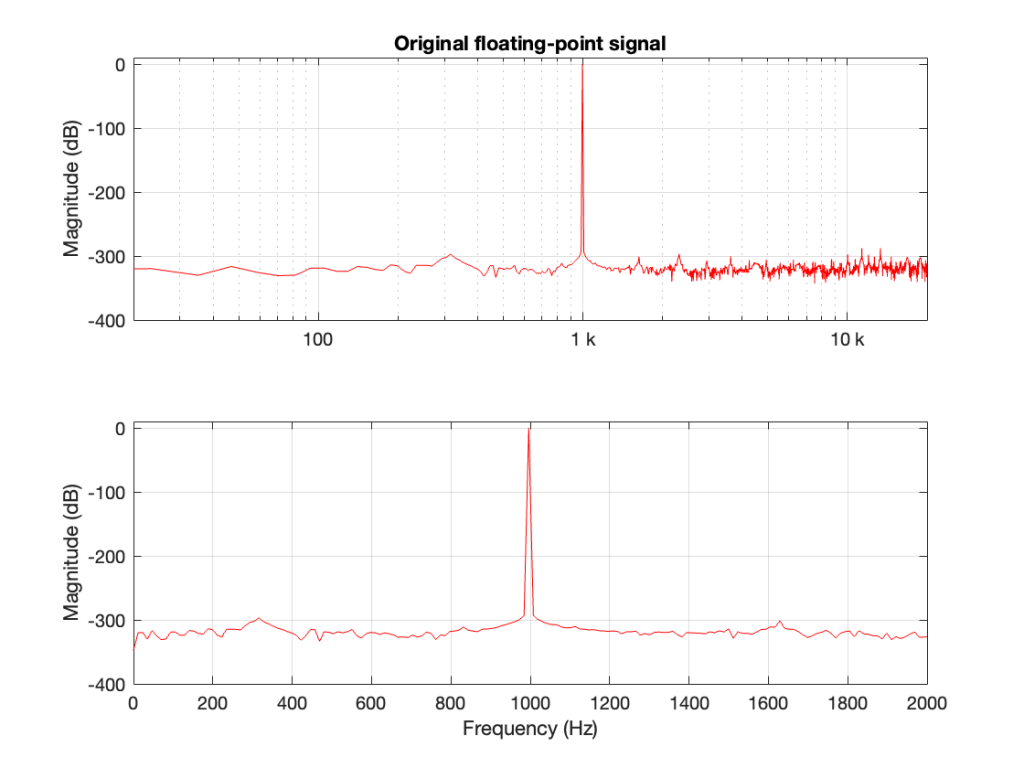
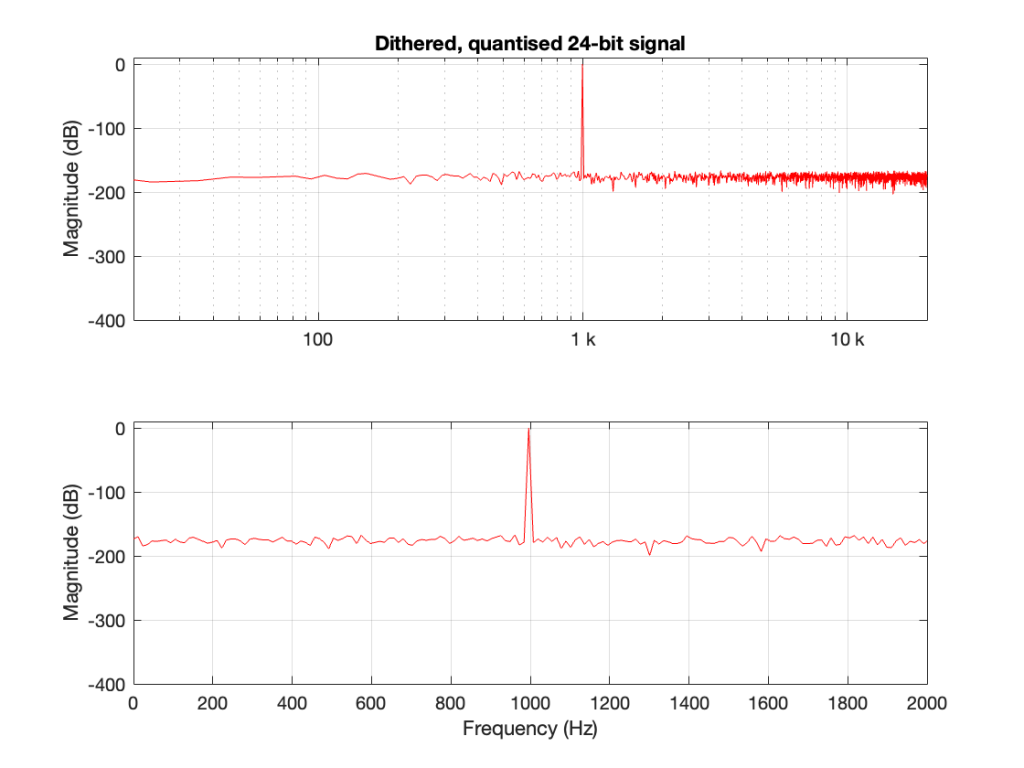
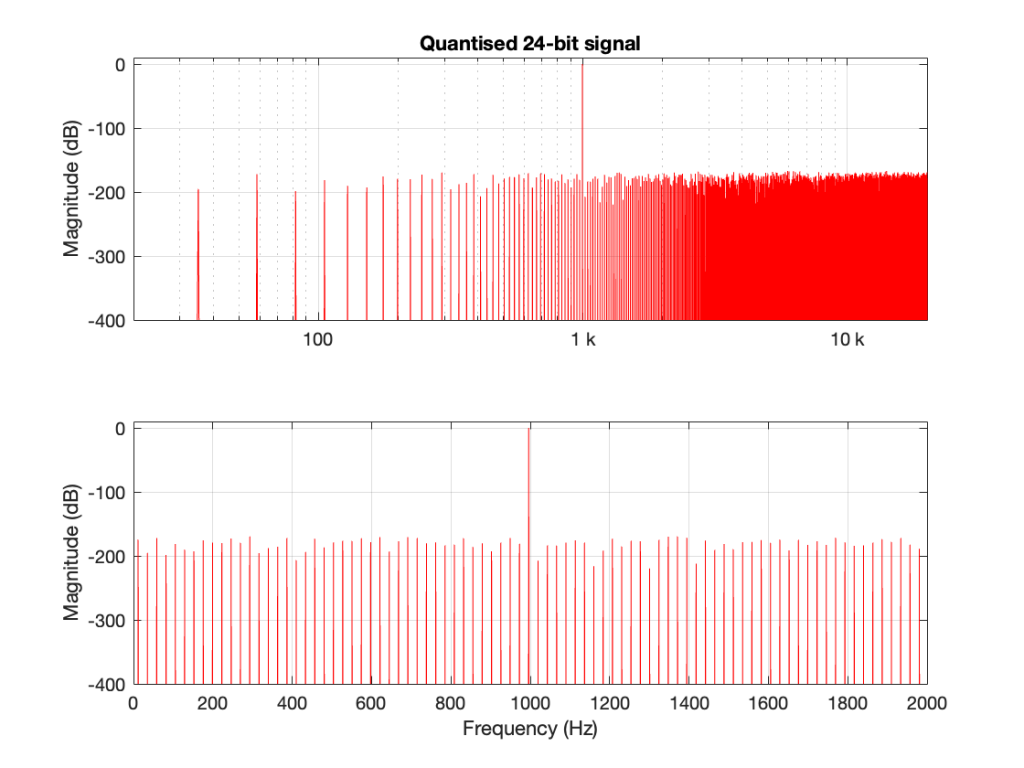
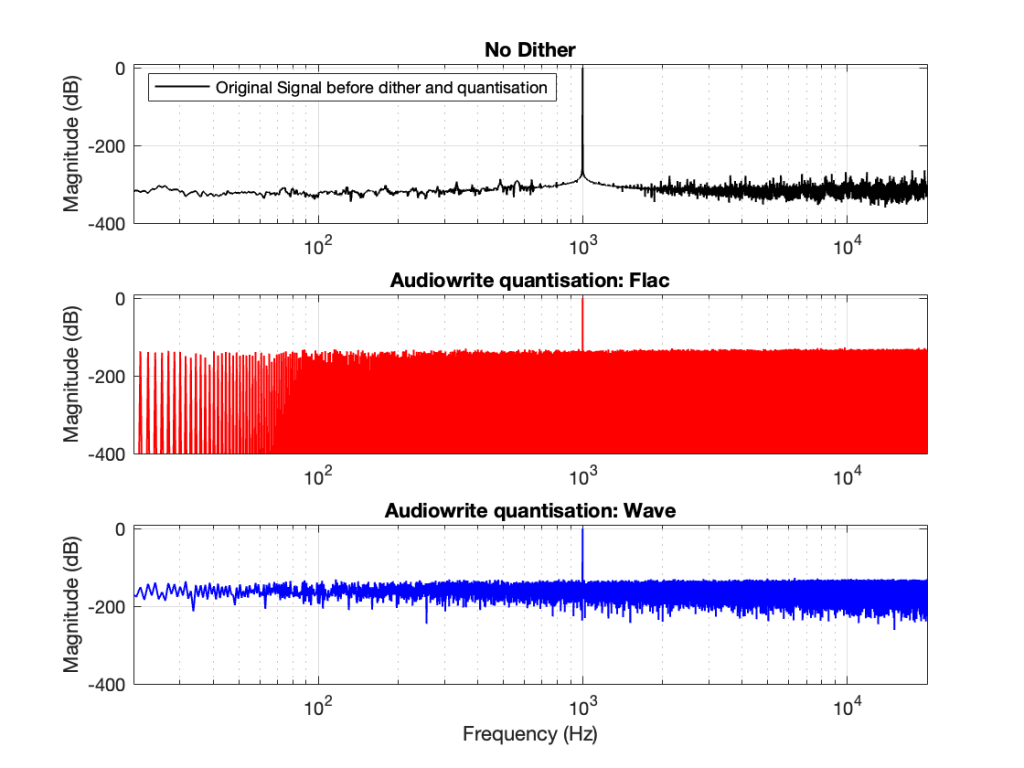
One of the best-known things about digital audio is the fact that you cannot record a signal that has a frequency that is higher than 1/2 the sampling rate.
Now, to be fair, that statement is not true. You CAN record a signal that has a frequency that is higher than 1/2 the sampling rate. You just won’t be able to play it back properly, because what comes out of the playback will not be the original frequency, but an alias of it.
If you record a one-spoked wheel with a series of photographs (in the old days, we called this ‘a movie’), the photos (the frames of the movie) might look something like this:

As you can see there, the wheel happens to be turning at a speed that results in it rotating 45º every frame.
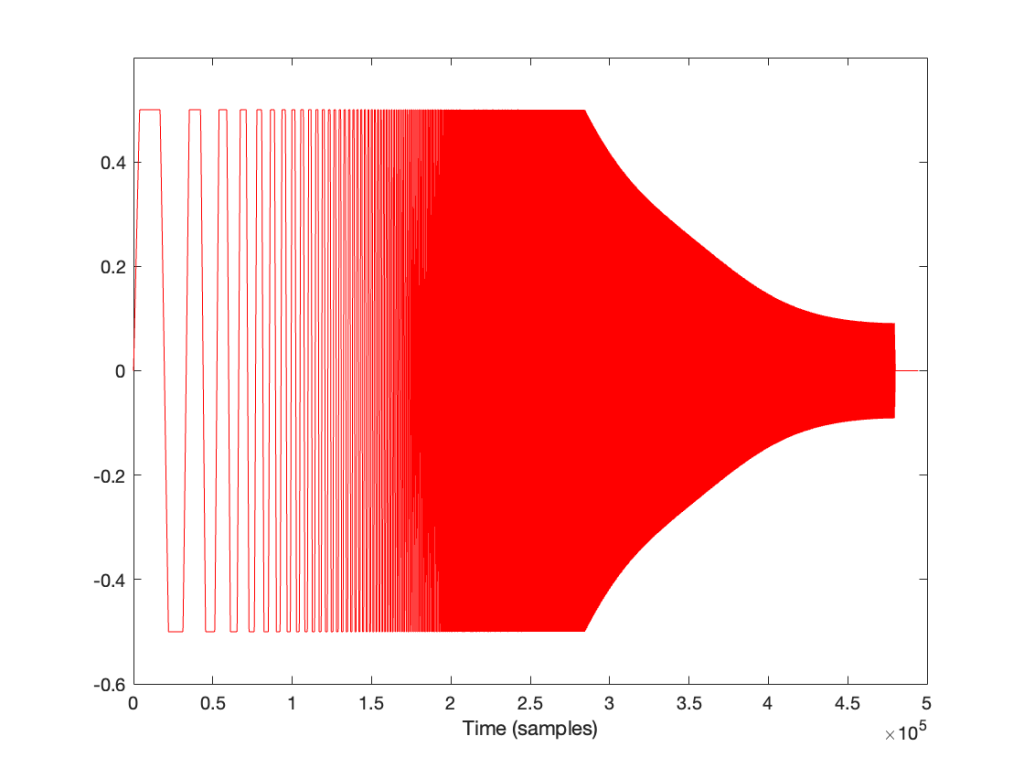
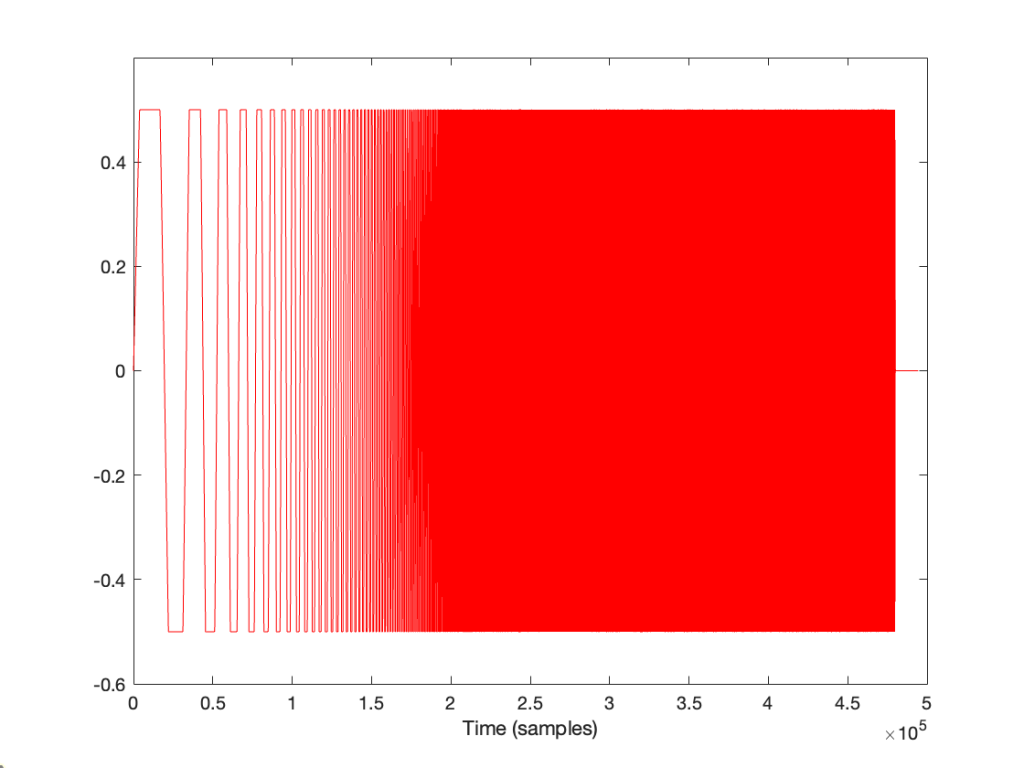
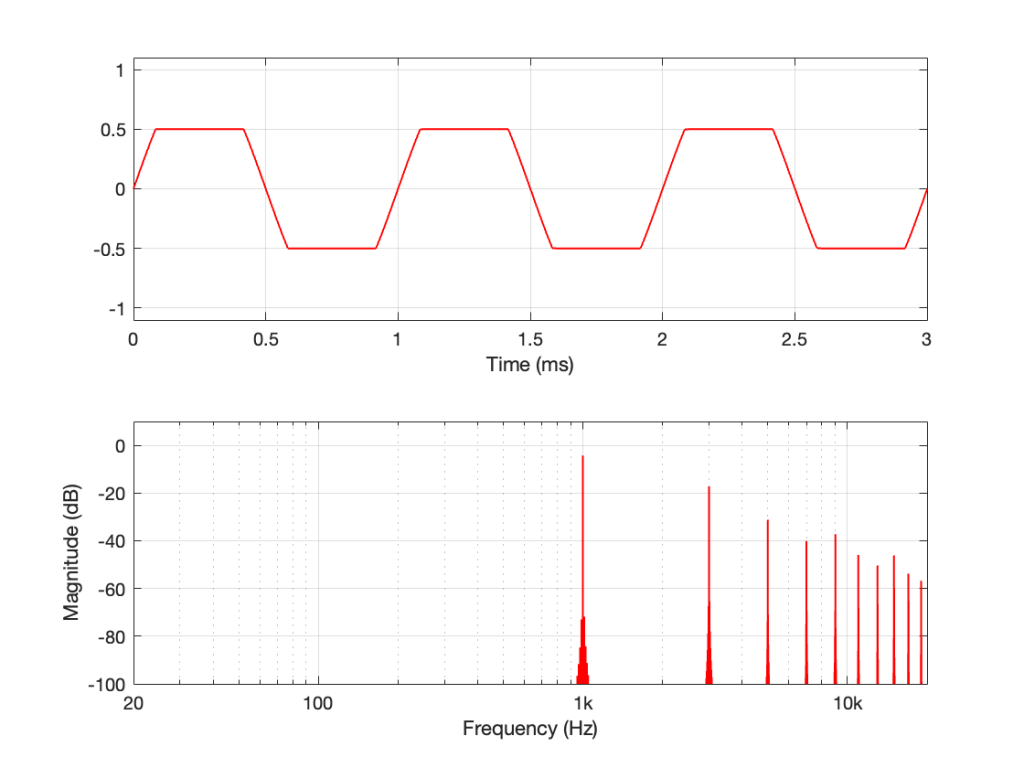
The equivalent of this in a digital audio world would be if we were recording a sine wave that rotated (yes…. rotated…) 45º every sample, like this:

Notice that the red lines indicating the sample values are equivalent to the height of the spoke at the wheel rim in the first figure.
If we speed up the wheel’s rotation so that it rotated 90º per frame, it looks like this:

And the audio equivalent would look like this:

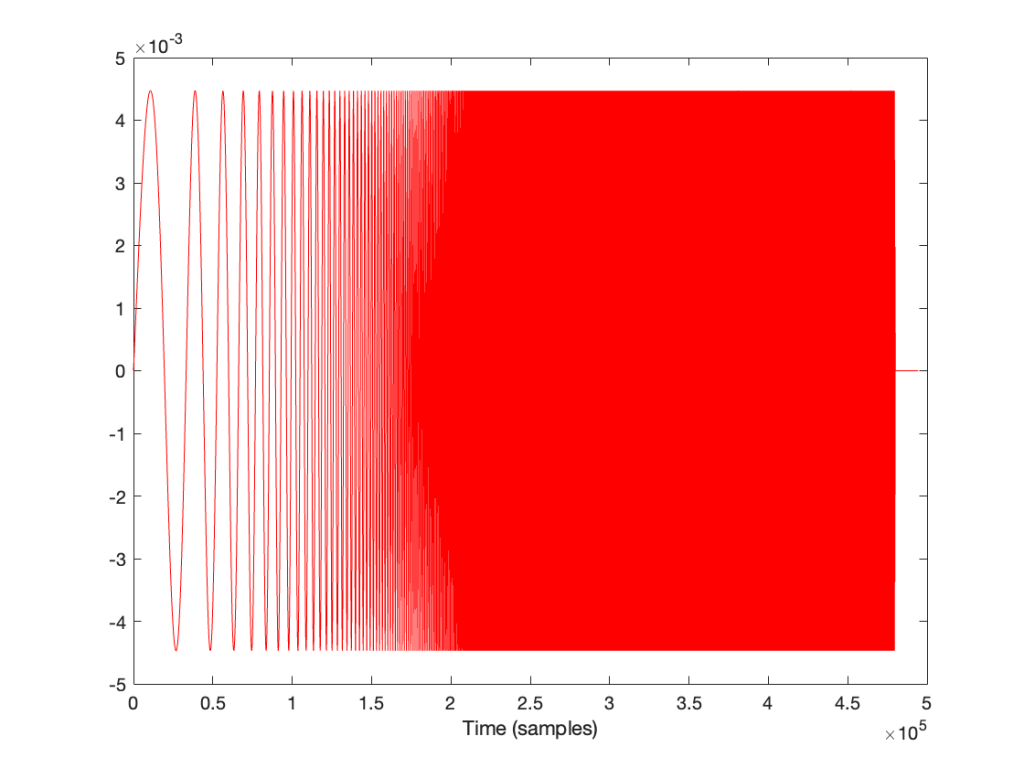
Speeding up even more to 135º per frame, we get this:

and this:

Then we get to a magical speed where the wheel rotated 180º per frame. At this speed, it appears when we look at the playback of the film that the wheel has stopped, and it now has two spokes.

In the audio equivalent, it looks like the result is that we have no output, as shown below.

However, this isn’t really true. It’s just an artefact of the fact that I chose to plot a sine wave. If I were to change the phase of this to be a cosine wave (at the same frequency) instead, for example, then it would definitely have an output.

At this point, the frequency of the audio signal is 1/2 the sampling rate.
What happens if the wheel goes even faster (and audio signal’s frequency goes above this)?

Notice that the wheel is now making more than a half-turn per frame. We can still record it. However, when we play it back, it doesn’t look like what happened. It looks like the wheel is going backwards like this:

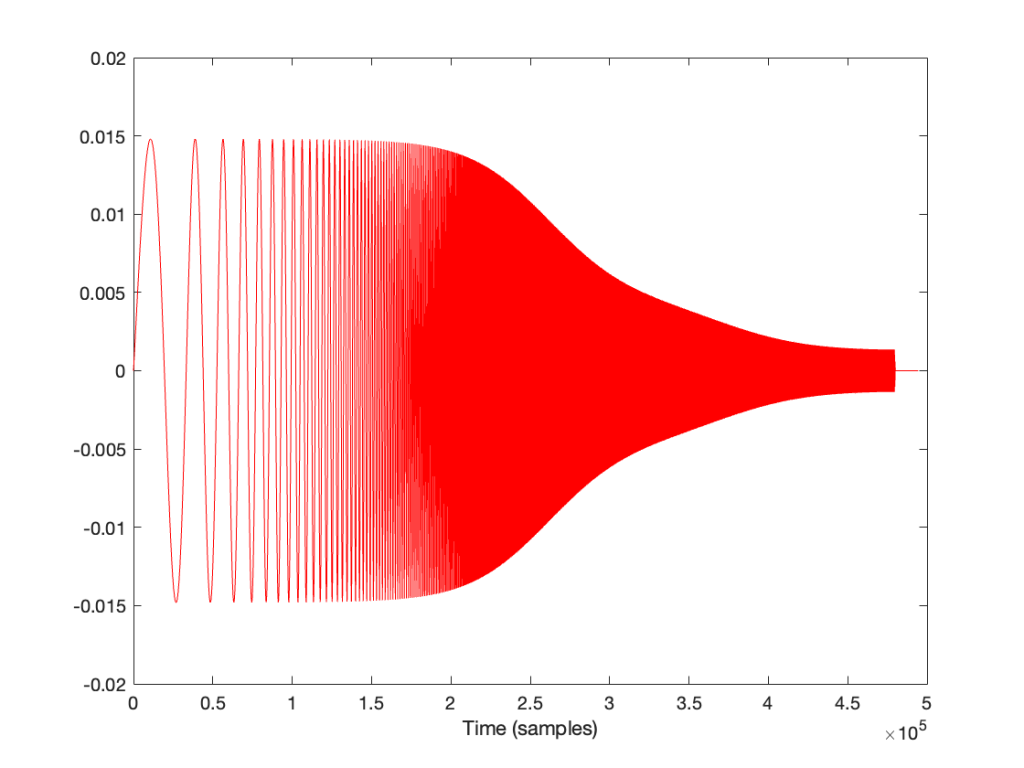
Similarly, if we record a sine wave that has a frequency that is higher than 1/2 the sampling rate like this:

Then, when we play it back, we get a lower frequency that fits the samples, like this:

Just a little math
There is a simple way to calculate the frequency of the signal that you get out of the system if you know the sampling rate and the frequency of the signal that you tried to record.
Let’s use the following abbreviations to make it easy to state:
- Fs = Sampling rate
- F_in = frequency of the input signal
- F_out = frequency of the output signal
IF
F_in < Fs/2
THEN
F_out = F_in
IF
Fs > F_in > Fs/2
THEN
F_out = Fs/2 – (F_in – Fs/2) = Fs – F_in
Some examples:
If your sampling rate is 48 kHz, and you try to record a 25 kHz sine wave, then the signal that you will play back will be:
48000 – 25000 = 23000 Hz
If your sampling rate is 48 kHz, and you try to record a 42 kHz sine wave, then the signal that you will play back will be:
48000 – 42000 = 6000 Hz
So, as you can see there, as the input signal’s frequency goes up, the alias frequency of the signal (the one you hear at the output) will go down.
There’s one more thing…
Go back and look at that last figure showing the playback signal of the sine wave. It looks like the sine wave has an inverted polarity compared to the signal that came into the system (notice that it starts on a downwards-slope whereas the input signal started on an upwards-slope). However, the polarity of the sine wave is NOT inverted. Nor has the phase shifted. The sine wave that you’re hearing at the output is going backwards in time compared to the signal at the input, just like the wheel appears to be rotating backwards when it’s actually going forwards.
In Part 2, we’ll talk about why you don’t need to worry about this in the real world, except when you REALLY need to worry about it.