If you listen to the radio in the mornings, they’ll give you the news, the sports, the traffic and the weather. Part of the weather report is to tell you that the barometric pressure is something around 100 kilopascals (abbreviated kPa)1 . What does this mean? Well, the air particles around you are all under pressure due to things like gravity and the weight of the air particles above them and other meteorological things that are outside the scope of this book. That pressure determines the amount of physical space between molecules in the air. When there’s a higher barometric pressure, there’s less space between the molecules than there is on a day with a lower barometric pressure.
We call this the stasis pressure and abbreviate it ℘o.
When all of the particles in a gaseous medium (like air) in a given volume (like a room) are at normal pressure, then the gas is said to be at its volume density (also known as the constant equilibrium density), abbreviated ρo, and measured in kg/m3. Remember that this is actually kilograms of air per cubic metre – if you were able to trap a cubic metre and weigh it, you’d find out that it’s about 1.3 kg.
These molecules like to stay at the same pressure all over, so if you bunch them up in one place in a room somehow, they’ll move around to try and equalize the difference. This is kind of like when you pour a glass of water into a bucket, the water level of the entire bucket equalizes and therefore rises, rather than the water from the glass all bunching up in a little mound of water where you poured it in...
Let’s think of this as a practical example. We’ll hang the piece of paper in front of a fan. If we turn on the fan, we’re essentially increasing the pressure of the air particles in front of the blades. The fan does this by removing air particles from the space behind it, thus reducing the pressure of the particles behind the blades, and putting them in front. Since the pressure in front of the fan is greater than any other place in the room, we have a situation where there is a greater air pressure on one side of the piece of paper than the other. The obvious result is that the paper moves away from the fan.
This is a large-scale example of how you hear sound. Let’s say hypothetically for a moment, that you are sitting alone in a sealed room on a day when the barometric pressure is 100 kPa. Let’s also say that you have a clarinet with you and that you play a concert A. What physically happens to convert air coming out of your mouth into a concert A coming in your ears?
To begin with, let’s pretend that a clarinet is just a tube with a hole in each end. One of the holes has a springy piece of wood next to it which, if you press on it, will close up the hole.
Those little fluctuations in the air pressure are small variations in the stasis pressure ℘o. They’re usually very small, never more than about ±1 Pa (though we’ll elaborate on that later...). At any given moment at a specific location, we can measure the the instantaneous pressure, ℘, which will be close to the stasis pressure, but slightly different because there’s a sound source causing it to change.
Once we know the stasis pressure and the instantaneous pressure, we can use these to figure out the instantaneous amplitude of the sound level, (also called the acoustic pressure or the excess pressure) abbreviated p, using Equation 3.1.
|
| (3.1) |

To see an animation of what this looks like, check out www.gmi.edu/ drussell/Demos/waves/wavemotion.html.
A sinusoidal oscillation of this pressure reaches a maximum peak pressure P which is used to determine the sound pressure level or SPL. In air, this level is typically expressed in decibels as a logarithmic ratio of the effective pressure Pe referenced to the threshold of hearing, the commonly-accepted lowest sound pressure level audible by humans at 1 kHz, 20 microPascals, using Equation 3.2 [Woram, 1989]. The intricacies of this equation have already been discussed in Section 2.2 on decibels.
![[ ]
SP L= 20 log ----Pe----
10 20 *10-6Pa](intro_to_sound_recording305x.png) | (3.2) |
Note that, for sinusoidal waveforms, the effective pressure can be calculated from the peak pressure using Equation 3.3. (If this doesn’t sound familiar, it should – re-read Section 2.1.6 on RMS.)
 | (3.3) |
Take a weight (a little one...) and hang it on the end of a Slinky which is attached to the ceiling and wait for it to stop bouncing.
Measure the length of the Slinky. This length is determined by the weight and the strength of the Slinky. If you use a bigger weight, the Slinky will be longer – if the slinky is stronger, it will be better able to support the weight and therefore be shorter.
This is the point where the “system” is at rest or stasis.
Pull down on the weight a little bit and let go. The Slinky will pull the weight up to the stasis point and pass it.
By the time the whole thing slows down, the weight will be too high and will want to come back down to the stasis point, which it will do, stopping at the point where we let it go in the first place (or almost anyway...)
If we attached a pen to the weight and ran piece of paper along by it as it sat there bobbing up and down, the line it would draw a sinusoidal waveform. The picture the weight would draw is a graph of the vertical position of the weight (the y-axis) as it relates to time (the x-axis).
If the graph is a perfect sinusoidal shape, then we call the system (the Slinky and the weight on the end) a simple harmonic oscillator.
Let’s look at that system I just described. We’ll put a weight hung on a spring as is shown in Figure 3.2
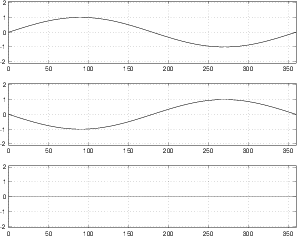
If there was no such thing as air friction, and if the spring was perfect, then, if you started the mass bobbing up and down, then it would continue doing that forever. Since, as we saw in the previous section, that this is a simple harmonic oscillator, if we graph its vertical displacement over time, then we get a perfect sinusoidal waveform as shown in Figure 3.3

In real life, however, there is friction. The mass pushes through the air and loses energy on each bob up and down. Eventually, it loses so much energy that it stops moving. An example of this behaviour is shown in Figure 3.4

There is a technical term that describes the difference between these two situations. The system with friction, shown in Figure 3.4 is called a damped oscillator. Since the oscillator is damped, then it loses energy over time. The higher the damping, the faster it loses energy. For example, if the same mass and spring were put in water, the system would be more highly damped than if it were in air. If they’re put in oil, the system is more highly damped than it is in water.
Since a system with friction is said to be damped, then the system without friction is therefore called an undamped oscillator.
If we go back to the clarinet example, it’s pretty obvious that the pressure wave that comes out the bell won’t be a sine wave. This is because the clarinet reed is doing more than simply opening and closing – it’s also wiggling and flapping a bit – on top of all that, the body of the clarinet is resonating various frequencies as well (more on this topic later), so what comes out is a bunch of different frequencies simultaneously.
We call these other frequencies harmonics which are mathematically related to the bottom frequency (called the fundamental) by simple multiplication... The first harmonic is the fundamental. The second harmonic is twice the frequency of the fundamental, the third harmonic is three times the frequency of the fundamental and so on. (This is an oversimplification that we’ll straighten out later...)
Some people call the fundamental and its harmonics overtones but you have to be careful here. There is a common misconception that overtones are harmonics and vice versa. In fact, in some books, you’ll see people saying that the first overtone is the second harmonic, the second overtone is the third harmonic and so on. This is not necessarily the case. A sound’s overtones are the harmonics that it contains, which is not necessarily all harmonics. As we’ll see later, not all instruments’ sounds contain all harmonics of the fundamental. There are particular cases, for example, where an instrument’s sound will only contain the odd harmonics of the fundamental. In this particular case, the first overtone is the third harmonic, the second overtone is the fifth harmonic and so on.
In other words, harmonics are a mathematical idea – frequencies that are related to a fundamental frequency whereas overtones are the frequencies that are produced by the sound source.
Another example showing that overtones are not harmonics occurs in many percussion instruments such as bells where the overtones have no harmonic relationship with the fundamental frequency – which is why these overtones are said to be enharmonically related.
There are basically three types of waves used to transmit energy through a medium or substance.
We’re only really concerned with the first two.
Transverse waves are the kind we see every day in ropes and puddles. They’re the kind where the motion of the particles is perpendicular to the direction of the wave propagation as can be seen in Figure 3.5. What does this mean? It’s easy to see if we go fishing... A boat on the surface of the ocean will sit there bobbing up and down as the waves roll past it. The waves are traveling towards the shore along the surface of the water, but the water itself only moves up and down, not sideways (we know this because the boat would move sideways as well if the water was doing so...) So, as the water molecules move vertically, the wave propagates horizontally.
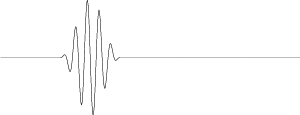
Longitudinal waves are a little tougher to see. They involve the compression (bunching together) and refraction (pulling apart) of the particles in the medium such that the motion of the particles is parallel with the direction of propagation of the wave. The easiest way to see a longitudinal wave is to stretch out a Slinky between two people, squeeze together a small section of it and let go. The compressed part will appear to move back and forth bouncing between the two ends of the spring. This is essentially the way sound travels through air particles.
Torsional waves don’t apply to anything we’re doing in this book, but they’re waves in which the particles rotate around the axis along which the wave propagates (like a twisting rod). This type of wave can be seen on a Shive wave machine at physics demonstrations and science and technology museums.
Think back to our original discussions concerning sound. We said that there are really two things moving in a sound wave – the air molecules (which are compressing and expanding) and the pressure wave which propagates outwardly from the sound source. We compared this to a wave moving along a rope. The rope moves up and down, but the wave moves in another direction entirely.
Let’s now think of this difference in terms of displacement and velocity – not of the sound wave itself (which is about 344 m/s at room temperature) but of the air molecules.
When a sound wave goes by a bunch of molecules, they compress and expand. In other words, they move closer together, then stop moving, then move further apart, then stop moving, then move closer together and so on. When the displacement is at its absolute maximum, the molecules are at the point where they’re stopped and about to head back towards a low pressure. When the displacement is 0 (and therefore at whatever barometric pressure the radio said it was this morning) the molecules are moving as fast as they can. If the displacement is at a maximum in the opposite direction, the molecules are stopped again.
When pressure is 0, the particle velocity is at a maximum (or a minimum) whereas when pressure is at a maximum (or a minimum) the particle velocity is 0.
This is identical to swinging on a playground swing. When you’re at the highest point off the ground, you’re stopped and about to head in the direction from which you just came. Therefore at the point of maximum displacement, you have a velocity of 0. When you’re at the point closest to the ground (where you started before you were moving) your velocity is highest.
So, in addition to measurements like instantaneous pressure, we can also talk about an instantaneous particle velocity, u. In addition, a sinusoidal oscillation results in a peak particle velocity, U.
Always remember that the particle velocity is dependent on the change
in displacement, therefore it is equivalent to the instantaneous slope (or the
partial derivative) of the displacement function. As a result, the velocity wave
precedes the displacement wave by 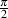 radians (or 90∘) as is shown in Figure
3.6.
radians (or 90∘) as is shown in Figure
3.6.

One other important thing to note here is that the velocity is also related to frequency (which is discussed below). If we maintain the same peak pressure, the higher the frequency, the faster the particles have to move back and forth, therefore the higher the peak velocity. So, remember that particle velocity is proportional both to pressure (and therefore displacement) and frequency.
The amplitude of a wave is simply an measurement of the height of the wave if it’s transverse, or the amount of compression and refraction if it’s longitudinal. In terms of sound, it’s measured in Pascals, since sound waves are variation in atmospheric pressure. If we were measuring waves on the ocean, the unit of measurement would be metres.
There are a number of methods of defining the amplitude measurement – we’ll be using three, and you have to be careful not to confuse them.

Go back to the clarinet example. If we play a concert A, then it just so happens that the reed is opening and closing at a rate of 440 times per second. This therefore means that there are 440 cycles between a high and a low pressure coming out of the bell of the clarinet each second.
We normally use the term Hertz (indicated Hz) to indicate the number of cycles per second in sound waves. Therefore 440 cycles per second is more commonly known as a frequency of 440 Hz. (In older books, you will see this called cycles per second or cps.)
In order to find the frequency of a note one octave above this pitch, multiply by 2 (1 octave = twice the frequency). One octave below is one-half of the frequency.
In order to find the frequency of a note one decade above this pitch, multiply by 1 (1 decade = ten times the frequency). One decade below is one-tenth of the frequency.
Always remember that a complete cycle consists of a high and a low pressure. One cycle is measured from a point on the wave to the next identical point on the wave (i.e. the positive-going zero crossing to the next positive-going zero crossing or maximum to maximum...)
If we know the frequency of a sound wave (i.e. 440 Hz), then we can calculate how long it takes a single cycle to exit the bell of the clarinet. If there are 440 cycles each second, then it takes 1/440th of a second to produce 1 cycle.
The usual equation for calculating this amount of time (known as the period) is:
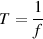 | (3.4) |
where T is the period and f is the frequency
See Section 3.10.
For this section, it’s important to remember two things.
We now know that the frequency of a sinusoidal sound wave is a measure of how many times a second the wave repeats itself. However, if we think of the wave as a rotating wheel, then this means that the wheel makes a full revolution the same number of times per second.
We also know that one full revolution of the wheel is 360∘ or 2π radians.
Consequently, if we multiply the frequency of the sound wave by 2π, we get the number of radians the wheel turns each second. This value is called the angular frequency or the radian frequency and is abbreviated ω.
 | (3.5) |
The angular frequency can also be used to determine the phase of the signal at any given moment in time. Let’s say for a moment that we have a sine wave with a frequency of 1 Hz, therefore ω = 2π. If it’s really a sine wave (meaning that it started out heading positive with a value of 0 at time 0 or t = 0), then we know that the time in seconds, multiplied by the angular frequency will give us the phase of the sine wave because we rotate 2π radians every second.
This is true for any frequency, so if we know the time t in seconds, then we can find the instantaneous phase using Equation 3.6.
 | (3.6) |
Usually, you’ll just see this notated as ωt as in sin(ωt).
Back in Section 1.5 we looked at how two wheels rotating at the same speed (or frequency) but in opposite directions will look exactly the same if we look at them from only one angle. This was our big excuse for getting into the whole concept of complex numbers – without both the sine and cosine components, we can only know the speed of rotation (frequency) and diameter (amplitude) of the sine wave. In other words, we’ll never know the direction of rotation.
As we walk through the world listening to sinusoidal waves, we only get one signal for each sine wave – we don’t get a sine and cosine component, just a pressure wave that changes in time. We can measure the frequency and the amplitude, but not the direction of rotation. In other words, the frequency that we’re looking at might be either positive or negative, depending on which direction the imaginary wheel is turning.
Here’s another way to think of this. Take a Slinky, stretch it out, and look at it from the side. If you didn’t have the benefit of perspective, you wouldn’t be able to tell if the Slinky was coiled clockwise or counterclockwise from left to right. One is positive frequency, the other is the negative equivalent.
In the real world, this doesn’t really matter too much, but as we’ll see later on, when you’re doing things like digital filtering, you need to worry about such things.
Pay attention during any thunder and lightning storm and you’ll be able to figure out that sound travels slower than light. Since the lightning and the thunder occur simultaneously and since the light flash arrives at you earlier than the clap of thunder (unless you’re extremely unlucky...) then this must be true. In fact, the speed of sound, abbreviated c is around 344 m/s although it changes with temperature, pressure and humidity.
Note that we’re talking about the speed of the wavefront – not the velocity of the air molecules. This latter velocity is dependent on the waveform, as well as its frequency and the amplitude.
The equation we normally use for c in metres per second is
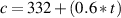 | (3.7) |
where t is the temperature in ∘C
There is a small deviation of c with frequency shown in Table 3.1, though this is small and therefore generally ignored
| Frequency | Deviation |
| 100 Hz | -30 ppm |
| 200 Hz | -10 ppm |
| 400 Hz | -3 ppm |
| 1.25 kHz | 0 ppm |
| 4 kHz | +5 ppm |
| 10 kHz | +10 ppm |
Changes in humidity change the value of c as is seen in Table 3.2.
| Humidity | Deviation |
| 0% | 0 ppm |
| 20% | +415 ppm |
| 40% | +1136 ppm |
| 60% | +1860 ppm |
| 80% | +2590 ppm |
| 100% | +3320 ppm |
The difference at a humidity level of 100% of 0.33% is bordering on our ability to detect a pitch shift.
Also – in case you were wondering, “ppm” stands for “parts per million.” It’s just
like “percent” really, except that you divide by 1000000 instead of 100 so it’s useful for
really small numbers. Therefore 1000 ppm is 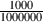 = 0.001 = 0.1%.
= 0.001 = 0.1%.
Let’s say that you’re standing outside, whistling a perfect 1 kHz sine tone. The moment you start whistling, the first wave – the wavefront – is moving away from you at a speed of 344 m/s. This means that exactly one second after you started whistling, the wavefront is 344 m away from you. At exactly that same moment, you are starting to whistle your 1001st cycle (because you’re whistling 1000 cycles per second). If we could stop time and look at the sound wave in the air at that moment, we would see the 1000 cycles that you just whistled sitting in the air taking up 344 m. Therefore you have 1000 cycles for every 344 m. Since we know this, we can calculate the length of one wave by dividing the speed of sound by the frequency – in this case, 344/1000 = 34.4 cm per wave in the air. This is known as the wavelength
The wavelength (abbreviated λ – the Greek letter lambda) is the distance from a point on a periodic (a fancy word meaning ‘repeating’) waveform to the next identical point. (i.e. crest to crest, or positive zero-crossing to positive zero crossing)
Equation 3.8 is used to calculate the wavelength, measured in metres.
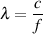 | (3.8) |
The wavelength of a sinusoidal acoustic wave is a measure of how many metres long a single wave is. We could think of this relationship between frequency and space in a different way. We can also measure the number of radians our wave changes (or our wheel turns) in one metre – in other words, the amount of phase change of the waveform per metre. This value is called the acoustic wavenumber of the sound wave and is abbreviated k0 or sometimes, just k. It’s measured in radians per metre and is calculated using Equation 3.10.
You can see from Equation 3.11 that the wavenumber is proportional to frequency.
Note that you will see this under a couple of different names – wave number, wavenumber and acoustic wavenumber will show up in different places to mean the same thing. The problem is that there are a couple of different definitions of the term “wavenumber” so you’re best to use the proper term “acoustic wavenumber.”
Go throw a rock in the water on a really calm lake. The result will be a bunch of high and low water levels that expand out from the point where the rock landed. The highs are slightly above the water level that existed before the rock hit, the lows are lower. This is analogous to the high and low pressures that are coming out of a clarinet, being respectively higher and lower than the equilibrium pressure that existed before the clarinet was brought into the room.
Now go and do the same thing out on the ocean as the waves are rolling past. The ripples that you create will cause the bigger wave to rise and fall on a small scale. This is essentially the same as what was happening on the calm lake, but now, the level of equilibrium is changing.
How do we find the final water level? We simply add the two levels together, making sure to pay attention to whether we should be adding a positive value (higher water level) or negative value (lower water level.)
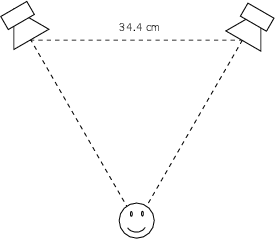
Let’s go outdoors and put two small omnidirectional (that is, they radiate sound equally in all directions) loudspeakers, about 34.4 cm apart. Let’s also take a sine wave generator set to produce a 500 Hz sine wave and send it to both speakers simultaneously. What happens?
If you’re equidistant from the two speakers as is shown in Figure 3.8, then you’ll be receiving the same part of the pressure wave at the same time. So, if you’re getting the high point in the wave from one speaker, you’re getting a high pressure from the second speaker as well.
Likewise, if you’re getting a low pressure from one speaker, you’re also receiving a low pressure from the other.
The end result of this overlap is that you get twice the pressure difference between the high and low points in your wave. This is because the two waves are interfering with each other constructively. This happens because the two have a phase relationship of 0∘ at your position.
Looking at Figure 3.9, essentially all we’re doing is adding two simultaneous points from the first two graphs and winding up with the bottom graph.

What happens if you’re standing on a line with the two loudspeakers, so that the more distant speaker is 34.4 cm farther away than the closer one as is shown in Figure 3.10?
Now, we have to consider the wavelength of the sound being produced. A 500 Hz sine tone has a wavelength of roughly 68 cm. Therefore, half of a wavelength is 34 cm, or the distance between the two loudspeakers.
This means that the sound from the farther loudspeaker is arriving at your position 1/2 of a cycle late. In other words, you’re getting a high pressure from the closer speaker as you get a low pressure from the farther speaker.
The end result of this effect is that you hear nothing (this is not really true for reasons that we’ll talk about later) because the two pressure levels are always opposite each other. This is shown in Figure 3.11.
The discussion of constructive and destructive interference above assumed that the tones coming out of the two loudspeakers have exactly matching frequencies. What happens if this is not the case?
If the two frequencies (let’s call them f1 and f2 where f2 > f1) are different then the resulting pressure looks like a periodic wave whose amplitude is being modulated periodically as is shown in Figure 3.12.

The big question is: what does this sound like? The answer to this question is “it depends on how far apart the frequencies are...”
If the frequencies are close together:
First and foremost, you’re going to hear the two sine waves of two frequencies, f1 and f2.
Interestingly, you’ll also hear beats at a rate equal to the lower frequency subtracted from the higher frequency. For example, if the two tones are at 440 and 444 Hz, you’ll hear the two notes beating 4 times per second (or f2 -f1).
This is the way we tune instruments with each other. If we have two flutes play two A 440’s at the same time (with no vibrato), then we should hear no beating. If there’s beating, the flutes are out of tune.
If the frequencies are far apart:
First and foremost, you’re going to hear the two sine waves of two frequencies f1 and f2.
Secondly, you’ll hear a note whose frequency is equal to the difference between the two frequencies being played, f2 -f1
Thirdly, you’ll hear other tones whose frequencies have the following mathematical relationships with the two tones being played. These are called difference tones, resultant tones or combination tones and they follow a sequence shown in Table 3.3.
| f2 -f1 | f2 -2f1 | f2 -3f1 | f2 -4f1 | . . . |
| 2f2 -f1 | 2f2 -2f1 | 2f2 -3f1 | 2f2 -4f1 | . . . |
| 3f2 -f1 | 3f2 -2f1 | 3f2 -3f1 | 3f2 -4f1 | . . . |
| 4f2 -f1 | 4f2 -2f1 | 4f2 -3f1 | 4f2 -4f1 | . . . |
| . | . | . | . | . |
| . | . | . | . | . |
| . | . | . | . | . |
This is a result of a number of effects.
If you’re doing an experiment using two tone generators and a loudspeaker, then the effect is likely a product of the speaker called intermodulation distortion. In this case, the combination tones are actually being generated by the driver. We’ll talk about this later.
If you’re using two loudspeakers (or two instruments) then there is some argument as to where the extra tones actually exist. Some arguments say that the tones are in the air, some say that the tones are generated at the eardrum. The most interesting arguments say that the tones are generated in the brain. The proof for this lies in an experiment where different tones are applied to each ear seperately (using headphones). In this case, some listeners still hear the combination tones (this is an effect called binaural beating).
We said earlier that the upper harmonics of a periodic waveform are multiples of the first harmonic. Therefore, if I have a non-sinusoidal, but periodic waveform, with a fundamental of 100 Hz, the actual harmonic content is 100 Hz, 200 Hz, 300 Hz, 400 Hz and so on up to ∞ Hz.
Let’s assume that the fundamental is lowered to 1 Hz – we’re now dealing with an object that is vibrating 1 time each second. The fundamental is 1 Hz, so the upper harmonics are 2 Hz, 3 Hz, 4 Hz, 5 Hz and so on up to ∞.
If we keep slowing down the fundamental to one single click, then the harmonic content is all frequencies up to infinity. Therefore it takes all frequencies sounding simultaneously with the correct phase relationships to create a single click.
If we were to graph this relationship, it would be Figure 3.13, where the two graphs essentially show the same information.
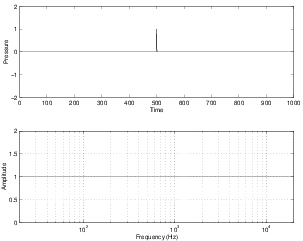
We saw in the previous section that a single click is a signal that contains all frequencies at the same magnitude. This is true, however, we have to be a little more specific... The click must be infinitely short in time (this is not very long at all...) in order for all frequencies to be equal in magnitude. However, if you have a click that is infinitely short, then you will find that it doesn’t contain a lot of total energy, so it will have to be very loud in order to have a reasonable magnitude at all frequencies. in fact, the click will have to be not only infinitely short, but infinitely loud. However, usually, when we produce an impulse in measuring a loudspeaker or a room’s acoustical behaviour, we do not produce an infinitely loud click, since this would cause the universe to explode (infinitely loud is very loud...).
So, we are supposed to make an infinitely short, infinitely loud sound, however, if we need to make this impulse (the correct word for our click) we usually just make it as short and as loud as possible (however, there are some tricks to get around this – we’ll talk about them later).
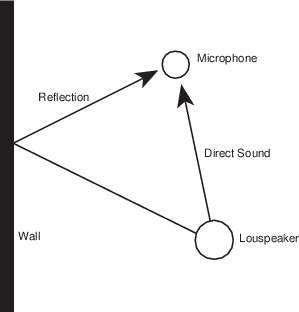
Let’s say that you wanted to measure something like the behaviour of a reflection off a wall, and how that compares to the sound coming directly to you from a sound source. As we’ll see in a later section, a wall might absorb some of the frequency components of your signal, so the reflection might not have as much high frequency energy (for example) as your direct sound. How can you measure this? Simple! You just get an omnidirectional loudspeaker and use that as your sound source. Put a microphone in the listening position and connect it to an oscilloscope so that you can see its output change in time. You produce an impulse (or as good an impulse as you can make without blowing up your loudspeaker) and look at the oscilloscope. You should see a spike when the direct sound arrives at the microphone, and another spike when the reflection arrives. If you have more walls, you’ll see lots of spikes coming in.
That collection of spikes that you’re looking at is a measure of the way the room responds (or behaves) when activated by an impulse – therefore we call it the room’s impulse response. In other words, it’s a measure of the change in the pressure over time when you make a click somewhere in the room.
As we’ll see in later sections, this impulse response is very useful and will be used repeatedly to measure the behaviour of all sorts of things like room acoustics, vibrating strings – even digital filters.
The theory explained in Section 3.1.17 that the combination of all frequencies results in a single click relies on an important point that we didn’t talk about – relative phase. The click can only happen if all of the phases of the harmonics are aligned properly – if not, then things tend to go awry... If we have all frequencies with random relative amplitude and phase, the result is noise in its various incarnations.
There is an official document defining different types of noise. The specifications for white, pink, blue and black noise are all found in The Federal Standard 1037C Telecommunications: Glossary of Telecommunication Terms. (I got the definitions from Rane’s online dictionary of audio terms at http://www.rane.com.)
White noise is defined as a noise that has equal amount of energy per frequency. This means that if you could measure the amount of energy between 100 Hz and 200 Hz it would equal the amount of energy between 1000 Hz and 1100 Hz. Because all frequencies have equal level, we call the noise white – just like light that contains all frequencies (colours) equally is white light.
This sounds “bright” to us because we hear pitch in octaves. 1 octave is a doubling of frequency, therefore 100 Hz – 200 Hz is an octave, but 1000 Hz – 2000 Hz (not 1000 Hz – 1100 Hz) is also an octave. Since white noise contains equal energy per Hz, there’s ten times a much energy in the 1 kHz octave than in the 100 Hz octave.
Pink noise is noise that has an equal amount of energy per octave. This means that there is less energy per Hz as you go up in frequency (in fact, there is a power loss of 50% (or a drop of 3.01 dB) each time you go up an octave)
This is used because it sounds relatively “equal” in distribution across frequency bands to us.
Another way of defining this noise is that the power of each frequency f is
proportional to 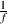 .
.
Blue noise is noise that is the opposite of pink noise in that it doubles the amount of power each time you go up 1 octave. You’ll virtally never see it (or hear it for that matter...).
Another way of defining this noise is that the power of each frequency f is proportional to the frequency.
Red Noise is used when pink noise isn’t low-end-heavy enough for you. For example, in
cases where you want to use noise to simulate road noise in the interior of a car,
then you want a lot of low-frequency information. You’ll also see it used in
oceanography. In the case of red noise, there is a 6.02 dB drop in power for every
increase in frequency of 1 octave. (In other words, the power is proportional to
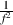 )
)
Purple Noise is to blue noise as red noise is to pink. It increases in power by 6.02 dB for every increase in frequency of 1 octave. (In other words, the power is proportional to f2.)
This is an odd case. It is essentially silence with the occasional randomly-spaced spike.
These definitions of noise are based on relative amounts of energy in frequency bands. However, you have to be careful with this kind of definition. Noise is not periodic, so at any given moment, you may not have the frequency content you expect. In order for the noise to have the spectral balance you expect, you have to measure for a long period of time – the longer you wait, the more accurate the measurement of the content.
What I have been avoiding is the fact that the various noise types don’t actually contain the spectral content that you think. More precisely, they have a defined probability of having a spectral content. For example, if you’re playing white noise, you have the same probability of getting an amount of energy between 100 Hz and 200 Hz as you are of getting the same energy between 1100 Hz and 1200 Hz. Both frequency ranges have the same bandwidth, therefore they have the same probability of having a given amount of energy. This does not necessarily mean that, if you measure for one second, they will in fact be equal – one might be more than the other.
Think of it as rolling two dice (make them different colours to keep them separate...) where each die is representative of the amount of energy in the two frequency ranges. On any given roll (any given measurement) one die might be higher than the other, or they might be equal... you never know until you roll. However, if you keep rolling and rolling, each time adding the amount that you rolled to all the other rolls for the same die, the two values will get closer and closer. The more rolls, the more likely they are to be equal. This is because both dice have the same probability.
We’ll talk more about this concept in a later section on probability density functions.
There is an obvious relationship between amplitude and distance – they are inversely proportional. That is to say, the farther away you get, the lower the amplitude. Why?
Let’s go back to throwing rocks into a lake. You throw in the rock and it produces a wave in the water. This wave can be considered as a manifestation of an energy transfer from the rock to the water. All of the energy is given to the wave from the rock at the moment of impact – after that, the wave theoretically maintains that energy.
The important thing to notice, though, is that the wave expands as it travels out into the lake. Its circumference gets bigger as it travels horizontally (as its radius gets bigger...) Therefore the wave is “longer” (if you’re measuring around the circumference). The total amount of energy in the wave, however, has not changed (actually it has gotten a little smaller due to friction, but we’re ignoring that effect...) therefore the same amount of energy has to be shared across a longer wavefront. This causes the height (and depth) of the wave to shrink as it expands.
What’s the mathematical relationship between the increasing circumference and the increasing radius? Well, the radius is travelling at the constant speed, determined by the density of the water and gravity and other things like the colour of your left shoe... We know from high school that the circumference is equal to the radius multiplied by about 6.28 (also known as 2π). The graph in Figure 3.14 shows the relationship between the radius and the circumference. You can see that the latter grows much more quickly than the former. What this means is that as the radius slowly expands out from the point of impact, the energy is getting shared between a “length” of the wave that is growing far faster (note that, if we double the radius, we double the circumference).
The same holds true with pressure waves expanding from a loudspeaker into a room. The only real difference is that the energy is expanding into 3 dimensions rather than 2, so the surface area of the spherical wavefront (the 3-D version of the circumference of the circular wave on the lake...) increases much more rapidly than the 2-dimensional counterpart. The equation used to find the surface of a sphere is 4πr2 where r is the radius. As you can see in Figure 3.15, the surface area of the sphere is already at 1200 units squared when the radius has only expanded to 10 units. The result of this in real life is that the energy appears to be dissipating at a rate of 6.02 dB per doubling of distance. (When we double the radius, we increase the surface area of the sphere fourfold so the intensity drops to 25% of the original level.) Of course, all of this assumes that the wavefront doesn’t hit anything like a wall or the floor or you...
Imagine that you’re suspended in infinite space with no walls, ceiling or floor anywhere in sight. If you make a noise, the wavefront of the sound is free to move away from you forever, without ever encountering any surface. No reflections or diffraction at all – forever. This space is a theoretical idea known as a free field because the wavefront is free to expand.
If you put a microphone in this free field, the wavefront from a single sound source would come from a single direction. This seems obvious, but I only mention it to compare with the next section.
For a visual analogy of what we’re talking about, imagine that you’re floating in space and the only thing you can see is a single star. There are at least three things that you’d notice about this odd situation. Firstly, the star doesn’t appear to be very bright, because most of its energy is going in a different direction than towards you. Secondly, you’d notice that everything but the star is very, very dark. Finally, you’d notice that shadows are very distinct and also very, very dark because there is no light bouncing back from anything to light up the backs of things.
Now imagine that you’re in the most reverberant room you’ve ever heard. You clap your hands and the reverb goes on until sometime next Tuesday. (If you’d like to hear what such as space sounds like, run out and buy a copy of the recording of Stuart Dempster and his crowd of trombonists playing in the Cistern Chapel in Seattle[Dempster, 1995] (... no, not the Sistene Chapel in The Vatican)) Anyways, if you were able to keep a record of every reflection in the reverb tail, keeping track of the direction it came from, you’d find that they come from everywhere. They don’t come from everywhere simultaneously – but if you wait long enough, you’ll get a wavefront from every possible direction at some time.
If we consider this in terms of probability, then we can say that, in this theoretical space, sound waves have an equal probability of coming from any direction at any given moment. This is essentially the definition of a diffuse field.
For a visual example of this, look out the window of a plane as you’re flying through a cloud on a really sunny day. The light from the sun bounces off of all the little particles in the cloud, so, from your perspective, it essentially comes from everywhere. This causes a couple of weird sensations. Firstly, there are no shadows – this is because the light is coming from everywhere so nothing can shadow anything else. Secondly, it is very difficult to determine distances. Unless you can see the wing of the plane, you have no idea how far away you’re actually able to see. This the same reason why people have car accidents in blinding snowstorms. They drive because they think they can see ahead much further than they’re really able to.
Note: This section is actually just a necessary preface to the following sections. If you already know the difference between potential energy and kinetic energy, feel free to skip this explanation.
Find a very lazy friend (preferably someone who doesn’t weigh very much) and put him on a playground swing. He’ll just sit there on the swing, which hangs by two ropes or chains, and he’ll just keep sitting there until someone gives them a push (he’s very lazy, remember?). This person has absolutely no energy. Then, you get behind him, and put your hands on his shoulders and start walking forwards, pushing him ahead of you. Then you stop.
So, you’re standing there, holding up your lazy friend who is sitting on a swing which is not yet swinging. You have put a lot of work into getting him all the way up in the air – in other words, you’ve expended a lot of energy while pushing him. However, that energy is not all lost... Rather than do all that work for nothing, what you’ve actually done is to transfer the work that you’ve done into your friend on the swing. He’s now sitting there in mid-air, full of potential to start swinging. In other words, he has potential energy – the energy is there, ready to make him swing back and forth, but it’s still only potentially useful because you haven’t released him yet.
So, once you get sick and tired of your friend complaining that he’s not having any fun (then again, you weren’t having any fun holding him up...) you let go and he starts moving back towards where he came from – downwards. As he gets closer and closer to the ground, he moves faster and faster. What is happening is that he’s gaining kinetic energy – the energy of movement (“kinetic” means “relating to motion”). The faster he moves, the more kinetic energy he has. What has happened in the process of him moving back to where he came from is that all of the potential energy you’ve put in him has been transferred into kinetic energy. When he’s at the bottom of the arc, closest to the ground, he is moving the fastest, and cannot move any lower. Therefore all of the potential energy has been converted to kinetic energy. (He no longer has the potential to go any faster – so he’s all out of potential energy.)
However, he does have inertia – this is the tendency for a body in motion to remain in motion. So, he passes the bottom of the arc and keeps moving in the same direction, still going away from the place where you released him. However, as he moves upwards, away from the ground, he starts slowing down, thereby losing kinetic energy. But, since he’s further away from the ground, he has the potential to come back, therefore his kinetic energy is being converted to potential energy.
As he swings back and forth, he is constantly transferring potential energy into kinetic energy and back again. In a perfect world, he would keep swinging forever, trading potential for kinetic energy. However, in the real world we have friction which causes his kinetic energy to be converted into heat. The higher the friction, the faster this conversion happens. So eventually, even with a little friction in the system, all of the kinetic energy will be converted to heat and lost, and he’ll stop swinging.
Get a dinner plate and hold it with two hands in front of you like youre holding the steering wheel of a car.
Without turning your plate, push it away from you, then pull it back towards you closer than where you started, then push it back out and so on. The top plot in Figure 3.16 shows the displacement of the plate relative to the resting position. A positive displacement means that the plate is further away from you than the resting position, a negative displacement means that its closer.
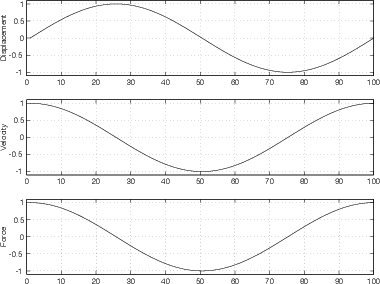
We can also think about the velocity of the plate. Velocity is a little like speed except that its smarter. Speed tells you how fast youre moving (how much distance youre traveling in an amount of time). Velocity tells you the same thing, but it also tells you in what direction youre moving. For example, if we say that positive velocity is forwards, then if youre going backwards, you must have negative velocity. Its possible in a car to have a velocity of -10 km/h, but you can never have a speed of -10 km/h. This is because speed is just distance travelled in time, and you cant move -10 km in an hour. (You would also have difficulty trying to move 10 km in negative 1 hour...) So, back to the plate. If we graph the velocity of the plate in relation to its displacement well get the second plot in Figure 3.16.
Now get into a large swimming pool holding your plate and do the same thing, pushing and pulling the plate further away from and closer to you. Think about how hard it is to push and pull the plate in the water. This is obviously because of the the fact that, in pushing the plate, you have to push the water out of the way. If I asked you to get in a swimming pool full of oil, it would be harder still to push and pull the plate. In air, its quite easy.
However, Im not really concerned at this point about how hard it is to push and pull the plate. Were more interested in the specifics of when you push and when you pull.
Lets go back to the swimming pool, and assume that youve already been pushing and pulling your plate for a while. People have given up staring at you and gone back to their water-volleyball game, and youre left alone to concentrate. As you move the plate away from you, no matter where the plate is, youre pushing. If youre moving the plate towards you, youre pulling. (This may seem obvious at the moment, but you have to bear with me... Youll see in a moment why Im stating the stupid...) Theres a graph showing this relationship in Figure 3.16.
What does Figure 3.16 tell us? We can see that the effort that youre putting into your plate is in phase with the velocity of the plate. If the velocity is positive (in other words, if the plate is moving away from you) then youre pushing it. If the velocity is negative (if the plate is moving towards you) then youre pulling it. Youll also note that if your effort is proportional to the plates velocity (in other words, you have to work harder to move the plate faster). You should also note that your effort (and the plates velocity) is 90∘ out of phase with the plates displacement. When the displacement is at maximum (when the plate is farthest away), the plates velocity and your effort level are zero. The same is true when the displacement is minimum (the plate is nearest). When the displacement is zero (the plate is at the starting point) then the velocity and your effort are at a maximum (or a minimum, depending on direction).
Lets go back briefly to the swimming pool filled with oil. All of the discussion of whether youre pushing or pulling will all hold to be true. The only thing that will change is how hard you have to push and pull. This is because oil is thicker and therefore harder to move than water.
Okay, okay... that previous section in the swimming pool might have seems like a total waste of your time. However, hopefully, this section will change your mind.
Take your dinner plate from the previous section and get out of the pool. Find a large, concrete wall and attach a spring to it. Then attach your plate to the other end of the spring.
Now hold your dinner plate the way you did in the previous section and push and pull it, moving it back and forth the way you did in the pool. The displacement and the velocity of the plate are the same as they were in the pool, represented by the top two graphs in Figure 3.17. However, if youre paying attention, youll notice that your behaviour has changed.
When the plate is moving away from you (therefore having an increasing positive displacement), youre pushing it. So far so good. Then you get as far away as you can get with the plate. The displacement is at a maximum and the velocity is zero, just like in the pool. However, unlike when youre in the pool, youre still pushing. If you stopped pushing, the plate would spring back – you have to push just to keep the plate that far away because the spring is pushing back towards you. As the plate comes back towards where it started, youre still pushing. This is a strange situation – youre pushing, but the plate is moving towards you – but you have to push against the spring. When the plate returns to its starting point, you neither push nor pull because the spring is holding the plate there for you. Then, as you move the plate towards you, you pull on it until its as close as its going to get. The displacement is at a minimum, the velocity is zero, and youre pulling as hard as you can. As the plate moves back out away from you again, its displacement returns to zero, its velocity is positive, but youre still pushing.
All of this is shown in Figure 3.17.
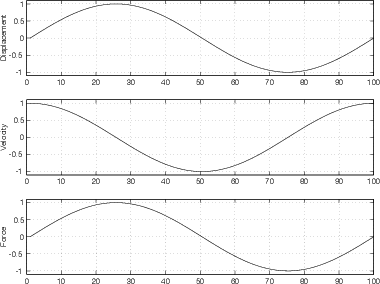
The interesting thing is to compare Figure 3.16 to Figure 3.17. Notice that the relationship between the plates displacement and its velocity has not changed. Theyre always 90∘ out of phase. However, what changes is your effort. In the case of the swimming pool (resistance), your effort was in phase with the velocity. In the case of the spring (capcitance), your effort was in phase with the displacement. Most importantly, your effort in the swimming pool is 90∘ out of phase with your effort with the spring.
The other important thing to note here was the issue of conservation of energy (time to think back to potential and kinetic energy). In the case of the pool, your energy was directly converted into kinetic energy – you push and the plate moves. This is why the velocity and your effort in the pool are in phase. If your effort goes up, the velocity (and therefore the kinetic energy) of the plate goes up. However, if you stop pushing, the plate stops moving. You are not storing any potential energy in the plate.
In the case of the spring, you push and put potential energy into the spring. The harder you push, the more energy the spring has to push back. This is why your effort is 90∘ out of phase with the velocity. Its because youre not making the plate move. Youre putting potential energy into the spring and its moving the plate.
One last time... lets take the plate, no swimming pool, no spring attached to a concrete wall... Just a plate. However, well make the plate really heavy. Also, lets ignore the fact that its hard to hold up because its so heavy.
Once again, well move the plate back and forth, pushing and pulling. Once again, we can see that the plates displacement and its velocity are the same as they were in the swimming pool and with the spring attached. However, once again, we have to think about when were pushing and when were pulling.
Once again, lets assume that youve already started pushing and pulling – you dont have to get the whole process started. Youve had the plate as close to you as it gets, and youve pushed it away until its back to the starting point. Now, as the plate is moving forwards, you have to slow it down, otherwise itll just keep going away because its so heavy. So, as soon as the plate gets to the starting point, although its moving away from you, youre pulling on it, slowing it down until it gets to its maximum displacement. When it gets there, you keep pulling so that it starts moving towards you. However, when it returns to its starting point, you have to starts pushing, otherwise this heavy plate is going to hit you in the chest. plate moves towards you, youre pushing.
This behaviour of displacement, velocity and your effort are shown in Figure 3.18.

There are three things that are interesting to note here. The first is that, just like the plate on the spring, your effort in this case is 90∘ out of phase with your effort in the swimming pool. The second is that your effort in this case is 180∘ out of phase with your effort in the case of the plate on a spring (when you were pulling on the spring, youre pushing on the heavy plate and vice versa). Finally, you should be able to decipher that youre still playing with the relationship between kinetic and potential energy in this case of the heavy plate (sounds like a Hardy Boys Mystery book – The Case of the Heavy Plate). Ill let you figure this one out.
So, what do these three dinner plates have to do with the concepts of acoustical and mechanical resistance, capacitance and inductance? Well, lets think about a loudspeaker driver – the woofer, for example. It looks a bit like a dinner plate, and if your speakers are big, its about the same size. The woofer is pushed in and out by the amplifier (well talk later about the details of this miraculous transformation of energy).
Mechanical and Acoustical Resistance
When the woofer moves in and out, there are parts of it that have to stretch (these are called the loudspeakers suspension - well discuss the details of this in the section on Loudspeaker construction). When they stretch, some of the energy is lost to friction – you put energy in, and you lose it to heat. This is exactly the same as the energy you lose pushing water out of the way with your dinner plate. This is mechanical resistance – the mechanical properties of the woofer itself cause you to lose energy as heat when you try to move it.
At the same time, you are pushing some air molecules out of the way, just like you were pushing water out of the way. This is more energy lost as the molecules bump against each other, generating heat (albeit very small amounts of it...). This is acoustical resistance – the acoustical properties of the air next to the loudspeaker result in energy lost as heat when you try to move it.
Mechanical and Acoustic Capacitance
The suspension of the woofer is probably comprised of two things – both are circular stretchy rings that keep the woofer centered, and pull it back to its resting position. These are exactly like the spring between the dinner plate and the concrete wall. So, the suspension springiness gives you a mechanical capacitance in which potential energy is stored.
At the same time, the air outside the woofer is a little springy. This is a bit of an odd concept, but think of a woofer in a sealed cabinet, sitting in a sealed room. If the woofer pushes out of the cabinet, then it is reducing the air pressure inside the cabinet and increasing the air pressure inside the room. That means that the rooms air pressure is trying to push the woofer back into the cabinet (and the cabinets air pressure is trying to pull it back in at the same time). This, again, is the same as your plate on a spring and is known as acoustic capacitance.
Mechanical and Acoustic Inductance
Finally, the woofer, just like your heavy plate, has some mass and therefore some inertia. So, once your amplifier starts moving it outwards, the woofer wants to keep moving outwards, and something has to stop it. This is known as mechanical inductance.
The air next to the woofer also has some mass and inertia, and it also wants to keep moving in the direction its already headed in. When the woofer stops moving outwards, the air next to it wants to pull it just a little further, resulting in acoustical inductance.
There are some minor points that have to be addressed here before we move on...
Firstly, one important thing to note here is that the behaviour of mechanical and acoustical resistance are identical. This is also true for mechanical and acoustic capacitance. Finally, its true for mechanical and acoustic inductance. The thing that makes, say, capacitance mechanical or acoustic is where the capacitance actually occurs. If its in the device itself (like the loudspeaker driver, for example) then its mechanical. If the capacitance is a property of the medium (like the air) around the device, then its acoustic.
Secondly we have the issue of what reactance is. This is actually pretty easy. Mechanical reactance is the combination of mechanical capacitance and mechanical inductance. Similarly, acoustical reactance is the combination of acoustic capacitance and acoustic inductance. The reason these are grouped is because they are both different from resistance. As we saw above, energy put into a reactive system is conserved – this is difference from energy put into a resistive system which is lost.
Finally, we have the issue of what impedance is. Again, this is easy. Mechanical impedance is the combination of mechanical resistance and mechanical reactance. Similarly, acoustical impedance is the combination of acoustical resistance and acoustical reactance.
Heres where things get really interesting if youre like me and youre curious about how things are the same instead of how theyre different...
An acoustic resistor (like the water in the swimming pool) just causes you to lose energy. This is exactly like a resistor in an electrical circuit which converts current into heat.
An acoustic reactor (the plate on the spring) causes you to work harder when youre moving slowly (think about pushing the plate away and then stopping...). The faster you move (the higher the frequency) the less you have to work (because you dont have to hold the spring in a compression for very long). This is the same as a capacitor. The lower the frequency, the harder it is to get signal through it.
Once you get the mechanical reactor (the heavy plate) moving, you dont have to do anything. It keeps going in that direction. The faster you try to move it back and forth (the higher the frequency) the harder you have to work to overcome inertia. This the same as an electrical inductor which allows DC (0 Hz) though but doesnt allow high frequencies through it.
Since these three things, an acoustical resistor, an acoustical reactor and a mechanical reactor all have electrical equivalents, we can draw an “acoustical circuit” using electrical analogies. Well get into this in a later section.
Before we move on to look at how rooms behave when you make noise in them, we have to begin by looking a little more closely at the concept of acoustical impedance. Earlier, we saw how sound is transmitted through air by moving molecules bumping up against each other. One air molecule moves and therefore moves the air molecules sitting next to it. In other words, were talking about energy being transferred from one molecule to another. The ease with which this energy is transferred between molecules is measured by the difference in the acoustical impedances of the two molecules. Ill explain.
Weve already seen that sound is essentially a change in pressure over time. If we have a static barometric pressure and then we apply a new pressure to the air molecules, then we change their displacement (we move them) and create a molecular velocity. So far, weve looked at the relationship between the displacement and the velocity of the air molecules, but we havent looked at how both of these relate to the pressure applied to get the whole thing moving in the first place. In the case of a pendulum (a weight hanging on the end of a stick thats free to swing back and forth), the greater the force applied to it, the more it moves and the faster it will go – the higher the pressure, the greater the displacement and the higher the velocity. The same is true of the air molecules – the higher the pressure we apply, the greater the displacement and the higher the velocity. However, the one thing were ignoring is how hard it is to get the pendulum (or the molecules) moving. If we apply the same force to two difference pendulums, one light one and one heavy one, then well get two difference maximum displacements and velocities as a result. Essentially, the heavier pendulum is harder to move, so we dont move it as fast or as far.
The issue that were now discussing is how much the pendulum impedes your attempts to move it. The same is true of molecules moved by a sound wave. Air molecules are like a light pendulum – theyre relatively easy to move. On the other hand, if we were to put a loudspeaker in poured concrete and play a tune, it would be much harder for the speaker to move the concrete molecules – therefore they wouldnt move as far with the same pressure applied by the loudspeaker. There would still be a sound wave going through the concrete (just as the heavy pendulum would move – just not very much) but it wouldnt be very loud.
The measurement of how much velocity results from a given amount of pressure is an indication of how hard it is to move the molecules – in other words, how much the molecules impede the transfer of energy. The higher the impedance, the lower the velocity for a given amount of pressure. This can be seen in Equation 3.12 which is true only for the free field situation.
 | (3.12) |
where z is the acoustical impedance in acoustic ohms (abbreviated Ω), p is the acoustic pressure and u is the particle velocity. Note that acoustical impedance can also be measured in Newton-seconds per cubic metre or N⋅ s / m3.
As you can see in this equation, z is proportional to p and inversely proportional to u. This means that if the impedance goes up and the pressure stays the same, then the velocity will go down.
In the specific case of unbounded plane waves (waves with a straight wavefront – not curved like the ones weve been discussing so far), this ratio is also equal to the product of the volume density of the medium, ρo and the speed of wave propogation c as is shown in Equation 3.13[]. This value zo is known as the specific acoustical impedance or characteristic impedance of the medium.
 | (3.13) |
where ρo is the volume density (or just the density) of the propagating medium in kg/m3 and c is the speed of sound in the medium in m/s.
So far, weve looked at a number of different ways to measure the level of sound. Weve seen the pressure, the particle displacement and velocity and some associated measurements like the SPL. These are all good ways to get an idea of how loud a sound is at a specific point in space, but they are all limited to that one point. All of these measurements tell you how loud a sound is at the point of the receiver, but they dont tell you much about how loud the sound source itself is. If this doesnt sound logical, think about the light radiated from a light bulb – if you measure that light from a distance, you can only tell how bright the light is where you measure it, you cant tell the wattage of the bulb (a measure of how powerful it is).
Weve already seen that the particle velocity is proportional to the pressure applied to the particles by the sound source. The higher the pressure, the greater the velocity. However, weve also seen that, the greater the acoustical impedance, the lower the particle velocity for the same amount of pressure. This means that, if we have a medium with a higher acoustical impedance, well have to apply more pressure to get the same particle velocity as we would with a lower impedance. Think about the pendulums again – if we have a heavy and a light one and we want them to have the same velocity, well have to push harder on the heavy one to get it to move as fast as the light one. In other words, well have to do more work to get the heavy one to move as fast.
Scientists typically dont like work – otherwise they would have gotten a job in construction instead... As a result, they dont talk about it much either. Instead they talk about how much energy they put into something using the word power. The more power you have in a device, the more it can do. This can be seen from day-to-day in the way light bulbs are rated. The amount of energy they emit (how much light and heat they give off) is expressed in how much power they use when theyre turned on. This electrical power rating (expressed in Watts) is discussed in Section ??.
We saw in that section that the amount of power used by a device is equal to the product (the multiplication) of the voltage (the pressure) and the current (the particle velocity). In the case of acoustics, the amount of acoustic power that is emitted by the sound source is equal to the product of the square of the sound pressure level and a total area, divided by the acoustical impedance of the medium. In other words,
 | (3.14) |
where Pac is the acoustic power in acoustic Watts, p is the sound pressure in Pa, A is the area in m2 and z is the acoustical impedance in N⋅s / m3.
So, for example, in the case of a spherically propagating sound wave as would come from an omnidirectional sound source in a free field, you measure the sound pressure at a given distance from the sound source. You determine the total area of the surface area of the sphere around the sound source on which you did the measurement (calculated using the radius of the sphere – the distance from the sound source to the measurement point). You can probably look up the impedance of the air in a book like this one, and from all that you can calculate the total acoustic power radiated from the sound source.
Therefore the acoustic power calculated from a measurement at a specific point in space is proportional to the square of the acoustic pressure. Remember that the change in pressure is a result of energy you put in – you put power into the system and you get a change in power as an output.
This relationship between acoustic power and acoustic pressure is moderately useful in that it gives us an idea of how much energy is being used to move a measurement device (like a microphone diaphragm), but it still has a couple of problems. Firstly, so far it is still a measurement of a single point in space, so we can only estimate the total power, not the total power actually radiated by the sound source (because so far, weve only assumed that the wavefront is spherical). Another problem with power measurements is that they cant give you a negative value. This is because a positive pressure produces a positive velocity and when the two are multiplied we get a positive power. A negative pressure multiplied by a negative velocity also equals a positive power. This really makes intuitive sense since its impossible to have a negative amount of energy, which is why we need power and pressure measurements in many cases – we need the latter to find out whats going on on the negative side of the stasis pressure.
The really important thing to remember about acoustic power is that, although we calculated it using a single measurement in the example above, it is independent of the measurement location. The acoustic power is a total amount of energy radiated by a source over all directions. So, if you measure from difference places, the total acoustic power emitted by the source doesnt change. A loudspeaker is putting the same amount of power into a room regardless of where you measure it.
 | (3.15) |
where Pac is the acoustic power in acoustic Watts, ξ is the particle displacement in metres, ω is the angular frequency in radians per second, z is the acoustical impedance in N⋅s/m3, and A is the area in m2.
 | (3.16) |
where Pac is the acoustic power in acoustic Watts, u is the particle velocity in m/s, z is the acoustical impedance in N⋅s/m3, and A is the area in m2.
 | (3.17) |
where Pac is the acoustic power in acoustic Watts, a is the particle acceleration in m/s2, z is the acoustical impedance in N⋅s/m3, A is the area in m2 and ω is the angular frequency in radians per second.
 | (3.18) |
where Pac is the acoustic power in acoustic Watts, p is the sound pressure in Pascals, A is the area in m2 and z is the acoustical impedance in N⋅s/m3.
 | (3.19) |
where Pac is the acoustic power in acoustic Watts, E is the sound energy density in W⋅s/m3, c is the speed of sound in m/s, and A is the area in m2.
 | (3.20) |
where Pac is the acoustic power in acoustic Watts, I is the sound intensity in W/m2 and A is the area in m2.
All of these equations are from [wik, ].
In theory, we can think of the sound power contained in an entire spherical surface surrounding a sound source. In reality, we cannot measure this, because we dont have an infinite number of infinitely small microphones to measure that entire surface. Microphones for measuring acoustic fields are pretty small, with diameters on the order of millimeters, but theyre not infinitely small. As a result, if we oversimplify a little bit for now, the microphone is giving us an output which is essentially the sum of all of the pressures applied to its diaphragm. If the face of the diaphragm is perpendicular to the direction of travel of the wavefront, then we can say that the microphone is measuring the acoustic intensity of the sound wave.
Huh?
Well, the intensity of a sound wave is the measure of all of the sound power distributed over a given area that is normal (perpendicular) to the direction of propagation. For example, lets think about a sound wave as a sphere expanding outwards from the sound source. When the sphere is at the sound source, it has the same amount of power as was radiated by the source, all packed into a small surface area. If we ignore any absorption in the air, as the sphere expands (because the wavefront moves away from the sound source in all directions) the same power is contained in the bigger surface area. Although the sphere gets bigger over time because its radius increases, the total power contained in it never changes.
If we did the same thought experiment, but only considered an angular slice of the sphere – say 45∘ by 45∘, then the same rule would hold true. As the sphere expands, the amount of power contained in the 45∘ by 45∘ slice would remain the same, even though its total surface area of that “square” on the spheres surface would increase.
Now, lets think of it a difference way. Instead of thinking of the whole sphere, or an angular slice of it, lets think about a fixed surface area such as 1 cm2 on the sphere. As the wavefront moves away from the sound source and the sphere expands, the fixed surface area becomes a smaller and smaller component of the total surface area of the sphere. Since the total power distributed over the sphere doesnt change, then the amount of power contained in our little 1 cm2 gets less and less, proportional to the ratio of the area to the total surface area of the sphere.
If the surface area that were talking about is part of the sphere expanding from the sound source (in other words, if its perpendicular to the direction of propagation of the wavefront) then the total sum of power in that area is what is called the sound intensity.
This is why sound appears to get quieter as we move further away from the sound source. Since your eardrum doesnt change in surface area, as you get further from a sound source, it has less intensity – there is less total sound power on the surface of your eardrum because your eardrum is smaller compared to the size of the sphere radiating from the source.
The sound intensity can be calculated if you know the sound power, Pac and the surface area, A, of a spherical wavefront with a radius of r, using Equation 3.21[wik, ].
 | (3.21) |
where I is the sound intensity in W/m2 and Pac is the acoustic power in acoustic Watts.
Get about 20 of your closest friends together and stand, single file in a line. Everybody has already agreed to not get in a fight over this one... Each person puts their hands on the shoulders of the person in front of them. The deal is that, if the person behind you pushes you forward, you push the person ahead of you with the same force as you you were pushed. One last thing: get the person at the front of the line to put their hands on a concrete wall.
The person at the back of the line pushes the person in front of him, and that person, in turn, pushes the person in front of her and so on and so on. So, each person in the line is falling forward by as much as they were pushed. Finally, the person at the front of the line gets pushed and pushes back against the concrete wall. As a result, she falls backwards, pushing the person behind her backward who falls back and pushes the person behind him backwards and so on until we get back to the back of the line.
There are a number of different things to notice here:
Now, repeat this whole process, but have the person at the front of the line stand in an open doorway instead of putting her hands on a concrete wall. The person at the back of the line pushes the person in front who pushes the person in front and so on until the front person is pushed forward. Because she has nothing to push against, she winds up falling forward. This pulls the person behind her forwards who pulls the person behind him forwards and so on.
The points to pay attention to here are:
Why have I drawn this picture for you?
Replace each person in the line with an air molecule. When you push a molecule forward, it pushes the adjacent molecule in the same direction which continues the same chain reaction. Notice here that each molecule can push its adjacent molecule easily – in fact, there is nothing at all stopping it from moving forwards and pushing.
Eventually, if we get to the last molecule in the line and it’s up against a concrete wall (or at least something that’s harder to move than another air molecule) then it winds up pushing back against the molecule behind it and so on. So, we pushed an air molecule forwards, but after the chain reaction, it gets pushed back towards us in the opposite direction.
If, however, the molecule down at the end is standing in the equivalent of an open doorway, then it falls out, pulling the molecule behind it int he same direction. We pushed the first molecule forward, and eventually, it gets pulled forwards by the molecule in front.
To oversimplify a little bit, what we’re really talking about here is the behaviour of a reflection as it relates to a change in acoustical impedance. This is basically a measure of how easily an air molecule can push or pull whatever is next to it (actually, how much the movement is restriced or impeded). If it’s another air molecule, then it can probably push as easily as it was pushed. If it’s concrete, then it can’t push as easily. The higher the acoustical impedance, the harder it is to move the molecule. This was discussed in more detail in the previous chapter.
As we change materials, we change the acoustical impedance, however, we can also change the acoustical impedance of a material by changing its environment. For example, it is harder to push air molecules when they’re in a tube than when they’re in a free field, therefore, the acoustical impedance of air inside the tube is higher than it is in the outside world.
How do we measure how hard it is to move something? Well, let’s think about trying to push a car, let’s say. You push on the car with an amount of pressure, and the car moves forward at a certain speed. If you push wheelbarrow with the same pressure, it will move faster (assuming that your wheelbarrow is easier to push than your car...) This relationship is used to determine the acoustical impedance of a given medium. Take a look at Equation 3.22.
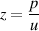 | (3.22) |
where z is the acoustical impedance of the material measured in N⋅s/m3 (Newton seconds per meter cubed)2 , p is the pressure applied to the molecules in the medium in Pascals and u is the velocity of the air molecules in m/s.
This equation tells us that if you have a wavefront with the same pressure in two different substances with two different acoustical impedances, then the particle velocity will be higher in the material with the lower impedance.
The idea of an acoustic reflection probably doesn’t come as a surprise. If a sound wave in air hits a hard surface like a smooth concrete wall, then it reflects off the wall and bounces back. The questions are, why does it reflect, and how?
An acoustic reflection occurs whenever you have a change in acoustical impedance. An easy way to think of this is to consider the acoustical impedance change as a gatekeeper. The difference in the acoustical impedances of two different media (such as air and concrete) tells us how much pressure is allowed to pass through the “gate” into the second medium. The pressure that isn’t allowed through is reflected back in the opposite direction. This is most easily seen using a picture.

Figure 3.19 shows two different media – let’s say air (the light gray area) and concrete (the dark gray) for now. If we send a pressure wave through the air towards the concrete (arrow pi for incident pressure wave), when the wavefront meets the boundary between the two substances, it sees a change in impedance. That change allows some of the pressure wave through to the second medium (pt for transmitted pressure wave) and the remainder bounces back into the air (pr for reflected pressure wave). This is shown in the Equation 3.23
 | (3.23) |
This makes sense since the energy we put into the whole system is in wave pi which is split into pt and pr. So what we’re saying is that the incidence pressure is equal to the sum of the two resulting pressures, but one of them (pr) is going backwards. If you want to think on a really small, local scale, then this also means that the molecule sitting right at the border of the two substances has equal pressures applied to it from both sides, because of Equation 3.23. This keeps Sir Issac Newton happy – every action having an equal and opposite reaction and all...
Let’s also look at the velocity of the air molecules. The velocity of the molecules in the wavefront headed towards the boundary is equal to the sum of the velocities of the reflected and the transmitted waves. This relationship is described in the equation
 | (3.24) |
therefore
 | (3.25) |
An interesting thing happens here. We can use Equation 3.22 to link acoustical impedance to the pressure and particle velocity in the each of the media as is shown in Equations 3.26 and 3.27.
 | (3.26) |
and
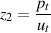 | (3.27) |
Now, let’s combine Equations 3.23 and 3.25 as shown below.
We can then use Equations 3.26 and 3.27 to make some replacements for ui, ut and ur...
and finally...
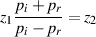 | (3.39) |
Equation 3.39 is pretty important because it tells us some intuitive things about the relationship between the impedance boundary and the behaviour of the reflected sound wave (and therefore the transmitted one as well).
Let’s take three different conditions and see what happens.
Example 1 – Matching acoustical impedances: If z2 = z1 (in simpler terms, if the
acoustical impedance of the second medium is the same as the first one) then this must
mean that  = 1. If this is true, then that, in turn, means that pi+pr = pi-pr
which must mean that pr = 0. Therefore, there is no reflected pressure wave. So,
we can conclude that if the impedances of the two media are the same, then
there’s no reflection. Intuitively, this makes sense. For example, you would not
expect to see a reflection from the middle of a room where there is nothing but
air.
= 1. If this is true, then that, in turn, means that pi+pr = pi-pr
which must mean that pr = 0. Therefore, there is no reflected pressure wave. So,
we can conclude that if the impedances of the two media are the same, then
there’s no reflection. Intuitively, this makes sense. For example, you would not
expect to see a reflection from the middle of a room where there is nothing but
air.
Example 2 – Impedance 2 is higher than impedance 1: If z2 > z1 (for example, if
the pressure wave is going from air to concrete) then this must mean that 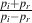 > 1. This,
in turn means that pi+pr > pi-pr, which means that pr > -pr which means that pr is
positive. This means that the pressure reflected off this boundary will have the same
polarity as the incident wave. In simpler terms: if we send a high pressure at
the concrete wall, we’ll get a high pressure back. If we send a low pressure,
we’ll get a low pressure reflection. This is the same as we saw when you were
pushing your classmates around at the beginning of this section. If the person
at the front of the line was leaning against the wall, if you pushed, you were
pushed.
> 1. This,
in turn means that pi+pr > pi-pr, which means that pr > -pr which means that pr is
positive. This means that the pressure reflected off this boundary will have the same
polarity as the incident wave. In simpler terms: if we send a high pressure at
the concrete wall, we’ll get a high pressure back. If we send a low pressure,
we’ll get a low pressure reflection. This is the same as we saw when you were
pushing your classmates around at the beginning of this section. If the person
at the front of the line was leaning against the wall, if you pushed, you were
pushed.
Example 3 – Impedance 2 is lower than impedance 1: If z2 < z1 (for example, if
the pressure wave is going from water to air) then this must mean that  < 1. This, in
turn means that pi+pr < pi-pr, which means that pr < -pr which means that pr is
negative. This means that the pressure reflected off this boundary will have the opposite
polarity of the incident wave. In simpler terms: if we send a high pressure at the surface
of the water from under water, we’ll get a low pressure back. If we send a low pressure,
we’ll get a high pressure reflection. This is the same as we saw when you were
pushing your classmates around at the beginning of this section. If the person
at the front of the line was leaning against nothing, if you pushed, you were
pulled.
< 1. This, in
turn means that pi+pr < pi-pr, which means that pr < -pr which means that pr is
negative. This means that the pressure reflected off this boundary will have the opposite
polarity of the incident wave. In simpler terms: if we send a high pressure at the surface
of the water from under water, we’ll get a low pressure back. If we send a low pressure,
we’ll get a high pressure reflection. This is the same as we saw when you were
pushing your classmates around at the beginning of this section. If the person
at the front of the line was leaning against nothing, if you pushed, you were
pulled.
The ratios of reflected and transmitted pressures to the incident pressure are frequently expressed as the pressure reflection coefficient, R , and pressure transmission coefficient, T , shown in Equations 3.40 and 3.41 [Kinsler and Frey, 1982].
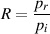 | (3.40) |
 | (3.41) |
What use are these? Well, let’s say that you have a sound wave hitting a wall with a
reflection coefficient of R = 1. This then means that pr = pi, which is a mathematical
way of saying that all of the energy in the sound wave will bounce back off the wall. Also
because of Equation 3.23, this also means that none of the sound will be transmitted into
the wall (because pt = 0 and therefore T = 0), so you don’t get angry neighbours. On the
other hand, if R = 0.5, then pr =  which in turn means that pr =
which in turn means that pr =  (and therefore
that T = 0.5) and you might be sending some sound next door... although we
would have to do a little more math to really decide whether that was indeed the
case.
(and therefore
that T = 0.5) and you might be sending some sound next door... although we
would have to do a little more math to really decide whether that was indeed the
case.
Note that the pressure reflection coefficient can either be a positive number of a negative number. If R is a positive number then the pressure of the reflection will have the same polarity as the incident wave, however, if R is negative, then the pressures of the incident and reflected waves will have opposite polarities. This is the same information as we saw when we evaluated the three Examples explaining Equation 3.39.
So far we have assumed that the media we’re talking about that are being used to transmit the sound, whether air or something else, are adiabatic. This is a fancy word that means that they don’t convert any of the sound power into heat. This, unfortunately, is not the case for any substance. All sound transmission media will cause some of the energy in the sound wave to be converted into heat, and therefore it will appear that the substance has absorbed some of the sound. The amount of absorption depends on the characteristics of the material, but a good rule of thumb is that when the material is made of a lot of changes in density, then you’re going to get more absorption than in a material with a constant density. For example, air has pretty much the same density all over a room, therefore you don’t get much sound energy absorbed by air. Steel has a very constant density, so you won’t get much absorption of a sound wave travelling through it. Fibreglas insulation, on the other hand is made up of millions of bits of glass and pockets of air, resulting in a very large number of big changes in acoustical impedance through the material. The result is that the insulation converts most of the sound energy into heat. (This is also what makes it a good insulator for heat in the first place.) A good illustration of this is a rumour (probably an urban myth) that I once heard about an experiment that was done in Sweden some years ago. Apparently, someone tried to measure the sound pressure level of a jet engine in a large anechoic chamber which is a room that is covered in absorbent material so that there are no reflections off any of the walls. Of course, since the walls are absorbent, then this means that they convert sound into heat. The sound of the jet engine was so loud that it caused the absorptive panels to melt! Remember that this was not because the engine made heat, but because it made a ?? loud noise.
The absorption coefficient α of a given material is defined as the ratio of the intensity of the absorbed sound to the intensity of the sound directed at the surface of the material as is shown in Equation 3.42.
 | (3.42) |
where α is the absorption coefficient, Ia is the intensity of the sound that is absorbed in W/m2 and Ii is the intensity of the incident sound in W/m2
Usually, a material’s absorption coefficient, α is found by measuring the amount of energy reflected off it and comparing that to the energy in the wave you directed at it. Unfortunately, however, this is not really as easy as it first sounds. One possible way of doing this is to put the material at the end of a pipe. The other end of the pipe is a loudspeaker emitting a single frequency. You put a very small microphone somewhere in the pipe between the two ends. If the material that you’re measuring is completely absorptive (α = 1), then none of the signal will bounce off the far end of the pipe. The less absorptive the material, the more energy will be bounced back into the pipe, and the higher the sound pressure at the microphone. Warning! This is an overly-simplified description of a measurement done using an impedance tube. For more (and better) information on how this is really done, check out www.gmi.edu/~drussell/GMI-Acoustics/Absorption.html
In practice, for lower frequencies, no energy will be lost in the propagation through air. However, for shorter wavelengths, there is an increasing attenuation due to viscothermal losses (losses due to energy being converted into heat) in the medium. These losses in air are on the order of 0.1 dB per metre at 10 kHz as is shown in Figure 3.20.

Usually, we can ignore this effect, since we’re usually pretty close to sound sources. The only times that you might want to consider this is when the sound has travelled a very long distance which, in practice, means either a sound source that’s really far away outdoors, or a reflection that has bounced around a big room a lot before it finally gets to the listening position.
Let’s stand in front of a perfectly reflective wall in an otherwise anechoic environment. We’ll put an omnidirectional loudspeaker and a microphone somewhere relatively near each other and near the wall. Let’s say, for the sake of argument, that the loudspeaker and the microphone are 34.4 cm away from each other and the total distance from the loudspeaker to the wall and back to the microphone (the path of the reflected sound) is 68.8 cm. This is shown in Figure 3.21
Now we’ll connect a sine wave generator to the loudspeaker and look at the output of the microphone on an oscilloscope. We’ll start by putting out a 1 Hz wave from the loudspeaker. The wavefront will radiate away from the loudspeaker in all directions (including the directions towards the microphone and towards the wall). One millisecond after the wavefront was emitted by the loudspeaker, it will reach the microphone. One millisecond later, the reflection off the wall will arrive at the microphone. This means that there is a difference of 1 ms between the time of arrival of the direct sound and of the early reflection off the wall. In real life, we would also know that the reflection off the wall will be one half the amplitude of the direct sound because the wavefront had to travel twice as far to get to the microphone. (Don’t forget that the wall is perfectly reflective, so there is no loss on the reflection itself.) However, we’re going to pretend for the first half of this section that sound does not decay with distance. We’ll come back to this issue and correct for it later.
Question: What is the phase difference between the direct sound and the reflection off the wall? Well, we know that the difference in the time of arrival is 1 ms. We can therefore calculate this as a phase difference using the frequency. The loudspeaker is putting out 1 Hz, which is 360∘ per second (or 2 π radians per second). There is a 0.001 s difference in the time of arrival, so the phase difference is 0.001 * 360∘ = 0.36∘. This is a very small difference. In fact, it’s so small that we can assume that the difference is 0. Therefore, the wave arriving as the direct sound is in phase with the wave arriving as the reflection. Therefore, these two waves add constructively at the microphone to make a sine wave that is twice as loud as either one of them individually (we’re pretending that sound doesn’t decay with distance, remember?).
Now, we’ll increase the frequency of the sine wave generator. As we get higher and higher in frequency, we are saying that we have more and more waves per second coming from the loudspeaker. This means that we have more degrees of phase per second coming from the loudspeaker. For example, if the frequency is 100 Hz, then we have 360∘ * 100 Hz = 36000∘ per second. the time difference between the arrival of the direct and reflected sounds is still 1 ms, however, since we are now at 100 Hz, that means that there is a 36000∘ * 0.001 = 36∘ difference in phase between the two. The higher in frequency we go, the larger the phase difference. This is because the difference in the time of arrival does not change.
Let’s move all the way up to a 500 Hz sine wave. Now the phase difference at the microphone between the direct and the reflected sound is 180∘ (you can do the math yourself...). This means that we will get destructive interference between the two, and there will be no output from the microphone. Essentially, the reflection is “cancelling” the direct sound.
Keep going up in frequency to 1 kHz. At this frequency, the phase difference is 360∘, so we get back to having perfect constructive interference and two times the output again, just like we did at 1 Hz.
At 1.5 kHz, we’ll get no output, at 2 kHz we get a boost and so on and so on. Notice that these frequencies are just multiples of the first cancellation frequency at 500 Hz.
If we graph this response of the output of the microphone vs. frequency and we draw the frequency scale linearly, it will look like Figure 3.22. (Interestingly, you might notice that the shape of this plot is a cosine curve with a DC offset.)
If you squint your eyes just right, the shape of this curve looks like a comb. And since, the effect at the microphone is as if we had done something to the original sound (we did do something to the original sound...) it sounds like it’s been filtered. Therefore, we call this effect a comb filter.
If we draw the same response on a dB scale, it will look like Figure 3.23 which looks even more like a comb.
If we draw the same response on a logarithmic frequency scale, it will look like Figure 3.24.
What happens if we change the difference in the time of arrival of the direct and the reflected sound? We still wind up with a comb filter, however, the frequencies of its boosts and cuts will change. The larger the difference in the time of arrival, the lower the frequency will shift in the filter’s response.
If the distance changes in time, you will perceive it as a kind of “swishing” sound. If you want to hear what this sounds like, put your hand in front of your face, palm towards you. Make a “ssshhhhh” sound and move your hand closer and farther from your face. You’ll hear a weird effect on the sound you’re making. This is a comb filter. The direct sound from your mouth to your ear is interfering with the reflection off your hand. As you change the distance to your hand, you change the difference in the time of arrival of the two sounds, so you hear the frequency response of the comb filter shifting as well.
The Real World
Up to now in this section, we have been pretending that sound doesn’t decay with distance. In real life, however, it does. So, what effect does this have on the response of the comb filter? It’s actually pretty simple. The basic frequency response shape won’t change much. However, since the reflection is now not quite as loud as the direct sound (because it had to travel farther), the constructive interference won’t give you two times the output, and the destructive interference won’t completely cancel. To get an idea of the result, take a look at Figures 3.25 to ??which shows the case of the example we started with. In this case, we have a difference in the time of arrival of 1 ms, and the reflection is 6 dB lower than the direct sound (because it had to travel 68.8 cm instead of 34.4 cm – half the distance).

The lower the level of the reflected wave, the smaller the bumps and troughs will be in the overall frequency response. The worst-case is when the delayed sound (the reflection) is identical in level to the direct sound, however, this can’t happen in real life. The more different the two signals are, the flatter their overall frequency response. For more information on this topic, see Section 9.4.2.
NOT YET WRITTEN

For this section, you will have to imagine a very strange thing – a single reflecting surface in a free field. Imagine that you’re floating in space (except that space is full of air so that you can breathe and sound can be transmitted) next to a wall that extends out to infinity in all directions. It may be easier to think of you standing outdoors on a concrete floor that goes out to infinity in all directions. Just remember – we’re not talking about a wall inside a room yet... just the wall itself. Room acoustics comes later.
The discussion in Section 3.2.1 assumes that the wave propagation is normal, or perpendicular, to the surface boundary. In most instances, however, the angle of incidence – an angle subtended by a normal to the boundary3 and the incident sound ray – is an oblique angle. If the reflective surface is large and flat relative to the wavelength of the reflected sound, there exists a simple relationship between the angle of incidence and the angle of reflection, subtended by the reflected ray of sound and the normal to the reflective surface. Snells law describes this relationship as is shown in Figure 3.29 and Equation 3.43 [Isaacs, 1990].
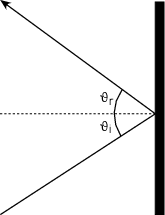
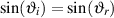 | (3.43) |
and therefore, in most cases:
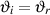 | (3.44) |
This is exactly the same as the light that bounces off a mirror. The light hits the mirror and then is reflected off at an angle that is equal to the angle of incidence. As a result, the reflections looks like a light bulb that appears to be behind the mirror. There is one interesting thing to note here – the point on the mirror where the light is reflected is dependent on the locations of the light, the mirror and the viewer. If the viewer moves, then the location of the reflection does as well. If you don’t believe me, go get a light and a mirror and see for yourself.
Since this type of reflection is most commonly investigated as it applies to visual media and thus reflected light, it is usually considered only in the spatial domain as is shown in the above diagram. The study of specular reflections in acoustic environments also requires that we consider the response in the time domain as well. This is not an issue in visual media since the speed of light is effectively infinite in human perception. If the surface is a perfect specular reflector with an infinite impedance, then the reflected pressure wave is an exact copy of the incident pressure wave. As a result, the reflection is equivalent to a simple delay with an attenuation determined by the propagation distance of the reflection as is shown in Figure 3.30 and the corresponding impulse response in Figure 3.31.


If the surface is irregular, then Snells Law as stated above does not apply. Instead of acting as a perfect mirror, be it for light or sound, the surface scatters the incident pressure in multiple directions. If we use the example of a light bulb placed close to a white painted wall, the brightest point on the reflecting surface is independent of the location of the viewer. This is substantially different from the case of a specular reflector such as a polished mirror in which the brightest point, the location of the reflection of the light bulb, would move along the mirrors surface with movements of the viewer. Lamberts Law describes this relationship and states that, in a perfectly diffusing reflector, the intensity is proportional to the cosine of the angle of incidence as is shown in Figure 3.32 and Equation 3.45 [Isaacs, 1990].

 | (3.45) |
where Ir and Ii are the intensities of the reflected and incident sound waves respectively.
Note that, in this case of a perfectly diffusing reflector, the “bright point” is the point on the surface of the reflector where the wavefront hits perpendicular to the surface. This means that it is irrelevant where the viewer is located. This can be seen in Figure 3.33 which shows a reflecting surface that is partly diffuse and specular. In this case, if the viewer were to move, the smaller specular reflection would move, but the diffuse reflection would not.

There are a number of physical characteristics of diffused reflections that differ substantially from their specular counterparts. This is due to the fact that, whereas the received reflection from a specular reflector originates from a single point on the surface, the reflection from a diffusive reflector is distributed over a larger area as is shown in Figure 3.34.

Dalenbäck [Dalenbäck et al., 1994] lists the results of this distribution in the spatial, temporal and frequency domains as the following:
The first issue will be discussed below. The second, third and fourth points are the product of the fact that the received reflection is distributed over the surface of the reflector. This results in multiple propagation distances for a single reflection as well as multiple angles and reflection locations. Since the reflection is distributed over both space and time at the listening position, there is an effect on the frequency content. Whereas, in the case of a perfect specular reflector, the frequency components of the resulting reflection form an identical copy of the original sound source, a diffusive reflector will modify those frequency characteristics according to the particular geometry of the surface. Finally, since the reflections are more widely distributed over the surfaces of the enclosure, the reverberant field approaches a perfectly diffuse field more rapidly.

The relative balance of the specular and diffused components of a reflection off a given surface are determined by the characteristics of that surface on a physical scale on the order of the wavelength of the acoustic signal. Although a specular reflection is the result of a wave reflecting off a flat, non-absorptive material, a non-specular reflection can be caused by a number of surface characteristics such as irregularities in the shape or absorption coefficient (and therefore acoustic impedance). In order to evaluate the specific qualities of assorted diffusion properties, various surface characteristics are discussed.
Irregular Surfaces
The natural world is comprised of very few specular reflectors for light waves even fewer for acoustic signals. Until the development of artificial structures, reflecting surfaces were, in almost all cases, irregularly-shaped (with the possible exception of the surface of a very calm body of water). As a result, natural acoustic reflections are almost always diffused to some extent. Early structures were built using simple construction techniques and resulted in flat surfaces and therefore specular reflections at that frequency.
For approximately 3000 years, and up until the turn of the 20th century, architectural trends tended to favour florid styles, including widespread use of various structural and decorative elements such as fluted pillars, entablatures, mouldings, and carvings. These random and periodic surface irregularities resulted in more diffused reflections according to the size, shape and absorptive characteristics of the various surfaces. The rise of the International Style in the early 1900s [Nuttgens, 1997] saw the disappearance of these largely irregular surfaces and the increasing use of expansive, flat surfaces of concrete, glass and other acoustically reflective materials. This stylistic move was later reinforced by the economic advantages of these design and construction techniques.
Maximum length sequence diffusers
The link between diffused reflections and better-sounding acoustics has resulted in much research in the past 30 years on how to construct diffusive surfaces with predictable results. This continues to be an extremely popular topic at current conferences in audio and acoustics with a great deal of the work continuing on the breakthroughs of Schroeder.
In his 1975 paper, Schroeder outlined a method of designing surface irregularities based on maximum length sequences (MLS) [Schroeder, 1975] which result in the diffusion of a specific frequency band. This method relies on the creation of a surface comprised of a series of reflection coefficients alternating between +1 and -1 in a predetermined periodic pattern.
Consider a sound wave entering the mouth of a well cut into the wall from the concert hall as shown in Figure 3.36.
Assuming that the bottom of the well has a reflection coefficient of 1, the reflection returns to the entrance of the well having propagated a distance equalling twice its depth dn, and therefore undergoing a shift in phase relative to the sound entering the well. The magnitude of this shift is dependent on the relationship between the wavelength and the depth according to Equation 3.46.
 | (3.46) |
where φ is the phase shift in radians, dn is the depth of the well and λ is the wavelength of the incident sound wave.
Therefore, if λ = 4dn, then the reflection will exit the well having undergone a phase shift of π radians. According to Schroeder, this implies that the well can be considered to have a reflective coefficient of -1 for that particular frequency, however this assumption will be expanded to include other frequencies in the following section.
Using an MLS, the particular required sequence of positive and negative reflection coefficients can be calculated, resulting in a sequence such as the following, for N=15:
+ + + - - - + - - + + - + - +
This is then implemented as a series of individually separated wells cut into the reflecting surface as is shown in Figure 3.37. Although the depth of the wells is dependent on a single so-called design wavelength denoted λo, in practice it has been found that the bandwidth of diffused frequencies ranges from one-half octave below to one half octave above this frequency [Schroeder, 1975]. For frequencies far below this bandwidth, the signal is typically assumed to be unaffected. For example, consider a case where the depth of the wells is equal to one half the wavelength of the incident sound wave. In this case, the wells now exhibit a reflective coefficient of +1; exactly the opposite of their intended effect, rendering the surface a flat and therefore specular reflector.

The advantage of using a diffusive surface geometry based on maximum length sequences lies in the fact that the power spectrum of the sequence is flat except for a minor dip at DC [Schroeder, 1975]. This permits the acoustical designer to specify a surface that maintains the sound energy in the room through reflection while maintaining a low interaural cross correlation (IACC) through predictable diffusion characteristics which do not impose a resonant characteristic on the reflection. The principal disadvantage of the MLS-based diffusion scheme is that it is specific to a relatively narrow frequency band, thus making it impractical for wide-band diffusion.
Schroeder Diffusers
The goal became to find a surface geometry which would permit designers the predictability of diffusion from MLS diffusers with a wider bandwidth. The new system was again introduced by Schroeder in 1979 in a paper describing the implementation of the quadratic residue diffuser or Schroeder diffuser [Schroeder, 1979] – a device which has since been widely accepted as one of the de facto standards for easily creating diffusive surfaces. Rather than relying on alternating reflecting coefficient patterns, this method considers the wall to be a flat surface with varying impedance according to location. This is accomplished using wells of various specific depths arranged in a periodic sequence based on residues of a quadratic function as in Equation 3.47 [Schroeder, 1979].
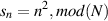 | (3.47) |
where sn is the sequence of relative depths of the wells, n is a number in the sequence of non-negative consecutive integers (0, 1, 2, 3 ...) denoting the well number, and N is a non-negative odd prime number.
If you’re uncomfortable with the concept of the modulo function, just think of it as
the remainder. For example, 5,mod(3) = 2 because 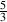 = 1 with a remainder of 2. It’s the
remainder that we’re looking for.
= 1 with a remainder of 2. It’s the
remainder that we’re looking for.
For example, for modulo 17, the series is
0, 1, 4, 9, 16, 8, 2, 15, 13, 13, 15, 2, 8, 16, 9, 4, 1, 0, 1, 4, 9, 16, 8, 2, 15...
As may be evident from the representation of this series in Figure 3.38, the pattern is
repeating and symmetrical around n = 0 and 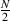 .
.

The actual depths of the wells are dependent on the design wavelength of the diffuser. In order to calculate these depths, Schroeder suggests Equation 3.48.
 | (3.48) |
where dn is the depth of well n and λo is the design wavelength [Schroeder, 1979].
The widths of these wells w should be constant (meaning that they should all be the
same) and small compared to the design wavelength (no greater than  ; Schroeder
suggests 0.137λo). Note that the result of Equation 3.48 is to make the median well
depth equal to one-quarter of the design wavelength. Since this arrangement has wells of
varying depths, the resulting bandwidth of diffused sound is increased substantially over
the MLS diffuser, ranging approximately from one-half octave below the design
frequency up to a limit imposed by λ >
; Schroeder
suggests 0.137λo). Note that the result of Equation 3.48 is to make the median well
depth equal to one-quarter of the design wavelength. Since this arrangement has wells of
varying depths, the resulting bandwidth of diffused sound is increased substantially over
the MLS diffuser, ranging approximately from one-half octave below the design
frequency up to a limit imposed by λ > 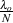 and, more significantly, λ > 2w [Schroeder,
1979].
and, more significantly, λ > 2w [Schroeder,
1979].
The result of this sequence of wells is an apparently flat reflecting surface with a varying and periodic impedance corresponding to the impedance at the mouth of each well. This surface has the interesting property that, for the frequency band mentioned above, the reflections will be scattered to propagate along predictable angles with very small differences in relative amplitude.
NOT YET WRITTEN

Go find a long piece of rope, tie one end of it to a solid object like a fence rail and pull it tight so that you look something like Figure 3.40
Then, with a flick of your wrist, you quickly move your end of the rope up and back down to where you started. If you did this properly, then the rope will have a bump in it as is shown in Figure 3.41. This bump will move quickly down the rope towards the other end.

When the bump hits the fence post, it can’t move it because fence posts are harder to move than rope molecules. Since the fence post is at the end of the rope, we say that it terminates the rope. The word termination is one that we use a lot in this book, both in terms of acoustic as well as electronics. All it means is the end of the system – the rope, the air, the wire... whatever the “system” is. So, an acoustician would say that the rope is terminated with a high impedance at the fence post end.
Remember back to the analogy in Section 3.2.2 where the person in the front was pushing on a concrete wall. You pushed the person ahead of you and you wound up getting pushed in the opposite direction that you pushed in the first place. The same is true here. When the wave on the rope refelects off a higher impedance, then the reflected wave does the same thing. You pull the rope up, and the reflection pulls you down. This end result is shown in Figure 3.42.

Take a look at a guitar string from the side as is shown in the top diagram in Figure 3.43. It’s a long, thin piece of metal that’s pulled tight and, on each end it’s held up by a piece of plastic called the bridge at the bottom and the nut at the top. Since the nut and the bridge are firmly attached to heavy guitar bits, they’re harder to move than the string, therefore we can say that the string is terminated at both ends with a high impedance.
Let’s look at what happens when you pluck a perfect string from the the centre point in slow motion. Before you pluck the string, it’s sitting at the equilibrium position as shown in the top diagram in Figure 3.43.
You grab a point on the string, and pull it up so that it looks like the second diagram in Figure 3.43. Then you let go...
One way to think of this is as follows: The string wants to get back to its equilibrium position, so it tries to flatten out. When it does get to the equilibrium position, however, it has some momentum, so it passes that point and keeps going in the opposite direction until it winds up on the other side as far as it was pulled in the first place. If we think of a single molecule at the centre of the string where you plucked, then the behaviour is exactly like a simple pendulum. At any other point on the string, the molecules were moved by the adjacent molecules, so they also behave like pendulums that weren’t pulled as far away from equilibrium as the centre one.
So, in total, the string can be seen as an infinite number of pendulums, all connected together in a line, just as is explained in Huygens theory.
If we were to pluck the string and wait a bit, then it would settle down into a pretty predictable and regular motion, swinging back and forth looking a bit like a skipping rope being turned by a couple of kids. If we were to make a movie of this movement, and look at a bunch of frames of the film all at the same time, they might look something like Figure 3.44.
In Figure 3.44, we can see that the string swings back and forth, with the point of largest displacement being in the centre of the string, halfway between the two anchored points at either end. Depending on the length, the tension and the mass of the string, it will swing back and forth at some speed (we’ll look at how to calculate this a little later...) which will determine the number of times per second it oscillates. That frequency is called the fundamental resonant frequency of the string. If it’s in the right range (between 20 Hz and 20,000 Hz) then you’ll hear this frequency as a musical pitch.
In reality, this is a bit of an oversimplification. The string actually resonates at other frequencies. For example, if you look at Figure 3.45, you’ll see a different mode of oscillation. Notice that the string still can’t move at the two anchored end points, but it now also does not move in the centre. In fact, if you get a skipping rope or a telephone cord and wiggle it back and forth regularly at the right speed, you can get it to do exactly this pattern. I would highly recommend trying.
A short word here about technical terms. The point on the string that doesn’t move is called a node. You can have more than one node on a string as we’ll see below. The point on the string that has the highest amplitude of movement is called the antinode, because it’s the evil opposite of the node, I suppose...
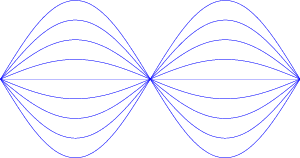
One of the interesting things about the mode shown in Figure 3.45 is that its wavelength on the string is exactly half the wavelength of the mode shown in Figure 3.44. As a result, it vibrates back and forth twice as fast and therefore has twice the frequency. Consequently, the pitch of this vibration is exactly one octave higher than the first.
This pattern continues upwards. For example, we have seen modes of vibration with one and with two “bumps” on the string, but we could also have three as is shown in Figure 3.46. The frequency of this mode would be three times the first. This trend continues upwards with an integer number of bumps on the string until you get to infinity.
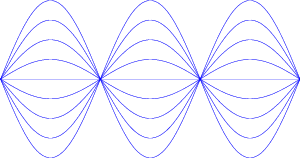
Since the string is actually vibrating with all of these modes at the same time, with some relative balance between them, we wind up hearing a fundamental frequency with a number of harmonics. The combined timbre (or sound colour) of the sound of the string is determined by the relative levels of each of these harmonics as they evolve over time. For example, if you listen to the sound of a guitar string, you might notice that it has a very bright sound immediately after it has been plucked, and that the sound gets darker over time. This is because at the start of the sound, there is a relatively high amount of energy in the upper harmonics, but these decay more quickly than the lower ones and the fundamental. Therefore, at the end of the sound, you get only the lowest harmonics and fundamental of the string, and therefore a darker sound quality.
It might be a little difficult to think that the string is moving at a maximum in the middle for some modes of vibration in exactly the same place as it’s not moving at all for other modes. If this is confusing, don’t worry, you’re completely normal. Take a look at Figure 3.47 which might help to alleviate the confusion. Each mode is an independent component that can be considered on its own, but the total movement of the string is the result of the sum of all of them.
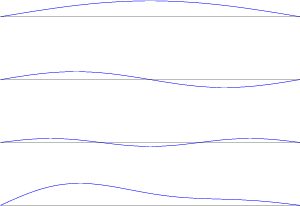
One of the neat tricks that you can do on a stringed instrument such as a violin or guitar is to play these modes selectively. For example, the normal way to play a violin is to clamp the string down to the fingerboard of the instrument with your finger to effectively shorten it. This will produce a higher note if the string is plucked or bowed. However, you could gently touch the string at exactly the halfway point and play. In this case, the string still has the same length as when you’re not touching it. However, your finger is preventing the string from moving at one particular point. That point (if your finger is halfway up the string) is supposed to be the point of maximum movement for all of the odd harmonics (which include the fundamental – the 1st harmonic). Since your finger is there, these harmonics can’t vibrate at all, so the only modes of vibration that work are the even-numbered harmonics. This means that the second harmonic of the string is the lowest one that’s vibrating, and therefore you hear a note an octave higher than normal. If you know any string players, get them to show you this effect. It’s particularly good on a ’cello or double bass because you can actually see the harmonics as a shape of the string.
Think back to the beginning of this section when you were playing with the skipping rope. Let’s take the same rope and attach it to two fence posts, pulling it tight. In our previous example, you flicked the rope with your wrist, making a bump in it that travelled along the rope and reflected off the opposite end. In our new setup, what we’ll do is to tap the rope and watch what happens. What you’ll (hopefully) be able to see is that the bump you created by tapping travels in two opposite directions to the two ends of the rope. These two bumps reflect and return, meeting each other at some point, crossing each other and so on. This process is shown in Figures 3.48 through 3.51.

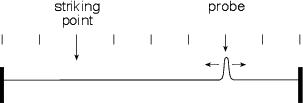

Let’s assume that you are able to make the bump in the rope infinitely narrow, so that it appears as a spike or an impulse. Let’s also put a theoretical probe on the rope that measures its vertical movement at a single point over time. We’ll also, for the sake of simplicity, put the probe the same distance from one of the fence posts as you are from the other post. This is to ensure that the probe is at the point where the two little spikes meet each other to make one big spike. If we graphed the output of the probe over time, it would look like Figure 3.52.
This graph shows how the rope responds in time when the impulse (an instantaneous change in displacement or pressure which instantaneous) is applied to it. Consequently we call it the impulse response of the system. Note that the graph in Figure 3.52 corresponds directly to Figures 3.49 to 3.51 so that you can see the relationship between the displacement at the point where the probe is located on the string and passing time. Note that only the first three spikes correspond to the pictures – after those three have gone by, the whole thing repeats over and over.
As we’ll see later in Section 9.2, we are able to do some math on this impulse response to find out what the frequency content of the signal is – in other words, the harmonic content of the signal. The results of this is shown in Figure 3.53.
This graph shows us that we have the fundamental frequency and all its harmonics at various levels up to ∞ Hz. The differences in the levels of the harmonics is due to the relative locations of the striking point and the probe on the string. If we were to move either or both of these locations, then the relative times of arrival of the impulses would change and the balance of the harmonics would change as well. Note that the actual frequencies shown in the graph are completely arbitrary. These will change with the characteristics of the string as we’ll see below in Section 3.5.4.
“So what?” I hear you cry. Well, this tells us the resonant frequencies of the string. Basically, Figure 3.53 (which is a frequency content plot based on the impulse response in time) is the same as the description of the standing wave in Section 3.5.2. Each spike in the graph corresponds to a frequency in the standing wave series.
If we weren’t able to change the pitch of a string, then many of our musical instruments would sound pretty horrid and we would have very boring music... Luckily, we can change the frequency of the modes of vibration of a string using any combination of three variables.
The reason a string vibrates in the first place is because, when you pull it back and let go, it doesn’t just swing back to the equilibrium position and stop dead in its tracks. It has momentum and therefore passes where it wants to be, then turns around and swings back again. The heavier the string is, the more momentum it has, so the harder it is to stop. Therefore, it will move slower. (I could make an analogy here about people, but I’ll behave...) If it moves slower, then it doesn’t vibrate as many times per second, therefore heavier strings vibrate at lower frequencies.
This is why the lower strings on a guitar or a piano have a bigger diameter. This makes them heavier per metre, therefore they vibrate at a lower frequency than a lighter string of the same length. As a result, your piano doesn’t have to be hundreds of metres long...
The fundamental mode of vibration of a string results in the string looking like a half-wavelength of a sound wave. In fact, this half-wavelength is exactly that, but the medium is the string itself, not the air. If we make the wavelength longer by lengthening the string, then the frequency is lowered, just as a longer wavelength in air corresponds to a lower frequency.
As we saw earlier, the reason the string vibrates is because it’s trying to get back to the equilibrium position. The tension on the string – how much its being stretched – is the force that’s trying to pull it back into position. The more you pull (therefore the higher the tension) the faster the string will move, therefore this higher the pitch. Also, the heavier the string, the harder it is to move, so the lower the pitch. Finally, the longer the string, the longer it takes the wave to travel down its length, so the lower the pitch.
The fundamental resonance frequency of a string can therefore be calculated if you have enough information about the string as is shown in Equation 3.49.
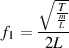 | (3.49) |
where f1 is the fundamental resonant frequency of the string in Hz, T is the string tension in Newtons (1 N is about 100 g), m is the string mass in kilograms, and L is the string length in metres.
While it’s nice to think of resonating strings in this way, that’s not really the way things work in the real world, but it’s pretty close. If you look at the plots above that show the modes of vibration of a string, you’ll notice that the ends start at the correct slope. This is a nice, theoretical model, but it really doesn’t reflect the way things really behave. If we zoom in at the point where the string is terminated (or anchored) on one end, we can see a different story. Take a look at Figure 3.54. The top plot shows the way we’ve been thinking up to now. The perfect string is securely anchored by a bridge or clamp, and inside the clamp it is free to bend as if it were hinged by a single molecule. of course, this is not the case, particularly with metal strings as we find on most instruments.
The bottom diagram tells a more realistic story. Notice that the string continues on a straight line out of the clamp and then gradually bends into the desired position – there is no fixed point where the bend occurs at an extreme angle.
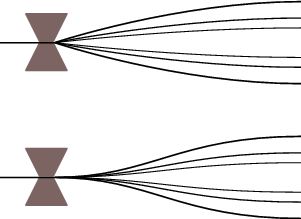
Now think back to the slopes of the string at the anchor point for the various modes of vibration. The higher the frequency of the mode, the shorter the wavelength on the string, and the steeper the slope at the string termination. This means that higher harmonics are trying to bend the string more at the ends, yet there is a small conflict here... there is typically less energy in the higher harmonics, so it’s more difficult for them to move the string, let alone bending it more than the fundamental. As a result, we get a strange behaviour as is shown in Figure 3.55

As you can see in this diagram, the lower harmonic is able to bend the string more, closer to the termination than the higher harmonic. This means that the effective length of the string is shorter for higher harmonics than for lower ones. As a result, the higher the harmonic, the more incorrect it is mathematically, and the sharper it is musically speaking. Essentially, the higher the harmonic, the sharper it gets.
This is why good piano tuners tune by ear rather than using a machine. Let’s say you want a Middle C on a piano to sound in tune with the C one octave above it. The fundamental of the higher C is theoretically the same frequency as the second harmonic of the lower one. But, we now know that the harmonic of the lower one is sharper than it should be, mathematically speaking. Therefore, in order to sound in tune, the higher C has to be a little higher than its theoretically correct tuning. If you tune the strings using a tuner, then they will have the correct frequencies for the theoretical world, but not for your piano. You will have to tune the various frequencies a little too high for higher pitches in order to sound correct.
The Physics of the Piano Blackham, E. D. Scientific American December 1965
Normal Vibration Frequencies of a Stiff Piano String Fletcher, H. JASA Vol 36, No 1 Jan 1964
Quality of Piano Tones Fletcher H. et al JASA Vol 34 No 6 June 1962
Imagine that you’re very, very small and that you’re standing at the end of the inside a pipe that is capped at both ends. (Essentially, this is exactly the same as if you were standing at one end of a hallway without doors.) Now, clap your hands. If we were in a free field (described in Section 3.1.21) then the power in your hand clap would be contained in a forever-expanding spherical wavefront, so it would appear to get quieter and quieter as it moves away. However, you’re not in a free field, you’re trapped in a pipe. As a result, the wave can only expand in one direction – down the length of the pipe. The result of this is that the sound power in your hand clap is trapped, and so, as the wavefront moves down the pipe, it doesn’t get any quieter because the wavefront doesn’t expand – it can only move forward.
In theory, if there was no friction against the pipe walls, and there was no absorption in the air, even if pipe were hundreds of kilometers long, the sound of your handclap would be as loud at the other end as it was 1 m down the pipe... (In fact, back in the early days of audio effects units, people used long pieces of hose as delay lines, exploiting this effect.)
One other thing – as you get further away from the sound source in the pipe, the wavefront becomes flatter and flatter. In fact, in not very much distance at all, it becomes a planewave. This means that if you look at the pressure wave across the pipe, you would see that it is perpendicular with the walls of the pipe. When this happens, the pipe is guiding the wave down its length, so we call the pipe a waveguide.
When the pressure wave hits the capped end of the pipe, it reflects off the wall and bounces back towards the direction from which it came. If we send a high-pressure wave down the pipe, since the cap has a higher acoustic impedance than the air in the pipe, the reflection will also be a high-pressure wave (as we saw in Section 3.2). This wavefront will travel back down the waveguide (the pipe) until it hits the opposite capped end, and the whole process repeats. This process is shown in Figures 3.56 through 3.59.
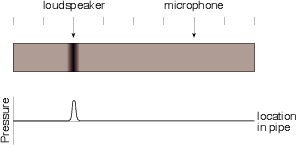

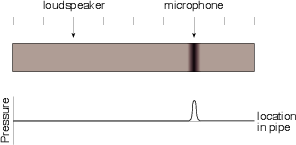
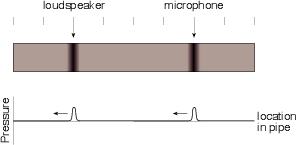
If we assume that the change in pressure is instantaneous and that it returns to the equilibrium pressure instantaneously then we are creating an impulse. The response at the microphone over time, therefore, is the impulse response of the closed pipe shown like Figure 3.60. Note that this impulse response corresponds directly to Figures 3.48 through 3.51. Also note that, unlike the struck rope, all pressure wave is always positive if we create a positive pressure to begin with. This is, in part, because we are now looking at air pressure whereas, in the case of the string, we were monitoring vertical displacement. In fact, if we were graphing the molecules’ displacements in the pipe, we would see the values alternating between positive and negative just as in the impulse response for the string.

Just as with the example of the vibrating string in the previous Chapter, we can convert the impulse response in Figure 3.60 into a plot of the frequency content of the signal as is shown in Figure 3.61. Note that this response is only true at the location of the microphone. If it or the loudspeaker’s position were changed, so would the relative balances of the harmonics. However, the frequencies of the harmonics would not change – these are determined by the length of the pipe and the speed of sound as we’ll see below.

Figure 3.61 tells us that the signal inside the pipe can be decomposed into a series of harmonics, just like we saw on the string in the previous section. The only problem here is that they’re a little more difficult to imagine because we’re talking about longitudinal waves instead of transverse waves.
It is important to note that, in almost every way, this system is identical to a guitar string. The only big difference is that the wave on the guitar sting is a transverse wave whereas the pipe has a longitudinal wave, but their basic behaviours are the same.
Of course, it’s not very useful to have a musical instrument that is a completely closed pipe – since none of the sound gets out, you probably won’t get very large audiences. Then again, you might wind up with the perfect instrument for playing John Cage’s 4’33”...
So, let’s let a little sound out of the pipe. We won’t change the caps on the two ends, we’ll just cut a small rectangular hole in the side of the pipe at one end. To get an idea of what this would look like, take a look at Figure 3.62.
Let’s think about what’s happening here in slow motion. Air comes into the pipe from the bottom through the small section on the left. It’s at a higher pressure than the air inside the pipe, so when it reaches the bottom of the pipe, it sends a high pressure wavefront up to the other end of the pipe. While that’s happening, there’s still air coming into the pipe. The high pressure wavefront bounces back down the pipe and gets back to where it started, meeting the new air that’s coming into the bottom. These two collide and the result is that air gets pushed out the hole on the side of the pipe. This, however, causes a negative pressure wavefront which travels up the pipe, bounces back down and arrives where it started where it sucks air into the hole in the side of the pipe. This causes a high pressure wavefront, etc etc... This whole process repeats itself so many times a second, that we can measure it as an oscillation using a microphone (if the pipe is the right length – more on this in the next section).
Consider the description above as an observer standing on the outside of the pipe. We just see that there is air getting pushed out and sucked into the hole on the side of the pipe a bunch of times a second. This results in high and low pressure wavefronts radiating outwards from the hole and we hear sound – and if the pipe is the right length, we might even hear a musical note.
So, we’ve seen that a pressure wave inside a pipe will bounce back and forth along its length, resulting in a number of harmonically-related frequencies resonating. If the signal that we send into the pipe in the first place contains information at those frequencies, then we’ll trigger the resonance. If the original signal doesn’t contain any information at the resonant frequency, then the resonance can’t get started in the first place.
TO BE WRITTEN

So, if we know the length of pipe, how can we calculate the resonant frequency? This might seem like an arbitrary question, but it’s really important if you’ve been hired to build a pipe organ. You want to build the pipes the right length in order to provide the correct pitch.
Take a look back at the example of an impulse response of a closed pipe, shown in Figure 3.60. As you can see, the sequence shown consists of three spikes and that sequence is repeated over and over forever (if it’s an undamped system). The time it takes for the sequence to repeat itself is the time it takes for the impulse to travel down the length of the pipe, bounce off one end, come all the way back up the pipe, bounce off the other end and to get back to where it started. Therefore the wavelength of the fundamental resonant frequency of a closed pipe is equal to two times the length of the pipe, as is shown in Equation 3.50. Note that this equation is a general one for calculating the wavelengths of all resonant frequencies of the pipe. If you want to find the wavelength of the fundamental, set n to equal 1.
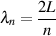 | (3.50) |
where λn is the wavelength of the nth resonant frequency of the closed pipe of length L.
Since the wavelength of the fundamental resonant frequency of a closed pipe is twice the length of the pipe, you’ll often hear closed pipes called half-wavelength resonators. This is a just geeky way of saying that it’s closed at both ends.
If you’d like to calculate the actual frequency that the pipe resonates, then you can just calculate it from the wavelength and the speed of sound using Equation 3.8. What you would wind up with would look like Equation 3.51.
 | (3.51) |
NOT YET WRITTEN
TO BE WRITTEN



The Physics of Woodwinds Benade, A. H. Scientific American October 1960
The Acoustics of Orchestral Instruments and of the Organ Richardson, E. G. Arnold and Co. (1929)
Horns, Strings and Harmony Benade, A. H. Doubleday and Co., Inc. (1960)
On Woodwind Instrument Bores Benade, A. H. JASA Vol 31 No 2 Feb 1959
Back in Section 3.1.2 we looked at a type of simple harmonic oscillator. This was comprised of a mass on the end of a spring. As we saw, if there is no such thing as friction, if you lift up the mass, it will bounce up and down forever. Also, if we graphed the displacement of the mass over time, we’d see a sinusoidal waveform. If there is such as things as friction (such as air friction), then some of the energy is lost from the system as heat and the oscillator is said to be damped. This means that, eventually, it will stop bouncing.
We could make a similar system using only moving air instead of a mass on a spring. Go find a wine bottle. If it’s not empty, then you’ll have to empty it (I’ll leave it to you to decide exactly how this should be accomplished). If we simplify the shape of the bottle a little bit, it is a tank with an opening into a long neck. The top of the neck is open to the outside world.
There is air in the tank (the bottle) whose pressure can be changed (we can make it higher or lower than the outside pressure) but if we do change it, it will want to get back to the normal pressure. This is essentially the same as the compression of the spring. If we compress the spring, it pushes back to try to be normal. If we pull the spring, it pulls against us to try to be normal. If we compress the air in the bottle, it pushes back to try to be the same as the outside pressure. If we decompress the air, it will pull back, trying to normalize. So, the tank is the spring.
As we saw in Section 3.6.1 on waveguides, if air goes into one end of a tube, then it will push air out the other end. In essence, the air in the tube is one complete thing that can move back and forth inside the tube. Remember that the air in the tube has some mass (just like the mass on the end of the spring) and that one end is connected to the tank (the spring).

Therefore, a wine bottle can be considered to be a simple harmonic oscillator. All we need to do is to get the mass moving back and forth inside the neck of the bottle. We already know how do do this – you blow across the top of the bottle and you’ll hear a note.
We can even take the analogy one step further. The system is a damped oscillator (good thing too... otherwise every bottle that you ever blew across would still be making sound... and that would be pretty annoying) because there is friction in the system. The air mass inside the neck of the bottle rubs against the inside of the neck as it moves back and forth. This resulting friction between the air and the neck causes losses in the system, however the wider the neck of the bottle, the less friction per mass, as we’ll see in the math later.
This thing that we’ve been looking at is called a wine bottle, but an acoustician would call it a Helmholtz resonator named after the German physicist, mathematician and physiologist, Hermann L. F. von Helmholtz (1821-1894).
What’s so interesting about this device that it warrants its own name other than “wine bottle?” Well, if we were to assume (incorrectly) that a wine bottle was a quarter-wavelength resonator (hey, it’s just a funny-shaped pipe that’s closed on one end, right?) and we were to calculate its fundamental resonant frequency, we’d find that we’d calculate a really wrong number. This is because a Helmholtz resonator doesn’t behave like a quarter-wavelength resonator, it has a much lower fundamental resonant frequency. Also, it’s a lot more stable – it’s pretty easy to get a quarter-wavelength resonator to fluke up to one of its harmonics just by blowing a little harder. If this wasn’t true, flute music would be really boring (or flutists would need more fingers). It’s much more difficult to get a beer bottle to give you a large range of notes just by blowing harder.
How do we calculate the fundamental resonant frequency of a Helmholtz resonator? (I knew you were just dying to find out...) This is shown in Equation 3.52
 | (3.52) |
where ω0 is the fundamental resonant frequency of the resonator in radians per second (to convert to Hz, see Equation 3.5), c is the speed of sound in m/s, S is the cross-sectional area of the neck of the bottle, L′ is the effective length of the neck (see below for more information on this) and V is the volume of the bottle (not including the neck) [Kinsler and Frey, 1982].
So, as you can see, this isn’t too bad to calculate except for the bit about the “effective length” of the neck. How does the effective length compare to the actual length of the neck of the bottle? As we saw in the previous chapter, the acoustical length of an open pipe is not the same as its real measurable length. In fact, it’s a bit longer, and the amount by which it’s longer is dependent on the frequency and the cross-sectional area of the pipe. This is also true for the neck of a Helmholtz resonator, since it’s open to the world on one end.
If the pipe is unflanged (meaning that it doesn’t flare out and get bigger on the end like a horn), then you can calculate the effective length using Equation 3.53.
 | (3.53) |
where L is the actual length of the pipe, and a is the inside radius of the neck [Kinsler and Frey, 1982].
If the pipe is flanged (meaning that it does flare out like a horn), then the effective length is calculated using Equation 3.54[Kinsler and Frey, 1982]
 | (3.54) |
Please note that these equations won’t give you exactly the right answer, but they’ll put you in the ballpark. Things like the actual shape of the bottle and the neck, how the flange is shaped, how the neck meets the bottle... many things will have a contribution to the actual frequency of the resonator.
Is this useful information? Well, consider that you now know that the oscillation frequency is dependent on the mass of the air inside the neck of the bottle. If you make the mass smaller, then the frequency of the oscillation will go up. Therefore, if you stick your finger into the top of a beer bottle and blow across it, you’ll get a higher pitch than if your finger wasn’t there because you’ve reduced the mass of the air in the neck. The further you stick your finger in, the higher the pitch. I once saw a woman in a bar in Montreal win money in a talent contest by playing “Girl From Ipanema” on a single beer bottle in this manner. Therefore, yes. It is useful information.
NOT YET WRITTEN



We’ve already got most of the work done when it comes to bowed strings. The string itself behaves pretty much the same way it does when it’s struck. That is to say that it tends to prefer to vibrate at its resonant modal frequencies. The only real question then is: how does the bow transfer what appears to be continuous energy into the string to keep vibrating?
Think of pushing a person on a swing. They’re sitting there, stopped, and you give them a little push. This moves them away, then they come back towards you, and just when they’re starting to head away from you again, you give them another little push. Every time they get close, you push them away once they’ve started moving away. Using this technique, you can use just a little energy on each push, in synch with the resonant frequency of the person on the swing to get them going quite high in the air. The trick here is that you’re pushing at the right time. You have to add energy to the system when they’re not moving too fast (at the bottom of the swing) because that would mean that you have to work hard, but at a time when you’re pushing in the same direction that they’re moving.
This is basically the way a bow works. Think of the string as the swing and the bow as you. In between the two is a mysterious substance called rosin which is essentially just dried tree sap (actually, it’s dried turpentine from pine wood as far as I’ve been able to find out). The important thing about rosin is that it is a substance with a very high static friction coefficient, but a very low dynamic friction coefficient.
Huh? Well, first let’s define what a friction coefficient is. Put a book on a table and then push it so that it slides – then stop pushing. The book stops moving. The reason is friction – the book really doesn’t want to move across the table because friction is preventing it from doing so. The amount of friction that’s pushing back against you is determined by a bunch of things including the mass of the book, and the smoothness of the two surfaces (the book cover and the table top). This amount of friction is called the friction coefficient. The higher the coefficient, the more friction there is and the harder it is to move the book – in essence the more the book “sticks” to the table.
Now we have to look at two different types of friction coefficients – static and dynamic. Just before you start to push the book across the table, it’s just sitting there, stopped (in other words, it’s static – i.e. it’s not moving). After you’ve started pushing the book, and it’s moving across the table, it’s probably easier to keep it going than it was to get it started. Therefore the dynamic friction coefficient (the amount of friction there is when the object is moving) is lower than the static friction coefficient (the amount of friction there is when the object is stopped).
So, going back to the statement that rosin has a very high static friction coefficient, but a very low dynamic friction coefficient, think about what happens when you start bowing a string.
In many ways this system is exactly the same as pushing a person on a swing. You feed a little energy into the oscillation on every cycle and therefore keep the whole thing going with only a minimum of energy expended. The ultimate reason so little energy is expended is because you are smart about when you inject it into the system. In the case of the bow and the string, the timing of the injection looks after itself.
The Physics of Violins Hutchins, C. M. Scientific American November 1962
The Mechanical Action of Violins Saunders, F. A. JASA Vol 9 No 2 Oct 1937
Regarding the Sound Quality of Violins and a Scientific Basis for Violin Construction Meinel, H. JASA Vol 29 No 7 July 1957
Subharmonics and Plate Tap Tones in Violin Acoustics Hutchins, C. M. et al JASA Vol 32 No 11 Nov 1960
On the Mechanical Theory of Vibrations of Bowed Strings and of Musical Instruments of the Violin Family Raman, C. V. Indian Association for the Cultivation of Science (1918)
The Bowed String and the Player Schelleng, J. C. JASA Vol 53 No 1 Jan 1973
The Physics of the Bowed String Schelleng, J. C. Scientific American January 1974
Go back – way back to a time just before harmony. When we had only a melody line, people would sing a tune made up of notes that were probably taught to them by someone else singing. Then people thought that it would be a really neat idea to add more notes at the same time – harmony! The problem was deciding which notes sounded good together (consonant) and which sounded bad (dissonant). Some people sat down and decided mathematically that some sounds ought to be consonant or dissonant while other people decided that they ought to use their ears.
For the most part, they both won. It turns out that, if you play two frequencies at the same time, you’ll like the combinations that have mathematically simple relationships – and there’s a reason which we talked about in a previous chapter – beating.
If I play an “A” below Middle C on a piano, the sound includes the fundamental 220 Hz, as well as all of the upper harmonics at various amplitudes. So we’re hearing 220 Hz, 440 Hz, 660 Hz, 880 Hz, 1100 Hz, 1320 Hz, and so on up to infinity. (Actually, the exact frequencies are a little different as we saw in Section 3.5.5.)
If I play another note which has a frequency that is relatively close to the fundamental of the 220 Hz I hear beating between the two fundamentals at a rate of f1 -f2. The same thing will happen if I play a note with a fundamental which is close to one of the harmonics of the 220 Hz (hence 2f1 -f2 and 3f1 -f2 and so on...).
For example, if I play a 220 Hz tone and a 445 Hz tone, I’ll hear beating, because the 445 Hz is only 5 Hz away from one of the harmonics of the 220 Hz tone. This will sound “dissonant” because, basically, we don’t like intervals that “beat.”
If I play a 440 Hz tone with the 220 Hz tone, there is no beating, because 440 Hz happens to be one of the harmonics of the 220 Hz tone. If there’s no beating then we think that it’s consonant.
Therefore, if I wanted to create a system of tuning the notes in a scale, I would do it using formulae for calculating the frequencies of the various notes that ensured that, at least for my most-used chords, the intervals in the chords would not beat. That is to say that when I play notes simultaneously, the various fundamentals have simple mathematical relationships.
The philosophy described above resulted in a tuning system called Pythagorean Temperament which was based on only 2 intervals. The idea was that, the smaller the mathematical relationship between two frequencies, the better, so the two smallest possible relationships were used to create an entire system. Those frequency ratios were 1:2 and 2:3.
Exactly what does this mean? Well, essentially what we’re saying when we talk about an interval of 1: 2 is that we have two frequencies where one is twice the other. For example, 100 Hz and 200 Hz. (100:200 = 1:2). As we have seen previously, this is known as an “octave.”
The second ratio of 2:3 is what we nowadays call a “Perfect Fifth.” In this interval, the two notes can be seen as harmonics of a common fundamental. Since the frequencies have a ratio of 2:3 we can consider them to be the 2nd and 3rd harmonics of another frequency 1 octave below the lower of the two notes.
Using only these two ratios (or intervals) and a little math, we can tune all the notes in a diatonic scale as follows:
If we start on a note which we’ll call the “tonic” at, oh, 220 Hz, we tune another note to have a 2:3 ratio with it. 2:3 is the same as 220:330, so the second note will be 330 Hz.
We can then repeat this using the 330 Hz note and tuning another note with it... If we wish to stay within the same octave as our tonic, however, we’ll have to tune up by a ratio of 2:3 and then transpose that down an octave (2:1). In other words, we’d go up a Perfect 5th and down an octave, creating a Major Second from the Tonic. Another way to do this is simply to tune down a Perfect Fourth (the inversion of a Perfect Fifth). This would result, however in a different ratio, being 3:4.
How did we arrive at this ratio? Well, we’ll start by doing it empirically. If we started on a 330 Hz tone, and went up a Perfect Fifth to 495 Hz and then down an octave, we’d be at 247.5 Hz. 247.5:330 = 3:4.
If we were to do this mathematically, we’d say that our first ratio is 2:3, the second ratio is 2:1. These two ratios must be multiplied (when we add intervals, we multiply the frequency ratios which multiply just like fractions) so 2:3 * 2:1 = 4:3. Therefore, in order to go down a fourth, the ratio is 4:3, up is 3:4.
In order to tune the other notes in the diatonic scale, we keep going, up a Perfect 5th, down a Perfect Fourth (or up 2:3, down 4:3) and so on until we have done 3 ascending fifths and 2 descending fourths. (or, without octave transpositions, 5 ascending fifths). That gets us 6 of the 7 notes we require (being, in chronological order, the Tonic, Fifth, Second, Sixth, and Third in a “Major” scale. The Fourth of the scale is achieved simply by calculating the 3:4 ratio with the Tonic.
It may be interesting to note that the first 5 notes we tune are the “common” pentatonic scale.
We could use the same system to get all of the chromatic notes by merely repeating the procedure for a total of 6 ascending fifths and 5 descending fourths (or 11 ascending fifths). This will present us with a problem, however.
If we do complete the system, starting at the tonic and calculating the other 11 notes in a chromatic scale, we’ll end up with what is known as one wolf fifth.
What’s a wolf fifth? Well, if we kept going around through the system until the 12th note, we ought to end up an octave from where we started – the problem is that we wind up a little too sharp. So, we tune the octave above the tonic to the tonic and put up with it being “out of tune” with the note a fifth below.
In fact, it’s wiser to put this this wolf fifth somewhere else in the scale – such as in an interval less likely to be played than the tonic and the fourth of the scale.
Let’s do a little math for a moment. If we go up a fifth and down a fourth and so on and so on through to the 12th note, we are actually doing the following equation:
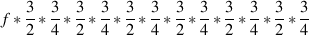 | (3.55) |
If we calculated this we’d see that we get the equation
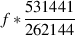 | (3.56) |
instead of the f * that we’d expect for an octave.
that we’d expect for an octave.
how far away from a “real” octave is the note you wind up with?
well, if we transpose the f * note down an octave, we get
note down an octave, we get 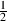 *f *
*f *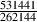 or
f *
or
f * .
.
In other words, the ratio between the tonic and the note which is an octave below the 12th note in the pythagorean tuning system is
531441 : 524288.
This amount of error is called the Pythagorean Comma.
Just for your information, according to the Grove dictionary, “Medieval theorists who discussed intervallic ratios nearly always did so in terms of Pythagorean intonation.” (look up “Pythagorean intonation”)
For an investigation of the relative sizes of intervals within the scale, look at Table 4.1 on page 86 of “The Science of Musical Sound” By Johann Sundberg.
The Pythagorean system is pretty good if you’re playing music that has a lot of open fifths and fourths (as Pythagorean music seems to have had, according to Grout) but what if you like a good old major chord – how does that sound? Well, one way to decide is to look at the intervals. To achieve a major third above the tonic in Pythagorean temperament, we go up 2 fifths and down 2 fourths (although not in that order) therefore, the frequency is
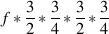 | (3.57) |
or
 | (3.58) |
This ratio of 81:64 doesn’t use very small numbers, and, in fact, we do hear considerably more beating than we’d like. So, once upon a time, a “better” tuning system was invented to accomodate people who liked intervals other than fourths and fifths.
The basic idea of this system, called Just Temperament (or pure temperament or just intonation) is that the notes in the diatonic scale have a realtively simple mathematical relationship with the tonic. In order to do this, you have to be fairly flexible about what you call “simple” (Pythagoras never used a bigger number than 4, remember) but the musical benefits outweigh the mathematical ones.
In just temperament we use the ratios shown in Table 3.4:
| Musical | Frequency ratio |
| Interval | of two notes |
| Tonic | 1:1 |
| 2nd | 9:8 |
| 3rd | 5:4 |
| 4th | 4:3 |
| 5th | 3:2 |
| 6th | 5:3 |
| 7th | 15:8 |
| Octave | 2:1 |
These are all fairly simple mathmatical relationships, and note that the fouth and fifth are identical to that of the Pythagorean system.
This system has a much better intonation (i.e. less beating) when you plunk down a I, IV or V triad because the ratios of the frequencies of the three notes in each of the chords have the simple relationships 4:5:6. (i.e. 100 Hz, 125 Hz and 150 Hz)
The system isn’t perfect, however, because intervals that should be the same actually have different sizes. For example,
The implications of this are intonation problems when you stray too far from your tonic key. Thus a keyboard instrument tuned using Just Intonation must be tuned for a specific key and you’re not permitted to transpose or modulate without losing your audience or your sanity or both. Of course, the problem only occurs in instruments with fixed tunings for notes (such as keyboard and fretted string instruments). Everyone else can compensate on the fly.
The major third and the tonic in Just Intonation have a frequency ratio of 5:4. The major third and the tonic in Pythagorean Intonation have a ratio of 64:81. The difference between these two intervals is
64:81 – 5:4 = 80:81
This is the amount of error in the major third in Pythagorean Tuning and is called the syntonic comma.
Meantone Temperaments were attempts to make the Just system “better.” The idea was that you fudge a little with a couple of notes in the scale to make different keys more palatable on the instrument. There were a number of attempts at this by people like Werckmeister, Valotti, Ramos, and de Caus, each with a different system that attempted to improve on the other. (Although Werckmeister was quite happy to use another system called “Equal Temperament”)
These are well discussed in chapters 18.3 – 18.5 of the book “Music Acoustics” by Donald Hall
The problem with all of the above systems is that an instrument tuned using either of them was limited to the number of keys it could play in. This is simply because of the problem mentioned with Just Intonation, different intervals that should be the same size, are not.
The simple solution to this problem is to decide on a single size for the smallest possible interval (in our case, the semitone) and just multiply to get all other intervals.
This was probably first suggested by a Sicilian abbot named Girolamo Roselli who, in turn convinced Frescobaldi to use it (but not without the “aid of ‘frequent and gratuitous beverages”’ (Grove Dictionary under “Temperaments”)
So, we have to divide an octave into semitones, or 12 equal divisions. How do we do this? Well, we need to find a ratio that can multiply by itself 12 times to arrive at twice the number we started with. (i.e. adding 12 semitones gives you an octave.) How do we do this?
We know that 3*3 = 9 so we say that 32 = 9 therefore, going backwards, “the square root of 9 = 3.” What this final equation says is “the number, when multiplied by itself once gives 9 is 3.” We want to find the number which, when multiplied by itself 12 times equals 2 (since we’re going up an octave) so, the number we’re looking for is “the twelfth root of 2.” (or about 1:1.06)That’s it.
Therefore, given any frequency f, the note one semitone up is f * the 12th root of 2. If you want to go up 2 semitones, you have to multiply by the 12th root of 2 twice or :
 | (3.59) |
or
 | (3.60) |
So, in order to go up any number of semitones, we simply do the following equation :
 | (3.61) |
where x is the number of semitones
The advantage of this is that you can play in any key on one instrument. The disadvantage is that every key is “out of tune.” But, they’re all equally out of tune, so we have gotten used to it. Sort of like we have gotten used to eating fast food, despite the fact that it tastes pretty wretched, sometimes even bordering on rancid...
To get an intuitive idea of the fact that equal temperament intervals are out of tune, even if they don’t sound like it most of the time, take a look at Figures 3.74 and 3.75


There are some people who want a better way of dividing up the octave. Basically, some people just aren’t satisfied with 12 equal divisions, so they divided up the semitone into 100 equal parts and called them cents . Since a cent is 1/100 of a semitone, it’s an interval which, when multiplied by itself 1200 times (12 semitones 100 cents) makes an octave, therefore the interval is the 1200th root of 2 (or 1:1.00058).
Therefore, 1 cent above 440 Hz is
 | (3.62) |
We can use cents to compare tuning systems. Remember that 100 cents is 1 semitone, 200 cents is 2 semitones, and so on.
There is a good comparison in cents of various tuning systems in “Musical Acoustics” by Donald Hall.
Tuning and Temperament, A Historical Survey Barbour, J. M.
Let’s ignore all the stuff we talked about in Section 3.2 for a minute. We’ll pretend that we didn’t talk about acoustical impedance and that we didn’t look at all sorts of nasty-looking equations. We’ll pretend for this chapter, when it comes to a sound wave reflecting off a wall, that all we know is Snell’s Law described in Section 3.3.1. So, for now, we’ll think that all walls are mirrors and that the angle of incidence equals the angle of reflection.
Let’s consider a rectangular room with one sound source and you in it as is shown in Figure 3.77. We’ll also ignore the fact that the room has a ceiling or a floor... One very convienent way to consider the way sound moves in this room is to not try to understand everything about it – but instead to be a complete egoist and ask “what sound gets to me?”
As we discussed earlier, when the source makes a sound, the wavefront expands spherically in all directions, but we’re not thinking that way at the moment. All you care about is you, so we can say that the sound travels from the source to you in a straight line. It takes a little while for the sound to get to you, according to the speed of sound and the distance between you and the source. This sound that you get first is usually called the direct sound, because it travels directly from the sound source to you. This path that the wave travels is shown in Figure 3.78 as a straight red line. In addition, if you were replaced by an omnidirectional microphone, we could think of the impulse response (explained in Section ??) as being a single copy of the sound arriving a little later than when it was emitted, and slightly lower in level because the sound had to travel some distance. This impulse response is shown in Figure 3.79.
Of course, the sound is really travelling out in all directions, which means that a lof of it is heading towards the walls of the room instead of heading towards you. As a result, there is a ray of sound that travels from the sound source, bounces off of one wall (remember Snell’s Law) and comes straight to you. Of course, this will happen with all four walls – a single reflection from each wall reaches you a little while after the direct sound and probably at different times according to the distance travelled. These are called first-order reflections because they contain only a single bounce off a surface. They’re shown as the blue lines in Figure 3.80 with the impulse response shown in Figure 3.81.
We also get situations where the sound wave bounces off two different walls before the sound reaches you, resulting in second-order reflections. In our perfectly rectangular room, there will be two types of these second-order reflections. In the first, the two walls that are reflecting are parallel and opposite to each other. In the second, the two walls are adjacent and perpendicular. These are shown as the green lines in Figure 3.82 and the impulse response in Figure 3.83. Note in the impulse response that it’s possible for a second-order reflection to arrive earlier than a first-order reflection, particularly if you are in a long rectangular room. For example, if you’re sitting in the front row of a big concert hall, it’s possible that you get a second-order reflection off the stage and side walls before you get a first-order reflection off the wall in the back behind the audience. The moral of the story here is that the order of reflection is only a general indicator of its order of arrival.
If the walls were perfect reflectors and there was no such thing as sound absorption in air, this series of more and more reflections would continue forever. However, there is a little energy in the sound wave lost in the air, and in the wall, so eventually, the reflections get quieter and quieter as they reach a higher and higher order until eventually, there is nothing.
Let’s say that your sound source is a person clapping their hands once – a sound with a very fast attack and decay. The first thing you hear is the direct sound, then the early reflections. These are probably separated enough in time and space that your brain can interpret them as separate events. Be careful about what I mean by this previous sentence. I do not necessarily mean that you will hear the direct and earlier reflections as separate hand claps (although if the room is big enough you might...) Instead, I mean that your brain uses these discrete components in the sound that arrives at the listening position to determine a bunch of information about the sound source and the room. We’ll talk about that more later.
If we consider higher and higher orders of reflections, then we get more and more reflections per second as time goes by. For example, in our rectangular, two-dimensional room, there are 4 first-order reflections, 8 second-order reflections, 12 third-order reflections and so on and so on. These will pile up on each other very quickly and just become a complete mess of sound that apparently comes from almost everywhere all at the same time (actually, you will start to approach a diffuse field situation). When the reflections get very dense, we typically call the collection of all of them reverberation or reverb. Essentially, reveberation is what you have when there are too many reflections to think about. So, instead of trying to calculate every single reflection coming in from every direction at every time, we just give up and start talking about the statistical properties of the room’s acoustics. So, you won’t hear about a 57th order reflection coming in a a predicted time. Instead, you’ll hear about the probability of a reflection coming from a certain direction at a given time. (This is sort of the same as trying to predict the weather. Nobody will tell you that it will definitely rain tomorrow starting at 2:34 in the afternoon. Instead, they’ll say that there is a 70% chance of rain. Hiding behind statistics helps you to avoid being incorrect...)
One immediately obvious thing about reverberation in a real room is that it takes a little while for it to die away or decay. So then the question is, how do we measure the reveberation time? Well, typically we have to oversimplify everything we do in audio, so one way to oversimplify this measurement is to just worry about one frequency. What we’ll do is to get a loudspeaker that’s emitting a sine tone with a constant level – therefore, just a single frequency. Also, we’ll put a microphone somewhere in the room and look at its output level on a decibel scale. If we leave the speaker on for a while, the sound pressure level at the microphone will stabilize and stay constant. Then we turn off the sine wave, and the revebreration will decay down to nothing. Interestingly, if the room is behaving according to theory, if we plot the output of the microphone over time on a decibel scale, then the decay of the reverberation will be a straight line as is shown in Figure 3.84.

The amount of time it takes the reverberation to decay a total of 60 decibels is what we call the reverberation time of the room, abbreviated RT 60.
Once upon a time (acutually, around the year 1900), a guy named Wallace Clement Sabine did some experiments and some math and figured out that we can arrive at an equation to predict the reveberation time of a room if we know a couple of things about it.
Let’s consider that the more absorptive the surfaces in the room, the more energy we lose in the walls, so the faster the reverberation will decay. Also, the more surface area there is (i.e. the bigger the walls, floor and ceiling) the more area there is to absorb sound, therefore the reverb will decay faster. So, the average absorption coefficient (see Section ??) and the surface area will be inversely proportional to the reverb time.
Also consider, however, that the bigger the room, the longer the sound will travel before it hits anything to reflect (or absorb) it. Therefore the bigger the room volume, the longer the reverb time.
Thinking about these three issues, and after doing some experiments with a stopwatch, Sabine settled on Equation 3.63:
 | (3.63) |
Where c is the speed of sound in the room and A is the total sound absorption by the room which can be calculated using Equation 3.64.
 | (3.64) |
Where S is the total surface area of the room and is the “average value of the statistical absorption coefficient.” [Morfey, 2001]
There is second famous equation that is used to calculate the reverberation time of a room, developed by C. F. Eyring in 1930. This equation is very similar to the Sabine equation, in fact you can use Equation 3.63 as the main equation. You just have to change the value of A using Equation 3.65:
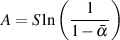 | (3.65) |
Note that some books will call this the Norris-Eyring Equation [Morfey, 2001].
I lied. All of the description of reflections and reverberation that I talked about above only applies to high frequencies. Low frequencies behave completely differently in a room. Remember back to Section ?? on woodwind instruments that, as soon as you have a pipe that is closed on both ends, it will have a natural resonance at a frequency that is determined by its length. Since the pipe is closed on both ends, then the fundamental resonant frequency has a wavelength equal to twice the length of the pipe. All we need to do to make the pipe resonate at that frequency and its harmonics is to put a sound source in there that has any energy at the resonant frequencies. Since, as we saw in Section ??, an impulse contains all frequencies, if we snap our fingers inside the pipe, it will ring.
Now, let’s change the scale a bit and consider a closed pipe the length of a room. This pipe will still resonate at its fundamental frequency and its harmonics, but these will be very low because the pipe will be very long.
If we wanted to calculated the fundamental resonant frequency of this pipe of length L (equal to the Length of the room), we just need to find the frequency with a wavelength of 2L as is shown in Equation 3.66
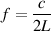 | (3.66) |
We also know that the harmonics of this frequency f will resonate as well. These are easy to calculate by just multiplying f by an integer – so the first harmonic will be 1f, the second harmonic will be 2f and so on.
It’s worth your while to compare Equation 3.66 to Equation 3.51 back in the section on resonance in closed pipes. You’ll notice that both equations are the same.
The interesting thing is that a room behaves in exactly the same way. We can think of a room with a length of L as a closed pipe with a length of L. In fact, I’m not even saying that a room is like a closed pipe – I’m saying that a room is a closed pipe. Therefore the room will resonate at a frequency with a wavelength of 2L and its harmonics. This can be calculated using Equation 3.67 which is exactly the same as Equation ??, but written slightly differently, and with a p added for the harmonic number.
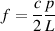 | (3.67) |
This behaviour doesn’t just apply to the length of the room. It also applies to the width and length – therefore the room is actually behaving as three pipes of lengths L, W and H (for Length, Width and Height) at the same time. These three fundamental frequencies (and their harmonics) will all resonate independently of each other.
There are a couple of interesting things to discuss when it comes to axial (one-dimensional) room modes.
Firstly, just as with the resonating closed pipe, there is the issue of the relationship between the particle pressure and the particle velocity. If we look at the particles adjacent to the wall, we see that these molecules cannot move, therefore the amplitude of their velocity wave is 0, and the amplitude of the pressure wave is at its maximum. Conversely, at the centre of the room, the amplitude of the velocity wave is maximum, and the amplitude of the pressure wave is 0.
FIGURE HERE?
Secondly, there’s the issue of phase. Remember back to the discussion on closed pipes that we can consider them to be waveguides. This means that the sound energy at one end of the pipe gets out the other end without being attenuated because it can’t expand in three dimensions – it can only travel in one. Also, it means that the pressure wave is in phase at any cross section of the pipe. At the resonant frequency of the room, this is also true. If you could freeze time and actually see the pressure wave in the room, you would see that the pressure wave at the resonant frequency is in phase across the room. So, if you have a loudspeaker in one corner of the room playing a sine wave at the fundamental resonance of the length of the room, then the sound wave is not expanding outwards as a sphere from the loudspeaker. Instead, it’s travelling back and forth in the room as a plane wave.
FIGURE HERE?
The axial room modes can be thought of in exactly the same way as a standing wave in a pipe or on a string. In all of these cases, the resonance is limited to a single dimension. However, a room has more than one dimension. There is also the issue of resonances in two-dimensions, known as tangential room modes. These behave in exactly the same way as a rectangular resonating plate (assuming of course that we’re talking about a rectangular room).
FINISH THIS OFF
 | (3.68) |
FINISH THIS OFF
FINISH THIS OFF
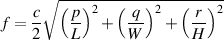 | (3.69) |
Equation 3.69 can also be used as the master equation for calculating any type of room mode – axial, tangential or oblique. For example, let’s say that you wanted to calculate the 2nd harmonic of the axial mode for the width of the room. You set q to equal 2 and set p and r to 0. This winds up making Equation 3.69 exactly the same as Equation 3.67 because the 0’s make the L and H components go away.
sound source couples to the mode
FINISH THIS OFF
We also have to consider how well the mode couples to the receiver.
FINISH THIS OFF
FINISH THIS OFF
So, now we’ve seen that, at high frequencies, we worry about reflections and statistical behaviour of the room. At low frequencies, we worry about room modes, since they’ll ring longer than the reverberation and be the dominant characteristic in the room’s behaviour. The question that should be sitting in the back of your head is “what’s the crossover frequency between the low and the high?”
This frequency is known as the Schroeder frequency or the Schroeder large-room frequency and is defined as the frequency where the modes start bunching so closely together that they no longer are seen as resonant peaks. In most definitions, you’ll see people talking about modal density which is just a measure of the number of resonant modes in a given bandwidth. (This number increases with frequency.)
As a result, a room can be considered in the same way that we think of two-way speakers – the low end has a modal behaviour, the high end is statistical and the crossover is at the Schroeder frequency. This frequency can be calculated using Equation 3.70.
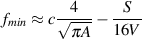 | (3.70) |
where fmin is the Schroeder frequency, A is the room absorption calculated using Equation 3.64, S is the surface area of the boundaries amd V is the room’s volume.
If you go way back in this book, you’ll remember that we mentioned that, for every doubling of distance from a sound source, you get a 6 dB drop in sound pressure level. This rule is true, but only if you’re in a free field like an anechoic chamber or at the top of a pole outdoors. What happens when you’re in a real room? This is where things get a little strange.
If you’re close to an omnidirectional sound source, then the direct sound is very loud compared to all of the reflections, reverberation and modes. As a result, you can sort of pretend that you’re in a free field, so, as you move away from the source, you lose 6 dB per doubling of distance, as if you were normal. However, if you’re far away from the sound source, the total summed power coming into your SPL meter from the reflections, reverberation and room modes is greater than the direct sound. When this is the case, then no matter where you go in the room, you’ll get the same reading on your SPL meter.
Of course, this means that there must be some middle distance where the direct sound’s level is equal to the reflected sound pressure level. This distance is known as the room’s critical distance.
This is a fairly easy thing to measure. Send a sine tone out of a loudspeaker and measure its level with an SPL meter while you’re standing fairly close to it. Back away from the speaker and keep looking at your SPL meter. It should drop as you get farther and farther away, but it will reach some minimum level and not drop below that, no matter how much farther away you get. The distance from the loudspeaker at which this minimum value is reached is the room radius.
Of course, if you don’t want to be bothered to measure this, you could always calculate it using Equation 3.71 []. Notice that the value is dependent on the volume of the room, V and the reverberation time.
 | (3.71) |
I’ve lived most of my adult life in apartment buildings in Montreal and Ottawa. In 12 years, I lived in 10 different apartments in those two cities, and as a result, I feel that I am a qualified expert in sound proofing... or, more to the point, the lack of it.
DEFINE SOUND TRANSMISSION INDEX
The easiest way to introduce airborne sound transmission is to break it up into high frequency and low frequency behaviour. This is because, in most situations, these two frequency bands are transmitted very differently between two spaces.
NOT WRITTEN YET
NOT WRITTEN YET
NOT WRITTEN YET
NOT YET WRITTEN
Acoustical Designing in Architecture Knudsen, V. O. and Harris, C. M. John Wiley and Sons, Inc. (1950)
Acoustics, Noise and Buildings Parkin, P. H. and Humphreys, H. R. Faber and Faber Ltd (1958)
Architectural Acoustics Knudsen, V. O. John Wiley and Sons, Inc. (1932)
Music, Acoustics and Architecture Beranek, L. L. John Wiley and Sons, Inc. (1962)
Architectural Acoustics Knudsen, V. O. Scientific American November 1963